DATA QUALITY TOOLS FOR
DATAWAREHOUSE MODELS
JASPREETI SINGH
Computer Science Department, University School of Information & Communication Technology, Guru Gobind Singh Indraprastha University, Sector-16,Dwarka, New Delhi -110006, India
SRISHTI VASHISHTHA
Computer Science Department, University School of Information & Communication Technology, Guru Gobind Singh Indraprastha University, Sector-16,Dwarka, New Delhi -110006, India
Abstract:
Data quality tools aim at detecting and correcting data problems that influence the accuracy and efficiency of data analysis applications. Data warehousing activities require data quality tools to ready the data and ensure that clean data populates the warehouse, thus raising usability of the warehouse. This research targets on the problems in the data that are addressed by data quality tools. We classify data quality tools based on datawarehouse stages and features of tool; which address the data quality problems and understand their functionalities.
Keywords: Data Quality; Datawarehouse; Data problems; Datawarehouse stages
1. Introduction
Data quality is the reliability and application efficiency of data; particularly when kept in a data warehouse. Attention to data quality is a demanding issue in all areas of information resource management. Nowadays organizations require a high level of data quality in order to efficiently run their data analysis applications (e.g. decision support systems, data mining and customer relationship management) and produce accurate results. The amount of data currently handled is huge, no adequate data entry control is usually performed and data is often obtained by merging different data sources. As a consequence, data anomalies are encountered more frequently than desired [7].
The existence of these data problems, commonly called dirty data, degrades significantly the quality of the information with a direct impact on the efficiency of the business that it supports [7].The elimination of dirty data [14] in information
systems is generally called data cleaning, it aims at obtaining data of high quality. It is a crucial task in various application scenarios.
Data quality tools are emerging as a way to correct and clean this dirty data generated at many stages while constructing and maintaining a datawarehouse (DW) [1]. These tools are used to review the data at the source; transform it so that it is persistent throughout the warehouse, divide it into atomic units, and assure it matches the business rules. Tools are of different types, some tools can be stand-alone packages, or some of them can be combined with data warehouse packages.
This paper is structured into five sections, first section is the introduction, second section describes the quality in data warehouse and database, third section discusses the data quality problems, fourth section represents the features of all tools and finally in the fifth section we present a classification of data quality tools based on fifteen features which address the data quality problems in six stages of DW discussed in section 4 and 5. Last section concludes the paper.
2. What is Quality?
Data quality tools aim at detecting and correcting data problems that affect the accuracy and efficiency of data analysis applications. Demand for data quality tools remains strong, with deployments in support of master data management, modernization and information governance programs. Competition among large vendors grows fiercer due to convergence between data quality tools and data integration tools. We propose a classification of relevant data quality tools that can be used as a framework for comparing tools and understand their functionalities.
2.1 Quality in database
tables is called a “relational database,” and such databases are constructed to handle all types of data. Database designers create and work with relational databases on a regular basis. However, these practitioners can face numerous problems when building a database using tables. One common problem is data redundancy, which occurs when data are duplicated in a database table, or relation. These duplicated data can cause anomalies that affect data quality and provide users with incorrect information. The way the data is entered, stored and managed, affects the data quality.
Quality in database means data which is consistent, well integrated, having standard representation, with no duplicate records and no missing values.
Within a single data source (e.g., list of customers), it is essential to correct integrity problems, standardize values, fill in missing data and consolidate duplicate occurrences. We refer to a data quality process as the sequence of data transformations that must be applied to data with problems in order to get data of good quality. Data quality tools are the software artifacts that take part.
2.2 Quality in datawarehouse
Quality considerations have accompanied DW research from the beginning. Over the past few years, a major portion of literature has evolved in tackling the problems introduced by the DW approach, such as the trade-off between freshness of DW data and disturbance of OLTP work during data extraction; the minimization of data transfer through incremental view maintenance; and a theory of computation with multidimensional data models.
Data quality is composed of data definition quality and the data content quality. Data definition quality is the degree to which data definition accurately describes the meaning of the real-world entity type or fact-type that the data represents. Data content quality is the degree to which data values accurately represent the characteristics of the real-world entity or fact and meet the need of the information costumers to perform their jobs effectively. [6]
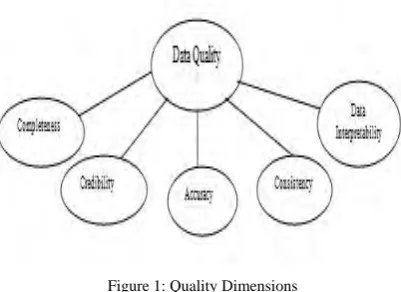
The quality of the data which is kept in the warehouse is influenced by all the processes which take place in the warehouse environment. We define data quality as a small subset of the dimensions proposed in other models. The basic quality dimensions we introduce are shown in figure:
Figure 1: Quality Dimensions
The existence of data alone does not ensure that all the management functions and decisions can be smoothly undertaken. The one definition of data quality is that it's about bad data [8] [14] - data that is missing or incorrect or invalid in some context. Abundant attempts have been made to define data quality and to identify its dimensions. Dimensions of data quality typically include accuracy, reliability, importance, consistency, precision, timeliness, fineness, understandability, conciseness and usefulness. We have undertaken the quality criteria by taking six key dimensions [11]:
Completeness: Is all the required information available? Are some data values missing, or in an unusable state?
Consistency: Do distinct occurrences of the same data instances agree with each other or provide conflicting information. Are values consistent across data sets?
Validity: Refers to the correctness and rationality of data.
Conformity: Check whether the data values conform to specified formats? Also check that do all the values conform to those formats? Maintaining conformance to specific formats is essential.
Accuracy: Ensure that data objects accurately represent the “real world” values they are expected to model. Incorrect spellings of product or person names, addresses, and even untimely or not current data can impact operational and analytical applications.
3.Data Quality Problems
This section discusses the Data Quality Problems in two domains: Database and Datawarehouse. 3.1 Data quality problems in database
The following list summarizes data quality problems that can be avoided by Relational Database Management System (RDBMS) [7] [8]:
Missing data: Data that has not been filled. A ‘not null’ constraint can avoid this problem. [1] Wrong data type: Violation of a data type constraint. Domain constraints can avoid this problem.
Wrong data value: Violation of a data range constraint. Check and domain constraints are used to avoid this problem.
Dangling data: Data in one table has no counterpart in another table. For example, a department identifier does not exist in the Department table and there is a reference to this value in the Employee table. This problem is addressed by referential integrity constraints (i.e. foreign keys).
Exact duplicate data: Different records have the same value in a field (or a combination of fields) for which duplicate values are not allowed. Unique and primary key constraints can avoid exact duplicates.
Generic domain constraints: Records or attribute values that violate a domain restriction. Domain and assertion constraints intend to avoid this problem.
The following data quality problems cannot be handled by RDBMS integrity constraints [7]:
Wrong categorical data: A category value that is out of the category range. The use of a wrong abstraction levels is also considered a type of wrong categorical data.
Outdated temporal data: Data that violates a temporal constraint that specifies the time instant or interval in which data is valid. For example, an employee salary is no longer valid when this employee’s salary has been raised.
Inconsistent spatial data: Inconsistencies between spatial data (e.g. coordinates, shapes) when they are stored in multiple fields.
Name conflicts: The same field name is used for different objects (homonyms) or different names are used for the same object (synonyms).
Structural conflicts: Different schema representations of the same object in different tables or databases. Other quality issues are [7]:
Duplicate records: Records that stand for the same real entity and do not contain contradicting information. Contradicting records: Records that stand for the same real entity and contain some kind of contradicting information.
Non-standardized data: Different records do not use the same representations of data, thus invalidating their comparison.
Ambiguous data: Data that can be interpreted in more than one way, with different meanings. Ambiguous data may occur due to the existence of abbreviation or an incomplete context.
Erroneous data: The data is valid but does not conform to the real entity. Misspellings: Misspelled words in database fields.
Misfielded values: Data is stored in the wrong field. 3.2 Data quality problems in datawarehouse
The Data Quality problems are vulnerable to following phases of data warehousing: Data Sourcing, Data Integration and Data Profiling, Data Staging & ETL and Database Scheme (Modeling).
Quality of data can be compromised depending upon how the data is received, entered, integrated, maintained, processed (Extracted, Transformed and Cleansed) and loaded. Data is impacted by numerous processes that bring data into your data environment, most of which affect its quality to some extent. Data quality in the data warehouse is influenced by all these phases of data warehousing. Despite all the efforts, there still exists a certain proportion of dirty data [14]. This residual dirty data should be reported, stating the reasons for the failure in data cleansing for the same.
Table 1. Datawarehouse data quality problems
S. No. Data Quality Problems in
Datawarehouse
1 Poor data handling procedures and processes.
2 Failure to stick to data entry and maintenance procedures.
3 Errors in the migration process from one system to another.
4
External and third-party data that may not fit with your company data standards or may otherwise be of unconvinced quality.
3.2.1 Data quality problems at data source
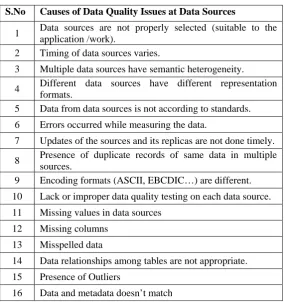
A leading cause of data warehouse and business intelligence project failures is to obtain the wrong or poor quality data. Since data is collected from many heterogeneous data sources, each of these data sources has their own representation, different storing methods and is of different type. Because of this diversity, several factors arise, which may contribute to data quality problems, if not properly examined. Table 2 lists the possible causes of data quality problems at data sources stage of data warehousing. [11]
Table 2. Causes of Data Quality Issues at Data Sources
S.No Causes of Data Quality Issues at Data Sources
1 Data sources are not properly selected (suitable to the application /work).
2 Timing of data sources varies.
3 Multiple data sources have semantic heterogeneity.
4 Different data sources have different representation formats.
5 Data from data sources is not according to standards.
6 Errors occurred while measuring the data.
7 Updates of the sources and its replicas are not done timely.
8 Presence of duplicate records of same data in multiple sources.
9 Encoding formats (ASCII, EBCDIC…) are different.
10 Lack or improper data quality testing on each data source.
11 Missing values in data sources
12 Missing columns
13 Misspelled data
14 Data relationships among tables are not appropriate.
15 Presence of Outliers
16 Data and metadata doesn’t match
3.2.2 Data quality problems in data profiling
Table 3. Causes of Data Quality Issues at Data Profiling Stage
S.No Causes of data quality problems at Data Profiling Stage
1 Data profiling of data sources not done sufficiently.
2 Inappropriate selection of data profiling tool.
3 Insufficient data content and structural analysis of data sources.
4 Alterations identified during data profiling are not documented properly.
5 Inappropriate parsing of records and fields to common format.
6 Missing data relationships are not identified.
7 Inappropriate standardization of records & fields to common format.
8 Incomplete and unreliable metadata of data sources.
9
Inability of integration between data profiling, ETL cause no proper flow of metadata which leave data quality problems.
3.2.3 Data quality problems in data staging ETL (Extraction, Transformation and Loading)
A data cleaning [9] process is executed in the data staging area in order to improve the accuracy of the data warehouse. The data staging area is the place where all 'grooming' is done on data after it is extracted from the source systems. Staging and ETL phase is considered to be the most critical stage of data warehousing where maximum responsibility of data quality efforts resides. It is a prime location for authenticating data quality from source or auditing and tracking down data issues. Table 4 summarizes the possible causes of data quality problems at data staging ETL of data warehousing.
Table 4. Causes of Data Quality Issues at Data ETL Stage
S.No Causes of data quality problems at Data ETL Stage
1 Type of architecture of data warehouse (Staging or Non Staging).
2 Different business rules of various data sources.
3 Lack of capturing only the changes in source files.
4 Lack of periodic refreshing of integrated data storage.
5 Extraction of data into required fields not done properly.
6 Lack of error reporting, validation and metadata updates in ETL.
7 Inappropriate handling of audit columns.
8 Inappropriate handling of update strategy (insert/delete/update) in ETL process.
9 Type of load strategy opted
(Bulk/Batch/Simple).
3.2.4 Data quality problems in data modeling
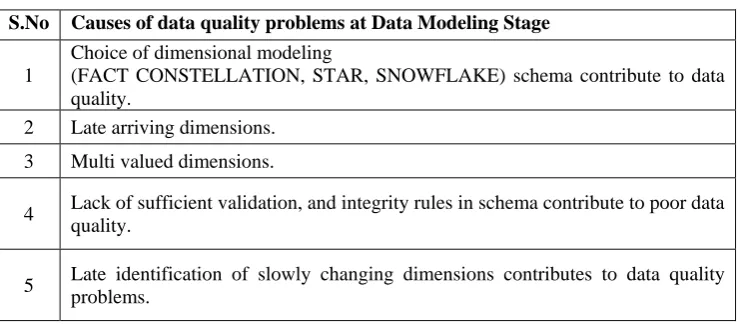
Design of the data warehouse greatly influences the quality of analysis that is possible with data in it. So, special attention should be given to the issues of schema design. A defective schema impacts negatively on the information quality. Table 5 summarizes the possible causes of data quality problems at data modeling stage of data warehousing. [11]
Table 5. Causes of Data Quality Issues at Data Modeling Stage
S.No Causes of data quality problems at Data Modeling Stage
1
Choice of dimensional modeling
(FACT CONSTELLATION, STAR, SNOWFLAKE) schema contribute to data quality.
2 Late arriving dimensions.
3 Multi valued dimensions.
4 Lack of sufficient validation, and integrity rules in schema contribute to poor data quality.
5 Late identification of slowly changing dimensions contributes to data quality problems.
4. Features of Data Quality Tools
In this section, we introduce the major features of data quality tools that we analyzed. Cleansing tools can be useful in automating many of the activities that are involved in cleansing the data- parsing, standardization, verification, validation, correction and matching. Generalized "cleansing" [9] is the modification of data values to meet domain restrictions, integrity constraints or other business rules that define when the quality of data is sufficient for the organization. Other tools are auditing, extraction, loading, etc. First, we describe each feature. Then, we summarize, in table 5 in section 5 [13].
1.Data standardization: converts the data elements to forms that are standard throughout the data warehouse.
2.Data Deduplication: converts the data elements to forms that no duplicate records exist throughout the data warehouse.
3.Data correction and verification: matches the data against known lists, such as Postal Codes, product lists, internal customer lists, etc.
4.Data Parsing: The decomposition of text fields into component parts and the formatting of values into consistent layouts. It breaks a record into atomic units that can be used in subsequent steps. Parsing includes placing elements of a record into the correct fields.
5.Data Matching: Identifying, linking or merging related entries within or across sets of data.
6.Data Enrichment: Enhancing the value of internally held data by appending related attributes from external sources.
7.Data Profiling: The analysis of data to capture statistics (metadata) that provides insight into the quality of the data and helps identify data quality issues.
8.Data Integrity: The ability to link related records together so that no duplication occurs across your systems. Data from heterogeneous data sources are well integrated. [3]
9.Data Auditing: To enhance the accuracy and correctness of the data at the source. Generally the data in the source database is compared to a set of business rules.
10.Data sources: The ability to extract data from different and heterogeneous data sources. Data sources may be relational databases, flat files, XML files, spreadsheets, legacy systems and application packages, such as SAP, Web based sources and EAI (Enterprise Application Integration) software.
11.Extraction capabilities: The process of extracting data from data sources should provide the following important capabilities: (i) the ability to schedule extracts by time, interval or event; (ii) a set of rules for selecting data from the source and (iii) the ability to select and merge records from multiple sources.
12.Loading capabilities: The process of loading data into the target system should be able to: (i)load data into multiple types of target systems; (ii)load data into heterogeneous target systems in parallel; (iii)both refresh and append data in the target data source and (iv)automatically create target tables.
13.Metadata repository: A repository that stores data schemas and information about the design of the data quality process. This information is consumed during the execution of data quality processes.
15.Performance techniques: Set of features to speed up data cleaning processes and to ensure scalability. Important techniques to improve performance are partitioning, parallel processing, threads, clustering & load balancing.
5. Classification of Tools based on the Features and Datawarehouse stages
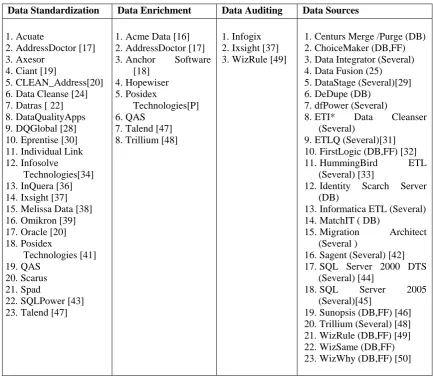
This section presents a classification of data quality tools based on their features which address the data quality problems along with the stages of DW. Fifteen features [13] have been taken under consideration; their functionalities have already been discussed in previous section. Six stages of DW are: Data Sources, Integration & Data Profiling, ETL, Data Modeling, Testing and Maintenance. Following are the classification tables (6-11):
DATA SOURCES
Table 6. Tools and their features in Data Sources Stage
Data Standardization Data Enrichment Data Auditing Data Sources
1. Acuate
2. AddressDoctor [17] 3. Axesor
4. Ciant [19]
5. CLEAN_Address[20] 6. Data Cleanse [24] 7. Datras [ 22] 8. DataQualityApps 9. DQGlobal [28] 10. Eprentise [30] 11. Individual Link 12. Infosolve
Technologies[34] 13. InQuera [36] 14. Ixsight [37] 15. Melissa Data [38] 16. Omikron [39] 17. Oracle [20] 18. Posidex
Technologies [41] 19. QAS
20. Scarus 21. Spad
22. SQLPower [43] 23. Talend [47]
1. Acme Data [16] 2. AddressDoctor [17] 3. Anchor Software
[18] 4. Hopewiser 5. Posidex
Technologies[P] 6. QAS
7. Talend [47] 8. Trillium [48]
1. Infogix 2. Ixsight [37] 3. WizRule [49]
1. Centurs Merge /Purge (DB) 2. ChoiceMaker (DB,FF) 3. Data Integrator (Several) 4. Data Fusion (25) 5. DataStage (Several)[29] 6. DeDupe (DB)
7. dfPower (Several)
8. ETI* Data Cleanser (Several)
9. ETLQ (Several)[31] 10. FirstLogic (DB,FF) [32]
11. HummingBird ETL (Several) [33]
12. Identity Scarch Server (DB)
13. Informatica ETL (Several) 14. MatchIT ( DB)
15. Migration Architect (Several )
16. Sagent (Several) [42] 17. SQL Server 2000 DTS
(Several) [44]
18. SQL Server 2005 (Several)[45]
INTEGRATION & DATA PROFILING
Table 7. Tools and their features in Integration & Data Profiling
Data DeDuplication Data Correction &
Verification
Data Parsing
1. Anchor Software [18] 2. Acuate
3. Ataccama 4. Axesor 5. BBC Software 6. Caatoose
7. Data Quality Apps 8. DQGlobal [28] 9. Eprentise [30] 10. helpITSystems 11. Hopewiser
12. InfosolveTechnologies [34] 13. Intelligent Search
Technology 14. InQuera [36] 15. Ixsight [37] 16. Omikron [39] 17. QAS
18. Scarus
19. SigmaDataServices 20. SQLPower [43] 21. WinPure
1. Acme Data [16] 2. AddressDoctor [17] 3. Ataccama
4. BBC Software 5. CLEAN_Address 6. Data8
7. DQGlobal [28] 8. Hopewiser
9. Infosolve Technologies [34] 10. MelissaData [38]
11. PostLocate 12. QAS
13. SQLPower [43]
1. Ataccama 2. Ciant [19] 3. Data Cleanse [24] 4. Data Quality Apps 5. Individual Link 6. Oracle [40] 7. Scarus 8. TS Quality 9. Trillium [48]
Data Matching Data Profiling Data Integrity
1. Acme Data [16] 2. Acuate
3. Ataccama 4. Caatoose 5. Ciant [19]
6. Data Quality Apps 7. DQGlobal [28] 8. Eprentise [30] 9. helpITSystems
10. InfosolveTechnologies [34] 11. InQuera [36]
12. IntelligentSeacrhTechnology 13. Oracle [40]
14. QAS
15. Posidex Technologies[41] 16. PostLocate
17. Talend[47] 18. Trillium[48] 19. TS Quality 20. WinPure
1. Ataccama 2. Datras [22] 3. Datiris
4. Intelligent Search
Technology
5. Posidex Technologies[41] 6. Sigma Data Services 7. Spad
8. Talend[47] 9. TIQ Solutions 10. TS Discovery [48]
ETL ( EXTRACTION TRANSFORMATION & LOADING)
Table 8. Tools and their features in ETL Stage
Extraction Capabilities Loading Capabilities
1. Data Integrator 2. Data Fusion [25] 3. Data Stage [29] 4. dfPower [26] 5. ETLQ [31] 6. FirstLogic [32]
7. Hummingbird ETL [33] 8. Informatica ETL [35] 9. Sagent [42]
10. SQL Server 2000 DTS (Several) [44] 11. SQL Server 2005 (Several) [45] 12. Sunopsis (DB,FF)[46]
13. Trillium (Several)[48]
1. Data Integrator 2. Data Fusion [25] 3. Data Stage [29] 4. dfPower [26] 5. ETLQ [31] 6. FirstLogic [32]
7. Hummingbird ETL [33] 8. Informatica ETL [35] 9. Sagent [42]
10. SQL Server 2000 DTS [44] 11. SQL Server 2005 [45] 12. Sunopsis [46] 13. Trillium[48]
DATA MODELING
Table 9. Tools and their features in Data Modeling Stage
Metadata Repository
1. ChoiceMaker [20] 2. Data Integrator 3. Data Stage [29] 4. dfPower [26] 5. ETI*Data Cleanser 6. ETLQ [31]
7. FirstLogic [32]
8. HummingBird ETL[33] 9. Identity Scarch Server 10. Informatica ETL [35] 11. Mirgration Architect 12. Sagent [42]
13. Sunopsis [46] 14. Trillium[48]
TESTING
Table 10. Tools and their features in Testing Stage
Debugging & Tracing
1. ChoiceMaker[20] 2. Data Integrator 3. Data Blade [23] 4. Data Fusion[25] 5. Data Stage[29]
6. Hummingbird ETL [33] 7. Informatica ETL[35] 8. Match IT
MAINTENANCE
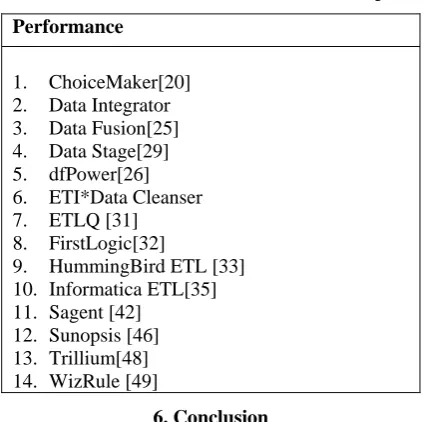
Table 11. Tools and their features in Maintenance Stage
Performance
1. ChoiceMaker[20] 2. Data Integrator 3. Data Fusion[25] 4. Data Stage[29] 5. dfPower[26] 6. ETI*Data Cleanser 7. ETLQ [31]
8. FirstLogic[32]
9. HummingBird ETL [33] 10. Informatica ETL[35] 11. Sagent [42]
12. Sunopsis [46] 13. Trillium[48] 14. WizRule [49]
6. Conclusion
Data quality tools transform data with problems into good quality data for a certain application domain. In this paper we have classified data quality tools according to their features which address quality issues and the stages of data warehousing.
Data quality tools are available to enhance the quality of the data at several stages in the process of developing a data warehouse. Cleansing tools can be useful in automating many of the activities that are involved in cleansing the data- parsing, standardization, verification, validation, correction and matching. Many of the tools specialize in auditing the data, discovering patterns in the data, and comparing the data to business rules. Data extraction and loading tools are accessible to translate the data from one platform to another, and populate the data warehouse. Data quality tools are used in data warehousing to ready the data and ensure that clean data populates the warehouse, thus enhancing the usability of the warehouse. This classification of tools will assist data warehouse users in many processes of data warehousing. Thus these tools will help in improving the overall development process of a datawarehouse.
References
[1] English, L. (1998). “Data Quality: Meeting Customer Needs”, Pitney Bowes white paper
[2] English, L., (1996). “Help for Data Quality Problems”, InformationWeek, October 7,1996, pp. 53 [3] Horowitz, A. (1998). “Ensuring the Integrity of Your Data”, Beyond Computing, May1998.
[4] J. Hammer, H. Garcia-Molina, J. Widom, W. Labio, Y. Zhuge. The Stanford Data Warehousing Project. Data Eng., Special Issue Materialized Views on Data Warehousing,18(2), pp. 41-48, 1995.
[5] Greenfield, L. (1998). “Data Cleaning, Extraction and Loading Tools”.
[6] M. Janson. Data quality: the Achilles heel of end-user computing, 361 “ Design and Analysis of Quality Information for Data Warehouses’’ Omega J. Management Science, 16, 5, 1988.
[7] José Barateiro, Helena Galhardas “A survey of data quality tools” [8] Kimball, R. (1996). “Dealing with Dirty Data” DBMS Online.
[9] Moss, L. (1998). “Data Cleansing: A Dichotomy of Data Warehousing?”, DM Review Magazine, February 1998.
[10] O’ Neill, P. (1998). “It’s a Dirty Job: Cleaning Data in the Warehouse”, Gartner Group,January 12, 1998. [11] Ranjit Singh, Dr. Kawaljeet Singh “A Descriptive Classification of Causes of Data Quality Problems in
Data Warehousing”, May 2010.
[12] Strange, K. (1997). “A Taxonomy of Data Quality”, Gartner Group, May 29, 1997. [13] Ted Friedman, Andreas Bitterer, “Magic Quadrant for Data Quality Tools”, 25 June 2010. [14] Won Kim et al (2002)- “A Taxonomy of Dirty.
[15] Watterson, K. (1998). “Dirty Data, Dumb Decisions”, DM Review Magazine, March 1998. [16] Acme Data; www.acmedata.net
[17] Address Doctor; www.addressdoctor.com
[18] Anchor Software; www.anchorcomputersoftware.com [19] Ciant; www.ciant.com
[21] Data Quality Tools for Data Warehousing A Small Sample Survey; http://www.ctg.albany.edu/publications/reports/data_quality_tools}.
[22] Datras; www.datras.de
[23] DataBlade (IBM); http://www.informix.com
[24] Data Cleanse; http://www.innovativesystems.com/technology_solutions/dq_cleanse_link_household.php [25] DataFusion (Oblog); http://www.oblog.pt.
[26] dfPower (DataFlux a SAS Company); [27] Data Flux; http://www.dataflux.com [28] DQ Global; www.dqglobal.com
[29] DataStage (Ascential); http://www.ascential.com [30] Eperentise; www.eprentise.com
[31] ETLQ(SAS); http://www.sas.com. [32] Firstlogic; http://www.firstlogic.com
[33] Hummingbird ETL (Genio); http://www.hummingbird.com. [34] InfosolveTechnologies; www.infosolvetech.com
[35] Boosting Data Quality for Business Success”, INFORMATICA White Paper, 2006 [Innovative Systems] http://www.innovativesystems.com
[36] Inquera www.inquera.com [37] Ixsight www.ixsight.com
[38] Melissa Data; http://www.melissadata.com/dqt/ibm.htm [39] Omikron; www.omikron.net
[40] Oracle; www.oracle.com [41] Posidex; www.posidex.com
[42] Sagent (Group 1 Software); http://www. sagent.com. [43] SQLPower www.sqlpower.ca
[44] SQL Server 2000 DTS (Microsoft); http://www.microsoft.com [45] SQL Server 2005 (Microsoft); http://www. microsoft.com [46] Sunopsis http://www.sunopsis.com.
[47] Talend; https://www.talend.com/products/data-quality [48] Trillium; http://www.trilliumsoft.com.