IDENTIFICATION OF DOMAIN AND
SUPERVISED LEARNING
CLASSIFICATIONS IN ACADEMIC
SOCIAL NETWORK
G.Ayyappan1, Dr.C.Nalini2, Dr.A.Kumaravel3
Research Scholar, Department of Computer Science, Bharath University1 Professor, Department of Computer Science, Bharath University2
Professor & Head, School of Computing, Bharath Unviersity3
[email protected], [email protected]2,[email protected]3
Abstract
Social network is a structure of human relations and association. The research journals serve as major source of primary information. The challenge of comparative analysis of published research in recent years becomes heavy due to increase in number of digital libraries and information content providers and their infra structure. However the infrastructure for tracking such research developments still remains a larger gap. Current information search services for research content, mainly based on bibliographic metadata, are not intelligent enough to understand the meaning of the content in research documents. It is required to identify, extract and manage meaningful information about the content embedded in research document, which is not readily available. None of the digital libraries are capable of providing information about the publications that support and challenge a given document and would not be able to trace the intellectual lineage for a given idea. The Researchers tend to publish more and more research output in journals. This paper focuses on Classification research articles from highly interconnected domains (with difficulty of associating with single broad domain) with Topic Modeling and Supervised Learning in academic social network.
Key Terms: Data Mining, Academic Social Network, Topic modeling, Supervised learning. I INTRODUCTION
In this section we focus on a different aspect of identifying the leading contributor as there is a relative lack of theory-based leadership studies in an R&D context (Scott & Bruce, 1998). More recent research has moved beyond simple examinations of leaders’ traits and behaviors and we in particular consider the exchanges with the members, frequency of publications, participation at conference, etc.
Social network is a structure of human relations and association. It is made up of a organized social actors in a network form. Information has varied number of forms and various purposes for communication. Journals serve as major source of primary information; researchers tend to publish more and more research output in journals. Jie Tang et al.,[1] Extraction and mining of academic social networks aims at providing comprehensive services in the scientific research field. An academic social network, people are not only interested in searching for different types of information (such as authors, conferences, and papers), but are also interested in finding semantics-based information (such as structured researcher profiles). During the last few decades observed a dramatic development in co-production of research results. Almost every paper in the research field is co-authored.
The Section one introduces the topic of research and explains need for the study. The section two deals with the review of Literature pertaining to the research problem. The section three, deals with the materials pertaining to the research problem. The section four, deals with analysis of empirical methods and identifying leading research contributors using novel metrics. Finally section five, consist of the conclusion.
II RELATED WORKS
Jie Tang et al.[3] proposed to simultaneously model topical aspects of authors, research articles, authors and publication locations. Search services such as expertise search and people association search have been provided based on the modeling results. Jie Tang et al.[4] proposed the Cross-domain collaborations exhibit very different patterns compared to traditional collaborations in the same domain. Jie Tang et al[5] proposed and developed The extracted profiles have been applied to expert finding, an important application on the Web. Jie Tang et al.[6] defined a two-step parameter estimation algorithm. Ash Mohammad Abbas [7] proposed and developed positionally weighted and equally weighted of authors for the research community.
III TERMS AND METHODS Data Mining
Data Mining is about explaining the past and predicting the future by means of data analysis. It is a multi-disciplinary field which combines database technology machine learning, statistics, and artificial intelligence.
Topic Modeling
Topic modeling is a form of text mining, a way of identifying patterns in a corpus. You take your corpus and run it through a tool which groups words across the corpus into ‘topics’.
The dataset named as topic_paper_author in the academic social network data fromAMiner [8,9].The dataset is collected for the purpose of cross domain recommendation. The attributes contain Data Mining, Medical Informatics, Theory, Visualization and Database areas.
In this research work used Weka 3.6.9 [11], open source software for Text Mining process, MeSH [12] for identification of specific research domain.
IV EXPERIMENTS AND RESULTS
In this experiment we go through two components one for extracting the themes in the article’s abstract by topic modeling and the second one for classifying those identified topics in to the domain subject area. Further we design the experiment for the classification of the topics focusing on parameter tuning for KNN classifiers. For this purpose we collect the dataset named as topic_paper_author in the academic social network data from
https://aminer.org/topic_paper_author [1].
S.No Attribute Data type
1 Conference Name Text
2 Title Text
3 Year Numeric
4 Abstract Text
5 Authors Text
Table 1 Description of Topic_Paper_Author Dataset
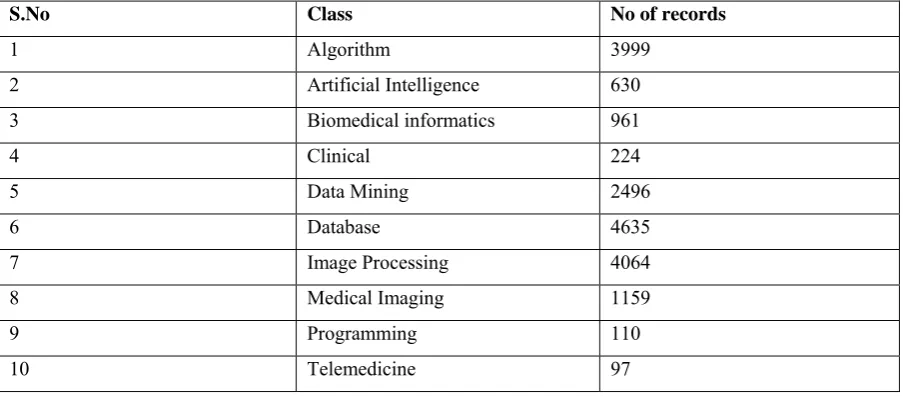
There are 10 classes in topic attribute. namely, Algorithm, Artificial Intelligence, Biomedical informatics, Clinical, Data Mining, Database, Image Processing, Medical Imaging, Programming, Telemedicine.
S.No Class No of records
1 Algorithm 3999
2 Artificial Intelligence 630
3 Biomedical informatics 961
4 Clinical 224
5 Data Mining 2496
6 Database 4635
7 Image Processing 4064
8 Medical Imaging 1159
9 Programming 110
10 Telemedicine 97
Fig.1 Proposed Architecture of K-NN
The first component in this experiment is realized by help of the tool MeSH(Medical Subject Headings) (Topic Extraction Tool) is recommended for extracting the topics for the abstracts available as a column/
attribute in the dataset discussed above. The Topics are divided into categories like as Algorithm, Data mining, Database, Artificial Intelligence, Clinical, Medical Imaging, Image Processing, Biomedical Informatics, Image Processing, and Telemedicine.This happens to be a little exercise around the topic modeling.
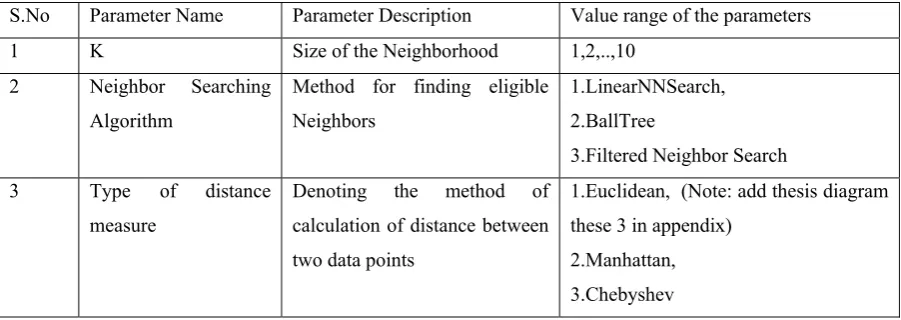
The second component in this experiment is realized by tuning the parameters of the KNN classifiers for bringing out the better classification accuracy for the categorizing the subject catalog for the given dataset namely the ‘Topic Paper Author’ dataset. It contains 18375 instances and 5 attributes. We do the parameter tuning for three parameters namely, Number of neighbors, Neighbor search algorithms and Type of distances. The range of parameters values are as follows.
Dataset: Academic Social Network Dataset (Topic_Paper_Author)
Collection of Abstracts
Convert Abstracts into Topics by Using MeSH (Topic Extraction Tool)
Get Topic Modeling
K‐nearest neighbours Classification
Convert Text into Comma Separated Value
Parameter Tuning:
Parameters ‐>
1) K: No.of Neighbours 1...10
2) Neighbour Search algorithm: LinearNNSearch, BallTree, and Filtered‐
NeigbhourSearch
3) Type of distance Variation: Euclidean, Manhattan, Chebyshev
Model Evaluation
10‐FoldCross Validation for Maximum Accuracy
S.No Parameter Name Parameter Description Value range of the parameters 1 K Size of the Neighborhood 1,2,..,10
2 Neighbor Searching Algorithm
Method for finding eligible Neighbors
1.LinearNNSearch, 2.BallTree
3.Filtered Neighbor Search 3 Type of distance
measure
Denoting the method of calculation of distance between two data points
1.Euclidean, (Note: add thesis diagram these 3 in appendix)
2.Manhattan, 3.Chebyshev Table 3 Parameter tuning details
We are performing the iterations over the values of the parameters as shown in the table 3 using 10 fold cross validation for increasing the accuracy of the model. In this research work we apply various k values in the topic modeling relational data model. We identify the high accuracy based on the below table. To identify the high accuracy based on apply various methods in k-NN like as LinearNNSearch, BallTree and FilteredNeighbourSearch methods and the below table.
KNN LinearNNSearch BallTree FilteredNeigbhourSearch 1 95.3796 95.3796 95.3796
2 95.5156 95.5156 95.5156 3 95.5483 95.5483 95.5483 4 95.5483 95.5483 95.5483 5 95.5483 95.5483 95.5483 6 95.5374 95.5374 95.5374 7 95.5537 95.5537 95.5537 8 95.5537 95.5537 95.5537
9 95.5592 95.5592 95.5592
10 95.5592 95.5592 95.5592
Table 4 Various K-NN Classification Accuracies
V CONCLUSION
The problem of extracting from the huge dataset for author article relationship with appropriate classifier with best accuracy is considered by carrying out the experiment . In this experiment to identify the best K-Nearest Neighbor classifier as the combination (9, FilterNeibourSearch, Euclidean) as it yields maximum accuracy as evident from the tables and figures enumerated in the previous section.
REFERENCES
[1] J. Tang, J. Zhang, L. Yao, J. Li, L. Zhang, and Z. Su, “Extraction and Mining of an Academic Social Network,” Proc. 14th ACM SIGKDD Int. Conf. Knowl. Discov. data Min., pp. 1193–1194, 2008.
articles,” Sci. Eng. Ethics, vol. 20, no. 2, pp. 345–361, 2014.
[3] G.Ayyappan, Dr.C.Nalini, Dr.A.Kumaravel, "IDENTIFICATION OF LEADING RESEARCH CONTRIBUTORS WITH NOVEL PERFORMANCE METRICS USING ACADEMIC SOCIAL NETWORK." International Journal on Computer Science and Engineering, Vol 9, No 9, pp 580-584, 2017.
[4] N. A. Aziz and M. P. Rozing, “Profit ( p ) -Index : The Degree to Which Authors Profit from,” vol. 8, no. 4, pp. 1–8, 2013. [5] J. Tang, S. Wu, J. Sun, and H. Su, “Cross-domain collaboration recommendation,” Kdd, p. 1285, 2012.
[6] J. Tang, L. Yao, D. Zhang, and J. Zhang, “A Combination Approach to Web User Profiling,” ACM Trans. Knowl. Discov. Data, vol. 5, no. 1, pp. 1–38, 2010.
[7] J. Tang, A. C. M. Fong, B. Wang, and J. Zhang, “A unified probabilistic framework for name disambiguation in digital library,” IEEE Trans. Knowl. Data Eng., vol. 24, no. 6, pp. 975–987, 2012.
[8] A. M. Abbas, “Weighted indices for evaluating the quality of research with multiple authorship,” Scientometrics, vol. 88, no. 1, pp. 107– 131, 2011.
[9] https://aminer.org/data#Academic%20Social%20Network [10] https://aminer.org/data#Topic-paper-author
[11] https://aminer.org/data