International Journal of Scientific Research in Computer Science, Engineering and Information Technology
© 2018 IJSRCSEIT | Volume 3 | Issue 4 | ISSN : 2456-3307
Serverless Computing with AWS Lambda
G Hari Prasad1, A. J. Rajasekhar21Department of MCA Sree Vidyanikethan Institute of Management, Sri Venkateswara University, Tirupati,
Andhra Pradesh, India
2Assistant Professor, Department of MCA, Sree Vidyanikethan Institute of Management,
Tirupati, Andhra Pradesh, India
ABSTRACT
Serverless models speak to another way to deal with planning applications in the cloud without having to unequivocally arrangement or oversee servers. .e designer specifies capacities with well defined passage and leave focuses, and the cloud supplier handles every single other part of execution. In this paper, we investigate a novel utilization of serverless designs to data recovery and portray a web crawler worked in this way with Amazon Web Services: postings records are put away in the DynamoDB NoSQL store and the postings traversal algorithm for query assessment is executed in the Lambda benefit. .e result is a web crawler that scales flexibly with a compensation for every demand show, as opposed to a server-based model that requires paying for running cases regardless of whether there are no solicitations. We exactly evaluate the execution and financial matters of our serverless engineering. While our execution is as of now too moderate for intuitive seeking, investigation demonstrates that the compensation per-ask for show is financially convincing, and future foundation enhancements will expand the attractiveness of serverless outlines after some time.
Keywords: Serverless computing, Server, Cloud Computing
I.
INTRODUCTION
Servers, referring to both software stacks and the machines they keep running on, are fundamental to the design of data recovery frameworks. In the standard outline, a look benefit sits tight for demands from a customer in view of some outstanding convention (e.g., HTTP or a RPC structure), executes the query, and returns the outcome. In an appropriated seek engineering, every server may just be in charge of a little segment of the whole report accumulation, and there might be numerous imitations of a similar service, yet servers remain the essential building piece. .e appearance of cloud computing implies that physical machines are these days progressively supplanted by on-request virtualized examples under a compensation as-you-go display. Be that as it may, running a web index
should be executed with all around defined passage and leave focuses, and Amazon handles the real execution of the code—from a couple of times each day to a great many solicitations for every second. .is paper investigates uses of serverless models for data recovery and portrays a pursuit application fabricated completely utilizing this approach with Amazon Web Services. Our key understanding is that query separates into two parts: postings records that include the list and postings traversal algorithms that control the postings to figure query comes about. .e postings records speak to the "state" of the application, which we store in Amazon's DynamoDB NoSQL store. .e "stateless" query assessment algorithm is embodied in Lambda code that gets postings of query terms put away in DynamoDB to process query comes about. .e commitment of this work is the first use of serverless processing to data recovery that we know about. We demonstrate that it is surely conceivable to fabricate a completely useful web crawler that does not require the express provisioning or service of servers. Exploratory outcomes demonstrate that our plan yields end-to-end query latencies of around three seconds on a standard web test accumulation of roughly 25 million records. While this dormancy isn't worthy for intuitive recovery today, the financial matters of the compensation per-ask for demonstrate is convincing. We trust that our outline is fascinating, and as serverless structures pick up prominence, foundation enhancements will build the attractiveness of our approach after some time.
II.
BACKGROUND
Serverless computing speaks to the intelligent augmentation of the "as an service" cloud computing pattern that started vigorously 10 years prior (despite the fact that points of reference go back numerous decades to the appearance of timesharing machines). Infrastructure as a service (IaaS) gives flexible, on-request registering resources, ordinarily as virtual machines—Amazon's EC2 was the first and remains the most noticeable case of this model, despite the
worldview. Such decay is consonant with the "mircoservices" engineering that is in vogue today. For instance, Hendrickson et al. conjecture about what it would take to revamp Gmail in a totally serverless outline, and the leaps forward important to make it a reality. In this paper, we center on the backend and investigate what serverless data recovery may resemble.
III.
SERVERLESS DESIGN
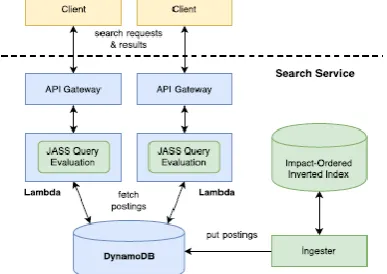
This area depicts the plan of our serverless pursuit engineering, appeared in Figure 1. We clarify how list structures are mapped to DynamoDB and how the query assessment algorithm is executed utilizing Lambda capacities. At show, we have planned our framework altogether around Amazon Web Services and along these lines seller secure is a worry. Other cloud suppliers o.er comparable abilities, in spite of the fact that they are not as develop as Amazon's services. Cloud interoperability is a critical issue in its own right, however past the extent of our work. In this paper, we consider the JASS score-at once query assessment algorithm on affect requested records is approach has been appeared to be both effective and efficient contrasted with state-of the-craftsmanship record at once approaches.
Figure 1. Our serverless search architecture.
AWS infrastructure is appeared in blue (Lambda and DynamoDB) and our custom segments are appeared in green. For each portion, its effect score is stacked, and for each docid in the section, the effect score is added to its aggregator. In JASS, the gatherers are
actualized as a variety of 16-bit whole numbers, one for each record, listed by the docid. To abstain from arranging the gatherers once all postings fragments have been prepared, a pile of the best k can be kept up amid handling. .at is, a.er adding the present effect score to the collector, we check if the record score is more prominent than the littlest score in the load; assuming this is the case, the pointer to the gatherer is added to the store. A.er all postings portions have been handled, the best k components are extricated from the load and returned as results.
the postings for that term as the esteem. .e issue with this plan is that notwithstanding for little accumulations, the measure of the postings records will surpass the 400KB size farthest point of DynamoDB things. Luckily, the association of effect requested lists exhibits a characteristic method for separating the postings—by their effect scores. Notwithstanding, with sufficiently expansive accumulations, a postings fragment (especially for little effect scores) can in any case surpass as far as possible. To suit this we present the thought of "gatherings", a requesting of different keeps running of docids that offer a similar effect score. In DynamoDB, we utilize a half and half sort key contained the effect score and the gathering number inside that effect score. Review that for JASS score-at once traversal we should recover postings for a term and a given effect score. Sadly, our half and half sort key outline does not make this simple to do. As a workaround, we made an optional list on the postings table with the term as the hash key and the effect score as the sort key to help querying straightforwardly by affect score. Since there is no uniqueness requirement for essential keys in an auxiliary list, this approach works paying little respect to regardless of whether the postings for an effect score are part crosswise over DynamoDB things (i.e., different gatherings). Notwithstanding the postings table, we made a different metadata table, which stores the quantity of archives in the gathering (vital for the instatement of query assessment) and in addition a rundown of effect esteems that have postings for each term. .is configuration enables us to abstain from getting non-existent effect scores. At last, we assembled an ingester program that takes affect requested files from an outside source and embeds the postings into DynamoDB as indicated by our plan. Our present usage is fairly guileless and does not oversee "hotspots" in the fundamental DynamoDB table that create while embeddings numerous things with a similar parcel key, and thus does not accomplish high throughput. 3.2 Lambda Query Evaluation Amazon's
Lambda gives engineers a chance to run code without provisioning or overseeing servers, despite the fact that making a Lambda requires indicating the measure of memory that is accessible to each code conjuring (up to a greatest of 1.5GB) and a timeout period (not surpassing 300 seconds). Code summons are charged by the term of the execution, gathered together to the closest 100ms of every a fine-grained way. While there are no determinations of computational resources gave to execute the Lambda, both the system transfer speed and the measure of preparing power have been seen to scale straightly with the memory asked. Lambda code must be composed in an upheld dialect: JavaScript, Python, Java, or C#. Nonetheless, there is no confinement against conjuring code written in different dialects. It is trifling, and to be sure normal use, to package resources, for example, local pairs and libraries alongside the capacity code itself. Our Lambda work is actualized in Python, which at that point summons a program written in C++ that plays out the real query assessment. At the point when a conjuring demand touches base at the API Gateway (a trigger that summons a Lambda on HTTP occasions), Amazon is in charge of provisioning the vital resources to execute the Lambda and dealing with its lifecycle.
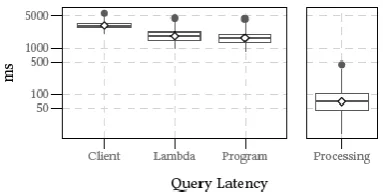
Figure 2. Performance of our serverless architecture.
for are issued no concurrently, and the outcomes are prepared when accessible. While it is conceivable to play out all solicitations no concurrently, this was not done since it would not yield a right score at any given moment traversal arrange. A.er handling has finished, the best k comes about are returned (k = 1000 in our examinations). Our usage right now returns inside numeric docids rather than outer (string) docids that are gathering particular.
IV.
EXPERIMENTS
To approve our outline, we actualized the serverless recovery engineering portrayed in the past area on the Gov2 gathering, contained around 25 million site pages. For assessment, we utilized subjects 701– 850 (with stopwords expelled) utilized as a part of the Terabyte Tracks from TREC 2004 to 2006. For practicality, we just ingested into DynamoDB the postings arrangements of the query terms.
Performance Analysis We report trial brings about Figure 2, indicating standard box-and-bristles plots for query inactivity, with the mean appeared as a white precious stone. Inertness figures are separated as takes after: "Customer" is estimated from the query customer utilizing the Unix order time (mean: 3087ms), "Lambda" is the billable length as estimated by Amazon (mean: 1887ms), "Program" is the inner planning by our query assessment algorithm (mean: 1722ms), and "Handling" catches the measure of time spent performing query assessment outside of sitting tight for DynamoDB asks for (mean: 87ms). difference between the "Program" and "Lambda" estimations catches the overhead of the Python Lambda summoning the local C++ pairs for query assessment. .e contrast amongst "Lambda" and "Customer" speaks to the extra overhead of summoning the Lambda itself and recovering the outcomes. In general, everything other than the "Handling" estimation reflects overheads of the serverless design in different structures. Indeed, even with all the "self-evident" advancements that we
have actualized, end-to-end customer query inertness is longer than is commonly viewed as usable for an intuitive query application. To be.er contextualize these outcomes, a current public-source reproducibility challenge sorted out by Lin et al. detailed a query idleness of JASS under comparable exploratory conditions as 51ms (same accumulation, same queries, on an EC2 occurrence). .is contrasts positively and our "Preparing" time, and the execution hole can be likely credited to CPU contrasts in the basic occurrences. Generally speaking, our tests recognized numerous wellsprings of latencies in the present outline, the greatest of which includes bringing postings from DynamoDB. .ere is significant opportunity to get better, and we would expect that as serverless outlines turn out to be more well known, Beyond DynamoDB latencies, there are a couple of evident wasteful aspects: for instance, the conjuring overhead of the C++ program can be disposed of if AWS upheld C++ Lambdas. Moreover, there is time
squandered in unnecessary information
transformation—all Lambda solicitations and reactions must be in JSON organization and double properties in DynamoDB are encoded in base64, which is ease back to unravel. It would not be extremely troublesome for Amazon to give the designer more €ne-grained control over serverless execution in such matters. Past these trials, there are a few extra queries with respect to our setup. In execution assessments, it is standard to recognize "icy" runs and "warm" runs, where the la.er advantage from reserving impacts. Since both DynamoDB and Lambda are fully managed services, this is troublesome for us to achieve the same number of parts of execution are not as straightforward as we might want. In any case, since our work is principally plausibility examine, we concede these more point by point investigations to future work.
DynamoDB in light of interest. In this segment, we give a cost investigation examination of serverless and server-based models. For a reasonable correlation, we indeed divert to come about because of the reproducibility investigation of Lin et al., which likewise analyzed JASS on a similar accumulation and queries. On an EC2 r3.4xlarge occasion, Lin et al. detailed a query inactivity of 51ms on a solitary string. Since the example has 16 vCPUs, on the off chance that we accept direct scaling, we touch base at a throughput of around 313 queries for each second on a completely stacked server. .is occasion costs USD$1.33 every hour paying little respect to stack, which implies that the cost is the same whether the server executes zero, one, or one million queries in any given hour. Then again, Lambda is charged on a for each demand premise in augmentations of 100ms. .e normal billable time for our framework was 1887ms for each query, which means USD$0.000047951. DynamoDB stockpiling is charged at USD$0.25 per GB every month in addition to extra expenses for read and compose activities. In any case, our use levels stay in the DynamoDB "complementary plan" for these tests, despite the fact that a heavier query load would not generously a.ect our examination.
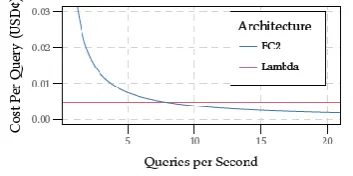
Figure 3. Cost of serverless vs. server-based architectures.
n Figure 3, we demonstrate the per-query cost in pennies for the server based and serverless structures accepting the arrangements above, as a component of query stack in queries every second (qps). .e Lambda configuration has a steady cost for every query, while the EC2 case turns out to be more practical at higher burdens, with the breakeven point around 7.7 queries for every second. Likewise, with Lambda we
without manual intercession. While a heap of 7.7 qps appears to be low, consider that in the diagram of the TREC 2016 Public Search Track, it was uncovered that CiteSeerX gets about 100,000 queries for each day, which converts into 1.2 qps by and large. We wander that in everything except the most requesting applications (e.g., business web indexes), a serverless plan would force from a cost viewpoint.
V.
CONCLUSION
Trends point to an unavoidable move of figuring to the cloud, and serverless designs re.ect this advancement. .is work speaks to, as far as anyone is concerned, the principal outline of a serverless engineering for data recovery. We promptly surrender that this underlying emphasis su.ers from execution issues, despite the fact that our cost examination legitimizes the compensation per-ask for show for most hunt needs. We expect that future changes in cloud framework, alongside extra improvements in our outline, will render serverless data recovery progressively referring.
VI.
REFERENCES
[1]. Jimmy Lin, Ma. Crane, Andrew Trotman, Jaime Callan, Ishan Cha.opadhyaya,John Foley, Grant Ingersoll, Craig Macdonald, and Sebastiano Vigna. 2016. Toward Reproducible Baselines: .e Public-Source IR Reproducibility Challenge. In ECIR. 408-420.
[2]. Jimmy Lin and Andrew Trotman. 2015. Anytime Ranking for Impact-Ordered Indexes. In ICTIR. 301-304.
[3]. Jimmy Lin and Andrew Trotman. 2017. .e Role of Index Compression in Score-at-a-Time .ery Evaluation. Information Retrieval 20, 3 (2017), 199-220.
[4]. Dirk Merkel. 2014. Docker: Lightweight Linux Containers for Consistent Development and Deployment. Linux Journal 2014, 239 (2014), Article No. 2.
Po-Yu Chuang. 2016. Overview of the TREC 2016 Public SearchTrack.
[6]. cecilia@aws. 2014. Re: Lambda CPU relative to which instance type? (9 Dec. 2014). Retrieved
February 2, 2017 from
h.ps://forums.aws.amazon.com/message. jspa?messageID=588722
[7]. Charles Clarke, Nick Craswell, and Ian Soboro.. 2004. Overview of the TREC 2004 Terabyte Track. In TREC.
[8]. Ma. Crane, J. Shane Culpepper, Jimmy Lin, Joel Mackenzie, and Andrew Trotman. 2017. A Comparison of Document-at-a-Time and Score-at-a-Time .ery Evaluation. In WSDM. 201-210.
[9]. Giuseppe DeCandia, Deniz Hastorun, Madan Jampani, Gunavardhan Kakulapati, Avinash Lakshman, Alex Pilchin, Swaminathan Sivasubramanian, Peter Vosshall, and Werner Vogels. 2007. Dynamo: Amazon’s Highly Available Key-value Store. In SOSP. 205-220. [10]. Vineet Gopal. 2015. Powering CRISPR With
AWS Lambda. (25 Sept. 2015). Retrieved
February 6, 2017 from
h.p://benchling.engineering/crispr-aws-lambda/
[11]. Sco. Hendrickson, Stephen Sturdevant, Tyler Harter, Venkateshwaran Venkataramani, Andrea C. Arpaci-Dusseau, and Remzi H. Arpaci-Dusseau. 2016. Serverless Computation with PublicLambda. In HotCloud.
[12]. Haslhofer, B., Sanderson, R., Simon, R., Sompel, H.: Public annotations on multimedia web resources. Multimedia Tools and Applications pp. 1-21 (2012)
[13]. Ridge, M.: Pelagios project blog: Pelagios usability testing results (September 2011),
http://pelagios- project.blogspot.co.at/2011/09/draft-results.html
[14]. Simon, R.: Pelagios project blog: The pelagios graph explorer: A first look (August 2011),
http://pelagios-project.blogspot.co.at/2011/08/ pelagios-graph-explorer-first-look.html
[15]. Thompson, H.S., McKelvie, D.: Hyperlink
semantics for standoff markup of readonly documents. In: Proceedings of SGML Europe 97: The next decade Pushing the Envelope. p. 227229 (1997)
About Authors:
Mr. G.HariPrasad is currently pursuing his Master of Computer Applications, Sree Vidyanikethan Institute of Management, Tirupati, A.P. He received his Master of Computer Applications from Sri Venkateswara University, Tirupati
Mr. A.J.Rajasekhar is currently working as an Assistant Professor
in Master of Computer