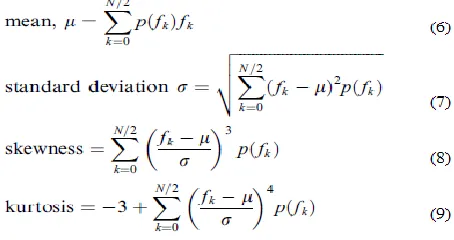International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 5, Issue 10, October 2015)
15
Speech Endpoint Detection Based on High Order Statistics
Abdelmajid FARCHI
1,3, Badia MOUNIR
2, Jamal EL ABBADI
31LIMMII laboratory, Science and Technical Faculty University Hassan 1er, Morocco 2LIMMII laboratory, Graduate School of technology of safi,University Cadi Ayyad, Morocco
3
LEC laboratory, School Mohammadia of Engineers of Rabat, Morocco
Abstract—For automatic speech recognition, endpoint detection is required to isolate the speech of interest so as to be able to create a speech pattern or template. The process of separating the speech segments of an utterance from the non-speech segments obtained during the recording process is called endpoint detection. In this paper, we present new endpoint detection algorithm based on high order statistical models and empirical rule-based energy detection algorithm. The performance of the proposed algorithm was evaluated for Arabic phonemes including the weak consonants which are difficult to detect using conventional endpoint detection methods.
Keywords—voice activity detection (VAD), frequency domain, spectral domain, high order statistics (HOS).
I. INTRODUCTION
Speech endpoint detection (also known as boundary detection, voice activity detection) is the process of detecting the onset and the terminus of speech utterance and exclusion of the non-speech segments by digital processing technology. The main use of endpoint detection is in speech coding and speech recognition. It is an important enabling technology for a variety of speech based applications. The recognition performance has a close relation to the accuracy of endpoint detection. More than half of speech recognition errors were caused by incorrect endpoint detection even in quiet environment [1]. Furthermore, higher detection rates can help to identify and reject background noise, which can in turn reduce the time complexity of speech recognition as well as improve the performance of speech recognition system.
A number of speech endpoint detection methods have been reported in the literature. This includes Short-Time Energy (STE) [2] and Zero-Crossing Rate (ZCR) [3]. These two features of speech have served as the basis for all energy- based endpoint detection algorithms. However, the performances of these algorithms are less satisfactory in highly noisy environments, especially for low SNR and noises with non-stationary characteristics. Many other different features have been investigated: Entropy [4], Mel-Frequency Cepstrum Coefficient (MFCC) [5], Hidden Markov Models (HMM) [6], Wavelet Transform Technology [7] and statistical models [8].
Despite these various methods, there is no universal detection algorithm yet working reliably in all possible noises and settings. Difficulties in endpoint detection arise not only from the different types of noise present in the recording, but also from the vocabulary words themselves. Some phonemes or sounds have very low energy when compared to the vowel portion of the speech, and as a result, they are interpreted as background noise [3].
In this article, we propose a new VAD algorithm based on spectral coefficients of signal, especially the first (spectral mean) and third (skewness) spectral coefficients. The performance of the proposed algorithm will be evaluated for different types of Moroccan Arabic phonemes including the weak consonants which are difficult to detect using conventional endpoint detection methods. The rest of article is organized as follows. In section 2, we will present the high order statistics (HOS). In section 3, the proposed VAD algorithm is developed. In section 4, several experiments are conducted. The results show the efficiency and the performance of the proposed algorithm.
II. HIGH ORDER STATISTICS
Higher order statistics (HOS) play an important role in digital signal processing. Commonly used features like: intensity, energy, autocorrelation and various spectral techniques can be expressed in the terms of HOS as first (mean) and second order (variance) statistic features. Obviously these important and well-known parameters suppress some parts of information (like phase) which may cause ambiguity in system identification and other applications. Unless the signal is Gaussian (Normal), these drawbacks can be eliminated by using HOS, like third and four order moments.
II.1. Definition of higher-order statistics
For random variable x, whose probability density is px, and its first characteristic function is defined as follows [9]:
The logarithm of ψν) is known as the second
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 5, Issue 10, October 2015)
16
The r-order moment μx ( r )and the r-order cumulant κx (
r )of the random variable xare:
II.2. High order statistics estimation
The spectrogram of a continuously recorded utterance is first derived. For each frame, the spectrum is obtained by fast Fourier transform (FFT). The probability density function for the spectrum can thus be estimated by
normalization aver all frequency components:
Where P(fk) is the power spectrum, fk = 2fNqk/N, k = 0, 1,…, N/2, and N is the window length. fNq indicates the Nyquist frequency.
The coefficients of the normalized power spectrum were computed as:
III. THE PROPOSED VADALGORITHM
The proposed algorithm has two steps to separate speech segments from background noise. For the first step, assuming that during the first 100 ms of the recording interval there is no speech present; some background silence statistics can be measured. Such statistics include the spectral centroid, standard deviation and skewness of the silence. These measurements are used to set two thresholds: mean threshold ThC and skewness threshold ThS.
[image:2.612.365.520.210.414.2]The second step consists of searching for the beginning point (BP) and the ending point (EP) of the utterance: By finding the first point at which the skewness exceeds ThS, and then the mean exceeds ThC. A similar approach is used to define the endpoint of the utterance.
Figure 1: The block diagram of general endpoint Detection algorithm.
IV. EXPERIMENTATION AND EVALUATION
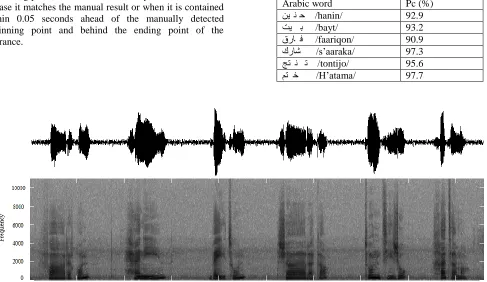
Participants were twenty adults who were Moroccan speakers of Arabic Modern Standard. The group included 10 female and 10 male subjects ranged in age from 19 to 27 years. They were asked to produce sentences containing words (Table.1) characterized by low energy onsets and tails, which make them particularly difficult to accurately determine their endpoints. Some phonemes or sounds have very low energy when compared to the vowel portion of the speech, and as a result, they are interpreted as background noise. Among such phonemes, the weak fricative /f/, weak plosive /t/ or nasals such as /n/ at the end.
Table 1:
vocabulary words used to perform the algorithm
Arabic word Word signification
ني ن ح /hanin/ nostalgia
تي ب /bayt/ home
قرا ف /faariqon/ difference
كراش /s’aaraka/ participated
جت ن ت /tontijo/ produce
[image:2.612.49.276.438.558.2]International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 5, Issue 10, October 2015)
17
The beginning and ending points of the speech utterance were labelled manually using both the time waveform and the spectrogram of utterances (Figure 2).
This manual detection information is used as a reference to determine the accuracy of those detected by the proposed algorithm.
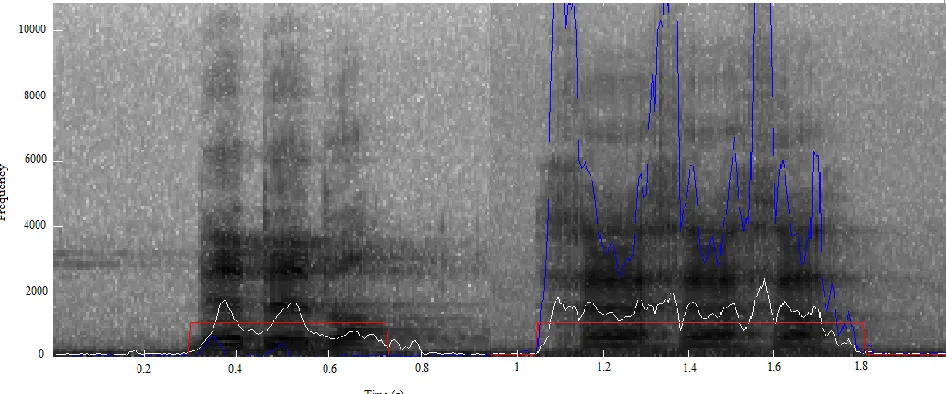
For the performance evaluation, the detection results of the proposed algorithm (Figure 3) were compared to the reference. The detected segment (detected beginning point and ending point) is counted as correctly detected utterance in case it matches the manual result or when it is contained within 0.05 seconds ahead of the manually detected beginning point and behind the ending point of the utterance.
[image:3.612.64.551.247.529.2]To evaluate the performance of the proposed algorithm, we used the probability of correctly detecting speech segments Pc, computed as the ratio of the number of correctly detected utterances to the total number of test utterances for each vocabulary word. Table 2 shows the experimental results in terms of Pc values over vocabulary words.
Table 2:
Pc values for vocabulary words
Arabic word Pc (%)
ني ن ح /hanin/ 92.9
تي ب /bayt/ 93.2
قرا ف /faariqon/ 90.9
كراش /s’aaraka/ 97.3
جت ن ت /tontijo/ 95.6
مت خ /H’atama/ 97.7
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 5, Issue 10, October 2015)
[image:4.612.72.545.138.335.2]18
Figure 3: endpoint detection by the proposed algorithm: mean (white), skewness (blue) and endpoint detection (red)
Table 2 shows the experimental results in terms of 𝑃𝑐 values over various utterances. In the experiments, it can be
seen that Pc is lower for words with low energy onsets and
weak consonant in tails (ني ن ح /hanin/ and قرا ف /faariqon/). The lowest value of Pc is obtained for the utterance ―قرا ف /faariqon/‖ due to his low energy onset and
his tail week consonant. The best values of Pc were
obtained for words which end in vowel (مت خ /H’atama/,
كراش /s’aaraka/ and جت ن ت /tontijo/). The low value Pc of
the word ―جت ن ت /tontijo/‖ in comparison with those obtained for ―مت خ /H’atama/‖ and ‖كراش /s’aaraka/‖ is due to his onset weak consonant ―t‖.
To assess the performance of the proposed algorithm, we compared the experimental results with those using the conventional algorithm with high SNR (speech data with clean 20, 15 and 5 dB signals). The average of 𝑃𝑐 shown by this proposed algorithm is about 94.6%. The maximum
Pc obtained by Sohn et al. [9] is 92%, that obtained by Ramίrez et al. [10], Gόrriz et al. [11] and Fukuda et al [12] is about 94.5%.
V. CONCLUSION
This paper proposed a new VAD technique to improve automatic speech recognition. The proposed feature extraction technique, based on the HOS was shown to be efficient and yet reliable.
Representative detection experiments conducted
confirmed that the proposed algorithm is superior to the conventional algorithms.
In addition, the proposed algorithm confirms its efficiency even when onsets and tails sounds are characterized by low energy or when sounds contain weak consonants which have very low energy. Based on these analysis and results, the proposed algorithm is attractive and feasible for real-time implementation of VADs.
REFERENCES
[1] T.Martin,‖ Applications of limited vocabulary recognition systems", in Rec. 1974 Symp. Speech Recognition, D. R. Reddy, Ed. New York: Academic, 1975.
[2] L. F. Lamer, L. R. Rabiner, A. E. Rosenberg, and J. G. Wilpon, ―An Improved Endpoint Detector for Isolated Word Recognition‖, IEEE Transactions on Acoustics Speech and Signal Processing, Vol. 29, No. 4, Aug. 1981.
[3] L.R. Rabiner and M.R. Sambur, ―An Algorithm for Determining the Endpoints of Isolated Utterances‖, Bell System Technical Journal, Vol. 54, No. 2, 1975.
[4] J. L. Shen, J. W. Hung and L.S. Lee, ―Robust Entropy-based Endpoint Detection for Speech Recognition in Noisy Environments,‖ International Conference on Spoken Language Processing, Sydney, 1998.
[5] G. D. Wu and C. T. Lin, ―Word Boundary Detection with Mel-Scale Frequency Bank in Noisy Environment,‖ IEEE Transactions on Speech and Audio Processing, Vol. 8, No.5, Sep. 2000.
[6] J. Sohn, N. S. Kim and W. Sung, ―A Statistical Model-Based Voice Activity Detection,‖ IEEE Signal Processing Letters, Vol. 6, No. 1, Jan. 1999.
[7] Kh. Aghajani, M.T. Manzuri, M. Karami and H. Tayebi, "A Robust Voice Activity Detection Based on Wavelet Transform", In Second International Conference on Electrical Engineering, Mar. 2008. [8] Jongseo Sohn, Nam Soo Kim and Wonyong Sung, ―A statistical
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 5, Issue 10, October 2015)
19
[9] J. Sohn,N. S.Kim, andW. Sung, ―Astatisticalmodel-based voice activity detection,‖ IEEE Signal Processing Letters, vol. 6, no. 1, pp. 1–3, 1999.
[10] J. Ram´ırez, J. C. Segura, J. M. G´orriz, and L. Garc´ıa, ―Improved voice activity detection using contextual multiple hypothesis testing for robust speech recognition,‖ IEEE Transactions on Audio, Speech and Language Processing, vol. 15, no. 8, pp. 2177–2189, 2007.
[11] J. M. G´orriz, J. Ram´ırez, E. W. Lang, C. G. Puntonet, and I. Turias, ―Improved likelihood ratio test based voice activity detector applied to speech recognition,‖ Speech Communication, vol. 52, no. 7-8, pp. 664–677, 2010.