International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 2, Issue 7, July 2012)478
A Framework for Dynamic Faculty Support System to
Analyze Student Course Data
J. Shana
1, T. Venkatachalam
21Department of MCA, Coimbatore Institute of Technology, Affiliated to Anna University of Chennai, Tamilnadu, India
2Department of Physics, Coimbatore Institute of Technology,
Affiliated to Anna University of Chennai, Tamilnadu, India
Abstract - This work attempts to propose a framework called Faculty Support System (FSS) that would enable the faculty to analyze their student’s performance in a course. Our framework uses open source analysis softwares and offers a simple easy to use client interface that can be used by any faculty for their course. Most analysis system use only static data but our FSS can dynamically update itself whenever there is change in analysis result. Student data show considerable change in trends and so implementing static rules won prove useful in education domain. So we propose a dynamic system whose client component is used by all non technical faculties and the analysis component is controlled by technical experts in knowledge mining. They can perform the analysis and load the rules into a rules database which is implemented by the client component. Our empirical studies on 182 students taking ‘C’ programming course have identified two data mining techniques that generate rules with considerable accuracy. Supervised association rule mining is used to identify the factors influencing the result of students and C4.5 decision tree algorithm to predict the result of student. The FSS can be integrated into any student management system or operated as a standalone system.FSS can be easily implemented by any institution and would also enable the concerned faculty to take effective measures to improve academically weaker students.
Keywords - Educational Data Mining, Classification algorithm, Decision Tree, Data Analysis, Prediction.
I.
I
NTRODUCTIONAll universities or colleges have student management system that store information in various forms. But they do not concentrate on the potential mining of knowledge from these data. One main reason is the lack of funds to invest in commercial analysis softwares and the other being lack of analysis knowledge among faculties. Due to the above reasons, the student data is under- utilized in numerous educational institutions in India. This paper suggests a framework for a low cost Faculty Support System using cost effective open source softwares and other commonly available softwares.
There are two levels at which the system functions. At one level are the domain experts or faculty who are experts in analysis techniques. They can use various techniques to perform analysis on student data and generate the necessary output for those methods that prove useful. This output is fed into the second level where it is implemented and used by all faculties. This is intended to be used by faculty to understand the performance of students in their course. In this work we concentrate on studying the performance of students in a particular subject. We have performed analysis on the student data using many data mining techniques and finally selected class association rule mining and C4.5decision tree algorithm for predicting the performance of students. The analysis result is implemented in the client component of the proposed system. The FSS would enable the faculty to understand what factors contribute to the success of students in a course. It can also predict with reasonable accuracy whether a particular student can be a bad performer.
II.
B
ACKGROUNDInternational Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 2, Issue 7, July 2012)479
described in [4][6]. They conducted a study on student performance by selecting a sample of 300 students (225 males, 75 females) from a group of colleges affiliated to Punjab university of Pakistan. An implementation of data mining techniques to analyze the performance of students was done by Bharaj and Pal [1].From the standpoint of the e-learning scholars data mining techniques is said to have been applied to solve different issues in educational environment such as student’s classification based on their learning performance, retention in a course, detection of irregular learning behavior and so on. Different domains require different data mining technique [6].Association rule mining is employed to discover interesting relationships between attributes of a transactional database. There are many variations of association rule [8]. Pandey and Pal [10] conducted study on the student performance based by selecting 60 students from a degree college of Dr. R. M. L. Awadh University, Faizabad, India. By means of association rule they find the interestingness of student in opting class teaching language.A class association rule (CAR) is a special type of association rule that describes an implicative co-occurring relationship between a set of items and a predefined target class and is expressed as IF-THEN rules [13].The use of k-means clustering algorithm to predict student‟s learning activities has been described in [3]. Han and Kamber [13] describes data mining software that allow the users to analyze data from different dimensions, categorize it and summarize the relationships which are identified during the mining process.
[image:2.612.42.274.491.702.2]III.
P
ROPOSEDS
YSTEMA
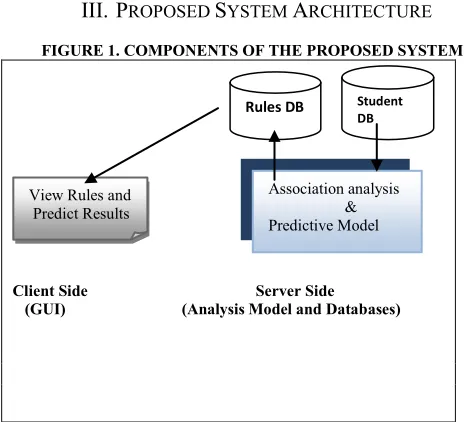
RCHITECTUREFIGURE 1. COMPONENTS OF THE PROPOSED SYSTEM
Client Side Server Side (GUI) (Analysis Model and Databases)
IV.
C
OMPONENTSO
FT
HEP
ROPOSEDS
YSTEMThis system can be implemented in two phases namely the Server side and the Client side. The server side consists of the following components:
A. Server Components-Student Database
Here the academic and non academic information regarding the students are maintained as required by the institution. This data is generated during new admissions, during examinations and continuous assessments. The database can be stored using any RDBMS software. Here MS Access is used to store the academic and non academic details of students who have studied ‘C’ programming course at the same level.
B. Analysis Model
Data Selection and Transformation: The relevant attributes needed for the analysis is selected and stored in a separate analysis table in the database. All the attributes are transformed into categorical values. The database for this experiment consists of 182 records with 14 attributes.
Association analysis and Prediction: Here we use the open source software WEKA 3.x to analyze the data. Any other open source software can be used. We have made an empirical study of student data set to analyze the effect of Class Association Rule mining algorithm (CAR) and various Decision Tree algorithms. CAR helps the faculty in identifying factors that influence the performance of students in a course. And decision tree algorithms help in predicting the results as ‘pass’ or ‘fail’ in a subject. Experimental results show that the C4.5 algorithm has considerable accuracy compared to all other decision tree algorithms in this domain. These two algorithms produce rules that can be very easily implemented in any high level language and understood by the faculty without even knowing the technical details. The domain experts can even change or update the rules from the server as long term changes in data would produce new rules. The client system is dynamic enough to reflect the changes.
Rules Database: The rules database consists of a bitmap table that stores the rules generated from the analysis component. These rules are stored as a matrix consisting of numerical representation of categorical values as shown in Table 1.This table would be implemented by the client component for predicting the result as well for analyzing the factors. Any change in the analysis results needs to update the bitmap values only and the client can dynamically incorporate these updates.
Rules DB Student
DB
View Rules and Predict Results
Association analysis & Predictive Model
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 2, Issue 7, July 2012) [image:3.612.50.271.122.207.2]480
TABLE 1 STORAGE FORMAT OF RULES GENEARATED RuleID A1 A2 A3 A4 CLASS
R1 1 Null Null 1 1
R2 Null 2 Null 1 1
R3 1 Null Null 2 1
R4 0 Null Null Null 0
In Table 1 a field having ‘1’ represents the value high, ‘0’ for low and ‘2’ for average.
C. Client Components
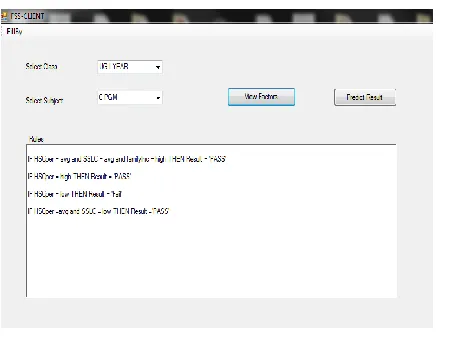
Factor Analysis: This implements a Graphical User Interface that displays the rules in IF-Then format. Any instructor can understand what factors influence the result of students in a course.
Prediction: Also the faculty can perform any prediction on the new data. The C4.5 classification model with highest accuracy is implemented in the prototype that predicts the performance of new students in the particular subject.
V.
A
NALYSISA
LGORITHMSU
SED A. Predictive AprioriIt is a supervised apriori algorithm. This generates rules that would help us analyze the class label namely ‘Result’. This helps in identifying the factors that influence the result of students.
According to Liu [13] class association rule mining can be done as follows:
• divide training set into classes; one for each class • mine frequent item set separately in each subset • take frequent item set as body and class label as
head
• Generate frequent item sets from all data (class attribute deleted) as rule body.
• Generate rules for each class label.
B. Decision Tree Induction ( C4.5 )
Classification Tree based on C4.5 uses the training samples to generate the model. The data classification process can be described as follows.
Learning using training data
Classification using test data
The learned model or classifier is represented in the form of classification rules. Test data are used to estimate the accuracy of the classification rules. If the accuracy is considered accepted, the rules can be applied the classification of new data records [14].
VI.EXPERIMENTAL RESULTS AND DISCUSSION A. Data Preparation
A student dataset consisting of 182 records with 12 attributes were selected for the study. The academic data was extracted from the student management system of the college. Other details were collected from through questionnaires.All the attributes are transformed into categorical values as shown in Table 2 for analysis.
TABLE 2 ATTRIBUTES OF THE DATASET Attributes Categorical Values
Secondary percentage(SSLC) High, Low, Average
HigherSecondary percentage(HSC) High, Low, Average
Subject difficulty High, Low, Medium
Stay Hostel, Home
Friends High, Low, Average
Staff approach Friendly-1 ,Strict-0
Previous skill CS-1,non-CS-0
Family Income High, Low, Average
Motivation High, Low, Average
Medium of instruction English-1, Native-0
Subject interest High, Low, Average
Nativity Urban, Rural
C. Predictive Apriori
[image:3.612.323.550.254.484.2]International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 2, Issue 7, July 2012) [image:4.612.67.531.145.290.2]481
TABLE 3 RULES GENERATED BY THE SUPERVISED APRIORI ALGORITHM
Antecedent Conseq N n[a] n[b] n[a^b] Supp Con Lift
medium=1 Result=pass 182 163 141 131 0.719 0.803 1.037
Family income=high,
motivation=high
Result=pass 182 64 141 58 0.318 0.906 1.169
Medium=1,stay=1 Result=pass 182 113 141 95 0.521 0.840 1.085
Medium=1,previous skill=high
Result=pass 182 129 141 107 0.587 0.829 1.070
Family income=high,
medium=1, motivation=high
Result=pass 182 60 141 55 0.302 0.916 1.183
Family
income=high,medium=1, stay=1
Result=pass 182 89 141 78 0.428 0.876 1.131
C. Decision Tree Algorithms
To select the best decision tree algorithm for predicting the class ‘result’ we analyzed the student data with four different decision tree algorithms. Ten fold cross validation was used in the experiment. The accuracy percentage of each of the algorithms is shown in Table 4.
TABLE 4 ACCURACY COMPARISON Technique Used Correctly Classified
Instances
ID3 76.92%
C4.5 83.52%
SimpleCART 76.90%
REPTree 78.02%
It is seen from the Table 4 that C4.5 algorithm gives the highest accuracy of 83.52% and the IF-THEN rules were generated from the tree shown in Figure 1. These rules are stored in the Rules DB and are implemented in the client component.
FIGURE 2.DECISION TREE FOR C4.5
From the decision tree we can easily generate IF-THEN rules that is easy to understand. Table 5 shows a few rules generated by the tree in Figure 2.
TABLE 5 SAMPLE RULES GENERATED FROM THE DECISION TREE
Sno Rules
1 IF Hscper=avg & SSLC=avg & FamInc=high & motivation=high THEN Result=’pass’
2 IF Hscper=high THEN Result=’pass’ 3 IF Hscper=low THEN Result=’fail’
4 IF Hscper=avg & SSLC =high THEN Result=’pass’ 5 IF Hscper=avg &SSLC=low THEN Result=’fail’
Rules generated by both the algorithms as given in Table 2 and Table 5 can be fed into the RulesDB. These rules help to identify the factors that affect the result of students in the course. Prediction for the unseen data can be made from these rules.
VIII.
S
YSTEMI
MPLEMENTATION[image:4.612.49.270.537.697.2]
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 2, Issue 7, July 2012) [image:5.612.48.273.172.341.2]482
FIGURE 3 CLIENT SCREEN USED BY THE FACULTY TO VIEW RULES
IX.
C
ONCLUSIONIn this paper we suggested a simple framework for analyzing the result of students in a particular course. This system can be very easily implemented by any educational institution as it uses open source softwares for analysis. It can be used by faculties who do not have any knowledge on data mining techniques. This work concentrated on the identification of factors that contribute to the success or failure of students in a subject and predict the result. Future work can concentrate on other student data analysis techniques that would mine other useful knowledge. This can be done in the analysis component and the client component can dynamically add these too.
A
CKNOWLEDGEMENTSI greatly acknowledgement my students who helped me with the data collection and necessary implementation for the above research work.
R
EFERENCES[1] Bharadwaj, B.K, Pal.S, 2011, Mining Educational Data to Analyze Students’ Performance, International Journal of Advanced Computer Science and Applications, Volume 2, Number 6,pp.63-69.
[2] Pandey U.K and Pal.S, 2011, A data mining view on class room teaching language, International Journal of computer science , Volume 8,issue 2,pp.277-282
[3] Shaeda Ayeesha, Tasleem Mustafa, Ahsan Raza Sattar, Inayat Khan,M., 2010, Data mining models for higher education system, European Journal of Scientific Research, ,Volume 23,No.1, pp.24-29.
[4] Alaa el-Halees, 2009, Mining student data to analyze e-learning behavior: A case study.
[5] Romero,C.,Ventura,S.,Salcines,E.2008, Data mining in course management systems: Moodle case study and tutorial. Computer and Education,51(1) pp.368-384.
[6] Castro.F, Vellido.A, Nebot.A, Mugica.F. 2007, Applying data mining techniques to e-learning problems, Volume 62,pp. 183-221. Springer Berlin Heidelberg.
[7] Dogan.B, Camurcu, A.Y. 2008, Association Rule Mining from an intelligent tutor, Journal of educational technology systems, Volume 36, Number 4, pp 433-477.
[8] Kotsiantis,S., Kanellopoulus,D. ,2006, Association rules mining: A recent overview.International Transactions on computer science and Engineering Journal , volume 32,1,pp.71-82.
[9] Hijazi,S.T., Naqvi, R.S.M.M, 2006, Factors affecting student’s performance:A case of private Colleges, Bangladesh e-journal of sociology,Volume 3, number 1.
[10] Philip j. Goldstein, Richard N. Kotz, 2005, Academic Analytics : The Uses of Management Information and Technology, Education Center for Applied Science, Volume 8. [11] Behrouz.et.al.,2003, Predicting student performance : An
application of data mining methods with the educational web based system LON-CAPA, IEEE, Boulder, CO.
[12] Jiuyong Li, Hong Shen ,Rodney Topor.,2003, Mining the Smallest Association Rule Set for Predictions. Proceedings of IEEE International Conference on Data Mining,pp 361-368. [13] Han,J and Kamber,M.,2006, Data Mining:Concepts and
Techniques, 2nd edition, Morgan kaufmann Series in Data
mining systems.
[14] Liu,B., Hsu, May,W.,1998 Integrating classification and Association rule mining. International conference on knowledge discovery and data mining, KDD’98 pp.80-86. [15] Takashi Washio, Hiroshi Motoda, 1998, Mining Association
Rules for Estimation and Prediction, PAKDD, Proceedings of the Second Pacific Asia Conference on Research and Development in Knowledge Discovery and Data Mining.