Detection of Overlapping Communities in Social Network
Full text
Figure




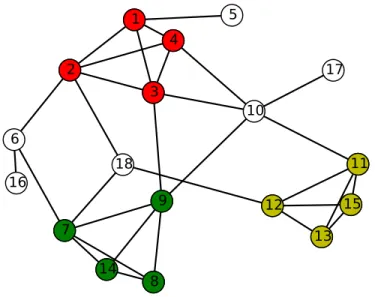


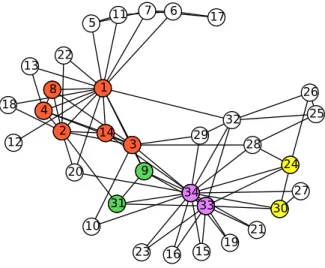


Related documents
This paper is devoted to the simultaneous weight and deflection optimization of cantilever beam by using a modified Non-Dominated sorting Genetic Algorithm,
This phase I study of TAK-117 (NCT01449370) aimed to determine the maximum tolerated dose (MTD) and/or optimal biologic dose and dose-limiting toxicities (DLTs) when administered on
The objective of the present study was to evaluate body composition and performance parameters of male judo athletes, derived from 5 minutes lasting all-out arm and leg
aeruginosa also possesses a variety of virulence factors such as exotoxin A (encoded by toxA gene), exoenzyme S (encoded by exoS gene), exoenzyme U (encoded by exoU
It is noteworthy that for the data considered in this study, the failure of either the bivariate Rice or Weibull distributions to adequately fit the joint distribution of wind
In this report, we describe a case of a woman who had received multiple sodium hyaluronate injections and developed severe necrotizing fasciitis near the injection site.. We
Detection of a tumour mass by means of US and CT scan with direct (visualization of the tumour) or indirect signs of tumour (bile or pancreatic duct dilatation, presence of
