International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 2, Issue 7, July 2012)238
PERFORMANCE ANALYSIS OF HANDWRITTEN
DEVNAGRI CHARACTERS RECOGNITION THROUGH
MACHINE INTELLIGENCE
Prashant M. Kakde
1, Vivek R. Raut
21Assistant Prof., H.V.P.M’S COLLEGE OF ENGINEERING AND TECHNOLOGY, AMRAVATI 2
Associate Prof., P.R.M.INSTITUTE OF TECHNOLOGY AND RESEARCH, BADNERA- AMRAVATI
Abstract - Handwritten character recognition is one of the most active areas of research. Developing a handwritten Devnagri character recognition system is a big challenge due to high variability of writing styles. Also Devnagri script has some special features like conjunct characters, shirolekha and spine. This affects the recognition rate and many other performance measures in recognition of characters. An Artificial Neural Network (ANN) can provide a better solution in character recognition.
This paper is a novel approach in recognition of handwritten Devnagri characters and analysis of various suitable performance measures. The character recognition and performance measures analysis is done by using neural network tool box in MATLAB.
Hence in this paper more emphasis is given on preprocessing of a Devnagri character. Performance of the handwritten Devnagri character recognition system can be analyzed by using various performance measures like mean square error (MSE), percentage error (% E), performance characteristics, recognition percentage etc.
Keywords – Artificial Neural Network (ANN), Handwritten Character Recognition (HCR), Scaled Conjugate Gradient (SCG), Performance Analysis.
I. INTRODUCTION
Handwritten character recognition is gaining popularity due to its potential application areas which would reduce the task of data entry and save the time in case of form filling, postal automation, and banking etc. But developing a system for handwritten character recognition poses a challenge to the researchers due to the varying shape of the character that may depend upon the writer, the physical and mental condition of the writer, the acquisition device, pen-width, pen ink color and many other factors. Constantin Anton, Cosmin Stirbu, Romeo-Vasile Badea in their paper [2] extended the role of character recognition to automatic hand writer identification on the basis of biometric modalities [2].
SPECIFIC FEATURES OF DEVNAGRI SCRIPT
Devnagari is the script for Hindi, Sanskrit Marathi, and Nepali languages. Devnagari script is a logical composition of its constituent symbols in two dimensions. It is an alphabetic script. Devnagari has 11 vowels and 33 simple consonants also called as non compound characters (figure.1).
Besides the consonants and the vowels, other constituent symbols in Devnagari are set of vowel modifiers called matra (placed to the left, right, above, or at the bottom of a character or conjunct), pure-consonant (also called half letters) which when combined with other consonants yield conjuncts. A horizontallinecalledshirolekha(a header line runs through the entire span of word) [4]. Devnagri script has two-dimensional compositions of symbols: core characters in the middle strip, optional modifiers above and/or below core characters. Two characters may be in shadow of each other. While line segments (strokes) are the predominant features for English, most of the characters in Devnagari script are formed by curves, holes, and also strokes. Vowels occur either in isolation or in combination with consonants.
Apart from vowels and consonants characters called basic characters, there are compound characters (figure.2) in Devnagari script alphabet system, which are formed by combining two or more basic characters. The shape of compound character is usually more complex than the constituent basic characters. Coupled to this in Devnagari script there is a practice of having more than twelve forms each for 33 consonants giving rise to modified shapes which, depending on whether the vowel modifier (figure.3) is placed to the left, right, top or bottom of the consonants. They are called modified characters [3].
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 2, Issue 7, July 2012)239
Figure 2 Compound charactersFigure 3 Modifiers
The problem of text recognition has been attempted by many different approaches. Template matching is one of the simplest approaches. In this many templates of each word aremaintained foraninput image, error or difference with each template is computed. The symbol corresponding to minimum error is output. The technique works effectively for recognition of standard fonts, but gives poor performance with hand written characters.
An ANN is an information processing method inspired by biological nervous system. A Neural Network consists of two basic kinds of elements, neurons and connections. Neurons connect with each other through connections to form a network. This is a simplified theory model of the human brain. A Neural Network often has multiple layers and neurons of a certain layer connect neurons of the next level in some way. Every connection between them is assigned with a weight value.
At the beginning, input data are fed into the neurons of the first layer, and by computing the weighted sum of all connected first layer neurons, we can get the neuron value of a second layer neuron and so on finally, we can reach the last layer, which is the output. All the computations involved in operating a Neural Network are a bunch of dot products. We need to train our network with sample inputs and compare the outcomes with our desired answers. Some algorithm can take the errors as inputs and modify the network [5].
Neural network is first trained by multiple sample images of each alphabet. Then in recognition process, the input image is directly given to neural network and recognized symbol is outputted. Although even best of the recognition approaches are able to recognize all those texts that human can. Major reason for this has been wide variation in writing practices and styles of different people and lot of context based information that human brain uses to interpret any text sample.
II. LITERATURE REVIEW
Sushama Shelke and P.B.Khanale et al. [6][30] in their
paper presents a novel approach for recognition of
unconstrained handwritten Marathi characters. The recognition is carried out using multistage feature extraction and classification scheme. The initial stages of feature extraction are based upon the structural features and the classification of the characters is done according to their parameters. The final stage of feature extraction employs Radon transform and Euclidean distance transform and applied to two separate feed forward back propagation neural networks. The hybrid classifier at the final stage takes the input from two neural network classifiers and template matching classifier and decides the final output based on maximum voting rule. This multistage feature extraction and classification scheme improves the recognition accuracy over individual classifiers considerably. The recognition rate achieved from the proposed method is 95.40% [6] [30].
Sreeraj.M et al. [7] in their paper presents an efficient Online Handwritten character Recognition System for Malayalam Characters (OHR-M) using K-NN algorithm. It would help in recognizing Malayalam text entered using pen-like devices. A novel feature extraction method, a combination of time domain features and dynamic representation of writing direction along with its curvature is used for recognizing Malayalam characters. This writer independent system gives an excellent accuracy of 98.125% with recognition time of 15-30 milliseconds [7].
Sandhya Arora and Vikas Dongre et al. [10] [24] in their paper presents a two stage classification approach for handwritten Devnagari characters The first stage is using structural properties like shirolekha, spine in character and second stage exploits some intersection features of characters which are fed to a feed forward neural network. Simple histogram based method does not work for finding shirolekha, vertical bar (Spine) in handwritten devnagari characters. So they designed a differential distance based technique to find a near straight line for shirolekha and spine. This approach has been tested for 50000 samples and they got 89.12% success [10] [24].
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 2, Issue 7, July 2012)240
It has been taken care into account that there is vast variation in writing styles size and thickness of characters and any distortion during scanning. There is no need of preprocessing as well as training. The notation of regular expression is short and precise and can be easily transformed into directed graphs or finite - state automata accepting all the symbol strings generated by the corresponding expressions. The method is efficient enough because of power of regular expressions [3] [25].R.Indra Gandhi et al. [15] proposed a new approach of Kohonen neural network based Self Organizing Map (SOM) algorithm for Tamil Character Recognition which provides much higher performance than the traditional neural network. Approaches: Step 1: It describes how a system is used to recognize a hand written Tamil characters using a classification approach. The aim of the pre-classification is to reduce the number of possible candidates of unknown character, to a subset of the total character set. This is otherwise known as cluster, so the algorithm will try to group similar characters together. Step 2: Members of pre-classified group are further analyzed using a statistical classifier for final recognition.
A recognition rate of around 79.9% was achieved for the first choice and more than 98.5% for the top three choices. The result shows that the proposed Kohonen SOM algorithm yields promising output and feasible with other existing techniques [15].
Anilkumar N. Holambe and Mahesh Jangid et al. [1][29] used Devnagari script OCR for recognition. The handwritten data set is created by them and for printed characters they have used ISM font. Here they are using gradient and curvature based feature extraction method. They have compared Nearest Neighbor, K-Nearest Neighbor, Euclidian Distance-based K-NN, Cosine Similarity -based KNN, Condensed Nearest Neighbor, Reduced Nearest neighbor, Farthest like neighbor and Nearest unlike Neighbor [1] [29].
III. PROBLEM DEFINITION
The literature survey elaborates the fact that there are number of deficiencies as well as scope for improvement in
handwritten character recognition. Developing a
handwritten Devnagri character recognition system is a big challenge due to:
1. High variability of writing styles.
2. Devnagri script has some special features like conjunct characters.
3. Identifying Shirolekha and spine.
4. The shape of compound character is usually more complex than the constituent basic characters. 5. Devnagari script there is a practice of having more
than twelve forms each for 33 consonants giving rise to modified shapes which are depending on whether the vowel modifier is placed to the left, right, top or bottom of the consonants. They are called modified characters [4].
This affects the recognition rate and many other performance measures in recognition of characters. All these challenges cannot be met by just a single feature extractor or a single classifier. Moreover, a feature extractor and classifier combination may recognize a character which may not be recognized by the other feature extractor and classifier combination.
In this paper an attempt is made to develop a hybrid system that can recognize the Devnagri characters over a wide range of varying conditions and accept a handwritten Devnagri text that would result into a recognized Devnagri character through machine intelligence. The performance analysis of the system is carried out for the following performance measures to arrive at the conclusion.
1. Performance of algorithm (comparison of LM and
SCG)
2. Training Error
3. Receiver operating characteristics.
4. Performance characteristics.
5. Regression plot.
6. MSE. - Average error squared between output and
target
7. Gradient
IV. METHODOLOGY
THE RECOGNITION PROCESS It involves the following steps:
1. Pre-processing of the scanned characters. 2. Classification techniques of characters. 3. Training a neural network.
4. Recognition of characters.
Preprocessing
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 2, Issue 7, July 2012)241
Shirolekha Detection
The differential distance based technique calculates the successive differences of distances of upper envelop of the curve from the reference line. Fig. 4 showsthe technique of detecting shirolekha
Spine Detection
Detection of the spine is explained in fig. 5
Figure 4 Detecting Shirorekha Figure 5 Detecting Spines
Intersection Features
Intersection features are unique for different characters hence feature points are exploited for the task of character recognition.
Classification of characters
[image:4.612.62.274.415.464.2]Before applying to Neural Network, characters are classified on the basis of shirolekha continuity and spine location (End spine, mid spine, No spine) [4]. The classification of the characters is shown in fig. 6.
Figure 6 Preliminary Classification
Neural Networks in Pattern Recognition
Pattern recognition is the association of an observation to past experience or knowledge. Humans continuously perform perceptual pattern recognition, and the amazing complexity of the cognitive processes involved has made pattern recognition an active area of search in psychology and neurophysiology for many decades.
With the recent advances in the computing technology, many pattern recognition tasks have become automated. These include tasks naturally performed by humans, such as speech and handwritten character recognition, as well as the jobs that are unnatural and difficult. Today useful applications of automatic pattern recognition are prevalent. As computers and the methods of automatic pattern
recognition progress, more and more fascinating
applications are being discovered in the fields of finance, manufacturing and medicine.
Pattern recognition is the science and art of giving names to the natural objects in the real world. A pattern is essentially an arrangement or an ordering, in which some organization of underlying structure can be said to exist. So a pattern can be referred to as a quantitative or structural description of an object or some other item of interest. A set of patterns that share some common properties can be regarded as pattern class.
It naturally involves extraction of significant attributes of the data from the background of irrelevant details, for example
1. Speech recognition maps a waveform into words
2. Character recognition maps a matrix of pixels into characters and words.
The pattern recognition solution involves many stages such as making the measurements, preprocessing and segmentation, finding a suitable numerical representation for the objects we are interested in, and finally classifying them on these representations [23].
Handwritten Character Recognition System
The continuous development of computer tools leads to a requirement of easier interfaces between the human and the computer. Handwritten character recognition may for instance be applied to zip-code recognition, automatic printed form acquisition, or checks reading. The importance of these applications has to intense research for several years in the field of off-line handwritten character recognition. Substantial progress has been recently achieved, but the recognition of handwritten text cannot yet approach human performance. The difficulties decent from 1. Variability of someone's calligraphy over time.
2. The similarity of some character with each other. 3. Infinite variety of character shapes.
4. Infinite variety of writing styles produced by different writers.
[image:4.612.325.564.598.684.2]The operation of pattern recognition system is presented as a series of consecutive processing the basic setting of pattern recognition is shown in Fig. 7
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 2, Issue 7, July 2012)242
Back Propagation Network (BPN)
Back propagation is a systematic method for training multi-layer artificial neural networks. It has amathematical foundation that is strong if not highly practical. It is a multi-layer forward network using extend gradient-descent based delta-learning rule, commonly known as back propagation (of errors) rule. Back propagation provides a computationally efficient method for changing the weights in a feed forward network, with differentiable activation function units, to learn a training set of input-output examples. GE Hinton, Rumelhart and R.O. Williams first introduced BPN in 1986.
Even though the work was performed by Parker (1985) the credit of publishing this net goes to Rumelhart, Hinton and Williams (1986). Back propagation net emerged as the most popular learning algorithm for the training of multilayer perceptrons and has been the workhorse for many neural network applications.
Being a gradient descent method it minimizes the total squared error of the output computed by the net. The network is trained by supervised learning method. The aim of this network is to train the net to achieve a balance between the ability to respond correctly to the input patterns that are used for training and the ability to provide good responses to the input that are similar.
Architecture
A multilayer feed forward back propagation network with one layer of z-hidden units is shown in the Fig.8. The Y output unit has Wok bias and Z hidden unit has Vok as
[image:5.612.370.514.245.429.2]bias.
Figure 8 Architecture of Back Propagation Network
It is found that both the output units and the hidden units have bias. The bias acts like weights on connection from units whose output is always 1. From the fig. 8 it is clear that the network has one input layer, one hidden layer and one output layer. There can be any number of hidden layers. The input layer is connected to the hidden layer and the hidden layer is connected to the output layer by means of Interconnection weights. In Fig. 8, only the feed forward phase of operation is shown.
But during the buck propagation phase of learning, the signals are sent in the reverse direction. The increase in the number of hidden layers results in the computational complexity of the network. As a result, the time taken for convergence and to minimize the error may be very high. The bins are provided for both the hidden and the output layer, to act upon the net input to be calculated [23].
The Proposed System Design Flow
Figure 9 Proposed System Design Flow
Data Collection
[image:5.612.83.271.491.582.2]
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 2, Issue 7, July 2012) [image:6.612.339.544.131.294.2]243
Figure 11 Extracted Image of CharacterScaled Conjugate Gradient Algorithm (trainscg)
The scaled conjugate gradient algorithm (SCG) was developed by Moller and was designed to avoid the time-consuming line search. This algorithm combines the model-trust region approach with the conjugate gradient approach. The conjugate gradient algorithms have relatively modest memory requirements. For large networks you will probably want to use trainscg or trainrp. Each of the conjugate gradient algorithms discussed so far requires a line search at each iteration. This line search is computationally expensive, because it requires that the network response to all training inputs be computed several times for each search.
V. RESULTS AND PERFORMANCE ANALYSIS
Receiver Operating Characteristics
It Plot the receiver operating characteristics for each output class. The more each curve hugs the left and top edges of the plot, the better the classification. The fig.12
shows the ROC for character
The colored lines in each axis represent the ROC curves for each of the four categories of this simple test problem. The
ROC curve
is a plot of the true positive rate (sensitivity) versus the false positive rate (1 - specificity) as the threshold is varied. A perfect test would show points in the upper-left corner, with 100% sensitivity and 100% specificity.Figure 12 Receiver Operating Characteristics
[image:6.612.88.252.135.259.2]Performance Characteristics
Figure 13 Performance Characteristics
The performance plot shows the best validation performance at epoch 99 and mean square error at this epoch is 0.0048952.The fig 13 shows the network
performance for Devnagri character
[image:6.612.331.547.315.493.2]International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 2, Issue 7, July 2012)244
Training Characteristics
[image:7.612.341.546.132.317.2]This plot shows the scaled conjugate gradient algorithm with momentum. The following fig.14 shows Gradient and validation fails at epoch 105.
Figure 14 Training Characteristics
Training a Neural Network with Levenberg-Marquardt algorithm (trainlm)
We have used Multilayer Perceptron Neural Network based scheme for identification of handwritten Devnagari scripts. The Multi Layer Perceptron (MLP) is created, in general, a layered feed-forward network. Generalization ability of an MLP is tested by checking its responses to input patterns which do not belong to the training set.
Back propagation algorithm, which uses patterns of known classes to constitute the training set, represents a supervised learning method. After supplying each training pattern to the MLP, it computes the sum of the squared errors at the output layer and adjusts the weight values of the synaptic connections to minimize the error sum. Weight values are adjusted by propagating the error sum from the output layer to the input layer.
Regression Plot
The next step is to perform some analysis of the network response. Put the entire data set through the network (training, validation, and test) and perform a linear regression between the network outputs and the corresponding targets. The fig. 15 shows the regression plot
for handwritten character
[image:7.612.61.275.191.355.2]The first two outputs seem to track the targets reasonably well (this is a difficult problem), and the R-values are around 0.9. Modeling the third output (VLDL levels) is not as successful and the problem needs more work.
Figure 15 Regression Plot
Performance Characteristics
The performance plot shows the best validation performance at epoch 1. The fig16 shows the network
performance for Devnagri character
The performance plot checks the network output match and the target for all three data sets (Test, Validation and Testing).
Figure 16 Performance Characteristics
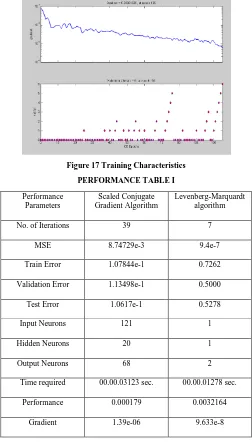
Training Characteristics
The fig.17 shows the training characteristics for
[image:7.612.335.546.417.589.2]International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 2, Issue 7, July 2012) [image:8.612.42.294.139.581.2]245
Figure 17 Training CharacteristicsPERFORMANCE TABLE I
Performance Parameters
Scaled Conjugate Gradient Algorithm
Levenberg-Marquardt algorithm
No. of Iterations 39 7
MSE 8.74729e-3 9.4e-7
Train Error 1.07844e-1 0.7262
Validation Error 1.13498e-1 0.5000
Test Error 1.0617e-1 0.5278
Input Neurons 121 1
Hidden Neurons 20 1
Output Neurons 68 2
Time required 00.00.03123 sec. 00.00.01278 sec.
Performance 0.000179 0.0032164
Gradient 1.39e-06 9.633e-8
From the above table we can conclude that
1. The SCG algorithm is almost as fast as the LM algorithm.
2. SCG algorithm performance does not degrade
when the error is reduced.
3. The validation error normally decreases during the
initial phase of training, as does the training set error. However, when the network begins to over fit the data, the error on the validation set typically begins to rise.
4. If the error in the test set reaches a minimum at a significantly different iteration number than the validation set error, this indicate a poor division of the data set.
5. Less no. of iterations required, indicates rate of convergence.
VI. CONCLUSION
In this paper, we have described a system for HCR for Devnagri script material. The recognition accuracy of the prototype implementation is promising, but more work needs to be done. In particular, no fine-tuning of the system has been done so far. Our character segmentation method also needs to be improved so that it can handle a larger variety of touching characters, which occur fairly often in images obtained from inferior-quality printed material.
In general, the system needs to be tested on a wider variety of images containing characters in diverse fonts and sizes. This will enable us to identify the major weaknesses in the system and implement remedies for them. We have designed a hand written character recognition (HCR) system with almost 90% of character recognition rate. The system is analyzed by using various performance measures and various characteristics.
VII. FUTURE SCOPE
The designed system has to be improved over following points.
1. Reduction in MSE. 2. Reduction in % error.
3. Recognition of conjunct characters.
4. Best validation performance at less iteration (Epochs). 5. Segmentation of characters can be improved to include
overlapping and joined characters.
6. New algorithms can be developed to help the segmentation of joined hand written letters.
The current thinning algorithm used produces short spurs which make computation of various attributes like pixel densities, or checking continuity of an image at times faulty and corruptive, an improved thinning algorithm can be developed to counter the problem of short spurs. The focus should be now on optimizing the recognition algorithm, which is left as a further scope for improvement.
Limitations
Following are the limitations of the designed system
1 Recognition of only Devnagari Script alphabets.
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 2, Issue 7, July 2012)246
3 Inputs image should not contain conjunct characters
4 The scanned images with 96-100 dpi resolution are
required.
5 MSE is much higher which should be minimized.
6 System shows on average 50% of misclassification hence % error should be minimized.
7 Ball point pen image with thickness of 0.5 mm and
Marker pen with thickness up to 2.5 mm are required.
8 Smart pre-processing or feature extraction and
classification are required to obtain clear image. Since image applied to the neural network does not give appropriate result
9 More work is required on conjunct characters.
REFERENCES
[1 ] Anilkumar N. Holambe Dr.Ravinder.C.Thool, ―Comparative Study
of Devanagari Handwritten and printed Character & Numerals Recognition using Nearest-Neighbor Classifiers‖, 978-1-4244-5540-9/102010 IEEE
[2 ] Constantin Anton, Cosmin Stirbu, Romeo, Vasile Badea―Automatic
hand writer identification using the feed forward neural networks‖, 978-0-9564263-7/6/2011 IEEE
[3 ] Dr. P. S. Deshpande Mrs. Latesh Malik Mrs. Sandhya Arora,
―Characterizing Hand Written Devanagari Characters using Evolved Regular Expressions‖, 1-4244-0549-1/ 2006 IEEE.
[4 ] Sushama Shelke Shaila Apte, ―A Novel feature
Multi-Classifier Scheme for Unconstrained Handwritten Devanagari Character Recognition‖,2010, 12th International Conference on Frontiers in Handwriting Recognition.
[5 ] Swamy Saran Atul, thesis on Handwritten Devanagari Character
Recognition.
[6 ] Sandhya Arora Meghnad Saha DebotoshBhatcharjee Mita Nasipuri
Latesh Malik, ―A Two Stage Classification Approach for Handwritten Devanagari Characters‖, International Conference on Computational Intelligence and Multimedia Applications 2007
[7 ] Sreeraj.M Sumam Mary Idicula, ―On-Line Handwritten Character
Recognition using Kohonen Networks‖, 2009 World Congress on Nature & Biologically Inspired Computing (NaBIC 2009)
[8 ] Alex Graves, Marcus Liwicki, Santiago Ferna´ndez Roman
Bertolami, Horst Bunke, and Ju¨rgen Schmidhuber,―A Novel Connectionist System for Unconstrained Handwriting Recognition‖, IEEE Transactions On Pattern Analysis And Machine Intelligence, Vol. 31, No. 5, May 2009.
[9 ] Salvador Espan˜a-Boquera, Maria Jose Castro-Bleda,Jorge
Gorbe-Moya, and Francisco Zamora-Martinez, ―Improving Offline
Handwritten Text Recognition with Hybrid HMM/ANN
Models‖,IEEE Transactions On Pattern Analysis And Machine Intelligence, Vol. 33, No. 4, April 2011.
[10 ]Sandhya Arora Debotosh Bhattacharjee Mita Nasipuri D. K. Basu
―Recognition of Non-Compound Handwritten Devnagari Characters
using a Combination of MLP and Minimum Edit
Distance‖,International Journal of Computer Science and Security (IJCSS),Volume (4) Issue ( 1).
[11 ]J.Pradeep, E.Srinivasan, S.Himavathi, ―Diagonal Based Feature
Extraction for Handwritten Character Recognition System Using Neural Network‖, 978-1-4244-8679-3/11/2011 IEEE.
[12 ]Hsin-Chia Fu,Yeong Yuh Xu, ―Multilinguistic Handwritten
Character Recognition by Bayesian Decision-Based Neural Networks‖,IEEE TRANSACTIONS ON SIGNAL PROCESSING, VOL. 46, NO. 10, OCTOBER 1998
[13 ]Cheng-Lin Liu, Hiroshi Sako, Hiromichi Fujisawa, ―Effects of
Classifier Structures and Training Regimes on Integrated
Segmentation and Recognition of Handwritten Numeral
Strings‖,IEEE TRANSACTIONS ON PATTERN ANALYSIS AND MACHINE INTELLIGENCE, VOL. 26, NO. 11, NOVEMBER 2004.
[14 ]Ján Dolinský, Hideyuki Takagi, ―Analysis and Modeling of
Naturalness in Handwritten Characters‖,IEEE TRANSACTIONS ON NEURAL NETWORKS, VOL. 20, NO. 10, OCTOBER 2009.
[15 ]R.Indra Gandhi, Dr.K.Iyakutti, ―An Attempt to Recognize
Handwritten Tamil Character Using Kohonen SOM‖, Int. J. of Advance d Networking and Applications 188 Volume: 01 Issue: 03 Pages: 188-192 (2009)
[16 ]Kailash S. Sharma, A. R. Karwankar, Dr.A.S.Bhalchandra,
―Devnagari Character Recognition Using Self Organizing Maps‖,978-1-4244-7770-8/10/2010 IEEE.
[17 ]Liang-Chia.Chen, Ju-Yi.Fan, Yung-Sheng Chen, ―A High Speed
Modified Hopfield Neural Network and A Design of Character Recognition System‖, CH3031-W91/0000-0308 81-00 1991 IEEE.
[18 ]Prerna Singh Nidhi Tyagi, ―Radial Basis Function For Handwritten
Devnagari Numeral Recognition‖,(IJACSA) International Journal of Advanced Computer Science and Applications, Vol. 2, No. 5, 2011
[19 ]J.Pradeep, E.Srinivasan, S.Himavathi, ―Neural Network based
Handwritten Character Recognition system without feature extraction‖,International Conference on Computer,Communication and Electrical Technology – ICCCET 2011, 18th & 19th March, 2011
[20 ]Paul D. Gader, Magdi Mohamed, and Jung-Hsien Chiang,
―Handwritten Word Recognition with Character and Inter-Character Neural Networks‖,IEEE TRANSACTIONS ON SYSTEMS, MAN, AND CYBERNETICS—PART B: CYBERNETICS, VOL. 27, NO. 1, FEBRUARY 1997.
[21 ]S. N. Sivanandam, M Paulraj, Introduction to Artificial Neural
Networks.
[22 ]S. N. Sivanandam, S. Sumathi, S.N. Deepa, Introduction to Artificial
Neural Networks using MATLAB 6.0.
[23 ]Vikas J Dongre Vijay H Mankar, ―A Review of Research on
Devnagari Character‖, International Journal of Computer Applications (0975 – 8887) Volume 12– No.2, November 2010.
[24 ]Prof. N.B. Pasalkar,Prof.(Mrs.) C.V.Joshi ,Mrs. Madhuri Tasgaonkar
, ―Script To Speech Conversion for Marathi Language‖, 0-7803-7651-X/03/2003 IEEE.
[25 ]K. Roy, K. Majumdar, ―Trilingual Script Separation of Handwritten
Postal Document‖, Sixth Indian Conference On Computer
Vision, Graphics & Image Processing, 978-0-7695-3476-
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 2, Issue 7, July 2012)247
[26 ]U. Pal, T. Wakabayashi, F. Kimura, ―Comparative Study of
Devnagari Handwritten Character Recognition Using Different Feature and Classifiers‖, 2009 10th International Conference on Document Analysis and Recognition, 978-0-7695-3725-2/2009 IEEE DOI 10.1109/ICDAR.2009.244
[27 ]U. Pal, N. Sharma, T. Wakabayashi, F. Kimura, “Off-Line
Handwritten Character Recognition of Devnagari Script‖,Ninth International Conference on Document Analysis and Recognition (ICDAR 2007) 0-7695-2822-8/07 2007.
[28 ]Mahesh Jangid Kartar Singh,Renu Dhir,Rajneesh Rani,
―Performance Comparison of Devnagari Handwritten Numerals Recognition‖, International Journal of Computer Applications (0975 –8887) Volume 22– No.1, May 2011.
[29 ]P.B.Khanale and S.D.Chitnis ―Handwritten Devnagri Character