Schema Level and Data Level Mapping Composition
Md Anisur Rahman
Comouter Science Department Khulna University, BangladeshMehedi Masud
Computer Science Department Taif University, Taif, Saudi ArabiaABSTRACT
Schema mappings and data mappings constitute essential build-ing blocks of data integration, data exchange and peer-to-peer data sharing systems. At present, either schema-level mappings or data-level mappings are used for data sharing purposes. In this paper we consider the semantics of bi-level mapping that combines the schema-level and data-level mappings. Tabular representation of the mappings helps to solve many mapping-related algorithmic and semantic problems, like mapping composition. Composition of mappings between sources has several computational advan-tages in a peer data sharing system, such as yielding more effi-cient query translation and pruning redundant paths. Considering the need of mapping composistion, this paper presents a mech-anism for composing two bi-level mappings by using tableaux.
General Terms:
Database, Peer to Peer
Keywords:
Mappings, data Interoperability, mapping composition
1. INTRODUCTION
Integrated access to distributed and heterogeneous information sources, e.g.data integration,data exchangeandP2P data shar-ing, is an important research area. In data integration systems data residing at different sources are combined to provide the users with a unified view [1]. In data exchange systems, instance of a target schema is created from data structured under a source schema [2]. In a P2P data sharing system each peer can exchange data with a set of other peers that are independently created [3]. Schema map-pings is the main technique for sharing and exchanging data in all the systems resolving data heterogeinity among the sources. A schema mapping describes the relationship between two database schemas at high level. There are three approaches for specify-ing the schema mappspecify-ings: local-as-view (LAV), global-as view (GAV), andglobal-and-local-as-view(GLAV). GLAV is a mixed approach and specifies the mappings by a set of assertions of the form∀~x(∃~yφS(~x, ~y) ∃~zφG(~x, ~z))whereφGis a query overG andφS is a query overS. Here,Gis global schema andSis source schema.
GAV specifies the mappings by a set of assertions of the form
∀~x(φS(~x) g(~x))wheregis an element of global schema (target schema)GandφS is a query over source schemaS. Relations in
Gare views and queries are expressed over the views. Queries can
simply be evaluated over the data satisfying the global relations. LAV approach specifies the mappings by a set of assertions of the form∀~x(s(~x) φG(~x))wheresis an element ofS andφG is a query overG.
1.1 Motivation
Combining two mappings into a single one is called mapping composition. Composition of mappings between data sources has several computational advantages, such as yielding more efficient query translation, pruning redundant paths, and better query exe-cution plans. This paper considers a tableau based [12] technique for composing the bi-level mappings. Essentially, the bi-level map-pings are first expressed by tableaux [12]. Then the composition is performed by manipulating those tableaux.
1.2 Objectives
Follwoing are the overall objective of this paper:
1. Analyze the problems to compose mappings of schema and data level mappings in data sharing environments.
2. Propose a framework that enables heterogeneous data sources to be shared efficiently considering data and schema level heterogene-ity. Moreover, propose a model to compose mappings between two indirect data sources.
2. LITERATURE REVIEW
Schema mappings [4, 5, 6, 7, 8] and data mappings [9] are used to address the schema-level and data-level heterogeneity, respec-tively. Several strategies are introduced for the schema mappings between the mediated and local schemas including, global-as-view (GAV) [1], local-as-view (LAV) [8], and global-and-local-as-view (GLAV) [5]. In GAV approach, the mediated schema is described in terms of local sources. In LAV, the local sources are described in terms of the mediated schema. GLAV is the combination of GAV and LAV approaches to integrate the mediated and local schemas. Schema-level mappings are effective only when the differences between the schemas are mainly structural, i.e. attribute values represent the same information, or can be transformed to be the same. However, data-level mappings are necessary when semanti-cally related attribute values differ. Data mappings are implemented by mapping tables [9] which are relations on the attributes being mapped. The tuples in the mapping tables show the correspondence between values in the mapped relations. These tables are treated as constraints (aka mapping constraints) on the exchange of data be-tween peers. In the following, some related works regarding the mappings of peer database management systems are discussed. In a peer data sharing system, each peer chooses its own database schemas, and maintains data independently of other peers. Contrary to the traditional data integration systems where a global mediated schema is required for data exchange, in a PDMS the semantic relationships exist between a pair of peers, or among a small set of peers for sharing data. The data is shared globally among the peers by traversing the transitive relationships among semantically related peers. Creating a unique global mediated schema is imprac-tical in a PDMS due to the volatility, peer autonomy, and scalabil-ity issues. Instead, mappings are implemented only between pairs of peers to unify the heterogeneous data sources. These mappings describe the relationship between the terms used in different peers. Hyperion system [11, 14] addresses the problem of mapping data in P2P systems where different peers may use different values to identify or describe the same data. Hyperion relies on mapping ta-bles that list pairs of corresponding values for search domains that are used in different peers. Mapping tables provide the foundation for exchanging information between peers.
The Piazza system [16] provides a solution to peer data manage-ment system where the single logical schema of data integration systems is replaced by a set of mediator schemas that are
inter-linked to define semantic mappings between the peer schemas. Pi-azza uses two data integration formalisms local-as-view (LAV) and global-as-view (GAV) for peer mappings. GAV is used to define relations of the mediator’s schema over the relations in the sources and LAV is used to define relations in the sources over the medi-ated schema. In Piazza, a reformulation algorithm for query pro-cessing is presented that addresses both GAV and LAV mappings. However, the Piazza system considers only the schema-level het-erogeneity among the peers.
The SASMINT system [17] provides a solution for supporting interoperability infrastructures that enables sharing and exchange of data among diverse sources. The system mainly finds and re-solves syntactic, semantic, and structural conflicts among schemas and matches schemas automatically. This system can be very use-ful to discover mappings between peers automatically. The system mainly discovers mappings between two peers which are directly connected. However, in this project the mappings are discovered between two peers which are connected through other peers in the path.
3. SYSTEM MODEL FOR MAPPING COMPOSITION
In this section we present a data sharing system modelΠwhere we conisder the composition of mappings. Before defining the system we recall different notions as presented in [10, 11].
A data sourceSi∈ Sis a tuple, whereSi= (P Si, Ri, Li). Where,
- P Siis the source schema through which data in a source is
exposed to the external world.
- Riis the set of sources comprised of local and external
sources.
- Liis the set of GLAV local mappings which define the
mappings betweenRiandP Si. Each local mapping, called
mapping assertion(akatuple generating dependency), inLi
has the form
∀~x(∃~yϕ(~x, ~y) ∃~zψ(~x, ~z))
whereϕ(~x, ~y)andψ(~x, ~z)are conjunctive queries over the relations inRiandP Sirespectively.
Source mappingsMi∈ Mis a set of mappings, called bi-level mapping orsource mappings, that define the schema and data-level mappings between sources. The construction of mappingsMij⊆ Miforms an acquaintance (i, j) betweenSiand
Sj. Each mappingm∈ Miis a pair< mSj,k, mDj,k>, where:
- mS
j,kis a GLAV mapping (practically GAV, sinces(~x)is
always a single relation) of the form
∀~x(∃~yϕ(~x, ~y) s(~x))
whereϕ(~x, ~y)is a conjunctive query over the peer schema of a peerPjands(~x)is thekthexternal source ofSi.
- mD
j,k=MT={mt1, mt2, . . . , mtq} ⊆M Tjiis a set of mapping
tables.M Ti
jdenotes the set of mapping tables used to map data
ofSjto data ofSi.
mcan alternatively be represented with the mapping assertion as follows:
∀~x(∃~yϕ(x, ~~ y)M T s(~x))
A data sharing systemΠis defined by a pairhS,Mi, whereS =
It is assumed that a curator with expertise in different domains is re-sponsible for generating the mapping tables. Schema mappings be-tween two sources are initially created by the corresponding source administrators when they agree to share data. Generating the map-pings automatically is another research area and this paper does not address this issue.
The semantics of source mappings can be given in terms of FOL. LetM T = {mt1[P~1, ~Q1], mt2[P~2, ~Q2], . . . , mtn[P~n, ~Qn]} be
a set of mapping tables, where for any pairs of mapping tables (mti[P~i, ~Qi], mtj[P~j, ~Qj]),mti 6= mtj =⇒ P~i 6= P~j, then
M T[~x]denotes a set of tuples resulted from transformation of~xby all the member mapping tables ofM T. Formally,
The semantics of source mappings is defined below. It is already mentioned that a mapping assertion of a source mapping is of the form:
∀~x(∃~yϕ(x, ~~ y)M Ts(~x))
Let us assume that the above assertion defines an external source
sof sourceSiin terms of the source schema of a sourceSj. An
interpretation of the schema ofSiandSjsatisfies the assertion if
that interpretation satisfies the following formula
∀~x∀~z(∃~y(ϕ(~x, ~y)∧~z∈M T[~x])≡s(~z))
A mapping can be interpreted as a definition of how the data of the external source would be instantiated by the data of other peers. The formula also tells us that before instantiating the ex-ternal source, data is converted using the corresponding mapping tables ofM T. However, if there is no data-level heterogeneity, no mapping table is needed. In that case, an empty mapping table
φis used in the assertion. In that case, a peer mapping is repre-sented as∀~x(∃~yϕ(x, ~~ y) φ s(~x))which satisfies the FOL formula
∀~x(∃~yϕ(x, ~~ y)≡s(~x)).
A data sharing systemΠis given in terms of a set of models that satisfy the local and source mappings ofΠ. Let a source databaseD
forΠbe a disjoint union of a set of local databases in each source
SiofΠ. Given a source databaseDforΠ, the set of models ofΠ
relative toDis:
semD(Π) ={I|I
is a finite model of all peer theoriesFirelative
toD, andIsatisfies all peer mappings} 4. MAPPING COMPOSITION
Consider three data sourcesA,B, andCand the mappingsMA→B
andMB→C among them. In general, two mappingsMA→B and
MB→Ccan be composed when there exists a common relation
be-tween them. For creating the mappingMA→C from MA→B and
MB→C, first the mappings are converted into tableaux [12]TSAB
andTSBC. Then the tableaux are merged into a tableauTSAC.
TableauxTSACcontains all the information to generateMA→C. A
homomorphism funtionθABis used to map the elements between
MA→BandMB→Cto produceMA→C.
In the following we show the theory to represent bi-level mappings using tabular forms.
Letm : ∀~x(∃~yϕ(~x, ~y) M T E(~x))be an arbitrary bi-level map-ping between sourcesS1 and S2, where~x = (x1, . . . , xp) and
~y= (x1, . . . , xq). Note thatϕ(~x, ~y)must have relations only from
the sourceS1andE(~x)must be an external data source of source
S2. A MATTE
ϕM T formis a partitioned table whose left hand side
partition is the summary-free source tableauTϕM T (representing the query{x~0|∀x~0∃y~0ϕ
M T(x~0, ~y0)}) and the right hand side
parti-tion is the summary-free target tableauTE(representing the query
{x~0|∀x~0E(x~0)})) Where,
Procedure BLM2SMT(m)
Input :A Bi-Level mappingm:∀~x(∃~yϕ(~x, ~y)M TE(~x))
Output:An SMTTϕψrepresentingm
begin
Letσ≡ ∀~x(∃~yϕ(~x, ~y)→E(~x))
Tϕψ=hTϕ,Tψi=T GD2SM T(σ)
for eachmt[P, Q]∈M Tdo addQtoTϕ.Columns
adda new row toTϕ.Rowswith tagmt
Tϕ.Rows[mt][P]←F reshN onDistinguished()
for eachR∈ Tϕ.T agsdo
ifIsDistinguished(Tϕ.Rows[R][P])then T emp=Tϕ.Rows[R][P]
Tϕ.Rows[R][P] =Tϕ.Rows[mt][P]
Tϕ.Rows[mt][Q] =T emp
endif endfor endfor Tϕψ← hTϕ,Tψi
returnTϕψ
[image:3.595.315.522.82.417.2]end
Fig. 1. Procedure BLM2SMT
~
x0≡(~x−P~+Q~) ~
y0≡(~y+P~) ~
P≡ S
mt(~p,~q)∈M T
~ p
~
Q≡ S
mt(~p,~q)∈M T
~ q
ϕM T≡ϕ(x~0, ~y0)
V
mt(~p,~q)∈M T
mt(~p, ~q)
An algorithm for computing MAT TE
ϕM T for the mapping
as-sertion m : ∀~x(∃~yϕ(~x, ~y) M T E(~x)) is shown in Figure 1.
BLM2M AT(m) initially uses the functionT GD2SM T(σ)to create a MAT TE
ϕ = hTϕ,TEi for the mapping assertion σ : ∀~x(∃~yϕ(x, ~~ y) E(~x))(without considering the mapping tables). Then it augmentsTϕby adding each mapping tablemt∈M Tto the rows ofTϕ. When a row is added toTϕ for a mapping table
mt(~p, ~q)∈M T, the following steps are taken: (1) A new row is added toTϕwith the tagmt. (2) New columns are added toTϕfor the attributes~q.
(3) For some rowR, ifTϕ[R][~p]contains some distinguished
vari-ablea~i, thenTϕ[R][~q]is assigneda~i.
(4) The columns ~q ofTϕ are unified by putting the same same non-distinguished variables for each row ofTϕ.
When all the modification is done to Tϕ, we call the modified
Tϕ, TϕM T. Finally,TϕM T is merged with TE to form the MAT
TE
ϕM T =hTϕM T,TEi.
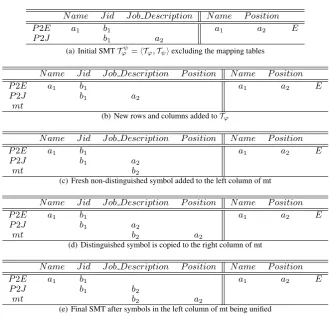
EXAMPLE 1. Consider the P2P data sharing system Π =<P,M>with the following settings:
P={P1, P2}
M={m}
When the algorithmBLM2M AT()of Figure 1 is applied tom, initially it creates the MATTψ
ϕ =hTϕ,Tψiof Figure 2(a) using the
algorithmM A2M AT()of Figure 1 on the mapping assertionσ≡ ∀x∃y∀z(P2E(x, y)∧P2J(y, z) E(x, z)).Tϕis then modified step by step for the mapping tablesmt. Figure 2(b) shows the new
Tψ
ϕ after a new rowmtand a new columnP ositionis added to Tϕ. Figure 2(c) shows that a fresh non-distinguished variableb2 has been assigned toTϕ[mt][J ob Description]. Figure 2(d) de-picts that distinguished variablea2ofTϕ[mt][J ob Description] is copied toTϕ[mt][P osition]. Finally, all the symbols of the col-umnJ ob DescrionofTϕis replaced by the same variableb2as
shown in Figure 2(e).
PROPOSITION 1. Let m ≡ ∀~x(∃~yϕ(~x, ~y) M T E(~x)) be a bi-level mapping.TE
ϕM T = hTϕM T,TEibe the schema mapping
tableaux (SMT) form. LetIbe an instance of the relations ofϕ. It is valid that
∀I0((I0∈CI(m, I))⇒(Tϕ
M T(I ./ M T)≡ TE(I
0 )))
Now we describe the mapping compostion process.
LetMA→Bis the mapping between A and B, andMB→C be the
mapping between B and C. The target is to find a mappingMA→C
between A and C that is equivalent to the composition of the two mappings MA→B and MB→C. The following example shows a
composition of two mappings.
Consider three data sources S1, S2 and S3 with the follow-ing mappfollow-ings among them.
(1)M3→2:πC311,C322(R31 ./C312=C321 R32) {mt32}
R21is the mapping betweenS3andS2:
(2)M2→1:R21
mt21
R11is the mapping betweenS1andS2:. From the above setting, an indirect mappingM3→1betweenS3and
S1can be constitueted as follows:
(3)M3→1:πC311,C322(R31./C312=C321 R32)
{mt32./mt21}
R11 is the composed mapping betweenS1andS2.
According to the algorithm in Figure 1, tableauTS21 fromM21 andTS32 fromMS21 are produced. After generating the tableau the following steps are considered to generate the tableauT31from
TS21and TS32. Finally, mappingM31 is generated from tableau
T31.
(1) MergeTS32andTS21and generate initial tableauTS131. In the merging process all the Rows, Columns, Tags, and Summaries ofTS32andTS21are transferred inTS131.
(2) Identify a common relationR21betweenTT32andTS21.
(3) Create a link between the mapping tables ofS2to the relations ofS3. The process has following two steps:
—For each columnCin the common relation, if(C, C0)∈θ32 whereC0 is a column of a arbitrary relationR ofS3, the value of T1
S31.Rows[R][C 0
] is updated by the value of
T1
S31.Rows[R21][C]. —If T1
S31.Rows[R21][C] be a distinguished variable then T1
S31.Summary[C 0]
is also updated by the value
T1
S31.Rows[R21][C]. After taking similar action for every columns ofR21inTS131,TS131takes the shape ofTS231. (4) Eliminate the common relationR21fromTS231using the
fol-lowing steps:
—The columns having non-null values only in the row with
R21are deleted.
—Delete the row with tagR21fromTS231. After eliminating theR21,T2
S31becomesT 3
S31. (5) Remove the redundant columns ofT3
S31(i.e. the columns with the same name).
Now we describe the steps for computing of target tableau,TT31,
and the homomorphism,θ31:
(1) Create a tableauTT31and initialize with the values ofTT21.
(2) Create an empty homomorphismθ31.
(3) For each columnCofTT21, do the following steps:
—Identify a columnBthat is mapped toCby the homomor-phismθ21.
—If B has an entry in TS31.Summary then (C, B) and(TT21.Summary[C], TS31.Summary[B])pairs are added toθ31.
—IfBcolumn is Null inTS31.Summarythen a columnA is identified that is mapped toBby the homomorphismθ32. IfAcolumn has an entry inTS31.Summarythen(C, A) and (TT21.Summary[C], TS31.Summary[A]) pairs are added toθ31.
—If neitherBnorAcan be found inTS31.Summaryfor the columnC,Cis deleted fromTT31.
NowTS31, TT31 and θ31 forms a triple and are then converted as normal bi-level mapping expression. In our example, when the triple< TS31, TT31, θ31 >is converted to normal expression, the mapping becomes as follows:
M3→1:πC311,C112(R31./C312=C321R32)
{mt32,mt21}
R11
5. DSICUSSION AND CONCLUSION
This paper presented a model of data sharing system and proposed mapping semantics, called bi-level mapping and its composition, combining the schema-level and the data-level mappings necessary for resolving heterogeneity among data sources in a data sharing system. This bi-level mappings allow sources efficient data sharing facilities that sources miss considering only schema or data level mappings. The bi-level mapping is based on the tableau represen-tation. The paper also provided an algorithm for the composition of two bi-level mappings.
To the best of our knowledge there is no implementation of com-bined scheme mappings in XML and unstructured database. This study is essential to understand and answer various fundamental is-sues and questions in regards to the suitability of bi-level mappings. There is also need to investigate the composition of mappings con-sidering the dynamic behavior of sources.
The development of algorithms that implement our proposals would seem to be a sensible and natural follow-on. Constructing prototypes may not straightforward and could be time consuming. Therefore, our future goal is to investigate the composition of map-pings considering XML databases, the dynamic behavior of peers. Further, we are interested to evaluate the whole process in a large data sharing system.
6. REFERENCES
[1] Lenzerini, M.: Data Integration: A Theoretical Perspective. In PODS, pp 233-246, (2002).
N ame J id J ob Description N ame P osition
P2E a1 b1 a1 a2 E
P2J b1 a2
(a) Initial SMTTϕψ=hTϕ,Tψiexcluding the mapping tables
N ame J id J ob Description P osition N ame P osition
P2E a1 b1 a1 a2 E
P2J b1 a2
mt
(b) New rows and columns added toTϕ
N ame J id J ob Description P osition N ame P osition
P2E a1 b1 a1 a2 E
P2J b1 a2
mt b2
(c) Fresh non-distinguished symbol added to the left column of mt
N ame J id J ob Description P osition N ame P osition
P2E a1 b1 a1 a2 E
P2J b1 a2
mt b2 a2
(d) Distinguished symbol is copied to the right column of mt
N ame J id J ob Description P osition N ame P osition
P2E a1 b1 a1 a2 E
P2J b1 b2
mt b2 a2
[image:5.595.139.469.58.376.2](e) Final SMT after symbols in the left column of mt being unified
Fig. 2. An example showing the steps for converting a Bi-Level Mapping to a SMT
[3] Arenas,M., Kantere, V., Kementsietsidis, A., Kiringa, I., Miller, R.J., Mylopoulos, J.: The Hyperion Project: From Data Integration to Data Coordination. In: SIGMOD RECORD (2003)
[4] Chawathe, S., Garcia-Molina, H., Hammer,J., Ireland, K., Pa-pakonstantinou, Y., Ullman, J. and Widom, J.: The TSIMMIS Project: Integration of Heterogeneous Information Sources. In: IPSJ (1994)
[5] Ullman, J.D.: Information Integration Using Logical Views. In: ICDT(1997)
[6] Boyd M., Kittivoravitkul, S., Lazanitis, C., McBrien, P.J., Ri-zopoulos, N.: AutoMed: A BAV Data Integration System for Heterogeneous Data Sources. In: CAiSE (2004)
[7] Miller, R.J., Hernndez, M., Haas, L.M., Yan, L., Howard, C.T., Fagin R., Popa, L.: The Clio Project: Managing Het-erogeneity. SIGMOD Record(2001)
[8] Levy, A.Y., Rajaraman A., Ordille, J.J.: Querying Heteroge-neous Information Sources Using Source Descriptions. In: VLDB (1996)
[9] Kemensietsidis, A., Arenas,M.: Mapping Data in Peer-to-Peer Systems: Semantics and Algorithmic Issues. In: ACM SIG-MOD (2003)
[10] M. A. Rahman, M. M. Masud, I. Kiringa, and A. El Sad-dik. Bi-Level Mapping: Combining Schema and Data Level Heterogeneity in Peer Data Sharing Systems.Proc. Alberto Mendelzon Workshop on Foundations of Data Management, Vol. 450, 2009.
[11] M. A. Rahman, M. M. Masud, I. Kiringa, and A. El Saddik. A Peer Data Sharing System Combining Schema and Data Level Mappings. InInternational Journal of Semantic Computing, Vol 3, No. 1, pp 105-129, 2009.
[12] Aho, A.V., Sagiv, Y., Ulman, J.D.,: Efficient Optimization of a Class of Relational Expressions. ACM Transactions on Dtabase Systems, Vol. 4, No. 4, pp 435-454, (1979)
[13] M. A. Rahman, M. M. Masud, I. Kiringa, and A. El Saddik. Tableaux-based optimization of schema mappings for data in-tegration. InJournal of Intelligent Information Systems, Vol 38, Issue 2, pp 533-554, 2012.
[14] Arenas,M., Kantere, V., Kementsietsidis, A., Kiringa, I., Miller, R.J., Mylopoulos, J.: The Hyperion Project: From Data Integration to Data Coordination. In: SIGMOD RECORD (2003)
[15] P. Rodriguez-Gianolli, M. Garzetti, L. Jiang, A. Kementsiet-sidis, I. Kiringa, M. Masud, R. Miller, and J. Mylopoulos: Data Sharing in the Hyperion Peer Database System, In Proc. Of the Intl Conf. on Very Large Data Bases (VLDB), pp. 1291-1294, 2005.
[16] Halevy, A.Y., Ives Z.G., Madhavan, J., Mork, P., Suciu, D., Tatarinov, I.: The Piazza Peer Data Management System. IEEE T.K.D.E. 16, 787–798 (2004)