3240
Optimization Based Fuzzy Deep Learning
Classification For Sentiment Analysis
K.K. Uma, Dr. K. Meenakshisundaram
ABSTRACT: In the field of sentiment analysis there are many algorithms exist to NLP problems. The matter of classifying sentiments in twitter dataset is incredibly a lot of necessary in real issues like decision-making and information system. In this paper a new general accuracy function selection and classification is proposed using optimized deep learning approach. This new method is proposed to solve the misclassification problem in social media review data set. In addition, the work is defined with a mew general accuracy feature selection technique using convolution neutral network clubbed with evolutionary optimized technique. A new deep learning fuzzy based classification is designed and used to extract features to identify the optimal feature selection fray bag of words, evolutionary method along with conditional neural networks permits to define novel accuracy Function for the designed Fuzzy-Long short Term memory classification of data under social comments in twitter will support to achieve better security and improves performance. This proposed technique prevents misclassification in better achievement with high reliability in achieving better performance evaluation and also the work solves the gap of more accurate detection of both sentiments and relevant emotion in text, The combination of optimized CNN with Fuzzy-LSTM gives better performance dealing with quick identification of aspect level sentiment analysis.
Keywords: Convolutionary Neural Network (CNN), Long Short Term Memory (LSTM), Fuzzy sets, optimization Natural Language Processing (NLP).
————————————————————
1.
INTRODUCTION
Reviewing a product is prevalent in online procurements. The view of a person is not only dependent on the text but also on the context. Social media like Twitter shows the survey of items sold online. The ups and downs of items sold online can be obtained from customer reviews. The online reviews of items include features of the item that users have purchased. The users add their views that include positive or negative sentiments. The summaries of anything like the product can be obtained from the product reviews. By using Fuzzy optimization rule mining, customer reviews are improved and user sentiments are analysed. Sentiment analysis plays an important role in data mining, and deals with identifying and analysing sentiments available in social media. Social networking websites generate huge volume of unstructured data. Twitter is mainly used, wherein tweets portray the users’ viewpoints and sentiments. It is a rich source of data that supports opinion mining, sentiment and emotion analysis. Micro-blogging websites like Twitter are an unlimited source of different kinds of information. People put their opinions on diverse topics, argue about current issues, criticize and express their emotions. The spectators of these platforms and social networks increase day by day. Data obtained from these sources are used in opinion mining, sentiment and emotion analysis. Opinions, sentiments and emotions are involved in sentiment analysis and opinion mining. Data in social media are always noisy with many mistakes in spelling, grammar and punctuation. At present, sentiment analysis methodologies deal with the polarity of positive and negative emotions. Polarity analysis yields only inadequate information. Defining positive/negative emotions is simple, but identifying the whole set is tedious.
______________________
K.K. Umaand, Research Scholar, Department of Computer Science, Erode Arts and Science College, Erode, Tamilnadu, India. E-Mail: [email protected]
Dr. K. Meenakshisundaram, Associate Professor, Department of Computer Science, Erode Arts and Science College, Erode, Tamilnadu, India.
Emoji has become the most popular form of communication. Emojis are visual illustration of emotions, objects or symbols. They are ideograms and smileys used in electronic messages and web pages. They are of different types including facial expressions, general objects, places, weather, animals and birds. They resemble emoticons, but Emojis are real pictures and not typographic. Emoticon refers to typographic displays of emotion, while. This paper proposes a scheme wherein, knowledge gained from a language is passed on to a language with scarce amount of labels. It deals with analysing symbols which include emoticons and emoji ideograms. As emotion tokens aid in expressing one’s emotions, it is seen in most of the tweets. Emojis aid in sentiment analysis by supporting cross-lingual sentiment classification.
2.
RELATED WORK
In this section, the work done by various authors on feature extraction using Convolutional Neural Networks (CNN) and Grey Wolf Optimization (GWO) are discussed. In addition, classification using Fuzzy logic and Long Short-Term Memory (LSTM) are also elaborated in detail with related literature reviews. More number of authors concentrated with techniques and methods that created a deep learning knowledge to start their research work in the same field.
2.1 Feature Extraction using Convolutional Neural Networks (CNN) in Text.
Rouvier& Favre (2016)Neural networks for every input space are trained individually, and then the representations retrieved from their concealed layers are combined as input of a fusion neural network. The objective of the task is to identify emotion polarity in tweets.
3241 Zhao & Zeng (2017) We frame this investigation as a text
classification problem, relating input word to their most likely associated emoji, using scraped Twitter tweets for the training data set. The LSTM-RNN model and CNN model performs better than baseline, even though the CNN model unexpectedly accomplishes much better accuracy and F1 results.
Zhang et al (2017) The model has two merged parts: CNN retrieves local n-gram characters within tweets and LSTM arranges the characters to confine long-distance dependency across tweets. In addition, three models (CNN, LSTM, BiLSTM) are used as baseline algorithms. The experimental result shows good performance.
Jianqiang et al (2018) An emotion characteristic set of tweets is formed by merging the word embeddings with n-grams characteristics and word emotion polarity score characteristics. The characteristic set is merged into a Deep Convolutional Neural Network for training and forecasting emotion categorization labels. The experimental results signify that the model gives better accuracy and F1-measure for twitter emotion categorization.
Ronzano et al (2018) have designed the first Italian Emoji Prediction technique (ITAmoji) at EVALITA 2018 evaluation campaign, after the achievement of the twin Multilingual Emoji Prediction Task, arranged in the context of SemEval-2018 to challenge the research community to routinely model the semantics of emojis on Twitter. Participants were asked to submit the designed systems which give its most likely related emoji, selected in an extensive and various emoji spaces. 12 runs were submitted at ITAmoji by 5 teams and presented the data sets, the evaluation methodology including various metrics and the methods of the contributing systems. They also presented a comparison among the performance of humans and automatic systems solving the same task.
2.2 Feature Extraction using Grey Wolf Optimization
Aswani et al (2017) Experimental results may be helpful in areas like digital, e-commerce influencer marketing to discover the reasons that might create buzz along with the variation among the normal talks on the consumers and impact of buzz. The content distributed on social media platforms becomes trendy and subsequently viral when distributed and propagated by a larger audience at a faster pace. Organizations are leveraging this power of social media in the domain of content buzz and virality by employing a variety of buzz monitoring methods to improve the arrival of their content.
Kumar et al (2018) have propounded a hybrid suggestion scheme which combines the content-based filtering and collaborative filtering, with emotion analysis of film tweets to facilitate the reduction effect of dependencies. Suggestion schemes are main intellectual schemes which play a very important function in providing discriminative information to users. Conventional approaches in suggestion schemes include content-based filtering and collaborative filtering. On the other hand, these approaches have certain drawbacks like the requirement of previous user history and habits for carrying out the task of suggestion. Movie tweets have been
gathered from microblogging websites to recognize the recent trends and user reactions of the movie. Experiments performed on public database generate hopeful results. Kumar & Jaiswal (2019) The characteristics are trained over five baseline classifiers namely, support vector machines, k-nearest neighbor, the Naïve Bayesian, decision tree and multilayer perceptron. The results confirm that the population-based meta-heuristic algorithms for characteristic subset selection perform better than the baseline supervised learning algorithms.
2.3 Classification using Fuzzy Logic
Grieves et al (2015) have measured performance by detecting characters by interacting with a device. Prediction candidates equivalent to the perceived characters are generated according to a language model that considers emoji along with phrases and words. The language model uses mapping table which maps a plurality of emoji to equivalent words. The mapping table allows a text prediction engine to suggest the emoji as substitutes for matching words. The text prediction engine may be arranged to analyse emoji as words within the model and produce probabilities and candidate rankings for predictions which include both words and emoji. User-specific emoji is also learned by monitoring a user's typing action to adjust predictions to the user's specific usage of emoji.
Perticone et al (2015) The lost in simplicity, and the extensive acceptance liking has enjoyed did not carried to the emotion version are gained in depth. We outline a sentiment-expression hybrid system according to linguistic fuzzy and textual analysis. Markov chains overcome the intrinsic limits of liking without loading the user with composite options.
Howells &Ertugan (2017) have proposed a model for emotion analysis of social media network information. The amount of information freely accessible from social networking increases on an hourly basis. A large amount of the information concerns customer insights and vision of organizations, and as such is of interest to business intelligence gatherers in marketing, customer retention and for customer relationship management. With the use of soft computing, particularly fuzzy logic, it will be likely to create, design, and build social bots which can investigate customer comments in social media networks. Additional programming would permit these social bots to interact with customers, and cautiously created social bots would be able to distribute marketing campaigns.
2.4 Classification using Long Short-Term Memory (LSTM)
Wang et al (2015) In addition, words with special functions (such as transition and negation) are illustrious and the differences of words with opposite emotions are exaggerated. A fascinating case study on negation emotion processing shows a promising potential of the architecture dealing with composite emotion phrases. The model is arranged to predict text based emoticons in a new way.
3242 baselines as well as humans solving the same task, signifying
that computational models are capable to capture the underlying semantics of emojis.
Mousa& Schuller (2017) have proposed a novel generative approach in which a separate probability distribution is calculated approximately for each emotion using Language Models (LMs) based on LSTM RNNs. A novel type of LM using a modified version of Bidirectional LSTM (BLSTM) called contextual BLSTM (cBLSTM) is introduced, where the probability of a word is calculated approximately based on its full left and right contexts. The approach is compared with a BLSTM binary classifier. Important enhancements are detected in classifying the IMDB movie review information set.
3. Proposed System Architecture
The proposed model as shown in Figure 1 includes various phases like data collection, pre-processing using Stop Word Removal, Tokenization and Normalization. Features are extracted using Bag of Words (BoW) and Modified Grey Wolf Optimization (MGWO) and Convolutional Neural Networks (CNN) and MGWO. Polarity is computed and classification is done using Fuzzy, Long Short-Term Memory (LSTM) and Fuzzy based Long Short-Term Memory (F-LSTM). Performance is analyzed interms of Accuracy, Precision, Recall, F-Measure and time period.
3.1 Feature Extraction using Bag of Words (BoWs)
The Bag of Words (BoW) algorithm finds its effective use in Information Retrieval (IR) and Natural Language Processing (NLP). The text including sentences is taken as a bag of words, preserving their diversity but excluding their grammar and order of words. It is also finds its application in Computer Vision (CV) (Sivic& Zisserman 2008) for the detailed versions in it. It is widely used in classification of documents where the
rate of word occurrence is taken as the
predominant feature taken for classifier training. It is referred in a linguistic framework in a work on Distributional Structure (Harris1954). BoW is also widely used to generate features. Once the words in the text are added to bags, diverse measures can be taken to describe the text. Out of all the features considered, the commonly seen feature is ‘frequency’ which gives the total number of times a word is found in the document of various dataset pertaining to the related field.
3.2 Feature extraction using Convolution Neural Networks
A Convolution Neural Network (CNN), a Deep Learning (DL) algorithm takes the input and assigns weights to various aspects and differentiates them. CNN involves less pre-processing in contrast to other classification algorithms. CNNs are capable of learning characteristics (Fukushima 2007). The architecture of a CNN is analogous to that of the connectivity pattern of Neurons in the human brain and was inspired by the organization of the visual cortex. Individual neurons respond to stimuli only in a restricted region of the visual field known as the receptive field. CNNs are stimulated by biological processes. The connection between neurons is similar to animal visual cortex. Individual neurons react to stimuli in the receptive field. CNN is used in this paper to extract frequent words and features of emoji seen in the reviews related to
food purchased by customers. The frequent terms may be relative or non-relative. The volume of data may be reduced if only relevant words are focussed on. CNN is capable of dealing with n-grams, combination of 2/3 words. For instance, ‘very good’, ‘not bad’. It deals with dimensionality reduction.
3.3 Modified Grey Wolf Optimization based Convolution Neural Networks
The main shortcoming of Grey Wolf Optimizer (GWO) is the complexity in the distance based path detection. The existing GWO algorithm is modified to reduce the distance of data. The Modified GWO (MGWO) algorithm (Figure 2) is propounded to improve accuracy, convergence speed and time taken by the GWO algorithm. Relevant words are focussed on to reduce the time taken. In the proposed algorithm, encompassing and searching methods are modified. The other portions of the GWO algorithm remain unchanged. The main aim of this variation is to find an optimal path for the wolf in the search space. The MGWO approach is outlined in the following sections. Optimization algorithm was called the optimal system and it was aimed to solve the travelling salesman problem, in which the goal is to find the shortest round-trip to link a series of data. Usually, the diversity of the solution is large at the beginning of a run and decreases with time. The modified version of grey wolf optimization outperforms in tackling search related problems and improves investigation with several benchmark employed mathematical tasks. It shows significant changes in global optimization techniques.
The mutation probability at time ‘t’ is given by,
The mutation rate in a run is modified to endorse speedy convergence to obtain better results during the initial stage and to introduce much diversity for circumventing local optimal challenges encountered in the later stages.
3243
MGWO ALGORITHM
4.
CLASSIFICATION
In this paper, the features are classified using Fuzzy based Long Short-Term Memory (F-LSTM) to yield better accuracy involving less time period.
4.1 Fuzzy Logic
The idea of fuzzy logic, a method of reasoning alike human reasoning was introduced by LotfiZadeh, University of California, Berkeley in 1960s (Zadeh 1965). Fuzzy logic, a form of many-valued logic, has truth values of real numbers ranging from ‘0’ to ‘1’. In case of Boolean logic, the truth values of variables may be either ‘0’ or ‘1’. The values ‘0’ and ‘1’ are considered as extreme cases of truth and various states of truth are considered to be in-between. Fuzzy logic deals with vagueness and heterogeneity. It considers multiple values and deals with values that are close to the actual rather than fixed and precise. Normally, traditional logic take values between true or false, but in fuzzy logic, the variables take a truth value between 0 and 1. Fuzzy logic classifies sentiments by defining membership functions. To be precise, fuzzy logic handles truth partially or with fuzziness, where the truth values may range from ‘completely true’ to ‘completely false’. When linguistic variables are involved, the ‘degrees of truth’ are managed by specific functions (Ahlawat et al 2014). Reviews on products have a greater impact on development of business and making decisions, as collecting reviews from diverse websites involve more time polarity checking demands much efforts. The reviews are to be classified into positive, negative and neutral. Classification and polarity estimation play a vital role in business development. The score is modified by increasing or decreasing by‘1’ based on the comfort capability in the sentence. If the sentence includes the word ‘not’, the sentence is taken as negative and the score is taken as negative. Thus, the polarities of the sentence are seen in the range [-1, 1]. A novel methodology is defined to classify customer reviews using Fuzzy based Long Short-Term Memory (FLSTM) a new neural network based technique toward sentiment analysis.
4.2 Long Short-Term Memory (LSTM)
As a great development of social networking environments with connected platforms through internet, the generation and use of data are increased rapidly or at exponential rate with the feature extraction is performed with the CNN and results are sent to Long Short Term Memory (LSTM). Reviews and comments in the dataset have been analysed and several feature have been extracted using CNN based LSTM algorithm. Deep learning features /classification results have received progressive performance in various application together with emotions and text. The advantage of this method are illustrated by performance analysis of various parameters which is a challenging large scale reviews in twitter database. The LSTM classification techniques are processed the feature selection from the 3*3 convolutional layer with activation function and 2*2 max pooling. The sigmoid function used in the LSTM layer predicts if the text is positive or negative review sentence. The whole idea of the work is to generalize the accuracy rate of classification problem commonly found in text analysis. LSTM mainly focuses word ordering. For instance, ‘only solve’, ‘solve only’. To be precise, the memory
cell helps in sequence classification, enabling the system to handle more number of emotions.
4.3 Fuzzy based Long Short-Term Memory (F-LSTM)
The proposed system includes 2 components, an objective or utility capacity and a lot of conceivable areas. Enhancement refers to the search for an open valued work if the work is fuzzily valued, or hypothetically if the space is fuzzily restricted.
Let,
X - Options
- Set or a fluffy arrangement of X
The goal or utility model is given by a mapping,
f: X1 → L(R)
L(R) - Set or a class of fluffy subsets of open value set ‘R’
The achievable space is depicted by a subset or a fluffy set C ⊂ X
Participation that gives the practicability of ‘x’ is
µC(x)∈[0,1]
The fluffy streamlining problem is usually mentioned as, f(x,r)→max{x∈C(1)}
where,
r - Fresh steady or a fluffy coefficient
From Equation, it is evident that to find ‘x has a place in area C’ to such a degree that f(x,r) becomes familiar like potentially ‘most extreme’.
In this phase, user reviews are categorized using fine-grained classification techniques. The reviews are categorized into very positive, positive, neutral, negative, or very negative. As mentioned earlier in the discussion, SentiWordNet (SWN) score of a feature descriptor is taken as the initial fuzzy score μ(s).
If the descriptor has a former hedge, the revised fuzzy score is computed as,
f(μ(s))=1−(1−μ(s))δ
The value is normalized using min-max normalization to map to the range [0, 1].
ResScore = (f(μ (s)) +1)/2
If 0≤ResScore≤0.25, then ‘C’is termed as ‘Very Negative’
If 0.25<ResScore≤0.5, then ‘C’is ‘Negative’ If 0.5<ResScore≤0.75, then ‘C’ is termed as
‘Positive’
If 0.75<ResScore≤1, then ‘C’ is termed as ‘Very Positive’
Consider for instance, a hotel's review stating ‘The hotel is Amenities’.
The initial sentiment score for the descriptor ‘Amenities’got using SWN is μ(s) = 0.862.
If this descriptor is led by a concentrator linguistic hedge, say for example, ‘Very Amenities’, then the revised fuzzy score is f(μ(s)) = 0.9324.
Likewise, if the descriptor is headed by a dilator linguistic hedge, say, ‘Somewhat Amenities, then the revised score is f(μ(s)) = 0.3876.
3244 Recognize words that deal with user views including
negative words, if any
Compute the polarity and the initial value of feature descriptors depending on the SWN score
Compute the whole sentiment score using fuzzy functions that includes the consequence of linguistic hedges.
From the discussion, it is evident that, the descriptor’s intensity level is attuned based on the linguistic hedges in the review.
5.
RESULTS & DISCUSSION
The Twitter reviews for restaurants are taken. From the data collected, the frequent words are found using Convolutional Neural Networks (CNN) from which the most relevant words are obtained.
The performance of the proposed system is evaluated in terms of Accuracy, Precision, Recall, F-Measure and Time Period. Classification accuracy is the most commonly used measure for determining performance of classifiers. It is the rate of number of correct predictions made by a model over a data set.
(10)
where,
TP - True Positive TN - True Negative FP - False Positive FN - False Negative
Precision is the probability of true positive reviews total positive reviews.
Recall gives the probability of true positive rate.
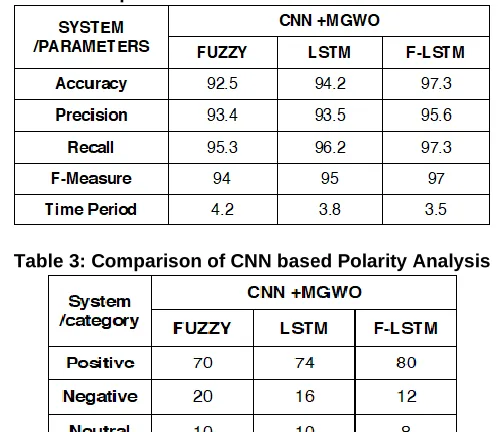
The performance of the proposed system is analysed for the novel scheme involving BoW and MGWO with Fuzzy logic, LSTM and F-LSTM. In addition, the system is improved by applying CNN instead of BoW. It is seen that the system with CNN, MGWO (Modified Grey Wolf Optimization) with F-LSTM yields the best results.
True positive is improved and false positive is reduced by using the review classification. Twitter dataset with customer reviews for hotels are taken for study.
Table 1: Comparison of BOW based Different Classifiers
Table 2: Comparison of CNN based Different Classifiers
Table 3: Comparison of CNN based Polarity Analysis
Table 4: Comparison of BOW based Polarity Analysis
The customers is more related to number of samples in the taken dataset, here we use Twitter dataset and performance analysis has been done with various parameters which eventually shows which one is dominant than other techniques. The results compares between available features selection of Modified Grey wolf Optimization (MGWO) and Bag of Words (BWO).
Table shows the number of Positive, Negative and Neutral reviews observed for the Twitter dataset including hotel reviews. Also it shows the performance of the propounded system with that of other hybrid models.
3245 Figure 1 shows the number of Positive, Negative and Neutral
samples detected by using BoW with MGWO and F-LSTM. The results pretty good says the combination effects and individual performance of various feature selection methods and number of samples which is related to reviewer’s comments in the taken database.
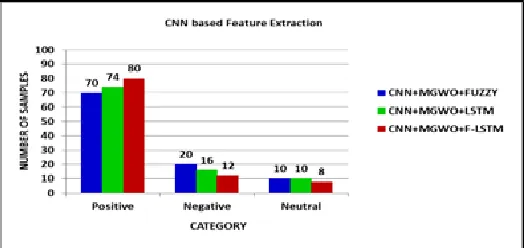
Figure 2: Classification for CNN based Feature Extraction
Figure 2 shows the number of Positive, Negative and Neutral samples detected by using CNN with MGWO and F-LSTM.
Figure 3: Performance for System with BoW based Feature Extraction
Figure 3 shows the performance of the system developed by using BoW with MGWO and F-LSTM.
Figure 4: Performance for System with CNN based Feature Extraction
Figure 4 shows the performance of the system developed by using CNN with MGWO and F-LSTM.
Figure 5: Aspect Level Sentiment Classification
Figure 5 explains Aspect level classification of sentiments deals with identifying sentiment polarity of particular aspects in a sentence. It offers a more fine-grained classification. The aspect attentions representing aspects pertaining to ‘Food’, ‘Room’ and ‘Service’ are shown in the pie chart (Figure 5). The aspect memory computes the semantic understanding between the given term and aspect, and subsequently produces the most correlated representation.
CONCLUSION
Various sentimental analyses have been revised using neural network methods in this paper. The customers can get related information through online reviews. The ratings of the service serve as an excellent use for decision making as they provide quick information of the online review. The sentiment data set used in the work contains a set of product various sentences which were categorised as positive, negative and neutral class, the work goes with deep learning board optimization technique because of the feed forward network that can extract to logical properties of an emoji in a sentence unigrams, bigrams model based word vector representation is used for feature vector, those feature vectors are fed in to CNN and LSTM for learning.
REFERENCES
[1] Ahlawat, N., Gautam, A., & Sharma, N., Use of Logic Gates to Make Edge Avoider Robot, International Journal of Information & Computation Technology, 4(6), pp.630, 2014.
[2] Aswani, R., Ghrera, S. P., Kar, A. K., & Chandra, S., Identifying buzz in social media: a hybrid approach using artificial bee colony and k-nearest neighbors for outlier detection. Social Network Analysis and Mining, 7(1), 38, 2017.
[3] Baccianella, S., Esuli, A., &Sebastiani, F., Sentiwordnet 3.0: an enhanced lexical resource for sentiment analysis and opinion mining, In Lrec, 10(2010), pp. 2200-2204, 2010.
[4] Barbieri, F., Ballesteros, M., &Saggion, H., Are emojis predictable?.arXiv preprint arXiv:1702.07285, 2017. [5] Esuli, A., &Sebastiani, F., Sentiwordnet: A publicly
available lexical resource for opinion mining, In LREC, 6, pp. 417-422, 2006.
3246 [7] Grieves, J. A., Almog, I., Badger, E. N., Cook, J. H., &
Fierro, M. G., U.S. Patent Application No. 14/045,461, 2015.
[8] Hochreiter, S., &Schmidhuber, J., Long short-term memory, Neural computation, 9(8), 1735-1780, 1997. [9] Howells, K., &Ertugan, A., Applying fuzzy logic for
sentiment analysis of social media network information in marketing. Procedia computer science, 120, 664-670, 2017.
[10] Jianqiang, Z., Xiaolin, G., &Xuejun, Z., Deep convolutional neural networks for twitter sentiment analysis. IEEE Access, 6, 23253-23260, 2018.
[11] Kumar, A., & Jaiswal, A., Swarm intelligence based optimal feature selection for enhanced predictive sentiment accuracy on twitter. Multimedia Tools and Applications, 1-25, 2019.
[12] Mousa, A., & Schuller, B., Contextual bidirectional long short-term memory recurrent neural network language models: A generative approach to sentiment analysis. In Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics: Volume 1, Long Papers, pp. 1023-1032, 2017.
[13] Sivic, J., & Zisserman, A., Efficient visual search of videos cast as text retrieval. IEEE transactions on pattern analysis and machine intelligence, 31(4), 591-606, 2008. [14] Zadeh, L.A., Fuzzy sets, Information and contro’, 8(3),
pp. 338-353, 1965.