MORPHOLOGY BASED PROTOTYPE
STATISTICAL MACHINE TRANSLATION SYSTEM
FOR ENGLISH TO TAMIL LANGUAGE
A Thesis
Submitted for the Degree of Doctor of Philosophy in the School of Engineering
by
ANAND KUMAR M
CENTER FOR EXCELLENCE IN COMPUTATIONAL ENGINEERING AND NETWORKING
AMRITA SCHOOL OF ENGINEERING
AMRITA VISHWA VIDYAPEETHAM
COIMBATORE-641 112, TAMILNADU, INDIA
AMRITA SCHOOL OF ENGINEERING
AMRITA VISHWA VIDYAPEETHAM, COIMBATORE-641 112
BONAFIDE CERTIFICATE
This is to certify that the thesis entitled
“
MORPHOLOGY BASED PROTOTYPE STATISTICAL MACHINE TRANSLATION SYSTEM FOR ENGLISH TO TAMIL LANGUAGE” submitted by Mr. ANAND KUMAR M, Reg. No. CB.EN.D*CEN08002 for the award of the Degree of Doctor of Philosophy in theSchool of Engineering is a bonafide record of the work carried out by him under my guidance and supervision at Amrita School of Engineering, Coimbatore.
Thesis Advisor
Dr. K.P.SOMAN
Professor and Head,
AMRITA SCHOOL OF ENGINEERING
AMRITA VISHWA VIDYAPEETHAM, COIMBATORE 641 112
CENTER FOR EXCELLENCE IN COMPUTATIONAL ENGINEERING AND NETWORKING
DECLARATION
I, ANAND KUMAR M (Reg. No. CB.EN.D*CEN08002) hereby declare that this thesis entitled “
MORPHOLOGY BASED PROTOTYPE STATISTICAL
MACHINE TRANSLATION SYSTEM FOR ENGLISH TO TAMIL
LANGUAGE
” is the record of the original work done by me under the guidance ofDr. K.P. SOMAN, Professor and Head, Center for Excellence in Computational Engineering and Networking, Amrita School of Engineering, Coimbatore and to the best of my knowledge this work has not formed the basis for the award of any degree/diploma/associateship/fellowship or a similar award, to any candidate in any University.
Place: Coimbatore
Signature of the Student Date:
COUNTERSIGNED
Thesis Advisor
Dr. K.P.SOMAN
Professor and Head
iv
TABLE OF CONTENTS
ACKNOWLEDGEMENT ... xii
LIST OF FIGURES ... xv
LIST OFTABLES ... xviii
ABBREVIATIONS ... xxi
ABSTRACT ... xxiv
1 INTRODUCTION ... 1
1.1 GENERAL ... 1
1.2 OVERVIEW OF MACHINE TRANSLATION ... 2
1.3 ROLE OF MACHINE TRANSLATION IN NLP ... 3
1.4 FEATURES OF STATISTICAL MACHINE TRANSLATION SYSTEM ... 4
1.5 MOTIVATION OF THE THESIS ... 6
1.6 OBJECTIVE OF THE THESIS ... 7
1.7 RESEARCH METHODOLOGY ... 9
1.7.1 Overall System Architecture ... 9
1.7.2 Details of Preprocessing English Language Sentence ... 10
1.7.2.1 Reordering English Language Sentence ... 10
1.7.2.2 Factorization of English Language Sentence ... 11
1.7.2.3 Compounding of English Language Sentence ... 11
1.7.3 Details of Preprocessing Tamil Language Sentence ... 12
1.7.3.1 Tamil Part-of-Speech Tagger ... 13
1.7.3.2 Tamil Morphological Analyzer ... 13
1.7.4 Factored SMT System for English to Tamil Language ... 14
1.7.5 Postprocessing for English to Tamil SMT ... 15
1.7.5.1 Tamil Morphological Generator ... 15
1.8 RESEARCH CONTRIBUTIONS ... 16
1.9 ORGANISATION OF THE THESIS ... 17
2 LITERATURE SURVEY ... 19
v
2.1.1 Part Of Speech Tagger for Indian Languages ... 21
2.1.2 Part Of Speech Tagger for Tamil Language ... 23
2.2 MORPHOLOGICAL ANALYZER AND GENERATOR ... 25
2.2.1 Morphological Analyzer and Generator for Indian Languages ... 26
2.2.2 Morphological Analyzer and Generator for Tamil Language ... 26
2.3 MACHINE TRANSLATION SYSTEMS ... 30
2.3.1 Machine Translation Systems for Indian Languages ... 30
2.3.2 Machine Translation Systems for Tamil Language ... 35
2.4 ADDING LINGUISTIC INFORMATION FOR SMT SYSTEM ... 38
2.5 RELATED NLP WORKS IN TAMIL ... 43
2.6 SUMMARY ... 46 3 THEORITICAL BACKGROUND ... 47 3.1 GENERAL ... 47 3.1.1 Tamil Language ... 47 3.1.2 Tamil Grammar ... 48 3.1.3 Tamil Characters ... 49
3.1.4 Morphological Richness of Tamil Language ... 50
3.1.5 Challenges in Tamil NLP ... 51
3.1.5.1 Ambiguity in Morpheme ... 51
3.1.5.2 Ambiguity in Word Class ... 52
3.1.5.3 Ambiguity in Word Sense ... 52
3.1.5.4 Ambiguity in Sentence ... 53
3.2 MORPHOLOGY ... 53
3.2.1 Types of Morphology ... 53
3.2.2 Lexemes ... 54
3.2.3 Lemma and Stems ... 54
3.2.4 Inflections and Word forms ... 55
3.2.5 Morphemes and Types ... 55
3.2.6 Allomorphs ... 56
3.2.7 Morpho-Phonemics ... 56
3.2.8 Morphotactics ... 57
vi
3.3.1 Machine Learning ... 58
3.3.2 Support Vector Machines ... 59
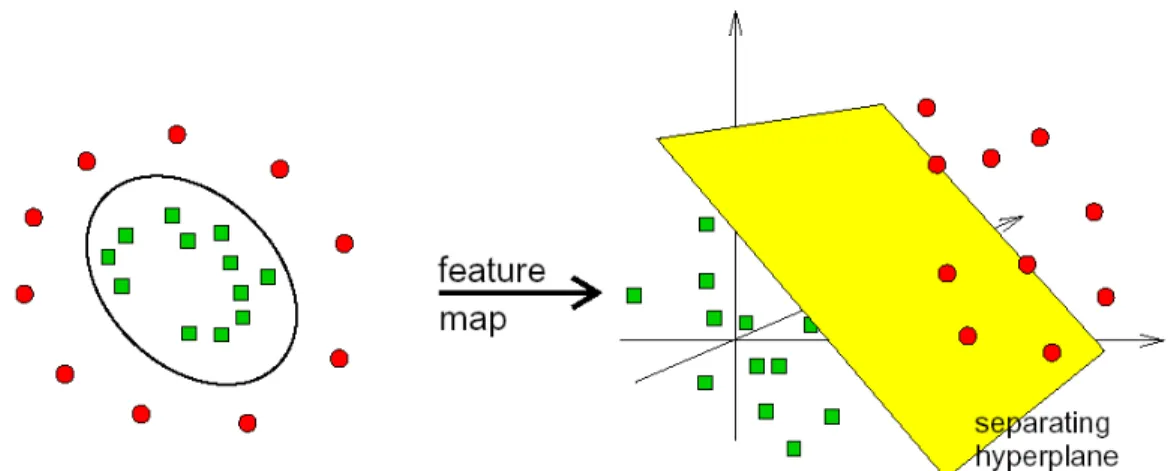
3.3.3 Geometrical Interpretation of SVM ... 61
3.3.4 SVM Formulation ... 64
3.4 VARIOUS APPROACHES FOR POS TAGGING ... 67
3.4.1 Supervised POS Tagging ... 67
3.4.2 Unsupervised POS Tagging ... 68
3.4.3 Rule based POS Tagging ... 68
3.4.4 Stochastic POS Tagging ... 69
3.4.5 Other Techniques ... 69
3.5 VARIOUS APPROACHES FOR MORPHOLOGICAL ANALYZER ... 70
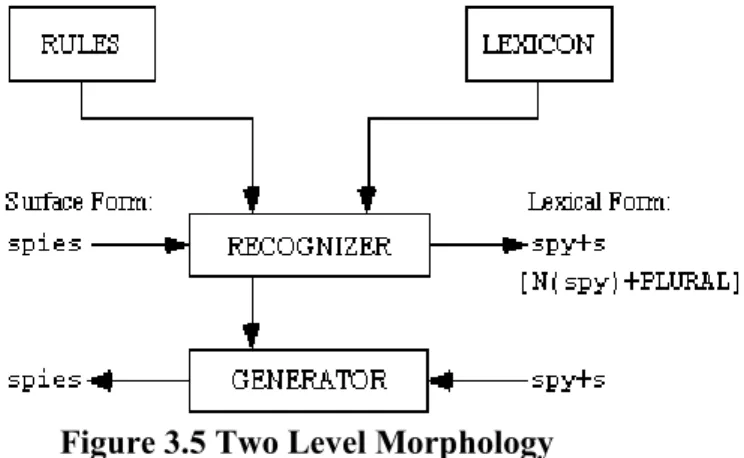
3.5.1 Two level Morphological Analysis ... 70
3.5.2 Unsupervised Morphological Analyser ... 71
3.5.3 Memory based Morphological Analysis ... 72
3.5.4 Stemmer based Approach ... 72
3.5.5 Suffix Stripping based Approach ... 72
3.6 VARIOUS APPROACHES IN MACHINE TRANSLATION ... 73
3.6.1 Linguistic or Rule based Approaches ... 73
3.6.1.1 Direct Approach ... 74
3.6.1.2 Interlingua Approach ... 76
3.6.1.3 Transfer Approach ... 77
3.6.2 Non Linguistic Approaches ... 79
3.6.2.1 Dictionary based Approach ... 79
3.6.2.2 Empirical or Corpus based Approach ... 79
3.6.2.3 Example based Approach ... 80
3.6.2.4 Statistical Approach ... 81
3.6.3 Hybrid Machine Translation System ... 82
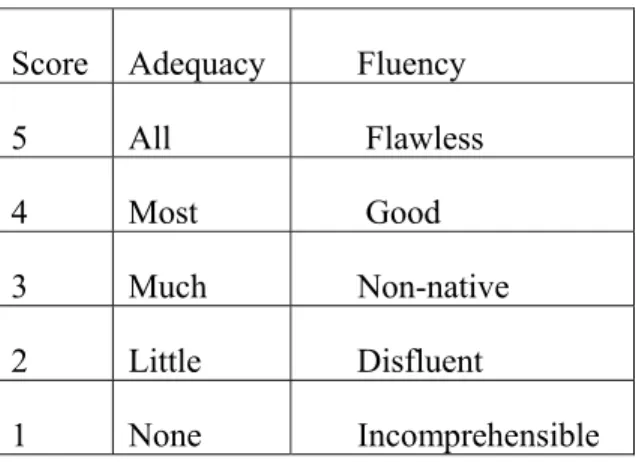
3.7 EVALUATING STATISTICAL MACHINE TRANSLATION ... 83
3.7.1 Human Evaluation Techniques ... 84
3.7.2 Automatic Evaluation Techniques ... 85
3.7.2.1 BLEU Score ... 85
3.7.2.2 NIST Metric ... 86
vii
3.7.2.4 Edit Distance Measures ... 88
3.8 SUMMARY ... 89
4 PREPROCESSING FOR ENGLISH LANGUAGE ... 90
4.1 MORPHO-SYNTACTIC INFORMATION OF ENGLISH LANGUAGE .. 90
4.1.1 POS and Lemma and Information ... 91
4.1.2 Syntactic Information ... 92
4.1.3 Dependency Information ... 93
4.2 DETAILS OF PREPROCESSING ENGLISH SENTENCES ... 94
4.2.1 Reordering English Sentences ... 96
4.2.1.1 Syntactic Comparision between English and Tamil ... 97
4.2.1.2 Reordering Methodology ... 98
4.2.2 Factoring English Sentence ... 102
4.2.3 Compounding English Language Sentence ... 105
4.2.3.1 Morphological Comparision between English and Tamil106 4.2.3.2 Compounding Methodology for English Sentence ... 109
4.2.4 Integrating Reordering and Compounding ... 113
4.3 SUMMARY ... 115
5 PART OF SPEECH TAGGER FOR TAMIL LANGUAGE ... 117
5.1 GENERAL ... 117
5.1.1 Part of Speech Tagging ... 117
5.1.2 Tamil POS Tagging ... 120
5.2 COMPLEXITY IN TAMIL POS TAGGING ... 122
5.2.1 Root Ambiguity ... 122
5.2.2 Noun Complexity ... 122
5.2.3 Verb Complexity ... 123
5.2.4 Adverb Complexity ... 125
5.2.5 Postposition Complexity ... 126
5.3 PART OF SPEECH TAGSET DEVELOPMENT ... 126
5.3.1 Available POS Tagsets for Tamil ... 127
5.3.2 AMRITA POS Tagset ... 128 5.4 DEVELOPMENT OF TAMIL POS CORPORA FOR PREPROCESSING129
viii
5.4.1 Untagged and Tagged Corpus ... 130
5.4.2 Available Corpus for Tamil ... 131
5.4.3 POS Tagged Corpus Development ... 131
5.4.4 Applications of Tagged Corpus ... 134
5.4.5 Details of POS Tagged corpus developed ... 134
5.5 DEVELOPMENT OF POS TAGGER USING SVMTOOL ... 136
5.5.1 SVMTool ... 136 5.5.2 Features of SVMTool ... 137 5.5.3 Components of SVMTool ... 138 5.5.3.1 SVMTlearn ... 138 5.5.3.2 SVMTagger ... 146 5.5.3.3 SVMTeval ... 151
5.6 RESULTS AND COMPARISON WITH OTHER TOOLS... 160
5.7 ERROR ANALYSIS ... 161
5.8 SUMMARY ... 162
6 MORPHOLOGICAL ANALYZER FOR TAMIL ... 163
6.1 GENERAL ... 163
6.1.1 Morphology in Language ... 163
6.1.2 Computational Morphology ... 163
6.1.3 Morphological Analyzer ... 164
6.1.4 Role of Morphological Analyzer in NLP ... 165
6.2 TAMIL MORPHOLOGY ... 166
6.2.1 Tamil Morphology and Language ... 166
6.2.2 Syntax of Tamil Morphology ... 167
6.2.3 Word Formation Rules(WFR) in Tamil ... 168
6.2.4 Tamil Verb Morphology ... 171
6.2.5 Tamil Noun Morphology ... 172
6.2.6 Tamil Morphological Analyzer ... 175
6.2.7 Challenges in Tamil Morphological Analzer ... 175
6.3 TAMIL MORPHOLOGICAL ANALYZER SYSTEM ... 176
6.4 TAMIL MORPHOLOGICAL ANALYZER FOR NOUNS AND VERBS 177 6.4.1 Morphological Analyzer using Machine Learning ... 177
ix
6.4.2 Novel Data Modeling for Noun/Verb Morphological Analyzer .... 179
6.4.2.1 Paradigm Classification ... 179
6.4.2.2 Word forms ... 180
6.4.2.3 Morphemes ... 183
6.4.2.4 Data Creation for Noun/Verb Morphological Analyzer.. 186
6.4.2.5 Issues in Data Creation ... 188
6.4.3 Morphological Tagging Framework using SVMTool ... 189
6.4.3.1 Support Vector Machine (SVM) ... 189
6.4.3.2 SVMTool ... 189
6.4.3.3 Implementation of Morphological Analyzer System ... 190
6.5 MORPH ANALYZER FOR PRONOUN USING PATTERNS ... 192
6.6 MORPH ANALYZER FOR PROPER NOUN USING SUFFIXES... 194
6.7 RESULTS AND EVALUATION ... 195
6.8 PREPROCESSED ENGLISH AND TAMIL SENTENCE... 198
6.9 SUMMARY ... 198
7 FACTORED SMT SYSTEM FOR ENGLISH TO TAMIL ... 200
7.1 STATISTICAL MACHINE TRANSLATION ... 200
7.2 COMPONENTS OF SMT ... 201
7.2.1 Translation Model ... 202
7.2.1.1 Expectation Maximization ... 202
7.2.1.2 Word based Translation Model ... 203
7.2.1.3 Phrase based Translation Model ... 204
7.2.2 Language Model ... 206
7.2.2.1 N-gram Language Models ... 208
7.2.3 Statistical Machine Translation Decoder ... 210
7.3 INTEGRATING LINGUISTIC INFORMATION IN SMT ... 210
7.3.1 Factored Translation Models ... 210
7.3.1.1 Decomposition of Factored Translation ... 212
7.3.2 Syntax based Translation Models ... 212
7.4 TOOLS USED IN SMT SYSTEM ... 213
7.4.1 MOSES ... 213
x
7.4.3 SRILM ... 214
7.5 DEVELOPMENT OF FACTORED CORPORA ... 215
7.5.1 Parallel Corpora Collection ... 215
7.5.2 Monolingual Corpora Collection ... 216
7.5.3 Automatic Creation of Factored Corpora ... 216
7.6 FACTORED SMT FOR ENGLISH TO TAMIL LANGUAGE ... 217
7.6.1 Building Language Model ... 218
7.6.2 Building Phrase based Translation Model... 219
7.7 SUMMARY ... 221
8 POSTPROCESSING FOR ENGLISH TO TAMIL SMT ... 222
8.1 GENERAL ... 222
8.2 MORPHOLOGICAL GENERATOR ... 223
8.2.1 Challenges in Tamil Morphological Generator ... 223
8.2.2 Simplified Part-of-Speech Catagories ... 225
8.3 MORPHOLOGICAL GENERATOR FOR TAMIL NOUN AND VERB . 226 8.3.1 Algorithm for Noun and Verb Morphological Generator ... 227
8.3.2 Word-forms Handled in Morphological Generator ... 229
8.3.3 Data Required for the Algorithm ... 230
8.3.3.1 Morpho Lexical Information File ... 230
8.3.3.2 Paradigm Classification Rules ... 232
8.3.3.3 Suffix Table ... 234
8.3.3.4 Stemming Rules ... 235
8.4 MORPHOLOGICAL GENERATOR FOR TAMIL PRONOUNS... 236
8.5 SUMMARY ... 238
9 EXPERIMENTS AND RESULTS ... 240
9.1 GENERAL ... 240
9.2 EXPERIMENTAL SETUP AND RESULTS ... 240
9.3 SUMMARY ... 245
10 CONCLUSION AND FUTUREWORK ... 246
xi
10.2 SUMMARY OF WORK DONE ... 247
10.3 CONCLUSIONS ... 249
10.4 FUTURE DIRECTIONS ... 250
APPENDIX-A ... 252
A.1 TAMIL TRANSLITERATION ... 252
A.2 DETAILS OF AMRITA POS TAGS ... 256
APPENDIX-B ... 264
B.1 PENN TREE BANK POS TAGS ... 264
B.2 DEPENDENCY TAGS ... 265
B.3 TAMIL VERB MLI ... 266
B.4 TAMIL NOUN WORD FORM ... 272
B.5 TAMIL VERB WORD FORM ... 275
B.6 MOSES INSTALLATION AND TRAINING ... 280
B.7 COMPARISION WITH GOOGLE OUTPUT ... 285
B.8 GRAPHICAL USER INTERFACES... 286
REFERENCES ... 290
xii
ACKNOWLEDGEMENT
I would never have been able to finish my dissertation without the guidance, support and encouragement of numerous people including my mentors, my friends, colleagues and support from my family and wife. At the end of my thesis I would like to thank all those people who made this thesis possible and an unforgettable experience for me.
First and foremost, I feel deeply indebted to Her Holiness Most Revered Mata Amritanandamayi Devi (Amma) for her inspiration and guidance throughout of my doctoral studies, both in unseen and unconcealed ways.
Wholeheartedly, I thank our respected Pro Chancellor, Swami Abhayamrita Chaitanya, by providing the necessary environment, infrastructure and encouragement for my research in Amrita Vishwa Vidyapeetham University. I thank Dr. P. Venkat Rangan, our respected Vice Chancellor, for his full hearted encouragements and supports throughout my doctoral studies.
I would like to express my sincere gratitude to my supervisor, Dr. K.P Soman, Professor and Head, Centre for Excellence in Computational Engineering and Networking (CEN), for his excellent guidance, patience, and providing an excellent atmosphere for doing research. His wide knowledge and logical way of thinking have been of great source of inspiration for me. I am really so happy and proud to say that I am a student of Dr.K.P.Soman. He has always extended his helping hands in solving research problems. The in-depth discussions, scholarly supervision and constructive suggestions received from him have broadened my knowledge. I strongly believe that without his guidance, the present work could have not reached this stage.
I wish to thank my doctoral committee members Dr.C.S Shunmuga Velayutham and Dr.V.P.Mohandass, for their encouraging words and support throughout this research.
I express my heartfelt gratitude to Dr.N.S.Pandian, Dean, PG Programmes, Amrita Vishwa Vidyapeetham, and Coimbatore, for the continuous support of my Ph.D study and research.
xiii
I wish to thank Dr.S.Rajendran for his supervision, advice, and guidance from the very early stage of this research as well as giving me extraordinary experiences through-out the work.
I express my deepest gratitude to Mrs.V.Dhanalakshmi, Head of the Department-Tamil, SRM University, Chennai. Whatever knowledge I have gained in linguistic is definitely because of her.
I also wish to thank my school teacher Mr. B. Vaithiyanathan M.Sc M.Ed for supporting me from School days. I would like to thank Mr. Arun Sankar K, who as a good friend from my graduate is always willing to help and give his best suggestions.
I express my sincere gratitude to my beloved Director, Dr.K.A.Chinnaraju, and Principal, Dr N.Nagarajan, CIET for giving me all the moral support to complete the thesis successfully. I would like to express my gratitude to my Head of the Department Dr.S.Gunasekaran, who is always inspiring me to complete this thesis work. I would also like to thank Mr.G.Ravi Kumar and Prof. Mrs.Janaki Kumar for their timely support and suggestions. I would like to thank my colleagues at the department of Computer science and engineering, especially Mr. N.Ramkumar, Mr.N.Boopal, Mr.A.Suresh, Mr.M.Yogesh, Mr.C.Prabu, and Mr.B .Saravanan for sharing their enthusiasm and for supporting me from the beginning of my career at CIET.
I wish to express my warm and sincere thanks to Dr. Mrs. M.S Vijaya, HOD (MCA), GRD Krishnamal College for Womenand Dr.M. Sabarimalai Manikandan,
SAMSUNG Electronics, for their kind support and direction which have been of great value in this study.
My sincere thanks also goes to Mr.Sivaprathap, Mr.Rakesh Peter, Mr.Loganathan and Mr.Antony P J, Mr.Ajit, Mr Saravanan, Mr.Kathir, Mr. Senthil, Mr.V Anand Kumar, Mrs. Latha Menon, and Sampath Kumar CEN
department for supporting me in all the ways. I also express my sense of gratitude to my friends Ms.Resmi N.G and Ms.Preeja for their encouragement and guidance. My research would not have been possible without the help of my friends C.Murugesan, S.Ramakrishnan, S.Mohanraj and A.Baladhandapani, I like to thank them for being with me in all circumstances.
xiv
I wish to give a special thank to my friends Mrs. Rekha Kishore, Mr.C. Arun Kumar, Mrs. Padmavathy and Mr.Tirumeni for supporting me in this research.
I would like to thank to my Grandpa Mr.M.Narayanasamy and Mr. A.Peter
who left us too soon. I hope that this work will make them proud.
I would like to thank my uncle Mr.P.M.Palraj and aunt Mrs.P.Rajeswari for their encouragement and motivation during my difficult moments during the long years of my education. I would also like to express deepest gratitude to my Grandma
Mrs.N.Valliyammal and my uncles Mr.N.Natesapandiyan and Mr.N.Pandiyan for supporting me from my school days.
I want to thank my parents Mr. N. Madasamy andMrs. M.Manohari for their kind support, the confidence and the love they have shown to me. You have been my greatest strength and I am blessed to be your son. I would also like to give a special thanks to my beloved brother Mr.M.Vasanthkumar for his support to me in all ways.
I wish to thank my sister Mrs.S.Arthi and her husband Mr.K.Suresh, for supporting me in all the ways. I would like to thank my father-in-law Mr.P.Velusamy,
and mother-in-law Mrs.V. Ponnuthai, without their encouragement and moral support it would have been impossible for me to finish this work.
Finally, I would like to give a special thank to my wife Mrs.Sharmiladevi V. She is always there for cheering me up at difficult times with great patience. Without her love and support it would have been impossible for me to finish this work.
xv
LIST OF FIGURES
Figure 1.1 Morphology based Factored SMT for English to Tamil Language ... 10
Figure 1.2 Reordering of English Language ... 11
Figure 1.3 Mapping English Word Factors to Tamil Word Factors ... 14
Figure 1.4 Thesis Organizations ... 17
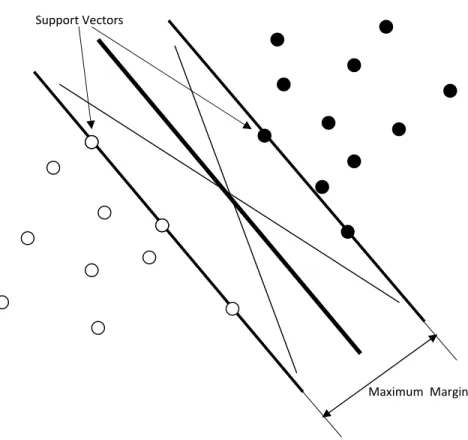
Figure 3.1 Maximum Margin and Support Vectors ... 62
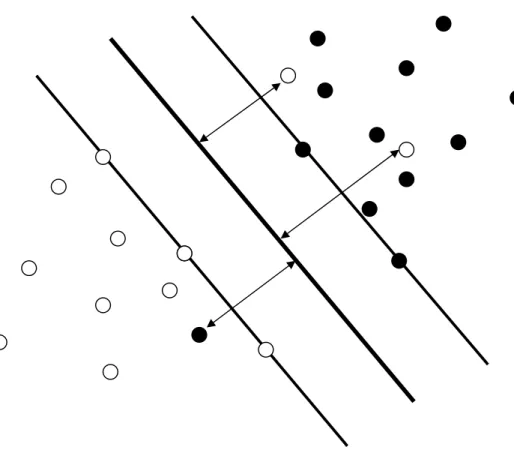
Figure 3.2 Training Errors in Support Vector Machine ... 63
Figure 3.3 Non-linear Classifier ... 64
Figure 3.4 Classification of POS Tagging Models ... 67
Figure 3.5 Two Level Morphology ... 71
Figure 3.6 Block Diagram of Direct Approach to Machine Translation ... 75
Figure.3.7 The Vauquios Triangle ... 77
Figure 3.8 Block Diagram of Transfer Approach ... 78
Figure 3.9 Block Diagram of EBMT System ... 80
Figure 3.10 Block Diagram of SMT System ... 81
Figure 3.11 Rule based Translation System with Post-processing ... 83
Figure 3.12 Statistical Machine Translation System with Pre-processing ... 83
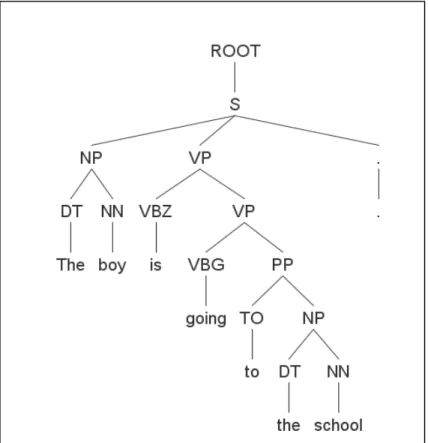
Figure 4.1 Example of English Syntactic Tree ... 92
Figure 4.2 Preprocessing Stages of English Sentence ... 95
Figure 4.3 Process of Reordering ... 99
Figure 4.4 English Syntactic Tree ... 101
Figure 4.5 English to Tamil Alignment ... 110
Figure 4.6 Block Diagram for Compounding ... 111
Figure 4.7 Integration Process ... 114
xvi
Figure 5.2 Example of Tagged Corpus ... 130
Figure 5.3 Untagged Corpus before Pre-editing ... 132
Figure 5.4 Untagged Corpus after Pre-editing ... 133
Figure 5.5 Training Data Format ... 139
Figure 5.6 Implementation of SVMTlearn ... 143
Figure 5.7 Example Input ... 149
Figure 5.8 Example Output ... 149
Figure 5.9 Implementation of SVMTagger ... 150
Figure 5.10 Implementation of SVMTeval ... 152
Figure 6.1 Role of Morphological Analyzer in NLP ... 166
Figure 6.3 General Framework for Morphological Analyzer System ... 176
Figure 6.4 Preprocessing Steps ... 187
Figure 6.5 Implementation of Noun/Verb Morph Analyzer ... 191
Figure 6.6 Structure of Pronoun Word form ... 192
Figure 6.7 Implementation of Pronoun Morph Analyzer ... 193
Figure 6.8 Implementation of Proper Noun Morph Analyzer ... 195
Figure 6.9 Training Data Vs Accuracy ... 196
Figure 7.1 The Noisy Channel Model to Machine Translation ... 201
Figure 7.2 Block Diagram for Factored Translation ... 211
Figure 7.3 Mapping English Factors to Tamil Factors ... 280
Figure 8.1 Tamil Sentence Generation ... 225
Figure 8.2 Algorithm for Morphological Generator ... 227
Figure 8.3 Architecture of Tamil Morphological Generator ... 228
Figure 8.4 Pseudo Code for Paradigm Classification ... 233
Figure 8.5 Structure of Pronoun Word form ... 237
Figure 8.6 Pronoun Morphological Generator ... 238
xvii
Figure 9.1 BLEU-1 Score for Various Models ... 243
Figure 9.2 BLEU-4 Score for Various Models ... 244
Figure 9.3 NIST Score for Various Models ... 244
xviii
LIST OF TABLES
Table 1.1 Factored English Sentences ... 12
Table 1.2 Compounded English Sentences ... 12
Table 3.1 Tamil Grammar ... 48
Table 3.2 Tamil Vowels ... 49
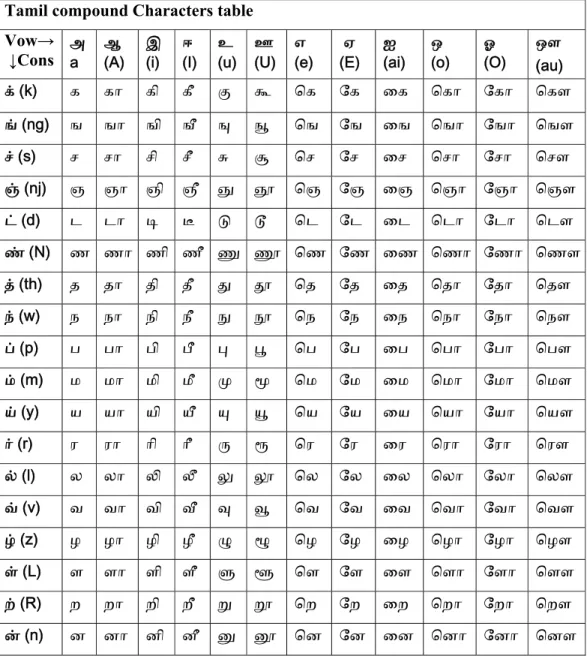
Table 3.3 Tamil Compound Letters ... 50
Table 3.4 Ambiguity in Morpheme’s Position ... 52
Table 3.5 An Example to Illustrate the Direct Approach ... 75
Table 3.6 An Example for Interlingua Representation ... 76
Table 3.7 An Example for Transfer Approach ... 79
Table 3.8 Example of English and Tamil Sentences ... 81
Table 3.9 Scales of Evaluation ... 85
Table 4.1 POS and Lemma of Words ... 91
Table 4.2 Reordering Rules ... 100
Table 4.3 Original and Reordered Sentences ... 102
Table 4.4 Description of Factors in English Word ... 103
Table 4.5 Example of English Word Factors ... 104
Table 4.6 Factored Representation of English Language Sentence ... 104
Table 4.7 Word forms of English ... 106
Table 4.8 Content Words of English ... 107
Table 4.9 Function Words of English ... 107
Table 4.10 English Word Forms based on Tenses ... 108
Table 4.11 Tamil Word Forms based on Tenses ... 109
Table 4.12 Compounding Rules for English Sentence ... 112
Table 4.13 Average Words per Sentence... 113
xix
Table 4.15 Compounded English Sentence ... 113
Table 4.16 Preprocessed English Sentences ... 115
Table 5.1 AMRITA POS Tagset ... 129
Table 5.2 Tag Count ... 134
Table 5.3 Corpus Statistics ... 135
Table 5.4 Example of Suitable POS Features for Model 0 ... 141
Table 5.5 Example of Suitable POS Features for Model 1 ... 141
Table 5.6 Example of Suitable POS Features for Model 2 ... 142
Table 5.7 Comparison of Accuracies ... 161
Table 5.8 Trials and Error ... 162
Table 5.9 Confusion Matrix ... 162
Table 6.1 Compound Word-forms Formation ... 171
Table 6.2 Simple Verb Finite Forms ... 172
Table 6.3 Noun Case Markers ... 173
Table 6.4 Minimized POS Tagset ... 177
Table 6.5 Number of Paradigms and Inflections ... 180
Table 6.6 Noun Paradigms ... 180
Table 6.7 Verb Paradigms ... 181
Table 6.8 Noun Word Forms ... 181
Table 6.9 Verb Word Forms ... 182
Table 6.10 Noun Morphemes ... 183
Table 6.11 Verb Morphemes ... 184
Table 6.12 Verb/Noun Ambiguous Morphemes ... 185
Table 6.13 Sample Data Format ... 187
Table 6.14 Example of Proper Noun Inflections ... 195
Table 6.15 Tagged Vs Untagged Accuracies ... 196
xx
Table 6.17 Sentence Level Accuracies ... 198
Table 6.18 Preprocessed English and Tamil Sentence ... 198
Table 7.1 Factored Parallel Sentences ... 217
Table 8.1 Morpho-phonemic Changes ... 224
Table 8.2 Simplified POS Tagset ... 225
Table 8.3 Verb and Noun Word Forms ... 229
Table 8.4 MLI for Tamil Verb ... 231
Table 8.5 Look up Table for Paradigm Classification ... 233
Table 8.6 Paradigms and inflections ... 234
Table 8.7 Suffix Table ... 235
Table 8.8 Stemming End Characters ... 236
Table 9.1 Details of Baseline Parallel Corpora ... 241
Table 9.2 Details of Factored Parallel Corpora ... 241
Table 9.3 BLEU and NIST Scores ... 243
xxi
LIST OF ABBREVIATIONS
ABBREVIATIONS FULL FORM
1PL First person Plural 1S First person Singular
2PE Second person Plural Epicene 2S Second person Singular
2SE Second person Singular Epicene 3PE Third person Plural Singular 3PN Third person Plural Neutral 3SE Third person Singular Epicene 3SF Third person Singular Feminine 3SM Third person Singular Masculine 3SN Third person Singular Neutral ACC Accusative
AI Artificial Intelligence
AU-KBC Anna University K B Chandrasekhar
BL Base line
BLEU Bi-Lingual Understudy
CALTS Centre for Applied Linguistics and Translation Studies
CIIL Central Institute of Indian Languages CLIR Cross lingual information retrieval
CRF Conditional Random Fields CWF Compressed Word Format
EBMT Example based Machine Translation EM Expectation Maximization
EOS End of Sentences
FSA Finite State Automata
FSM Finite State Machine
FSMT Factored Statistical Machine Translation FST Finite State Transducer
xxii
HMM Hidden Markov Model
IBM International Business Machine
IE Information Extraction
IIIT International Institute of Information Technology
IR Information Retrieval
KWIC Key word in context
LDC Language data Consortium LSV Letter Successor Varieties ManTra MAchiNe assisted TRAnslation MBMA Memory based Morphological Analysis
MEMM Maximum Entropy Markov Models
MG Morphological Generator
MIRA Margin Infused Relaxed Algorithm
ML Machine Learning
MLI Morpho-Lexical Information
MT Machine Translation
NIST National Institute of Standards and Technology
NLI Natural Language Interface NLP Natural Language Processing NLU Natural Language Understanding
PBSMT Phrase based Statistical Machine Translation PCFG Probalistic Context Free Grammar
PER Position Independent Word Error Rate PLIL Pseudo Lingual for Indian Languages
PN Proper Noun
PNG Person-Number-Gender POS Part-of-Speech
POST Part-of-Speech Tagging
QA Question Answering
xxiii
RCILTS Resource Centre for Indian Language Technology Solutions
SMR Statistical Machine Reordering SMT Statistical Machine Translation
SOV Subject-Object-Verb SRILM Stanford Research Institute for Language
Modeling
SVM Support Vector Machine
SVO Subject-Verb-Object TBL Transformation based learning
TDIL Technology Development for Indian Languages
TER Translation Edit Rate
TnT Trigrams n Tagger
UCSG Universal Clause Structure Grammar
UN United Nations
VG Verb Group
WER Word Error Rate
WFR Word Formation Rules
WSJ Wall Street Journal
xxiv
ABSTRACT
Machine translation is about automatic translation of one natural language text to another using computer. In this thesis, morphology based Factored Statistical Machine Translation system (F-SMT) is proposed for translating sentence from English to Tamil. Tamil linguistic tools such as Part-of-Speech Tagger, Morphological Analyzer and Morphological Generator are also developed as a part of this research work. Conventionally, rule-based approaches are employed for developing Machine Translation. It uses transfer-rules between the source language and the target language for producing grammatical translations. The major drawback of this approach is that it always requires the help of a good linguist for the rule improvement. So, recently data-driven approaches such as example-based and statistical based systems are getting more attention from research community. Currently, Statistical Machine Translation (SMT) systems are playing a major role in developing translation between languages. The main advantage of using Statistical Machine Translation system is that it is language independent and it disambiguates the sense automatically with the use of large quantities of parallel corpora. SMT system considers the translation problem as a machine learning problem.
Statistical learning methods perform translation based on large amounts of parallel training data. At first, non-structural information and statistical parameters are derived from the bi-lingual corpora. These statistical parameters are then used for translation. Baseline Statistical Machine Translation system considers only surface forms and does not use linguistic knowledge of the languages. Therefore its performance is better for similar language pair when compared to the dissimilar language pair. Translating English into morphologically rich languages is a challenging task. Because of the highly rich morphological nature of Tamil language, a simple lexical mapping alone does not help for retrieving and mapping all the morphological and syntactic information from the English language sentences.
Tamil word forms are productive, that is, word forms are written without spaces. Inflected forms of Tamil words are seperate words in Tamil. This leads to the problem of sparse data. It is very difficult to collect or create a parallel corpus which contains all the possible Tamil surface words. Because, a single Tamil root verb is
xxv
inflected into more than ten thousand different forms. Moreover, selecting a correct Tamil word or phrase during translation is a challenging job. The corpus size and quality decides the accuracy of the Machine Translation system. The limited availability of parallel corpora for English-Tamil language and high inflectional variation increases the data sparseness problem for baseline phrase-based SMT system. While translating from English to Tamil language, the SMT baseline system will not generate the Tamil word forms that are not present in the training corpora.
The proposed Machine Translation system is based on factored Statistical Machine Translation models. The words are factored into lemma and inflected forms based on their part of speech. This factorization reduces the data sparseness in decoding. Factored translation models allow the integration of the linguistic information into a phrase-based translation model. These linguistic features are treated as separate tokens during the factored training process. Baseline SMT system uses untagged corpora for training, whereas factored SMT uses linguistically factored corpora. Pre-processing phase allows including language specific knowledge into the parallel corpus indirectly. In preprocessing, bi-lingual corpora are converted into factored bi-lingual corpora using linguistic tools and reordering rules. Similarly, Tamil language sentences are also pre-processed using the proposed linguistic tools like POS tagger and Morphological analyzer. These factored corpora are then given to the Statistical Machine Translation models for training. Finally, Tamil morphological generator is used for generating a surface word from output factors.
CHAPTER 1
INTRODUCTION
1.1 GENERAL
Machine Translation is an automatic translation of one natural language text to another using computer. Initial attempts for Machine Translation made in 1950’s didn’t meet with success. Now internet users need a fast automatic translation system between languages. Several approaches like Linguistic based and Interlingua based systems are used to develop a machine translation system. But currently, statistical methods dominate the machine translation field. Statistical Machine Translation (SMT) approach draws knowledge from automata theory, artificial intelligence, data structure and statistics. SMT system treats translation as a machine learning problem. This means that a learning algorithm is applied to a large amount of parallel corpora. Parallel corpora are sentences in one language along with its translation. Learning algorithms create a model from parallel sentences and using this model, unseen sentences are translated. If parallel corpora are available for a language pair then it is easy to build a bilingual SMT system. The accuracy of the system is highly dependent on the quality and quantity of the parallel corpus and the domain. These parallel corpora are constantly growing. Parallel corpora are the fundamental resource for SMT system. Parallel corpora are available from government’s bi-lingual text books, news papers, websites and novels.
SMT models are giving good accuracy for language pairs, particularly for similar languages in specific domains or languages that have large availability of bi-lingual corpora. If a sentence in language pair is not structurally similar, then the translation patterns are difficult to learn. Huge amounts of parallel corpora are required for learning the pattern, therefore statistical methods are difficult to use in “less resourced” languages. To enhance the translation performance of dissimilar language pairs and less resourced languages, an external preprocessing is required. This preprocessing is performed using linguistic tools.
In SMT system, statistical methods are used for mapping of source language phrases into target language phrases. Statistical model parameters are estimated from bi-lingual and mono-lingual corpora. There are two models in the SMT system. They
are Translation model and Language model. The translation model takes parallel sentences and finds the translation hypothesis between the phrases. Language model is based on the statistical properties of n-grams. It uses the monolingual corpora.
Several translation models are available in SMT system. Some important models are phrase based model, syntax based model and factored model. Phrase Based Statistical Machine Translation (PBSMT) is limited to the mapping of small text chunks. Factored translation model is an extension of phrase based models. It integrates linguistic information at the word level. This thesis proposes a pre-processing method
that uses linguistic tools to the development of English to Tamil machine translation system. In this translation system, external linguistic tools are used to augment the linguistic information into the parallel corpora. The pre and post processing methodology proposed in this thesis are applicable to other language pairs too.
1.2
OVERVIEW OF MACHINE TRANSLATION
Machine translation is one of the major oldest and the most active area in natural language processing. The word ‘translation’ refers to transformation of text or speech from one language into other. Machine translation can be defined as, the application of computers to the task of translating texts from one natural language to another. It is a focussed field of research in linguistic concepts of syntax, semantics, pragmatics and discourse.
Today a number of systems are available for producing translations, though they are not perfect. In the process of translation, which is either carried out manually or automated through machines, the context of the text in the source language when translated must convey the exact context in the target language. Translation is not just word level replacement. A translator, either a machine or human, must interpret and analyse all the elements in the text. Also human/machine should be familiar with all the issues during the translation process and must know how to handle it. This requires in-depth knowledge in grammar, sentence structure, meanings, etc and also an understanding in each language’s culture in order to handle idioms and phrases originated from different culture. The cross culture understanding is an important issue that holds the accuracy of the translation.
It will be a great challenge for humans to design automatic machine translation system. It is difficult for translating sentences by taking into consideration all the required information. Humans need several revisions to make the perfect translation. No two individual human translators can generate identical translations of the same text in the same language pair. Hence it will be a greater challenge for humans to design a fully automated machine translation system to produce high quality translations.
1.3
ROLE OF MACHINE TRANSLATION IN NLP
Natural Language Processing (NLP) is the field of computer science devoted to the development of models and technologies enabling computers to use human languages both as input and output [1]. The ultimate goal of NLP is to build computational models that equal human performance in the task of reading, writing, learning, speaking and understanding. Computational models are useful to explore the nature of linguistic communication as well as for enabling effective human-machine interaction. Jurafsky and Martin (2005) [2] describe Natural Language Processing as “computational techniques that process spoken and written human language as language”. According to the Microsoft researchers, the goal of the Natural Language Processing (NLP) is “to design and build software that will analyze, understand and generate languages that humans use naturally, so that eventually one will be able to address their computer like addressing another person”.
Machine Translation is used for translating texts for assimilation purpose which aids bilingual or cross-lingual communication and also for searching, accessing and understanding foreign language information from databases and web-pages [3]. In the field of information retrieval a lot of research is going on in Cross-Language Information Retrieval (CLIR), i.e. information retrieval systems capable of searching databases in many different languages [4].
Construction of robust systems for speech-to-speech translation to facilitate “cross-lingual” oral communication has been the dream of speech and natural language researchers for decades. Machine translation is an important module in speech translation systems. Currently, computer assisted learning plays a major role in academic environment. The use of Machine Translation in language learning has not yet got enough attention because of poor quality of automatic translation output. Using
good automatic translation system, students can improve their translation and writing skills. Such system can break the language barriers of students and language learners.
1.4 FEATURES
OF
STATISTICAL MACHINE TRANSLATION
SYSTEM
Traditionally, rule based approaches are used to develop a machine translation system. Rule based approach feeds the rules into machine using appropriate representations. Feeding all linguistic knowledge into a machine would be very hard. In this context, the statistical approach to Machine Translation has some attractive qualities that made it the preferred approach in machine translation research over the past two decades. Statistical translation models learn translation patterns directly from data, and generalize them to translate a new text. The SMT approach is largely language-independent, i.e. the models can be applied to any language pair.
System based on statistical methods is much better than the traditional rule-based systems. In SMT, implementation and development times are much shorter. SMT can improve by coupling new models for reordering and decoding. It only needs to learn parallel corpora for generating a translation system. In contrast, rule based system needs transfer rules which only linguistic experts can generate. These rules are entirely dependent on language pair involved and defining general “transfer-rules” is not an easy task, especially for languages with different structures [5].
SMT system can be developed rapidly if the appropriate corpus is available. A Rule Based Machine Translation (RBMT) system requires a lot of development and customization costs until it reaches the desired quality threshold. Packaged RBMT systems have been already developed and it is extremely difficult to reprogram models and equivalences. Above all, RBMT has a much longer process involving more human resources. RBMT system is retrained by adding new rules and vocabulary among other things [5].
Statistical Machine Translation works well for translations in a specific domain with the engine trained with bilingual corpus in that domain. A SMT system requires more computing resources in terms of hardware to train the models. Billions of calculations need to take place during the training of the engine and the computing knowledge required for it is highly specialized. However, training time can be reduced
nowadays thanks to the wider availability of more powerful computers. RBMT requires a longer deployment and compilation time by experts so that, in principle, building costs are also higher. SMT generates statistical patterns automatically, including a good learning of exceptions to rules. As regards to the rules governing the transfer of RBMT systems, certainly they can be seen as special cases of statistical standards. Nevertheless, they generalize too much and cannot handle exceptions. Finally SMT systems can be upgraded with syntactic information and even semantics, like the RBMT. A SMT engine can generate improved translations if retrained or adapted again. In contrast, the RBMT generates very similar translations after retraining [5].
SMT systems, in general, have trouble in handling the morphology on the source or the target side especially for morphologically rich languages. Errors in morphology can have severe consequences on meaning of the sentence. They change the grammatical function of words or the interpretation of the sentence through the wrong verb tense. Factored translation models try to solve this issue by explicitly handling morphology on the generation side.
Another advantage of Statistical Machine Translation system is that, it generates a more natural or closer to the literal translation of the input sentence. Symbolic approaches to machine translation take great human effort in language engineering. In knowledge based machine translation, for example, designers must first find out what kinds of linguistic, general common-sense and domain-specific knowledge is important for a task. Then they have to design an Interlingua representation for the knowledge and write grammars to parse input sentences. Output sentences are generated using the Interlingua representation. All of these require expertise in language technologies and it requires tedious and laborious work.
The major advantage of Statistical Machine Translation system is its learnability. As long as a model is set up, it can learn automatically with well-studied algorithms for parameter estimation. Therefore parallel corpus replaces the human expertise for the task. The coverage of grammar is also one of the serious problems in rule based system. Statistical Machine Translation system is a good candidate that meets these criteria. It can learn to have a good coverage as long as the training data is representative enough. It can statistically model the noise in spoken language, so it does not have to make a binary keep/abandon decision and is therefore more robust to noisy data [5].
1.5 MOTIVATION
OF
THE
THESIS
Machine translation (MT) is the application of computers to the task of translating texts from one natural language to another. Even though machine translation was envisioned as a computer application in the 1950’s, machine translation is still considered to be an open problem [3].
The demand for machine translation is growing rapidly. As multilingualism is considered to be a part of democracy, the European Union funds EuroMatrixPlus [6], a project to build machine translation system for all European language pairs, to automatically translate the documents to its 23 official languages, which were being translated manually. Also as the United Nations (UN) is translating a large number of documents into several languages, the UN has created bilingual corpora for some language pairs like Chinese–English, Arabic–English which are among the largest bilingual corpora distributed through the Linguistic Data Consortium (LDC). In the World Wide Web, as around 20% of web pages and other resources are available in their national languages. Machine Translation can be used to translate these web pages and resources to the required language in order to understand the content in those pages and resources, thereby decreasing the effect of language as a barrier of communication [7].
In a linguistically diverse country like India, machine translation is a very essential technology. Human translation is widely prevalent in India since ancient times which are evident from the various works of philosophy, arts, mythology, religion and science which have been translated among ancient to modern Indian languages. Also, numerous classic works of art, ancient, medieval and modern, have also been translated between European and Indian languages since the 18th century. As of now, human translation in India finds application mainly in the administration, media and education and to a lesser extent in business, arts and science and technology [8].
India has 18 constitutional languages, which are written in 10 different scripts. Hindi is the official language of the India. English is the language which is most widely used in the media, commerce, science and technology and education. Many of the states have their own regional language, which is either Hindi or one of the other constitutional languages.
In such a situation, there is a big market for translation between English and the various Indian languages. Currently, the translation is done manually. Use of automation is largely restricted to word processing. Two specific examples of high volume manual translation are translation of news from English into local languages, translation of annual reports of government departments and public sector units among English, Hindi and the local language. Many resources such as news, weather reports, books, etc., in English are being manually translated to Indian languages. Of these, News and weather reports from all around the world are translated from English to Indian languages by human translators more often. Human translation is slow and also consumes more time and cost compared to machine translation. It is clear from this that there is large market available for machine translation rather than human translation from English into Indian languages. The reason for choosing automatic machine translation rather than human translation is that machine translation is faster and cheaper than human translation.
Tamil, a Dravidian language, is spoken by around 72 million people and has the official status in the state of Tamilnadu and Indian union territory of Puducherry. Tamil is also an official language of Sri Lanka and Singapore. Tamil is also spoken by significant minorities in Malaysia and Mauritius as well as emigrant communities around the world. It is one of the 22 scheduled languages of India and declared a classical language by the government of India in 2004 [9].
In this thesis a methodology for English to Tamil Statistical Machine Translation is proposed, along with a pre-processing technique. This pre-processing method is used to handle morphological variance between English and Tamil. Linguistic tools are developed to generate linguistically motivated data for the factored translation model for English-Tamil.
1.6
OBJECTIVE OF THE THESIS
The main aim of this research is to develop a morphology based prototype Statistical Machine Translation system for English to Tamil language by integrating different linguistic tools. This research will also address the issue of how the morphologically correct sentence is generated when translating from a morphologically simple language into a morphologically rich language. The objective of the research is detailed as follows:
• Develop a pre-processing module (Reordering, Compounding and Factorization) for English language sentence to transform the structure to more similar to that of Tamil.
The pre-processing module for source language includes three stages, which are reordering, factorization and compounding. In reordering stage, the source language sentence is to be syntactically reordered according to the Tamil language syntax. After reordering, the English words will be factored into lemma and other morphological features. It will be followed by the compounding process, in which the various function words are removed from the reordered sentence and attached as a morphological factor to the corresponding content word.
• Develop a Tamil Part-of-Speech (POS) tagger to label the Tamil words in a sentence.
Tamil POS tagger is going to develop using Support Vector Machine (SVM) based machine learning tool. POS annotated corpus will be created for training the automatic tagger system.
• Develop a Morphological Analyser to segment the Tamil surface word into linguistic factors.
Morphological analyzer system is to be developed using machine learning approach. POS tagger and morphological analyser tools are to be used for pre-processing the Tamil language sentence. Linguistic information from the tools is to be incorporated to the surface words before SMT training.
• Build a Morphology based prototype Factored Statistical Machine Translation (F-SMT) system for English to Tamil.
After pre-processing, the bi-lingual sentences are to be created and transformed as factored bi-lingual sentences. Monolingual corpora for Tamil are collected and factored using Tamil POS tagger and morphological analyser. These sentences will be used for training the factored Statistical machine translation model.
• Develop a Tamil Morphological Generator system to generate Tamil surface word form.
Morphological generator transforms the translation output into grammatically correct target language sentence. Morphological generator is used in post processing module for English to Tamil machine translation system.
1.7 RESEARCH
METHODOLOGY
1.7.1 Overall System Architecture
Tamil is a morphologically rich language with free word-order of Subject-Object-Verb (SOV) pattern. English language is morphologically simple with a fixed word order of Subject-Verb-Object (SVO) pattern. The baseline SMT system would not perform well for the languages with different word order and disparate morphological structure. For resolving this, factored models are introduced in SMT system. The factored model, which is a subtype of SMT system, will allow multiple levels of representation of the word-from the most specific level to more general levels of analysis such as lemma, part-of-speech and morphological features [10]. Figure 1.1 shows the overall architecture of the proposed English to Tamil SMT system. The preprocessing module is externally attached to the factored SMT system. This module converts bilingual corpora into factored bi-lingual corpora using morphology based linguistic tools and reordering rules. After preprocessing, the representations of source language sentence syntax closely follow the sentence structure of target language. This transformation decreases the complexity in alignment, which is also one of the key problems in baseline SMT system.
Parallel corpora are used to train the statistical translation models. Parallel corpora are created and converted into factored parallel corpora using preprocessing. English sentences are factored using Stanford Parser tool and Tamil sentences are factored using Tamil POS Tagger and Morphological analyzer. Monolingual corpus is collected from various news papers and factored using Tamil linguistic tools. This mono-lingual corpus is used in language model. Finally, in post-processing, Tamil morphological generator is used for generating a surface word from output factors.
1.7
Ma nee be tran lan 1.7 wo pro lan Ob the bet Sta Figure7.2
Detail
achine Trans eds appropri performed nslating into nguage sente 7.2.1 Reorde Reordering ord order thaocess for lan nguage pair bject (SVO) e main verb tween subje anford Parse 1.1 Morpho
ls of Pre-p
slation syste iate pre-proc on the raw o target lan nce consists ering Englis g means, rea at is closer nguages wh has dispara whereas Tam of a Tamil ct and obje er tool. Base ology basedprocessing
em for langu cessing or mo source lang nguage sent s of reorderin sh Languag arrange the to that of t hich differs te syntactic mil word or sentence al ect [11]. En d on reorder d Factored SEnglish L
uage pair wi odeling befo guage senten tence. The ng, factoriza e Sentence word order the target la in their syn structure. E rder is Subje lways comes nglish syntac ring rules so SMT for EnLanguage
ith disparate ore translatio nce to make pre-process ation and comof source l anguage sen ntactic struc English wor ect-Object-V s at the end ctic relation ource langua nglish to Tam
Sentence
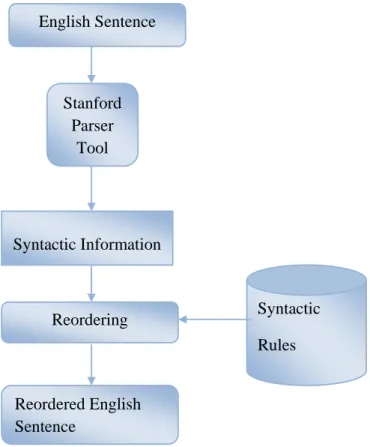
e morpholog on. The prep e it more ap ing module mpounding. language se ntence. It is cture. Englis rd order is S Verb (SOV). d but in Eng ns are retriev age sentence mil languag gical structur processing ca ppropriate fo e for Englis ntence into an importan sh and Tam Subject-Verb For exampl glish it come ved from th e is reordere ge re an for sh a nt mil b-le, es he d.Reordering rules are handcrafted using the syntactic word order difference between English and Tamil language. 180 reordering rules are created based on the sentence structure of English and Tamil. Reordering significantly improves the performance of the Machine Translation system. Lexicalized distortion reordering model is implemented in Moses toolkit [180]. But this automatic reordering in Moses toolkit is good for short range sentences. Therefore external tool or component is needed for dealing the long distance reordering. This reordering is also a one way of indirectly integrating syntactic information to the source language. 80% of English sentences are reordered correctly according to the rules which are developed. Example for English reordering is given in the Figure 1.2.
English Sentence: I bought vegetables to my home.
Reordered English: I my to home vegetables bought
Tamil Sentence : நான் என் ைடய ட் ற்கு காய்கறிகள் வாங்கிேனன் . Figure 1.2 Reordering of English language
1.7.2.2 Factorization of English Language Sentence
Factored models can be used for morphologically rich languages, in order to reduce the amount of bi-lingual data. Factorization refers splitting the word into linguistic factors and integrates as a vector. Stanford Parser is used to parse the English sentences. From the parsed tree, the linguistic information such as lemma, part-of-speech tags, syntactic information and dependency information are retrieved. This linguistic information is integrated as factors in the original word.
1.7.2.3 Compounding for English language sentence
Compounding is defined as adding additional morphological information to morphological factor of source (English) language words [188]. Additional morphological information includes function word, subject information, dependency relations, auxiliary verbs and model verbs. This information is based on the
morphological structure of Tamil language sentence. In compounding phase, the function words are identified from the English factored corpora using dependency information. After finding the function words, these are removed from the factored sentence and attached as a morphological factor to the corresponding content word. Compounding process reduces the length of the English sentence. Like function words, auxiliary verbs and model verbs are also removed and attached as a morphological factor of source language word. Now the morphological representation of the English language sentence is similar to that of the Tamil language sentence. This compounding step indirectly integrates dependency information into the source language factor. Table 1.1 and Table 1.2 show the factored and compounded sentences respectively.
Table 1.1 Factored English Sentences
Table 1.2 Compounded English Sentences
1.7.3
Details of Pre-processing for Tamil Language Sentence
Like preprocessing of English sentence, Tamil sentence is also pre-processed using linguistic tools such as Parts-of-Speech (POS) Tagger and morphological analyzer. Tamil surface words are segmented into linguistic information and this information is integrated as factors in SMT training corpora. Tamil sentence is given to Part-of-Speech Tagger tool and then using this of-speech information, the simplified part-of-speech tag is identified. Based on this simplified tag, the word is given to the Tamil
I | i | PN | prn my | my | PN | PRP$ home | home | N | NN to | to | TO | TO vegetables | vegetable | N | NNS bought | buy | V | VBD . I | i | PN | prn_i my | my | PN | PRP$ home | home | N |NN_to vegetables | vegetable | N | NNS bought | buy | V | VBD_1S.
morphological analyzer. Morphological analyzer split the word to lemma and morphological information. Parallel corpora as well as the monolingual corpora are preprocessed in this stage.
1.7.3.1 Tamil Part-of-Speech Tagger
POS tagging means labeling grammatical classes i.e. assigning parts of speech tags to each and every word of the given sentence. Tamil sentences are POS tagged using Tamil POS Tagger tool. This tagger was developed, using Support Vector Machine (SVM) based machine learning tool, SVMTool [12], which make the task simple and efficient. In this method, POS tagged corpus is created and used to generate a trained model. The SVMTool is used for creating models using tagged sentences and untagged sentences are tagged using those models. 42k sentences (approx 5 lakh words) are tagged for this Part-of-Speech tagger with the help of eminent Tamil linguist. The experiments are conducted with our tagged corpus. The overall accuracy of 94.6% is obtained for the test set which contains 6K sentences (approx 35 thousand words). 1.7.3.2 Tamil Morphological Analyzer
After POS tagging, sentences in the corpora are morphologically analyzed for finding the lemma and morphological information. Morphological analyzer is a software tool used to segment the word into meaningful units. Morphological analysis of Tamil is a complex process because of its “morphological-rich” nature. Generally, rule based approaches are used to develop morphological analyzer system. For a morphologically rich language like Tamil, the creation of rules is a challenging task. Here a novel machine learning based approach is proposed and implemented for Tamil verb and noun Morphological analyzer. Additionally, this approach is tested for languages such as Malayalam, Telugu and Kannada.
This approach is based on sequence labeling and training by kernel methods. It captures the non-linear relationships and various morphological features of natural language words in a better and simpler way. In this machine learning approach, two training models are created for morphological analyzer. First model is trained using the sequence of input characters and their corresponding output labels. This trained Model-I is used for finding the morpheme boundaries. Second model is trained using sequence of morphemes and their grammatical categories. This trained Model-II is used for
assigning grammatical classes to each morpheme. The SVM based tool was used for training the data. This tool segments each word into its lemma and morphological information.
1.7.4
Factored SMT System for English to Tamil Language
Factored translation is an extension of Phrase based Statistical Machine Translation (PBSMT) that allows the integration of additional morphological and lexical information, such as lemma, word class, gender, number, etc., at the word level on source and the target languages. In SMT system, three different toolkits are used for translation modeling, language modeling and decoding. These toolkits are implemented using GIZA++, SRILM and Moses toolkits. GIZA++ is a Statistical Machine Translation toolkit that is used to train IBM models 1-5 and an HMM word alignment model. It is an extension of GIZA which was designed as part of the SMT toolkit. SRILM is a toolkit for language modeling that can be used in speech recognition, statistical tagging and segmentation, and Statistical Machine Translation. Moses is an open source SMT system toolkit that allows to automatically training translation models for any language pair. What is needed is a collection of translated texts (parallel corpus). An efficient search algorithm finds quickly the highest probability translation among the exponential number of choices. Figure 1.3 explains the mapping of English factors and Tamil factors in Factored SMT system.
Figure 1.3 Mapping English Word Factors to Tamil Word Factors
Morphological, syntactic and semantic information can be integrated as factors in factored translation model during training. Initially, English factors “Lemma” and “Minimized-POS” are aligned to Tamil factors “Lemma” and “M-POS” then
“Minimized-POS” and “Compound-Tag” factors of English word is aligned to “Morphological information” factor of Tamil word. Here, the important thing is Tamil surface new words are not generated in SMT decoder. Only factors are generated from SMT system and the surface word is generated in the post processing stage. Tamil morphological generator is used in post processing to generate a Tamil surface word from output factors. The system is evaluated with different sentence patterns like simple, continuous and model auxiliaries and with these types, 85% of the sentences are translated correctly. In addition, for other sentence types, the performance is 60%. The prototype machine translation system which is developed properly handles the noun-verb agreement. This is an essential requirement for translating into morphologically rich languages like Tamil. BLEU and NIST evaluation scores clearly show that the factored model with an integration of linguistic knowledge gives better result for English to Tamil Statistical Machine Translation system.
1.7.5
Post-processing for English to Tamil SMT
Post-processing is engaged to generate a Tamil surface word using output factors. In factored SMT system, the aim is to translate factors only, not to generate a surface word. Due to the morphological rich nature of Tamil language, word generation is handled separately. Morphological generator is applied in post-processing stage of English to Tamil Machine Translation system. Post-processing transforms the translated factors into grammatically correct target language sentence.
1.7.5.1 Tamil Morphological Generator
Tamil morphological generator receives the factors in the form of “lemma + word_class + morpho-lexical information”, where lemma specifies the lemma of the word form to be generated, word_class denotes the grammatical category and morpho-lexical information states the type of inflection. These factors are output of the proposed Machine Translation system. The novel suffix based approach is developed for Tamil Morphological generator. Tamil noun and verb paradigm classification is done based on its case and tense markers respectively. Number of paradigms for verb and noun is defined. In Tamil, verbs are classified into 32 paradigmsand nouns and classified into 25 [13]. Noun and verb paradigms are used for creating suffix table. Morphological generator system is divided into 3 modules. The first module takes the
lemma and word-class as input and gives the lemma’s paradigm number and word’s stem as output. This paradigm number is referred as column index. Paradigm number provides information about all the possible inflected words of a lemma in a particular word class. The second module takes morpho-lexical information as an input and gives its index number as an output. From the complete morpho-lexical information list, the index number of the corresponding input morpho-lexical information factor is identified and this is referred as row index. In third module, a two dimensional suffix-table is used to generate the word using row index and column index. Finally the identified suffix is attached with the stem to create a word form. For pronouns, pattern matching approach is followed for generating pronoun word form.
1.8 RESEARCH
CONTRIBUTIONS
This thesis shows how preprocessing and post processing can be used to improve the statistical machine translation for English to Tamil language. The main focus of this research is on translation from English into Tamil language, but also the development of linguistic tools for Tamil language. The contributions are,
• Introduced a novel pre-processing method for English sentences which is based on reordering and compounding. Reordering rearrange the English sentence structures according to Tamil sentence. Compounding removes the function words and auxiliaries then merged to the morphological factor of content word. This pre-processing reorganizes the English sentence structure according to the structure of Tamil sentence.
• Created a Tamil POS Tagger and tagged corpora size of 5 lakh words which is a part of pre-processing Tamil language sentence.
• Introduced a novel method for developing Tamil morphological analyser
which is based on Machine learning approach. Corpora developed for this approach contains 4 lakh morphologically segmented Tamil verbs and 2 lakh Tamil nouns.
• Introduced a novel algorithm for developing Tamil morphological generator
with the use of paradigms and suffixes. Using this generator, it is possible to generate 10 thousand distinct word form of a single Tamil verb.
• Successfully integrated these pre-processing and post-processing modules and developed English to Tamil factored SMT system.
1.9
ORGANIZATION OF THE THESIS
This thesis is divided into ten chapters. Figure 1.4 shows the Organization of the thesis.
Figure 1.4 Thesis Organizations Chapter‐10 CONCLUSION Chapter‐I INTRODUCTION BACKGROUND LITERATURE SURVEY Chapter‐2 Chapter‐3 Chapter‐7 Chapter‐8 Chapter‐9 FACTORED SMT MORPHOLOGICAL GENERATOR FOR TAMIL
EXPERIMENTS AND RESULTS Chapter‐4 PREPROCESSING ENGLISH LANGUAGE PREPROCESSING TAMIL LANGUAGE
Chapter‐6 MORPH ANALYZER FOR TAMIL
This thesis is organized as follows. General introduction is presented in chapter 1. Chapter 2 presents the literature survey for linguistic tools and available Machine Translation systems for Indian languages. In Chapter 3, the theoretical background and language processing for Tamil is described. Chapter 4 contains the different stages of preprocessing English language sentences. Stages include reordering, factorization and compounding. Chapter 5 and 6 presents the preprocessing of Tamil sentence using linguistic tools. In Chapter 5, development of Tamil POS tagger is explained and Chapter 6 illustrates the Morphological Analyzer for Tamil language. This morphological analyzer is developed based on the new machine learning based approach. Additionally, the detailed descriptions of the method and data resources are also illustrated. Chapter 7 presents the Factored SMT system for English to Tamil language. This chapter explains how the factored corpora are trained and decoded using SMT Toolkit. Post-processing for Tamil language is discussed in chapter 8. Morphological generator is used as a Post-processing tool. This chapter also explains the detailed description about a new algorithm which is developed for Tamil Morphological generator. Chapter 9 explains the experiment and results of English to Tamil Statistical Machine Translation system. It also describes the training and testing details of SMT toolkit. The output of the developed system is evaluated using BLEU and NIST metrics. Finally Chapter 10 concludes the thesis and explains the future directions about this research.
CHAPTER 2
LITERATURE
SURVEY
This chapter presents the state of the art in the field of Tamil Linguistic tools and Machine Translation systems. Tamil Linguistic tools include POS Tagger, Morphological analyzer and Morphological generator. This chapter discusses the literature review about the Linguistic tools and Machine Translation systems for Indian languages and Tamil languages.
2.1
PART OF SPEECH TAGGER
Part-of-Speech (POS) tagging is the process of labeling a Part-of-Speech or other lexical class marker to each and every word in a sentence. It is similar to the process of tokenization for computer languages. Hence POS tagging is considered as an important process in speech recognition, natural language parsing, morphological parsing, information retrieval and machine translation.
Different approaches have been used for Part-of-Speech (POS) tagging, where the notable ones are rule-based, stochastic, or transformation-based learning approaches. Rule-based taggers try to assign a tag to each word using a set of hand-written rules. These rules could specify, for instance, that a word following a determiner and an adjective must be a noun. This means that the set of rules must be properly written and checked by human experts. The stochastic (probabilistic) approach uses a training corpus to pick the most probable tag for a word [14-17]. All probabilistic methods cited above are based on first order or second order Markov Models.
There are a few other techniques which use proba