This is the author’s version of a work that was submitted/accepted for pub-lication in the following source:
Hou, Jun & Nayak, Richi (2013) The heterogeneous cluster ensemble method using hubness for clustering text documents. Lecture Notes in Computer Science [Web Information Systems Engineering - WISE 2013: 14th International Conference, Nanjing, China, October 13-15, 2013, Pro-ceedings, Part I],8180, pp. 102-110.
This file was downloaded from: http://eprints.qut.edu.au/63173/
c
Copyright 2013 Springer
Notice: Changes introduced as a result of publishing processes such as
copy-editing and formatting may not be reflected in this document. For a definitive version of this work, please refer to the published source:
The Heterogeneous Cluster Ensemble Method using
Hubness for Clustering Text Documents
Jun Hou & Richi Nayak
School of Electrical Engineering and Computer Science, Queensland University of Technology, Brisbane, Australia
[email protected],[email protected]
Abstract. We propose a cluster ensemble method to map the corpus docu-ments into the semantic space embedded in Wikipedia and group them using multiple types of feature space. A heterogeneous cluster ensemble is con-structed with multiple types of relations i.e. term, document-concept and document-category. A final clustering solution is obtained by ex-ploiting associations between document pairs and hubness of the documents. Empirical analysis with various real data sets reveals that the proposed meth-od outperforms state-of-the-art text clustering approaches.
Keywords: Text Clustering, Document Representation, Cluster Ensemble
1
Introduction
Grouping of text documents into clusters is an elementary step in many ap-plications such as Indexing, Retrieval and Mining of data on the Web. In tra-ditional Vector space model (VSM), a document is represented as a feature vector which consists of weighted terms. A disadvantage of VSM representa-tion is that it is not able to capture the semantic relarepresenta-tions among terms [2]. Researchers have introduced two approaches of enriching document repre-sentation: (1) topic modelling, such as pLSI [13] and LDA [14]; and (2) em-bedding external knowledge into data representation model [1][2][15]. The semantic relations between the terms discovered by these methods are lim-ited in either original document space or concepts represented by Wikipedia articles. They fail to capture other useful semantic knowledge, e.g. Wikipedia category that contains much meaningful information in the form of a hierar-chical ontology [11]. In addition, these methods failed to model and cluster documents represented with multiple feature space (or relations).
In this paper, we propose a novel unsupervised cluster ensemble learning method, entitled Cluster Ensemble based Sequential Clustering using Hub-ness (CESC-H), for enriching document representation with multiple feature space and utilising them in document clustering. We propose to enhance data model by using semantic information derived from external knowledge i.e. Wikipedia concepts and categories. We construct a heterogeneous clus-ter ensemble using different types of feature spaces selected to maximize the diversity of the cluster ensemble. In order to build an accurate cluster ensemble learner, (1) we learn consistent clusters that hold same documents, and (2) utilize the phenomenon of high dimensional data, hubs, to represent cluster center and sequentially join inconsistent documents into consistent clusters to deliver a final clustering solution.
2
Related Work
Our work is related to document representation enrichment techniques that incorporate semantic information from external knowledge, i.e., Wikipedia into Vector space model (VSM) [1][2][15]. [1] maps Wikipedia concepts to documents based on the content overlap between each document and Wik-ipedia articles. [2][15] represented documents as WikWik-ipedia concepts by mapping candidate phrases of each document to anchor text in Wikipedia articles. However, in these works, only Wikipedia articles are considered and our proposed cluster ensemble framework incorporates Wikipedia category and concepts both into document representation, thereby introducing more semantic features into the clustering process.
Another related work is cluster ensemble learning. Cluster ensemble learning is a process of determining robust and accurate clustering solution from an ensemble of weak clustering results. Researchers have approached this prob-lem by finding the most optimizing partition, for instance, hypergraph cut-ting-based optimization [5] and probabilistic model with finite mixture of multinomial distributions [6]. Finding a consensus clustering solution has also been approached by learning ensemble information from the co-association matrix of documents such as fixed cutting threshold [7], agglomerative clus-tering [8] and weighted co-association matrix [10]. Our proposed cluster
en-semble learning not only models documents with multiple feature spaces but also provides accurate clustering result by differentiating consistent clusters and inconsistent documents and utilizing hubness of document for grouping.
3
The Proposed Cluster Ensemble based Sequential Clustering
using Hubness (CESC-H) Method
Figure 1 illustrates the process of clustering text documents. Firstly, each document is mapped to Wikipedia articles (concepts) and categories, and cluster ensemble matrices are formed. A heterogeneous cluster ensemble construct is obtained by applying the (same) clustering algorithm on each matrix separately. The Affinity Matrix is proposed for identifying consistent clusters and inconsistent documents based on documents consistency in the cluster ensemble. Using the concept of representative hubs, the final cluster-ing solution is delivered by placcluster-ing all inconsistent documents to the most similar consistent cluster.
Fig. 1. – The Cluster Ensemble based Sequential Clustering using Hubness Method
3.1 Cluster Ensemble Matrices
In this section, we discuss how to construct a heterogeneous cluster ensem-ble with different cluster ensemensem-ble matrices.
Mapping Concept, Category A Document Collection such as Reuters-21578, 20Newsgroup Cluster Ensemble Matrices Affinity Matrix
Similarity Metrics between consistent clusters and inconsistent documents: Sim(cluster,d) = Sim(representative hubs, d) Clustering Solutions Clustering Algorithm such as Kmeans Consistent Clusters Inconsistent Documents Final Clustering Mapping document consistency
Document-Term (D-T) Matrix.A document is represented as a term vector
with term set . Each value of the vector represents the equivalent weight (TF*IDF) value of the term,
(1) where is term frequency and denotes inverse document frequency for documents.
Document-Concept (D-C) Matrix. In the D-C matrix, a document is repre-sented by a concept vector where is the total number of concepts, and each value of is the concept salience ( ), calcu-lated as in equation 3. If the anchor text of a Wikipedia article appears in a document, the document is mapped to the Wikipedia article. However, an anchor text, for example “tree”, can appear in many Wikipedia articles, “tree (the plant)” or “tree (data structure)”. Therefore, we find the most related Wikipedia article for an ambiguous anchor text by calculating the sum of the relatedness score between unambiguous Wikipedia articles and candidate Wikipedia articles. The relatedness of each pair of Wikipedia concepts ( ), is measured by computing the overlap of sets of hyperlinks in them [9]: ( ) ( | | |) | (2) where is the total number of Wikipedia articles. In order to punish irrele-vant concepts and highlight document topic related concepts, the concept salience [18] is applied as the weight of a concept integrating local syntac-tic weight and semansyntac-tic relatedness with other concepts in document : ( ) (3) where is the syntactic weight in equation (1) of the corresponding term . is the sum of relatedness of concept with other con-cepts that the rest of terms in document map to:
( | ) ∑ (4) where is obtained using equation (2). If a concept is mapped to a
n-gram (n>=2) phrase, the syntactic weight in (3) is the sum of the weight of each uni-gram term.
Document-Category(D-Ca) Matrix. A document is represented by a cate-gory vector { } where is a vector that contains parent categories assigned for the concept . The weight of a cate-gory is the weight of the corresponding concept. If a catecate-gory is assigned to more than one concept, the sum of the weight of these concepts is the cate-gory’s weight.
Fig. 2. – The Process of Identifying Consistent Clusters and Inconsistent Documents. (a) A document collection (b) Three Component clustering results (ovals with solid line, dotted line and dashed line) and documents which have larger value than threshold (connected with bold line) (c) Consistent clusters (c1 and c2) and inconsistent documents ( and ).
3.2 Affinity Matrix
In this section, we discuss how to construct an ensemble learner based on Affinity Matrix to identify consistent clusters. Figure 2 illustrates the process in simpler manner. Affinity Matrix (AM) is constructed by identifying docu-ment pairs which co-locate in the same partition of all component solutions (steps 1-3 in Figure 3). Let Cluster ensemble contains all component clustering solution. A component clustering solution
contains partitions for the specific feature space. For a docu-ment , function searches through each clustering partition space in each to identify which partition belonging to:
{ (5) where is the number of partitions and is the identifier of the component clustering result. The consensus function then accumulates the total co-occurrence of a document pair in all component clustering solu-tions using in (5): d6 d4 d1 d2 d3 d5 d7 d1 d2 d4 d3 d5 d6 d7 d1 d2 d4 d3 d5 d6 d7 c1 c2 (a) (b) (c)
( ) ∑ ( ( )) { (6) Affinity Matrix ( symmetric matrix where is the number of docu-ments) contains consistency degree ( ( )) for each pair of docu-ments ( ) in the corpus. The proposed method differentiates con-sistent clusters and inconcon-sistent documents by setting a threshold ( ) on the values in AM and, consequently, is able to obtain reliable consistent clusters with setting a high threshold (steps 4-15 in Figure 3). Documents whose con-sistency degree is above are combined to form consistent clusters (c1 and c2 in Figure 2). Documents with lower consistency degree are dropped to a waiting list as inconsistent documents ( and in Figure 2). The next section shows the process of joining inconsistent documents to consistent clusters.
Fig. 3. – The Unsupervised Cluster Ensemble Learning Algorithm.
Input: Cluster ensemble for document collection with
docu-ments on types of feature space;consistency degree threshold ; number of nearest-neighbour and representative hub threshold .
Output:Final document partition and is the number of clusters.
Initialization:Set the affinity matrix as a null matrix, and set and
(incon-sistent document set) as empty. 1: for to do
2: using equation (5) and (6) 3: end for 4: for do 5: for do 6: if and 7: if && && 8: 9: else 10: ; 11: else 12: 13: end if 14: end for 15: end for 16: for do 17: using equation (8) 18: and using equation (7) 19: end for
3.3 Hubness of Document
The traditional centroid based partitional methods usually fail to distinguish clusters due to the curse of high dimensionality [4]. In this paper, in order to join inconsistent documents to the consistent clusters, we propose to use hubs as representation of the cluster center instead of centroids (step 16-19 in Figure 3). Let be a document in a consistent cluster and be a docu-ments in the document collection . Let denote the set of docu-ments, where document is among the –nearest-neighbour list of docu-ment and . The hubness score of , , is defined as: | ( )| (7) The hubness score of depends on the and the – nearest-neighbour at data point . We make use of top- (top proportion of) documents ranked by hubness score as hubs. Let be the set of repre-sentative hubs for cluster For an inconsistent document , we find the most similar consistent cluster whose representative hub set is most close to :
‖ ‖ (8)
4
Experiments and Evaluation
4.1 Experimental Setup
Data
Set Description #Classes #Documents #Terms
#Wikipedia Concepts #Wikipedia Categories D1 Multi5 5 500 2000 1667 4528 D2 Multi10 10 500 2000 1658 4519 D3 R-Min20Max200 25 1413 2904 2450 5676 D4 R-Top10 10 8023 5146 4109 9045
Table 1. Data set summary
As shown in table 1, two subsets from the 20Newsgroups data set are ex-tracted in the same line as [2]: Multi5 and Multi10. Other two subsets were created from the Reuters-21578 data set as [2]: Min20-Max200 and R-Top10. For each data set, Wikipedia concepts and categories are mapped to the terms of documents via methods discussed in the section 3.1.
Theproposed approach (CESC-H) is benchmarked with following approaches: Single Feature Space.This is a vector-space-model-based Bisecting K-means
approach [3] based on each feature space: term (D-T), concept (D-C), caetegory (D-Ca) which are represented as a, b and c in Tables 2.
Linear Combination of Feature Space. This approach clusters do-cuments based on linearly combined syntactic and semantic feature space: term and concept (D-(T+C)), term and category (D-(T+Ca)) and term, concept and cate-gory (D-(T+C+Ca)) which are d, e and f, respectively in Tables 2.
HOCO[3].This is a High-Order Co-Clustering method using the consistency information theory to simultaneously cluster documents, terms and concepts. Cluster Ensemble Based Methods.The CSPA, HGPA and MCLA are hyper-graph-based methods [5] whereas EAC uses evidence accumulation [8]. CESC. Variation of the proposed method CESC-H but computing similarity between consistent clusters and inconsistent documents using the cluster centroid instead of hubs.
4.2 Experimental Results
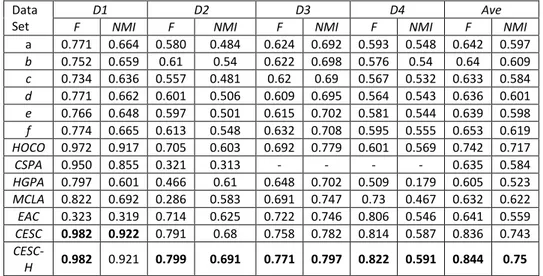
Table 2 presents the clustering performance in FScore and NMI on each data set and method respectively. CSPA was not able to work on data sets D3 and D4 due to computation complexity.
Data Set
D1 D2 D3 D4 Ave
F NMI F NMI F NMI F NMI F NMI
a 0.771 0.664 0.580 0.484 0.624 0.692 0.593 0.548 0.642 0.597 b 0.752 0.659 0.61 0.54 0.622 0.698 0.576 0.54 0.64 0.609 c 0.734 0.636 0.557 0.481 0.62 0.69 0.567 0.532 0.633 0.584 d 0.771 0.662 0.601 0.506 0.609 0.695 0.564 0.543 0.636 0.601 e 0.766 0.648 0.597 0.501 0.615 0.702 0.581 0.544 0.639 0.598 f 0.774 0.665 0.613 0.548 0.632 0.708 0.595 0.555 0.653 0.619 HOCO 0.972 0.917 0.705 0.603 0.692 0.779 0.601 0.569 0.742 0.717 CSPA 0.950 0.855 0.321 0.313 - - - - 0.635 0.584 HGPA 0.797 0.601 0.466 0.61 0.648 0.702 0.509 0.179 0.605 0.523 MCLA 0.822 0.692 0.286 0.583 0.691 0.747 0.73 0.467 0.632 0.622 EAC 0.323 0.319 0.714 0.625 0.722 0.746 0.806 0.546 0.641 0.559 CESC 0.982 0.922 0.791 0.68 0.758 0.782 0.814 0.587 0.836 0.743 CESC-H 0.982 0.921 0.799 0.691 0.771 0.797 0.822 0.591 0.844 0.75
Table 2. – Fscore (F) and NMI for Each Data Set and Method.
We can see that the proposed methods (CESC-H and CESC) and HOCO get significantly better performance than clustering with linear combination of feature space. More importantly,CESC-H (and CESC)outperforms HOCO as it
uses heterogeneous cluster ensemble with additional external knowledge (i.e. Wikipedia category). The CESC and CESC-H approach consistently out-performs other cluster ensemble methods, CSPA, HGPA, MCLA and EAC. Dif-ferent from our proposed method, these ensemble methods do not differen-tiate consistent clusters and inconsistent documents. Moreover, CESC-H per-forms better than CESC on each data set, as hubness scores of clusters can better represent the cluster than the cluster centriod, thereby improving the accuracy of joining inconsistent documents to consistent clusters.
4.3 Sensitivity Analysis
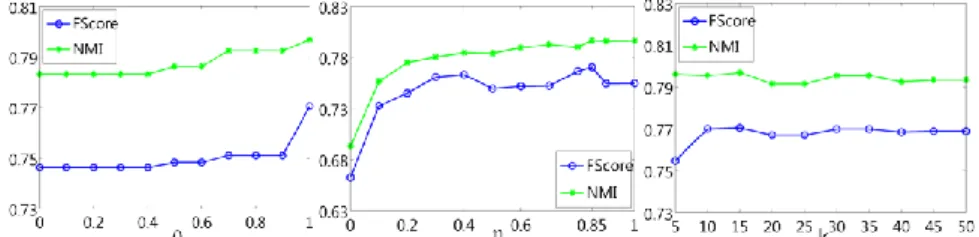
As shown in Figure 4, when increases, performance of CESC-H is improved. The larger value compels a document pair to be grouped in the same parti-tion by more cluster ensemble components. Similarly with the higher value of ( = 0.85), CESC-H achieves the best result. When the neighbourhood size is large enough ( = 15), representative hubs are stable and accurate clustering solution is obtained.
Fig. 4. – FScore/NMI as function of different trade-off parameters: consistency degree thresh-old ; representative hub threshold and number of nearest-neighbour
5
Conclusions and Future Work
The proposed novel Cluster Ensemble based Sequential Clustering using Hubness (CESC-H) method, integrating unsupervised cluster ensemble learn-ing and hubness of documents, has the capability of clusterlearn-ing documents represented with multiple feature space (or relations). CESC-H is able to in-troduce and model more external knowledge for document representation and maximize the diversity of cluster ensemble. With the support of hubness
of documents, CESC-H learns accurate final clustering solution by joining in-consistent documents into in-consistent clusters. Experiments on four data sets demonstrate that the proposed approach outperforms many start-of-the-art
clustering methods. In future, we will investigate other cluster ensemble learning approaches with more features.
References
1. Hu, X., Zhang, X., Lu, C., Park, E., Zhou, X.: Exploiting wikipedia as external knowledge for document clustering. In: Proc. of the 15th ACM SIGKDD, pp. 389–396 (2009)
2. Jing, L. P., Jiali Yun, Jian Yu and Joshua Huang: High-Order Co-clustering Text Data on Se-mantics-Based Representation Mode. In Proc. of the PAKDD, pp. 171-180 (2011)
3. Steinbach, S., Karypis, G., Kumar, V.: A comparison of document clustering techniques. In: Proc. of the Workshop on Text Mining at ACM SIGKDD (2000)
4. R. Agrawal, J. Gehrke, D. Gunopulos, and P. Raghavan: Automatic subspace clustering of high dimensional data for data mining applications. In Proc. of the 1998 ACM SIGMOD, pp. 94-105 (1998)
5. Strehl A, Ghosh J.: “Cluster Ensembles – A Knowledge Reuse Framework for Combining Multiple Partitions.” Journal of Machine Learning Research, 3, pp. 583–617 (2003) 6. A. Topchy, A. Jain, W. Punch: “A mixture model for clustering ensembles”, In
Proceed-ings of the SIAM International Conference on Data Mining, pp. 331–338, (2004)
7. Fred, A.: Finding consistent clusters in data partitions. In: Kittler, J., Roli, F. (eds.) MCS 2001. LNCS, vol. 2096, pp. 309–318. Springer, Heidelberg (2001)
8. Fred, A. N., A. K. Jain: “Combining multiple clusterings using evidence accumulation”, IEEE Transactions on Pattern Analysis and Machine Intelligence, Vol. 27 (6), pp. 835-850 (2005) 9. Medelyan, O., Witten, I., Milne, D.: Topic indexing with wikipedia. In: Proc. Of AAAI (2008) 10. Sandro Vega-Pons, José Ruiz-Shulcloper, Alejandro Guerra-Gandón: Weighted association based methods for the combination of heterogeneous partitions. Pattern Recognition Letters 32:16, 2163-2170 (2011)
11. Köhncke, B., Balke, W.-T.: Using Wikipedia Categories for Compact Representations of Chemical Documents. In: Proc. of the ACM CIKM (2010)
12. Tomasev N, Radovanovic M, Mladenic D, Ivanovic M: The role of hubness in clustering high-dimen-sional data. In: Proceedings of PAKDD, pp 183–195 (2011)
13. Deerwester, S. C., S.T. Dumais,T.K. Landauer, G.W.: Furnas,and R.A.harshman. Indexing bylatent semantic analysis. Journal of the American Society of Information Science, 41(6):391–407 (1990)
14. D. Blei, A. Ng, and M. Jordan: Latent Dirichlet allocation. Journal of Machine Learning Re-search, 3:993–1022 (2003)
15. A. Huang, D. Milne, E. Frank, I.H.: Witten, Clustering documents using a Wikipedia-based concept representation, in: 13th PAKDD, Bangkok, Thailand, pp. 628–636 (2009)