Capturing both Types and Constraints in Data Integration
Michael Benedikt
y
, Chee-Yong Chan
, Wenfei Fan y , Juliana Freire z , Rajeev Rastogi y y
BellLaboratories, Lucent Technologies
SoC, National University of Singapore
z
OGI, OregonHealth & Science University
fbenedikt,wenfei,rastogig@r esea rch. bell- labs .com, [email protected], [email protected]
Abstract
Wepropose aframeworkforintegratingdatafrommultiple relational sources into an XML document that both con-forms to a given DTD and satises predened XML con-straints. The framework is based on a specication lan-guage,AIG,thatextendsaDTDby(1)associatingelement typeswith semantic attributes (inherited and synthesized, inspiredbythecorrespondingnotionsfromAttribute Gram-mars), (2) computing these attributes via parameterized SQLqueriesovermultipledatasources,and(3) incorporat-ingXMLkeysandinclusionconstraints. ThenoveltyofAIG consists insemantic attributes and their dependency rela-tionsforcontrollingcontext-dependent,DTD-directed con-structionofXMLdocuments,as wellas for checkingXML constraintsinparallel with document-generation. Wealso presentcost-basedoptimizationtechniquesforeÆciently eval-uatingAIGs, including algorithmsformerging queriesand for scheduling queries onmultiple datasources. This pro-vides a newgrammar-based approach for data integration underbothsyntacticandsemanticconstraints.
1.
Introduction
Dataexchangeapplicationsfrequentlyrequireenterprises to integrate data from dierent relational sources for ex-portasanXMLdocument. TheintegratedXMLdocument is typicallyrequiredto conformto apredened \schema". Typically a schema consists of two parts: a type speci-cation and a set of integrity constraints, e.g., a specica-tioninXMLSchema[28]; thus,theintegrateddatashould bothconformtothetypeandsatisestheconstraints.Here we consider DTDsfor XMLtypes, andkeys andinclusion constraints(ageneralization offoreignkeys)forXML con-straints,whichrepresenttheschemafeaturesmostcommon incurrentpractice.
Example 1.1: Letus considerdata exchange between an insurancecompanyand ahospital. Thehospitalmaintains four relational databases: onecontaining patient informa-tion,one indicatingwhether atreatment is covered by an insurancepolicy,onestoringbillinginformation,andone de-scribingtreatmentprocedures{atreatmentmay requirea
WorkdonewhiletheauthorwaswithBell Labs.
Permission to make digital or hard copies of all or part of this work for
personal or classroom use is granted without fee provided that copies are
not made or distributed for profit or commercial advantage and that copies
bear this notice and the full citation on the first page. To copy otherwise, to
republish, to post on servers or to redistribute to lists, requires prior specific
permission and/or a fee.
SIGMOD 2003, June 9-12, 2003, San Diego, CA.
Copyright 2003 ACM 1-58113-634-X/03/06 ...
$5.00.
procedureconsistingofothertreatments.Thedatabasesare speciedbythefollowingschemas(withkeysunderlined):
DB1: patientinformation
patient(SSN,pname,policy), visitInfo(SSN,trId,date)
DB 2 : insurancecoverage cover(policy ,trId) DB3: billinginformation billing(trId ,price)
DB4: treatmentprocedurehierarchy
treatment(trId,tname), procedure(trId1,trId2)
Thehospitalsendsadailyreporttotheinsurancecompany that includesinformation onpatientsandtheir treatments forthatday. Theinsurancecompanyrequiresthereportto be inanXMLformat conformingto axedDTDD (here weomitthedenitionofelementswhosetypeisPCDATA):
<!ELEMENT report (patient*)>
<!ELEMENT patient (SSN, pname, treatments, bill)>
<!ELEMENT treatments (treatment*)>
<!ELEMENT treatment (trId, tname, procedure)> <!ELEMENT procedure (treatment*)>
<!ELEMENT bill (item*)>
<!ELEMENT item (trId, price)>
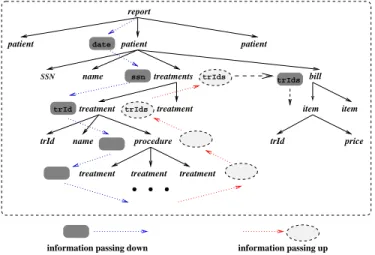
An XMLreportconforming toD isdepicted inFig. 1. It containsinformationfromthedatabaseDB1aboutpatients treatedontheday. Foreachpatient,thetreatments sub-tree describes the treatments covered by the patient's in-surancepolicyaswellastheprocedurehierarchyofeachof thesetreatment,usingthedatainDB1;DB2andDB4;the billsubtreecollectsthepriceforeachtreatmentappearing inthetreatments subtree,usingDB
3
,forthereference of theinsurancecompany.
Observethefollowing. First,theintegrationrequires multi-source queries,i.e., queries onmultipledatabases. For ex-ample, to nd the treatments of a patient covered by in-surance, oneneeds aquery on both DB1 and DB2. Sec-ond, treatment is dened recursively, i.e., in terms of it-self. Thus, atreatment subtree may have an unbounded depth that cannot be determined at compile-time but is rather data-driven, i.e., determined by the data in DB
4 . Third,theconstructionofthebillsubtreeofapatient is context-dependent: it is determinedby thetrIds collected inthe treatments subtreeofthe patient. Infactinmany XML-basedinformationintegrationtasksthenaturalowof tree constructionis not strictlytop-down, but may rather requirepushinginformationcalculated duringconstruction ofonepartofthetreeovertoanotherpart. Thearrowsin Fig.1indicatetheinformationowforthisexample.
00
00
11
11
00
00
11
11
00
00
11
11
date
ssn
trId
trIds
trIds
bill
item
item
trId
price
trIds
report
patient
patient
patient
SSN
name
treatments
treatment
treatment
trId
procedure
treatment
treatment
treatment
name
information passing down
information passing up
Figure1: ExampleofXMLreport
Furthermore,theinsurancecompanyimposesthe follow-ingconstraintsontheXMLreports:
Key: patient(item.trId ! item)
IC: patient(treatment.trId item.trId)
Therst constraint asserts that ineach subtreerooted at a patient, trId is a key of item elements: for any two items,iftheir trIdsubelementshavethesamevalue,then thetwomustbethesameelement. Thatis,eachtreatment ischargedonlyonceforeachpatient. Thesecondoneisan inclusionconstraint; itstatesthat undereachpatient, for anytreatmentelementtheremustbeanitemsuchthatthe values of their trId subelements are equal. Thisspecies aninter-database constraint: eachtreatmentinDB4 must haveacorrespondingpriceentryinDB
3
. 2
Onegoalofthisworkistodevelopalanguagewithwhich, givenacollectionRofrelationaldatabases(sources),aDTD DandasetofXMLconstraints,onecanspecifyan inte-gration(mapping) suchthat (R ) isanXMLdocument thatbothconformstoD andsatises. Furthermore,the languageshould be capable of specifyingintegration tasks commonlyfoundinpractice,suchasthoseinvolving recur-siveDTDs,multi-sourcequeriesandthecontext-dependent constructionsillustratedbytheexample.
Tothis endwepropose aformalism,called Attribute In-tegration Grammar (AIG), to specify data integration in XML.AnAIG consistsoftwoparts: agrammarandaset ofXMLconstraints. Inspiredbyattributegrammars[13], thegrammarextendsaDTDDbyassociatingsemantic at-tributesandsemanticruleswithelementtypes. The seman-tic attributes, which can be either synthesized (evaluated bottom-up)or inherited (evaluatedtop-down),are usedto passdata andcontrolduring AIGevaluation. The seman-tic rules compute the values of the attributes by extract-ing data from databases via multi-source SQL queries. A queryforcomputinganattributemaytakeotherattributes asparameters.Thisintroducesadependencyrelationon at-tributes,andthusthepowertospecifysophisticatedcontrol owwithintheAIGevaluationaswellascontext-dependent constructionof elements. The constraints are compiled into relations onsynthesized attributes and their satisfac-tioncheckingisembeddedintotheattributeevaluation. As aresult,theXMLdocumentisconstructedviaacontrolled
guaranteedtobothconformtoD andsatisfy . Asan example, Fig. 2 givesan AIG,
0
, specifying the dataintegrationdescribedinExample1.1. Wedeferthe ex-planationof0 toSection3whereweformallydeneAIGs. Basedon AIGs, we develop a middleware system to in-tegrate relationaldata. The system implements a variety of optimizationtechniquesto evaluateAIGseÆciently. At compiletime,itconvertsXMLconstraintsintorelationson synthesized attributes, reduces attribute dependencies to a minimum, and rewrites multi-source queries into single-source ones while remaining in the AIG framework. At runtime,usingbasicdatabasestatistics,itgenerates execu-tionplansthatinvolveschedulingandmergingsingle-source queriestomaximizeparallelismamongunderlyingrelational enginesandtoreduceresponsetime.
Contributions. We propose a grammar-based approach to integrating relationaldatainXMLundersyntacticand semanticconstraints.
WeintroduceaspecicationlanguageAIG,which pro-videsasystematicmethodforsupportingDTD confor-mantandcontext-dependentintegration.
WeshowthatXMLconstraintscanbecapturedinthe sameframeworkviaconstraintcompilation.
We show howto supportmulti-sourcequerieswithin ourspecicationandoptimizationframework.
Weadaptqueryschedulingandmergingtechniquesfor eÆcientlyevaluatingAIGs.
Related work. Little previous work has addressed the issue of DTD conformance and constraint satisfaction for XML-baseddataintegration. Clio [23]derivesschema and datamappingsfrom inter-schemaconstraints; itis unclear howitcanensureDTDconformanceautomatically. Results on the existence of mappings satisfying those constraints are exploredin[14];thisisinspiredbyClio, butdealsonly withthe relationalsetting. MIX[2] addressesDTD check-ing/inferenceforXMLintegration,buttheinferenceprocess isexpensive,anddoesnotprovideanyguidancefor howto dene a mapping that type checks [22]; moreover, it does not considerconstraints. XMLpublishing systemssuchas SilkRoute [15] and XPERANTO [27] consider only a sin-glerelationalsourceanddonottakeDTDsandconstraints intoaccount. Earlierrule-basedsystems[10,12,20]relyon object identiers to model recursive data structures; it is unclearhowtheycanhandlerecursiveDTDsand context-dependentintegrationofmultipledatabases. Data integra-tionmappingscanbespeciedinTuringComplete transfor-mationlanguagessuchasXQuery[7]andXSLT[9];but op-timization fortheselanguages stillremainsto beexplored, and their complexity makes it desirable to work within a morelimitedformalism. Ourcontributioniscomplementary to workonschema mapping (see[24] for asurvey),which focusesonschematranslationratherthanprovidingsupport forexplicitspecicationandevaluationofdataintegration. Closesttoourworkis[3],whichpresentsaformalismfor publishing relational datain XMLwith respectto a xed DTD.AIGsextendstheformalismof[3]inseveralnontrivial aspects.First,AIGssupportmultipledatasources. Second, AIGs support both synthesized and inherited attributes;
Semantic attributes: Inh(report) = (date)
Inh(patient) = (date, SSN, pname, policy)
Inh(treatments) = (date, SSN, policy) Syn(treatments) = Syn(treatment)
= Syn(procedure) = (set(trIdS)) Inh(treatment) = (trId, tname)
Inh(procedure) = (trId)
Inh(bill) = (set(trIdS)) Inh(item) = (trId, price)
Inh(SSN ) = Inh(pname) = Inh(trId ) = Inh(price) = Inh(tname) = Inh(S) = Syn(trId) = (val)
Semantic rules: report!patient* Inh(patient).date = Inh(report).date Inh(patient).(SSN,pname,policy) Q 1 (Inh(report)) where Q 1 (v):
select p.SSN, p.pname, p.policy
from DB
1
:patient p, DB 1
:visitInfo i where p.SSN = i.SSN and i.date = v.date
patient!SSN,pname,treatments,bill Inh(SSN ).val = Inh(patient).SSN, Inh(pname).val = Inh(patient).pname,
Inh(treatments) = Inh(patient)(date,SSN,policy) Inh(bill ).trIdS = Syn(treatments).trIdS
/* The treatments subtree of a patient */ treatments!treatment*
Inh(treatment).(trId,tname) Q2(Inh(treatments)) where Q2(v):
select t.trId, t.tname
from DB1:visitInfo i, DB2:cover c, DB
4
:treatment t
where i.SSN = v.SSN and i.date = v.date and t.trId = i.trId and c.trId = i.trId and c.policy = v.policy
Syn(treatments).trIdS = S
Syn(treatment).trIdS
treatment!trId,tname,procedure Inh(trId ).val = Inh(treatment).trId Inh(tname).val = Inh(treatment).tname Inh(procedure).trId = Inh(treatment).trId Syn(treatment).trIdS = Syn(procedure).trIdS
[ fSyn(trId).valg
procedure!treatment*
Inh(treatment).(trId, tname) Q3(Inh(procedure)) Syn(procedure).trIdS =
S
Syn(treatment).trIdS where Q3(v):
select p.trId2, t.tname
from DB4:procedure p, DB4:treatment t where p.trId1 = v.trId and t.trId = p.trId2
trId!S
Syn(trId ).val = Inh(trId).val Inh(S).val = Inh(trId).val
/* The bill subtree of a patient */ bill! item*:
Inh(item ).(trId, price) Q4(Inh(bill ).trIdS) where Q
4 (V): select trId, price
from DB
3
:billing where trId in V
item! trId,price:
Inh(trId ).val = Inh(item).trId, Inh(price).val = Inh(item).tname
XMLconstraints:
patient (item.trId ! item)
patient (treatment.trId item.trId)
Figure2: ExampleAIG
passing duringdocument generation. Third, AIG incorpo-rates into the integration process XML constraintson the target document, which are not considered in[3]. Due to the increased expressiveness, the evaluation of AIGs de-mands techniques far beyond those reported in [3]: it re-quires the analysis of inter-query dependencies,constraint compilation, rewriting of multi-source queries into single-source ones, grouping and scheduling of queries based on thedatasources;thetop-downevaluationstrategyof[3]no longerworksinthiscontext.
Organization. Section 2 reviews DTDs and XML con-straints. Section3denesAIGs,followedbystaticanalyses of AIGs in Section4. Section 5presentsevaluation tech-niques for AIGs. Section 6 presentsexperimental results; andSection7identiesfutureresearchtopics.
2.
Schema Specification
Schema specications for XMLdata normally make use ofDTDsandXMLconstraints.
DTDs. A DTD (Document Type Denition [4]) can be
representedasatupleD=(El e;P;r),whereEl eisanite setofelementtypes;risadistinguishedtypeinEl e,called the root type; P denes the element types: for each A in El e,P(A) isaregular expressionand A!P(A) iscalled theproduction ofA. Tosimplifythediscussionweconsider P(A)oftheform:
::= S j j B1;:::;Bn j B1+:::+Bn j B
where Sdenotesthestring (PCDATA)type,istheempty word,BisatypeinEl e(referredtoasasubelementtype of A),and\+",\;"and\"denotedisjunction,concatenation and theKleenestar, respectively(hereweuse\+" instead of\j"toavoidconfusion).
Recall that an XML document (tree) T conforms to a DTD D if the following conditions are met: (1)thereis a uniquenode, the root, inT labeledwith r; (2)eachnode inT islabeledeitherwithanEl etypeA,called anA ele-ment,orwithS,calledatextnode;(3)eachAelementhas alistofchildrenofelementsandtextnodessuchthatthey areorderedandtheir labelsare intheregularlanguage de-nedbyP(A);and(4)eachtextnodecarriesastringvalue (PCDATA)andisaleafofthetree.
ThesimplicationoftheP(A)'sabovedoesnotlose gen-eralitybecauseofthefollowingfacts,whichare straightfor-wardtoverify: (1)byintroducingentities[4] (macrosofa regularexpression),aDTDD
1
withgeneralregular expres-sions can be converted to D
2
of the form given above in lineartime;and(2)anyXMLdocumentconformingtoD2 canbeconvertedtooneconformingtoD1inlineartime(by eliminatingentities),andviceversa(bylabelingentities).
ToavoidoverloadingthenotionsusedinAIGs,wedonot consider DTD attributes in this paper; butit is trivial to extendourframeworktoincorporatethem.
XML constraints. WeconsiderXMLkeysand inclusion constraints of [1], dened inthe presence of a DTD D as follows:
(1)Key:C(A:l!A),whereC ;Aandlareelementtypes suchthatinD,lisauniquestring-subelementtypeofA,i.e., P(l )=SandlisuniqueinP(A). AnXMLtreeT satises thekeyiinanysubtreeTcofT rootedataCelement,for
c
l subelementsare equal, then xand y are the same node. Thatis,thel -subelementvalueofanAelementauniquely identiesa amongall theAelementsinTc. Wesaythat l isakeyof AelementsrelativetoC elements.
(2) Inclusion constraint (IC): C(B:lB A:lA), where C ;A;B;lA andlB areelement typesofD suchthatlA and l
B
are of stringtypein P(A) and P(B), respectively. An XMLtreeT satisestheICiinanysubtreeT
c
ofTrooted ataC element, foranyB element bthereexistsanA ele-mentainT
c
suchthatthevalueofany l B
subelementofb equalsthevalueofanl
A
subelementofa.
WehaveseenXMLkeysandinclusionconstraintsin Ex-ample1.1. AcursoryexaminationofexistingXML specica-tionsrevealsthatmostXMLconstraintsareofthisform. In particular,foreignkeysaresupported:aforeignkeyisapair consistingofakeyC(A:lA!A)andanICC(B:lBA:lA). To simplifythe discussion we consider XMLconstraints dened withsingle subelement. Thesame framework can beusedtohandleconstraintsinXMLSchema[28].
3.
Attribute Integration Grammars
ThissectiondenesthesyntaxandsemanticsofAIGs.
3.1 DenitionofAIGs
Denition 3.1: GivenaDTD D=(El e;P;r), asetof XMLconstraintsand acollectionRofrelational schemas, an attribute integration grammar (AIG) from R to D, denotedby:R!D,isdenedtobeatripleof:
1. Attributes: twodisjointtuplesofattributesare associ-atedwitheachA2El e[fSg,calledtheinherited and synthesizedattributes ofAanddenotedbyInh(A)and Syn(A),respectively. WeuseInh(A):x(resp.Syn(A):y) todenoteamemberofInh(A)(resp.Syn(A)).
Eachattributememberhaseitheratupletype(tupleof strings)(a1;:::;ak)wheretheai'saredistinctnames, or a settypeset(a
1 ;:::;a
k
) denoting asetof tuples withcomponentsai's.
2. Rules: a setof semantic rules, rule(p),is associated witheachproductionp=A!inP. Inrule(p),(1) thereis arulefor computingthevaluesofSyn(A)by combiningthevaluesofSyn(B
i
)foreachB i
in. and (2)foreachelementtypeBthatoccursin,thereisa rulefor computingInh(B)bymeansofanSQLquery onmulti-databasesofRandusingInh(A)andSyn(B
i ) as parameters. HereBi'saretheelementtypesother thanBmentionedin.
Thedependency relation ofpisthe transitive closure of the following relation: for any B;B
0
in , B de-pends onB
0
i Inh(B)is dened using Syn(B 0
). The dependencyrelationissaidtobeacycliciforanyB in,(B;B)isnotinthedependencyrelation.
3. Constraints: XMLkeysandinclusionconstraintsof arespecied.
TheAIGrequiresthatthedependencyrelationofevery
pro-ductionofD isacyclic. 2
As an example, Fig. 2 gives an AIG 0
. Observe that the dependency relations of all the productions of
0 are
dency relation is not cyclic since Inh(treatments) is not denedusingSyn(bill )directlyorindirectly.
Roughlyspeaking, givena databaseinstance I of R, an AIGextractsdatafromIusingtheSQLqueriesintherules for inheritedattributes, constructsan XML tree with the data directed by the productions of its DTD, and checks whether the XML tree satises its constraints. The syn-thesizedattributescollectdatacomputedateachstageand pass it to SQL queries as parameters such that the XML tree can be constructed ina context-dependent and data-driven way. Thedependency relations specify anordering on the data and control ow, which are acyclic to assure that the computation can be carried out. The inherited attributeInh(r)ofthe root, referred toas the attribute of theAIG,isaglobalparameterthatenablesustocompute dierentXMLtreesfordierentinputvalues. ThusanAIG is a mapping: it takes I and Inh(r) as parameters, inte-grates the data of I following D, and produces an XML tree that both conforms to D and satises . For exam-ple, givena dateand DB
1 ;DB 2 ;DB 3 andDB 4 described inExample 1.1, the AIG
0
generates anXMLreportfor theparticulardatebyintegratingtherelationaldata.
We next dene in detail the semantic rules in an AIG
: R ! D. Consider a production p = A ! in D
with element typesB1;:::;Bn in. We use thenotation \
Syn(B)to denotethe vectorcontaining all thesynthesized
attributes Syn(Bi),and \
Syn(Bi)to denotethevectorofall exceptSyn(B
i
)forxedi. Weusetwotypesoffunctionsg and f for computing thesynthesized attributeSyn(A) and theinheritedattributesInh(Bi),respectively:
g(Inh(A); \ Syn(B))::=(x1;:::;x k )jfxgj [ xjx1[:::[x k f(Inh(A); \ Syn(B i ))::=(x 1 ;:::;x k ) j Q(x 1 ;:::;x k )
wherex;x1;:::;xmaremembersofSyn(Bj)forsomej(j6= iinthesecondcase)andInh(A),(:)andf:gconstructa tu-ple and a set of tuples, respectively; [ denotes set union, S
xbuildsasetbycollectingallthetuplesinx,andQisan multi-sourceSQLquery overdatabases of R, whichtreats members of Inh(A) and Syn(Bj) as parameters (a tempo-raryrelationiscreatedinthedatabaseifsomememberisa set). Typecompatibilityisrequired: thetypeofSyn(A)must matchthatofg,i.e.,ifSyn(A)isofatupletype(a1;:::;a
k ) thengmustbedenedusing(:)andreturnstuplesofarity k, and if Syn(A) is of type set(a
1 :::a k ) then g is dened usingf:g;[or S
andreturnsasetoftuplesofarityk. Sim-ilarly for Inh(Bi) and f; in particular, Inh(Bi) is of a set typeif isdened withaquery. It is easytoverify that typecompatibility canbe checkedstaticallyinlineartime. Also note that while Inh(Bi) can be dened with queries toextractdatafromtheunderlyingdatabases,Syn(A)uses simpletupleandsetconstructorstocombinedatacomputed previously.
Morespecically,withthesefunctionswedescriberule(p) associatedwitheachproductionp=A!.
(1)IfisSthenrule(p)isdenedas
Syn(A)=g(Inh(A)); Inh(S)=f(Inh(A));
where f;gare as denedabovesuchthat f mustreturna tupleofasingle member,i.e., astring, whichistreated as
theonefortrId ! SintheAIG 0 . (2)IfisB 1 ;:::;B n
,thenrule(p)consistsof
Syn(A)=g( \ Syn(B)) Inh(B 1 )=f 1 (Inh(A); \ Syn(B 1 )) ::: Inh(Bn)=fn(Inh(A); \ Syn(Bn)) whereg;f i
areasdenedabove, \ Syn(B i )isalistofSyn(B j )'s,
whichdoesnotinclude Syn(B i
), and \
Syn(B)is alist of all Syn(Bj)'s. This is the only case where the inherited at-tributeof Bi canbe denedwithsynthesized attributesof B
i
'ssiblings. For anexampleseetherules forthepatient productionin0.
(3)IfisB1+:::+Bnthenrule(p)isdenedas:
Syn(A)=case Qc(Inh(A)) of 1:g 1 (Syn(B 1 )); :::; n: g n (Syn(B n )) (Inh(B 1 ),:::,Inh(B n ))=case Q c (Inh(A)) of 1: f1(Inh(A)); :::; n: fn(Inh(A))
whereQcisaquerythatreturnsavaluein[1;n],referredto astheconditionquery oftherule,andf
j ;g
i
areasabove. If Qc(Inh(A))=i,thenSyn(A)andInh(Bi)arecomputedwith gi(Syn(Bi))andfi(Inh(A)),respectively,otherwisetheyare assignedwithnull(oremptysetdependingontheirtypes). These capture the semantics of the nondeterministic pro-ductioninadata-drivenfashion.
(4)IfisB
,thenrule(p)isdenedasfollows:
Syn(A)= [
Syn(B); Inh(B) Q(Inh(A));
where Q is a query. The rule for Syn(A) collects all the synthesizedattributesofitschildrenintoaset. Therulefor Inh(B)introduces aniteration, whichcreates aB childfor each tuple inthe outputof Q(Inh(A)) suchthat the child carriesthetupleasthevalueofitsinheritedattribute. See therulesforthetreatmentsproductionforanexample.
(5)Ifis,thenrule(p)isdenedby
Syn(A)=g(Inh(A));
where gis as denedabove. This is theother case where Syn(A)canbedenedusingInh(A).
Severalsubtletiesareworthmentioning. First,werestrict datasourcestoberelationaljusttosimplifythediscussion. Thesame frameworkcanbe extended tointegrate object-oriented, XML and other formats of data, by expressing queriesin,e.g.,OQL[6]orfragmentsofXQuery[7]. Second, AIGsare nota mildvariationof attributegrammars(see, e.g., [13]) or their typical applications [21]; they are quite dierentinsemanticdenitionsandevaluationstrategies.
3.2 Conceptual Evaluation
We nextgive the semantics of an AIG by presenting aconceptual evaluation strategy. Herewe focus on DTD-directedintegration,deferringthediscussionofthesupport forconstraintsandmulti-sourcequeriestoSections3.3and 3.4. OptimizationtechniquesforeÆcientevaluationofAIGs willbediscussedinSection5.
GivendatabaseinstancesI oftheschema Randavalue voftheattributeInh(r)of theAIG,isevaluated
depth-pushed onto thestack. For eachnodel v atthe topof the stack,wecomputetheinheritedattributevalue~aofl v,nd theproductionp=A!P(A)intheDTDfortheelement typeAofl v,andevaluaterule(p)using~aasfollows:
(1)If p=A!S,recall Syn(A)=g(Inh(A)) andInh(S)= f(Inh(A)). A text node is created as the only child of l v with f(~a) as its PCDATA. Then, g(~a) is computed as the synthesizedattributeofl v.
(2)Ifp=A!B 1
;:::;B k
,recallSyn(A)=g( \ Syn(B)) and
Inh(Bi) = fi(Inh(A); \
Syn(Bi)). We create a node tagged withBi foreachi2[1;n]. These nodesare treatedas the childrenofl v,intheorderspeciedbytheproduction.Since the dependencyrelationof pis acyclic, thereis a topolog-icalorderonB1;:::;Bk suchthat eachBi needs onlythe synthesized attributesof thoseprecedingit inthe order to compute its inherited attribute, while the rst one needs Inh(A)only. Wepushthesenodesontothestackin reverse-topologicalorder,andproceedtoevaluatethemsubstituting ~aforInh(A).Afterallthesenodesareevaluatedandpopped othestack,wecomputeSyn(A)ofl vusingthefunctiong andthesynthesizedattributesofthesenodes.
(3)Ifp=A!B1+:::+Bk,werstevaluatethecondition query, which takesInh(A), i.e., ~a, as a parameter. Based onitsvalue,aparticularBi isselectedandthefunctionfor computingInh(Bi)is evaluated, afunctiondependingon~a only. A single B
i
nodeis created as the onlychild of the node l v, and pushed onto the stack. We then proceed to evaluatethenode. After thenodeis poppedothestack, Syn(A)iscomputedbyapplyinggito~aandSyn(Bi).
(4)Ifp=A!B
,recallInh(B) Q(Inh(A))andSyn(A)= S
Syn(B). We rst compute Inh(B). If Inh(B) is empty, thenl v has nochildrenand Syn(A)is empty;otherwise m nodestaggedwithB arecreatedasthechildrenofl v,such that each B node carries a tuple from the set Inh(B) as itsinheritedattribute.Thenewly-creatednodesarepushed ontothestackandevaluatedinthesameway.Afterallthese nodes have been evaluated and popped o the stack, we computeSyn(A)ofl vbycollectingthesynthesizedattributes ofthesenodesintoaset.
(5) If p = A ! , recall Syn(A)= g(Inh(A)). We simply computeg(~a)asthesynthesizedattributeofl v.
AfterSyn(A)ofl viscomputed,wepopl vothestack,and proceedto evaluateothernodesuntilnomorenodesarein the stack. At the end of the evaluation, an XML tree is created,denotedby(I;v).
The following should be remarked. First, each node is visited onlytwice: itiscreatedandpushed ontothestack, and popped o the stack after its subtree is created and evaluated; it willnot beonthe stack afterward. Thus the evaluationtakesone-sweep: it proceedsdepth-rst, follow-inganordercontrolledbythedependencyrelationsinstead ofleft-rightorright-leftderivation. Ateachnode,its inher-itedattributeisevaluatedrst,thenitssubtree,andnally, its synthesized attributes. Second, the evaluation is data-driven: the choiceofa production inthenondeterministic case and the expansion of the XML tree in the recursive casearedeterminedbyqueriesontheunderlyingrelational data. Third, context-dependent constructionofXMLtrees issupported: synthesizedattributesallowustocontrol the derivationof asubtreewith datafromother subtrees.
Fi-nally, eachstep ofthe evaluationexpandsthe tree strictly following the DTD D. It is easy to showthat if the AIG evaluation terminates,thenitgenerates anXMLtreethat conformstoD. Thisyieldsasystematicmethodfor DTD-directedintegration.
Example3.1: ConsideragaintheAIG0 ofFig.2. Given databasesDB 1 ;DB 2 ;DB 3 ;DB 4 describedinExample1.1, anda value v ofof Inh(report ).date, theevaluation of0 generatesanXMLtreeT oftheform depictedinFig1as follows. Itrstcreates the root ofT,taggedwithreport. Following therules forthereport production,itcomputes Inh(patient)byextractingdatafromDB1viaqueryQ1(v), whichtreatsvasaconstant. Foreachtupleinthe output ofQ1(v),itcreatesapatientelementasachildofreport, carryingthetupleasthevalueofitsinheritedattribute.For eachpatientnodept,itcreatesSSN,pname,treatmentsand billsubelements. Therst two have their Ssubelements carryingthecorrespondingPCDATAfromtheInh(Patient ) valuev
0
ofpt. Nowthedependencyrelationofthepatient production decides that the bill subtree cannot be con-structedbeforethetreatmentssubtree.Thusitrst evalu-atesthetreatmentschildofptbycomputingQ
2 (v
0 ),which isamulti-sourcequeryoverthreedatabases: DB
1 ;DB
2 and DB4. Againfor eachtupleinthe outputof Q2(v
0 )it cre-atesa treatment subelement. Thesubtree rooted at each treatment node is generated similarly, usingthe rules for the treatment and procedure productions. Observe that treatment is recursively dened; thus, its subtree is ex-pandeduntilitreachestreatmentnodeswhoseprocedures donotconsistofothertreatments,i.e.,whenQ
3
returnsthe empty set over DB4 at procedure nodes. That is, AIGs handle recursion in a data-driven fashion. At this point Syn(procedure);Syn(treatment)andSyn(treatments)are computed bottom-up by collecting trIds from their chil-dren'ssynthesizedattributes. Observethatthevaluevs of Syn(treatments)cannotbecomputedbeforethe construc-tionofthetreatments subtreeiscompletedsince the sub-tree has an unbounded depth. Next, vs is passed to the billchild of thepatient nodept, and theevaluation pro-ceedsto generatethe billsubtree usingthedata inDB3 andvsasInh(bill ). Theintegrationiscompletedwhenall
thepatientsubtreesaregenerated. 2
3.3 ConstraintCompilation
An AIG is pre-processed so that (1) enforcement of its XMLconstraintsisdoneinparallelwithdocument genera-tion,and(2)multi-sourcequeriesarerewritten into single-sourceonestobeexecuteddirectlybyunderlyingrelational engines.TheoutputofthisstepproducesaspecializedAIG, an AIG that may have extra semantic rules and internal computationstates. The generationofspecialized AIGsis automatic: nouserinterventionisneeded.
We now describe how to pre-process constraints in an AIGto getaspecialized AIG
0
. TheAIG
0
extends withadditionalsynthesizedattributes,semanticrulesanda guard construct. Thesynthesizedattributesmayhaveabag type (setwithduplicates), alongwithbag unionoperators \];
U
"analogoustosetoperators\[; S
". Aguardcaptures aconstraintwithabooleanconditionontheseattributes: if theconditionholdsthentheevaluationproceeds,otherwise it aborts, i.e., it is terminated without success. The pre-processing step, referredto asconstraintcompilation,does
Syn(patient) = Syn(bill ) = ... = (bag(B),set(S1),set(S2) , ...) Semantic rules:
patient!SSN,pname,treatments,bill Syn(patient).B = Syn(SSN).B ] Syn(pname).B
] Syn(treatments).B ] Syn(bill).B Syn(patient).S1 = Syn(SSN ).S1 [ Syn(pname).S1
[ Syn(treatments).S1 [ Syn(bill).S1 Syn(patient).S2 = ...
guard: unique(Syn(patient).B)
guard: subset(Syn(patient).S1, Syn(patient).S2)
treatments!treatment* Inh(treatments).B = U Syn(treatment).B Inh(treatments).S1 = S Syn(treatment).S1 Inh(treatments).S2 = ...
item!trId,tname
Syn(item ).B = Syn(trId).val Syn(item ).S1 = f g
Syn(item ).S2 = Syn(trId ).val
. . .
Figure3: Constraint compilationin 0 0
(1) For each key k : C(A:l ! A), create an additional member of type bag(l
k
) in Syn(X) for every element type X. Addsemantic rules such that (i)Syn(A):lk is given the valueof thelsubelementofA elements,(ii)for any Xnot equaltoA,Syn(X):l
k
collectsSyn(A):l k
'sbelowitinits sub-tree,excluding thel subelementvalueof X;and(iii) adda guard unique(Syn(C):l
k
) for the context type C, which re-turnstrueiSyn(C):l
k
containsnoduplicates,i.e.,the val-uesofallthelsubelementsofAelementsareuniquewithin eachCsubtree. Thisautomaticallygeneratescodein
0 for checkingthekey.
(2) Inclusion constraint C(B:l B
A:l
A
) is treated simi-larly: create two additional members la;lb of set type in Syn(X)andaddassociatedrulesusingsetoperators. Forthe typeC,aguardsubset(Syn(C):l
a
;Syn(C):l b
)returnstruei Syn(C):la is containedinSyn(C):lb,i.e., theinclusion rela-tionholdswithineachCsubtree.
The evaluation of the AIG is aborted i any of these guardsisevaluatedtofalse,i.e.,anyconstraintisviolated. Forexample,theconstraintsoftheAIG0 arecompiled intosynthesizedattributesandrulesshowninFig. 3.
Severalremarksare worthmentioning. First,the seman-tic rulesassociatedwithconstraintscanbesimplied stat-ically. For example,the rule forSyn(patient ):B inFig. 3 canberewrittentoSyn(patient):B=Syn(bill ):B.These rules neednotbenecessarily evaluatedbottom-up: the re-lation onattributesimposedbyconstraintscanbeused to optimize the evaluation. Indeed, if at some point during generation, a bag-valued attribute (key) is found to have duplicates,evaluationisabortedimmediately. Similarly,an inclusion constraint C(B:l B A:l A ) suggests thatB:l B is passed tothe rules forA suchthat onecancheck whether thereisavalueofB:lB thatisnotinA:lA duringthe com-putation of A:l
A
, and vice versa. Thisavoids unnecessary computation. Constraintrepairing[19]canbeincorporated intotheframework,buttosimplifythediscussion,wefocus onconstraintcheckinginthispaper.
3.4 Multi-source QueryDecomposition
Inh(St ) = (date, SSN, policy) Inh(St
1
) = (set(trId, policy)) Inh(St2) = Syn(St1) = (set(trId)) Syn(St ) = Syn(St 2 ) = (set(trId, tname)), ... Semantic rules: treatments!St,treatment* Inh(St ) = Q 2 (Inh(treatments)), Inh(treatment).(trId,tname) Syn(St ), ... where Q 2 (v):
select i.trId, v.policy
from DB
1
:visitInfo i
where i.SSN = v.SSN and i.date = v.date
St!St 1 ,St 2 Inh(St1) = Q 0 2 (Inh(St )), Inh(St2) = Q 00 2 (Syn(St1)) Syn(St ) = Syn(St 2 ) where Q 0 2 (v1): select c.trId from DB2:cover c, v1 T1
where c.trId = T1.trId and c.policy = T1.policy where Q
00 2
(v2):
select t.trId, t.tname
from DB
4
:treatment t, v 2
T2 where t.trId = T2.trId
St1 !
Syn(St1) = Inh(St1) /* similarly for St 2
*/
. . .
Figure 4: Multi-source querydecomposition in
0 0
Recall that the query Q2 in the AIG 0 is dened on multiple databases: DB1;DB2 and DB3, whichmay have dierent systemsand mayevenresideindierent sites. It isdesirabletoshiftworkfromthemiddlewaretothesource relational engine as much as possible; thus one wants to rewritethequeryintosub-queriessuchthateachofthemcan besenttoandexecutedattheunderlyingrelationalsystem. Forthis reason aspecialized AIG supportsa setof states, ST,tosupplementthesetEl eintheDTD.Astate inST behaveslikeatypeinEl e: ithasassociatedattributesand semantic rules, whichare evaluated inthesame way. The dierence is that after the integration process terminates thenodes labeledwithstatesinST are removedfromthe resultingXMLtreeT. Thatis, theseST nodesonlyserve forcomputationpurpose. Asanexample,Fig.4showshow the specialized AIG
0 0 rewrites Q 2 by means of internal statesSt;St1andSt2.
A specialized AIG can be viewed as a two-way tree au-tomaton[11]thatcanissuequeries.Itshouldbementioned that multi-source query decomposition is conducted auto-matically. Aleft-deepqueryplantree isrstgenerated by meansofanunderlying relationaloptimizer,underthe as-sumptionthatallthedatalieonthesamesource. Internal statesareintroducedtorepresenttheoutputofeachnodein theplantree. Theparent-childrelationshipfollowsthetree structureoftheplan, theinheritedattributeand semantic rule for a given state correspond to the output attributes andoperatoroftheassociatednodeinthequeryplan.
4.
Static analyses of AIGs
An advantage of using a limited specication language is the ability to infer powerful static guarantees, and per-form advanced program analyses. In contrast, expressive languages such as XQuery and XSLT can not allow such
andhenceterminationissuesandoutputguaranteesareout ofreach.Sinceakeygoalofintegratingdatatowardsa tar-getXMLDTDistoensureconformanceoftheoutputtoa standardinterface,staticcorrectnessassuranceshouldbea centraldesigngoal.
The following results give a sample of the correctness checksthatcanbedonestaticallyonAIGs:
GivenanAIGwithoutconstraintsanddenedwith conjunctivequeries,onecandecidewhetherwill nec-essarilyterminateonallinstances.
Given anAIG as above,one candecidewhether willterminateonsomeinstances.
GivenanAIGasaboveandanelementtypeEinthe DTDof,onecandecidewhetherE canbereached, andwhetherEmustbereachedonanyinstance.
All of the above are proved by symbolic execution of , tracking along each paththe conjunctive queries that are guaranteed to hold down that path. One can show that eveninthecaseofrecursiveDTDs,oneneedonlysimulate executiondowntoaxeddepthtodetectnon-termination. Ofcourse, somelimits ofstatic analysis follow from the correspondinglimitsonrelationalqueries:
TheaboveproblemsareundecidableforAIGsdened witharbitrarySQLqueries,evenwhentheunderlying DTDisnon-recursive.
It isundecidable whether anAIGwithinclusion and key constraints necessarily terminates (on some in-stance)evenwhentheunderlyingDTDisnon-recursive andthequeriesinvolvedareconjunctive.
Therstresultfollowsdirectlyfromtheundecidabilityof equivalenceproblemforSQL,whilethesecondresultmakes use of undecidability results for the consistency of DTDs and(relativeunary)XMLconstraints[1].
Therestrictedform of AIGsalsoallows certain kinds of optimizationstobedoneeasilyatcompiletime. Anexample iscopyelimination. A semanticruleina(specialized)AIG isclassiedasacopyrule(CSR)ifitsrighthandsidemakes useonlyoffunctionsoftheformx
k or
S
x;itisreferred to asaqueryrule(QSR)otherwise. Forexample,thesemantic rule\Inh(treatments).trIdS=
S
Syn(treatment).trIdS"is a CSR.A copychain is amaximal sequenceof dependent
CSRsA 1 =f 1 (A 0 );:::;A n =f n (A n 1 )followedbyaQSR Qthat referenceseldsof An. Incopy elimination, we re-placeanyreference toeldsofAn inQbythe correspond-ing attributes of A
0
. Note that inthe resulting AIG, the semanticrule forthe attributesof anelementtypeE may nowhaveparametersthatarefarawayfromEintheDTD. Copy-eliminationisa kindof inlining{wewill seeamore generalversionofthisinthemergingalgorithmofSection5. Itreducesdependenciesamongqueriesandthusallowsmore queriesondierentdatasourcestobeexecutedparallelly.
5.
Evaluating AIGs
Inthissection,wepresentamediatorsystemfor evaluat-ing AIGs whose goal is to generate the DTD-conforming XML document as fast as possible. Compared to tradi-tional distributed query processing [18], the optimization and evaluation of AIGs present additional challenges. In AIGs, evaluation involvesaset of queriesthat are related byinter-query dependencies (seethedenitionofquery
de-output
scheduling
AIG specification
data sources
execution
query plan
API
statistics
queries
SQL
results
query
plan
cost estimate
XML document
specialized AIG
tagging
phase
optimization
execution
tagging
plan
plan
query
dependency graph
optimizer
optimizer
merging
pre−processing
relations
Figure 5: AIG MiddlewareArchitecture
thesequeriesisusedtodrivethegenerationoftheXML doc-ument,asqueriesaretransformedduringoptimization,this relationshipmustbedynamicallymaintained. Thetaskto manipulateandcombinequeriesisthusheavilyconstrained bybothinter-queryandquery-to-data-sourcedependencies, leadingtoanoveloptimizationproblem.
5.1 Overview
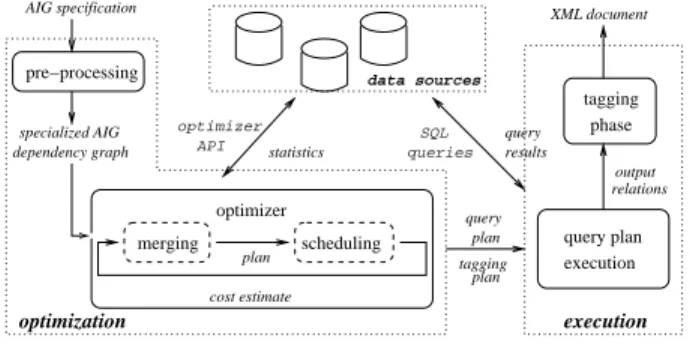
The architecture of the middleware system is shown in Fig. 5. The systemtakesanAIG specication as input and evaluates it in four phases to produce an XML doc-ument that conforms to the DTD and satises the con-straints embedded in . In the pre-processing phase, it rewritesintoaspecializedAIGwithsingle-source param-eterizedqueriesand relationsencodingtheconstraints(see Sections3.3 and3.4); andperformscopyelimination. The optimizationphaseproducesacustomizedapplication, con-sisting of 1) a set of non-parameterized queries for each source, along with their input and output schemas; 2) a queryplangivinganorderingforthequeriesamongthe var-iousdatasources; and3)atagging planforgeneratingthe naldocumenttree. Theexecutionphaseperformsthe run-timeevaluation oftheAIG. Thequeryplanisexecutedto produceasetofoutputrelations{arelationalrepresentation of the XML document. More specically, at each source, theunprocessedquerythatislowestintheplan'sordering isselectedforexecution assoonas itsinputsareavailable. Whenthequeryiscompletelyevaluated,itsresultsarethen shipped(viathemediator)toeverydependentsite. Finally, inthe tagging phase, the tagging plan is applied to these relationsto producethenal outputdocument. Notethat whilequeryplanevaluationinvolvesbothprocessingonthe sources and shipping of data over the network, tagging is donecompletelywithinthemiddleware.
Tosimplifythediscussion,inthebulkof thissection we willfocusonthecaseofnon-recursiveAIGs. Asanexample, we use a variation of the AIG 0 of Fig. 2, by unfolding the recursiononly onceand assuming that the procedure leafhasnochildren. Fornon-recursiveAIGs,therstthree phasescanbedoneentirelyatcompiletime.Wediscusshow ourproposedtechniquescanbeextendedtohandlerecursive AIGsinSection5.5.
The pre-processing of the AIG yields a specialized AIG
0 0
by decomposing multi-source queries, as illustrated in Fig4(tosimplifythediscussionweignoretherulesfor con-straints). Thegraphrepresentationof
0 0
aftercopy elimina-tionisshowninFig. 6.Inthisgraph,edgelabelsrepresent queriesfor computinginheritedattributes (e.g.,Q2, Q2'); nodelabelsrepresentqueriesforcomputingsynthesized at-tributes(e.g.,ST,ST1);and thedashededgesindicatethe
bill
Inh
Inh
Inh
Inh
Inh
Inh
Inh
Inh
Inh
Inh
Syn
Syn
Syn
Syn
Syn
Syn
Syn
Syn
Syn
Syn
*
report
patient
treatments
*
treatment
tname
procedure
*
treatment
tname
procedure
Q1
trId
pname
SSN
ST
Q2
Q3
item
*
trId
price
Q4
Q5
Q6
trId
ST1
Q2’
Q2"
ST2
Figure 6: Example: aspecialized AIG
owofinformation. Theresultsofthequeriesthatcompute inheritedattributesare shippedtothemediator(viewedas aspecialdatasourceMediator),cachedintemporarytables, and usedtoconstructthenalXMLdocumentinthe tag-gingphase.Thesynthesizedattributesarecomputedatthe mediatorusingthecachedtables. Observethatcopy elim-inationremovesthequeriesandattributesthat aredened via copy rules (with simpleprojections) and are not refer-encedbyotherattributes. Inthetagging phase,thevalues oftheseattributesaresimplyextractedfromthecached ta-bleswhentheyareneeded.
Toconstruct the nalXMLtree, the queriesinan AIG needto berewritten suchthat theoutputrelation ofeach query contains information that canuniquely identify the position of a node inthe XML tree, i.e., a coding of the pathfrom the root to the node. Furthermore,as opposed totheconceptualevaluationstrategy,foreachqueryQthat takesasingletupleofthe outputtmpof anotherqueryQ
0
as aninput, we convertQ to onethattakestheentireset tmp of tuples as an input. This is done by replacing the tupleparameterinQwiththetemporarytablethatcontains theoutputofQ
0
. Inourexample,theparameterizedquery Q2(v) inFig. 4, where vis a singletuplein Inh(patient) (theresultofthequeryQ
1 ):
select i.trId, v.policy
from DB
1
:visitInfo i
where i.SSN = v.SSN and i.date = v.date
istransformedintoQ 2
(T patient
):
select i.trId, v.policy, v.SSN
from DB
1
:visitInfo i, T patient
:v where i.SSN = v.SSN and i.date = v.date
where T patient
is atemporarytablestoring Inh(patient ).
ObservethatQ 2
(T patient
)isexecutedoncewhenT patient
is available,insteadofbeingexecutedforeachtupleinT
patient .
NotethattheoutputofQ 2
(T patient
)includesanextraeld SSN,whichencodesapathfromtheroottoapatientnode; this,togetherwiththetrIdeld,uniquelyidentiesthe po-sitionoftheSTnodes(infact,treatmentnodes)inthenal document. Giventhis,thenalXMLdocumentcanbe gen-eratedbysimplysort-mergingthecachedtemporarytables. This query rewriting process is done in the optimization phaseviaaniterativeprocessinwhichthescalarparameters ofqueryQarereplacedbytemporarytables,oneperoutput ofeachquerythatQdependsupon. Theoptimizationphase alsogeneratesthetaggingplan,whichwillproducethetree inatop-downfashion,associatingeachnodeofelementtype E withakeypathinthetableforInh(E)|internalstates (e.g.,ST;ST
1 ;ST
2
)inthespecialized AIGareeliminatedin thetaggingphase.
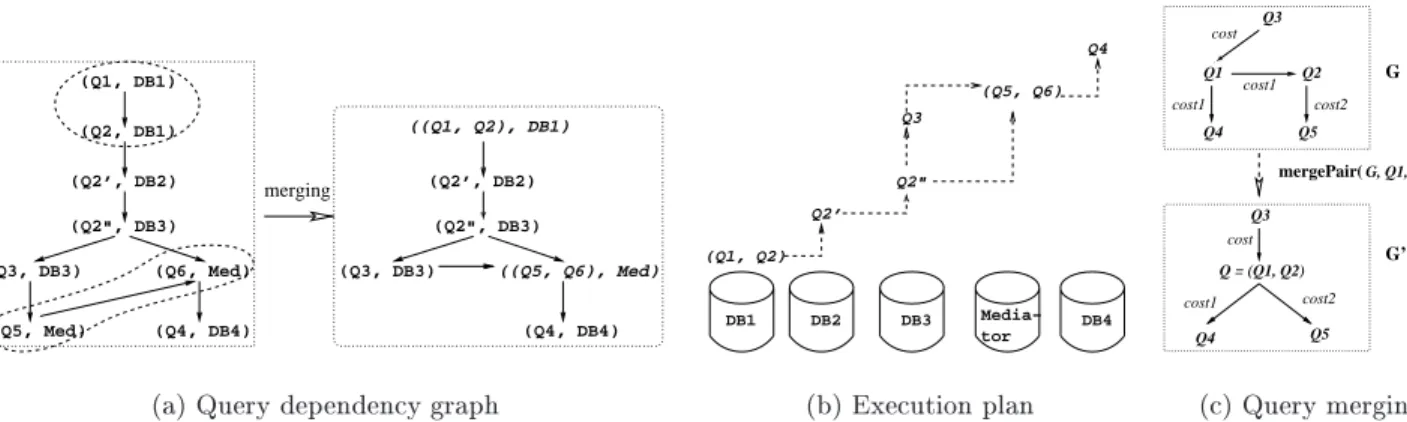
the queries generated by the process above, we dene the query dependency graph G of the AIG.The graphG con-tainsanodeforeachquery,andadirectededgefromanode Q 1 tonode Q 2 ithe result ofQ 1 is used inQ 2 , denoted byQ1!G Q2. ThequerydependencygraphfortheAIGof Fig. 6 is shownin Fig. 7(a). Inthis graph, eachquery is associated withthedatasourcewhereitisevaluated. Note thatGisaDAG(directedacyclic graph): the DAG struc-turereectsthefactthatanAIGgenerallyspeciessharing ofa queryoutputamong multiple furtherqueries. Thisis insharpcontrastbothtotraditionaldistributedquery pro-cessingandtoXMLpublishingformalismssuchas[15,3].
Wenextconsiderqueryplangenerationinthe optimiza-tionphase. Dierentfactors contributetothe total execu-tiontimeofanAIGspecication,mostnotably: communi-cationcosts{datamustbetransferredbetweendatasources as well as between the mediator and data sources; query execution overheads { in addition to the cost of sending queriestodatasources(i.e.,openingaconnection,parsing and preparingthe statement, etc.), temporary tables may have to be createdand populated with inputsto a query; query execution costs {thetotal executiontimeofaquery inagivendatasource;parallelexecution {queriesin dier-entsourcesmaybeexecutedinparallel. Consequently,the maingoal of theAIG optimizeris to minimizethesecosts andoverheads byexploitinginter-queryparallelism. Inthe remainderofthissection,wediscussoptimizationindetail. TheAIGoptimizerreducesthenumberofqueriesissued to data sources by merging queries that are processed at thesamesourceintoasingle, largerquery. Querymerging canhelpdecreasethecommunicationcostsbetweenthe me-diatorand datasources,while alsopotentiallydiminishing queryprocessing time and execution overheads. However, querymergingmayinvolveouter-joinsorouter-unionswhich increasethearityof thequery'sresulttableandhencethe outputsize. Furthermore, injudicious query merging may increaseprocessing timeand lead to unnecessary delay of furtherqueryexecutions. Section5.4 outlinesacost-based query merging algorithm that iteratively applies a greedy heuristictoselectpairsofqueriestomerge,where thecost function estimates the best query schedule (i.e., with the smallesttotal executiontime)for themergedquerygraph. Theinteractionofschedulingandmergingisoneofthemost delicatepointsoftheoptimizationalgorithm. Theproblem ofschedulingqueriesinthepresenceofDAG-likequery de-pendencies,suchasthoseconsideredhere,isNP-hard,and thus an approximate scheduling algorithm is an essential componentofoursolution.
Thevariousstepsoftheoptimizationalgorithmare illus-tratedinFig.7. Theoptimizationalgorithmproceedsas fol-lows. GiventheAIGquerydependencygraphG,invokethe algorithmMerge(seeSection5.4)tomergenodes (queries) inGthatleadtoreductioninqueryevaluationcost. This in-volvesafunctionforestimatingthecostofaqueryplan(see Section5.2),and analgorithm,Schedule (seeSection5.3) for computingagood queryexecution orderingfor G{ an approximationto theoptimalschedule forG. Atthe end of this merging phase, the nal schedule is generated and submittedtotheruntimeengine ofthe middleware foruse intheexecution phase. Notethat, whilethe AIGremains xedduringoptimization,thequerydependencygraphGis updatedineachstageoftheiterativeoptimization.
be generated for the exampleare showninFigs. 7(a) and 7(b). Atruntime,themiddlewareissuesqueriestoeachdata sourceaccordingtothequeryplan,andshipsoutputtables producedbyqueriestosourcesthataredependentonthese resultsassoonastheybecomeavailable. Attheendofthis process,themiddlewareappliesthetaggingplantoproduce thenalXMLtree.
5.2 Cost Evaluation
Inorder to estimate the cost of anAIG, information is neededaboutthecostofexecutingindividualqueries, ship-pingdata,andthedegreeofinter-queryparallelism. Inour current implementation, we assume thatdata sources pro-videaquerycostingAPI,i.e.,for agivena queryQto be executedonadatasourceS,S providesestimatesforboth theprocessingtimeofevaluatingQ(inseconds),denotedby eval cost(Q) ,aswellas theoutputsize (numberof tuples andtuplewidthinbytes)ofQ,denotedbysize(Q) . In par-ticular,ifQreferencestheresults ofanotherqueryQ
0 ,the APIisableto acceptcostestimatesofQ
0
(e.g.,cardinality information)asinputsinthecomputationofevalcost(Q) . Themediatoralsomaintainsinformationaboutthecosts for communicatingwiththe variousdata sources. This in-formation is usedto estimatethe communicationtime (in seconds)toshipresultsto/fromdatasources. Wedenoteby trans cost(S
1 ;S
2
;B)thecostoftransferringdataofsize B bytesfromsourceS1 toS2. Notethatifneither S1 norS2 referstothemediator,thenthedataisshippedfromS1 to S
2
viathemediator;andifS 1
andS 2
are thesamesource, trans cost(S1;S2;B)=0.
Giventhe evaluationcosts ofeachindividual query,and the costof shippingdata acrossdatasources,thetotal ex-ecution time can be derived from the execution plan pro-duced by the scheduling algorithm (see Section 5.3). An execution plan P contains a schedule for each datasource Siwhichconsistsofasequenceofqueriesi=<Qi;1;Qi;2, ;Qi;m>tobeexecuted(inthegivenorder)atSi. Note thattheschedulesinP haveto beconsistentwiththe par-tialorderinginthequerydependencygraphG;i.e.,ifQ
i;k is reachable fromQi;j inG,thenj<k. Letcomp time(Qi;j) denotethe completiontimeof theevaluationofqueryQ
i;j ondatasourceS
i
. Thentheresponsetimeofevaluatingthe execution planP,denotedbycost(P),is simplythe maxi-mumofcomp time(Qi;j)overallthequeriesQi;j inP. The completiontimeofaqueryQatsourceS
i
canbecomputed recursivelyasfollows:
comptime(Q i;m
)=evalcost(Qi;m)+maxfTg; whereT =fcomp time(Q
i;m 1
)g [ fcomp time(Q j;n
) + transcost(Sj;Si;size(Qj;n) )jQj;n!
G Qi;mg
Thus cost(P)=maxfcomp time(Qi;j) jQi;j2i;i2Pg, and canbe computedinat mostquadratic timeusing dy-namicprogramming.
5.3 Scheduling Algorithm
GivenaquerydependencygraphG,thegoalofscheduling istoproduceanexecutionplanP thatisconsistentwithG and thatminimizestheresponse time. Unfortunately,for any reasonablecost functiononqueryplans, including the costfunctiongiveninSection5.2,theproblemofndingthe optimalexecutionplanisNP-hard,evenwhenthereisonly
(Q1, DB1)
(Q2, DB1)
(Q2’, DB2)
(Q2", DB3)
(Q3, DB3)
(Q6, Med)
(Q5, Med)
(Q4, DB4)
(Q2’, DB2)
(Q2", DB3)
(Q3, DB3)
(Q4, DB4)
((Q1, Q2), DB1)
((Q5, Q6), Med)
merging
(a)Querydependencygraph
Media−
tor
DB1
DB2
DB3
DB4
Q2’
(Q1, Q2)
Q4
(Q5, Q6)
Q3
Q2"
(b)ExecutionplanmergePair( )
G, Q1, Q2
Q1
Q2
Q3
Q4
Q5
Q = (Q1, Q2)
Q3
cost
cost1
cost1
cost2
cost
G
G’
Q4
Q5
cost1
cost2
(c)QuerymergingFigure7: Dependencygraph, querymergingand scheduling
AlgorithmSchedule(G)
1.LetLdenotethesequenceofqueriesinGsorted inreversetopologicalorder;
2.foreachQ2Ldo 3. `evel (Q)=0; 4. foreachQ! G Q 0 do
5. `evel (Q)=maxftranscost(S;S 0
;size(Q))+`evel (Q 0
); `evel (Q)g, whereQandQ
0 are evaluatedatSandS
0 ,resp.; 6. `evel (Q)=`evel (Q)+eval cost(Q); 7.foreachdatasourceS
i do
8. Let
i
bethesetofqueriesinGevaluatedatS i
;
9. Sort
i
suchthatQprecedesQ 0 in i if `evel (Q)>`evel (Q 0 );
10.returnexecutionplanP=fijSiisasourceg;
Figure 8: Algorithm Schedule
ing to minimizecompletion time[16]). We thuspresent a heuristicthatgivesanapproximatesolution.
Similarlytothelist-scheduling heuristic[25],weassigna priorityvaluetoeachqueryinGtoreectits\criticality", andthensortthequeriesbasedontheirpriorityvalues. The basic idea is to optimize the critical paths of G, i.e., the sequencesofqueriesthataecttheoverallcompletiontime. ForaqueryQondatasourceS,wedeneapathcostofQto bethecostfor evaluatingall thequeriesalongapathfrom QtoaleafqueryinthedependencygraphG,andweadopt themaximumpathcostasthepriorityvalue ofQ,denoted by`evel (Q). Then,`evel (Q)canbecomputedrecursively:
`evel (Q)=evalcost(Q)+maxf`evel (Q 0 )+ transcost(S;S 0 ;size(Q))jQ! G Q 0 g where S and S 0
denote, respectively, the sources where Q
and Q
0
are evaluated. Intuitively, Qi;j is given a higher priority than Qi;k if `evel (Qi;j) > `evel (Qi;k), i.e., if the evaluationofthequeriesdependentonQ
i;j
takeslongertime thanthose dependingonQ
i;k
. Thismotivates usto order Qi;jbeforeQi;k onsourceSi.
Putting these together, we have AlgorithmSchedule in Fig.8. First,steps1to6compute`evel (Q)foreachquery Q, and then steps 7 to 9 create a schedule for each data sourcebysorting thequeriestobeevaluated atthe source basedon`evel (Q). It is easy to verifythat the algorithm takesatmostquadratictime.
5.4 MergingAlgorithm
Wenextpresentamergingalgorithmthatselectscertain
AlgorithmMerge(G)
1. P :=Schedule(G); cost:=cost(P); 2. repeat
3. benet:=false; Gnew=G; 4. foreachQ
1 ;Q
2
2Gscheduledforthesamesourcedo
5. G 0 :=mergePair(G;Q1;Q2); 6. if(G 0 isacyclic) 7. thenP 0 :=Schedule(G 0 ); c:=cost(P 0 ); 8. ifc<cost
9. thenbenet:=true; cost:=c; G
new :=G
0 ; 10. G:=Gnew;
11. until(benet=false); 12. returnG;
Figure9: Algorithm Merge
binesthemintoasinglequery. Query merging canreduce the datacommunicationoverhead,and may alsolead to a more eÆcient query plan, since more optimization oppor-tunities are oered for the data source's query optimizer. However, injudicious merging could lead to less execution parallelism since merging queries also result intheir data dependenciesbeing\merged". Thus,querymerginghasto beoptimizedjointlywithqueryscheduling.
Algorithm Merge takes a querydependency graph G as inputanditerativelyderivesanewquerydependencygraph G
0
fromGbydeterminingthe\best"pairofqueriesinGto mergeateachiteration. Twoqueriescanbemergedonlyif theyareexecutedatthesamedatasourceandtheresultant new query dependency graph from their merging remains acyclic. Thecostofthe executionplan foraquery depen-dencygraphGiscomputedusingSchedule(G)asdiscussed intheprevioussection. Theiterativequerymergingprocess continuesuntilnopairofqueriesthatcanbemergedwould leadtoreductionoftheexecutioncost.
ThefunctionmergePairderivesanewdependencygraph G
0
fromaninputdependencygraphGbymergingtwoofits queriesQ1 andQ2 intoasinglequeryQ
0
.Morespecically, G
0
is constructed from G as follows: for each query Q, if Q! G Q 1 or Q! G Q 2 , we add an edge Q! G Q 0 ; similarly, if there is an edge Q1!GQ or Q2!GQ, we add an edge Q
0
!GQ. Finally,weremoveQ1;Q2andalltheiredgesfrom G;theresultinggraphisG
0
,asdepictedinFig.7(c). Wenextdescribe howa newquery Qis generated from themergingoftwoqueriesQ1 andQ2. Forthesimplecase wheretherearenodatadependenciesbetweenQ
1 andQ
2 ,Q issimplytheouter-unionofQ
1 andQ
2
whetherthetuplesarefromQ 1
orQ 2
soastofacilitatethe extractionoftherelevanttuplesfromQatlaterstages. For thecase wherethe queries Q1 and Q2 are related by data dependencies,e.g., Q1!GQ2,they are merged by inlining Q
1 inQ
2
,combiningthecommonkeypaths,asintheouter joinapproachof [15,3].
Theextraction andshippingof relevant tuplesis impor-tant for reducing the communication costs. Consider the example dependency graph in Fig. 7(c), which shows the mergingoftwoqueriesQ1andQ2intoanewqueryQ. Each directededge inthegureis labeledwiththe communica-tioncostofshippingtheoutputofonequerytobeusedas inputforanotherquery. NotethatsinceQ4 needsonlythe outputofQ1(similarly,Q5needsonlytheoutputofQ2),the relevant tuplesfrom Qare extractedbefore shippingthem tothetargetquery;consequently,thecommunicationcosts inGandG
0
remainthesame.
OnecanverifythatAlgorithmMergetakesatmostO(n 5
) timewherenisthesizeofthedependencygraphG. Thisis alsotheoverheadofentireoptimizationphase,includingthe costsofthefunctioncostandAlgorithmsSchedule,Merge.
5.5 Discussion
Wediscusshereseveralextensionsoftheevaluation algo-rithmdescribedpreviously.
We rstdescribethe modicationsnecessaryfor dealing with recursion. In the presence of recursion in the DTD embedded inanAIG , thegraph representation of be-comescyclic. Webeginwith auser-supplied estimatedof themaximumdepthoftheoutputtree,and calculatefrom ita(partial)AIGbyiterativelyunfoldingtherecursiverules untilallnodesthatarestillexpandableareofdepthaboved. Optimizationisperformedatcompiletimeontheresulting
AIG
0
asbefore,withthecaveatthatcertainnodesinthe dependencygraphmayhavequerieswithinputsdepending uponfurtherexpansion. Ifatruntimeallqueriescanbe eval-uated,thecomputationof
0
terminatesandthenaloutput relationsofcanbeproduced. If therearenodesQinthe dependencygraphthatare blockedwaiting for tables that requirefurtherprocessingfortheirmaterialization,thenthe recursionisunrolledagainstartingfromtheelementtypein
0
correspondingtoQ:thisprocesscontinuesuntilallinputs are available, withthe value of d being updatedto reect thenewdepthinformation. Itisworthmentioningthatthe depthof recursiveevaluation of XMLdocumentsfound in practiceisgenerallyfairlysmall[8];henceaconservative es-timateoftherecursiondepthwillyieldanon-recursiveDTD equivalent to theoriginal inmost cases. This allows usto exploitthecost-based estimationusedinthenon-recursive case,whileavoidingasmuchaspossibletheneedtoiterate theprocessatruntime.
We now describe several additional features of the mid-dleware that canlead to signicant performance improve-ments. The algorithm described here made use of static queryschedules for simplicity { signicant eÆciency gains canaccruefromusingdynamicscheduling,inwhicha run-timeschedulerupdatesthequeryplansforeachsitein par-allelwithevaluation,takingadvantageofknowledgeabout workloadondatasources. Additionalgainscomefrom en-hancingthe query-processing powerof the middleware en-gine. For our prototype, the middleware does not pos-sess arelationalengine: anymiddlewareprocessingis
per-patient 2500 3300 5000 visitInfo 11371 14887 22496 cover 2224 3762 8996 billing 175 250 350 treatment 175 250 350 procedure 441 718 923
Table1: Cardinalitiesoftablesfordierentdatasets
be to provide a relational query-processor on the middle-ware,whoseoptimizercanthenbeusedtoestimatethecost ofmiddlewareprocessing.
Relatedwork. Evaluationalgorithmsformiddleware sys-tems has been explored in relational integration systems such as Garlic [17]. Garlic allows cost-based optimization and processing of relational queries overmultiple sources, dealing withissues of scheduling and parallelization as we do,whileallowingforsourceswithlimitedquerycapabilities. IntheXMLcontextthe relationalqueriestobe optimized canbemodiedatthecostofpost-processingtoreconstruct thenaloutputtree. Thespecicationofcomplex interde-pendences in AIGs leads to the problem of optimizing a setofquerieswithDAG-likedependencies,asopposedtoa single query tree insystems such as Garlic. Recent XML publishingmiddlewaresuchas[5,15,26]giveevaluation al-gorithmsspecicallygearedtorelational-to-XMLmappings. Theformalismstherefeaturesingledatasources,and tem-platesthatcorrespondtoxed-depthtop-downevaluation.
6.
Experimental Results
Inordertoverifythe eectivenessof ourquery schedul-ing andquerymergingalgorithms,weconducteda prelim-inary experimental evaluation using the AIG described in Example 1.1. Therelational datasets wereconstructed in two steps: rst, we used the ToXgene data generator
1 to produceXMLdatathatconforms toacanonicalrelational DTD;wethenusedasimpleparserthatreadstheXMLdata and generates acomma-separated le(whichcanbe bulk-loadedintotheRDBMS).Wegenerateddatasetsbyvarying thesizesofthedierentrelations(seeTable1). Further vari-antswereobtainedbyunfoldingtherecursivegrammarrule \procedure ! treatment
" multiple times to obtain non-recursiveDTDswithbetween2to7levelsoftrIdelements. Notethatthemaineectofunfoldingistheincreaseinthe sizeofintermediateresults. Forexample,fortheLargedata set,thecardinalityofa3-wayselfjoinoftheproceduretable is4055,whereasthecardinalityofa4-wayselfjoinis6837. ThequeryplanswererunonDB2v8.1forLinux. Thetotal evaluationtimewascomputedbysimulatingthetransferof temporarytablesamong thedistributed datasources, i.e., themediatoranddierentdatabases, usingdierent band-widths.
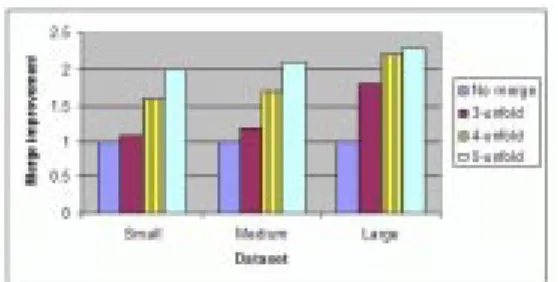
Fig.10demonstratestheimpactofquerymergingonthe performanceofAIGevaluationfordatasetsofdierentsizes andunfoldinglevels. Theevaluationtimeincludesboththe queryevaluationandcommunicationcosts(forabandwidth of1Mbpsamongdatasources). EachentryinFig.10shows the ratio of the evaluation time withoutquery merging to thatwithquerymerging. Theresultsclearlydemonstrate asignicantgaininperformance(uptoafactorof2:2)when querymergingisenabled. Asexpected,theperformance im-provementincreaseswithlargerdatasetsandmorecomplex
Figure 10: Improvementduetoquerymerging
DTDs.
7.
Conclusion
We have proposed a new approach for integrating rela-tional data from dierent sources into an XMLdocument underbothsyntacticandsemanticconstraints.Thisisbased onanovelnotion ofAIGs. AIGsnotonlyyieldauniform frameworkfor ensuringbothDTD-conformance and XML-constraintsatisfactionindataintegration,butalsoprovide the ability to support data-driven and context-dependent generationofXMLdocuments. Wehavealsoimplemented aprototypeofamiddlewaresystemforevaluatingAIGs ef-ciently. Thesystemexploresnewoptimizationtechniques for merging and scheduling queries over multiple sources inthepresences ofDAG-likeinter-querydependencies;our preliminaryexperimentalresultsshowthatthesetechniques yieldsubstantialreductionsinprocessingtime.
Severalextensionstotheoptimizationframeworkare tar-geted for future work. We intend to incorporatedynamic scheduling algorithms, and to make use of selectivity esti-mateswithinourcostfunction. Intheoptimizationprocess, werecognizetheneedtotakeintoaccountbothrestrictions onthecapabilities ofsources(asin[17])andlimitationson processing power andcachememory size onthe mediator. Weare alsoinvestigatingmethods forstaticallygenerating query plans for AIGs based on recursive DTDs, utilizing statisticsonthedepthofchainswithinsourcerelations. Fi-nally,wearestudyingextensionsofAIGswhichyield map-pingsthatareguaranteedtobeinformation-preserving.
Acknowledgments: Wenfei Fanis supportedinpart by NSFCareer Award IIS-0093168 and NSFC 60228006. We thankDenilsonBarbosaforhelpingusgeneratethedatasets usedintheexperiments.
8.
References
[1] M. Arenas, W.Fan, and L. Libkin.Onverifying con-sistencyofXMLspecications.InPODS,2002.
[2] C.Baru,A.Gupta,B.Ludascher,R.Marciano,Y. Pa-pakonstantinou, P.Velikhov, andV.Chu.XML-based informationmediationwithMIX.InSIGMOD,2000.
[3] M.Benedikt,C.Y.Chan,W.Fan,R.Rastogi,S.Zheng, and A.Zhou.DTD-directed publishingwith attribute translationgrammars.InVLDB,2002.
[4] T.Bray,J.Paoli,andC.M.Sperberg-McQueen. Exten-sibleMarkupLanguage(XML) 1.0. W3C Recommen-dation,Feb.1998.http://www.w3.org/TR/REC-xm l/.
[5] M. J.Carey, D.Florescu, Z.G. Ives, Y. Lu,J. Shan-mugasundaram, E. J. Shekita, and S. N. Subrama-nian. XPERANTO: Publishing object-relational data
3.0.MorganKaufmann,2000.
[7] D.Chamberlinetal.XQuery1.0: AnXMLQuery Lan-guage.W3CWorkingDraft,June2001.
http://www.w3.org/TR/xquery.
[8] B.Choi.WhatarerealDTDslike.InWebDB,2002.
[9] J.Clark. XSLTransformations (XSLT).W3C Recom-mendation,Nov.1999.http://www.w3.org/TR/xslt.
[10] S. Cluet,C.Delobel, J.Simeon, and K.Smaga. Your mediatorsneeddataconversion! InSIGMOD,1998.
[11] H. Comon, M. Dauchet, R. Gilleron, F. Jacquemard, D. Ligiez, S.Tison, and M.Tommasa. Tree Automata TechniquesandApplications.Online,1999.
[12] S. Davidson and A. Kosky. WOL: A language for database transformations and constraints. In ICDE, 1997.
[13] P. Deransart, M. Jourdan, and B. Lorho (eds). At-tributeGrammars.LNCS323,1988.
[14] R.Fagin,P.Kolaitis,R.Miller,andL.Popa.Semantics andqueryanswering.InICDT,2003.
[15] M.F.Fernandez,A.Morishima,andD.Suciu.EÆcient evaluation of XML middleware queries. In SIGMOD, 2001.
[16] M. GareyandD.Johnson.Computersand Intractabil-ity: AGuidetotheTheoryofNP-Completeness.W.H. FreemanandCompany,1979.
[17] L.M.Haas,D.Kossmann,E.L.Wimmers,andJ.Yang. Optimizing queries across diverse data sources. In VLDB,1997.
[18] D. Kossman.Thestateofthe artindistributedquery processing. ACM Computing Surveys, 32(4):422{469, December2000.
[19] M. Lenzerini.Dataintegration: Atheoretical perspec-tive.InPODS,2002.
[20] T.Milo andS.Zohar.Usingschemamatchingto sim-plifyheterogeneousdatatranslation.InVLDB,1998.
[21] F.NevenandJ.V.denBussche.Extensionsofattribute grammars for structured document queries. JACM, 49(1):56{100, 2002.
[22] Y.PapakonstantinouandV.Vianu.Typeinferencefor viewsofsemistructureddata.InPODS,2000.
[23] L. Popa,Y.Velegrakis,R.J.Miller,M.A.Hernandez, andR.Fagin.Translatingwebdata.InVLDB,2002.
[24] E. RahmandP.A.Bernstein.A surveyofapproaches toautomaticschemamatching.VLDBJournal,2001.
[25] V. Rayward-Smith, F. Burton, and G.J.Janacek. SchedulingParallelProgramsAssumingPreallocation. InP.Chretienne,E. Coman,J. Lenstra, andZ. Liu, editors, Scheduling Theory andits Applications, pages 145{165.JohnWiley&Sons,1995.
[26] J. Shanmugasundaram, J. Kiernan, E. J. Shekita, C. Fan, and J. Funderburk.Querying XML views of relationaldata.InVLDB,2001.
[27] J. Shanmugasundaram,E. J. Shekita, R. Barr, M. J. Carey,B.G.Lindsay,H.Pirahesh,andB.Reinwald. Ef-cientlypublishingrelationaldataasXMLdocuments. VLDBJournal, 10(2-3):133{154,2001.
[28] H.Thompsonetal.XMLSchema.W3CWorkingDraft, May2001.http://www.w3.org/XML/Schema .