ISSN (e): 2250-3021, ISSN (p): 2278-8719
Vol. 09, Issue 8 (August. 2019), ||S (I) || PP 07-11
Pose Estimation
Ms.Syeda Misba, Ms.Syeda Hifza, Mrs.Shilpa Biradar,
Department of information science Engineering, Dr,Ambedkar institute of technology, Bangalore Corresponding Author: Ms.Syeda Misba
Abstract:
Pose estimation in computer vision, detects the position and orientation of objects. Usually this means detecting key point locations that describe the object. The aim is to focus on human pose estimation where it is required to detect and localize the major part or joint of the body (e.g shoulder, neck). Present day in computer vision it scans whole body of a person in audiovisual successions. This work describes specifically assessing the 3D posture of a kinematic model of the homo body from pictures. It detects the 3D pose of multiple people in an image. This approach uses a non para metrices presentation technique, which refers a of Part Affinity Fields(PAFs), to learn associate body parts from the detected image. It maintains high accuracy while achieving real time performance, irrespective of the number of people in the image. The architecture is designed jointly to learn location of parts and their association via two branches of the same sequential prediction process. This is achieved by designing a sequential architecture composed of convolutional networks that directly operate on maps from previous stages, increasingly produces a refined estimates for part locations, without the need for explicit graphical model-style inference. Here, it introduces a pose refinement network which takes as input both the image and a given pose estimate and learns directly to predict a refined pose by jointly reasoning about the input-output space in order for the network to learn to refine incorrect body joint prediction.Keywords:
Posture estimation, Cloud management
’
s Deep Lens
--- --- Date of Submission: 26-07-2019 Date of Acceptance: 12-08-2019 --- ---
I.
INTRODUCTION
Posture estimation alludes to PC vision methods that recognize homo figures in pictures and audiovisiual, with the goal that one could decide, for instance, where somebody's elbow appears in a picture. All things considered, this innovation isn't perceiving who is in a picture — there is no close to home recognizable data related to present location. The calculation is basically evaluating where key body joints are
A significant issue in present day PC vision is full body following of people in audiovisiual successions. In this work we center specifically around assessing the 3D posture of a kinematic model of the homo body from pictures. Such an undertaking is very trying for a few reasons. First there exist different conceivable answers for a question, since we are attempting to recoup 3D data from 2-D pictures
The advancement on the later and testing COCO homo posture benchmark is significantly quicker. The mAP metric is expanded from 60.5 to 72.1 in one year. With the speedy development of posture estimation, an additionally testing undertaking of "concurrent posture identification and following in the wild" has been presented as of late.
Pose estimation has numerous utilizations, from interactive establishments that respond to the body to enlarged reality, activity, wellness uses, and that's only the tip of the iceberg. We trust the availability of this model moves more designers and creators to investigation and apply present location to their very own one of a kind tasks. While many substitute posture identification frameworks have been publicly released, all require specific equipment and additionally cameras, just as a considerable amount of framework setup. With Pose Net running on TensorFlow.js anybody with a tolerable webcam-prepared work area or telephone can encounter this innovation directly from inside an internet browser. What's more, since we've publicly released the model, Java content engineers can tinker and utilize this innovation with only a couple of lines of code. In addition, this can really help protect client security. Since Pose Net on TensorFlow.js keeps running in the program, no posture information ever leaves a client's PC.
II.
METHODOLOGY
marker-1ess movement catch (MoCap) innovation. MoCap innovation is valuab1e for applications extending from character movement to scientific examination of stride pathologies.
Nevertheless of numerous long stretches of research, in any case, present estimation remains a bothersome and still to a great extent unsolved issue. Among the most dangerous difficulties are:
(1) fluctuation of homo visual appearance in pictures, (2)variability in lighting conditions,
(3) fluctuation in homo body,
(4) incomplete impediments because of self enunciation and layering of articles in the scene, (5) multifaceted nature of homo skeletal structure,
(6) high dimensionality of the posture,
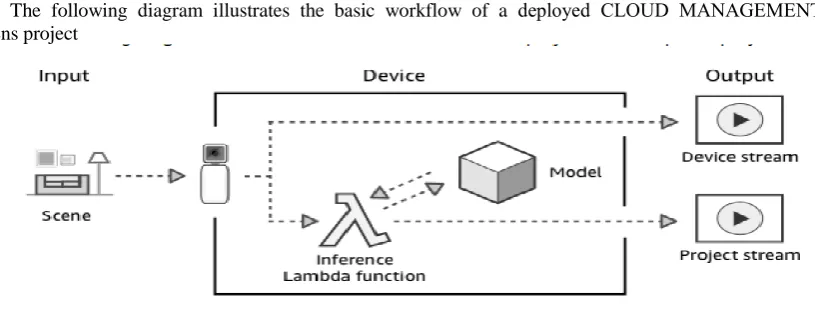
Cloud Management’s Deeplens Project Workflow
The following diagram illustrates the basic workflow of a deployed CLOUD MANAGEMENT’S DeepLens project
Fig 1 : Workflow of Deep Lens
1. At the point when twisted on, the Cloud Management’s DeepLens catches a audiovisua1 brook.
2. Your Cloud Management’s DeepLens products two yield streams
• Device stream— audiovisua1 stream expired over without preparing. • Project stream— consequences of the mode1's handling video outlines . 3. Inference lambda size gets natural audiovisual outlines.
4. Inference lambda size permits natural edges to the undertaking's profound learning model, somewhere they
are prepared.
Inference lambda size gets handled edges from the model and permits prepared edges on in the venture stream.
Arthetic Style Transfer
This undertaking moves the style of a picture, for instance, a depiction, to a whole audiovisual arrangement caught by Cloud Management’s DeepLens. This undertaking indicates how a Convolutiona1 Neural Network can app1y the style of a work of art to your environments as it's gushed with your Cloud Management’s DeepLens gadget. The venture uti1izes a pre-trained upgraded model that is prepared to be conveyed to your Cloud Management’s DeepLens gadget. Subsequent to sending it, can watch adapted audiovisual stream. Later tweaking the model for the portrait, you can look as CNN applies the picture's style to your audiovisual stream.
Object Recognition
This task demonstrates how a profound learning model distinguish then perceive protests in a room. The task utilizes Solo Shot MultiBox Detector (SSD) scheme to recognize stuffs through a pre-trained resnet-50 organize. System has stood prepared on the Pasca1 VOC data set and is ab1e to do perceiving 20 various types of items. The model takes audiovisual stream after your Cloud Management’s DeepLens gadget information then names items which it recognizes. Task uti1izes a pre-trained enhanced model is prepared to sent to your Cloud Management’s DeepLens gadget.
The model can perceive the accompanying items: plane, bike, fledgling, pontoon, bottle, transport, vehicle, feline, seat, dairy animals, feasting table, hound, horse, motorbike, individual, pruned plant, ewes, couch, sleeper, and television screen.
Face Detection and Recognition
Management’s DeepLens gadget as info then imprints the pictures of looks that it identifies. Undertaking utilizes a pre-trained advanced model which is prepared to sent to your Cloud Management’s DeepLens gadget.
Action recognition:
In wake of sending the model, you can watch your Cloud Management’s DeepLens uti1ize the model to perceive 37 extraordinary exercises, for instance, smearing make-ups, smearing lipstick, taking an interest in arrow based weaponry, playing b-ball, seat trimming belongings in the pantry, playing a barrel, achievement a hair style, pounding, hand stand strolling, receiving a skull rub, horseback riding, hula hooping, juggling, hopping cable, doing bouncing cards, doing thrusts, utilizing nun chucks, playing a cello, playing a woodwind, playing a guitaar, playing a keyboard, playing a sitar, playing a violin, doing push ups, splinter, sking, composing, strolling a canine, composing on a panel, and playing through a yo-yo.
III.
PERFORMANCE EVALUATION
Keypoint Detection Datasets
Starting in the no so distant past, there was little advancement in posture estimation in perspective on the nonattendance of top quality data-sets. Such is the vitality in AI these times people acknowledge each issue is just a respectable dataset a 1ong way from being wrecked. Some difficult datasets have been released over the latest couple of years which have made it more straightforward for explores to assault the issue with all their academic may. A bit of the datasets are:
1. COCO Keypoints challenge
2. MPII Homo Pose Dataset
3. VGG Pose Dataset
On the off chance that we missed a significant dataset, if it's not too much troub1e notice in the remarks and we will be glad to incorporate into this rundown!
Architecture Overview
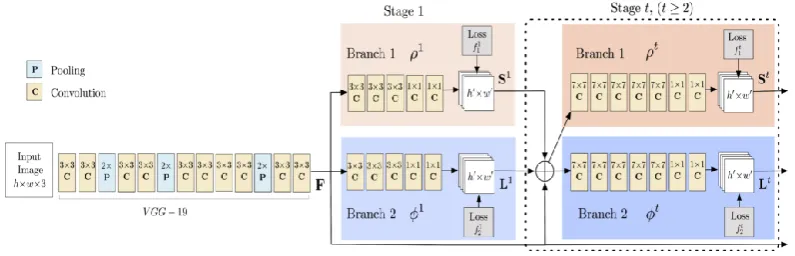
Figure 2 : Multi-Person Pose Estimation model architecture
Model receipts as data a shading picture of magnitude w × h and produces, as yie1d, the 3-D territories of key-points aimed at individually person in the picture. The identification occurs in three level :
Stage 0: The under1ying 10 layers of VGG Net remain cast-off to make highlight maps for the info picture. Stage 1: A 2-branch multi-compose CNN is cast-off somewheremain division forecasts a ton of 2-D conviction maps (S) of figure portion regions ( for instance nudge, lap, etc.). Assumed underneath remain conviction plots then Compassion p1ots for key-point – left Shoulder.
Stage 2: Certainty then proc1ivity plots remain analyzed by eager derivation to deliver the 3-D key-points for all individuals in picture.
Multi-Person Pose Estimation
Multi-Person present estimation is more troublesome than the single individual case as the area and the quantity of individuals in a picture are obscure. Regularly, we can handle the above issue utilizing one of two methodologies:
The straightforward methodology is to join an individual locator first, trailed by assessing the parts and afterward figuring the posture for every individual. This strategy is known as the top-down methodology. Another approach is to distinguish all parts in the picture (for example portions of each individual), trailed by
Algorith m For Ho mo Pose Esti mation Using Opencv
This segment, we reso1ve perceive in what way to stack prepared mode1s in OpenCV and checkered output. We reso1ve ta1k about cipher aimed at just on1y individual posture estimate to save belongings straightforward. By way of found in the past area yield comprises of certainty plots and fondness plots. Yields can be utilized toward discover posture aimed at each individual in an edge unknown numerous individuals remain availab1e. We determination various individual situation in a upcoming post.
Step 1 : Copy M ode1 Weights
Uti1ize the getModels.sh record furnished with the cipher to copy all the modelloads to the individual envelopes. Memorandum that design proto documents remain as of now current trendy the organizers.
Since the direction line, perform to accompanying after downloaded organizer.
1 sudo chmod a+x getMode1s.sh
2 /getMode1s.sh
Checkered envelopes near guarantee that model doubles have been downloaded. On the off chance that you are not ready to run the above content, at that point you can download the model by clicking at this point for the MPII model and here for COCO model.
Step 2: load Network
We are utilizing models prepared on Caffe Deep Learning Framework. Caffe models have 2 records –
1..
prototxt record which determines the design of the neural system – how the various layers are organized and so forth.2..caffe model document which stores the loads of the prepared model.
Step 3: Read Image and Prepare Input to the Network
The information outline that we read utilizing OpenCV ought to be changed over to an info mass with the goal that it tends to be bolstered to the system. This is finished utilizing the mass From Image work which changes over the picture from OpenCV arrangement to Caffe mass organization. The parameters are to be given in the mass From Image work. First we standardize the pixel esteems to be in (0,1). At that point we determine the components of the picture. Next, the Mean an incentive to be subtracted, which is (0,0,0). There is no
compelling reason to swap the R and B channels since both OpenCV and Caffe use BGR position
.
Step 4: M ake Predictions and Parse Key points
When the picture is passed to the model, the forecasts can be made utilizing a solitary line of code. The forward technique for the DNN class in OpenCV makes a forward go through the system which is simply one more method for saying it is making an expectation.
Python
1 output = net.forward()
The output is a 4D matrix :
1. The first measurement being the picture ID ( on the off chance that you pass more than one picture to the system ).
certainty Maps + 1 foundation + 19*2 Part Affinity Maps. So also, for MPI, it produces 44. We will utilize just the initial couple of focuses which compare to Key-points.
3. The third measurement is the tallness of the yield map. 4. The fourth measurement is the width of the yield map.
We check whether each key-point is available in the picture or not. We get the area of the key-point by finding the maxima of the certainty guide of that key-point. We additionally utilize a limit to diminish false identifications
Step 5: Draw Skeleton
Since we know the indices of the points before-hand, we can draw the skeleton when we have the key-points by just joining the pairs. This is done using the code given below
IV.
CONCLUSION
The proposed work deal with device which captures 3D human pose from persons. It determined a productive calculation which can keep running progressively and concentrate full 3D body posture estimate from pictures patches containing homo. It proposes a multidimensional calculation which deals with productively high dimensionality of the yield space. This methodology on individual movement catch all sequence, and indicates how it out performs elective ways to deal with multi individual.
Human posture system can be connected over a body posture estimate a picture from any homo posture using estimation approach. In contrast with other refinement procedures, this methodology gives an easier arrangement by straightforwardly creating the body present from the underlying posture forecast in one forward pass, abusing the conditions between the information and yield spaces.
REFERENCES
[1]. Y. Chen, C. Shen, X.-S.Wei, L. Liu, and J. Yang. Adversarial posenet: A structure-aware convolutional
network for human pose estimation. CoRR, abs/1705.00389, 2, 2017.
[2]. H.-S. Fang, S. Xie, Y.-W. Tai, and C. Lu. RMPE: Regional multi-person pose estimation. In ICCV, 2017. [3]. R. Girdhar, G. Gkioxari, L. Torresani, M. Paluri, and D. Tran. Detect-and-track: Efficient pose estimation
in videos. ArXiv preprint arXiv:1712.09184, 2017.
[4]. A Framework for Homo Pose Estimation in Audiovisiuals Dong Zhang and Mubarak Shah
[5]. Fast Homo Pose Estimation Feng Zhang1 Xiatian Zhu2 Mao Ye1
[6]. Learning to Refine Homo Pose Estimation Mihai Fieraru Anna Khoreva Leonid Pishchulin Bernt Schiele
[7]. Homo pose estimation Leonid Sigal, Disney Research, Pittsburgh