PERFORMANCE OF K-MEANS
CLUSTERING AND BIRD FLOCKING
ALGORITHM FOR GROUPING THE
WEB LOG FILES
R. SUGUNA
Assistant Professor
Department of Computer Science and Engineering Arunai College of Engineering,
Thiruvannamalai – 606 603 [email protected]
D. SHARMILA
Professor and Head
Department of Electronics and Instrumentation Engineering Bannari Amman Institute of Technology
Sathyamangalam- 638 401 [email protected]
Abstract
Data mining is the process of analyzing the interesting pattern and knowledge in different perspectives and summarizing it into useful information from the large amount of data. Technically, data mining is the process of finding correlations or patterns among dozens of fields in large relational databases. The unlabled vast amount of data can be grouped using clustering or classification algorithms. Cluster analysis or clustering is the task of assigning a set of objects into groups called clusters. So, the objects in the same cluster are more similar to each other than to those in other clusters. Many of the researchers evaluated the performance of the familiar K-means clustering algorithm and attempt to improve the efficiency of the algorithm. This paper will analyze the performance of the K-means clustering algorithm with the biological based algorithm called Bird flocking algorithm for grouping the web logs. Web logs are unformatted text files which contains the information regarding the user’s browser detail. The proposed system takes the input as web log files and groups the web sites based on the interesting rate of the users. The performance is evaluated in terms of no of clusters, CPU utilization time and accuracy.
Keywords: K-Means Clustering; Bird flocking algorithm; Web Logs. 1. Introduction
In today’s world data is increased in numerous amounts. Every day millions of people accessing the web sites and viewing the web pages for getting information, sharing information and making decisions. The user’s website accessing details are stored in web servers in the form of unformatted text files called “web logs”. It is always better to pre process the web logs [1-3] by eliminating noise and redundancy. A few sites consist of large number of pages, but millions of sites only contain a handful of pages. Few sites contain millions of links, but many sites have one or two. When users visit the web pages they leave ample information in web server log, which is structurally complex, large in size and ever growing in nature.
Web mining [1-4] is all about collecting all this information process them and extract useful content as per the requirement of the user or client. Web usage mining is a sub section of the web mining. The main aim of the web usage mining is to collect the usage of a particular website or websites. Web usage mining is the field of data mining which deals with the uncovering and analysis of usage patterns from web data, specifically web logs, in order to improve web based applications.
pages are accessing by whom, how much time user is accessing a particular page. Since log files are unformatted text files, they are complex to understand and study. So, the Web log files are preprocessed to eliminate the unwanted information to make the log files easy to handle. The main aim of this paper is to cluster the web log files based on the user’s interesting rate of accessing the web sites by using K-Means clustering algorithm and Bird flocking algorithm. The performance of both the algorithms is compared with the measures (i) no of clusters (ii) CPU time and (iii) Accuracy.
The paper is organized as follows: The reviews of the Related Works are present in the Section 2. Section 3 describes the algorithms for K-means and Bird flocking algorithm, Section 4 describes the Result and Analysis. Finally Conclusion and Future work is described in Section 5.
2. Related Works
The researchers are attempted to evaluate the performance of the K-means clustering algorithm with the variations of K-means algorithms (e.g., Particle Swarm Optimization (PSO) based K-means, Fuzzy K-means, hard K-means). In our existing work [5], we have proposed bird flocking algorithm with new separation, alignment and cohesion rule for grouping the web log files. The web log files are pre processed to support the bird flocking algorithm.
Lopamudra Dey and Anirban Mukhopadhyay [6] have done the work on clustering analysis of microarray gene expression data. Microarray consists of large number of gene sequences under multiple conditions. This technology is used to concurrently monitor the expression levels of thousands of genes and across collection of related samples. The most important area of microarray technology is the data clustering analysis. The author used PSO based K-means clustering algorithm for clustering the microarray genes. The newly proposed algorithm given better accuracy than K-Means clustering algorithm for grouping the data. Xiaohui Cui et al. [7] have presented a novel flocking based approach for document clustering analysis. The flocking clustering algorithm uses stochastic and heuristic principles discovered from observing bird flocks or fish schools. The flocking based algorithm does not require any initial partitional seeds. The algorithm generates a clustering of a given set of data through the embedding of the high-dimensional data items on a two-dimensional grid for easy clustering result retrieval and visualization. The authors evaluated the efficiency of flocking algorithm with both a synthetic dataset and a real document collection that includes 100 news articles collected from the Internet. The results shown that the flocking clustering algorithm achieves better performance compared to the K- means and the Ant clustering algorithm for real document clustering.
Ujjwal Maulik and Sanghamitra Bandyopadhyay [8] have evaluated the performance of three clustering algorithms, hard K-Means, single linkage, and a simulated annealing (SA) based technique, in conjunction with four cluster validity indices, namely Davies-Bouldin index, Dunn’s index, Calinski-Harabasz index, and a recently developed index I. Based on a relation between the index I and the Dunn’s index, a lower bound of the value of the former is theoretically estimated in order to get unique hard K-partition when the data set has distinct substructures. The effectiveness of the different validity indices and clustering methods in automatically evolving the appropriate number of clusters is demonstrated experimentally for both artificial and real-life data sets with the number of clusters varying from two to ten. Once the appropriate number of clusters is determined, the SA-based clustering technique is used for proper partitioning of the data into the said number of clusters. B. Bahmani Firouzi et al. [9] have proposed a hybrid evolutionary algorithm based on the combination of PSO, SA and K-means algorithms, called PSO-SA-K, which can find better cluster partition. The performance is evaluated through several benchmark data sets. The simulation results show that the proposed algorithm outperforms previous approaches, such as PSO, SA and K-means for partitional clustering problem.
Kanungo T et al. [10] have done a simple and efficient implementation of Lloyd's k-means clustering algorithm. This algorithm is easy to implement, requiring a kd-tree as the only major data structure. They established the practical efficiency of the filtering algorithm in two ways. First, a data-sensitive analysis of the algorithm's running time, which shows that the algorithm runs faster as the separation between, clusters, increases. Second, a number of empirical studies both on synthetically generated data and on real data sets from applications in color quantization, data compression, and image segmentation.
3. Clustering Fundamentals
are similar to each other according to a specified similarity (distance) measure. Clustering is a sequential process which takes patterns (data) as a raw material and produces clusters as a result.
Data Selection of Data Representation Clustering n Clusters
Procedure
Feedback
Fig. 1. Steps in Clustering Process
3.1 K-Means Clustering Algorithm
The k-means [11-14] method partitions the data set into k subsets such that all points in a given subset are closest to the same centre. In detail, it randomly selects k of the instances to represent the clusters. Based on the selected attributes, all remaining instances are assigned to their closer centre. K-means then computes the new centers by taking the mean of all data points belonging to the same cluster. The operation is iterated until there is no change in the gravity centres. If k cannot be known ahead of time, various values of k can be evaluated until the most suitable one is found.
Most commonly used proximity measure, at least for ratio scales (scales with an absolute 0) is the Minkowski metric, which is a generalization of the normal distance between points in Euclidean space. It is defined as,
(1)
where, r is a parameter, d is the dimensionality of the data object, and xik and xjk are, respectively, the kth components of the ith and jth objects, xi and xj.
Algorithm 1. K-means clustering algorithm
Input:
D = {t1, t2, t3 …, tn} //set of elements
K //number of desired clusters
Output:
K //set of cluster
Clustering algorithm:
Assign each item ti to a cluster randomly; Calculate mean for each cluster;
Repeat:
Assign each item ti to the cluster which has the closet mean;
Calculate new mean for each cluster;
Calculate square error;
Until
The minimum total square errors are reached.
3.2 Bird Flocking Algorithm
The bird flocking algorithm [15] is swarm intelligence algorithm based on the behavior of bird flock. The bird flocking was introduced by C. Reynolds as boids model. The following Algorithm shows the structure of a typical Boids model. A boid is the representation of a bird in the bird flocking algorithm. The main features affecting a boid are the speed and course of the flock. The speed and course of the boids are controlled Reynolds rules.
Feature Extraction
Similarity
Algorithm 2. Bird flocking algorithm
Data: A group of boids. For each Frame do For each boid do
Separation (boid); Cohesion (boid); Alignment (boid); End
For each boid do
boid.x ← cos(boid.course) * b.velocity * dT ime; boid.y ← sin(boid.course) * b.velocity * dT ime; End
End
Reynolds have defined three rules for updating the speed and course of the boids, the rules are defined as, Cohesion rule is the rule that keeps the flock together, without it there would not be any flocking at all, separation rule is the rule the steer boids to avoid collisions and alignment rule, tries to make the boids mimic each other’s course and speed.
3.2.1 The New Separation, Alignment and Cohesion Rules
According to the new rules [16] defined by Marcio Frayze David and Leandro Nunes de Castro the three behavioral rules are redefined. The rules are redefined based on their affinity value. The rules are followed as, Separation rule: The strength of the separation between two Boids is inversely proportional to the affinity between the Boids, the lower the value of affinity, the greater the separation force between them. Alignment rule: The degree of alignment varies with the affinity between the Boids, the greater the affinity value between the Boids, the harder the alignment between them. Cohesion rule: The strength of cohesion varies with the Boids affinity, the greater the affinity value, the stronger the cohesion, and vice-versa. By following these three rules, new clusters are formed.
3.2.2 Affinity Calculation
Web logs are pre processed to support the new alignment, separation and cohesion of bird flocking algorithm. The following five details are considered for clustering process. (i) Ip address, (ii) User name, (iii) Web site or URL, (vi) Session time and (v) Frequency. The web log details of each user are represented as boid. If there are n numbers of users, then n numbers of boids are considered in a dataset.
1 2
[
,
,...,
n]
D
x x
x
Where D is considered as the set of boids, x represents a boid in the dataset D and n is the total number boids present in the dataset. Now each of these boids is subjected for the Affinity calculation process. The affinity is based on the interesting measure based on each boids and is used for grouping the same type of boids. The affinities Aij between two boids are calculated using the following equation.
2
1
(
)
L
i j i k j k
k
A
x
y
Where xi and yj are the boids considered for similarity calculation, L- total length between Boids xi and yj. The Euclidean distance between the objects is adapted for the calculation affinity value between the boids from the database that these Boids represent. The affinity value is related to the centroid of the boids for finding the chances of a boid to stay or leave the group.
4. Result and Analysis
The performance of the both the algorithms are evaluated in the following section under different evaluation criteria. The algorithms are implemented in JAVA language and executed on a core i3 processor, 3.06MHZ, 4 GB RAM computer. The weblogs of 50 user’s details are collected from the server system of our institute and considered for evaluation of the algorithms in various evaluation criteria. The evaluation criteria considered for
(2)
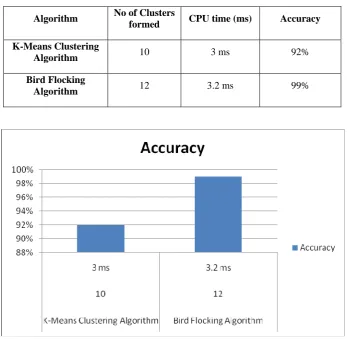
Table 1: Comparison of K-means clustering and Bird flocking algorithm
Algorithm No of Clusters
formed CPU time (ms) Accuracy
K-Means Clustering
Algorithm 10 3 ms 92%
Bird Flocking
Algorithm 12 3.2 ms 99%
Fig. 4. Performance evaluation of K-means clustering and Bird flocking algorithm
5. Conclusion and Future work
The performance of K-means clustering algorithm is compared with the Bird flocking algorithm with the evaluation criteria: (i) no of clusters, (ii) CPU time and (iii) accuracy. The K-means algorithm formed the less number of clusters with short period of time. But for the accuracy consideration issue, Bird flocking algorithm given better result. The aim of forming the cluster is to analyze and understand the user’s website accessing behavior for better customization and recommendation of the web sites. The numerous amounts of users daily accessing the web, so the size of web server is increasing in a dense manner day by day. Accurate grouping of users is an important thing to understand the user’s browsing behavior. Bird flocking algorithm gives better result for grouping the users based on their browsing details. In future, this grouping may be used for customizing the web sites.
References
[1] Kosala, R.; Blockeel, H. (2000). Web mining research: a survey, SIGKDD explorations: newsletter of the special interest group (SIG) on knowledge discovery & data mining, ACM 2(1), pp.1–15.
[2] Cooley, R.; Mobasher, B.; Srivastava, J (1997). Web mining: Information and pattern discovery on the World Wide Web, Proc. of the IEEE International Conference on Tools with AI, pp.558-567.
[3] Balaji, L; Dr. Murthy, Y. S. S. R (2012). An Effective Web Usage Mining, IJECCE, Vol 3(3), pp. 281-286.
[4] Suguna, R.; Sharmila, D. (2012). Article: An Overview of Web Usage Mining, International Journal of Computer Applications, Vol 39 (13), pp. 11-13.
[5] Suguna, R.; Sharmila, D. (2012). User Interest Based Web Usage Mining using a Modified Bird Flocking Algorithm, European Journal of Scientific Research (EJSR), Vol 86(2), pp. 218-231.
[6] Lopamudra Dey; Anirban Mukhopadhyay. Microarray Gene Expression Data Clustering using PSO based K-means Algorithm, International Journal of Computer Science and its Applications. [ISSN 2250 - 3765]
[7] Xiaohui Cui; Jinzhu Gao; Thomas E. Potok. (2006). A flocking based algorithm for document clustering analysis, Journal of Systems Architecture.
[8] Ujjwal Maulik; Sanghamitra Bandyopadhyay. (2002). Performance Evaluation of Some Clustering Algorithms and Validity Indices, IEEE transactions on pattern analysis and machine intelligence, Vol. 24(12).
[10] T Wu A. Y.; et. al., An efficient k-means clustering algorithm: analysis and implementation, IEEE Transactions Pattern Analysis and Machine Intelligence, Vol.24 (7), pp. 881 – 892.
[11] http://www-users.cs.umn.edu/~han/dmclass/cluster_survey_10_02_00.pdf
[12] Khaled Alsabti,; Sanjay Ranka,; Vineet Singh,. An Efficient K-Means Clustering Algorithm.
[13] Bonner, R. E. (1964). Some clustering techniques, IBM journal of Research and Development, 8(1), pp. 22-3. [14] Hartigan, J. A.; Wong, M. A. (1979). A K-Means clustering algorithm, Blackwell Publishing, Vol.28, pp. 100-108.
[15] Craig, W. Reynolds. (1987). Flocks, herds and schools: A distributed behavioral model, Proceeding SIGGRAPH '87 Proc. of the 14th annual conference on Computer graphics and interactive techniques, pp. 25 – 34.