International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 3, Issue 5, May 2013)
513
“Role of Component Based Systems in Data Mining & Cloud
Computing”
Rimmy Chuchra
1, Mahak Jindal
2, Bharti Mehta
31
Asst.Proff (CSE) & Sri Sai University (SSU),Palampur(HP) 2,3M.Tech(CSE) & Yadwindra college of Engg. Talwandi Sabo
Abstract--In this paper we proposed a “Collaborative approach” which tells how component based systems are used with data mining as well as cloud computing. Data Mining helps for extracting potentially useful information from the raw data. The function of association rules are an important data mining technique used to find the interesting relationship with the other related objects. The logical significance to study the concept of dependency in component based systems with data mining is to show the relation between one or more products where a change of one season to another season leads to a potential for a change of one product offer to another product offer. These association rules can either be use at a single level or in multiple levels. Sometimes, association rules becomes important because of output of one rule may be act as an input for other rules. In this way, we can say that limited numbers of association rules are generated at different levels. Data mining techniques help businesses to become more efficient by reducing costs. Here, we uses two types of data mining techniques called “Feature Selection & feature extraction” and “Attribute importance” which helps us for “Product Mining”. Data mining techniques and applications are very much needed in the cloud computing paradigm. When we implement data mining techniques with cloud computing then it will allow the users to retrieve meaningful information from virtually integrated data warehouse that reduces the costs of infrastructure. The major benefit to combine component based systems with cloud computing is it is very easy to use with “platform as a service”. The other benefits to combine these concepts are making systems more reliable, well maintained and also cost effective.
Keywords - Association rules, attribute importance, feature selection, feature extraction, cloud computing, component based systems, dependency, product mining.
I. INTRODUCTION
In this research paper, we are discussing about three major fields which are data mining, cloud computing and CBS (component based systems) in software engineering.
Data mining is a technique which is used for the extraction of hidden predictive information from large databases.
The goal of data mining is to extract knowledge from a data set in a human-understandable language involves database, data management, data pre-processing, model and inference considerations, interestingness metrics etc. The Growing Reasons for Data mining is to Growing Data Volume ,Limited Human Analysis , Low Cost Machine Learning etc. The major objective of data mining is to fast retrieval of data and information, knowledge discovery from databases, to detect hidden patterns which are previously unknown and time saving. There are several types of data mining techniques are available in the market like clustering, classification, regression analysis, feature extraction, decision trees, neural networks, attribute selection, statistics, association rules, rule induction etc. Here, in this research paper we are using three techniques whose names are feature extraction, attribute selection and association rules. Each technique can be explained one by one.
A. Association rules: -There are various benefits to use this data mining technique. It helps to find out the interesting relationship between the products and their values in the market. It becomes more popular in market basket analysis because of all possible combinations of potentially interesting product groupings can be explored. Only for this reason a limited number of attributes are able to generate hundred of association rules. To implement association rules we use “Apriori Algorithm” that only process discrete category data and avoid numeric data. This algorithm helps to examine baskets of items and generate rules for those baskets containing minimum number of items. In this way we can easily generate a chain of associations by using “Apriori Algorithm”. The major benefit to use this technique is the output attribute for one rule can be act like an input for another rule. Sometimes these become more useful due to main two reasons:
1) Accuracy: - How often is the rule correct?
2) Coverage: - How often does the rule apply?
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 3, Issue 5, May 2013)
514
While selecting these interesting rules from the set of all possible rules we can easily find out the relation of one product with any other product.
Our major objective is to achieve “Product Mining” that means find out the complete description about the product either product selling or product purchasing from the market.
B. Feature Selection: - It is also used in data mining techniques to describe the tools and techniques available for reducing inputs to a manageable size for processing and analysis. Feature selection implies not only cardinality reduction, which means imposing an arbitrary or predefined cutoff on the number of attributes that can be considered when building a model, but also the choice of attributes, meaning that either the analyst or the modeling tool actively selects or discards attributes based on their usefulness for analysis.
The ability to apply feature selection is critical for effective analysis, because datasets frequently contain far more information than is needed to build the model.
C. Feature Extraction:- It helps to produces new attributes as linear combination of existing attributes.
This technique is used in various real world applications like application for text data, latent semantic analysis, data compression, data decomposition, projection and pattern reorganization. The major benefit to use this technique is become more beneficial use as part of the data analysis process, as shows which features are important for prediction, and how these features are related.
D. Attribute Importance: - It helps to find out the rank attributes according to the strength of relationship with target attribute. Use cases include finding factors most associated with customers who respond to an offer.
E. Cloud computing: - This concept consists of shared computing resources which are opposed to local servers or devices. Users can pay on the basis of resource usage as timely basis. The major goal of cloud computing is to provide easily scalable access to computing resources and IT(Information Technology) services for achieving better performance.
Cloud computing basically provides three different types of service based architectures are SaaS, PaaS, IaaS etc.
SaaS (software as-a-service):- It offers application as a service on the internet.
PaaS (Platform as-a-service):- This is to be used by developers for developing new applications.
IaaS (Infrastructure as-a-service):- It is basically deals by providers to provide features on-demand Utility.
F. Component based Systems:-These are used with the
concept of dependency (i.e.- how to show dependency of one product with another product) which helps to predict relation of one product with other related products Here, we use two types of dependency where first one is called
“Depend on” and other one is called“Depend By”. Both dependencies will be shown in fig.1 and fig.2. The major significance to use dependency concept is it is easy to find out selling or purchasing depend on which specific product. The major benefit is to provide secure environment while usage of component which can either work in individual manner or other work with other related components.
II. OUR CONTRIBUTION
In this research paper, we proposed a “collaborative
approach” that is Component based systems with data mining and component based systems with cloud computing. The logical significance to study the concept of dependency in component based systems with data mining is to show the relation between one or more products where a change of one season to another season(For example winter to summer or summer to winter) leads to a potential for a change of one product offer to another product offer. Change in season can obviously affect the customer current demand like more
demand of ice-creams in summers and similarly more
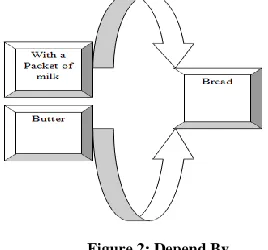
demand of soup in winters, ultimately which is reflected for different-different products. Here, we just have to mine the data on season basis that mean which product sale is greater at specific season. Consider a product data set which consists of {butter, a packet of milk, bread}.In this given dataset we have to show dependency of one particular product on other.
In this research paper, we have to show two different types of dependency flows which are given below:
Depend On.
Depend By.
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 3, Issue 5, May 2013)
515
Figure 1: Depend On [image:3.612.89.223.270.395.2]A graphical representation to show the type of dependency “Depend by”.
Figure 2: Depend By
Here, we are uses a “Association rules” for product mining which can be applied as possible combinations are given below:
1) IF Season = Summer & Seasonal_Product_Name = Ice-Cream & Current_demand = Yes THEN Product_Selling = Yes.
2) IF Season = Summer & Seasonal_Product_Name = Soup & Current_demand = No THEN Product_Selling = No.
3) IF Season = Winter & Seasonal_Product_Name = Soup
& Current_Demand = Yes THEN Product_Selling = Yes.
4) IF Season = Winter & Seasonal_Product_Name = Ice-Cream
& Current_Demand = No THEN Product_Selling = No.
The major benefit to use these association rules are it holds several other output attributes and output of one attribute can also be used as an input of other attribute and maximum possible combinations we can easily find out the relationships with other products. Suppose if we want to search or find out the relevant information about one product then on the same time we will easily get the information of another product which is related with that specific product.
Above we discussed in the example of dependency based concepts like a packet of milk and butter free with a piece of bread, If any user want to search about the flavors of bread available then automatically he/she will be get information about the a packet of milk as well as butter because of these are offered products (i.e. - free products while purchasing bread). In this way this concept also helps to save the time. Ultimately the objective of data mining is achieved.
The major benefit to combine component based systems with cloud computing is it is very easy to use with
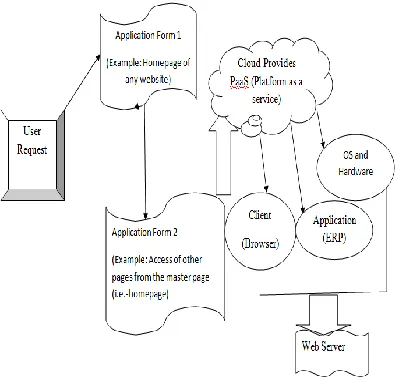
“platform as a service”. Where “Platform as a service” which is used on the developer side for developing new applications. By using this approach we can easily find out the dependency of one specific application on other application on a single platform which means how they work collectively and which features are actually depend on other application. Generally, cloud computing helps to tell the typical use of representational state of data or information transfer. When combine with component based systems approach then we can easily find out the current state of that specific component where it will be working. So, in this way this becomes more important and more meaningful approach. The other benefits to combine these concepts are making systems more reliable, well maintained and also cost effective. In this fig.2 we simply see user send request to the social cloud this social cloud helps to forward this user request to the cloud service provider then it helps to find out the dependency of two different applications for example which are the part of same website on a common platform.
[image:3.612.337.548.503.657.2]III. RESEARCH DESIGN
Figure 3: Discovery of new interesting relationships by using the concept of dependency with data mining technique (i.e. - Association
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 3, Issue 5, May 2013)
[image:4.612.66.264.136.328.2]516
Figure 2: Application Dependency shown in Cloud computing byusing Paas (Platform as a service).
IV. CONCLUSIONS
In this research paper, we have discussed a
“collaborative approach” that merges two separate broader areas with two different aspects like component based systems with data mining and component based systems with cloud computing. This also tells how “component based systems use the concept of dependency in data mining as well as cloud computing. When
Component based systems uses with data mining then it helps to find out the interesting relationships between the products by using the technique of “Association rules” and find out the dependency of one product with one another. By using this approach “Product mining” will also done. Similarly, when Component based systems uses with cloud computing then helps to find out the dependency of two different applications on a common platform.
V. FUTURE SCOPE
In future, this work will be extended by using component based systems as a service provider like Saas (software as a service) in cloud computing. In this case component act as an independent entity and executable entity that cannot compile before it is used with other components. Different types of services are offered by component based systems that can be only accessed through an interface.
Acknowledgement
A special thanks to Mylord and there are a bunch of people to thank for this paper, including Mr. Shubham Chuchra. This paper would not exist but for their faith in me, and I offer them my heartful thanks.
REFERENCES
[1] Bhagyashree Ambulkar and Viashali boarker, “Data mining in Cloud Computing”, MPGI National Multi Conference 2012(MPGINMC-2012),7-8 April 2012.
[2] Jeffery Voas and jia Zhang, “Cloud Computing”: New wine or just a new bottle?”, IEEE Internet Computing Magzine 2009, Link: http://www.cmlab.csie.ntu.edu,tw/~jimmychad/CN2011/Readings/C loudComputing New Wine.Pdf.
[3] ORACLE, “Oracle Data mining techniques and algorithms”, Link:http://www.oracle.com/technetwork/database/options/advanced analytics/odm/odm-techniques-algorithms-097163.html.
[4] http://www.enterpriseappstoday.com/businessintelligence/article.php /3889491/Data-Mining-with-Cloud-Computing.htm.
[5] http://knol.google.com/k/data-mining-through-cloud-computing#. [6] http://research.nesc.ac.uk/node/376.
[7] Tinghuai Ma,sainan Wang,, zhong liu, “Privacy preservingbased on association rule mining,” in advanced computer theory and engg.(ICACTE), VOL.1,pp-637-640,Augst 2010.
[8] Jaiwei han , Micheline kambe. “Data mining concepts and techniques”, 2nd Ed. CA Morgan Kaufmann publishers, 2006, pp.234-239.
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 3, Issue 5, May 2013)
517
Author Bibliography