© 2015, IRJET ISO 9001:2008 Certified Journal Page 1344
Big Data Analytics processing with Apache Hadoop storage
R.Gayathri
1, M.BalaAnand
21
Assistant Professor, Computer Science and Engineering, V.R.S. College of Engineering and Technology,
Tamil Nadu, India
2
Assistant Professor, Computer Science and Engineering, V.R.S. College of Engineering and Technology,
Tamil Nadu, India
---Abstract
—Big Data is a term connected to information sets whose size is past the capacity of customary programmingadvancements to catch, store, oversee and prepare inside a passable slipped by time. The well known supposition around Huge
Data examination is that it requires web scale adaptability: over many figure hubs with connected capacity. In this paper, we
wrangle on the need of an enormously adaptable disseminated registering stage for Enormous Data examination in customary
organizations. For associations which needn't bother with a flat, web request adaptability in their investigation stage, Big Data
examination can be based on top of a customary POSIX Group File Systems utilizing a mutual stockpiling model. In this
study, we looked at a broadly utilized bunched record framework: (SF-CFS) with Hadoop Distributed File System (HDFS)
utilizing mainstream Guide diminish. In our investigations VxCFS couldn't just match the execution of HDFS, yet,
additionally beat much of the time. Along these lines, endeavors can satisfy their Big Data examination need with a customary
and existing shared stockpiling model without relocating to an alternate stockpiling model in their information focuses. This
likewise incorporates different advantages like soundness and vigor, a rich arrangement of elements and similarity with
customary examination application.
Key words - BigData; Hadoop; Clustered File Systems; Investigation; Cloud
I. Introduction The exponential development of information in the course of the most recent decade has presented another space
in the field of data innovation called Big Data. Datasets that extends the points of confinement of conventional information
handling and stockpiling frameworks is frequently alluded to as Big Data. The need to handle also, investigate such gigantic
datasets has presented another type of information examination called Big Data Analytics.
Enormous Data examination includes breaking down expansive sums of information of an assortment of sorts to reveal
concealed examples, obscure relationships and other valuable data. Numerous associations are progressively utilizing Big Data
examination to show signs of improvement bits of knowledge into their organizations, expand their income and productivity and
increase upper hands over adversary associations.
The attributes of Big Data can be comprehensively separated into four Vs i.e. Volume, Velocity, Varity and Variability.
Volume includes to the extent of the information. While Speed tells about the pace at which information is created; Varity and
Variability lets us know about the many-sided quality and structure of information and distinctive methods for translating it.
A typical thought about the applications which expend or break down Big Data is that they require a greatly adaptable
© 2015, IRJET ISO 9001:2008 Certified Journal Page 1345
conventional endeavor organizations this is normally not the case. According to Apache Hadoop wiki [3], huge number of
arrangements of Hadoop in undertakings normally doesn't surpass 16 hubs.
In such situations, the part of conventional stockpiling model with shared stockpiling also, to serve the need to
conventional and in addition Big Data investigation can't be completely discounted. Huge Data investigation stage in today's
reality regularly alludes to the Map-Reduce structure, created by Google [4], and the instruments and biological system
constructed around it.
Guide Reduce structure gives a programming model utilizing "guide" and "diminish" capacities Shared Disk Big Data
Analytics with Apache.
Hadoopover key- quality matches that can be implemented in parallel on a substantial bunch of figure hubs. Apache
Hadoop [1] is an open source usage of Google's Map-Reduce demonstrate, and has turned out to be to a great degree mainstream
over the a long time for building Big Data examination stage. The other key part of Big Data examination is to push the
calculation close to the information.
By and large, in a Map-Reduce environment, the figure and capacity hubs are the same, i.e. the computational
undertakings keep running on the same arrangement of hubs that hold the information required for the calculations. As a matter of
course, Apache Hadoop utilizes Hadoop Distributed Document System (HDFS) [2] as the hidden stockpiling backend, yet it is
intended to work with other record frameworks also. HDFS is not a POSIX-consistent document framework, and once
information is composed it is not modifiable (a compose once, read-numerous entrance model).
HDFS secures information by duplicating information hinders over various hubs, with a default replication variable of 3.
In this paper, we attempt to accumulate a sound thinking behind the need of another non-POSIX stockpiling stack for Big
Data examination and backer, in light of assessment and examination that such a stage can be fabricated on conventional POSIX
based bunch document frameworks. Conventional bunch document frameworks are frequently taken a gander at with an impulse
that it requires costly top of the line servers with best in class SAN. Be that as it may, as opposed to such impressions, these record
frameworks can be arranged utilizing merchandise on the other hand mid-range servers for lower expenses. All the more critically,
these document frameworks can bolster customary applications that depend on POSIX API's.
The broad accessibility of instruments, programming applications and human mastery are other additional items to these
record frameworks. Comparative endeavors are attempted by IBM Research [5], where they have presented an idea of metablock
in GPFS to empower the decision of a bigger piece granularity for Map/Reduce applications to exist together with a littler square
granularity required for conventional applications, and have thought about the execution of GPFS.
Whatever is left of the paper is sorted out as takes after. Area 2 portrays the idea of shared Big Data investigation.
Segment 3 depicts the structural engineering of the Hadoop connector. Area 4 portrays our test setup took after by our
investigations and results in segment 5. Area 6 tells us about extra utilize cases and advantages of our preparation. The future
© 2015, IRJET ISO 9001:2008 Certified Journal Page 1346 II. SHARED DISK BIG DATA ANALYTICS
In our study we analyze the execution of Hadoop Distributed File System (HDFS), the true record framework in Apache
Hadoop with a business bunch record framework called VERITAS Storage Foundation Bunch File System (SF-CFS) by
Symantec, with a assortment of workloads and guide lessen applications. We demonstrate that a bunched record framework can
really coordinate the execution of HDFS for guide/lessen workloads and can even beat it for a few cases. We have utilized
VMware virtual machines as register hubs in our group and have utilized a mid-level stockpiling cluster (Hitachi HUS130) for our
study.
While we comprehend that looking at a grouped record framework running on top of a SAN to that of a circulated
document framework running on neighborhood plates is not an apple to apple correlation, but rather the study is for the most part
coordinated towards getting an appropriate and right thinking (if any) behind the thought of presenting a new capacity model for
Big Data investigation in datacenters of ventures and associations which are not working at a web scale. To have an assessment,
we have run the same workload with HDFS in a SAN situation. Both SF-CFS and HDFS has been arranged with their default
settings/tunable in our analyses.
We have added to a record framework connector module for SF-CFS record framework supplanting HDFS out and out
furthermore have exploited SF- CFS's potential by executing the local interfaces from this module. Our mutual circle Big Data
investigation arrangement needn't bother with any adjustment in the Map Reduce implementation. Just by setting a couple of
parameters in the arrangement of Apache Hadoop, the entire Big Data examination stage can be made up and running extremely
rapidly.
III. ARCHITECTURE
The bunched record framework connector module we produced for Apache Hadoop stage has an extremely basic
structural planning. It uproots the HDFS usefulness from the Hadoop stack. It acquaints SF-CFS with the Hadoop class by
executing the APIs which are utilized for correspondence between Map/Reduce Framework furthermore, the File System. This
could be accomplished in light of the fact that the Map-Reduce system dependably talks as far as a very much characterized
FileSystem [6] API for every information access.
The FileSystem API is a dynamic class which the record serving innovation underneath Hadoop must execute. Both
[image:3.595.191.416.622.755.2]HDFS and our bunched document framework connector module execute this FileSystem class, as appeared in Figure 1.
© 2015, IRJET ISO 9001:2008 Certified Journal Page 1347
Clustered File System being a parallel shared information record framework, the document framework namespace and
the information is accessible to every one of the hubs in the bunch at any given purpose of time.
Not at all like HDFS, where a Name Node keeps up the metadata data of the entire record framework namespace, with
SF-CFS every one of the hubs in the group can serve the metadata.
Subsequently a question from Map Reduce system relating to information territory can simply be determined by the
process hub itself. The advantage of such a determination is the disposal of additional jumps navigated with HDFS in situations
when information is not locally accessible.
Additionally, the information need not be recreated crosswise over information hubs if there should arise an occurrence
of a bunched document framework.
Since, every one of the hubs have entry to the information; we can say that the replication component in SF-CFS is
comparable to the HDFS with replication variable equivalent to the no. of hubs in the bunch. This building design gets rid of the
danger of losing information when an information hub kicks the bucket and least replication was not accomplished for that piece
of information.
The utilization of RAID advances and seller SLAs away exhibits utilized as a part of SAN environment can record to
general dependability of the information.
IV. Exploratory SETUP
In this study on shared plate Big Data investigation, we have analyzed HDFS (Apache Hadoop 1.0.2) which is the default
record arrangement of Apache Hadoop and Symantec Corporation's Cluster File System (SFCFSHA 6.0) which is broadly sent by
endeavours and associations in keeping money, monetary, telecom, avionics and different segments. The equipment setup for our
assessment involves a 8 hub group with VMware virtual machines on ESX4.1. Each VM has been facilitated on individual ESX
has and has 8 CPUs of 2.77GHz and 32GB physical memory. The bunch hubs are interconnected with a 1Gbps system connection
committed to Map Reduce movement through a DLink switch. Shared capacity for bunched record framework is cut with SAS
circles from a mid-range Hitachi exhibit and direct connected stockpiling for HDFS is made accessible from nearby SAS circles
of the ESX has. Each of the process hub virtual machine is running on Linux 2.6.32 (RHEL6.2).
The setup for HDFS-SAN comprises of the same stockpiling LUNs utilized for SF-CFS, yet, designing in a manner that
no two hubs see the same stockpiling, in order to copy a neighborhood plate sort of situation. HDFS-Local setup utilizes the DAS
of each of the register hubs. In both cases, we utilized ext4 as the essential record framework. The following table summarizes the
© 2015, IRJET ISO 9001:2008 Certified Journal Page 1348 V. Test results
We have utilized TeraSort, TestDFSIO, MRbench and GridMix3 [7] for looking at the execution of SF-CFS and HDFS.
These are broadly utilized guide/decrease benchmarks and are accessible pre-bundled inside Apache Hadoop dissemination. In our
execution assessment, for TestDFSIO and TeraSort, we have done the correlation for HDFS replication component of 1 and in
addition 3.
TeraSort:
TeraSort is a Map Reduce application to do parallel consolidation sort on the keys in the information set created by
TeraGen. It is a benchmark that joins testing the HDFS and Map Reduce layers of a Hadoop group. A full TeraSort benchmark
run comprises of the accompanying three stages:
1. Create the info information with TeraGen
2. Run TeraSort on the information
3. Accept the sorted yield information utilizing TeraValidate
Scenario Our solution
SF-CFS HDFS in SAN with replication factor 1
HDFS-SAN
(1)
HDFS in SAN with replication factor 3
HDFS-SAN
(3)
HDFS in Local Disks (DAS) with
replication factor 1
HDFS-Local (1)
HDFS in Local Disks (DAS) with
replication factor 1
HDFS-Local (3)
HDFS in Local Disks (DAS) with
© 2015, IRJET ISO 9001:2008 Certified Journal Page 1349
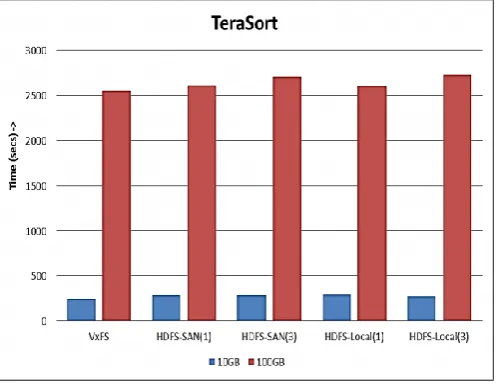
Figure 2: TeraSort outine
Hadoop TeraSort is a Map Reduce work with a custom partitioner that uses a sorted rundown of n-1 inspected keys that
characterize the key reach for each lessen. Figure: 2 above show the conduct of TeraSort benchmark for a dataset size of 10GB
and 100GB. As watched, SF-CFS performs superior to anything HDFS in all the diverse situations.
In our study, the execution tests are done on 64MB records and changing the quantity of documents for diverse test
situations as outlined in figure 3 and 4 above. It has been watched that HDFS altogether outflanks SF-CFS in read for both
replication element of 1 and 3. This is because of the way that HDFS pre-gets a whole piece of information equivalent to the
square size and HDFS don't experience the ill effects of any store soundness issues with its compose once semantics.
HDFS-Local(3) gives an included point of interest of read parallelism equivalent to the number of register hubs, accepting the squares are
equally dispersed/repeated over all hubs, which a common record framework needs.
In TestDFSIO keep in touch with, it is watched that HDFS with DAS with a replication variable of 1 outflanks SF-CFS.
This execution change however comes at the expense of information misfortune in the occasion of hub disappointments. Taking
all things together different cases, SF-CFS performs comparable or superior to anything HDFS for TestDFSIO compose workload.
MRBench:
MRbench benchmarks a Hadoop bunch by running little occupations rehashed over various times. It puts its attention on the Map
Reduce layer and as its effect on the record framework layer of Hadoop is negligible. In our assessment we ran MRbench
employments rehashed 50 times for SF-CFS, HDFS in SAN and HDFS in nearby circles for replication element of 3. The normal
reaction time reported by MRBench in milliseconds was observed to be best for SF-CFS:
GridMix3:
GridMix3 is utilized to reproduce Map Reduce load on a Hadoop bunch by imitating ongoing burden mined from
generation Hadoop groups. The objective of GridMix3 is to produce a sensible workload on a bunch to approve group use and
© 2015, IRJET ISO 9001:2008 Certified Journal Page 1350
that consequently catch fundamental ngredients of occupation executions. In our tests, we utilized the employment follow
accessible from Apache Subversion. We watched that SF-CFS performed superior to anything HDFS in SAN and in addition
HDFS in nearby circles with replication component of 3.
Over the span of our study, we additionally contrasted the execution of SF-CFS and HDFS running so as to utilize the
SWIM [9] benchmark Facebook employment follows and have watched SF-CFS to perform better or at standard with HDFS. It
contains suites of workloads of a huge number of employments, with complex information, entry, and calculation designs which
empowers thorough execution estimation of Map/Reduce frameworks.
VI. A DDITIONAL CONSIDERATIONS
Notwithstanding tantamount execution showed by CFS for different Map/Reduce workloads and applications,
SF-CFS gives the advantages of being a powerful, stable and exceedingly dependable record framework. It gives the capacity run
examination on top of existing information utilizing existing investigation instruments and applications, which kills the
requirement for duplicate in and duplicate out of information from a Hadoop group, sparing huge measure of time. SF-CFS
additionally bolsters information ingestion over NFS.
Alongside all these, it acquires other standard components like depiction, pressure, document level replication and
de-duplication and so on. For instance, gzip pressure for the data parts with HDFS is impractical as it is difficult to begin perusing at
a subjective point in a gzip stream, and a guide errand can't read its split freely of the others [8]. In any case, if pressure is
empowered in SF-CFS, the record framework will perform the decompression and return the information to applications
transparently. Information reinforcements, calamity recuperation are other inherent advantages of utilizing SF-CFS for enormous
information investigation. SF-CFS answer for Hadoop, otherwise called Symantec Enterprise Solution for HadoopTM is
accessible as a free download for SF-CFS clients of Symantec Corporation [10].
VII. F UTURE W ORK
Amid our investigation of the execution showed by a business bunch record framework in Map/Reduce workloads and its
examination with a dispersed document framework, we watched that a lot of time is spent amid the duplicate period of the
Map/Reduce model after guide undertaking completions. In Hadoop stage, the information and yield information of Map/Reduce
occupations are put away in HDFS, with middle information produced by Map errands are put away in the neighborhood record
arrangement of the Mapper hubs and are duplicated (rearranged) by means of HTTP to Reducer hubs. The time taken to duplicate
this middle of the road guide yields build proportionately to the span of the information.
Be that as it may, subsequent to in the event of a bunched document framework, every one of the hubs see all the
information, this duplicate stage can be stayed away from by keeping the transitional information in the grouped record
framework also and specifically understanding it from that point by the reducer hubs. This attempt will totally take out the
duplicate stage after guide is over and bound to give a critical help to general execution of Map/Reduce employments. This will
© 2015, IRJET ISO 9001:2008 Certified Journal Page 1351 VIII. CONCLUSIONS
From all the execution benchmark numbers what's more, their examination, it can be unquestionably contemplated that
for Big Data investigation need, conventional shared stockpiling model can't be completely precluded. While because of
engineering and plan issues, a group document framework may not scale at the same rate as a mutual nothing model does, yet for
use situations where web request versatility is not required, a bunched record framework can make a nice showing even in the Big
Data examination area. A bunched document framework like SF-CFS can give various different advantages its plenty of elements.
This decade has seen the achievement of virtualization which presented the late patterns of server onsolidation, green registering
activities in endeavours [11].
Enormous information examination with a grouped document framework from the current foundation adjusts into this
model and bearing. A cautious investigation of the need and utilize cases are required before building a Big Data examination
stage, as opposed to running with the thought that common nothing model is the main response to Big Data needs.
REFERENCES
[1]D.E. O’Leary. Artificial Intelligence and Big Data.IEEE Computer Society, 96-99, 2013.
[2]S. Chaudhuri.How Different id Big Data? IEEE 28thInternational Conference on Data Engineering, 5, 2012.
[3]H. Topi. Where is Big Data in Your Information Systems Curriculum?acmInroads, Vol. 4. No.1, 12-13, 2013.
[4]IBM, Big Data at the Speed of Business, What is big data, Online available from http://www-1.ibm.com/software/data/bigdata/
[5]C. Li, N. Onose, P. Pirzadeh, R. Vernica, J. Wen. ASTERIX: An Open Source System for “Big Data” Management and
Analysis (Demo). Proceedings of the VLDB Endowment, Vol 5, No. 12, 1898-1901, 2012.
[6]C. Okoli, K. Schabram. A Guide to Conducting a Systematic Literature Review of Information Systems Research. Sprouts:
Working Papers on Information Systems, 2010.
[7]B. Kitchenham, S. Charters. Guidelines for performing Systematic Literature Reviews in Software Engineering. EBSE
Technical Report EBSE-2007-01,2007.
[8]Merriam-Webster. Online available from http://www.merria mwebster.com/dictionary/definition
[9]H. Suonuuti. Guide to Terminology, 2nd edition ed. Tekniikan sanastokeskus ry, Helsinki, 2001.
[10] B. Marr, Key Performance Indicators, The 75 measures every manager needs to know. Pearson education limited, 2012.
© 2015, IRJET ISO 9001:2008 Certified Journal Page 1352 BIOGRAPHIES
R.Gayathri was born in Cuddalore, India. She received the B.E. degree in Computer science and engineering
from the University of Trichy, in 2011, and the M.E in Software engineering from College of engineering
Guindy, Chennai. In 2014, she joined as a Assistant Professor in V.R.S.College of Engineering and
Technology. Her area of interests include data mining.She is a Life Member of the Indian Society for Technical
Education (ISTE).
Mr.M.BalaAnand M.E (Ph.D) was born in Villupuram, India. He received the B.Tech. degree in Information
Technology from V.R.S. College of Engineering & Technology, Arasur, Villupuram, in 2010, and the M.E in
Software engineering from Hindustan University in 2012, He joined as a Assistant Professor in V.R.S.College
of Engineering and Technology. His area of interests includes Big Data and Software Engineering. Hde is a
Life Member of the Indian Society for Technical Education (ISTE).