Guanru Peng. Aspect Based Rating Prediction For Yelp Customer Review. A Master’s Paper for the M.S. in IS degree. May, 2020. 43 pages. Advisor: Stephanie Haas
With the wide spread of online review platforms, online reviews and star ratings have been widely used by customers to determine the quality of business. However, overall star rating is not once-for-all measurement in summarizing the review because review writers are likely to differ in how would they evaluate different aspects of the restaurants. In this paper, we attempted to predict the rating a reviewer will assign mainly based on the review text as well as other features derived from the Yelp review dataset. We created dictionaries to identify the <aspect-noun, sentiment word> combinations on sentence level and incorporated these new features. Our model achieved a fairly high level accuracy (84.61%). The contribution of aspect-related features was also discussed.
Headings:
Product Reviews
Sentiment
ASPECT BASED RATING PREDICTION FOR YELP CUSTOMER REVIEW
by Guanru Peng
A Master’s paper submitted to the faculty of the School of Information and Library Science of the University of North Carolina at Chapel Hill
in partial fulfillment of the requirements for the degree of Master of Science in
Information Science.
Chapel Hill, North Carolina
May 2020
Approved by
_______________________________
Table of Contents
I. Introduction ...2
II. Literature Review ...5
2.1 Aspect Extraction ...5
2.2 Rating Prediction ...7
2.3 Hybrid Approach ...10
III. The Object And Hypotheses ...12
IV. Data Description ...13
IV. Data Preparation ...16
V. Feature Selection and Model ...17
5.1 Text Features ...17
5.2 Non-Text Features ...20
5.3 Model ...22
VI. Results...26
VII. Discussion and Conclusion ...29
NOTES ...34
Reference ...35
2
I.
Introduction
Online review platforms such as Yelp1 and Tripadvisor2 have been used as a source
of data for NLP tasks related to user’s review since it offers large quantity of available
user review data of different areas. It provides a reliable platform for every customer to
write review along with giving their start-rating as well as an open-ended comment. In
the last a few years, Yelp provided and updated an open to download dataset for personal
study use or other educational and academic purposes.
Positive reviews and describing rating have been recently shown to have a significant
influence on consumer shopping behavior (Anderson & Magruder, 2012; Mo, Li, & Fan,
2015). A Yelp review typically consists of text, the date of the review, and an overall star
rating. A user review typically looks like this:
It is not easy for other general users to evaluate the review text, unless they are
willing to spend some time and effort on reading and comprehending the reviews
thoroughly. A widely used solution to provide a brief overview of the review is to
quantify the overall rate of a business in form of 1-5 star(s). For Yelp users who search
restaurant information, a star rating is a brief summary of the entire review that helps
them decide whether they need to learn more about the restaurant or not.
However, overall star rating is not once-for-all metric in summarizing the review
because review writers are likely to differ in how much value they ascribe to different
aspects of the restaurants. Overall star rating can helpful for providing an overview fo the
review, but cannot reflect details regarding different aspects of the restaurant. In the
scenario of product review or service review, we can regard aspects as product attributes
or features (Q. Liu et al., 2016). For example, consider the following review taken from
the Yelp dataset:
“The beer is not that good but I can live with that… I just cannot stand those incredibly rude staff! Such a disappointment talking to the waiters.”
In this case, two aspects of the restaurant were mentioned: food quality and service.
And judging by the review text, a negative sentiment associated with the aspect “service”
is more influential than the negative sentiment associated with the aspect “food quality”,
which may further results in a lower rating given by the reviewer. Since each review can
be regarded as an integration of various content regarding various aspects of the
restaurant, taking these aspects and their associated sentiment into consideration might be
4 Therefore, this study is an attempt toward predicting the star rating of each review.
Aspect-dependent lexicon were created to detect theco-occurrence of aspect keywords
and opinion keywords on sentence level. The counted co-occurrence of these word pairs
are used as aspect-related features for model training and testing. We differentiated those
aspect-related features from other features by categorizing them into various feature
groups. Then we built our model on each of these feature groups as well as on a
combined feature group to evaluate how each group contribute to the rating prediction
II.
Literature Review
The product aspect rating prediction problem usually involves two subtasks: aspect
extraction and rating prediction (Titov and McDonald, 2008b). Therefore this paper will
start with a quick review of researches on both.
2.1 Aspect Extraction
Aspect extraction is a crucial part in aspect based sentiment analysis, which aims to
identify fine grained polarity towards a specific aspect in the text (Jo and Oh, 2011;
Pontiki et al.,2015). Aspect extraction aims to extract two types of aspects are defined in
aspect based sentiment analysis: implicit aspects and explicit aspects. Explicit aspects are
concepts that explicitly denote targets in the opinionated sentences (Poria et al., 2014),
while the implicit aspects are concepts that are implied in the text. For instance, consider
the following review:
“This restaurant offers some top tierfood in the state. But it takes me nearly 5 hours to drive here. ”
In this review, one explicit aspect that is directly stated is “food”. The second
sentence also implicitly shows the sentiment associated with the aspect “location”. The
6
Unsupervised implicit aspects extraction uses unlabeled data to extract implicit
aspects from the corpus and not use any algorithm that require some training. Topic
modeling, as a widely used unsupervised technique, depends on searching the document
for all included topics where in aspect-based sentiment analysis, these topics represents
the implicit aspects in the review text (Rana, Cheah, & Letchmunan, 2016).
First of all, LDA (Latent Dirichlet Allocation) has been widely used as an
unsupervised method to detect latent topics. It assumes that there are latent variables that
reflect the thematic structure of the documents (Blei et al, 2003). Given a selected
parameter K as the total number of latent topics in the text, LDA transforms the
distribution from the individual parameters to the hidden variable.
Lu et al. studied the problem of automatically generating an aspect rating summary,
which provides a decomposed view of overall ratings for each major aspect of the review
(Lu et al., 2009). The data they used were all short seller feedback comments collected
from eBay. In their research, the unstructured text was first preprocessed into phrases of
the format of <head term, sentiment word> pairs, and the head terms are clustered by
structured PLSA (Probabilistic Latent Semantic Analysis) to find the K major latent
aspects in the text. Then, they predicted the phrase ratings by either local prediction or
global prediction, and subsequently provided an overall, aggregated aspect rating.
In their research work in 2011, Jo and Oh proposed a sentence-LDA model (SLDA)
to automatically discover what aspects are evaluated in reviews as well as how
sentiments for different aspects are expressed (Jo and Oh, 2011). For instance, “the
of the laptop flickers” is related to negative sentiment. They took these {aspect,
sentiment} pairs into account, and extended the SLDA to Aspect and Sentiment
Unification Model (ASUM) that combines aspect and sentiment together to discover
these {aspect, sentiment} in the review text, without the need of sentiment labels of the
reviews since ASUM extract aspects in an unsupervised way. ASUM is capable of
recognizing and capturing aspects that are closely related with a sentiment. Their
sentiment classification experiment result shows that ASUM, combined with SLDA,
outperforms other generative models.
Xu et al. used the developed aspect dependent sentiment lexicons for implicit feature
identification (Xu et al., 2013). They proposed a Joint Aspect Sentiment (JAS) model,
which is designed on generative topic model to discover the explicit aspects and detect
the entries of aspect-dependent sentiment lexicon. They also used the lexicon for implicit
aspect identification based on the use of the information and knowledge of a specific
opinion words as a clue that can be used to identify the hidden aspects in the review text.
2.2 Rating Prediction
Most of the recent work related to review rating prediction relies on sentiment
analysis to extract sentiment features from the review text.
In 2007, Snyder and Barzilay (Snyder & Barzilay, 2007) used Good Grief algorithm,
which jointly learns the ranking models for individual aspects using an online Perception
Rank algorithm. This algorithm guides the prediction of individual ranking models for
8 contrast. They evaluated their model on a corpus of restaurant reviews available on the
website http://www.we8there.com. They used ranking loss as their metrics, which
measures the average distance between the true rank and the predicted rank, lower values
represents a better performance of the model.
Leung et al. proposed a relative frequency method to create an opinion dictionary, in
order to infer review ratings from the review text (Leung et al., 2006). Their method
determines the sentiment strength of a word with respect to a certain sentiment class
(positive or negative) as the relative frequency of its occurrence in that class. They
integrate this inference technique with collaborative filtering algorithms and test their
method on movie review from IMDb. They evaluated the accuracies produced by their
model in rating reviews with respect to a 2-point or 3-point scale.
Ganu et al. proposed a method to use the text of the reviews to improve recommender
systems, like the ones used by Netflix, which often rely solely on the structured metadata
information of the product/business and the star ratings (Ganu et al., 2009). Using
restaurant reviews from City search New York, they manually annotated a subset of the
reviews (3,400 out of 52,264) with the associated sentiment (positive, negative, neutral
and conflict) and whether the review is specifically about a certain aspect of restaurant
review (food, service, ambience, etc). They trained and tested Support Vector Machine
classifier on the manually labeled data and used this model to automatically annotate the
rest of the entire dataset. They proposed both a rating which relies on sentiment
information only and one that incorporates topics and sentiment information into a
regression-based rating. They proved that the both topic and sentiment information are
Qu et al. proposed a novel feature extraction method called bag-of-opinions, which
extracts opinions from the Amazon review corpus (Qu et al., 2010). The opinion features
they searched are a combination of an opinion root word, an opinion modifier and a
negation word. For instance, in the phrase “not very helpful”, the opinion root word is
helpful, the opinion modifier is very, and the negation word is not. After extracting these
features out of the review text, they assigned each opinion with a score learned by ridge
regression from a domain-independent corpus of reviews. They predicted a review’s
rating by aggregating the scores of opinions present in that review and concluded that
their bag-of-opinions representation is better suited for capturing the expressive power of
n-grams.
Fan and Khademi predicted the average star rating of catering businesses on Yelp
solely from its review text (Fan and Khademi, 2014). They incorporated the unigrams
language model with feature extraction methods such as Parts-of-Speech (POS) tagging.
They tried different feature generation methods including word frequency from raw text
review, word frequency after POS and adjective frequency after POS. In their modeling
phase, they trained linear regression, support vector regression and decision tree models
for prediction. They evaluated their models with Root Mean Square Error (RMSE), and
concluded that Linear Regression with most frequent adjectives after POS as features as
well as Linear Regression with the top frequent words counted from raw data
10
2.3 Hybrid Approach
Many researchers have already been working on incorporating various ways of aspect
extraction in review rating prediction.
Titov and McDonald proposed a work on aspect-based sentiment summarization
using MG-LDA model to extract latent topics in the review text (Titov and McDonald,
2008). They created Multi-Aspect Sentiment model (MAS) to discover latent topics in
text and extract textual evidence from reviews supporting each of these aspect ratings.
The first part of MAS is based on Multi-Grain Latent Dirichlet Allocation, which has
been previously used to detect and build topics that are representative of every latent
ratable aspect. The second part is a set of sentiment predictors per aspect that are
designed to force specific topics in the model to be directly correlated with a particular
aspect.
Wang et al. stated that the the multi-aspect rating prediction is an example of Latent
Aspect Rating Analysis (LARA) problem, consist of inferring aspect ratings for each
review and the detecting relative weights assigned by the review writers to each aspect
(Wang et al., 2010). Aspect keywords are provided as user input, and they proposed a
novel method with two phases, called Latent Rating Regression (LRR). Firstly, the LRR
model uses a bootstrapping algorithm to automatically identify and extract related words
for each indicated aspect, and flags the document content accordingly. In the second
stage, the LRR model generated the overall rating for each review based on the weighted
Wang and Ester proposed a similar work on combining topic modeling and rating
prediction together by constructing a sentiment-aligned topic model (SATM) to tackle the
limitation of previous rating prediction models that they may not do the prediction tasks
well due to the sentiment alignment problem(Hao Wang and Martin Ester, 2014). A
sentiment alignment problem, by the definition of the authors, is that the sentiment topics
(a sentiment labeled word distribution) do not have a clear correspondence to the actual
ratings. For instance, a topic with 5 as sentiment labeled does not necessarily correspond
to rating 5. Previous topic models are likely fail to capture specific sentiments if the
dataset is highly skewed that one sentiment is too dominant in the entire dataset. By
incorporating the overall rating distribution and a sentiment lexicon, their SATM model
can better align the sentiment labels with corresponding ratings. They also experiments
SATM on a TripAdvisor dataset demonstrate the effectiveness of SATM on aspect rating
12
III. The
Object And Hypotheses
The goal of this research is to predict the number of stars a reviewer gives a restaurant
based on the review text plus other features such as the date of the review and total
number of “cool”, “useful" tags of the review. To simplify the problem, we re-formulated
it as a binary model. All reviews with a 4 or 5-star rating were classified into the “high
rating” category, and all reviews with a 1 or 2-star rating were classified into the “low
rating” category. Reviews with 3 stars were omitted since these kind of reviews appears
to be neutral and ambiguous, and can be put to either side depends on different point of
views. Another reason not to include these reviews is that they only comprise a minor
fraction of the dataset, compared to other reviews. Therefore, we treat the rating
prediction task as a binary classification. There are two hypotheses that were made prior
to feature selection and modeling.
H1: the overall sentiment of the review can be regarded as a direct reflection of the
star rating; positive reviews indicate a higher star rating and negative reviews imply a
lower star rating.
H2: identifying different aspects in the review text and the frequencies of their
co-occurrence with positive and negative words within a single review can contribute to
IV.
Data Description
The dataset used for this study is readily available from Yelp and open todownload3.
The dataset contains information about businesses as well as users in 12 metropolitan
areas across four countries. A total of 6 datasets are included, among which the
review.json, business.json and user.json were used in the model construction. Among all
of our files, review.json is the largest one, containing over 4.7 million reviews on Yelp
from 2004 to 2017, and has a size of 3.82 GB. Each review is accompanied by its
business id, user id, date, stars (on scales of 1 to 5), review id and its original text. All ids
in this dataset (business id, user id, review id) are represented by randomly assigned
combinations of numbers and letters. The following are snapshots of the example data
points in the review and business datasets.
14
Fig 3. An example data point in business.json
The business.json was used to filter out all the restaurant business data for this study.
Additionally, we noticed that the 'attribute' list contains unique values that indicates
various features of restaurant business, such as parking policy and take out service. The
unique values in the attribute list are extracted to help us creating aspect keywords lists.
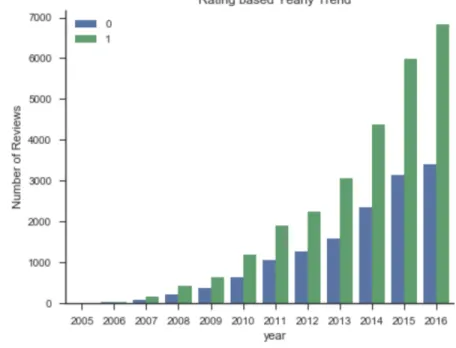
We also counted the total number of the the number of reviews written by Yelp users
each year. Here we treated "higher rating” ones as reviews with 4 or 5 stars and "lower
rating" ones as reviews with with 1 or 2 stars. The distribution of review stars after the
preprocessing indicates an overall upward trend from 2 stars to 5 stars. It can be inferred
from this distribution trends that Yelp users tend not to give neutral ratings. From 2006 to
2016, the total number of reviews shows an upward trend, while the proportion of
were more high rating reviews than the low rating ones, the dataset needs to be
rebalanced to ensure the labels are evenly distributed.
\
16
IV.
Data Preparation
To perform the rating prediction task, all the datasets used were converted from .json
file to .csv file. Two files, review.csv, business.csv, were merged together using each
business’s unique identifier. Since catering business is the only concern, all data entries
about other businesses such as dentistry and saloon were excluded. This is done by
filtering out all the business that includes the keyword “restaurant" in the business
categories and attributes. Then some unnecessary information, such as duplicates and
blank data points, were filtered out. After the concatenation of these two datasets and all
the filtering, we cut the total number of reviews down to 322,5067.
Therefore we have a dataset that can be divided by two parts: reviews, which consists
of corresponding information regarding each review, including user id, business id,
review text, star rating given by the user, and counts for tags such as “fun”, “useful” and
“cool”; and attributes regarding business information, among which we mainly focus on
the attribute list that provides a description of restaurant’ s features, such as location,
price range, business hours, etc. We extracted the all unique values in the business
attribute list and stored those values in a separate text file. Given the large number of
restaurant reviews remaining after these steps, we decided to further trim the dataset.
Therefore we selected all the restaurant reviews within 1 year period of time, from
2014-01-20 to 2015-2014-01-20. We also rebalanced the dataset based on the rating label to
guarantee an equalized distribution of ratings. After the pruning phase, the size of the
V. Feature Selection and Model
We now move on to the feature selection part. For our purposes, we used a rather
simple but practical approach based on the exploratory data analysis and our assumptions
regarding the reviews. While the Yelp dataset consists of 5 different parts, we focused
mainly on the review dataset itself, and did not bring business or user factors into the
equation. The next two sections describe the text and the non-text features.
5.1 Text Features
All the text features are generated solely from the review text.
Review length and punctuation count
Review length is a basic feature that is directly associated with our assumptions that a
longer review is likely to provide more information about the reviewer’s thoughts on the
restaurant. It shows the total number of characters contained in each review, and is
usually used as a measurement of informativeness. The same can be applied to total
number of punctuations. We are curious to find out if longer review could be an indicator
that the Yelp user carefully wrote this review to provide his or her genuine feelings
instead of some random thoughts, thus it may shed some light on the rating prediction.
Number of all capitals (1)
and indicates a polarized sentiment, which could possess a strong predicative power
in determining the star rating. We have counted all the capitalized words in each review
18
Number of exclamation marks and question marks (2)
The use of exclamation marks and question marks can also be regarded as an
expression of strong sentiment. It is possible that people type multiple sentences end with
question marks or exclamation marks to convey either obvious dissatisfaction or
amazement. Gezici et al., stated in their research that taking the total number of
exclamation marks and question marks eventually elevates the model performance
(Gezici et al., 2012). Therefore we incorporated the punctuation features to see if
capturing the total number of these two might contribute to the predictive modeling.
Sentiment features: polarity and subjectivity (2)
These sentiment features are generated based on the review text itself. We used
Textblob to process the textual data and calculate the sentiment polarity and subjectivity
of the text. Polarity score is a float that lies in the range of [-1, 1] where -1 represents an
extremely negative sentiment and 1 indicates a strong positive sentiment. Each word in
the Textblob lexicon has scores for sentiment polarity and subjectivity. Thus, Textblob
uses a lexicon based approach to detect the occurrence of sentiment words in the review
text and assign an overall polarity or an overall subjectivity score to the review text
accordingly. We also used Textblob to assign subjectivity score to the review text.
Subjectivity is considered as we assume that polarized reviews tends to be more
subjective. This score is also a value that lies within [0, 1], where 1 suggests that the text
Aspect-based features (8)
For this study, we decide to take different aspects of the review text into account.
Whether certain parts of the review are actually positive or negative about certain
attributes of the restaurants could be of great use in predicting its rating. The Yelp dataset
provides a list of attributes associated with each restaurant, including various aspects
such as parking services, good for kids or not, restaurant counter services, diet, good
food, etc. Those business attributes were extracted and stored in a separate text file.
Based on these attributes, we categorized 4 different domains of evaluating a restaurant:
location, policy (of the restaurant), food quality, environment. We decided to examine the
review text based on these 4 general aspects. Each of these aspects is associated with
either negative or positive word. We utilized an approach which is similar to the one
proposed by Lu et al., where they preprocessed the text data and into the format of <head
term, sentiment word> pairs (Lu et al., 2009).
Our approach is to detect all the <aspect-noun, sentiment word> pairs in the review
text on a sentence level. To create lexicon regarding aspect-related nouns and sentiment
words, we selected some words from the keyword list4 used by H.Wang, Y. Lu and
C.Zhai in their study of latent aspect regression analysis (H.Wang, Y. Lu and C.Zhai,
2011). By creating lexicon of positive and negative words associated with each aspect
noun, we searched word pairs in the review text and count the co-occurrence of positive
or negative word with each aspect. This part was executed on sentence level, which
means that as long as the <aspect-noun, sentiment word> pairs occurs within one
sentence, we will count its occurrence. The word pairs we detected and captured are
20
•
policy_positive / policy_negative: We detected word pairs that indicatesentiment regarding the policy (or service) of the restaurant. For example, <service,
wonderful> and <staff, kind> will be counted as positive sentiment towards policy.
And <service, disastrous> and <waiter, horrible> will be counted as negative.
•
location_negative /location_positive: We looked for word pairs that indicatenegative sentiment regarding the location of the restaurant. For example, <parking,
convenient> and <place, wonderful> will be counted as positive. And <place, far> will
be counted as negative.
•
food_positive / food_negative: We detected word pairs that indicate sentimentregarding the food of the restaurant. For example, <breakfast, tasty> and <food,
delicious> will be counted as positive sentiment towards policy. And <dinner,
disastrous> and <meat, gross> will be counted as negative.
•
environment_positive / environment_negative: We looked for word pairsthat indicate negative sentiment regarding the location of the restaurant. For example,
<environment, clean> and <ambience, quiet> will be counted as positive. And
<hygiene, unacceptable> will be counted as negative.
5.2 Non-Text Features
Date feature (1)
Whether the customer come to the restaurant during weekday or weekend may
may have different feelings towards the same service based on whether it is weekend or
not. For instance, restaurants might be more crowded during weekend so customers are
likely to develop negative feelings towards the services and environments, while the
situation during weekdays might be the opposite. Therefore based on the date when the
review is created, we included a Boolean value to indicate whether the review is
composed during weekend or not.
Tag Count (3)
Each review enables readers of a review to express their opinion by clicking the three
given tags. These tags include:
Useful: The “Useful" tag count of each review displays the total number of review
readers who think this review is useful to them.
Funny: The “Funny" tag count of each review shows how many readers find this
review funny.
Cool: The “Cool” tag count of each review shows how many readers consider this
review to be cool.
We are interested in finding out that if there is a correlation between the reader’s
22
5.3 Model
Since our rating prediction is transformed into a binary classification problem, we
selected logistic regression as our classifier and trained a model based on the feature
described in section 5. The entire feature set is divided into two parts: non-text features
and text features (including aspect features and non-aspect features). The following tables
represent the complete feature set that was used in this study, categorized by different
feature groups.
Table 1a. All non-text features
- Non-text Features
weekend_yes
(Whether the review was written during weekend)
useful
(Total number of useful votes received)
cool
(Total number of cool votes received)
funny
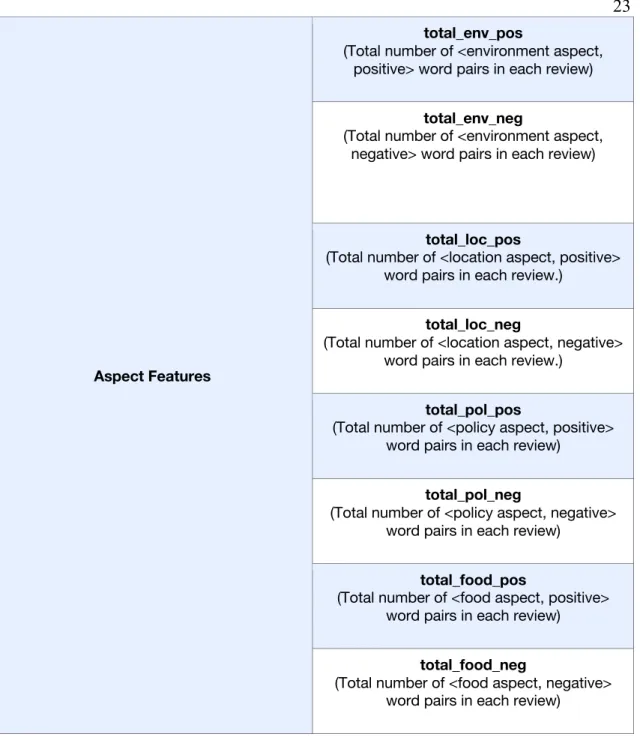
Aspect Features
total_env_pos
(Total number of <environment aspect, positive> word pairs in each review)
total_env_neg
(Total number of <environment aspect, negative> word pairs in each review)
total_loc_pos
(Total number of <location aspect, positive> word pairs in each review.)
total_loc_neg
(Total number of <location aspect, negative> word pairs in each review.)
total_pol_pos
(Total number of <policy aspect, positive> word pairs in each review)
total_pol_neg
(Total number of <policy aspect, negative> word pairs in each review)
total_food_pos
(Total number of <food aspect, positive> word pairs in each review)
total_food_neg
(Total number of <food aspect, negative> word pairs in each review)
24
Table 1c. All non-aspect features
Text Features Non-Aspect Features
Lengths
(The lengths of each review)
Polarity
(The sentiment polarity score assigned to each review)
Subjectivity
(The subjectivity score assigned to each review)
NoPunct
(Total number of punctuations in each review)
NoCaps
(Total number of all-capitals in each review)
NoExclam
(Total number of exclamation marks in each review)
NoQuestion
We proceeded to the model training phase by doing the feature extraction first and
then training and testing the model using a 90/10 train/test split. We utilized accuracy as
our evaluation metric.
We also conducted a feature ablation study to analyze how each feature contributed to
the overall performance of our model, especially all the identified <aspect-noun,
sentiment word> aspect features. To achieve this, we started with a full feature set, and
then removed one feature at a time, trained the model based on the rest features, and
proceeded with testing. The same procedure was also applied to different feature groups,
including text features, non-text features, aspect-features and non-aspect features. We
removed these feature groups one at a time, trained and tested model on the rest of the
26
VI. Results
The overall accuracy we achieved with our model trained with full feature set is
84.61%, which is a fairly good score since the dataset is balanced and the baseline
accuracy is 50%. The test AUC score is 92.19%. We also built our model on different
combination of feature sets Table 2 shows the effects of each feature set on the model
performance.
Feature Groups Accuracy
Text Features: Aspect Features Only 67.63%
Text Features: Non-Aspect Features Only 83.39%
Text Features: (Non-Aspect Features) + (Aspect Features) 83.48%
Full feature set: (Non-Aspect Features) + (Aspect Features) + (Non-Text Features)
84.61%
Table 2. Model performance with different feature sets
We also did feature ablation study to capture how each feature or each feature group
contributes to the overall performance of our model, and present our result in a feature
ablation study table. The number below each feature (or feature group) represents the
accuracy we get after removing that feature (or feature group) and retraining & testing
our model on the rest of the features. The number in the brackets indicates the percentage
change of the accuracy after eliminating that feature (the overall accuracy with full
Table 3. Feature ablation study
- Text Features 0.6553 (-29.116%) -Non-Aspect Features 0.6763 (-25.107%) -lengths 0.8465 (+0.04%) -polarity 0.755 (-12.06%) -subjectivity 0.8452 (-0.106%) -NoPunct 0.8464 (+0.035%) -NoCaps 0.8475 (+0.165%) -NoExclam 0.8492 (+0.365%) -NoQuestion 0.8464 (+0.035%) -Aspect Features 0.8341 (-1.439%) -total_env_pos 0.8473 (+0.141%) -total_env_neg 0.8464 (+0.035%) -total_loc_pos 0.8467 (+0.070%) -total_loc_neg 0.8468 (+0.082%) -total_pol_pos 0.8475 (+0.165%) -total_pol_neg: 0.845 (-0.13%) -total_food_pos 0.8464 (+0.035%) -total_food_neg: 0.8443 (-0.213%)
28 As we can see from the table above, the sentiment polarity feature is the most
impactful one in the feature set, which supports the H1 that sentiment polarity of the
review text reflects the rating directly. However, the aspect features do not contribute
much as we have expected to the overall performance. Removing the aspect feature set
only cause the accuracy to drop by 1.439%, a minor change compared to non-aspect text
VII. Discussion and Conclusion
After examining the overall accuracy of our model and the results of feature ablation
analysis, we can conclude that our model yielded a fair performance on this binary
classification task. However, contrary to what we expected, the aspect features we
incorporated in modeling did not contribute much to the performance.
The non-aspect text features contribute significantly to the overall accuracy.
Removing this feature group will cause the performance decrease by 25.107%. Among
all the non-aspect text features, sentiment polarity is the most influential one, followed by
subjectivity, which indicates how subjective the review text appears. Other features
actually hurt the overall accuracy. Review length and punctuation count are associated
with the total length of the review text, but that does not necessarily have positive
correlation with the stars given by the reviewer. At first the possibility that an either
extremely long or short review might be a good indicator for higher rating or lower rating
was considered in selecting features, but it turns out that the length does not boost the
model performance.
The total number of exclamation marks, question marks, and all-uppercase words did
not contribute to the prediction task. These features were incorporated since their
presence are usually good sentiment indicators. Barbosa and Feng proposed the use of
syntax features of tweets including links, punctuation and exclamation marks for
30 selection to demonstrate that those linguistic features boost the overall performance
(Barbosa and Feng, 2010). The use of all-capital words are sometimes regarded as a
“shout out” or a way of venting either anger or happiness. After re-examining the
distribution of all-capital words, it is worth noticing that more than half (44,692) of the
total reviews do not contain any question marks or all-capital words. This could be
explained by the limited data selected for training and testing, since only reviews from
2014-01-20 to 2015-01-20 are used in the prediction task. Analyzing a longer time period
might enrich the data.
Removing the aspect features from the group only reveals a minor impact on the
model performance, though the opposite situation was expected. The total number of
food-negative word combinations (total_food_neg) seems to be the most impactful
feature in the entire aspect feature set. It supports our expectation that comments about
the food will be common in reviews about catering businesses. Reviewers might not be
able to develop a feeling towards the surroundings or service, or they may simply not
care about these factors. However, the food they eat is likely to give them an impression.
The rest of the aspect features do not contribute to the performance. One possible
explanation for this result is that the aspect extraction method does not perform well,
since keyword dictionaries of four aspects were used in this process to capture all the
word pairs. However, revisiting the feature extraction phase reveals that the all the aspect
features are too sparse. Most of them are zeroes. The dictionaries used in the feature
extraction were created manually to count the occurrence of those word pairs within each
sentence of the review. If the dictionaries can be enriched, we will be able to capture
Non-text features turned out to be helpful but in a limited way. The weekend feature
is not useful in this model. Whether the review was composed during weekend or
weekday failed to serve as a discriminator. The count of useful, cool, and funny tags do
have some predictive power, but correlation between these tag counts and the overall
rating could be further examined. These tags essentially represent how other users
perceive the review text. Do they think the review is useful because of the rated stars or
based on the review text? Both the "useful" and “cool tag" can be regarded as indicating
that the review is approved or accepted by other users, but “funny” appears to be more
ambiguous since it can be interpreted as being funny in a positive way or negative way.
The relationships between these tags and the actual rating of the review are worthy being
further examined.
To conclude, the goal of this study was to predict the review rating. It turns out that
the model yields a fairly good performance with 84.61% accuracy. Different set of
features were used in this study, including text features generated based on the review
text and non-text features extracted from the review dataset. We made two hypotheses
about the rating prediction task prior to feature selection and modeling:
H1: the overall sentiment of the review can be regarded as a direct reflection of the
star rating; positive reviews indicate a higher star rating and negative reviews show a
lower star rating.
H1 is supported by the results of the feature ablation study since text features were
proved to be the most influential feature group, especially the sentiment polarity and
subjectivity. Non-text features such as “cool”, “funny”, “useful" tag counts all have
32 H2: identifying different aspects in the review text and the frequencies of their
co-occurrence with positive and negative words within a single review can contribute to
rating prediction
H2 was not supported by the results. The aspect-based features did not work as well
as we have expected, which could be a result of flawed feature extraction. For the future
work, we could consider enriching the dictionaries to extract more aspect-specific word
pairs or expression, so that we can better dive into their relationships with the overall
rating. Another factor we could take into account is that the data elements describing the
business and the user could also be incorporated in predicting the rating. For instance,
more personalized data such as user’s review count, or the average rating of all of his or
her reviews may also shed some light on the user’s rating pattern. On the business side, it
would be also interesting to consider the correlation between the overall rating and
business factors such as the average star that a restaurant receives, total review counts,
Acknowledgment
I would like to express my very great appreciation to Professor Stephanie Haas, since the
completion of this paper could not have been possible without your guidance. I deeply
appreciate all of your help, your support, your patience and enthusiastic encouragement
during my most difficult time.
34
NOTES
1
https://www.yelp.com
2
https://www.tripadvisor.com
3
https://www.yelp.com/dataset
4
https://github.com/redris96/LARA/blob/master/aspect_keywords.
Reference
M. Anderson, and J. Magruder, "Learning from the crowd: Regression discontinuity
estimates of the effects of an online review database", Econ. J., vol. 122, no. 563, pp.
957–989, 2012
D.Blei, A. Ng, and M.Jordan. Latent dirichlet allocation. The Journal of Machine
Learning Research, 3:993-1022, 2003.
L. Barbosa and J. Feng. 2010. Robust sentiment detection on twitter from biased and
noisy data. Proceedings of the 23rd International Conference on Computational
Linguistics: Posters, pages 36–44.
M. Fan and M. Khademi. Predicting a business star in yelp from its reviews text
alone.arXiv preprint arXiv:1401.0864, 2014.
G, Ganu, N, Elhadad, and Amelie Marian. Beyond the stars: Improving rating predictions
using review text content. In WebDB, 2009.
Gezici, G., Yanikoglu, B., Tapucu, D., Saygin, Y.: New Features for Sentiment Analysis:
Do Sentences Matter? In: Proceedings of SDAD-2012, 1st International Workshop on
36
Y. Jo and A. H. Oh. 2011. Aspect and sentiment unification model for online review
analysis. In Proceedings of the Fourth ACM International Conference on Web Search and
Data Mining, WSDM ’11, pages 815–824, New York, NY, USA. ACM.
C. Leung, S. Chan, and F. Chung. Integrating collaborative filtering and sentiment
analysis: A rating inference approach. Proceedings of the ECAI 2006 workshop on
recommender systems, pages 62–66, 2006.
Qian Liu, Bing Liu, Yuanlin Zhang, Doo Soon Kim, and Zhiqiang Gao. 2016. Improving
opinion aspect extraction using semantic similarity and aspect associations. In Thirtieth
AAAI Conference on Artificial Intelligence.
Y. Lu, C.Zhai, and N. Sundaresan. 2009. Rated aspect summarization of short comments.
In Proceedings of the 18th International Conference on World Wide Web, WWW ’09,
pages 131–140, New York, NY, USA. ACM.
Hu. M, & Liu. B. (2004, August). Mining and summarizing customer reviews. In
Proceedings of the tenth ACM SIGKDD international conference on Knowledge
discovery and data mining (pp. 168-177). ACM.
Mo, Z., Li, Y. & Fan, P., 2015. Effect of Online Reviews on Consumer Purchase
B. Snyder, R. Barzilay, “Multiple aspect ranking using the 354. good grief algorithm,” in
Proceedings of NAACL HLT, 2007, pp. 300–307.
M.Pontiki, D.Galanis, H.Papageorgiou, S.Manandhar, and I.Androutsopoulos. 2015.
Semeval-2015 task 12: Aspect based sentiment analysis. In Proceedings of the 9th
International Work- shop on Semantic Evaluation (SemEval 2015), pages 486–495.
S.Poria, E. Cambria, L. WeiKu, C. Gui, A.Gelbukh.(2014). A Rule-Based Approach to
Aspect Extraction from Product Reviews, Proceedings of the Second Work- shop on
Natural Language Processing for Social Media (SocialNLP), Association for
Computational Linguistics and Dublin City University, Dublin Ireland, pp 28-37. DOI:
10.3115/v1/W14- 5905
L. Qu, G. Ifrim, and G. Weikum. The bag-of-opinions method for review rating
prediction from sparse text patterns. In Proceedings of the 23rd International Conference
on Computational Linguistics (COLING 2010), pages 913–921, 2010.
T.A. Rana, Y.N. Cheah, S.Letchmunan. 2016 Topic modeling in sentiment analysis: A
systematic review. Journal of ICT Research and Applications, 10(1) (2016), pp.76-93
I, Titov, R,T. McDonald. 2008b. A joint model of text and aspect ratings for sentiment
summarization. In ACL 2008, Proceedings of the 46th Annual Meeting of the
Association for Computational Linguistics, June 15-20, 2008, Columbus, Ohio, USA,
38
H.Wang, Y. Lu, and C. Zhai. 2011. Latent aspect rating analysis without aspect keyword
supervision. In Proceedings of the 17th ACM SIGKDD International Conference on
Knowledge Discovery and Data Mining, KDD ’11, pages 618– 626, New York, NY,
USA. ACM.
H. Wang and M. Ester. 2014. A sentiment-aligned topic model for product aspect rating
prediction. In EMNLP, pages 1192–1202.
Xu X., Cheng X., Tan S., Liu Y., Shen H. Aspect-level opinion mining of online
Appendix
The following part are lists of words created for each aspect.
Aspects Aspect-related nouns
Location 'location','place','bar','shop','taxi','beach', 'site', 'facility',
'tube', 'traffic', 'boulevard', 'street', 'shuttle', 'boutique',
'position', 'avenue', 'beach', 'distance', 'restaurant', 'block',
‘route'
Policy 'policy', 'recption',
'service','quality','staff','waiter','waitress','prepare','price',
'staff', 'concierge', 'management', 'charge', 'guide', 'guest',
'customer', 'website', 'price', 'dollar', 'worth', 'pay', 'value',
'bargain', '
Food 'taste','food','coffee', 'drink', 'dinner', 'buffet', 'tea', 'meat',
'seafood', 'cuisine', 'cheese', 'bread', 'snack', 'wine',
'appetizer', 'dessert'
Environment 'wifi', 'experience', 'quality', 'vocation', 'floor','table',
'atmosphere', 'accomodation', 'accomodate', 'expectation',
'sanitation','environment','health','hygiene','surrounding'
Aspects (Sentiment)
Aspect-related sentiment words:
Environment
(positive) 'clean','good','quiet','decent', ‘accessible’, superb, nice, good,
great, perfect, favourite, wonderful, excellent, amazing, top,
underrated
Environment (negative)
’disappointed','bad','nasty','crouded','noisy', 'dirty', ‘bug’, nasty,
noisy, terrible, disastrous, worse, worst, hell, disappointed,
disgusting, sad
Location
(positive) 'good','easy','pleasant','pleased','decent','fun', 'convenient', 'close',
‘soothing', ‘enjoyable’ Location (negative) 'disappointed','hard','busy','annoy','underground' Policy (positive) 'friendly','24hour', 'welcoming','fantastic','nice','communicative','helpful','super',
‘available', 'great','good','pleased','quick','fast','decent','organic',
'courteous'
Policy
(negative) ’bad','confusing','improper','late','disrespect','tragic', 'overpriced',
'pricy'
Food
(positive) great, tasty, delicious, pleasant
Food
(negative) gross, disgusting, slow, outdated
Attribute Values Extracted From Attribute Column in business.json
AcceptsCreditCards
HasGarage
StreetParking
HasParkingLot
DoesCater
IsGoodforKids
HasDessert
HasLateNight
HasDinner
HasBrunch
HasTV
GoodForGroups
AllowsReservations
HasTableService
WheelchairAccessible