Hely Mehta. Validating Medical Queries with Literature from PubMed using Topic Modelling. A Master’s Paper for the M.S. in I.S degree. May ,2020. 52 pages. Advisor: David Gotz
Finding relevant literature that can be used to validate a search query is an interesting and complex task based on the nature of the search query. This study aims to find relevant titles and abstracts from PubMed that would provide insight on the search queries and analyze them using Topic Modelling techniques specifically using the Latent Dirichlet Allocation algorithm. A search query in this context would be comprised of the medical conditions that combined are indicative of a certain outcome. Medical queries would be predefined, and the PubMed NCBI-E-Utilities would be used to collect abstracts and titles for those queries.
Headings:
Medical Literature Analysis
Text Mining
Information Retrieval
VALIDATING MEDICAL QUERIES WITH LITERATURE FROM PUBMED USING TOPIC MODELLING
by
Hely Mehta
A Master’s paper proposal submitted to the faculty of the School of Information and Library Science of the University of North Carolina at Chapel Hill
in partial fulfillment of the requirements for the degree of Master of Science in
Information Science.
Chapel Hill, North Carolina
October 2019
Approved by
_______________________________________
Table of Contents
Introduction ... 3
Literature Review... 6
Searching for Medical Literature ... 6
Text Mining ... 12
Topic Modelling... 14
Research Question ... 18
Methodology ... 19
Data Collection Methods ... 19
Data Analysis Methods ... 23
Text Cleaning and Processing ... 23
Building Topic Models ... 24
Topic Model Evaluation ... 25
Results ... 28
Dataset... 28
Coherence Score Comparison ... 29
Topic Interpretation ... 31
Discussion ... 36
Observing the topics ... 38
Generalizable Findings ... 43
Conclusion ... 45
Introduction
Finding relevant literature from a domain is a difficult task especially when the
scale of research papers increases rapidly. Once we define the terms to search for these
papers and retrieve them for a specific domain, we can analyze them to understand if they
are indeed “relevant” to our search query and the domain. For this study, I am interested
in analyzing and determining relevant literature pertaining to the Medical domain.
While searching for literature that is related to a medical research or study,
medical science researchers and medical professionals often have to spend an enormous
amount of time looking for past literature that provides them with important insights on
the previous research done and the results that were obtained. This leads to other
important questions of whether a given paper has more information on the given medical
topic. For example, a paper that discusses effects of kidney failure in patients might have
information that discusses other past symptoms or procedures that patients might have
undergone. It might also have information about a specific procedure or medicine that
was proposed that helped certain patients from an acute kidney failure as an outcome.
Thus, analyzing relevant literature would provide a deeper insight in understanding
whether the particular paper contains information that would support the search query.
Searching for literature in terms of published research studies and scientific
papers in various medical and scientific journals has become an online information
engines return a huge amount of results for a given search query. Hence an
analysis of the results would reveal which results are actually relevant.
Google scholar, Yahoo Search and PubMed are some of the popular web-based
search engines used for searching literature online. For this study I want to consider
PubMed for collecting literature for a given search query as it is one of the largest online
information sources for Medical Literature. It is used widely among the medical research
and medical professional community. PubMed also supports various features to refine a
query which would help in retrieving better results.
PubMed is a free search engine based on the Medical Literature Analysis and
Retrieval System Online (MEDLINE) database of references and abstracts on life
sciences and biomedical topics. It is maintained by the National Center for Biotechnology
Information (NCBI) at the United States National Library of Medicine (NLM).[1]
In the context of this study, a “search query” will be formed from a pre-defined sequence
of medical events that together are indicative of an outcome. These sequences originate
from a user’s interaction with a visualization that is formed from structured medical data.
Hence, the search query is formed form such a sequence instead of a traditional keyword
search.
These medical events and sequences used for this study are generated from visualizations
from Cadence, a visual analytics platform for event sequence analysis.
The Cadence software was developed at the Visual Analytics and Communication
Lab (VACLab) at the University of North Carolina at Chapel Hill. The VACLab is
affiliated with the School of Information and Library Science and the Carolina Health
The search queries are formed by analyzing patient medical data that
have gone through a specific sequence of treatments. I would collect data from PubMed
for these pre-defined search queries and then analyze the results to understand which
papers are relevant.
For this study, I want to look at titles and abstracts of the papers returned by the
search query in PubMed. Analyzing the full text of a paper would quickly become a very
complex task and would require some complex text mining techniques. Even while
considering abstracts, analyzing them would require some significant text mining tasks.
For analyzing the abstracts and titles I would use Topic Modelling as the goal is to find
documents that would summarize the sequence of medical events in terms from the
visualization by topics instead of finding a ranked list of documents. This approach
Literature Review
This study contains two major parts: Searching and retrieving titles and abstracts
for search queries from PubMed and analyzing the results to determine their relevance.
The first task falls into domain of Information Retrieval and since the search queries
pertain to the Medical domain and PubMed is the search engine, the first section provides
a brief overview about searching for medical literature and how it can be performed using
PubMed. The subsequent sections are related to the second part of the study. For
analyzing text data, there is brief overview of Text Mining discussing Information
Extraction and what a term frequency-inverse document frequency model is. Finally,
there is a discussion about Topic Modelling techniques as it is the technique used for
analyzing the data retrieved from PubMed.
Searching for Medical Literature
Searching for medical literature has been an interesting domain of research and
has evolved with technology from traditional physical paper search to online web-based
search engines. Since the domain of the search queries for this study is pertaining to
Medical Literature it is important to understand how information retrieval methods and
In 1959, Seymour Taine[3] of the National Library of Medicine estimated
that 220,000 indexable medical articles are published each year and The Current List of
Medical Literature (Hare J., 1941)[4] at the time was able to cover just about half of these.
The Current List of Medical Literature was one of the earliest exhausted, classified index
of literature in any scientific field. The first list appeared in 1941.
The sheer magnitude of medical literature became impossible to deal with using
the traditional methods of indexing medical records. To this end, the Medical Literature
Analysis and Retrieval System (MEDLARS) was created and introduced by the National
Library of Medicine in 1964 to automate the composition of the Current List of Medical
Literature. Central to MEDLARS is the concept of a single, integrated system based on
the combination of several basic bibliographic services (Taine,1964)[5].
One of the central aspects of MEDLARS while indexing medical literature was
the use a controlled vocabulary called the Medical Subject Headings (MeSH). This
vocabulary is built for the organization for all health-related knowledge. The research
articles are indexed using MeSH.
In less than a decade MEDLARS became one of the largest machine-readable
databases in the world with citations for over 1.5 million research articles for medical
literature. With that in 1971, the National Library of Medicine introduced Medical
Literature Analysis and Retrieval System Online (MEDLINE) as a prototype for online
bibliographic search system. The MEDLINE system could be searched using MeSH or
by using simple text (McCarn D.B., 1980) [6]. The most popular way to access MEDLINE
component of PubMed but it also contains publisher-submitted citations that
have not been indexed by MEDLINE (Delwiche, 2008) [7].
Using web-based search engines for information retrieval is the most popular and
easiest way to search for information online. Popular ways to search for Medical
Literature are through Google, Google Scholar, Yahoo Search and PubMed (Steinbrook,
2006 )[8].When going through free text search options like Google and Yahoo Search,
users see articles that best match the query and they aren’t bound in context of the issues
relating to the query or in context of well-known journals. With usage of Google Scholar
finding scientific articles from Scientific Journals using free text queries has increased.
One of the consistent ways to search for Medical Literature from structured data is using
PubMed.
PubMed can be defined as an Indexed Bibliographic Database for searching
Scientific Literature. In “Searching the medical literature” by G Gore (2003)[9] , defines
Indexed Bibliographic Databases as a structured collection of descriptive information
used to identify publications, such as journal articles. The information is organized into
searchable fields (such as author, title or subject). PubMed indexes papers from various
journals. The most indexed sections of an article are the title, authors’ name, the source,
abstract (it sometimes includes the full text). It was developed as a part of NCBI’s Entrez
Retrieval System that provides access to a diverse set of 38 databases. It includes
abstracts and citations from over 5000 journals for biomedical articles (Lu, Z.,2011) [10] It
is the primary tool used for searching and retrieving biomedical literature using clinical
queries. It was considered a good choice for collecting the search results for medical
the articles particularly title and abstract. It is also the largest biomedical
resource available online and is freely accessible. It is updated regularly, hence providing
users with the most recent medical literature.
The following is the general flow of a PubMed search query.
Figure 1: Overview of general user interactions with PubMed for searching literature.
Adapted from Dogan et al., (11).
When a search query is entered in natural language, PubMed considers them as
free text keywords and matches input keywords. It does not consider stop-words in the
query. It allows users to tag search terms in the query with quantifiers to improve user’s
original searches (i.e. search term[tag]). When a user makes an untagged or free-text
search query PubMed automatically tags search terms using a process called Automatic
Term Mapping (ATM) (Lu et.al, 2008).[12]
ATM maps the untagged search terms used in the query to pre-indexed terms in
Headings (MeSH) tables, author name tables, journal name tables. For the
medical search queries considered in this study MeSH can be used to translate the search
terms in the query to retrieve better results from PubMed. For example, a search query
“Heart Failure” would be mapped to include MeSH terms indexed with it. The search
results would include literature with the term “congenital” as well.
Another way to extract data or in this case results for a search query from
PubMed is to utilize several public APIs that allow programmatic access to many
databases and tools. PubMed Central (PMC) APIs provide programmatic access to the
PubMed Central literature content. The NCBI provides the Entrez Programming Utilities
(E-Utilities). It is collection of 8 server-side programs that provide a way to query the
database system at NCBI. It converts a limited amount of input parameters into a fixed
URL syntax to search and retrieve results for a given query.
Thus, before analyzing the search query results a formative step in the study
would be to use PubMed’s searching mechanism to retrieve the best results. There are
nine E-Utilities and each of them performs a specific task. From these nine functions two
of them can be used for collecting the abstracts from PubMed needed for this study. The
E-Utilities server can be reached using a base URL.
The base URL https://eutils.ncbi.nlm.nih.gov/entrez/eutils/. The Esearch utility is
used for searching a text query against a single database. Each Entrez database refers to
the data records using a unique integer-based identifier. PubMed assigns a PMID to all
citations in their database. For example, a text search query “heart disease and heart
attack” can be made using ESearch utility by the following URL syntax
e+and+heart+failure. The major things to note here is db and term parameters
passed to the URL, db is the database and term are the text terms in the search query. The
response is received in the XML format which contains all the PMID’s that matched the
search query.
Figure 2: Response from ESearch query in XML format
The next task would be to take the PMID’s and retrieve the actual abstracts or
content the PMID’s are referring to. This is done through the EFetch utility. The URL
syntax for EFetch is as follows
https://eutils.ncbi.nlm.nih.gov/entrez/eutils/efetch.fcgi?db=pubmed&id=27558065,27466
125,27127816,26842040&retmode=abstract&rettype=text. The db parameters remains
the same and id parameter is used for passing all the PMID’s retrieved by ESearch. The
retmode and rettype parameter defines what part of the record and type needs to be
Text Mining
Text Mining is a Knowledge-Discovery technique that is used in in analyzing and
finding information that is relevant to the user. Text Mining techniques are considered
useful in the context of this study as we want to find whether the abstracts contain useful
or relevant information. Text Mining deals with analyzing data that is either unstructured
or semi-structured in nature. This aspect is of great importance as most of data that we
deal with today is in the unstructured form as opposed to structured or database form.
Text Mining requires understanding and interacting with other domains such as Natural
Language Processing, Machine Learning, Statistics and Information Extraction.
Information Extraction is a major problem in Text Mining.
The general goal of Information Extraction in the text mining process is to form
some sort of structured data from semi-structured or unstructured data. One of its
fundamental tasks is Named Entity Recognition (NER) which is used to identify named
entities from free form text into types such as location, person, medical codes,
expressions (Aggrawal, 2012).[14] One can build on this technique to then extract useful
relationships between these entities. In medical literature researchers often must sift
through many scientific journals for discovering relationships between different medical
symptoms and conditions. In such cases a simple keyword search may not suffice as
medical terms may have synonyms and other ambiguous names. Hence, it is useful for
identifying entities which are related to each other.
Many NER and information extraction systems make use of list of words of
entities. These are also referred to as dictionaries sometimes. These groups are often
research studies have used unsupervised word clustering methods to generate
such list of words to significantly improve the performance of an entity tagging of genes
in biomedical text (Jiang, 2012)[15] Discovering relations between medical entities
identified by NER can be done using co-occurrence statistics. Co-occurrence methods
can be pattern-based methods that might focus more on linguistic conditions for finding
relations. This involve running natural language processing technique such as parts of
speech on sentences and then finding linguistic relations on these phrases (noun phrase,
verb phase, etc.). There are statistical based co-occurrence methods too such as
pointwise mutual information which uses the word counts of entities over the entire
corpus.
With text analysis consisting of short texts or paragraphs often summarization
techniques are employed. These techniques generally rely on intermediate representation
of text and then identify important content based on this representation.
There are many approaches used, such as frequency-based analysis, Term
Frequency- Inverse Document Frequency weighting, topic word approaches and latent
semantic approaches. In latent semantic based approach, patterns of word co-occurrence
are identified and based on those patterns, they are converted to topics that they might
represent. In Term Frequency- Inverse Document Frequency (TFIDF) approach uses two
quantities- term frequency (c(w)) and document frequency (d(w)). The term frequency is
determined by the number of times that word occurs in a given document divided by the
number of words in the document. The document frequency is determined by number of
times the word occurs in all the documents (D) divided by the total number of documents.
The TFIDF model is a simple way to represent topic words which appear often in
a document but are not very common in other documents, thereby increasing their
importance. The TFIDF is determined in many ways by varying the weight factor of term
frequency and document frequency. These weight factors can be considered as tuning
parameters for web search engines to determine if a given document is relevant for a
given query. The TFIDF model can be used for filtering out documents that aren’t
relevant to a given search query by tuning the weights for term frequency and document
frequency. The documents can then be ranked or scored from most important to least
important based on their TFIDF score.
Topic Modelling
To understand and manage a rapid growth of online document archives, new
methods need to be developed for organizing and indexing such large collections. With a
greater number of documents, the techniques need better ways to find patterns in words
of a document. One such hierarchical probabilistic modelling technique is called topic
modelling. As the name suggests this technique tries to find the underlying topics by
finding patterns in the words. Topic modelling provides a generative model for
documents, where each topic is distribution over the words found in the document.
According to Seungil and Stephen, 2010[17], “Each document in each corpus is
modeled by a distribution over a certain number of topics, each of which is a
distribution over words in the vocabulary. By learning the distributions, a corresponding
low-rank representation of the high dimensional histogram can be obtained for each
document
This indicates that in terms of text mining methods, topic modelling follows a
“bag-of-words” approach which ignores ordering of words. In a nutshell, topic modelling
tries to break down a document in a probability distribution over topics, those topics are
distributed over concepts and the concepts are distributed over words.
Topic Modelling methods generally fall into two categories, one that follows bag
of words approach includes Latent semantic analysis (LSA), Probabilistic Latent
Semantic analysis (PLSA), Latent Dirichlet allocation (LDA) and Correlated topic model
(CTM). The other category of topic models is called topic evolution models and they
employ methods such as Dynamic Topic Models (DTM) and topic over time (TOT).
Topic evolution models consider an additional factor of time. These methods consider
time where the topics in each corpus can evolve overtime. In this study for data analysis,
the first category of topic modelling methods is of interest as I want to find the topics the
results of a given search query clusters into (Hofmann, T., 2001).[18]
Latent Semantic Analysis (LSA) was one of the earliest method initially
formulated for improving information retrieval in Dumais, Furnas, Landauer, and
Deerwester (1988)[19] and Deerwester, Dumais, Furnas, Landauer, and Harshman
(1990)[20]. LSA creates a vector-based representation of texts and finds semantic content
within it. It tries to pick the highest efficient related words by computing the similarity
formed from the documents. SVD is used for dimensionality reduction of the
matrix. Similarity measures are then computed to retrieve the most similar documents. It
recognizes relationships between words based on their constituent words and their
occurrence in the documents. LSA was adopted widely but it’s one weakness was its
unsatisfactory statistical foundation as explained by Hoffman (1990) [21] , in which he
proposes PLSA method. PLSA uses a statistical model called the aspect model, as an
alternative to the LSA. It models each word in a document as a sample from a mixture
model and the components of this mixture can be thought of as representations of
“topics”. This is how a document is reduced to a distribution of topics in PLSA. Both
PLSA and LSA are based on the “bag-of-words” assumption, which means that the order
of the words in a document is not important and can be neglected. This assumption also
extends to documents wherein the methods assume that the specific ordering of
documents in a given corpus can also be neglected. Thus, the topic modelling method
should consider mixture models that captures neglecting ordering in both words and
documents. This was the basis of Latent Dirichlet Allocation proposed in Blei et. al
(2003) [22] . They describe LDA as a generative probabilistic model for a corpus and
describe the documents as a random mixture over latent topics and each topic is
determined by a distribution over words.
LDA is one of the most widely known and used methods for topic modelling and
so for the purpose of this study, it was useful to understand what were the assumptions
and motivations that led to its development. LDA seems applicable for the analysis of
text in this study as the goal of Blei et all was described as “find short descriptions of the
preserving the essential statistical relationships that are useful for basic tasks
such as classification, novelty detection, summarization, and similarity and relevance
judgments.”
LDA is an unsupervised topic modelling technique and several ways are proposed
for evaluating the interpretability of the topics generated from the topic models. The goal
has been to automate the human interpretability of the topics. In Chang et al. (2009) [23]
the notion of “intruder words” was introduced where words were randomly placed in the
topics and users were asked to identify the words. This idea was built on the assumption
that it would be easy to identify random words in a coherent topic as compared to an
incoherent topic. This method was widely used but was a time-consuming process as it
relied on manual annotation and could not be automated. Newman et al. (2010) [24] was
one of the first effort that introduced the notion of topic coherence and discussed an
automated method for estimating topic coherence using Pairwise mutual information. For
this study we look at the coherence score of the topic models that are generated and use it
Research Question
The goal of this study is to find relevant titles and abstracts from PubMed that
would either support or provide insight on the search queries. The search queries would be
predefined and would be related to the Medical Domain.
The primary research question for this study was- are the returned search results relevant
to the given query? In order to answer this, I broke the question further into “how references
are relevant?”
This gave me an idea to investigate methods for analyzing abstracts to determine
their relevance. I decided to form a topic model that would look at the topics that can be
determined from the titles and abstracts for a given query from PubMed.
For analyzing the search query, I looked at different text mining techniques which can be
used to process the abstracts and titles returned by PubMed.
Using topic modelling, I am interested in analyzing the abstracts and implement
LDA topic modelling to determine the topics they form. The topic clusters formed, would
help determine if the abstracts and titles returned from PubMed are about the medical
Methodology
Data Collection Methods
The initial step in the data collection process was focused on creating search
queries formed from a sequence of medical events observed in Cadence. As a result, 4
such medical event sequences were generated and using those a simple free text search
query was created.
After determining the terms that can be used from the medical sequence, a search
query was formed. These are the four sequences of medical events extracted from
Cadence.
(b)
(d)
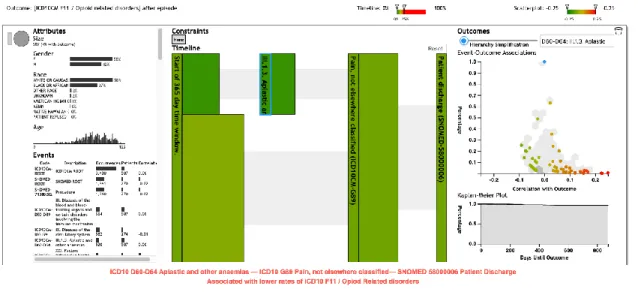
Figure 3 (a, b, c, d): Sequence of medical events taken from Cadence (Provided
by Dr. David Gotz (Associate Professor at School of Information and Library Science,
UNC-Chapel Hill)
Each of these sequences have been tagged by the medical events present in it.
Using them, the terms for each sequence can be determined. For example, the first
sequence contains “nicotine dependence” and “pain”. These can be converted to a simple
text query “nicotine pain”.
Hence for each sequence these terms were determined. With every progressive
sequence the terms were more complicated or more medical oriented such as in sequence
3.c the term “Diagnostic Radiography, Combined AP and lateral”. For terms like this, I
consulted the Unified Medical Language System (UMLS) [25] and entered these terms in
their SNOMED database. As seen in the figure this term has a SNOMED code. Using
UMLS, I looked for synonyms for this term to see if they could be broken down into
simpler terms. I also searched for these terms on MedlinePlus [26]. It is an online health
service would be people with limited knowledge there were good chances of
finding common terms that could be used. The goal was to find simple terms that can be
used to search PubMed and find as many results as possible. After determining the terms
from each sequence, I conducted a search on PubMed on each of them to see if there
were any results. The final search terms for each sequence are as follows.
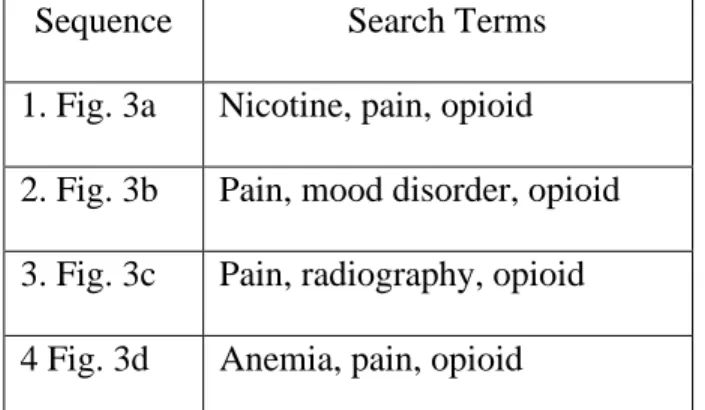
Sequence Search Terms
1. Fig. 3a Nicotine, pain, opioid
2. Fig. 3b Pain, mood disorder, opioid
3. Fig. 3c Pain, radiography, opioid
4 Fig. 3d Anemia, pain, opioid
Table 1: Search Terms used for each sequenceon Pubmed
Every query has “opioid” as a search term as all the sequences have events which
are associated to opioid related disorders.
For each search query I performed the “OR” and “AND” Boolean queries using
the search terms. For each sequence I formed four search queries from the search terms.
One set of Boolean queries were formed from search terms without “opioid” and the
other set with “opioid”. After performing simple search queries on PubMed using these
search terms, I had to find a way to collect those results and process them for data
analysis. I used the NCBI’s E-Utilities as explained earlier. Instead of creating the URL
manually for each query I created a python script with all the required parameters to
extract the top 150 results for each search query.
The E-Utilities are very useful for extracting a lot of data about the research
research articles were collected. There are some articles where only the title is
available but not the abstract. Any research articles without an abstract were skipped and
not collected in the final dataset.
For fetching results from PubMed, I used the Biopython [27] package. It was
created to use Python for bioinformatics. It contains methods and classes to extract
information from the Entrez system and the PubMed service. For each search query, the
results were stored in a csv file making it easier to access and process.
Data Analysis Methods
The main aspect of analyzing the data is through creating Topic Models and
interpret whether the topics are relevant for the given search query. In order to created
said topic models I first had to create a text cleaning and processing pipeline. The next
step was to prepare the text for creating an LDA topic model. The first section describes
text cleaning and processing and the next section describes preparing the text for topic
modelling and the technique used for creating an LDA topic model.
Text Cleaning and Processing
The text was cleaned and processed using the following steps: Tokenization, POS
Tagging and Lemmatization. I created a pipeline for cleaning the text using two Natural
Language Processing (NLP) python libraries namely NLTK and SpaCy. NLTK is a
powerful NLP toolkit designed for carrying out NLP tasks from tokenization to text
open-source software library written in Python and Cython. SpaCy provides
powerful tokenization functions that support more than 50 language models.
Hence the tokenization step is carried out using SpaCy’s English model. Using
other functions, the text was tokenized by removing any whitespaces, stop words,
punctuation. I added more stop words to the stop word list and regex patterns to remove
some of the embedded html tags such <i>, <b> and <sub> present in the text.
I used NLTK’s POS tagger to retrieve all the verbs and nouns from the tokens as those
would be the most important parts of speech in the text for forming topics in the topic
models.
Lemmatization is the process of converting a word to its base form. Since
lemmatization considers the context of the word and tries to convert it to its most basic
form, I preferred using it over just stemming the word tokens. I used the WordNet
Lemmatizer from NLTK to complete the lemmatization.
Building Topic Models
The next step was to create an LDA model based on the tokens extracted in the
previous step for each search query. I used Gensim for creating the LDA models for this
study. Gensim is an open-source python library used for unsupervised topic modelling
and natural language processing. It includes implementation for Latent Semantic
Analysis, Text-Frequency-Inverse Document Frequency and Latent Dirichlet Allocation.
In order to create a base LDA model we need to create a dictionary of tokens and
a corpus which assigns a unique id to each word in the dictionary and maps it to its word
Topic Model Evaluation
The basis of topic modelling is to “learn” topics which are typically represented
as sets of important words which are formed from unlabeled documents. Due to
unsupervised learning of the topics generated in a topic model it is difficult to evaluate
the quality of the models. However, there are some objective measures to determine how
good the topic models are. There are several evaluation metrics- intrinsic evaluation
metrics such as topic interpretability, extrinsic evaluation metrics such as how well the
models perform tasks such as classification and human judgement to interpret the quality
of the topics.
For this study we look at the topic coherence, an intrinsic measure to determine
the quality of the topic model.
Before defining topic coherence, we need to understand what coherence is. A set
of documents or sentences can be coherent if they support each other. Topic coherence
measures try to measure coherence between the topics by measuring the degree of
semantic similarity between high scoring words in the topic. The topic coherence
measure used in this study is called Cv. A study which systematically and empirically
explored most of the topic coherence measures and their correlation with available human
topic ranking data conducted by Röderet.al.[28] discovered this coherence measure.
The Cv coherence measure is calculated in a four-step process:[29].
i. Segmentation of the data into word pairs.
ii. Calculation of word probabilities.
iii. Calculation of a confirmation measure which helps in quantifying how strongly a
iv. Aggregation of individual confirmation measures into an overall
coherence score.
Data segmentation pairs each topic’s top N words with every other top-N word.
Probability of each word with set of words is calculated by counting the occurrence of a
word or set of words divided by total number of documents. For every segment formed a
confirmation measure is calculated using similarity measures such as Normalized
Pointwise Mutual Information (NPMI). Each word set is represented as context vectors
and the NPMI is calculated between the words present in each set. Then the confirmation
measure is calculated using cosine similarity between all the context vectors. The final
coherence measure is the arithmetic mean of all the confirmation measures.
Gensim provides a coherence model to calculate the coherence score for an LDA
model. This coherence model will be used in the find the coherence score of all the topics
models and find the model with the highest coherence score.
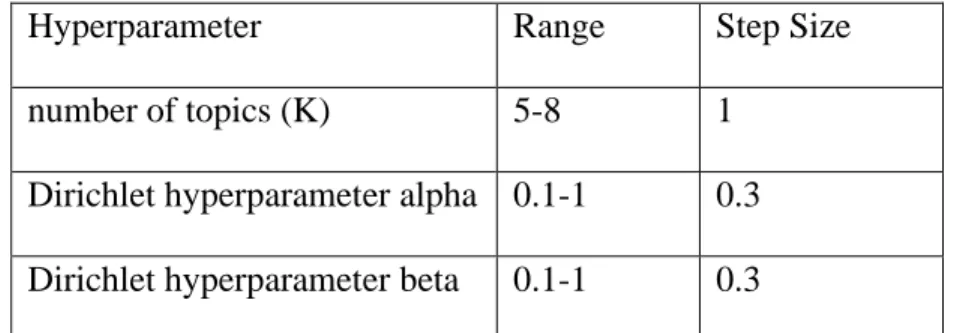
The other factor that can be used to improve the quality of the topic models is to
tune the hyperparameters of the topic model. The model hyperparameters can be thought
of as knobs that can be fine tuned for a machine learning algorithm to find the best
model. There are 3 such hyperparameters, namely number of topics (K), Dirichlet
hyperparameter alpha: Document-Topic Density and Dirichlet hyperparameter beta:
Word-Topic Density that can be tuned for a given topic model.
A higher value of alpha means that each document is likely to contain a mixture
of most of the topics and not any single topic specifically. A low alpha value reduces
such constraints on documents and would mean that a document may contain a mixture
similarly but with respect to words. A high beta value means every topic is
likely to contain a mixture of most of the words and a low value means that a topic may
contain a mixture of just a few words. Tuning these parameters will yield a better
coherence value thereby forming a good topic model for the given set of documents.
For each search query, first a base LDA model is build using only number of
topics (K) and passes (i.e. iterations over the corpus) and its coherence score is
calculated. Then a series of sensitivity tests can be conducted to find the model
hyperparameters that yield the highest coherence score.
After finding the topic model with the best coherence score, the topics generated
by the topic model can be visualized and evaluated using the PyLDAvis package. It is an
interactive LDA visualization python package. This interactive visualization package was
developed primarily for understanding the meaning of each topic and how the topics
relate to each other (C Sievert, K Shirley,2014) [30].
The visualization is divided into two sections. The left section of the chart plots
each topic as a circle in a two-dimensional plane. The area of the circle depicts its
prevalence in the corpus. The centers of the circles are calculated by the distance between
the topics. They are then scaled to project the inter-topic distances onto two dimensions.
The right section of the visualization is a bar chart that show the most relevant terms for
each topic which can be used to interpret the topic.
By hovering over a topic on the left we can find the most useful terms that can be used
Results
Dataset
As mentioned before for each sequence four Boolean searches were made to
collect data from PubMed, two with opioid combined with all the other search terms and
two with only the rest of the search terms. The abstracts and titles of the top 150 results
were extracted. The next step was to build topic models for abstracts and titles from the
results collected.
As with the Boolean searches, the topic models are divided into sets, one that are
formed from combining the results of the Boolean search with search terms with opioid
and the other without it. For each sequence we get four topic models- two for abstracts
and two for titles. First a base LDA model is created for each document set by keeping
the number of topics to 5 and its coherence score is calculated. The final four models for
each sequence were decided after running sensitivity tests for the model hyperparameters.
The range for the hyperparameters are as follows:
Hyperparameter Range Step Size
number of topics (K) 5-8 1
Dirichlet hyperparameter alpha 0.1-1 0.3
Dirichlet hyperparameter beta 0.1-1 0.3
A topic model for every combination of these hyperparameters was
generated and its coherence score was measured. The model with the highest coherence
score from the 120 topic models was selected as the final model. This process was
repeated for every document set. This was a time-consuming process and Google Cloud
VM instance was used with a 30GB memory to perform this step. The final model LDA
model for each document set is visualized using PyLDAvis to find the most relevant
words that help determine the topics.
Coherence Score Comparison
The coherence scores for the base model and the best model are calculated for
each document set and grouped according the sequence and search terms. The model
parameters of the best model are also noted. The comparisons are made separately for
abstracts and titles.
Sr. No Search terms Base LDA
Model
Coherence
Score
Best LDA
Model
Coherence
Score
Model
Hyperparameters
Alpha
(a)
Beta
(b)
No. of
topics
(k)
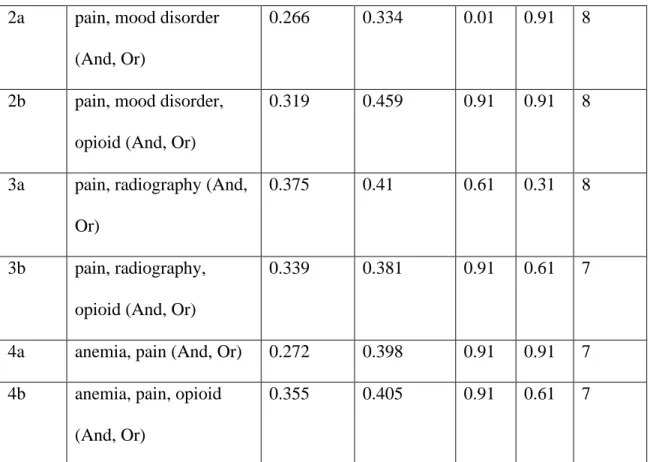
1a pain, nicotine (And, Or) 0.34 0.369 0.91 0.61 5
1b pain, nicotine, opioid
(And, Or)
2a pain, mood disorder
(And, Or)
0.266 0.334 0.01 0.91 8
2b pain, mood disorder,
opioid (And, Or)
0.319 0.459 0.91 0.91 8
3a pain, radiography (And,
Or)
0.375 0.41 0.61 0.31 8
3b pain, radiography,
opioid (And, Or)
0.339 0.381 0.91 0.61 7
4a anemia, pain (And, Or) 0.272 0.398 0.91 0.91 7
4b anemia, pain, opioid
(And, Or)
0.355 0.405 0.91 0.61 7
Table 3: Base LDA model and Best LDA model Coherence Score and model
hyperparameters for Abstracts
Sr. No Search terms Base LDA
Model Coherence Score Best LDA Model Coherence Score Model Hyperparameters Alpha (a) Beta (b) No. of topics (k)
1a pain, nicotine
(And, Or)
0.429 0.431 0.01 0.61 6
1b pain, nicotine,
opioid (And, Or)
2a pain, mood
disorder (And,
Or)
0.407 0.442 0.61 0.01 8
2b pain, mood
disorder, opioid
(And, Or)
0.433 0.443 0.01 0.61 5
3a pain, radiography
(And, Or)
0.363 0.396 0.01 0.61 8
3b pain, radiography,
opioid (And, Or)
0.415 0.466 0.61 0.61 8
4a anemia, pain
(And, Or)
0.297 0.402 0.91 0.01 7
4b anemia, pain,
opioid (And, Or)
0.382 0.406 0.01 0.91 7
Table 4: Base LDA model and Best LDA model Coherence Score and model
hyperparameters for Titles
Topic Interpretation
For every model we look at the top 10 most relevant terms across the document
set in terms of their overall frequency in the document set and then look at the top 5 terms
for the 3 most prevalent topics of the document set. The pyLDAvis visualizations for
topic models are used to determine this.
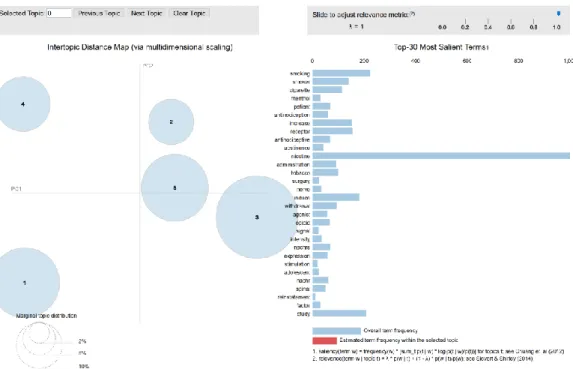
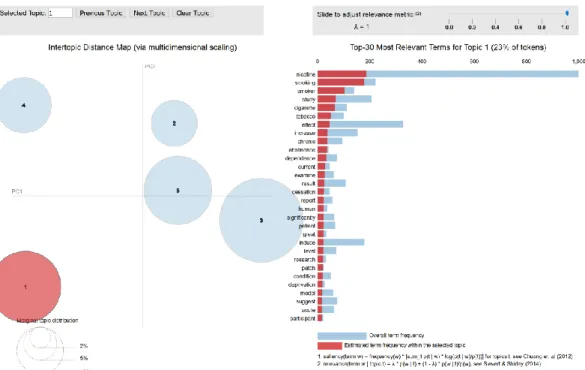
Figure 4: Visualization for abstract topic model 1a
Selecting a topic within the visualization would list the top words for that topic.
The most prevalent topics for this model are topic 1,3 and 5. On selecting topic 1 the top
Figure 5: Visualization for topic 1 for abstract model 1a
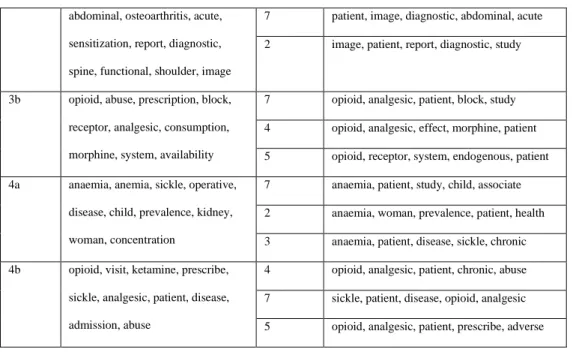
Sr. No Top 10 words Prevalent Topics
Top 5 words for a prevalent topic
1a Smoking, smoker, cigarette, menthol, patient, antinociception, increase, receptor, antinociceptive, abstinence
3 nicotine, effect, induce, receptor, study
1 nicotine, smoking, smoker, study, cigarette
5 nicotine, effect, receptor, induce, increase
1b nicotine, opioid, analgesic, patient, group, abuse, smoker, neuron, cigarette, stress
3 nicotine, effect, smoking, study, induce
5 opioid, patient, analgesic, study, prescribe
2 opioid, analgesic, abuse, prescription, patient
2a depression, disorder, group, cognitive, bipolar, symptom, increase, effect, problem, study
4 disorder, patient, study, anxiety, symptom
2 disorder, study, patient, bipolar, chronic
7 disorder, study, problem, associate, veteran
2b patient, receptor, opioid, disorder, sleep, effect, antidepressant, control, prescription, affective
8 opioid, disorder, patient, chronic, study
4 disorder, receptor, opioid, effect, treatment
5 disorder, sleep, patient, circadian, associate
abdominal, osteoarthritis, acute, sensitization, report, diagnostic, spine, functional, shoulder, image
7 patient, image, diagnostic, abdominal, acute
2 image, patient, report, diagnostic, study
3b opioid, abuse, prescription, block, receptor, analgesic, consumption, morphine, system, availability
7 opioid, analgesic, patient, block, study 4 opioid, analgesic, effect, morphine, patient 5 opioid, receptor, system, endogenous, patient
4a anaemia, anemia, sickle, operative, disease, child, prevalence, kidney, woman, concentration
7 anaemia, patient, study, child, associate 2 anaemia, woman, prevalence, patient, health 3 anaemia, patient, disease, sickle, chronic
4b opioid, visit, ketamine, prescribe, sickle, analgesic, patient, disease, admission, abuse
4 opioid, analgesic, patient, chronic, abuse 7 sickle, patient, disease, opioid, analgesic 5 opioid, analgesic, patient, prescribe, adverse
Table 5: Top 10 most relevant terms of the LDA model and the top 5 words for three
most relevant topics for Abstracts
Sr. No Top 10 words Prevalent Topics
Top 5 words for a prevalent topic 1a smoking, nicotine, patch,
hyperalgesia, acetylcholine, transdermal, smoker, chronic, interaction, model
5 nicotine, effect, receptor, induce, smoking
3 nicotine, effect, smoker, postoperative, patch
1 nicotine, exposure, effect, opioid, interaction
1b nicotinic, cigarette, smoker, smoking, postoperative, opioid, model, control, surgery, trial
8 opioid, analgesic, nicotine, trial, control
2 nicotine, patient, smoking, cigarette, effect
1 opioid, analgesic, cancer, prescribe, treatment
2a chronic, effect, disease, sleep, fibromyalgia, quality, mental, association, implication, anxiety
4 disorder, patient, study, anxiety, association 1 disorder, chronic, patient, symptom, increase 5 disorder, effect, sleep, patient, fibromyalgia
2b opioids, disorder, chronic, therapy, alcohol, buprenorphine, major, receptor, depression, health
4 disorder, opioid, patient, prescription, receptor 3 opioid, patient, chronic, disorder, therapy
resonance, magnetic, diagnostic, clinic, study, abdominal, evaluation, acute, emergency, patient
4 image, resonance, magnetic, study, patient
1 image, diagnostic, evaluation, magnetic, resonance
3b opioid, analgesic, block, randomize, control, guide, ultrasound, patient, cancer, trial
5 opioid, analgesic, study, prescription, review
6 block, guide, ultrasound, control, trial 3 opioid, patient, cancer, analgesic, receptor 4a sickle, disease, surgery, anaemia,
anemia, study, prevalence, woman, adult, treatment
5 anaemia, study, surgery, prevalence, preoperative
6 anaemia, child, study, chronic, association
3 anemia, anaemia, associate, patient, sickle 4b disease, sickle, analgesic, opioid,
acute, clinical, prescription, patient, child, chronic
2 sickle, disease, management, acute, opioid 6 opioid, analgesic, patient, cancer, study
7 opioid, analgesic, sickle, patient, management
Table 6 : Top 10 most relevant terms of the LDA model and the top 5 words for three
Discussion
Observing Coherence Scores
There are two comparisons to be made with respect to the coherence scores for
the LDA model. The first comparison can be made between the base and the best LDA
model. The tuning of the hyperparameters of the LDA model almost always result in an
increase in the coherence score. The second comparison can be made with respect to the
number of search terms i.e. with and without “opioid”.
For abstracts, the highest coherence score observed in base models is 0.375 and
the lowest is 0.266. The difference of coherence score between the best and the base
LDA model for most models is at least 0.05 or higher. For model 2b with search terms
pain, mood disorder and opioid the difference in coherence score was the highest at
0.140. The lowest difference in coherence score was observed for model 1a with search
terms pain and nicotine at 0.029.
The difference in coherence score can be understood better by looking at the
hyperparameters. For abstracts, the models that earn a higher coherence score have an
alpha value higher than 0.5, beta value higher than 0.5 and the number of topics as either
7 or 8. Since, the sensitivity tests were conducted for three values of alpha and beta-
0.01,0.61,0.91, the models with a good coherence score tend to have alpha and beta
This means most of the abstracts for a given sequence have a mixture of topics
instead of a specific topic. The higher number of topics also supports this.
The LDA models with opioid as a search term along with other terms tends to
yield a higher coherence score as compared to the ones without it. The highest difference
is observed between model 2a and 2b at 0.125 and lowest or rather a reverse trend is
observed for model 3a and 3b where the coherence score of 3a (without opioid as the
search term) was more than 3b at -0.029.
For titles, the highest coherence score observed for base models is 0.443 and the
lowest is 0.297. The difference of coherence score between the best and the base LDA
model for most models is at least 0.03 or higher. For model 4a with search terms pain,
anemia and opioid the difference in coherence score was the highest at 0.105. The lowest
difference in coherence score was observed for model 1a with search terms pain and
nicotine at 0.002.
The models that earn a higher coherence score have an alpha value higher than
0.5, beta value less than 0.5 and the number of topics to be either 7 or 8. Since, the
sensitivity tests were conducted for three values of alpha and beta- 0.01,0.61,0.91, the
models with a good coherence score tend to have alpha as 0.91 or 0.61 and beta values as
0.01. This means most of the titles for a given sequence have a mixture of topics instead
of a specific topic, but every topic doesn’t contain a mixture of words due to the low beta
value.
For titles, the LDA models with opioid as a search term along with other terms
Observing the topics
From the top 10 words for each model, a general idea can be formed of what most
of the documents could be about. A closer look at the most prevalent topics reveals what
are the different topics each model is about.
Sr. No Top 10 words Prevalent Topics
Top 5 words for a prevalent topic
Inferred Topic
1a Smoking, smoker, cigarette, menthol, patient, antinociception, increase, receptor, antinociceptive, abstinence
3 nicotine, effect, induce, receptor, study
Nicotine related study possibly studying nerve responses
1 nicotine, smoking, smoker, study, cigarette
Studying Nicotine effects due to smoking
5 nicotine, effect, receptor, induce, increase
Nicotine related study possibly studying nerve responses
1b nicotine, opioid, analgesic, patient, group, abuse, smoker, neuron, cigarette, stress
3 nicotine, effect, smoking, study, induce
Nicotine related study possibly studying nerve responses
5 opioid, patient, analgesic, study, prescribe
Opioid related study possibly about prescribed opioid drugs
2 opioid, analgesic, abuse, prescription, patient
Opioid related drug abuse by patients
2a depression, disorder, group, cognitive, bipolar, symptom, increase, effect, problem, study
4 disorder, patient, study, anxiety, symptom
Study about anxiety patients and disorders observed in them 2 disorder, study,
patient, bipolar, chronic
7 disorder, study, problem, associate, veteran
Study related to disorders observed in veterans
2b patient, receptor, opioid, disorder, sleep, effect, antidepressant, control, prescription, affective
8 opioid, disorder, patient, chronic, study
Opioid related study in patients with chronic disorders
4 disorder, receptor, opioid, effect, treatment
Opioid related study possibly studying nerve responses
5 disorder, sleep, patient, circadian, associate
Studying patients with sleep disorders
3a abdominal, osteoarthritis, acute, sensitization, report, diagnostic, spine, functional, shoulder, image
6 image, patient, clinical, diagnostic, evaluation
Evaluating diagnostic images in clinical patients
7 patient, image, diagnostic, abdominal, acute
Diagnostic imaging in patients with abdominal issues
2 image, patient, report, diagnostic, study
Studying diagnostic images in patients
3b opioid, abuse, prescription, block, receptor, analgesic, consumption, morphine, system, availability
7 opioid, analgesic, patient, block, study
Opioid related study possibly studying nerve responses in patients 4 opioid, analgesic,
effect, morphine, patient
Effects of opioid and morphine in patients
5 opioid, receptor, system, endogenous, patient
Effects of opioid on internal system and nerves in patients 4a anaemia, anemia,
sickle, operative, disease, child, prevalence, kidney, woman,
concentration
7 anaemia, patient, study, child, associate
Anemia related study possibly with children as patients
2 anaemia, woman, prevalence, patient, health
3 anaemia, patient, disease, sickle, chronic
Anemia and sickle cell disease in patients 4b opioid, visit,
ketamine, prescribe, sickle, analgesic, patient, disease, admission, abuse
4 opioid, analgesic, patient, chronic, abuse
Opioid related drug abuse by patients
7 sickle, patient, disease, opioid, analgesic
Opioid use with sickle cell patients 5 opioid, analgesic,
patient, prescribe, adverse
Adverse effects of prescribed opioid drugs in patients
Table 7: Interpreting the topic for most prevalent topics in abstracts
From all the topics across all the models there are some very clear indicators of
documents being about a certain kind of study. “Study” occurs in 10 topics from a total of
24 topics. There are also strong indicators about studying the effects in a specific
population with “patient” occurring in 17 topics. There were a few topics with clear
indication of the demographics about the patients with one topic mentioning veteran and
other mentioning women. The topics for models with search terms including opioid are
mostly dominated by opioid related issues occurring in 10 out of the 12 topics. The
search term “pain” isn’t seen explicitly in any of the topics across all models, but the
results contain indicators such “analgesic” which is a pain-relieving drug is seen in some
topics.
Sr. No Top 10 words Prevalent Topics
Top 5 words for a prevalent topic
Inferred Topic
1a smoking, nicotine, patch, hyperalgesia, acetylcholine,
5 nicotine, effect, receptor, induce, smoking
transdermal, smoker, chronic, interaction, model
3 nicotine, effect, smoker, postoperative, patch
Effects of nicotine patch in smokers after undergoing surgery
1 nicotine, exposure, effect, opioid, interaction
Effects of nicotine and opioid interaction
1b nicotinic, cigarette, smoker, smoking, postoperative, opioid, model, control, surgery, trial
8 opioid, analgesic, nicotine, trial, control
Trial for nicotine and opioid
2 nicotine, patient, smoking, cigarette, effect
Studying Nicotine effects due to smoking
1 opioid, analgesic, cancer, prescribe, treatment
Effects on prescribed opioid drugs for cancer treatment
2a chronic, effect, disease, sleep, fibromyalgia, quality, mental, association, implication, anxiety
4 disorder, patient, study, anxiety, association
About anxiety patients and disorders observed in them
1 disorder, chronic, patient, symptom, increase
About symptoms in patients with chronic disorders
5 disorder, effect, sleep, patient, fibromyalgia
Patients with sleep disorders 2b opioids, disorder,
chronic, therapy, alcohol, buprenorphine, major, receptor, depression, health
4 disorder, opioid, patient, prescription, receptor
about prescribed opioid drugs with possible mood disorders 3 opioid, patient,
chronic, disorder, therapy
About patients with chronic disorders undergoing therapy 1 disorder, chronic,
patient, opioid, major
3a resonance, magnetic, diagnostic, clinic, study, abdominal, evaluation, acute, emergency, patient
3 image, diagnostic, patient, study, abdominal
Study about diagnostic imaging in patients with abdominal issues
4 image, resonance, magnetic, study, patient
Study that involves magnetic imaging in patients
1 image, diagnostic, evaluation, magnetic, resonance
Studying diagnostic images in patients
3b opioid, analgesic, block, randomize, control, guide, ultrasound, patient, cancer, trial
5 opioid, analgesic, study, prescription, review
Studying effects of prescribed opioid drugs
6 block, guide, ultrasound, control, trial
Ultrasound results in trail patients
3 opioid, patient, cancer, analgesic, receptor
Effects of opioid drugs possibly on cancer patients 4a sickle, disease,
surgery, anaemia, anemia, study, prevalence, woman, adult, treatment
5 anaemia, study, surgery, prevalence, preoperative
Study of preoperative and surgery in patients with anaemia 6 anaemia, child, study,
chronic, association
Anemia related study possibly with children as patients
3 anemia, anaemia, associate, patient, sickle
Anemia and sickle cell disease in patients
4b disease, sickle, analgesic, opioid, acute, clinical, prescription, patient, child, chronic
2 sickle, disease, management, acute, opioid
Opioid use with sickle cell patients
6 opioid, analgesic, patient, cancer, study
7 opioid, analgesic, sickle, patient, management
Opioid use with sickle cell patients
Table 8: Interpreting the topic for most prevalent topics in titles
Overall, the topics for titles were harder to decipher as compared to the abstracts.
This is probably due to the high value of alpha causing a greater mixture of topics in the
documents. It could also be due to the short length of the titles as compared to the
abstracts. The topics for models with search terms including opioid are again dominated
by opioid related issues occurring in 9 out of the 12 topics.
Generalizable Findings
The observations are made with respect to the search terms used specifically for
this study. Some of the findings can be extended to work with any search term and as a
result any other sequence of events. A higher value of alpha and beta (greater than 0.5)
produce better topic models for abstracts. A high value of alpha (greater than 0.5) and a
low value of beta (lower than 0.5) for titles. A higher number of topics in the range of
6-8 is preferable for both abstract and title. In terms of human interpretability of topics by
looking at the top words for each topic, I feel the topics produced by abstracts are more
interpretable and provide strong indicators of what a document is about as compared to
titles. However, the topic models produced by titles can be used as a starting point to
understand if the documents about anything specific related to the search terms. If they
do not the topic models for abstracts produced from those documents may not provide
The search terms from a given sequence need to be converted into a
more general term as exact medical terms may produce few results in PubMed. At the
same time, the number of search terms can be kept at a minimum as adding more terms
may lead to less number of results from PubMed and can be dominated by one of the
Conclusion
In this study, I tried validating medical queries with Literature from PubMed
using Topic Modelling. The first part of the study concentrates on finding the appropriate
search terms that can be used for a given sequence and be used to pull data from PubMed.
This study concentrates on using more general search terms to find results from PubMed
as opposed to very specific medical terms. This was done to ensure that PubMed returns
at least some relevant results for the sequence. After getting the results from PubMed I
only gathered the title and abstracts of the research papers.
The second part of the study concentrates on generating topic models from the
abstracts and titles. These topic models were then evaluated based on their coherence
score and model hyperparameters to find the best topic model. The topic models were
visualized using pyLDAvis to find the most relevant words for each model and the most
prevalent topics for each model.
For abstracts, it is observed that high values of alpha and beta preferably in the
range of 0.61-0.91 number of topics to be high preferably in the range of 7-10 yields
topic models with a high coherence score.
For titles, it is observed that high values of alpha preferably in the range of
0.61-0.91 and low beta values preferably in the range of 0.01-0.31 and the number of topics in
the range of 7-10 yields topic models with a high coherence score.
For abstracts, it was easier to interpret topics as they were words for strong indications of
For titles, it was difficult to interpret topics to be about a specific thing
as compared to abstracts. A domain expert which in this case would be a person with
experience in the medical domain might be able to interpret the topics better. I only
looked at the top 5 words for each topic. It is possible to look at a greater number of
words to interpret a topic in a better way.
A wider range of sensitivity tests with a more minute step-size might indicate a
better set alpha, beta and number of topics that can be used for building the topic models.
While looking at the coherence scores and the topic models generated it seems that
abstracts are more useful in determining the relevance of a document with respect to the
medical search query. The topics in the documents also reveal that the document set can
References
1. Pubmed https://en.wikipedia.org/wiki/PubMed
VACLab - https://github.com/VACLab/CadenceEVA
2. Taine, S. I. (1959). New program for indexing at the National Library of
Medicine. Bulletin of the Medical Library Association, 47(2), 117.
3. Hare, J. (1941). The Current List of Medical Literature. Science, 94(2439),
299-300.
4. Taine, S. I. (1964). Bibliographic aspects of MEDLARS. Bulletin of the Medical
Library Association, 52(1), 152.
5. Smith, C. A. (2005). An evolution of experts: MEDLINE in the library school.
Journal of the Medical Library Association, 93(1), 53.
6. McCarn, D. B. (1980). Medline: An introduction to on‐line searching. Journal of
the American Society for Information Science, 31(3), 181-192.
7. Delwiche, F. A. (2008). Searching medline via pubmed. Clinical Laboratory
Science, 21(1), 35.
8. Steinbrook, R. (2006). Searching for the Right Search — Reaching the Medical
Literature. New England Journal of Medicine, 354(1), 4–7. doi:
10.1056/nejmp058128
9. Gore, G. (2003). Searching the medical literature. Injury Prevention, 9(2), 103–
10.Lu, Z. (2011). PubMed and beyond: a survey of web tools for searching
biomedical literature. Database, 2011(0). doi: 10.1093/database/baq036
11.Dogan, R. I., Murray, G. C., Neveol, A., & Lu, Z. (2009). Understanding
PubMed(R) user search behavior through log analysis. Database, 2009(0). doi:
10.1093/database/bap018
12.Lu, Z., Kim, W., & Wilbur, W. J. (2008). Evaluation of query expansion using
MeSH in PubMed. Information Retrieval, 12(1), 69–80. doi:
10.1007/s10791-008-9074-8
13.How Does E-utilities Work? - The Insider's Guide To Accessing Nlm Data -
National Library Of Medicine
https://dataguide.nlm.nih.gov/eutilities/how_eutilities_works.html
14.Aggarwal, C. C., & Zhai, C. (2012). An Introduction to Text Mining. Mining Text
Data, 1–10. doi: 10.1007/978-1-4614-3223-4_1
15.Jiang, J. (2012). Information Extraction from Text. Mining Text Data, 11–41. doi:
10.1007/978-1-4614-3223-4_2
16.Nenkova, A., & Mckeown, K. (2012). A Survey of Text Summarization
Techniques. Mining Text Data, 43–76. doi: 10.1007/978-1-4614-3223-4_3
17.Huh, S., & Fienberg, S. E. (2012). Discriminative topic modeling based on
manifold learning. ACM Transactions on Knowledge Discovery from Data
(TKDD), 5(4), 1-25.
18.Hofmann, T. (2001). Unsupervised learning by probabilistic latent semantic
19.Dumais, S. T., Furnas, G. W., Landauer, T. K., Deerwester, S., &
Harshman, R. (1988). Using latent semantic analysis to improve access to textual
information. Proceedings of the SIGCHI Conference on Human Factors in
Computing Systems - CHI 88. doi: 10.1145/57167.57214
20.Deerwester, S., Dumais, S. T., Furnas, G. W., Landauer, T. K., & Harshman, R.
(1990). Indexing by latent semantic analysis. Journal of the American society for
information science, 41(6), 391-407.
21.Hofmann, T. (1999, July). Probabilistic latent semantic analysis. In Proceedings
of the Fifteenth conference on Uncertainty in artificial intelligence (pp. 289-296).
Morgan Kaufmann Publishers Inc..
22.Blei, D. M., Ng, A. Y., & Jordan, M. I. (2003). Latent dirichlet allocation. Journal
of machine Learning research, 3(Jan), 993-1022.
23.Chang, J., Gerrish, S., Wang, C., Boyd-Graber, J. L., & Blei, D. M. (2009).
Reading tea leaves: How humans interpret topic models. In Advances in neural
information processing systems (pp. 288-296).
24.Lau, J. H., Grieser, K., Newman, D., & Baldwin, T. (2011, June). Automatic
labelling of topic models. In Proceedings of the 49th Annual Meeting of the
Association for Computational Linguistics: Human Language
Technologies-Volume 1 (pp. 1536-1545). Association for Computational Linguistics.
25.UMLS Technology Services. [online]. Available at: https://uts.nlm.nih.gov/.
26.Medlineplus.gov. 2020. Medlineplus: About Medlineplus. [online] Available at:
27.Biopython.org. 2020. Documentation · Biopython. [online] Available at:
https://biopython.org/wiki/Documentation.
28.Röder, M., Both, A., & Hinneburg, A. (2015, February). Exploring the space of
topic coherence measures. In Proceedings of the eighth ACM international
conference on Web search and data mining (pp. 399-408).
29.Syed, S., & Spruit, M. (2017, October). Full-text or abstract? Examining topic
coherence scores using latent dirichlet allocation. In 2017 IEEE International
conference on data science and advanced analytics (DSAA) (pp. 165-174). IEEE.
30.Sievert, C., & Shirley, K. (2014, June). LDAvis: A method for visualizing and
interpreting topics. In Proceedings of the workshop on interactive language
learning, visualization, and interfaces (pp. 63-70).
31.Sandler, T., Schein, A. I., & Ungar, L. H. (2005). Automatic term list generation
for entity tagging.
32.Dumais, S. T. (2004). Latent semantic analysis. Annual review of information
science and technology, 38(1), 188-230.
33.Lau, J. H., Newman, D., & Baldwin, T. (2014, April). Machine reading tea leaves:
Automatically evaluating topic coherence and topic model quality. In Proceedings
of the 14th Conference of the European Chapter of the Association for