Title Improving Maximum Margin Clustering Through Span of Support Vectors Minimization
Authors V. Vijaya Saradhi, Girish K. Palshikar Affiliation TRDDC, Tata Consultancy Services, Pune e-mail [email protected], [email protected] Address 54, Hadapsar Industrial Estate,
Hadapsar,
Pune - 411 013,Maharashtra India
Key Words
Brief background:
Maximum margin based clustering has shown to be a promising method. The central idea in the maximum margin clustering (MMC) method is to assign labels (belonging to the set {-1, +1}) to all the N data points such that the resulting label assignment has maximum margin. This convex integer programming problem is cast as a semi definite programming (SDP) formulation by introducing a few relaxations [1]. Experiments show the superiority of MMC over spectral kernel clustering method, and other clustering methods.
Our Contribution:
In the present work, we aim at improving further the MMC formulation. Our idea is to assign labels to all the N data points such that margin is maximized and the generalization error bound on the support vector machine (SVM) (given in terms of span of support vectors) is minimized simultaneously. Minimizing the span of support vectors is formulated as SDP formulation and is combined with the original MMC formulation which aims at maximizing the margin. The resulting formulation is shown to perform better compared to original MMC on UCI data sets.
Introduction:
Kernel based methods for clustering 1 is gaining popularity for un-supervised learning. Kernel based methods work by mapping the data points into a high dimensional feature space (much greater than the input dimension) and obtains decision boundaries in the thus mapped feature space [2]. These include spectral kernel method proposed in [3], support vector clustering introduced in[4], and maximum margin clustering [1]. Recently introduced technique based on maximum margin heuristic for clustering is empirically shown to outperform other kernel based clustering methods.
In the spectral kernel clustering [3], a kernel function is assumed to be available before hand. Using this kernel function, a kernel matrix is constructed on the input data points. A cost function, which captures correlation coefficient between the kernel matrix and the true cluster matrix, is optimized in order to obtain labels for the data points to be clustered.
1
In support vector cluster method introduced in [4], input data points are mapped into feature space implicitly using a kernel function. In this feature space, a minimum radius hyper-sphere is found such that all the mapped data points are enclosed in the sphere. The hyper-sphere enclosing all the data points is mapped back into the input data space forming contours. These contours are interpreted as clusters. A quadratic optimization problem is formulated for finding the minimum radius hyper-sphere radius.
The key to success of SVM performance in the context of classification problems is SVM obtains decision surface through maximum margin heuristic -- find the optimal separating hyper-plane such that margin2 is maximized. Given a training data set consisting of N data points {(Xi, yi)}i=1 .. N where Xi is the input data point in Rd and yi belonging to the set {-1, 1}
is the output, SVM solves the following quadratic optimization formulation for obtaining the optimal separating hyper-plane (by `optimum' we mean hyper-plane having maximum margin) [2].
0
1 min
1 2
, ,
i
i i
T i
N
i i b
w
b X w y to subject
C w
Where ξi is a slack variable, C is regularization parameter and φ is the specified mapping of
input data points into the feature space.
The maximum margin heuristic has been extended in [1] for un-supervised learning namely clustering problem. Core idea in obtaining clusters using maximum margin heuristic is to find a label assignment (from the set {-1, +1}) to all the data points such that the resulting
assignment yields maximum margin. This is achieved solving the following:
l y e l y
b X w y t
s
C w
T i
i
i i
T i
N
i i b
w y
1 , 1
0 1 .
. min min
1 2
, ,
2
The fourth constraint is introduced to avoid trivial solution to the label assignment namely, assign all the data points to one cluster. `l’ is the minimum number of points a cluster should have specified by the user. Replacing the primal form of the SVM optimization equation with it's dual in the above equation we have:
l y e l y e C y t s yy o K e T i T T T T y 1 , 1 0 0 . . 2 max min Above formulation is a convex integer programming formulation. Xu et al [1] introduced a few relaxations to formulate the above as an SDP problem given below:
le Me le M e M diag e C e e K o M ts T T
M 0 0 2 . . min , , ,
M is an N x N matrix of real numbers and µ, ν are vectors of length N belonging to real numbers, K is a kernel matrix of size N x N. The symbol “o” stands for element wise
multiplication and stands for positive semi definite matrix. Solving the above SDP formulation yields a matrix M of label assignments for each of the data points. Experiments show the superiority of MMC over spectral kernel clustering method and other clustering methods [1].
Span of Support Vectors:
The performance of SVMs is bounded by the geometric quantity 'Span' introduced in [5]. The span of support vectors is used to bound the estimated generalization error for SVMs. It gives an estimate of the leave-one-out (LOO) error and has been empirically shown to be tight.
Let
NSVi i
i y
X , 1 be the set of support vectors. Let the corresponding Lagrange multipliers for the data points be
o o
SV N
1,, . For a fixed support vector Xj define a set j as:
0 , , 1 | , 1 , 1 i o j j i o i N j i i i N j i i i ij X i j y y
Where λi belongs to real numbers set. The span of support vector Xj is denoted by Sj and is
given by: 2
2min
, X X
X d
S j
X j j j
j
. The maximal value of Sj is known as S-span
and is given by
SV
SV N
N
X d X
d X
d
Smax 1,1 , 2,2 ,, , .
Using the above definition of S-span, the following theorem has been proved [5].
Theorem 1. Suppose that an SVM separates training data of size N without error. Then the expectation of the probability of error perrorN1 for the SVM trained on the training data of size N-1 has the bound:
2 1
N SD E EperrorN
Where the values of span of support vectors S, diameter of the smallest sphere containing the training data points D, and the margin, ρ, are considered for training sets of size N.
Main Contribution:
Our idea in improving the performance of MMC is to minimize the error bound given in theorem 1. Note that the expected value of the generalization error depends on S, the S-span of set of support vectors and D, the diameter of the smallest sphere containing the data points. Hence to reduce the generalization bound, we minimize the radius of the hyper-sphere
enclosing all the data points which in turn reduces S-span. The minimum bounding hyper-sphere is formulated as a quadratic programming problem [6]. This is expressed as a SDP formulation as given below.
0 0
0 4
4 .
.
4 min
,
s
e e
K o I
e e
K o I K
t s
s
T
Where λ,ν are the Lagrange multipliers.
minimizing quantity (4s), we are minimizing the hyper-sphere radius and in turn the span; by minimizing (δ), we are maximizing the margin ρ. Hence the sum achieves our objective. The new SDP formulation is given below.
0 0 0 ) ( 0 4 4 0 2 . . 4 min 2 1 1 1 , , , 2 2 2 1 le Me le M e M diag s e e K o I e e K o I K e C e e K o M t s s T T T M Remarks:Heuristic: The objective function of the new SDP is carefully formulated as the sum of the objective functions of MMC SDP and Span SDP. This (sum) is to preserve the SDP structure of the resulting problem. Note that the objective function in an SDP should be linear and hence we are adding these two terms for obtaining optimal solution.
Formulation: Adding objective functions and constraints of MMC SDP and Span SDP to obtain the proposed formulation is equivalent to adding the dual of the SVM and minimum hyper-sphere enclosing all the training data points and then casting the resulting equation into an SDP.
The above SDP formulation is solved using Self Dual Minimizer (SeDuMi) [7] and YALMIP Yet Another Linear Matrix Inequality Problem (YALMIP) [8] packages using MATLAB.
Experimental Results:
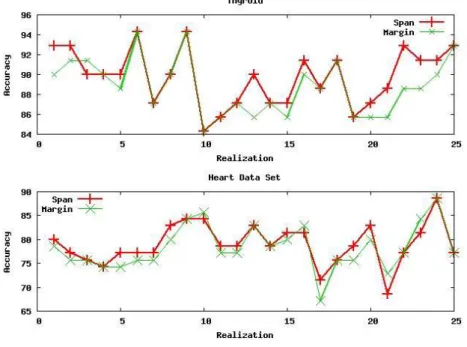
For both the data sets we use Gaussian function as kernel with spread width as 0.05 and 0.1 respectively. The user defined parameter C is chosen to be 0.01. Cluster size constraint parameter l is chosen to be 10 in both the data sets. As the class labels are known, the quality of the clusters is measured directly using the true class labels and the performance in terms of classification accuracy is reported. Results of the clustering are presented in table 1 and figure 1.
We note that the performance of span based MMC is better than that of MMC. An increase in the accuracy of 0.97% is obtained in the case of thyroid data set and in the case of heart, an improvement of 0.64% is obtained. Span of SVs in both formulations suggest that MMC has higher span compared to the proposed formulation. The improvement though is small, we consider it to be significant as MMC obtains best labeling assignment.
Data Set MMC Span-MMC Heart 78.28 78.92 Thyroid 88.80 89.77
Table 1 Performance Comparison of proposed Span based MMC
Summary:
In this work, we have proposed a kernel based clustering method that not only maximizes margin but also minimizes span bound. Maximizing the margin and minimizing the span bound simultaneously while assigning labels for data points in maximum margin clustering experimentally shown to perform better than just maximizing the margin for clustering. A thorough experimental analysis is needed for measuring the quality of clusters, evaluating the margin, span and error.
Reference:
[1] Linli Xu, James Neufeld, Bryce Larson and Dale Schuurmans, Maximum Margin Clustering, Advances in Neural Information Processing Systems 17, Editors Lawrence K. Saul and Yair Weiss and Léon Bottou, pp. 1537-1544, 2005.
[2] B. Schölkopf and A. J. Smola, Learning with Kernel, MIT Press, MA2002.
[4] Asa Ben-Hur, David Horn, Hava T. Siegelmann, Vladimir Vapnik, Support Vector Clustering, Journal of Machine Learning Research, Vol. 2, Dec, pp. 125 – 137, 2001.
[5] V. Vapnik and O. Chapelle, Bounds on error expectation for support vector machines, Neural Computation, vol. 12, pp. 2013 – 2036, 2000.
[6] V. Vapnik, Statistical Learning Theory, Wiley, 1998.
[7] J. F. Sturm, Using SeDuMi 1.02, a MATLAB toolbox for optimization over symmetric cones, Optimization Methods and Software, 11 - 12, pp. 625
– 653 1999.
[8] J. Löfberg, YALMIP : A toolbox for modeling and optimization in MATLAB, in Proceedings of the CACSD Conference, Taipei, Taiwan, 2004.
Available from http://control.ee.ethz.ch/~joloef/yalmip.php.