Journal of Computing and Security
Effect of Purposeful Feature Extraction in High-dimensional
Kinship Verification Problem
Pendar Alirezazadeh
a, Abdolhossein Fathi
a,∗
, Fardin Abdali-Mohammadi
aaDepartment of Computer Engineering and Information Technology, Razi University, Kermanshah, Iran.
A R T I C L E I N F O.
Article history:
Received:31 July 2017
Revised:20 November 2017
Accepted:07 January 2018
Published Online:10 February 2018 Keywords:
Kinship Verification, Purposeful Feature Extraction, Redundancy, Feature Selection.
A B S T R A C T
Recently, researchers have shown an increased interest in kinship verification via facial images in the field of computer vision. The matter of fact is that kinship verification is done according to similarities of parent and child faces. To this end, we need more local features extraction. All the methods reviewed so far, however, suffer the fact that they have divided images into distinct block, to extract more local features. The main problem has two aspects: aimless division and features extraction from unnecessary regions that lead to overlapping, noise and reduction of classification rate. In this paper, at first, the main parts of face such as eyes, nose and mouth are detected along with the whole face image. Then they will be used for feature extraction. In order to reduce feature vectors redundancy, new method of feature selection named as Kinship Feature Selection (KinFS), based on Random Subset Feature Selection (RSFS) algorithm is proposed. This method reduces the redundancy and improves verification rate by selecting effective features. The experiment results show that purposeful feature extraction by proposed KinFS method are efficient in improving kinship verification rate.
c
2016 JComSec. All rights reserved.
1
Introduction
Since using facial images, it is possible to obtain im-portant information such as identity, gender, expres-sion, age and ethnicity; facial image analysis is highly regarded in computer vision and machine learning in the past two decades [1, 2] . Recent advances in psychology present the ability to recognize and ver-ify kinship based on facial images by human, even if the faces in the images are unfamiliar [3, 4]. Inspired by this finding, kinship verification via facial images using computer vision’s techniques has become a
sig-∗ Corresponding author.
Email addresses:[email protected](P. Alirezazadeh),[email protected](A. Fathi),
[email protected](F. Abdali-Mohammadi) ISSN: 2322-4460 c2016 JComSec. All rights reserved.
nificant discussion and some efforts have been made in this field in recent years [5–15]. Kinship verification has many related applications in the real world, such as finding missing children and sorting family albums. Kinship verification is based on the similarity between parent and child images. These images do not belong to a single person and they have some similarities and differences. To this end, more extracted features is highly appreciated in this problem.
In the literature, various methods have been devel-oped and introduced for the given problem, and these methods can be categorized into three main groups: 1) feature-based methods, 2) learning-based methods, and 3) feature selection-based methods.
vec-184 Effect of Purposeful Feature Extraction in High-dimensional . . . — P. Alirezazadeh, A. Fathi, et al.
tors from the parent and child facial images; and then applying K-Nearest Neighbors (KNN) or Support Vec-tor Machine (SVM) classifiers [5–8] to verify them. In feature-based methods, some discriminative fea-tures have been used to represent face images in a more effective way. Features such as histogram of gra-dient [5, 7], Gabor gragra-dient orientation pyramid [6], skin color [5] and self-similarity [8] were employed.
Although good results achieved in this field, these methods suffer from two major problems:
(1) Dimension of feature vectors is high and this leads to redundancy in feature vectors and re-duces classification performance.
(2) To extract more local features, they tried to di-vide the image into smaller blocks and apply feature extraction on each block. The main prob-lem of this type of feature extraction is aimless division. Aimless division leads to feature extrac-tion from unrelated areas and leads to overlap and noise.
Learning-based methods tried to learn classifier bet-ter [9–12, 15] by employing some of the best statistical learning techniques. To solve the problem of high di-mensions feature vectors, these methods have used dimension reduction methods such as subspace learn-ing [10] , metric learnlearn-ing [9, 11] transfer learnlearn-ing [10], multiple kernel learning [6]. In some methods based on feature learning, they tried to perform kinship verifica-tion via learning the discriminative mid-level features instead of the low level features [12, 15]. Feature re-duction may eliminate some important local features. Feature-selection based methods tried to deal with high dimensional feature vectors and reduce their dundancy [13, 14]. These methods attempted to re-duce redundancy and improve the performance of the classifier by selecting effective features among ex-tracted high dimensional feature vector. The feature selection was done by different techniques such as genetic algorithm [13] and multi-perspective holistic approach [14]. Despite the success of learning and fea-ture selection based methods, both of these methods have used aimless division of facial images in feature extraction phase.
In this paper, at first the main facial regions of parent and child faces including the left and right eyes, nose and mouth are detected and different features of these areas are extracted. Then, in order to reduce redundancy, we propose a new method for feature selection named as Kinship Feature Selection (KinFS). The main idea of this method is derived from random subset feature selection (RSFS) algorithm. Using this method a proper subset that includes effective features is selected and presented to SVM for determining
kinship relations.
2
The Proposed Method
We propose an efficient feature selection method along with feature extraction for kinship verification prob-lem. To this end, we employ different feature descrip-tors in a manner that corresponding regions should be compared with each other’s (eyes compared with eyes, mouth compared with mouth and so on). In addition, we try to remove the unrelated features, which have negative effect on recognition rate, from the extracted features for each region. Since in the kinship problem we have two feature vectors (parent and child feature vectors) that they should be processed in the same manner, we need to modify and adapt the existing feature selection methods. To this end, a new wrapper-based feature selection technique named as KinFS is proposed.
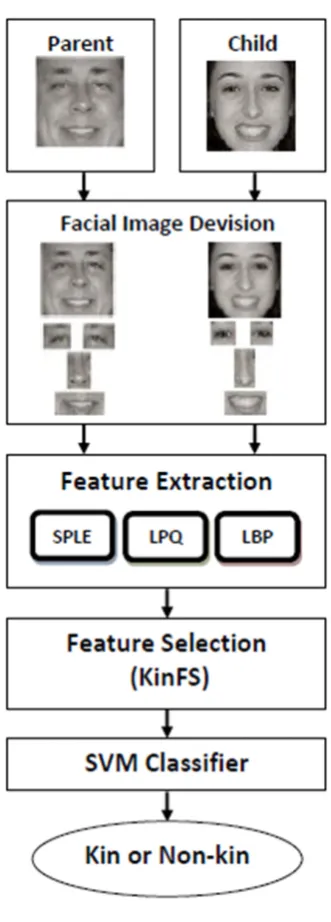
Purposeful feature extraction causes to compare similarity between the same parts of the faces of the parent and child, which means that the eyes of the parent are compared with the child’s eyes. This can reduce the number of areas and subsequently reduce the dimension of feature vector. Also purposeful fea-ture extraction prevents extraction of feafea-tures from unrelated areas and improves classification perfor-mance. Accordingly, first the main areas of the facial images of parent and child including the left eye, right eye, nose and mouth are detected by the proposed method in [16] and then feature extraction methods are applied on them and also on the whole face im-age. After feature extraction, the effective features are selected and redundancy is reduced by the proposed KinFS method. Finally, by using SVM, kinship or non-kinship relation between parent and child images is determined. The flowchart of proposed method is presented in Figure 1.
2.1 Features Extraction
To determine the kinship relation between input im-ages, three local feature descriptors named LPQ [17] , LBP [18] and SPLE [13] are applied on the extracted facial regions.
July 2016, Volume 3, Number 3 (pp. 183–191) 185
effective features are selected and redundancy is reduced by the proposed KinFS method. Finally, by using SVM,
kinship or non-kinship relation between parent and child images is determined. The flowchart of proposed method is
presented in Figure 1.
Fig.1. The Flowchart of the proposed method.
2.1.
Features Extraction
To determine the kinship relation between input images, three local feature descriptors named LPQ [17], LBP [18]
and SPLE [13] are applied on the extracted facial regions.
Local Phase Quantization (LPQ) descriptor was introduced to describe the blurred and low quality images. This
descriptor is insensitive to blurriness and stable against changes in light. LPQ method is based on quantizing the Fourier
transform phase in local neighborhoods. In LPQ feature extraction by reducing radius around each pixel, higher local
information is extracted but the blur tolerance of the descriptor is reduced at the same time [17]. To avoid this issue, the
Figure 1. The Flowchart of the Proposed Method.
describer is used as multi-scale in three scales or radii 3, 5 and 7. Therefore the feature vector with size 768 is obtained for each area.
Also for a better representation of the images, the Local Binary Patterns (LBP) [18] and Spatial Pyra-mid LEarning (SPLE) [13] descriptors are used. The reason of choosing these descriptors is the ability of them in describing local texture features and their good performance in different problems such as face recognition [19], gender detection [20] and kinship ver-ification [13].
To describe each region of the face using LBP, a histogram with 256 bins is used instead of 59 bins for
better performance [9]. Thus, by applying LBP de-scriptor and extracting features from the left and right eyes, nose, mouth and the whole face and concatenat-ing feature vectors to each other obtain a vector with dimension 1280.
For SPLE feature extraction, in each region of the facial image, low-level feature vectors are sampled and quantized to 200 bins by K-means. Therefore, each region is encoded as a 200-dimensional feature vector. By concatenating the extracted feature vectors from different regions and the whole image, the feature vec-tor with 1000 dimensions is obtained for each image. The final feature vector for each facial image is obtained by concatenating the extracted vectors from three descriptors LPQ, LBP and SPLE.
2.2 Kinship Feature Selection (KinFS)
To better description of the facial regions, always sev-eral feature extraction operators are used. Therefore, these large set of features may be redundant and dete-riorate the performance of the classifier. To solve this limitation, several feature selection (FS) algorithms were introduced [13, 21, 22]. Feature selection tries to reduce the size of feature vector without losing useful information. However, selecting an optimal feature subset from a high dimensional feature space is an NP-complete problem. Therefore, several meta-heuristic algorithms for feature selection was introduced in the literature, which can be divided into three cate-gories [21]: embedded-based, filter-based and wrapper-based methods. In embedded methods, feature selec-tion is performed during the train of classifier. The filter-based methods rank features or feature subsets independent of the classifier as a pre-processing step using different criteria such as feature correlation and information gain. While as, the wrapper-based tech-niques employed learning techtech-niques like genetic al-gorithm [13], simulated annealing [22] and neural net-works [23] to evaluate the score and importance of features or feature subsets. Some methods also try to combine these techniques and achieve better re-sults [24].
iter-186 Effect of Purposeful Feature Extraction in High-dimensional . . . — P. Alirezazadeh, A. Fathi, et al.
Algorithm 1KinFS
1: Input:F1, F2, f eatureSize, dataSize
2: fori= 1 to iterationNodo
3: permutF eature←permute(1, f eatureSize)
4: index←permutF eature(1. . . f eatureSize)
5: U ←Πindex(F1)
6: V ←Πindex(F2)
7: r1...f eatureSize←random()
8: sim=Pf eatureSize
l=1 (min(Ul, Vl))
9: permutF eature←permute(1, dataSize) 10: index1...dataSize←rand(0,1)
11: test←σindex(id)=1(sim)
12: train←σindex(id)=0(sim)
13: model←IntersectSV M classif y(train)
14: c←model(test)
15: r=r+ci−E{c}
16: end for
ation a subset of the available features is selected and the data are classified by it. Unlike the Sequential For-ward Selection [25] and Sequential Floating ForFor-ward Selection [26] algorithms in which the value of each feature is evaluated by including or excluding it in the feature set directly, in RSFS the value of each feature is evaluated by the performance of the classification of the subset in which it exists. Each KinFS feature is evaluated according to the average usefulness in a number of different feature combinations. Therefore, KinFS algorithm is not susceptible to a local optimal solution [27, 28].
In kinship verification, the input feature vector is not a single concept vector; instead there are two distinct parent and child feature vectors as the input. The column of these vectors are extracted from the peer to peer areas of the face and choosing a good subset of the features is done based on both of these vectors.
Kinship verification is a binary classification prob-lem and SVM classifier has the best performance for this work [9]. Therefore, we propose KinFS method and utilize SVM on parent and child feature vectors as shown in Algorithms 1.
In this algorithm,F1 andF2 are parents and chil-dren feature vectors respectively. featureSize is the length of feature subset anddataSizeis the number of pairs (¡parent,child¿). At each iteration i of KinFS algorithm, it randomly selects the subsets U andV
that have n features (i.e.featureSize in pseudocode and it set to 78) from the full sets F1 andF2 (line 3-6). The distribution of sampling is uniform. At first, for each pair of selected features (f1j, f2j) a relevance valuesrj ∈(−∞,+∞) is randomly assigned (line 7). Then, the similarity of the parent vectorU and the child vectorV is calculated by the intersection
ker-nel (line 8). Classification is done by aid of SVM. To this end, half of data are chosen for training set and the others are chosen for development set (line 9-12). The parameterci is the value of the obtained classifi-cation performance on development set at iteration
iandEcis the average classification performance of all previous iterations, and we update relevancerj of all used features (line 15) using them. In our experi-ments the iteration number was set to 50000 (itera-tionNo=50000) to have enough permutation for each feature. Besides the extracted feature sets, a dummy feature setZis defined as well. These dummy features play no role in classification task.
Along with updating the relevance of true features, a similar process for the subsetzjof the dummy features
Z with related relevance qj is performed based on the above-mentioned equation (line 15). The criterion function of this process is the function of criterion true features of the same iteration. The dummy features are never used in the actual classification (they do not have any value), but their relevances are updated and saved through similar process to true features. Therefore, relevanceqj of each dummy featurezj is created under a random process without any actual classification, in this case the relevance of dummy feature provide a baseline levelrrandthat is used to find a good subset of the total features.
It means that the relevancerjof a true feature must apply in the following condition:
p(rj > rrand)≥δ,∀fj ∈F1, F2 (1) Whererrandis the relevance of the dummy features andδis a probability threshold. The random baseline levelrrand is defined as the normal distribution of the dummy relevancesqj, thus the probability that a true feature is more relevant than a dummy feature is obtained based on the following cumulative normal distribution:
p(rj> rrand) = 1
σg
√
2π
Z rj
−∞
exp(−(x−µg) 2
2σg2 )dx
for classification at each iteration is square root of
F1 size (f eatureSize= √F1 = √F2 ' 78) based on [27, 28]. The proposed method is repeated 50000 times to achieve the final subset of features according to Equations (1) and 2.
3
Experimental Results
3.1 Dataset
To evaluate the proposed method, the dataset Kin-FaceW was used. This dataset was divided into two subsets: KinFaceW-I and KinFaceW-II. Both of these subsets include four relations of the kinship images: father-son (F-S), father-daughter (F-D), mother-son (M-S) and mother-daughter (M-D). For each relation there are 156, 134, 116 and 127 pairs of kinship im-ages in I, respectively. Dataset KinFaceW-II consists of 250 kinship image pairs for each rela-tion. The difference between these two datasets is that the images of KinFaceW-I were collected from differ-ent photos but the images of KinFaceW-II dataset were collected from same photos. The images of these datasets were collected in uncontrolled conditions. These images have different lightings, expressions and gestures. Some images were blurry and all images were cropped to 64×64 pixels so that only the face region was remained. These properties have made kinship verification on these datasets challenging.
We also evaluated the proposed method on UBKin-face dataset [15]. This dataset contains 600 images from children and parents, which divided in three sets: set1 is related to images of parent when they have been young, set2 is related to images of parent when they have been middle aged, and set3 is related to images of parent when they have been old aged. We evaluated the proposed method on set1 and set2.
3.2 Experiment Settings
In order to demonstrate the effect of purposeful feature extraction, descriptors LPQ, SPLE and LBP were ap-plied on the images of KinFaceW-I and KinFaceW-II datasets under two conditions. In the first condition, or normal mode (N-Mode), the descriptors were ap-plied on the same way that they were apap-plied on all blocks of facial images. The normal mode is the way that existing methods employed for feature extraction. They divided the face region into several blocks with-out overlapped and then different feature descriptors were employed for extracting their feature vectors. By concatenating the feature vectors of all blocks, the final feature vector of parent or child face image was obtained. In the second condition, or purposeful mode (P-Mode), the descriptors were only applied on the
Table 1. Verification Rate (%) of Descriptors in Normal (N– Mode) and Purposeful (P-Mode) Modes on Different Relations of the KinFaceW-I Dataset.
Descriptor/Relation F-S F-D M-S M-D
LPQ (N-Mode) 70.2 62.34 59.02 66.65
LPQ (P-Mode) 73.4 65.68 56.92 70.04
SPLE (N-Mode) [13] 65.1 59.3 67.6 78.4
SPLE (P-Mode) 65.09 61.57 68.04 78.41
LBP (N-Mode) [9] 62.7 60.2 54.4 61.4
LBP (P-Mode) 72.41 63.75 62.97 65.7
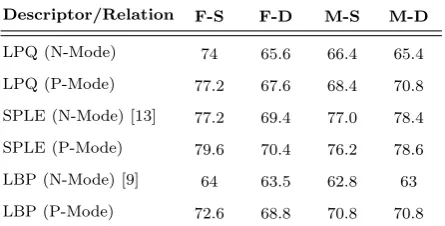
Table 2. Verification Rate (%) of Descriptors in Normal (N– Mode) and Purposeful (P-Mode) Modes on Different Relations of the KinFaceW-II Dataset.
Descriptor/Relation F-S F-D M-S M-D
LPQ (N-Mode) 74 65.6 66.4 65.4
LPQ (P-Mode) 77.2 67.6 68.4 70.8
SPLE (N-Mode) [13] 77.2 69.4 77.0 78.4
SPLE (P-Mode) 79.6 70.4 76.2 78.6
LBP (N-Mode) [9] 64 63.5 62.8 63
LBP (P-Mode) 72.6 68.8 70.8 70.8
main facial parts. In purposeful feature extraction the left eye, right eye, nose and mouth were detected and different feature descriptors were applied on these ar-eas. In this mode, we also applied all descriptors over-all face images to obtain global view of faces. There-fore, we have five regions in this mode for each image. The results of the classification of employing different descriptors in normal (N-Mode) and purposeful (P-Mode) modes using SVM on both datasets are shown in Tables 1 and 2.
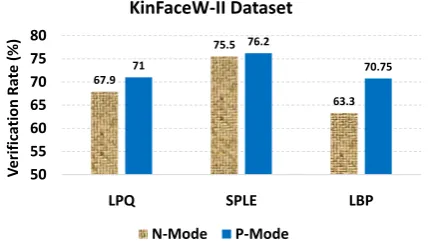
From the obtained results, it is clear that for all rela-tions on both datasets, the purposeful mode (P-Mode) shows better verification rate than normal mode (N-Mode). For more comparison, we compare the average verification rate for three descriptors (LPQ, SPLE and LBP) and the obtained results are shown in Fig-ures 2 and 3 for both KinFaceW-I and KinFaceW-II datasets.
188 Effect of Purposeful Feature Extraction in High-dimensional . . . — P. Alirezazadeh, A. Fathi, et al.
64.5
67.6
59.7
67.3 68.3 66.2
50 55 60 65 70
LPQ SPLE LBP
V erifica tio n Ra te (%) KinFaceW-I Dataset N-Mode P-Mode
Figure 2. The Comparison of Purposeful Mode (P-Mode) and Normal Mode (N-Mode) on KinFaceW-I Dataset.
67.9 75.5 63.3 71 76.2 70.75 50 55 60 65 70 75 80
LPQ SPLE LBP
V erific ation Ra te (%) KinFaceW-II Dataset N-Mode P-Mode
Figure 3. The Comparison of Purposeful Mode (P-Mode) and Normal Mode (N-Mode) on KinFaceW-II Dataset.
In the normal mode, SPLE descriptor extracts 4200 features for each image while as the descriptor was applied on the image purposefully, not only the feature dimension is reduced by 1000, but also the verification rate was improved 0.68% and 0.7% on the KinFaceW-I and KinFaceW-II datasets, respectively.
For the LBP descriptor in normal mode, the input image was divided into 16 non-overlapping blocks and LBP 256 bins descriptor was applied on each block to obtain the feature vector with 4096 dimensions. By purposeful feature extraction, LBP descriptor was applied on main areas and also on the whole facial images. The resulted feature vector with 1280 dimen-sions achieved 6.5% and 7.45% improvement on the KinFaceW-I and KinFaceW-II datasets respectively. Also to show the impact of the proposed feature selection, we evaluated the proposed method in two cases: when employing the proposed feature selection method (KinFS) and when no feature selection has been used. The results of these experiments on differ-ent relationship (F-S, F-D, M-S and M-D) for both KinFaceW-I and KinFaceW-II datasets are shown in Figure 4 and 5 respectively.
From the obtained results, the proposed feature selection technique increased the performance of kin-ship verification rate on all relation of KinFaceW-I and KinFaceW-II datasets. It increased the average
69.5 63.8 79.1 74.7 77.8 73.5 79.6 84.6 50 55 60 65 70 75 80 85 90
F-S F-D M-S M-D
V erifica tio n Ra te (%) KinFaceW-I Dataset
without KinFS with KinFS
Figure 4. The Evaluation of Effect of the Proposed Feature Selection (KinFS) on KinFaceW-I Dataset.
81.6 72.1 76.4 78.9 87.5 79.8 83.9 86.7 50 55 60 65 70 75 80 85 90
F-S F-D M-S M-D
V erifica tio n Ra te (%) KinFaceW-II Dataset
without KinFS with KinFS
Figure 5. The Evaluation of Effect of the Proposed Feature Selection (KinFS) on KinFaceW-I Dataset.
performance of kinship verification more than 7% on both datasets.
3.3 Results and Analysis
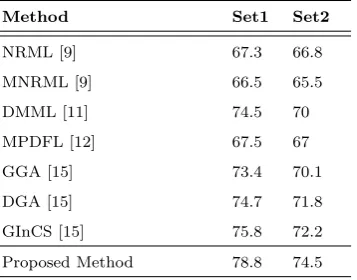
ge-Table 3. The Mean Accuracy of Different Methods on UBKin-Face Dataset (%)
Method Set1 Set2
NRML [9] 67.3 66.8
MNRML [9] 66.5 65.5
DMML [11] 74.5 70
MPDFL [12] 67.5 67
GGA [15] 73.4 70.1
DGA [15] 74.7 71.8
GInCS [15] 75.8 72.2
Proposed Method 78.8 74.5
Table 4. The Mean Accuracy of Different Methods on Kin-FaceW-I Dataset (%)
Relation F-S F-D M-S M-D Mean
NRML [9] 64.1 59.1 63.9 71.0 64.3
MNRML [9] 72.5 66.5 66.2 72.0 69.9
DMML [11] 74.5 69.5 69.5 75.5 72.3
MPDFL [12] 73.5 67.5 66.1 73.1 70.1
GGA [15] 70.5 70.0 67.2 74.3 70.5
DGA [15] 76.4 72.5 71.9 77.3 74.5
GInCS [15] 77.3 76.9 75.8 81.4 77.9
Proposed Method 77.8 73.5 79.6 84.6 78.9
Table 5. The Mean Accuracy of Different Methods on Kin-FaceW-II Dataset (%)
Relation F-S F-D M-S M-D Mean
NRML [9] 76.8 73.1 76.8 77.0 75.7
MNRML [9] 76.9 74.3 77.4 77.6 76.5
DMML [11] 78.5 76.5 78.5 79.5 78.3
MPDFL [12] 77.3 74.7 77.8 78.0 77
GGA [15] 81.8 74.3 80.5 80.8 79.4
DGA [15] 83.9 76.7 83.4 84.8 82.2
GInCS [15] 85.4 77 81.6 81.6 81.4
Proposed Method 87.5 79.8 83.9 86.7 84.5
netic algorithm for feature learning while GInCS tried to learn inheritable color space for feature extraction.
The NRML, MNRML and DMML methods are met-ric learning based methods and all of these methods have used SPLE and LBP descriptors in normal mode. The proposed method improved the verification rate at least 4.3% on UBKinface dataset compared to them. In addition, the methods GGA, DGA and GInCS employed feature selection approaches and MPDFL
method is a feature learning based method. The pro-posed method improved the verification rate at least 2.3% on UBKinface dataset compared to GGA, DGA, GInCS and MPDFL. The proposed method improved the verification rate on KinFaceW-I dataset compared to NRML, MNRML, DMML, MPDFL, GGA, DGA and GInCS by 14.6%, 9%, 6.6%, 8.8%, 8.4%, 4.4% and 1% respectively by employing purposeful feature extraction and reduction. Using a similar method, on KinFaceW-II dataset, the proposed method improved the verification rate compared to NRML, MNRML, DMML, MPDFL, GGA, DGA and GInCS by 8.8%, 8%, 6.2%, 7.5%, 5.1%, 2.3% and 3.1% respectively.
4
Conclusion
In this paper, a purposeful feature extraction and se-lection method for kinship verification were presented. Feature extraction from unnecessary regions leads to overlapping, noise and reduction of classification per-formance on kinship verification. Applying feature descriptors on main areas of facial image including eyes, nose and mouth cause reduction of features vec-tor dimension, and comparing similarity between the same areas of parent and child faces improve classifi-cation performance. Since the redundancy in features vector has an important effect on reduction of verifi-cation rate, a new feature selection method, named as KinFS, was proposed to select effective features and reduce feature redundancy. The proposed method ob-tained verification rate 78.8%, 78.9% and 84.5% on UBKinface, KinFaceW-I and KinFaceW-II datasets, respectively. Although selection of effective features in high dimensional problem is very important but its combination with methods such as learning-based methods can improve performance of the proposed method. This issue can be considered for future work.
References
[1] Young-Suk Shin. Facial Expression Recognition of Various Internal States via Manifold Learn-ing. Journal of Computer Science and Technol-ogy, 24(4):745–752, Jul 2009. ISSN 1860-4749. doi:10.1007/s11390-009-9257-9.
[2] Pin Liao, Li Shen, Yi-Qiang Chen, and Shu-Chang Liu. Unified model in identity subspace for face recognition.Journal of Computer Science and Technology, 19(5):684–690, Sep 2004. ISSN 1860-4749. doi:10.1007/BF02945595.
[3] Dal Martello, Maria F., Maloney, and Laurence T. Lateralization of kin recognition signals in the human face.Journal of vision, 10(8), 2010. ISSN 1534-7362. doi:10.1167/10.8.9.
Bene-190 Effect of Purposeful Feature Extraction in High-dimensional . . . — P. Alirezazadeh, A. Fathi, et al.
dict C. Jones, S. Craig Roberts, Marion Petrie, and Tim D. Spector. Kin recog-nition signals in adult faces. Vision Re-search, 49(1):38–43, 2009. ISSN 0042-6989. doi:https://doi.org/10.1016/j.visres.2008.09.025. [5] Xiuzhuang Zhou, Junlin Hu, Jiwen Lu, Yuanyuan
Shang, and Yong Guan. Kinship Verification from Facial Images Under Uncontrolled Condi-tions. InProceedings of the 19th ACM Interna-tional Conference on Multimedia, MM ’11, pages 953–956. ACM, 2011. ISBN 978-1-4503-0616-4. doi:10.1145/2072298.2071911.
[6] Xiuzhuang Zhou, Jiwen Lu, Junlin Hu, and Yuanyuan Shang. Gabor-based Gradient Ori-entation Pyramid for Kinship Verification Un-der Uncontrolled Environments. In Proceed-ings of the 20th ACM International Con-ference on Multimedia, MM ’12, pages 725– 728. ACM, 2012. ISBN 978-1-4503-1089-5. doi:10.1145/2393347.2396297.
[7] R. Fang, K. D. Tang, N. Snavely, and T. Chen. Towards computational models of kinship verifi-cation. In2010 IEEE International Conference on Image Processing, pages 1577–1580, Sept 2010. doi:10.1109/ICIP.2010.5652590.
[8] N. Kohli, R. Singh, and M. Vatsa. Self-similarity representation of Weber faces for kinship clas-sification. In 2012 IEEE Fifth International Conference on Biometrics: Theory, Applications and Systems (BTAS), pages 245–250, Sept 2012. doi:10.1109/BTAS.2012.6374584.
[9] J. Lu, X. Zhou, Y. P. Tan, Y. Shang, and J. Zhou. Neighborhood Repulsed Metric Learn-ing for Kinship Verification. IEEE Transac-tions on Pattern Analysis and Machine Intelli-gence, 36(2):331–345, Feb 2014. ISSN 0162-8828. doi:10.1109/TPAMI.2013.134.
[10] S. Xia, M. Shao, J. Luo, and Y. Fu. Un-derstanding Kin Relationships in a Photo.
IEEE Transactions on Multimedia, 14(4): 1046–1056, Aug 2012. ISSN 1520-9210. doi:10.1109/TMM.2012.2187436.
[11] H. Yan, J. Lu, W. Deng, and X. Zhou. Discriminative Multimetric Learning for Kin-ship Verification. IEEE Transactions on Information Forensics and Security, 9(7): 1169–1178, July 2014. ISSN 1556-6013. doi:10.1109/TIFS.2014.2327757.
[12] H. Yan, J. Lu, and X. Zhou. Prototype-Based Discriminative Feature Learning for Kinship Ver-ification. IEEE Transactions on Cybernetics, 45(11):2535–2545, Nov 2015. ISSN 2168-2267. doi:10.1109/TCYB.2014.2376934.
[13] P. Alirezazadeh, A. Fathi, and F. Abdali-Mohammadi. A Genetic Algorithm-Based Feature Selection for Kinship Verification.
IEEE Signal Processing Letters, 22(12): 2459–2463, Dec 2015. ISSN 1070-9908. doi:10.1109/LSP.2015.2490805.
[14] A. Bottinok, I. U. Islam, and T. F. Vieira. A multi-perspective holistic approach to Kinship Verifica-tion in the Wild. In2015 11th IEEE International Conference and Workshops on Automatic Face and Gesture Recognition (FG), volume 02, pages 1–6, May 2015. doi:10.1109/FG.2015.7284834. [15] Q. Liu, A. Puthenputhussery, and C. Liu.
A novel inheritable color space with applica-tion to kinship verificaapplica-tion. In 2016 IEEE Winter Conference on Applications of Com-puter Vision (WACV), pages 1–9, March 2016. doi:10.1109/WACV.2016.7477667.
[16] M. Castrilln, O. Dniz, C. Guerra, and M. Hernndez. ENCARA2: Real-time de-tection of multiple faces at different reso-lutions in video streams. Journal of Vi-sual Communication and Image Representa-tion, 18(2):130 – 140, 2007. ISSN 1047-3203. doi:https://doi.org/10.1016/j.jvcir.2006.11.004. [17] C. H. Chan, M. A. Tahir, J. Kittler, and
M. Pietikinen. Multiscale Local Phase Quantiza-tion for Robust Component-Based Face Recogni-tion Using Kernel Fusion of Multiple Descriptors.
IEEE Transactions on Pattern Analysis and Ma-chine Intelligence, 35(5):1164–1177, May 2013. ISSN 0162-8828. doi:10.1109/TPAMI.2012.199. [18] T. Ojala, M. Pietikainen, and T. Maenpaa.
Mul-tiresolution gray-scale and rotation invariant tex-ture classification with local binary patterns.
IEEE Transactions on Pattern Analysis and Ma-chine Intelligence, 24(7):971–987, Jul 2002. ISSN 0162-8828. doi:10.1109/TPAMI.2002.1017623. [19] Abdolhossein Fathi and Fardin
Abdali-Mohammadi. Improving Face Recognition Systems Security Using Local Binary Patterns.
Journal of Computing and Security, 2(1):55–62, 2016. ISSN 2383-0417. URLhttp://jcomsec. org/index.php/JCS/article/view/195. [20] Abdenour Hadid, Juha Ylioinas, Messaoud
Bengherabi, Mohammad Ghahramani, and Abdelmalik Taleb-Ahmed. Gender and texture classification: A comparative analysis using 13 variants of local binary patterns.Pattern Recogni-tion Letters, 68:231 – 238, 2015. ISSN 0167-8655. doi:https://doi.org/10.1016/j.patrec.2015.04.017. Special Issue on Soft Biometrics.
[22] Ayoub Bagheri, Mohamad Saraee, and Shiva Nadi. PSA: A Hybrid Feature Selection Approach for Persian Text Classification. Journal of Com-puting and Security, 1(4):261–272, 2015. ISSN 2383-0417. URL http://jcomsec.org/index. php/JCS/article/view/136.
[23] Rahul Karthik Sivagaminathan and Sreeram Ra-makrishnan. A hybrid approach for feature subset selection using neural networks and ant colony optimization. Expert Systems with Ap-plications, 33(1):49 – 60, 2007. ISSN 0957-4174. doi:https://doi.org/10.1016/j.eswa.2006.04.010. [24] Mehdi Hosseinzadeh Aghdam, Jafar Tanha,
Ah-mad Reza Naghsh-nilchi, and MohamAh-mad Ehsan Basiri. Combination of Ant Colony Optimization and Bayesian Classification for Feature Selection in a Bioinformatics Dataset.Journal of Computer Science & Systems Biology, 2(3):186–199, 2009. [25] Jouni Pohjalainen, Okko Rsnen, and Serdar
Kadioglu. Feature selection methods and their combinations in high-dimensional classi-fication of speaker likability, intelligibility and personality traits. Computer Speech & Lan-guage, 29(1):145 – 171, 2015. ISSN 0885-2308. doi:https://doi.org/10.1016/j.csl.2013.11.004. [26] A. W. Whitney. A Direct Method of
Nonparamet-ric Measurement Selection. IEEE Transactions on Computers, C-20(9):1100–1103, Sept 1971. ISSN 0018-9340. doi:10.1109/T-C.1971.223410. [27] P. Somol, P. Pudil, J. Novoviov, and P.
Pa-clk. Adaptive floating search methods in feature selection. Pattern Recognition Let-ters, 20(11):1157 – 1163, 1999. ISSN 0167-8655. doi:https://doi.org/10.1016/S0167-8655(99)00083-5.
[28] Okko R¨as¨anen and Jouni Pohjalainen. Random subset feature selection in automatic recognition of developmental disorders, affective states, and level of conflict from speech. InINTERSPEECH, pages 210–214. ISCA, 2013.
Pendar Alirezazadehwas born in Kerman-shah, Iran. He received his B.Sc. in Com-puter Engineering from Razi University in 2009 and his M.Sc. in Information Technology-Multimedia Systems from Razi University in 2015.. His research interests include Medical Image Processing, Biometric, Computer Vi-sion and Pattern Recognition.
Abdolhossein Fathi was born in Delfan, Iran, in 1978. He received his B.Sc. in Com-puter Engineering from Iran university of Sci-ence and Technology in 2001 and his M.Sc. in Computer Architecture from Sharif Univer-sity of Technology in 2003. He also received his Ph.D. Degree from the University of Is-fahan in 2012. He is an assistant professor at Razi University, Kermanshah, Iran. His re-search interests include Signal and Image Processing, Biomet-ric, Data Compression, Computer Vision, Pattern Recognition and Medical Image Analysis.