Abstract: Within the first stage, Smart Crawler performs site based sorting out center pages with the automated of search engines, avoiding visiting an oversized variety of pages. To realize additional correct results for a targeted crawl, Smart Crawler ranks websites to order extremely relevant ones for a given topic. Within the second stage, Smart Crawler achieves quick in site looking by excavating most relevant links with associate degree of reconciling link ranking. In the second stage, Smart Crawler achieves fast in-site searching by excavating most relevant links with an accommodative link ranking. Deep web is a vast repository in a web that are not always listed by automated search engines. Proposed system is contributing new module based on user login for selected registered users who can browse the specific domain according to given input by the user. This is module is also used for filtering the results.
KeyWords: Adaptive learning, deep web, feature selection, ranking, two-stage crawler.
I. INTRODUCTION
A web crawler is methods that go round over internet web storing and accumulating data in to database for further arrangement and analysis. The procedure of internet crawling entails gathering pages from the online. After that they arranging manner the search engine can retrieve it effectually and with ease. The imperative function can accomplish that quickly. Also it works effectually and conveniently without much interference with the functioning of the remote server. A web crawler begins with a URL or a list of URLs, known as seeds. It might visited the URL on the highest of the record other hand the web page it looks for hyperlinks to different web sites that means it provides them to the present list of URLs in the web pages record. Internet crawlers aren't a centrally managed repository of data. The web can held together with the aid of a suite of agreed
protocols and data formats, just like the Transmission control Protocol (TCP), Domain name service (DNS), Hypertext text transfer
(HTTP), Hypertext Markup Language
(HTML).Additionally the robots exclusion protocol participate in position in web. The huge volume data which implies can only down load a confined number of the web sites inside a given time, so it desires to prioritize its downloads. High rate of exchange can indicate pages would have already been update. Crawling scheme is large search engines like google cover most effective a component to the publicly on hand part. Everyday, most internet users limit their searches to the web, as a result the specialization in the contents of web pages we can limit this circular to appear engines. A seem engine employs specified code robots, often called spiders, to make lists of the words observed on web sites to search out data on the numerous ample websites that exist. Once a spider is constructing its lists, the applying is termed web crawling. (There are unit some negative aspects to line a part of the online the globe wide internet -- an oversized set of arachnid - centric names for tools is one amongst them.) to be able to make and hold a valuable record of words, a look engine's spiders ought to pass - determine a lot of pages. We have developed an instance system that's designed specially crawl entity content consultant. The crawl approach is optimized through exploiting options amazing to entity -oriented websites. In this paper, we are going to be aware of describing crucial factors of our approach, in conjunction with query new release, empty web page filtering and URL deduplication.
II. RELATED WORKS
Authors : Luciano Barbosa and Juliana Freire.
Smart Crawler for efficient web interfaces
G.Sravanthi
M.Tech, Computer Science &Engineering
Sri Indu Institute of Engg. & Tech,Sheriguda(Vi),IBP(M),RR Dist.
Vasavi Chithanuru
Associate
Professor
, Department of CSE
Sri Indu Institute of Engg. & Tech,Sheriguda(Vi),IBP(M),RR Dist.
Dr. I.Satyanarayana
PRINCIPAL
Abstract: In this paper we describe new adaptive crawling systems to efficiently find the entry aspects to hidden-net sources. The truth that hidden-web sources are very sparsely disbursed makes the challenge of finding them principally difficult. We care for this hindrance via making use of the contents of pages to focal point the crawl on an issue; via prioritizing promising hyperlinks inside the subject; and via additionally following hyperlinks that would possibly not lead to on the promotion benefit. We suggest a brand new framework whereby crawlers routinely be trained patterns of promising links and adapt their focus as
the crawl progresses, therefore extensively
lowering the quantity of required guide setup and tuning. Our experiments over actual web sites in a representative set of domains indicate that on-line learning results in enormous gains in harvest premiums—the adaptive crawlers retrieve up to thrice as many varieties as crawlers that use a fixed center of attention strategy.
Conclusion: We've got offered a brand new
adaptive targeted crawling procedure for
efficaciously locating hidden-web access aspects. This process simply balances the exploitation of received skills with the exploration of hyperlinks with previously unknown patterns, making it mighty and equipped to correct biases offered within the studying process. We've got shown, by means of a detailed experimental analysis, that vast increases in harvest rates are received as crawlers be trained from new experiences. Considering the fact that crawlers that study from scratch are in a position to obtain harvest premiums which can be similar to, and mostly larger than manually configured crawlers, this framework can commonly cut down the effort to configure a crawler. Furthermore, by way of making use of the form classifier, distress produces high quality results which can be imperative for a number information integration tasks.
Authors : Dr. Jill Ellsworth.
Abstract: Probably the most favorite exchange items the knowledge age is so data. Expertise has become a normal need as soon as meals, shelter, and wear. Because of technological developments, an outsized quantity of data is out there on the web, that has end up a flowery entity containing data from a range of sources. Data is located mistreatment search engines like google and yahoo. A searcher has access to an oversized variety of
data, however it nonetheless some distance far from the gigantic treasury of data untruthfulness to a cut back situation the online, a massive store of data on the a long way aspect the reach of standard search engines like google: the ―Deep web‖ or ―Invisible web‖. The contents of the Deep web don't seem to be enclosed up within the search outcome of normal search engines like google. The crawlers of average search engines set up solely static pages and are not able to access the dynamic net content material of Deep internet databases. Thus, the Deep internet is as an alternative termed the ―Hidden‖ or ―Invisible internet‖. The time period Invisible internet used to be coined via Dr.
Jill Ellsworth to assess with information
inaccessible to commonplace engines like google. Nonetheless mistreatment the term Invisible web to give an explanation for recorded info that is offered nevertheless not quite simply available, is not correct.
Conclusion: The advent of web and access to world data was an pleasant revenue, even though data managers had the hard task of organizing, retrieving, and delivering access to certain data. Clients rely on the popular search engines like google and portals, that are not able to give access to the hidden store of priceless data provided within the Deep internet. To entry the data provided on these databases, clients can need to be compelled to end up acquainted with the structure of the Deep internet. Any information created must be shared and used, seeing that that by myself outcome within the creation of plenty of information. As soon as a selected data is made, data when it comes to its existence need to published in order that clients are mindful and create most use of available data.
Authors : Raju Balakrishnan and Subbbarao Kambhampati.
Abstract: One on the spot assignment in looking out the deep web databases is supply resolution— i.e. Picking the essential valuable web databases for
responsive a given query. The prevailing
information option methods (each textual content and relational) determine the provide nice
supported the query-similarity-established
the value of the results. These 2 issues are primary for the open collections similar to the deep web. Due to the fact that variety of sources present solutions to any question, we have a tendency to get together that the agreements between these solutions are no doubt to be priceless in assessing the importance and also the trustiness of the sources. We have a tendency to reckon the agreement between the sources seeing that the contract of the solutions derived again. Whereas computing the contract, we have a tendency to additionally live and atone for doable collusion between the sources. This adjusted agreement is sculptural as a graph with sources on the vertices.
Conclusion: A compelling goblet for the talents retrieval evaluation is to integrate and search the structured deep internet sources. A correct away crisis showcase by using this quest is supply option, i.e. Identifying crucial and nontoxic sources to reply a question. Prior methods to the current hindrance relied on strictly question notably based measures to check the relevancy of a provide. The relevancy comparison exceptionally based best on question similarity is good tampered by means of the content owner, considering that the are living is insensitive to the awareness and trustiness of the results. The absolute range and uncontrolled nature of the sources inside the deep web outcome in central variability among the sources, and necessitates a quite a few sturdy live of relevancy sensitive to deliver quality and trustiness. To the current finish, we have a tendency to planned SourceRank, an international are living derived handiest from the degree of contract between the results came back by way of character sources. SourceRank performs a project admire PageRank besides for talents sources. Now not like PageRank but, it can be derived from implicit endorsement (measured in terms of agreement) as a substitute of from designated hyperlinks.
III. SYSTEM ARCHITECTURE
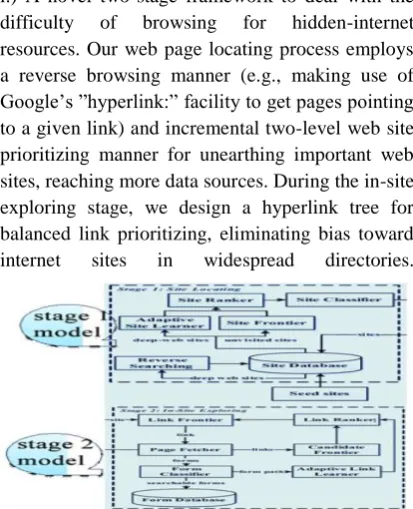
The web site frontier will fetch web-page URLs from the website online database. The un-visited sites are given to web page frontier and are prioritized by using website ranker, whereas the visited sites are brought to fetched web page list. Web page Ranker assigns a rating for each unvisited site that corresponds to its relevance to the already discovered deep web interfaces. The
website online Ranker is accelerated throughout crawling through an Adaptive website online Learner. It is going to adaptively learns from features of deep-internet sites (web pages containing one or more searchable forms) found. To obtain more accurate results for a targeted crawl, web page Classifier categorizes URLs into significant or irrelevant for a given matter in keeping with the homepage content material.
After probably the most critical site is located within the first stage, the second stage performs
effective in-website online exploration for
excavating searchable types. Hyperlinks of a website are saved in hyperlink Frontier and corresponding pages are fetched. Then embedded varieties are classified by form Classifier to seek out searchable forms. To enhance accuracy of kind classifier, prequery and submit-question strategies for classifying deep-web features are mixed. Moreover, the links in these pages are extracted into Candidate Frontier. To prioritize links in Candidate Frontier, sensible Crawler ranks them with hyperlink Ranker. When the crawler discovers a brand new web page, the website’s URL is inserted into the website Database. The link Ranker is adaptively increased with the aid of an Adaptive hyperlink Learner, which learns from the URL route leading to imperative varieties.
Fig. 2. Adaptive learning process in smart crawler
Adaptive learning: Smart crawler uses an adaptive studying method that enhances the educational capability for the duration of crawling. As proven in fig.1 website online ranker and link ranker are given by means of adaptive studying. Given Fig.2. shows the method for adaptive finding out which is invoked periodically. Our experimental results on a suite of consultant domains show the agility and accuracy of our proposed crawler framework, which efficiently retrieves deep-web interfaces from huge-scale web sites and achieves better harvest premiums than other crawlers. With the aid of advise an powerful harvesting framework for deep-net interfaces, specifically shrewd-Crawler we've shown that our technique achieves both huge insurance plan for deep internet interfaces and maintains incredibly efficient crawling. Smart Crawler is a centered crawler including two stages: effective website online locating and balanced in-web site exploring. Clever Crawler performs site- established locating by means of reversely browsing the recognized deep websites for middle pages, which can quite simply to find many data sources for sparse domains. Through ranking accrued web sites and by way of focusing the crawling on a subject matter, smart Crawler achieves extra accurate outcome. Major advantages of proposed method are:
i.) A novel two-stage framework to deal with the
difficulty of browsing for hidden-internet
resources. Our web page locating process employs a reverse browsing manner (e.g., making use of Google’s ‖hyperlink:‖ facility to get pages pointing to a given link) and incremental two-level web site prioritizing manner for unearthing important web sites, reaching more data sources. During the in-site exploring stage, we design a hyperlink tree for balanced link prioritizing, eliminating bias toward
internet sites in widespread directories.
Fig -3: Showing System Architecture
ii.) An adaptive learning algorithm that performs online feature selection and uses these features to automatically construct link rankers. In the site locating stage, high relevant sites are prioritized and the crawling is focused on a topic using the contents of the root page of sites, achieving more accurate results. During the insight exploring stage, relevant links are prioritized for fast in-site searching.
Merits
-query and Post-query approaches for classifying deep-web forms are included.
IV. CONCLUSION
An strong harvesting framework for deep-web interfaces, specifically smart-Crawler is proposed. It has been shown that above method achieves each large scope for deep web interfaces and continues highly efficient crawling. Smart Crawler is a targeted crawler includes two levels: website online finding and balanced in-web page exploring. Smart Crawler performs website online-based finding by using reversely searching the identified deep web pages for center pages, which is able to efficaciously to find many data sources for sparse domains. Smart Crawler achieves more accurate outcome by ranking accumulated sites and focusing the crawling on a given subject. The in-website exploring stage makes use of adaptive link-rating to search inside a website online and design a hyperlink tree for disposing of bias toward particular directories of a website for wider insurance policy of web directories.
REFERENCES
[1] Kevin Chen-Chuan Chang, Bin He, and Zhen Zhang. Toward large scale integration: Building ametaquerier over databases on the web. In CIDR, pages 44–55, 2005.
[2] Roger E. Bohn and James E. Short. How much information? 2009 report on American consumers. Technical report, University of California, San Diego, 2009.
[3] Denis Shestakov and Tapio Salakoski. On estimating the scale of national deep web. In Database and Expert Systems Applications, pages 780–789. Springer, 2007.
[5]. Michael K. Bergman. White paper: The deep web: Surfacing hidden value. Journal of electronic publishing, 7(1), 2001.
[6]. Yeye He, Dong Xin, Venkatesh Ganti, Sriram Rajaraman, and Nirav Shah. Crawling deep web entity pages. In Proceedingsof the sixth ACM international conference on Web search and data mining, pages 355– 364. ACM, 2013.
[7]. Infomine. UC Riverside library. http://lib-www.ucr.edu/, 2014.
[8]. Clusty’s searchable database dirctory. http://www.clusty. com/, 2009
Author’s Profile
G.Sravanthi
pursing M.Tech in ComputerScience Engineering from Sri Indu Institute of Engg. & Tech,Sheriguda(Vi),IBP(M),RR Dist.
Vasavi Chithanuru
working as Associateprofessor, Department of CSE in Sri Indu
Institute of Engg. & Tech,
Sheriguda(Vi),IBP(M),RR Dist.
Dr. I.Satyanarayana Completed B.E-Mechanical Engg. from Andhra University, M.Tech Cryogenic
Engg. Specilization-IIT Kharagpur,