Exploring Dynamic Compilation and Cross-Layer Object
Management Policies for Managed Language Applications
By
Michael Jantz
Submitted to the Department of Electrical Engineering and Computer Science and the Graduate Faculty of the University of Kansas
in partial fulfillment of the requirements for the degree of Doctor of Philosophy
Committee members
Prasad A. Kulkarni, Chairperson
Bo Luo
Andrew Gill
Xin Fu
Karen Nordheden
The Dissertation Committee for Michael Jantz certifies that this is the approved version of the following dissertation :
Exploring Dynamic Compilation and Cross-Layer Object Management Policies for Managed Language Applications
Prasad A. Kulkarni, Chairperson
Abstract
Recent years have witnessed the widespread adoption of managed programming lan-guages that are designed to execute on virtual machines. Virtual machine architectures provide several powerful software engineering advantages over statically compiled bi-naries, such as portable program representations, additional safety guarantees, auto-matic memory and thread management, and dynamic program composition, which have largely driven their success. To support and facilitate the use of these features, virtual machines implement a number of services that adaptively manage and optimize application behavior during execution. Such runtime services often require tradeoffs between efficiency and effectiveness, and different policies can have major implica-tions on the system’s performance and energy requirements.
In this work, we extensively explore policies for the two runtime services that are most important for achieving performance and energy efficiency: dynamic (or Just-In-Time (JIT)) compilation and memory management. First, we examine the properties of single-tier and multi-tier JIT compilation policies in order to find strategies that realize the best program performance for existing and future machines. Our analysis performs hundreds of experiments with different compiler aggressiveness and opti-mization levels to evaluate the performance impact of varyingif and whenmethods are compiled. We later investigate the issue of how to optimize program regions to maximize performance in JIT compilation environments. For this study, we conduct a thorough analysis of the behavior of optimization phases in our dynamic compiler, and construct a custom experimental framework to determine the performance limits of phase selection during dynamic compilation. Next, we explore innovative memory
management strategies to improve energy efficiency in the memory subsystem. We propose and develop a novelcross-layerapproach to memory management that inte-grates information and analysis in the VM with fine-grained management of memory resources in the operating system. Using custom as well as standard benchmark work-loads, we perform detailed evaluation that demonstrates the energy-saving potential of our approach. We implement and evaluate all of our studies using the industry-standard Oracle HotSpot Java Virtual Machine to ensure that our conclusions are sup-ported by widely-used, state-of-the-art runtime technology.
Acknowledgements
I would like to thank my advisor, Prasad Kulkarni, whose guidance and mentorship has been the most significant force in growing my skills and shaping my attitudes towards scientific research. Without his patience and support, this work would not have been possible. I must also thank my family: my parents, whose love and encouragement helped me get through the hardest and most stressful times of my Ph.D., and my sisters, particularly, Marianne, who served as a sounding board for many of the ideas presented in this dissertation. Finally, I thank my wife, Leslie, whose love, advice, and cooking kept me fueled and motivated to finish this work.
Contents
1 Introduction 1
2 Exploring Single and Multi-Level JIT Compilation Policy for Modern Machines 6
2.1 Introduction . . . 7
2.2 Background and Related Work . . . 10
2.3 Experimental Framework . . . 13
2.4 JIT Compilation on Single-Core Machines . . . 19
2.4.1 Compilation Threshold with Single Compiler Thread . . . 19
2.4.2 Effect of Multiple Compiler Threads on Single-Core Machines . . . 22
2.4.2.1 Single-Core Compilation Policy with the HotSpot Server Compiler 22 2.4.2.2 Single-Core Compilation Policy with the HotSpot Tiered Compiler 25 2.5 JIT Compilation on Multi-Core Machines . . . 27
2.5.1 Multi-Core Compilation Policy with the HotSpot Server Compiler . . . 28
2.5.2 Multi-Core Compilation Policy with the HotSpot Tiered Compiler . . . 30
2.6 JIT Compilation on Many-Core Machines . . . 34
2.6.1 Many-Core Compilation Policy with the HotSpot Server Compiler . . . 36
2.6.2 Many-Core Compilation Policy with the HotSpot Tiered Compiler . . . 38
2.7 Effect of Priority-Based Compiler Queues . . . 39
2.7.1 Priority-Based Compiler Queues in the HotSpot Server Compiler . . . 41
2.7.1.2 Many-Core Machine Configuration . . . 42
2.7.2 Priority-Based Compiler Queues in the HotSpot Tiered Compiler . . . 43
2.8 Effect of Multiple Application Threads . . . 44
2.9 Conclusions . . . 46
2.10 Future Work . . . 48
3 Performance Potential of Optimization Phase Selection During Dynamic JIT Compi-lation 50 3.1 Introduction . . . 51
3.2 Background and Related Work . . . 53
3.3 Experimental Framework . . . 56
3.3.1 Compiler and Benchmarks . . . 57
3.3.2 Performance Measurement . . . 58
3.4 Analyzing Behavior of Compiler Optimizations for Phase Selection . . . 59
3.4.1 Experimental Setup . . . 60
3.4.2 Results and Observations . . . 60
3.5 Limits of Optimization Selection . . . 63
3.5.1 Genetic Algorithm Description . . . 64
3.5.2 Program-Wide GA Results . . . 65
3.5.3 Method-Specific Genetic Algorithm . . . 66
3.5.3.1 Experimental Setup . . . 67
3.5.3.2 Method-Specific GA Results . . . 69
3.6 Effectiveness of Feature Vector Based Heuristic Techniques . . . 70
3.6.1 Overview of Approach . . . 71
3.6.2 Our Experimental Configuration . . . 72
3.6.3 Feature-Vector Based Heuristic Algorithm Results . . . 73
3.6.4 Discussion . . . 75
3.8 Conclusions . . . 77
4 A Framework for Application Guidance in Virtual Memory Systems 79 4.1 Introduction . . . 80
4.2 Related Work . . . 83
4.3 Background . . . 86
4.4 Application-Guided Memory Management . . . 87
4.4.1 Expressing Application Intent through Colors . . . 88
4.4.2 Memory Containerization with Trays . . . 91
4.5 Experimental Setup . . . 93
4.5.1 Platform . . . 93
4.5.2 The HotSpot Java Virtual Machine . . . 93
4.5.3 Application Tools for Monitoring Resources . . . 94
4.5.4 DRAM Power Measurement . . . 95
4.6 Emulating the NUMA API . . . 95
4.6.1 Exploiting HotSpot’s Memory Manager to improve NUMA Locality . . . . 95
4.6.2 Experimental Results . . . 96
4.7 Memory Priority for Applications . . . 98
4.7.1 memnice . . . 98
4.7.2 Usingmemnicewith Kernel Compilation . . . 100
4.8 Reducing DRAM Power Consumption . . . 100
4.8.1 Potential of Containerized Memory Management to Reduce DRAM Power Consumption . . . 101
4.8.2 Localized Allocation and Recycling to Reduce DRAM Power Consumption 103 4.8.3 Exploiting Generational Garbage Collection . . . 105
4.9 Future Work . . . 107
5 Automatic Cross-Layer Memory Management to Reduce DRAM Power
Consump-tion 109
5.1 Introduction . . . 110
5.2 Related Work . . . 112
5.3 Background . . . 113
5.3.1 Overview of DRAM Structure . . . 113
5.3.2 DRAM Power Consumption . . . 114
5.3.3 Operating System View of Physical Memory . . . 114
5.3.4 Automatic Heap Management in Managed Language Runtimes . . . 115
5.4 Cross-Layer Memory Management . . . 116
5.5 Potential of Cross-Layer Framework to Reduce DRAM Energy Consumption . . . 118
5.5.1 The MemBench Benchmark . . . 119
5.5.2 Experimental Evaluation . . . 120
5.6 Experimental Framework . . . 123
5.6.1 Platform . . . 123
5.6.2 Memory Power and Bandwidth Measurement . . . 123
5.6.3 HotSpot Java Virtual Machine . . . 124
5.6.4 Benchmarks . . . 125
5.6.5 Baseline Configuration Performance . . . 126
5.7 Automatic Cross-Layer Memory Management . . . 127
5.7.1 Profiling for Hot and Cold Allocation Points . . . 127
5.7.2 Experimental Evaluation . . . 129
5.7.2.1 Memory Profile Analysis . . . 129
5.7.3 Controlling the Power State of DRAM Ranks . . . 130
5.7.4 Performance and Energy Evaluation . . . 133
5.8 Future Work . . . 134
List of Figures
2.1 Ratio of client and sever compile times when compiling the same number of pro-gram methods . . . 17 2.2 Steady-state program execution times using the server and client compilers as a
ratio of the interpreted program run-time . . . 17 2.3 Ratio of multi-core performance to single-core performance for each compiler
con-figuration. . . 18 2.4 Effect of different compilation thresholds on average benchmark performance on
single-core processors. . . 20 2.5 Effect of multiple compiler threads on single-core program performance in the
HotSpot VM with server compiler. The discrete measured thread points are plotted equi-distantly on the x-axis. . . 23 2.6 Effect of multiple compiler threads on single-core program performance in the
HotSpot VM with tiered compiler. The discrete measured thread points are plotted equi-distantly on the x-axis. . . 25 2.7 Effect of multiple compiler threads on multi-core application performance with the
HotSpot Server VM . . . 28 2.8 Effect of multiple compiler threads on multi-core application performance with the
HotSpot Tiered VM . . . 31 2.9 Effect of multiple compiler threads on multi-core compilation activity with the
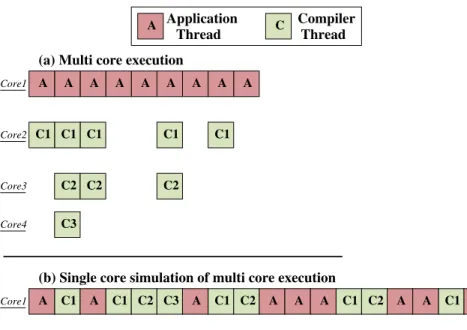
2.10 Simulation of multi-core VM execution on single-core processor . . . 35 2.11 Effect of multiple compiler threads on many-core application performance with
the HotSpot Server VM . . . 36 2.12 Comparison of multi- and many-core performance results for the server and tiered
VM. . . 37 2.13 Effect of multiple compiler threads on many-core application performance with
the HotSpot Tiered VM . . . 39 2.14 Performance of the tiered and ideal compiler priority algorithms over FIFO for
HotSpot server compiler on single-core machines . . . 41 2.15 Performance of the tiered and ideal compiler priority algorithms over FIFO for
HotSpot server compiler on many-core machines . . . 42 2.16 Effect of different numbers of application threads on single-core performance with
the HotSpot Tiered VM . . . 44 2.17 Effect of different numbers of application threads on multi-core performance with
the HotSpot Tiered VM . . . 45
3.1 Left Y-axis:Accumulated positive and negative impact of each HotSpot optimiza-tion over our focus methods (non-scaled). Right Y-axis:Number of focus methods that are positively or negatively impacted by each HotSpot optimization. . . 61 3.2 Left Y-axis: Accumulated positive and negative impact of the 25 HotSpot
opti-mizations for each focus method (non-scaled). Right Y-axis: Number of opti-mizations that positively or negatively impact each focus method. . . 61 3.3 Average performance of best GA sequence in each generation compared to the
default compiler. . . 65 3.4 Performance of best program-wide optimization phase sequence after 100
3.5 Performance of method-specific optimization selection after 100 GA generations. Methods in (a) are ordered by the % of run-time spent in their respective bench-marks. In (b), methods from the same benchmark are shown together. All results are are scaled by the fraction of total program time spent in the focus method and show the run-time improvement of that individual method. . . 69 3.6 Accumulated improvement of method-specific optimization selection in
bench-marks with multiple focus method. . . 71 3.7 Effectiveness of benchmark-wide logistic regression. Training data for each
bench-mark consists of all the remaining programs from both benchbench-mark suites. . . 74 3.8 Effectiveness of method-specific logistic regression. Training data for each method
consists of all the other focus methods used in Section 3.5.3. . . 75 3.9 Experiments to analyze and improve the performance of feature-vector based
heuris-tic algorithms for online phase selection. (a) Not using cross-validation and (b) Using observations for Section 3.4. . . 76
4.1 Physical memory representation in the Linux kernel with trays as it relates to the system’s memory hardware. . . 92 4.2 Comparison of implementing the HotSpot NUMA optimization with the default
NUMA API vs. our memory coloring framework (a) shows the performance of each implementation relative to the default HotSpot performance. (b) shows the % of NUMA-local memory reads with each configuration. . . 97 4.3 Free memory available during kernel compilations with different memory priorities 100 4.4 Relationship between memory utilization and power consumption on three
differ-ent configurations . . . 103 4.5 Local allocation and recycling reduces DRAM power consumption. (a) shows
DRAM power relative to the default kernel (with interleaving enabled) and (b) shows the results relative to the custom kernel without local allocation and recy-cling. . . 104
4.6 Raw power governor samples with and without “tenured generation optimization” applied . . . 106
5.1 Colored spaces in our JVM framework. Dotted lines indicate possible paths for objects to move from one colored space to another. . . 118 5.2 Performance (a), bandwidth (b), average DRAM power (c), and DRAM energy (d)
for the MemBench benchmark. . . 121 5.3 Performance of our baseline configuration with the custom kernel compared to the
default configuration with the unmodified Linux kernel. . . 126 5.4 Perf. with each colored configuration compared to default. . . 133 5.5 DRAM energy consumed with each colored configuration compared to default. . . 134
List of Tables
2.1 Threshold parameters in the tiered compiler . . . 15
2.2 Benchmarks used in our experiments. . . 16
3.1 Configurable optimizations in our modified HotSpot compiler. Optimizations marked with∗are disabled in the default compiler. . . 56
3.2 Focus methods and their respective % of runtime . . . 67
3.3 List of method features used in our experiments . . . 72
5.1 Allocation Time for the MemBench Benchmark. . . 120
5.2 Benchmarks from SPECjvm2008 . . . 125
5.3 Cold Size / Total Size in profile and guided runs . . . 130
5.4 Average CKE OFF Residencies: Default Configuration . . . 131
5.5 Average CKE OFF Residencies: 2% Knapsack Coloring . . . 131
5.6 Average CKE OFF Residencies: 5% Knapsack Coloring . . . 132
Chapter 1
Introduction
Since the introduction of the Java programming language almost two decades ago, applications written in managed languages have become ubiquitous in domains ranging from embedded de-vices to enterprise servers. A major reason for their popularity is that managed languages have the distinct advantage of program portability; each application is distributed as machine-independent binary codes and executes inside a virtual machine(VM) environment (also called runtime sys-tem). In addition to enabling portable program emulation, VMs provide a convenient sandbox for monitoring and controlling application behavior at runtime. This architecture allows managed languages to deliver a number of other powerful features, such as garbage collection and dynamic class loading, that enhance the user-end programming model. To support these features, managed languages implement a number of services in the runtime system for managing and optimizing application behavior during execution. Despite their benefits, these services often introduce sig-nificant overheads and have created new challenges for achieving high performance.
Therefore, much research and industry effort has been focused on finding techniques and poli-cies to improve the efficiency of runtime services. This technology often relies upon program monitoring, such as online profiling or sampling, to help guide optimization and management de-cisions. In many cases, virtual machines have to carefully balance tradeoffs between the amount of overhead that can be tolerated and the benefits that can be delivered by the runtime service.
For example, consider the evolution of runtime emulation technology. Since the application binary format does not match the native architecture, VMs have to translate program instructions to machine code at runtime. Unfortunately, simple interpretation schemes incur large overheads and are too slow to compete with native execution. Thus, virtual machines have incorporated dynamic or Just-In-Time (JIT) compilation to improve emulation performance. However, since it occurs at runtime, JIT compilation contributes to the overall execution time of the application and can potentially impede application progress and further degrade its response time, if performed injudiciously. To address these issues, researchers invented selective compilation techniques to control if and when to compile program methods (Hölzle & Ungar, 1996; Paleczny et al., 2001; Krintz et al., 2000; Arnold et al., 2005). Selective compilation uses online profiling to identify the subset of hot methods that the application executes most often, and compiles these methods at program startup, This technique effectively limits the overhead of JIT compilation, while still deriving most of its performance benefits. Most current VMs employ selective compilation with a
stagedemulation model (e.g. interpret first, compile later), and use heuristics to balance throughput performance with response time (Hansen, 1974).
In this work, we explore a wide range of system policies and configurations as well as pro-pose innovative solutions for managing tradeoffs and improving optimization decisions in virtual machines. Our goal is to discover strategies and techniques that improve system performance and energy efficiency for a wide range of managed language applications. Thus, we target our investi-gation to runtime services that are most likely to impact execution efficiency, specifically, dynamic compilation and memory management. We conduct all of our studies using applications written in Java (today’s most popular managed language), and employ the industry-standard Oracle HotSpot Java Virtual Machine (JVM) to implement and evaluate each VM-based approach.
We first investigate the questions ofif,when, andhowto compile and optimize program regions during execution to maximize program efficiency. Previous research has shown that a conservative JIT compilation policy is most effective to obtain good runtime performance without impeding application progress on single-core machines. However, we observe that the best strategy depends
on architectural features, such as the number of available computing cores, as well as character-istics of the runtime compiler, including the number of compiling threads and how fast and how well methods are optimized. Our first study, presented in the next chapter, explores the properties of single-tier and multi-tier JIT compilation policies that enable VMs to realize the best program performance on modern machines. We design and implement an experimental framework to effec-tively control aspects of if and when methods are compiled, and perform hundreds of experiments to determine the best strategy for current single/multi-core as well as future many-core architec-tures.
Our second study, presented in Chapter 3, examines the problem ofphase selectionin dynamic compilers. Customizing the applied set of optimization phases for individual methods or programs has been found to significantly improve the performance of staticallygenerated code. However, the performance potential of phase selection for JIT compilers is largely unexplored. For this study, we develop an open-source, production-quality framework for applying program-wide or method-specific customized phase selections using the HotSpot server compiler as base. Using this framework, we conduct novel experiments to understand the behavior of optimization phases relevant to the phase selection problem. We employ long-running genetic algorithms to deter-mine the performance limits of customized phase selections, and later use these results to evaluate existing state-of-the-art heuristics.
In contrast to program emulation technology, which is, in most cases, confined to the virtual machine, most systems provide operating system and hardware support to virtualize applications’ access to memory resources. Despite its widespread popularity and native support, virtual memory creates a number of challenges for system optimizers and engineers. Specifically, it is very difficult to obtain precise control over the distribution of memory capacity, bandwidth, and/or power, when virtualizing system memory. For our second set of studies, we propose innovative memory man-agement strategies to overcome these challenges and enable more efficient distribution of memory resources. In Chapter 4, we propose and implement ourapplication guidanceframework for vir-tual memory systems. Our approach improves collaboration between the applications, operating
system, and memory hardware (i.e. controllers and DIMMs) during memory management in order to balance power and performance objectives. It includes an application programming interface (API) that enables applications to efficiently communicate different provisioning goals concerning groups of virtual ranges to the kernel. The OS incorporates this information while performing physical page allocation and recycling to achieve the various objectives. In this work, we describe the design and implementation of our application guidance framework, and present examples and experiments to showcase and evaluate the potential of our approach.
Our application guidance framework relies on engineers to manually determine and insert ef-fective memory usage guidance into application source code to realize provisioning goals. Un-fortunately, these requirements are infeasible for many workloads and usage scenarios. Thus, for our final study, which is presented in Chapter 5, we integrate our application guidance framework with the HotSpot JVM to provide anautomaticcross-layer memory management framework. Our implementation develops a novel profiling-based analysis and code generator in HotSpot that auto-matically classify and organize Java program objects into separate heap regions to improve energy efficiency. We evaluate our framework using a combination of custom as well as standard bench-mark workloads and find that it achieves significant DRAM energy savings without requiring any source code modifications or re-compilations.
The studies presented in this dissertation make significant progress towards understanding and improving program efficiency with virtual machine runtime services. We investigate a wide range of strategies and implement a number of new techniques to optimize power and performance for managed language applications. In sum, the major contributions of this dissertation are:
• We conduct a thorough exploration of various factors that affect JIT compilation strategy, and provide policy recommendations for available single/multi-core and future many-core machines,
• We construct a robust, open-source framework for exploring dynamic compiler phase selec-tion in the HotSpot JVM, and, using this framework, present the first analysis of theideal
• We design and implement the first-ever virtual memory system to allow applications to pro-vide guidance to the operating system during memory management, and present several examples to showcase and evaluate the benefits of this approach, and
• We integrate our application guidance framework with the HotSpot JVM to provide auto-matic cross-layer memory management, and perform detailed experimental and performance analysis to demonstrate the energy-saving potential of this approach.
Chapter 2
Exploring Single and Multi-Level JIT
Compilation Policy for Modern Machines
Dynamic or Just-in-Time (JIT) compilation is essential to achieve high-performance emulation for programs written in managed languages, such as Java and C#. It has been observed that a conservative JIT compilation policy is most effective to obtain good runtime performance without impeding application progress on single-core machines. At the same time, it is often suggested that a more aggressive dynamic compilation strategy may perform best on modern machines that provide abundant computing resources, especially with virtual machines (VM) that are also capable of spawning multiple concurrent compiler threads. However, comprehensive research on the best JIT compilation policy for such modern processors and VMs is currently lacking. The goal of this study is to explore the properties of single-tier and multi-tier JIT compilation policies that can enable existing and future VMs to realize the best program performance on modern machines.
In this chapter, we design novel experiments and implement new VM configurations to ef-fectively control the compiler aggressiveness and optimization levels (if and when methods are compiled) in the industry-standard Oracle HotSpot Java VM to achieve this goal. We find that the best JIT compilation policy is determined by the nature of the application and the speed and effec-tiveness of the dynamic compilers. We extend earlier results showing the suitability of
conserva-tive JIT compilation on single-core machines for VMs with multiple concurrent compiler threads. We show that employing the free compilation resources (compiler threads and hardware cores) to aggressively compilemore program methods quickly reaches a point of diminishing returns. At the same time, we also find that using the free resources to reduce compiler queue backup (com-pile selected hot methodsearly) significantly benefits program performance, especially for slower (highly-optimizing) JIT compilers. For such compilers, we observe that accurately prioritizing JIT method compiles is crucial to realize the most performance benefit with the smallest hardware budget. Finally, we show that a tiered compilation policy, although complex to implement, greatly alleviates the impact of more and early JIT compilation of programs on modern machines.
2.1
Introduction
To achieve application portability, programs written in managed programming languages, such as Java (Gosling et al., 2005) and C# (Microsoft, 2001), are distributed as machine-independent intermediate language binary codes for a virtual machine (VM) architecture. Since the program binary format does not match the native architecture, VMs have to employ either interpretation or dynamic compilation for executing the program. Additionally, the overheads inherent during program interpretation make dynamic or Just-in-Time (JIT) compilation essential to achieve high-performance emulation of such programs in a VM (Smith & Nair, 2005).
Since it occurs at runtime, JIT compilation contributes to the overall execution time of the ap-plication and can potentially impede apap-plication progress and further degrade itsresponsetime, if performed injudiciously. Therefore, JIT compilation policies need to carefully tuneif,when, and
how to compile different program regions to achieve the best overall performance. Researchers invented the technique ofselective compilationto address the issues ofif andwhento compile pro-gram methods during dynamic compilation (Hölzle & Ungar, 1996; Paleczny et al., 2001; Krintz et al., 2000; Arnold et al., 2005). Additionally, several modern VMs provide multiple optimization levels along with decision logic to control and decidehowto compile each method. While a
single-tiercompilation strategy always applies the same set of optimizations to each method, amulti-tier
policy may compile the same method multiple times at distinct optimization levels during the same program run. The control logic in the VM determines each method’shotnesslevel (or how much of the execution time is spent in a method) to decide its compilation level.
Motivation: Due to recent changes and emerging trends in hardware and VM architectures, there is an urgent need for a fresh evaluation of JIT compilation strategies on modern machines. Re-search on JIT compilation policies has primarily been conducted on single-processor machines and for VMs with a single compiler thread. As a result, existing policies that attempt to improve program efficiency while minimizing application pause times and interference are typically quite conservative. Recent years have witnessed a major paradigm shift in microprocessor design from high-clock frequency single-core machines to processors that now integrate multiple cores on a single chip. These modern architectures allow the possibility of running the compiler thread(s) on a separate core(s) to minimize interference with the application thread. VM developers are also responding to this change in their hardware environment by allowing the VM to simultaneously ini-tiate multiple concurrent compiler threads. Such evolution in the hardware and VM contexts may require radically different JIT compilation policies to achieve the most effective overall program performance.
Objective: The objective of this research is to investigate and recommend JIT compilation strate-gies to enable the VM to realize the best program performance on existing single/multi-core pro-cessors and future many-core machines. We vary thecompilation threshold, the number of initiated compiler threads, and single and multi-tier compilation strategies to controlif, when, and howto detect and compile important program methods. The compilation threshold is a heuristic value that indicates thehotnessof each method in the program. Thus, more aggressive policies employ a smaller compilation threshold so that more methods becomehotsooner. We induce progressive in-creases in the aggressiveness of JIT compilation strategies, and the number of concurrent compiler threads and analyze their effect on program performance. While a single-tier compilation strat-egy uses a single compiler (and fixed optimization set) for each hot method, a multi-tier compiler
policy typically compiles a hot method with progressivelyadvanced (that apply more and better optimizations to potentially produce higher-quality code), but slower, JIT compilers. Our experi-ments change the different multi-tier hotness thresholds in lock-step to alsopartiallycontrol how (optimization level) each method is compiled.1 Additionally, we design and construct a novel VM configuration to conduct experiments for many-core machines that are not commonly available as yet.
Findings and Contributions:This is the first work to thoroughly explore and evaluate these various compilation parameters and strategies 1) on multi-core and many-core machines and 2) together. We find that the most effective JIT compilation strategy depends on several factors, including: the availability of free computing resources, program features (particularly the ratio of hot pro-gram methods), and the compiling speed, quality of generated code, and the method prioritization algorithm used by the compiler(s) employed. In sum, the major contributions of this research are:
1. We design original experiments and VM configurations to investigate the most effective JIT compilation policies for modern processors and VMs with single and multi-level JIT compilation.
2. We quantify the impact of altering ‘if’, ‘when’, and one aspect to ‘how’ methods are com-piled on application performance. Our experiments evaluate JVM performance with vari-ous settings for compiler aggressiveness and the number of compilation threads, as well as different techniques for prioritizing method compiles, with both single and multi-level JIT compilers.
3. We explain the impact of different JIT compilation strategies on available single/multi-core and future many-core machines.
1In contrast to the two components of ‘if’ and ‘when’ to compile, the issue of how to compile program regions is
much broader and is not unique to dynamic compilation, as can be attested by the presence of multiple optimization levels in GCC, and the wide body of research in profile-driven compilation (Graham et al., 1982; Chang et al., 1991; Arnold et al., 2002; Hazelwood & Grove, 2003) and optimization phase ordering/selection (Whitfield & Soffa, 1997; Haneda et al., 2005a; Cavazos & O’Boyle, 2006; Sanchez et al., 2011) for static and dynamic compilers. Consequently, we only explore one aspect of ‘how’ to compile methods in this chapter, and provide a more thorough examination of these issues in Chapter 3.
The rest of this chapter is organized as follows. In the next section, we present background information and related work on existing JIT compilation policies. We describe our general ex-perimental setup in Section 2.3. Our experiments exploring different JIT compilation strategies for VMs with multiple compiler threads on single-core machines are described in Section 2.4. In Section 2.5, we present results that explore the most effective JIT compilation policies for multi-core machines. We describe the results of our novel experimental configuration to study compila-tion policies for future many-core machines in Seccompila-tion 2.6. We explain the impact of prioritizing method compiles, and effect of multiple application threads in Sections 2.7 and 2.8. Finally, we present our conclusions and describe avenues for future work in Sections 2.9 and 2.10 respectively.
2.2
Background and Related Work
Several researchers have explored the effects of conducting compilation at runtime on overall pro-gram performance and application pause times. The ParcPlace Smalltalk VM (Deutsch & Schiff-man, 1984) followed by the Self-93 VM (Hölzle & Ungar, 1996) pioneered many of the adaptive optimization techniques employed in current VMs, including selective compilation with multiple compiler threads on single-core machines. Aggressive compilation on such machines has the po-tential of degrading program performance by increasing the compilation time. The technique of selective compilation was invented to address this issue with dynamic compilation (Hölzle & Un-gar, 1996; Paleczny et al., 2001; Krintz et al., 2000; Arnold et al., 2005). This technique is based on the observation that most applications spend a large majority of their execution time in a small portion of the code (Knuth, 1971; Bruening & Duesterwald, 2000; Arnold et al., 2005). Selective compilation uses online profiling to detect this subset ofhotmethods to compile at program startup, and thus limits the overhead of JIT compilation while still deriving the most performance benefit. Most current VMs employ selective compilation with astagedemulation model (Hansen, 1974). With this model, each method is interpreted or compiled with a fast non-optimizing compiler at program start to improve application response time. Later, the VM determines and selectively
compiles and optimizes only the subset of hot methods to achieve better program performance. Unfortunately, selecting the hot methods to compile requires future program execution infor-mation, which is hard to accurately predict (Namjoshi & Kulkarni, 2010). In the absence of any better strategy, most existing JIT compilers employ a simple prediction model that estimates that frequently executedcurrenthot methods will also remain hot in the future (Grcevski et al., 2004; Kotzmann et al., 2008; Arnold et al., 2000a). Online profiling is used to detect these current hot methods. The most popular online profiling approaches are based on instrumentation coun-ters (Hansen, 1974; Hölzle & Ungar, 1996; Kotzmann et al., 2008), interrupt-timer-based sam-pling (Arnold et al., 2000a), or a combination of the two methods (Grcevski et al., 2004). The method/loop is sent for compilation if the respective method counters exceed a fixed threshold.
Finding the correct threshold value is crucial to achieve good program startup performance in a virtual machine. Setting a higher than ideal compilation threshold may cause the virtual ma-chine to be too conservative in sending methods for compilation, reducing program performance by denying hot methods a chance for optimization. In contrast, a compiler with a very low com-pilation threshold may compile too many methods, increasing comcom-pilation overhead. Therefore, most performance-aware JIT compilers experiment with many different threshold values for each compiler stage to determine the one that achieves the best performance over a large benchmark suite.
Resource constraints force JIT compilation policies to make several tradeoffs. Thus, selec-tive compilation limits the time spent by the compiler at the cost of potentially lower application performance. Additionally, the use of online profiling causes delays in making the compilation de-cisions at program startup. The first component of this delay is caused by the VM waiting for the method counters to reach the compilationthresholdbeforequeuingit for compilation. The second factor contributing to the compilation delay occurs as each compilation request waits in the com-piler queue to be serviced by a free comcom-piler thread. Restricting method compiles and the delay in optimizing hot methods results in poor application startup performance as the program spends more time executing in unoptimized code (Kulkarni et al., 2007a; Krintz, 2003; Gu & Verbrugge,
2008).
Various strategies have been developed to address these delays in JIT compilation at program startup. Researchers have explored the potential of offline profiling and classfile annotation (Krintz & Calder, 2001; Krintz, 2003), early and accurate prediction of hot methods (Namjoshi & Kulka-rni, 2010), and online program phase detection (Gu & Verbrugge, 2008) to alleviate the first delay component caused by online profiling. Likewise, researchers have also studied techniques to ad-dress the second component of the compilation delay caused by the backup and wait time in the method compilation queue. These techniques include increasing the priority (Sundaresan et al., 2006) and CPU utilization (Kulkarni et al., 2007a; Harris, 1998) of the compiler thread, and pro-viding a priority-queue implementation to reduce the delay for thehotterprogram methods (Arnold et al., 2000b).
However, most of the studies described above have only been targeted for single-core machines. There exist few explorations of JIT compilation issues for multi-core machines. Krintz et al. in-vestigated the impact of background compilation in a separate thread to reduce the overhead of dy-namic compilation (Krintz et al., 2000). This technique uses a single compiler thread and employs offline profiling to determine and prioritize hot methods to compile. Kulkarni et al. briefly discuss performing parallel JIT compilation with multiple compiler threads on multi-core machines, but do not provide any experimental results (Kulkarni et al., 2007a). Existing JVMs, such as Sun’s HotSpot server VM (Paleczny et al., 2001) and the Azul VM (derived from HotSpot), support multiple compiler threads, but do not present any discussions on ideal compilation strategies for multi-core machines. Prior work by Böhm et al. explores the issue of parallel JIT compilation with a priority queue based dynamic work scheduling strategy in the context of their dynamic binary translator (Böhm et al., 2011). Esmaeilzadeh et al. study the scalability of various Java workloads and their power / performance tradeoffs across several different architectures (Esmaeilzadeh et al., 2011). Our earlier publications explore some aspects of the impact of varying the aggressiveness of dynamic compilation on modern machines for JVMs with multiple compiler threads (Kulka-rni & Fuller, 2011; Kulka(Kulka-rni, 2011). This chapter extends our earlier works by (a) providing
more comprehensive results, (b) re-implementing most of the experiments in the latest OpenJDK JVM that provides a state-of-the-art multi-tier compiler and supports improved optimizations, (c) differentiating the results and re-analyzing our observations based on benchmark characteristics, (d) exploring different heuristic priority schemes, and (e) investigating the effects of aggressive compilation and multiple compiler threads on the multi-tiered JIT compilation strategies. Several production-grade Java VMs, including the Oracle HotSpot and IBM J9, now adopt a multi-tier compilation strategy, which make our results with the multi-tiered compiler highly interesting and important.
2.3
Experimental Framework
The research presented in this chapter is performed using Oracle’s OpenJDK/HotSpot Java virtual machine (build 1.6.0_25-b06) (Paleczny et al., 2001). The HotSpot VM uses interpretation at pro-gram startup. It then employs a counter-based profiling mechanism, and uses the sum of a method’s
invocationand loopback-edge counters to detect and promote hot methods for compilation. We call the sum of these counters theexecution countof the method. Methods/loops are determined to be hot if the corresponding method execution count exceeds a fixed threshold. The HotSpot VM allows the creation of an arbitrary number of compiler threads, as specified on the command-line.
The HotSpot VM implements two distinct optimizing compilers to improve application per-formance beyond interpretation. The client compiler provides relatively fast compilation times with smaller program performance gains to reduce application startup time (especially, on single-core machines). The server compiler applies an aggressive optimization strategy to maximize performance benefits for longer running applications. We conducted experiments to compare the overhead and effectiveness of HotSpot’s client and server compiler configurations. We found that the client compiler is immensely fast, and onlyrequires about 2% of the time, on average, taken by the server compiler to compile the same set of hot methods. At the same time, the simple and fastclient compiler is able to obtain most (95%) of the performance gain (relative to interpreted
code) realized by the server compiler.
In addition to the single-level client and server compilers, HotSpot provides atiered compiler
configuration that utilizes and combines the benefits of the client and server compilers. In the most common path in the tiered compiler, each hot method is first compiled with the client compiler (possibly with additional profiling code inserted), and later, if the method remains hot, is recom-piled with the server compiler. Each compiler thread in the HotSpot tiered compiler is dedicated to either the client or server compiler, andeach compiler is allocated at least one thread. To account for the longer compilation times needed by the server compiler, HotSpot automatically assigns the compiler threads at a 2:1 ratio in favor of the server compiler. The property of the client compiler to quickly produce high-quality optimized code greatly influences the behavior of the tiered compiler under varying compilation loads, as our later experiments in this chapter will reveal.
There is a singlecompiler queuedesignated to each (client and server) compiler in the tiered configuration. These queues employ a simple execution count based priority heuristic to ensure the most active methods are compiled earlier. This heuristic computes the execution count of each method in the appropriate queue since the last queue removal to find the most active method. As the load on the compiler threads increases, HotSpot dynamically increases its compilation thresholds to prevent either the client or server compiler queues from growing prohibitively long. In addition, the HotSpot tiered compiler has logic to automatically removestalemethods that have stayed in the queue for too long. For our present experiments, we disable the automatic throttling of compilation thresholds and removal of stale methods to appropriately model the behavior of a generic tiered compilation policy. The tiered compiler uses different thresholds that move in lockstep to tune the aggressiveness of its component client and server compilers. Table 2.1 describes these compilation thresholds and their default values for each compiler in the tiered configuration.
The experiments in this chapter were conducted using all the benchmarks from three different benchmark suites, SPECjvm98 (SPEC98, 1998), SPECjvm2008 (SPEC2008, 2008) and DaCapo-9.12-bach (Blackburn et al., 2006). We employ two inputs (10 and 100) for benchmarks in the SPECjvm98 suite, two inputs (small and default) for the DaCapo benchmarks, and a single input
Table 2.1: Threshold parameters in the tiered compiler
Parameter Description Client
Default
Server Default Invocation Threshold Compile method if invocation count exceeds this threshold 200 5000 Backedge Threshold OSR compile method if backedge count exceeds this threshold 7000 40000
Compile Threshold Compile method if invocation + backedge count exceeds this threshold (and invocation count>Minimum Invocation Threshold)
2000 15000
Minimum Invocation Threshold
Minimum number of invocations required before method can be considered for compilation
100 600
(startup) for benchmarks in the SPECjvm2008 suite, resulting in 57 benchmark/input pairs. Two benchmarks from the DaCapo benchmark suite, tradebeans and tradesoap, did not always run correctly with thedefault version of the HotSpot VM, so these benchmarks were excluded from our set. In order to limit possible sources of variation in our experiments, we set the number of application threads to one whenever possible. Unfortunately, several of our benchmarks employ multiple application threads due tointernal multithreadingthat cannot be controlled by the harness application. Table 2.2 lists the name, number of invoked methods (under the column labeled #M), and number of application threads (under the column labeled #AT) for each benchmark in our suite.
All our experiments were performed on a cluster of dual quad-core, 64-bit, x86 machines running Red Hat Enterprise Linux 5 as the operating system. The cluster includes three models of server machine: Dell M600 (two 2.83GHz Intel Xeon E5440 processors, 16GB DDR2 SDRAM), Dell M605 (two 2.4GHz AMD Opteron 2378 processors, 16GB DDR2 SDRAM), and PowerEdge SC1435 (two 2.5GHz AMD Opteron 2380 processors, 8GB DDR2 SDRAM). We run all of our experiments on one of these three models, but experiments comparing runs of the same benchmark always use the same model. There are no hyperthreading or frequency scaling techniques of any kind enabled during our experiments.
We disable seven of the eight available cores to run our single-core experiments. Our multi-core experiments utilize all available cores. More specific variations made to the hardware configuration are explained in the respective sections. Each benchmark is run in isolation to prevent interference from other user programs. In order to account for inherent timing variations during the benchmark runs, all the performance results in this chapter report the average over 10 runs for each
benchmark-Table 2.2: Benchmarks used in our experiments.
SPECjvm98 SPECjvm2008 DaCapo-9.12-bach
Name #M #AT Name #M #AT Name #M #AT
_201_compress_100 517 1 compiler.compiler 3195 1 avrora_default 1849 6
_201_compress_10 514 1 compiler.sunflow 3082 1 avrora_small 1844 3
_202_jess_100 778 1 compress 960 1 batik_default 4366 1
_202_jess_10 759 1 crypto.aes 1186 1 batik_small 3747 1
_205_raytrace_100 657 1 crypto.rsa 960 1 eclipse_default 11145 5
_205_raytrace_10 639 1 crypto.signverify 1042 1 eclipse_small 5461 3
_209_db_100 512 1 derby 6579 1 fop_default 4245 1
_209_db_10 515 1 mpegaudio 959 1 fop_small 4601 2
_213_javac_100 1239 1 scimark.fft.small 859 1 h2_default 2154 3
_213_javac_10 1211 1 scimark.lu.small 735 1 h2_small 2142 3
_222_mpegaudio_100 659 1 scimark.monte_carlo 707 1 jython_default 3547 1
_222_mpegaudio_10 674 1 scimark.sor.small 715 1 jython_small 2070 2
_227_mtrt_100 658 2 scimark.sparse.small 717 1 luindex_default 1689 2
_227_mtrt_10 666 2 serial 1121 1 luindex_small 1425 1
_228_jack_100 736 1 sunflow 2015 5 lusearch_default 1192 1
_228_jack_10 734 1 xml.transform 2592 1 lusearch_small 1303 2
xml.validation 1794 1 pmd_default 3881 8 pmd_small 3058 3 sunflow_default 1874 2 sunflow_small 1826 2 tomcat_default 9286 6 tomcat_small 9189 6 xalan_default 2296 1 xalan_small 2277 1
configuration pair. Theharnessof all our benchmark suites allows each benchmark to be iterated
multiple times in the same VM run. We measure the performance of each benchmark as the time it takes to invoke and complete one benchmark iteration. Thus, for all of the experiments in the subsequent sections of this paper, any compilation that occurs is performed concurrently with the running application.
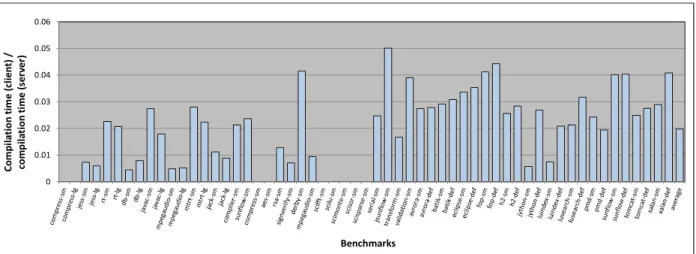
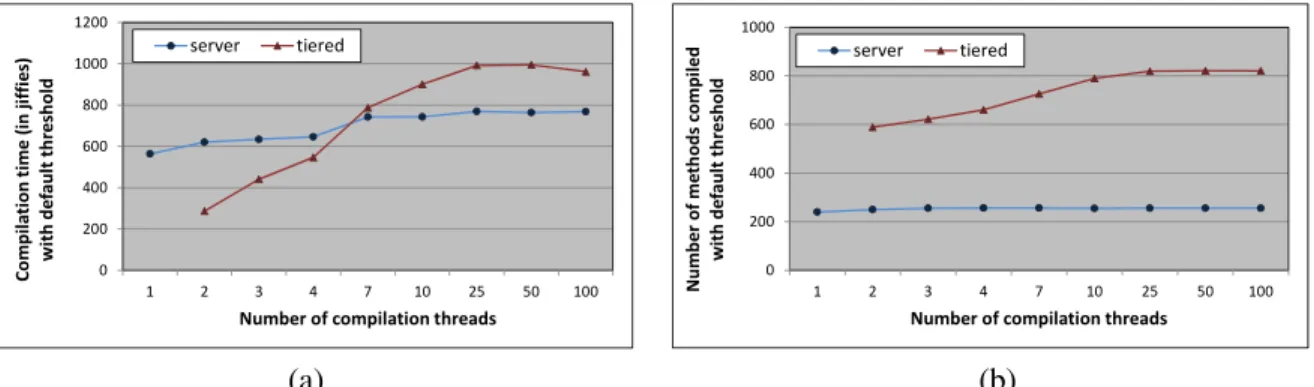
However, we first conduct experiments to illustrate thecompilationandsteady-stateexecution time differences of the HotSpot server and client compilers for all our benchmark programs. Fig-ures 2.1 and 2.2 show the results of these experiments. Each experiment employs one of either the server or client compiler. Regardless of which compiler is used, we use the default server compiler threshold to identify hot methods to ensure the same set of methods are compiled in our com-parisons. Each steady-state run disables background compilation to enable all hot methods to be compiled in the first program iteration. We reset the method execution counts after each iteration to prevent any other methods from becoming hot in later program iterations. We then allow each benchmark to iterate 11 more times and record the median runtime of these iterations as the time of the steady-state run. For each benchmark, Figure 2.1 plots the ratio of compilation time
regis-0 0.01 0.02 0.03 0.04 0.05 0.06 C o m p il a ti o n t im e ( cl ie n t) / co m p il a ti o n t im e ( se rv e r) Benchmarks
Figure 2.1: Ratio of client and sever compile times when compiling the same number of program methods 0 0.1 0.2 0.3 0.4 0.5 0.6 T im e w it h c o m p il e d c o d e / ti m e w it h i n te rp re te d c o d e Benchmarks Client Server 0.754 0.797
Figure 2.2: Steady-state program execution times using the server and client compilers as a ratio of the interpreted program run-time
tered by the client and server compilers, averaged over 10 steady-state program runs. Our Linux system measures thread times injiffies. The duration of each jiffy, which is configurable at kernel compile time, is about 1msec on our system. Some benchmarks compile only a few methods in our steady-state experiments (the minimum ismonte_carlowhich has only two hot methods with the default server compiler threshold), and require very little compilation time. Cases in which the steady-state run registers less than one jiffy of compilation thread time are reported as zero in Figure 2.1. As we can see, the client compiler is immensely fast, and onlyrequires about 2% of the time, on average, taken by the server compilerto compile the same set of methods.
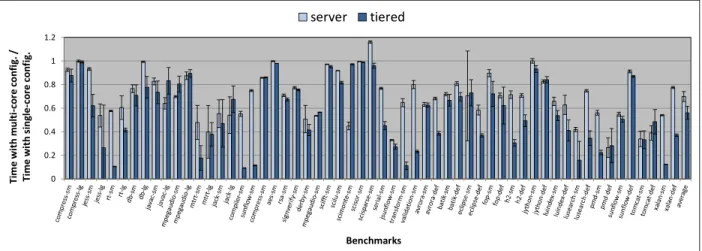
0 0.2 0.4 0.6 0.8 1 1.2 T im e w it h m u lt i-co re c o n fi g . / T im e w it h s in g le -c o re c o n fi g . Benchmarks server tiered
Figure 2.3: Ratio of multi-core performance to single-core performance for each compiler config-uration.
Figure 2.2 plots the steady-state benchmark run-time using the client and server compilers as compared with the time required for interpreted execution. To estimate the degree of variability in our run-time results, we compute 95% confidence intervals for the difference between the means as described in (Georges et al., 2007) and plot these intervals as error bars.2 Figure 2 shows that both the compilers achieve significant program speedups. However, it is interesting to note that the simple and fastclient compiler is able to obtain most of the performance gain realized by the server compiler. This property of the client compiler to quickly produce high-quality optimized code greatly influences the behavior of the tiered compiler under varying compilation loads, as our later experiments in this chapter will reveal.
Finally, we present a study to compare the program performance on single-core and multi-core machines. Figure 2.3 shows the multi-core performance of each benchmark relative to single-core performance for both the default server and tiered compiler configurations. Not surprisingly, we observe that most benchmarks run much faster with the multi-core configuration. Much of this difference is simply due to increased parallelism, but other micro-architectural effects, such as cache affinity and inter-core communication, may also impact performance depending on the workload. Another significant factor, which we encounter in our experiments throughout this
2It is difficult to estimate confidence intervals for the average across all the benchmarks (which is reported as an
average of ratios). For these estimates, we assume the maximum difference between the means for each benchmark (in either the positive or negative direction) and re-calculate the average.
work, is that additional cores enable earlier compilation of hot methods. This effect accounts for the result that the tiered VM, with its much more aggressive compilation threshold, exhibits a more pronounced performance improvement, on average, than the server VM. The remainder of this chapter explores and explains the impact of different JIT compilation strategies on modern and future architectures using the HotSpot server and tiered compiler configurations.
2.4
JIT Compilation on Single-Core Machines
In this section we report the results of our experiments conducted on single-core processors to understand the impact of aggressive JIT compilation and more compiler threads in a VM on pro-gram performance. Our experimental setup controls the aggressiveness of distinct JIT compilation policies by varying the selective compilation threshold. Changing the compilation threshold can affect program performance in two ways: (a) by compiling a lesser or greater percentage of the program code (if a method is compiled), and (b) by sending methods to compile early or late (when
is each method compiled). We first employ the HotSpot server VM with a single compiler thread to find the selective compilation threshold that achieves the best average performance with our set of benchmark programs.3 Next, we evaluate the impact of multiple compiler threads on program performance for machines with a single processor with both the server and tiered compilers in the HotSpot JVM.
2.4.1
Compilation Threshold with Single Compiler Thread
By virtue of sharing the same computation resources, the application and compiler threads share a complex relationship in a VM running on a single-core machine. A highly selective compile threshold may achieve poor overall program performance by spending too much time executing in non-optimized code resulting in poor overall program run-time. By contrast, a lower than ideal compile threshold may also produce poor performance by spending too long in the compiler thread.
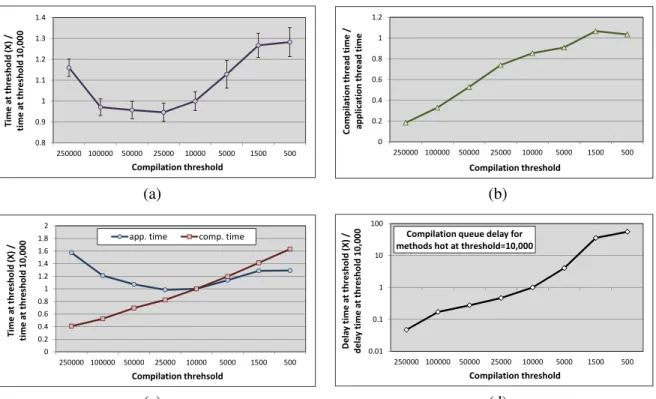
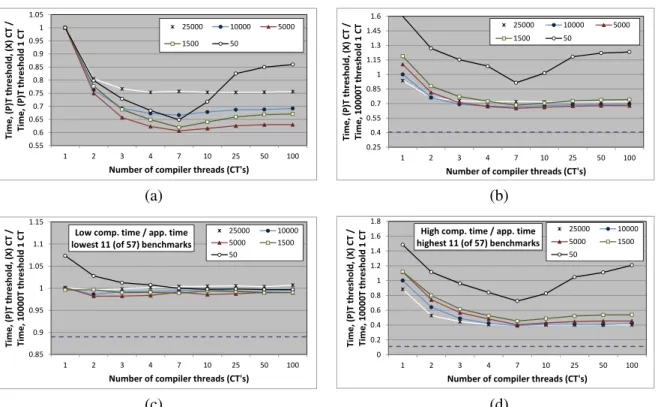
0.8 0.9 1 1.1 1.2 1.3 1.4 250000 100000 50000 25000 10000 5000 1500 500 T im e a t th re sh o ld ( X ) / ti m e a t th re sh o ld 1 0 ,0 0 0 Compilation threshold 0 0.2 0.4 0.6 0.8 1 1.2 250000 100000 50000 25000 10000 5000 1500 500 C o m p il a ti o n t h re a d t im e / a p p li ca ti o n t h re a d t im e Compilation threshold (a) (b) 0 0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.8 2 250000 100000 50000 25000 10000 5000 1500 500 T im e a t th re sh o ld ( X ) / ti m e a t th re sh o ld 1 0 ,0 0 0 Compilation threhsold
app. time comp. time
0.01 0.1 1 10 100 250000 100000 50000 25000 10000 5000 1500 500 D e la y t im e a t th re sh o ld ( X ) / d e la y t im e a t th re sh o ld 1 0 ,0 0 0 Compilation threshold Compilation queue delay for methods hot at threshold=10,000
(c) (d)
Figure 2.4: Effect of different compilation thresholds on average benchmark performance on single-core processors.
Therefore, the compiler thresholds need to be carefully tuned to achieve the most efficient average program execution on single-core machines over several benchmarks.
We perform an experiment to determine the ideal compilation threshold for the HotSpot server VM with asinglecompiler thread on our set of benchmarks. These results are presented in Fig-ure 2.4(a). The figFig-ure compares the average overall program performance at different compile thresholds to the average program performance at the threshold of 10,000, which is the default compilation threshold for the HotSpot server compiler. We find that a few of the less aggressive thresholds are slightly faster, on average, than the default for our set of benchmark programs (al-though the difference is within the margin of error). The default HotSpot server VM employs two compiler threads and may have been tuned with applications that run longer than our benchmarks, which may explain this result. The average benchmark performance worsens at both high and low compile thresholds.
to estimate the amount of time spent doing compilation compared to the amount of time spent executing the application. Figure 2.4(b) shows the ratio of compilation to application thread times at each threshold averaged over all the benchmarks. Thus, compilation thresholds that achieve good performance spend a significant portion of their overall runtime doing compilation. We can also see that reducing the compilation threshold increases the relative amount of time spent doing compilation. However, it is not clear how much of this trend is due to longer compilation thread times (from compiling more methods) or reduced application thread times (from executing more native code).
Therefore, we also consider the effect of compilation aggressiveness on each component sep-arately. Figure 2.4(c) shows the break-down of the overall program execution in terms of the application and compiler thread times at different thresholds to their respective times at the com-pile threshold of 10,000, averaged over all benchmark programs. We observe that high thresholds (>10,000) compile less and degrade performance by not providing an opportunity to the VM to
compile several important program methods. In contrast, the compiler thread times increase with lower compilation thresholds (<10,000) as more methods are sent for compilation. We expected
this increased compilation to improve application thread performance. However, the behavior of the application thread times at low compile thresholds is less intuitive.
On further analysis we found that JIT compilation policies with lower thresholds send more methods to compile and contribute to compiler queue backup. We hypothesize that the flood of less important program methods delays the compilation of the most critical methods, resulting in the non-intuitive degradation in application performance at lower thresholds. To verify this hypothesis we conduct a separate set of experiments thatmeasure the average compilation queue delay (time spent waiting in the compile queue) of hot methods in our benchmarks.These experiments compute the mean average compilation queue delay only for methods that are hot at the default threshold of 10,000 for each benchmark / compile threshold combination.
Figure 2.4(d) plots the average compilation queue delay at each compile threshold relative to the average compilation queue delay at the default threshold of 10,000 averaged over the
bench-marks.4 As we can see, the average compilation queue delay for hot methods increases dramat-ically as the compilation threshold is reduced. Thus, we conclude that increasing compiler ag-gressiveness is not likely to improve VM performance running with a single compiler thread on single-core machines.
2.4.2
Effect of Multiple Compiler Threads on Single-Core Machines
In this section we analyze the effect of multiple compiler threads on program performance on a single-core machine with the server and tiered compiler configurations of the HotSpot VM.
2.4.2.1 Single-Core Compilation Policy with the HotSpot Server Compiler
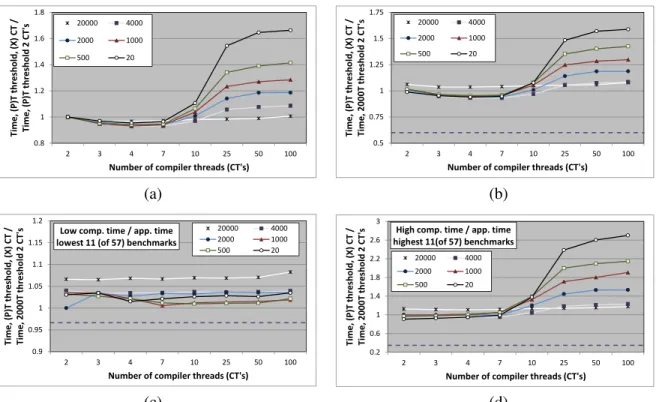
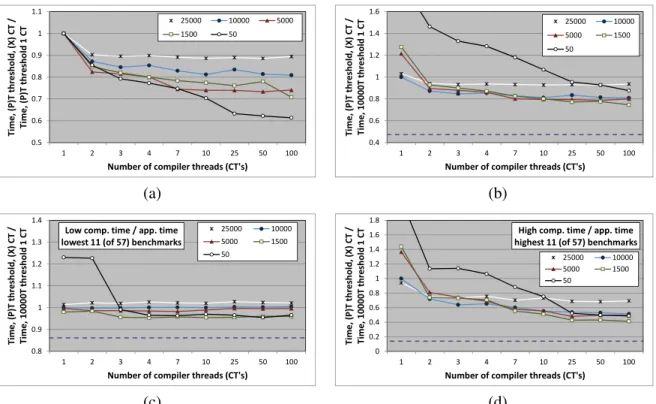
For each compilation threshold, a separate plot in Figure 2.5(a) compares the average overall pro-gram performance with multiple compiler threads to the average performance with a single com-piler thread at that same threshold. Intuitively, a greater number of comcom-piler threads should be able to reduce the method compilation queue delay. Indeed, we notice program performance im-provements for one or two extra compiler threads, but the benefits do not hold with increasing number of such threads (>3). We further analyzed the performance degradation with more
com-piler threads and noticed an increase in the overall compiler thread times in these cases. This increase suggests that several methods that were queued for compilation, but never got compiled before program termination with a single compiler thread are now compiled as we provide more VM compiler resources. While the increased compiler activity increases compilation overhead, many of these methods contribute little to improving program performance. Consequently, the potential improvement in application performance achieved by more compilations seems unable to recover the additional compiler overhead, resulting in a net loss in overall program performance.
Figure 2.5(b) compares the average overall program performance in each case to the average performance of a baseline configuration with a single compiler thread at a threshold of 10,000.
4We cannot compute a meaningful ratio for benchmarks with zero or very close to zero average compilation queue
delay at the baseline threshold. Thus, these results do not include 14 (of 57) benchmarks with an average compilation queue delay less than 1msec (the precision of our timer) at the default threshold.
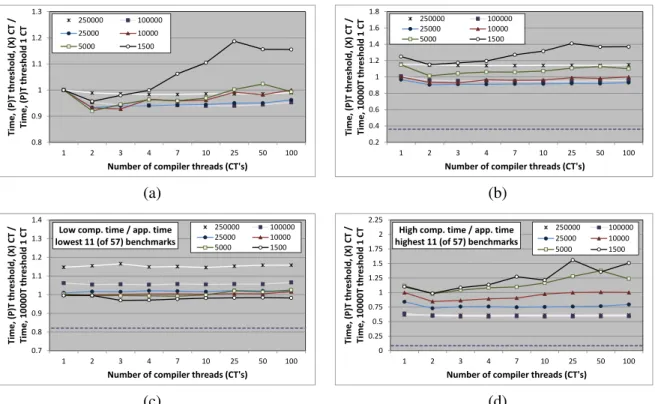
0.8 0.9 1 1.1 1.2 1.3 1 2 3 4 7 10 25 50 100 T im e , (P )T t h re sh o ld , (X ) C T / T im e , (P )T t h re sh o ld 1 C T
Number of compiler threads (CT's)
250000 100000 25000 10000 5000 1500 0.2 0.4 0.6 0.8 1 1.2 1.4 1.6 1.8 1 2 3 4 7 10 25 50 100 T im e , (P )T t h re sh o ld , (X ) C T / T im e , 1 0 0 0 0 T t h re sh o ld 1 C T
Number of compiler threads (CT's)
250000 100000 25000 10000 5000 1500 (a) (b) 0.7 0.8 0.9 1 1.1 1.2 1.3 1.4 1 2 3 4 7 10 25 50 100 T im e , (P )T t h re sh o ld , (X ) C T / T im e , 1 0 0 0 0 T t h re sh o ld 1 C T
Number of compiler threads (CT's) Low comp. time / app. time
lowest 11 (of 57) benchmarks
250000 100000 25000 10000 5000 1500 0 0.25 0.5 0.75 1 1.25 1.5 1.75 2 2.25 1 2 3 4 7 10 25 50 100 T im e , (P )T t h re sh o ld , (X ) C T / T im e , 1 0 0 0 0 T t h re sh o ld 1 C T
Number of compiler threads (CT's) High comp. time / app. time
highest 11 (of 57) benchmarks
250000 100000
25000 10000
5000 1500
(c) (d)
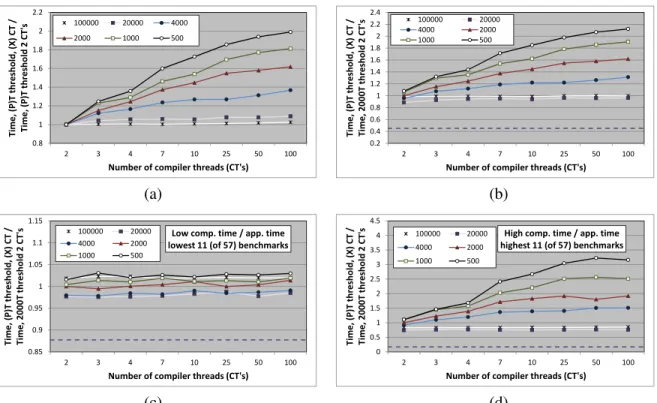
Figure 2.5: Effect of multiple compiler threads on single-core program performance in the HotSpot VM with server compiler. The discrete measured thread points are plotted equi-distantly on the x-axis.
These results reveal the best compiler policy on single-core machines with multiple compiler threads. Thus, we can see that, on average, the more aggressive thresholds perform quite poorly, while moderately conservative thresholds fare the best (with any number of compiler threads). Our analysis finds higher compiler aggressiveness to send more program methods for compilation, which includes methods that may not make substantial contributions to performance improvement (coldmethods). Additionally, the default server compiler in HotSpot uses a simple FIFO (first-in first-out) compilation queue, and compiles methods in the same order in which they are sent. Con-sequently, the cold methods delay the compilation of the really important hot methods relative to the application thread, producing the resultant loss in performance.
To further evaluate the configurations with varying compilation resources and aggressiveness (in these and later experiments), we design anoptimalscenario that measures the performance of each benchmark with all of its methods pre-compiled. Thus, the ‘optimal’ configuration reveals the best-case benefit of JIT compilation. The dashed line in Figure 2.5(b) shows the optimal
run-time on the single-core machine configuration relative to the same baseline startup performance (single benchmark iteration with one compiler thread and a threshold of 10,000), averaged over all the benchmarks. Thus, the “optimal” steady-state configuration achieves much better performance compared to the “startup” runs that compile methods concurrently with the running application on single-core machines. On average, the optimal performance is about 64% faster than the base-line configuration and about 54% faster than the fastest compilation thread / compile threshold configuration (with two compilation threads and a compile threshold of 25,000).
Figure 2.5(c) shows the same plots as in Figure 2.5(b) but only for the 11 (20%) benchmarks with the lowest compilation to application time ratio. Thus, for applications that spend relatively little time compiling, only the very aggressive compilation thresholds cause some compilation queue delay and may produce small performance improvements in some cases. For such bench-marks, all the hot methods are always compiled before program termination. Consequently, the small performance improvements with the more aggressive thresholds are due to compiling hot methods earlier (reduced queue delay). Furthermore, there is only a small performance difference between the startup and optimal runs. By contrast, Figure 2.5(d) only includes the 11 (20%) bench-marks with a relatively high compilation to application time ratio. For programs with such high compilation activity, the effect of compilation queue delay is more pronounced. We find that the less aggressive compiler policies produce better efficiency gains for these programs, but there is still much room for improvement as evidenced by optimal performance results.
These observations suggest that a VM that can adapt its compilation threshold based on the compiler load may achieve the best performance for all programs on single-core machines. Addi-tionally, implementing a priority-queue to order compilations may also enable the more aggressive compilation thresholds to achieve better performance. We explore the effect of prioritized method compiles on program performance in further detail in Section 2.7. Finally, a small increase in the number of compiler threads can also improve performance by reducing the compilation queue delay.