Algorithmically generating new algebraic
features of polynomial systems for
machine learning
Florescu, D. & England, M.
Published PDF deposited in Coventry University’s Repository
Original citation:
Florescu, D & England, M 2019, Algorithmically generating new algebraic features of
polynomial systems for machine learning. in Proceedings of the 4th International
Workshop on Satisfiability Checking and Symbolic Computation. vol. (In-Press), CEUR
Workshop Proceedings, 4th International Workshop on Satisfiability Checking and
Symbolic Computation, Bern , Switzerland, 10/07/19.
ISSN 1613-0073
ESSN 1613-0073
Publisher: CEUR Workshop Proceedings
Copyright © 2019 for the individual papers by the papers' authors. This volume
and its papers are published under the Creative Commons License Attribution 4.0
International (CC BY 4.0).
Copyright © and Moral Rights are retained by the author(s) and/ or other
copyright owners. A copy can be downloaded for personal non-commercial
research or study, without prior permission or charge. This item cannot be
reproduced or quoted extensively from without first obtaining permission in
writing from the copyright holder(s). The content must not be changed in any way
or sold commercially in any format or medium without the formal permission of
the copyright holders.
Algorithmically
Generating
New
Algebraic
Features
of
Polynomial
Systems
for
Machine
Learning
Dorian
Florescu
Matthew
England
[email protected]
[email protected]
Faculty ofEngineering,EnvironmentandComputing, Coventry University,Coventry,CV15FB,UK
Abstract
There are a variety of choices to be made in both computer algebra systems (CASs)andsatisfiabilitymodulotheory(SMT) solverswhich can impact performance without affecting mathematical correctness. Such choices are candidates for machine learning (ML) approaches, however,therearedifficultiesinapplyingstandardMLtechniques,such as theefficient identification of MLfeatures from inputdata whichis typicallya polynomialsystem.
Ourfocusisselectingthevariableorderingforcylindricalalgebraicde composition (CAD), an important algorithm implemented in several CASs,andnowalsoSMT-solvers. Wecreatedaframeworktodescribe allthepreviouslyidentifiedMLfeaturesfortheproblemandthenenu meratedalloptionsin thisframeworkto automaticallygeneratemany more features. Wevalidatetheusefulnessofthesewithanexperiment whichshows thatanML choicefor CADvariable orderingissuperior tothosemadebyhumancreatedheuristics,andfurtherimprovedwith these additionalfeatures. This technique of feature generation could be useful for other choices related to CAD, or even choices for other algorithmsin CASs/SMT-solverswithpolynomial systemsasinput.
1
Introduction
MachineLearning (ML),that isstatistical techniques togive computer systems theabilityto learn rulesfrom data,isatopic thathasfoundgreatsuccessinadiverserangeoffieldsoverrecentyears. MLismostattractive when theunderlying functional relationship tobe modelledis complexor notwell understood. Hence ML has yettomakea largeimpactinthefieldswhichformSC2,SymbolicComputationandSatisfiability Checking[1], sincetheseprizemathematicalcorrectnessandseektounderstandunderlyingfunctionalrelationships. However, as mostdeveloperswouldacknowledge, oursoftwareusually comeswitha rangeofchoices which,whilehaving noeffectonthecorrectnessoftheendresult,couldhaveagreateffectontheresourcesrequiredtofindit. These choicesrangefromthelowlevel(inwhatordertoperformasearchthatmayterminateearly)tothehigh(which of a set of competingexact algorithms to use for this problem instance). In making such choices we may be facedwithdecisionswhererelationships arenotfullyunderstood, butarenotthekeyobject ofstudy.
Copyright©c bythepaper’sauthors. UsepermittedunderCreativeCommonsLicenseAttribution4.0International(CCBY4.0).
In: J. Abbott,A. Griggio(eds.): Proceedingsof the4th SC-squareWorkshop, Bern, Switzerland, 10thJuly2019, publishedat http://ceur-ws.org
Inpracticesuchchoices maybe madebyman-made heuristicsbasedonsomeexperimentation (e.g. [18])or
magic constants wherecrossinga singlethresholdchangessystembehaviour[11]. Itislikelythat manyofthese decisions couldbeimprovedbyallowinglearning algorithmstoanalysethedata. Thebroad topicofthispaper is ML for algorithm choices where the input is a set of polynomials, which encompasses a variety of tools in computer algebrasystemsand theSMTtheoryof[QuantifierFree]Non-LinearRealArithmetic,[QF]NRA.
Therehasbeen littleresearchontheuseofMLin computer algebra: only[33]onidentifyingefficient multi variate Hornerschemes;[28] [27][24]onthetopic ofCADvariableorderingchoice;[26], [27]onthequestionof whether to preconditionCAD with GroebnerBases; and[31] ondecidingtheorder ofsub-formulae solvingfor a QEprocedure. WithinSMTtherehasbeen significantworkontheBooleanlogicside e.g. theportfolioSAT solver SATZilla[46] andMapleSAT[34]whichviewssolver branchingas anoptimisation problem. However thereislittleworkontheuseofMLtochoose oroptimisetheorysolvers.
Wenotethatother fieldsofmathematicalsoftwareareaheadin theuseof ML,mostnotably theautomated reasoningcommunity(seee.g. [43], [32],[7],orthebriefsurveyin[19]).
1.1 Difficulties with MLfor problemsin NRA
There are difficultiesin applying standard ML techniques to problems in NRA. Oneis the lackof sufficiently largedatasets, whichis addressed onlypartially bytheSMT-LIB. Theexperimentin [26] foundthe[QF]NRA sections of the SMT-LIB too uniform, and had to resort to random generated examples (although the state of benchmarking in computer algebra is far worse [22]). There have been improvements since then, with the benchmarks increasing both in number and diversity of underlying application. For example, there are now problemsarising frombiology[4],[23]andeconomics[38],[39].
AnotherdifficultyistheidentificationofsuitablefeaturesfromtheinputwithwhichtotraintheMLmodels. There are some obvious candidates concerning the size and degrees of polynomials, and the distribution of variables. However, this provides a starting set (i.e. before any feature selectiontakes place) that is small in comparison to other machinelearning applications. Themain focusof this paper is tointroduce a method to automatically(andcheaply)generatefurtherfeaturesforMLfrom polynomialsystems.
1.2 Contribution and plan
OurmaincontributionsarethenewfeaturegenerationapproachdescribedinSection3andthevalidationofits use in the experimentsdescribed in Sections 4−5. Theexperiments arefor the choice of variableordering for cylindrical algebraicdecomposition, a topic whosebackground wefirst presentin Section 2, but weemphasise that thetechniquesmay beapplicablemorebroadly.
2
Background
on
variable
ordering
for
CAD
2.1 Cylindrical algebraic decomposition
ACylindrical AlgebraicDecomposition (CAD)isa decomposition oforderedRn spaceintocells arrangedcylin drically: the projections of any pair of cells with respect to the variable ordering are either equal or disjoint. Theprojections form aninducedCAD of thelower dimensional space. Thecells are (semi)-algebraicmeaning eachcanbe describedwithafinitesequenceofpolynomial constraints.
ACAD isproduced tobetruth-invariant foralogicalformula(sotheformulaiseither trueor falseoneach cell). Such adecomposition can thenbe usedtoperformQuantifierElimination(QE) overthereals, i.e. given a quantified Tarski formulafind an equivalent quantifier free formula over the reals. For example, QE would
2
transform ∃x,ax +bx+c = 0∧a =0 to the equivalent unquantified statement b2−4ac ≥0. A CAD over
the(x,a,b,c)-space couldbe usedto ascertain this, solong as thevariable orderingensured that therewasan inducedCAD of (a,b,c)-space. Wetestone sample pointper cellandconstruct a quantifierfree formulafrom therelevantsemi-algebraic celldescriptions.
CADwasintroducedbyCollinsin1975[15]andworksrelativetoasetofpolynomials. Collins’CADproduces a decomposition so that each polynomial has constant sign oneach cell (thustruth-invariant for any formula builtwiththosepolynomials). Thealgorithmfirstprojectsthepolynomialsintosmallerandsmallerdimensions; andthenusestheseto lift−toincrementallybuild decompositionsoflargerand largerspacesaccordingtothe polynomialsat thatlevel. ForfurtherdetailsonCADsee forexamplethecollection[12].
QEhasnumerousapplicationsthroughoutscienceandengineering[42]. Ourworkalsospeedsupindependent applicationsofCAD,suchasreasoningwith multi-valuedfunctions[17] ormotionplanning [45].
2.2 Variable ordering
Thedefinition of cylindricityandboth stagesof thealgorithmare relativeto anordering ofthevariables. For example,givenpolynomialsin variablesorderedasxn>xn−1>. . . ,>x2>x1 wefirstprojectawayxn andso
onuntil we areleft withpolynomials univariatein x1. Wethenstart liftingbydecomposingthex1−axis,and
thenthe(x1, x2)−planeandsosoon. Thecylindricityconditionrefers toprojectionsofcellsinRn ontoaspace
(x1, . . . , xm) where m < n. There have been numerous advances to CAD since itsinception: new projection
schemes [35], [37]; partial construction [16], [44]; symbolic-numeric lifting [41], [29]; adapting to the Boolean structure[5],[20]; andadaptationsforSMT[30],[9]. However,theneedforafixedvariableorderingremains.
Depending onthe application, the variable ordering may be determined, constrained, or free. QE, requires that quantifiedvariables are eliminated first and that variables are eliminated in the order in which theyare quantifiedso there isonly partialfreedom. Thediscriminantin theexamplefrom Section 2.1 couldhave been found withany CAD whicheliminatesx first. A CAD forthequadratic polynomialunder ordering a-b-c
hasonly27cells,but 115arerequiredforthereverseordering.
Sincewecan switchtheorderofquantifiedvariablesin astatement whenthequantifieris thesame,wealso havesomechoiceontheorderingofquantifiedvariables. Forexample,aQEproblemoftheform∃x∃y∀a φ(x,y,a) couldbe solvedbya CAD undereither orderingx>y >aororderingy>x>a. IntheSMTcontextthereis onlyasingleexistentiallyquantifiedblock andsothereisa completelyfreechoiceofordering.
Thechoice of variable orderingcan have a great effect onthe time/ memory useof CAD,andthe number ofcells in theoutput. BrownandDavenportpresenteda classof problemsinwhichone variableordering gave outputofdoubleexponential complexityinthenumberofvariablesandanotheroutputofaconstant size[10].
2.3 Prior work on choosingthe variable ordering
Heuristicshave beendeveloped tochoose a variableordering, withDolzmannet al. [18] giving thebestknown study. Afteranalysingavariety ofmetricstheyproposedaheuristic,sotd,whichconstructsthefullset ofpro jectionpolynomialsforeachpermitted orderingandselectstheorderingwhosecorrespondingsethasthelowest
sumof total degrees for eachof themonomials in each ofthe polynomials. Thesecond author demonstrated examples forwhich thatheuristic couldbe misledin[6]; andthen latershowedthat tailoringto animplemen tationcouldimproveperformance[21]. These heuristicsallinvolvedpotentiallycostlyprojection operationson theinputpolynomials.
In[28]thesecondauthor ofthepresentpapercollaboratedtousea supportvectormachinetochoosewhich of threehuman madeheuristicstobelieve whenpicking thevariableordering, basedonlyonsimplefeaturesof the inputpolynomials. The experimentsidentified substantialsubclasseson whicheachof thethree heuristics madethebestdecision,anddemonstratedthatthemachinelearnedchoicedidsignificantlybetterthananyone heuristicoverall. Thisworkwaspicked upagainin [24]bythepresent authors,where MLwasused to predict directlythevariableorderingforCAD,leadingtotheshortestcomputingtime,withexperimentsconductedfor fourdifferentMLmodels.
Both [28] and [24] used a set of 11 human identified features. These did lead to goodperformance of the models,withMLoutperformingthepriorhumancreatedheuristics,butastartingsetof11featuresisrelatively smallforMLandso wehypothesisethatidentifying morewouldimprovetheresults.
3
Generating
new
features
algorithmically
3.1 Existing features forsets of polynomials
AnearlyheuristicforthechoiceofCADvariableorderingisthatofBrown[8],whichchoosesavariableordering accordingto thefollowingcriteria,startingwiththefirstandbreakingtieswithsuccessive ones.
(1) Eliminatea variablefirstifitappearswiththelowestoveralldegreein theinput.
(2) Foreachvariable calculate themaximum totaldegreefor theset of termsin theinput in whichit occurs. Eliminatefirstthevariableforwhichthis islowest.
(3) Eliminatea variablefirstifthereisa smallernumber oftermsintheinputwhichcontainthevariable. Despitebeing computationallycheaperthan thesotdheuristic (becausethelatterperforms projectionsbefore measuringdegrees)experimentsin[28]suggestedthissimplermeasureactuallyperformsslightlybetter,although
Table1: FeaturesusedbyMLin[28] tochoosetheorderingof3variablesforCAD. # Description In Framework 1 2 3 4 5 6 7 8 9 10 11 Numberofpolynomials
Maximumtotaldegreeofpolynomials
Maximumdegreeofx1among allpolynomials
Maximumdegreeofx2among allpolynomials
Maximumdegreeofx3among allpolynomials
Proportionofx1occurringin polynomials
Proportionofx2occurringin polynomials
Proportionofx3occurringin polynomials
Proportionofx1occurringin monomials
Proportionofx2occurringin monomials
Proportionofx3occurringin monomials
P I dm,p maxm,p ( v v ) dm,p maxm,p 1 dm,p maxm,p 2 dm,p maxm,p 3 I dm,p avp(sgn( m )) I 1 dm,p avp(sgn( m )) I 2 dm,p avp(sgn( m 3 )) avm,p(sgn(dm,p1 )) avm,p (sgn(dm,p2 )) avm,p (sgn(dm,p3 ))
thekeymessagefromthoseexperimentsisthatthereweresubstantialsubsetsofproblemsforwhicheach human-madeheuristicmadeabetter choicethantheothers.
TheBrownheuristicinspiredalmostallthefeaturesusedbytheauthorsof[28],[24]toperformMLforCAD variableordering,with thefullset of11featureslistedinTable1 (column3will beexplainedlater).
3.2 A new frameworkfor generatingpolynomial features
OurnewfeaturegenerationprocedureisbasedontheobservationthatallthemeasurementstakenbytheBrown
heauristic, and allthose features used in [28], [24] can be formalisedmathematically using a small number of functions. Forsimplicity, thefollowingdiscussion willbe restrictedto polynomialsof 3 variablesas these were usedin thefollowing experiments,but everythinggeneralisesin anobvious waytonvariables.
Letaprobleminstance P rbe definedbyaset ofP polynomials
P r={Pp|p= 1, . . . , P}. (1)
This is the typicalinput for producing a sign-invariant CAD.Of course, any problem instance consisting of a logicalformulawhoseatomsarepolynomialsignconditionscan alsohavesuchasetextracted.
Inthefollowingwedefinethenotationforpolynomialvariablesandcoefficientsthatwillbeusedthroughout themanuscript. Eachpolynomialwithindexp,forp= 1, . . . , P containsadifferentnumberofmonomials,which will be labelled with index m, where m= 1, . . . , Mp and Mp denotes thenumber ofmonomials in polynomial p. Wenotethatthese arejustlabels andarenotsetting anorderingthemselves. Thedegrees correspondingto eachofthevariablesx1, x2, x3 area functionofmandp. Theseneedto beexplicitlylabelledin orderto allow
a rigorousdefinition ofourproposedprocedureoffeaturegeneration. Wecannowwrite eachpolynomialas
Mp dm,p dm,p dm,p m,p 1 2 3 = c ·x x x , p= 1,...,P. (2) Pp 1 2 3 m=1
Here,xv representsthepolynomialvariables(v= 1,2,3). Thusforeachmonomialineachpolynomialthereisa
tuple (m,p)ofpositiveintegers that labelit. Thenin turn wedenotebydm,pv thedegreeofvariablexv in that m,p
monomial, and by c theconstant coefficient, i.e., tuple superscripts are giving a label for a monomialin a probleminstance. Theoriginalindicesaresimplyalabelling andnotanorderingofthevariablesx1, x2, x3.
Therefore,anyone ofourprobleminstances P risuniquelyrepresentedbyaset ofsets
m,p,(dm,p
, dm,p, dm,p
SP r= [c 1 2 3 )]|m= 1, . . . , Mp |p= 1, . . . , P . (3)
Observethat eachofBrown’smeasurescannowbeformalisedasa vectoroffeaturesforchoosingavariable.
dm,p
(2) Maximumtotaldegreeofthosetermsintheinputinwhichavariable occurs: )·(dm,p+dm,p+dm,p
sgn(dm,p ).
maxm,p v 1 2 3
I
(3) Numberoftermsin theinputwhichcontainthevariable: sgn(dm,p).
m,p v
Inthelattertwo weusethesignfunctiontodiscriminatebetweenmonomialswhichcontaina variable(signof degree is positive) and those which do not(sign of degree is zero). Of course the sign of the degree is never negative.
Definenow alsotheaveragingfunctions
1 1 1 1
avm , avp , avm,p .
Mp m P p P p Mp m
ThenallthefeaturesinTable1canbeformalisedsimilarlytoBrown’smetrics,asshownin thethirdcolumnof Table1. Wecan placeallofthesescalarsinto asingleframework:
f(P r) = (g4◦g3◦g2◦g1◦hm,p) (P r), (4) where I dm,p )d m,p hm,p(P r)∈ v ,sgn(dm,pv )·( v v) )|v= 1,2,3
andg1, g2, g3,andg4 arealltakenfrom theset
I I I I
maxp,maxm,maxm,p,max0, p, m, m,p, 0,avp,avm,avm,p,av0,sgn,sgn0 .
I
Intheabovesetmax0, 0, av0 andsgn0 areallequal totheidentityfunction.
2 4 2 d1,2 d1,2
For example, let P r = {x1x2−x3, x1x2x3+x1x3}. If m = 1, p = 2, then h1,2(P r) ∈ v ,sgn v ·
I 1,2
)d ) |v= 1,2,3 = 1,1·7,4,4·7,2,2·7 .
v v
3.3 Generating additional features
Wewillthusconsiderderivingalloftheotherfeatureswhichfallintothisframework,buttodosowemustfirst impose anumberofrules.
I
1. Thefunctions g1, g2, g3, g4 must allbelong to distinctcategories of function,i.e. one eachof max, , av,
andsgn.
2. Exactly one ofthe functions g1, g2, g3, g4 is computed overpand exactly one is computedover m(it may
bethesame one).
3. Thecomputationoverpisalwaysperformedbyafunctiongiwithanindexigreaterorequaltothatofthe
functioncomputingoverm.
The expression of f(P r)can be interpreted as follows. Thevalues hm,p(P r) are functions of variables m
andp. Eachofthefunctionsg1, g2, g3, g4 eitherleavethefunctionunchanged,or theyturn itintoa functionof
fewervariables(firstintoa functionofp,andthenintoa scalarvalue,representingtheMLfeature).
The rules above are justified as follows. Rule 1 reduces the redundancy in the feature set. Rules 2 and 3 guarantee that the feature fv (P r) is well defined and is a scalar number. In particular, Rule 3 is necessary
because thecomputation overthe termsin a polynomial isdependent ontheirnumber, whichisnot thesame forallpolynomials.
Thefinal set {f(1)(P r), . . . , f(Nf)(P r)} hassizeN
f =1728fora problemwith 3 variables. Thisnumber is
attainedasfollows: wehave 12possible distributionsofindexestothefunctions g1, . . . , g4 asshownin Table2;
then4!possibleorderingsofthosefunctions;and6possiblechoices forh. So4!·6·12=1728.
However, manyofthese featureswillbe identical(e.g. dueto adifferentplacementoftheidentify function). Wedonotidentifythesemanuallynow: thattaskistrivialforagivendataset,butsubstantialtodoingenerality.
4
Machine
learning
experiment
with
the
new
features
WenowdescribeaMLexperimenttochoosethevariableorderingforcylcindricalalgebraicdecomposition. The methodology here issimilar to that in ourrecent paper [24] exceptfor theaddition ofthe extrafeatures from Section 3. Amoredetailed discussionofthemethodologycan befoundin[24].
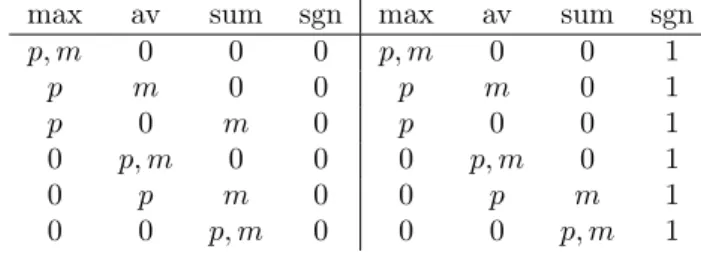
Table2: Possible distributionsofindicestothefunctionclassesin featureframework. max av sum sgn p,m 0 0 0 p m 0 0 p 0 m 0 0 p,m 0 0 0 p m 0 0 0 p,m 0 max av sum sgn p,m 0 0 1 p m 0 1 p 0 0 1 0 p,m 0 1 0 p m 1 0 0 p,m 1 4.1 Problem set
We usethe nlsat dataset1 produced to evaluate theworkin [30], thusthe problems areall fully existentially quantified. Althoughthere areCADalgorithmsthatreduce whatisbeingcomputedbasedonthequantifiersin theinput(most notablyviaPartialCAD [16]),theconclusionsdrawn arelikely tobe applicableoutsideofthe SATcontext. Weusethe6117problemswith3variablesfromthisdatabase,soeachhasachoiceofsixdifferent variable orderings. We extracted only the polynomials involved, and randomly divided into two datasets for training(4612)andtesting(1505). OnlytheformerwasusedtotunetheparametersoftheMLmodels.
4.2 Software
WeusedtheCAD routine CylindricalAlgebraicDecomposewhichispartoftheRegularChainsLibraryfor
Maple. Thisalgorithmbuildsdecompositionsfirstofn-dimensionalcomplexspacebeforerefiningtoaCADof
Rn [14], [13], [3]. We ranthecode in Maple2018 but used anupdatedversion ofthe RegularChainsLibrary
(http://www.regularchains.org). Trainingand evaluationof theMLmodels wasdoneusing thescikit-learn
package[40]v0.20.2forPython2.7. ThefeaturesforMLwereextractedusingcodewritteninthesympypackage v1.3for Python2.7,as wastheBrownheuristic. Thesotdheuristicwasimplemented inMaple as partofthe
ProjectionCADpackage[25].
4.3 Timings
CAD constructionwastimed inaMaple scriptthat wascalledseparatelyfrom PythonforeachCAD (toavoid Maple’s caching of results). The target variable ordering for ML was defined as the one that minimises the computingtimefora givenproblem. AllCAD functioncalls includedatime limit. Forthetrainingdatasetan initial timelimitof4 secondswasused,doubled incrementallyifallorderingstimed out,untilCAD completed foratleastoneordering(atargetvariableorderingcouldbeassignedforallproblemsusingtimelimitsnobigger than64seconds). Theproblemsinthetestingdatasetwereprocessedwithalargertimelimitof128secondsfor allorderings(timeoutset as128s).
4.4 Feature simplification
When computedon a set of problems {P r1, . . . ,P rN}, some of thefeatures f(i) turn outto be constant, i.e. f(i)(P r
1) =f(i)(P r2) =· · ·=f(i)(P rN).Suchfeatureswillhave nobenefitforMLandareremoved. Further,
other features may be repetitive, i.e. f(i)(P r
n) = f(j)(P rn),∀n = 1,...,N. This repetition may represent a
mathematicalequality,orjustbethecaseofthegivendataset. Eitherway,theyaremergedintoasinglefeature fortheexperiment. Afterthesesteps,weareleftwith78featuresforourdataset: sowhilealargemajoritywere redundant,westillhave seventimesthoseavailablein [28],[24].
4.5 Feature selection
Featureselectionwasperformed withthetrainingdataset toseeifanyfeatureswereredundantfortheML.We chosetheAnalysisofVariance(ANOVA)F-valuetodeterminetheimportanceofeachfeaturefortheclassification task. Otherchoices weconsidered wereunsuitableforourproblem,e.g. themutualinformationbasedselection requires very largeamounts of data. Each problem is assigned a target ordering, or class c = 1, . . . , C, where
C=6. LetP rc,n denoteproblemnumbernfromthetrainingdatasetthatisassignedclassnumberc,c= 1, . . . , C
IC
andn= 1, . . . , Nc,whereNc denotesthenumber ofproblemsthatareassignedclassc.Thus c=1Nc=N.
TheF-valueforfeaturenumber iiscomputedasfollows[36].
2 1 IC N ¯(i) f¯(i) c fc − C−1 c=1 Fi= 2, (5) 1 IC INc f(i)(P r ¯(i) c,n)−fc N−C c=1 n=1 ¯ ¯ wherefc (i)
isthesamplemeanin classc,andf(i)theoverallmeanofthedata:
Nc C Nc f¯(i)= 1 f(i)(P rc,n), f¯(i)= 1 f(i)(P rc,n). c Ncn=1 N c=1n=1
The numerator in (5) represents the between-class variability or explained variance and the denominator the
within-class variability orunexplained variance. ThethreefeatureswiththehighestF-values were:
I 1 I 1 I
f65 (P r)=max0 avm,p 0sign(dm,p2 )=P p Mp msign(dm,p2 ),
I I v)d m,p f46 (P r)=max0 avmsign(d m,p )·( ) ) p 2 v I 1 I I )d m,p = p M sign(dm,p)·( ), p m 2 v v) I I )d m,p f76(P r)=av0 maxmsign(d m,p )·( ) p 2 v v) I I v)d m,p = maxmsign(d m,p )·( ) ). p 2 v
The new features may be translated back into natural language. For example, feature 65 is the proportion of monomials containing variable x2, averaged across all polynomials; feature 46 the sum of the degrees of
the variables in all monomials containing variable x2, averaged across all monomials and summed across all
polynomials; and feature 76 the maximum sum of the degrees of the variables in all monomials containing variablex2,summedacrossallpolynomials.
Featureselectiondidnotsuggesttoremoveanyfeatures(theyallcontributedmeaningfulinformation),sowe proceedwithourexperimentusingall78.
4.6 ML models
Four ofthe mostcommonlyused deterministicMLmodels weretuned onthe trainingdata(fordetails onthe methodssee e.g. thetextbook [2]). Wealsogiveanoverview ofeachin [24].
• TheK−NearestNeighbours(KNN)classifier[2,§2.5].
• TheMulti-LayerPerceptron (MLP)classifier[2,§2.5].
• TheDecisionTree(DT)classifier[2,§14.4].
• TheSupportVectorMachine(SVM)classifierwithRBF kernel[2,§6.3].
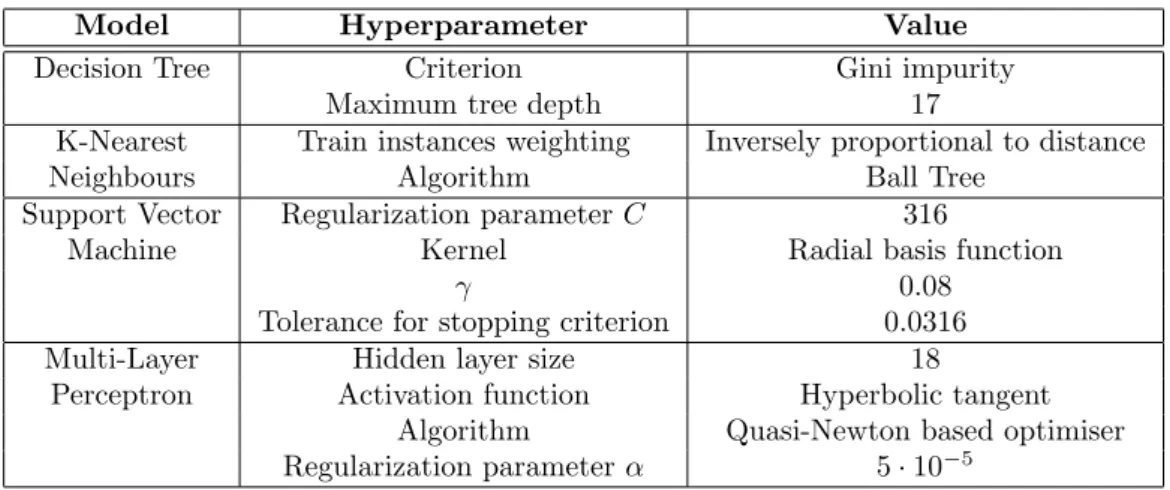
Eachmodelwastrainedusinggridsearch5-foldcross-validation,i.e. thesetwasrandomlydividedinto5and each possible combination of 4 parts was used to tune the model parameters, leaving the last part for fitting thehyperparameterswithcross-validation,byoptimisingtheaverageF-score. Gridsearcheswereperformedfor an initially large rangefor each hyperparameter; then gradually decreased to home into optimal values. This lastedfromafewsecondsforsimplermodelslikeKNNtoafewminutesformorecomplexmodelslikeMLP.The optimalhyperparametersselectedduringcross-validationarein Table3.
4.7 Comparing with human made heuristics
TheMLapproacheswerecomparedintermsofpredictionaccuracyandresultingCADcomputingtimeagainst thetwo bestknown humanconstructedheuristicsBrown [8]andsotd [18]as discussedearlier. UnliketheML, these can end uppredictingseveralvariable orderings(i.e. whentheycannot discriminate). Inpracticeifthis weretohappentheheuristicwouldselectonerandomly(orperhapslexicographically),howeverthatfinalpickis notmeaningful. Toaccommodatethis,foreachproblem,thepredictionaccuracyofsuchaheuristicisjudgedto bethepercentageofitspredictedvariableorderingsthatarealsotargetorderings. Theaverageofthispercentage over all problems in the testing dataset represents theprediction accuracy. Similarly, thecomputing time for such methods was assessed as the average computing time over all predicted orderings, and it is this that is summedupforallproblemsin thetestingdataset.
Table3: TheMLhyperparameters usedfollowingoptimisationonthetrainingdataset.
Model Hyperparameter Value
DecisionTree Criterion Maximumtreedepth
Giniimpurity 17 K-Nearest
Neighbours
Train instancesweighting Algorithm
Inverselyproportionalto distance BallTree SupportVector Machine RegularizationparameterC Kernel γ
Toleranceforstoppingcriterion
316
Radialbasisfunction 0.08
0.0316 Multi-Layer
Perceptron
Hiddenlayersize Activationfunction
Algorithm
Regularizationparameterα
18
Hyperbolictangent Quasi-Newtonbasedoptimiser
5·10−5
5
Experimental
Results
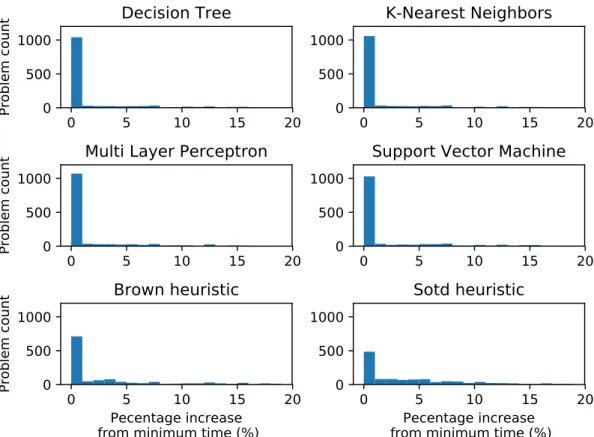
TheresultsarepresentedinTable4. WecomparethefourMLmodelsonaccuracy,definedasthepercentageof problemswheretheyselectedtheoptimumordering,andalsothetotalcomputationtime(inseconds)forsolving all theproblems with theirchosen orderings. Thefirst two rowsof the toptable reproduce the resultsof [24] whichusedonlythe11featuresfromTable1,whilethelattertworowsaretheresultsfromthenewexperiment inthepresentpaperwhichhas78features. Wealsocomparewiththetwohumanconstructedheuristicsandthe outcome ofa randomchoice between the6 orderings (whichdo notchange with the number offeatures). We mightexpectarandomchoicetobecorrectonesixthofthetimebutitishigherasforsomeproblemstherewere multiplevariableorderingswithequallyfasttimings. Thedistributionofthecomputationtimes: thedifferences betweenthecomputationtimeofeachmethodandtheminimumcomputationtime,givenasapercentageofthe minimumtime,aredepictedinFigure 1.
5.1 Range of possible outcomes
Theminimumtotalcomputingtime,achieved ifweselectanoptimalorderingforeveryproblem, is8623s (the virtualbestheuristic). Choosingatrandomwouldtake30235s, almost4timesasmuch. Themaximumtime,if weselectedtheworstorderingforeveryproblem,is64534s. TheK-NearestNeighboursmodel(with78features) achievedtheshortesttimeofourmodels andheuristics,with9178s,only6%morethantheminimalpossible.
Table4: Thetoptablecomparesperformanceofthemachinelearningclassifiers(DT,KNN,MLP,SVM)withthe originalsetoffeaturesaspublishedin[24]andtheextendedsetdevelopedinthepresentpaper. Forcomparison, thebottomtableshowsthebestandworstpossiblechoices,alongwiththeresultsofarandomchoiceandthose oftwohuman-made heuristics(Brownandsotd).
DT KNN MLP SVM From[24] (11Features) Accuracy Time(s) 62.6% 9994 63.3% 10105 61.6% 9822 58.8% 10725 NewExperiment (78Features) Accuracy Time(s) 65.2% 9603 66.3% 9178 67% 9399 65% 9487
VirtualBestHeuristic VirtualWorstHeuristic random Brown sotd Accuracy Time (s) 100% 8623 0% 64534 22.7% 30235 51% 10951 49.5% 11938
0
5
10
15
20
0
500
1000
Problem count
Decision Tree
0
5
10
15
20
0
500
1000
K-Nearest Neighbors
0
5
10
15
20
0
500
1000
Problem count
Multi Layer Perceptron
0
5
10
15
20
0
500
1000
Support Vector Machine
0
5
10
15
20
Pecentage increase
from minimum time (%)
0
500
1000
Problem count
Brown heuristic
0
5
10
15
20
Pecentage increase
from minimum time (%)
0
500
1000
Sotd heuristic
Figure1: Thehistogramsofthepercentageincreasein computationtimerelativetotheminimumcomputation timeforeachmethod,calculatedforabinsizeof1%.
5.2 Human-made heuristics
Sincetheyarenotaffectedbythenewfeatureframeworkofthepresentpaperthefindingsonthehumanmade heuristicsarethesameasin[24]. Ofthetwohuman-madeheuristics,Brownperformedthebest,surprisingsince thesotdheuristichasaccesstoadditionalinformation(notjusttheinputpolynomialsbutalsotheirprojections). Obtaininganorderingfora probleminstancewithsotdhencetakeslongerthanforBrownoranyMLmodel −
generating anorderingwithsotd forallproblems inthetesting datasettook over30min. Using Brownwe can solveallproblemsin 10,951s,27%more thantheminimum. Whilesotd isonly0.7%lessaccuratethanBrown
in identifying thebestordering, itis muchslowerat 11938s or 38%more thantheminimum. So, whileBrown
isnotmuchbetteratidentifying thebest, itismuchbetter atdiscardingtheworst!
5.3 ML choices
The resultsshowthat all MLapproaches outperformthe human constructedheuristicsin terms ofboth accu racy and timings. Moreover, the results show that the new algorithm for generating features leads to a clear improvementin ML performancecompared tousing onlya small number of human generatedfeatures in [24]. Forallfourmodulesbothaccuracyhasincreasedandcomputationtimedecreased. Thebestachieved timewas 14% abovetheminimumusing theoriginal11featuresbut nowonly6%abovewiththenewfeatures.
Thecomputingtimeforallthemethodsliesbetweenthebest(8623s)andtheworst (64534s). Therefore,if we scale this timeto [0,100]so that theshortest time correspondsto 0 and theslowest to 100, then thebest human-madeheuristic(Brown)liesat4.16,andthebestMLmethod(KNN)liesat0.99. SousingMLallowsus tobe 4timesclosertotheminimumpossiblecomputingtime.
Figure 1 showsthat thehuman-madeheuristicsresultin computing timesthat areoftensignificantly larger than1%ofthecorrespondingminimumtimeforeachproblem. TheMLmethods,ontheotherhand,allresult in over1000problems (∼75%of thetestingdataset) within1%oftheminimumtime.
6
Final
Thoughts
In thisexperiment theMLP and KNN models offeredthebest performance, and a clearadvance onthe prior stateoftheart. Butweacknowledgethatthereismuchmoretodoandemphasisethattheseareonlytheinitial findingsoftheprojectandweneedto seeifthefindingsarereplicated. Planned extensionsinclude: expanding thedatasettoproblemswithmorevariablesandquantifierstructure;tryingdifferentfeatureselectiontechniques, andseeingifclassifierstrainedfortheMapleCAD maybeapplied tootherimplementations.
Our main result is that a great many more features can be obtained triviallyfrom the input (i.e. without any projectionoperations)thanpreviouslythought, andthatthese arerelevantandleadtobetter MLchoices. Someof these areeasyto expressin natural language, suchas thenumber ofpolynomialscontaininga certain variable,butothersdonothaveanobviousinterpretation. Thisisimportantbecausesomethingthatishardto describeinnaturallanguageisunlikelytobesuggestedbya humanasafeature,whichillustratesthebenefitof ourframework. Thiscontributiontofeatureextractionforalgebraicproblemsshouldbemorewidelyapplicable thantheCADvariableorderingdecision.
Acknowledgements
This work is supported by EPSRC Project EP/R019622/1: Embedding Machine Learning within Quantifier Elimination Procedures.
References
´
[1] Abrah´am, E., Abbott, J., Becker,B., Bigatti, A.,Brain,M., Buchberger, B.,Cimatti, A.,Davenport, J., England,M.,Fontaine, P.,Forrest, S.,Griggio, A.,Kroening, D.,Seiler,W.,Sturm,T.: SC2: Satisfiability checkingmeets symboliccomputation. In: Proc.CICM’16,LNCS9791, pp.28–43.Springer(2016),
https://doi.org/10.1007/978-3-319-42547-43
[2] Bishop,C.: PatternRecognition andMachineLearning.Springer(2006)
[3] Bradford,R.,Chen, C.,Davenport, J.,England, M.,Moreno Maza, M.,Wilson, D.: Truthtableinvariant cylindricalalgebraicdecompositionbyregularchains.In: Proc.CASC’14,LNCS8660,pp.44–58.Springer (2014),http://dx.doi.org/10.1007/978-3-319-10515-44
[4] Bradford, R., Davenport, J., England, M., Errami, H., Gerdt, V., Grigoriev, D., Hoyt, C., Koˇsta, M., Radulescu,O.,Sturm,T.,Weber,A.: Acasestudyontheparametricoccurrenceofmultiplesteadystates. In: Proc.ISSAC’17,pp.45–52.ACM(2017),https://doi.org/10.1145/3087604.3087622
[5] Bradford, R., Davenport, J., England, M., McCallum, S., Wilson, D.: Truth table invariant cylindrical algebraicdecomposition.J.Symb.Comp.76,1–35(2016),http://dx.doi.org/10.1016/j.jsc.2015.11.002
[6] Bradford, R., Davenport, J., England, M., Wilson, D.: Optimising problem formulations for cylindrical algebraic decomposition. In: Intelligent Computer Mathematics, LNCS 7961, pp. 19–34. Springer Berlin Heidelberg(2013),http://dx.doi.org/10.1007/978-3-642-39320-4 2
[7] Bridge,J.,Holden,S.,Paulson,L.: Machinelearningforfirst-ordertheoremproving.JournalofAutomated Reasoning53,141–172(2014),https://doi.org/10.1007/s10817-014-9301-5
[8] Brown,C.: Tutorial: Cylindricalalgebraicdecomposition,atISSAC’04, (2004), http://www.usna.edu/Users/cs/wcbrown/research/ISSAC04/handout.pdf
[9] Brown,C.: Constructing a singleopen cellin a cylindricalalgebraic decomposition.In: Proc.ISSAC’13, pp.133–140.ACM(2013),https://doi.org/10.1145/2465506.2465952
[10] Brown,C.,Davenport,J.: Thecomplexityofquantifiereliminationandcylindricalalgebraicdecomposition. In: Proc.ISSAC’07,pp.54–60.ACM(2007),https://doi.org/10.1145/1277548.1277557
[11] Carette,J.: Understandingexpressionsimplification.In: Proc.ISSAC’04,pp.72–79.ACM (2004), https://doi.org/10.1145/1005285.1005298
[12] Caviness,B.,Johnson,J.: QuantifierEliminationandCylindricalAlgebraicDecomposition.Texts&Mono graphsin SymbolicComputation,Springer-Verlag (1998),https://doi.org/10.1007/978-3-7091-9459-1
[13] Chen,C.,MorenoMaza,M.: Anincrementalalgorithmforcomputingcylindricalalgebraicdecompositions. In: ComputerMathematics,pp.199—221.SpringerBerlinHeidelberg(2014),
https://doi.org/10.1007/978-3-662-43799-517
[14] Chen,C.,MorenoMaza,M.,Xia,B.,Yang,L.:Computingcylindricalalgebraicdecompositionviatriangular decomposition.In: Proc.ISSAC’09,95–102.ACM (2009),https://doi.org/10.1145/1576702.1576718
[15] Collins, G.: Quantifier elimination for real closed fields bycylindrical algebraic decomposition. In: Proc. 2ndGIConferenceonAutomataTheoryandFormalLanguages.pp.134–183.Springer-Verlag(reprintedin thecollection[12])(1975),https://doi.org/10.1007/3-540-07407-417
[16] Collins, G., Hong, H.: Partial cylindrical algebraic decomposition for quantifier elimination. Journal of SymbolicComputation 12,299–328(1991),https://doi.org/10.1016/S0747-7171(08)80152-6
[17] Davenport, J., Bradford, R., England, M., Wilson, D.: Program verification in the presence of complex numbers,functions withbranchcutsetc.In: Proc.SYNASC’12, pp.83–88.IEEE(2012),
http://dx.doi.org/10.1109/SYNASC.2012.68
[18] Dolzmann,A.,Seidl,A.,Sturm,T.: EfficientprojectionordersforCAD.In: Proc.ISSAC’04,pp.111–118. ACM(2004),https://doi.org/10.1145/1005285.1005303
[19] England, M.: Machine learning formathematical software.In: Mathematical Software – Proc.ICMS ’18. LNCS10931,pp.165–174.Springer(2018),https://doi.org/10.1007/978-3-319-96418-820
[20] England, M.,Bradford,R., Davenport,J.: Improving theuseofequationalconstraints incylindricalalge braicdecomposition.In: Proc.ISSAC’15,pp.165–172.ACM(2015),
http://dx.doi.org/10.1145/2755996.2756678
[21] England,M.,Bradford,R.,Davenport,J.,Wilson,D.: Choosingavariableorderingfortruth-tableinvariant CAD by incremental triangular decomposition. In: Proc. ICMS ’14, LNCS 8592, pp. 450–457. Springer (2014),http://dx.doi.org/10.1007/978-3-662-44199-268
[22] England, M.,Davenport,J.: Experiencewithheuristics,benchmarks&standards forcylindricalalgebraic decomposition.In: Proc.SC2’16.CEUR-WS1804 (2016),http://ceur-ws.org/Vol-1804/
[23] England, M., Errami, H., Grigoriev, D., Radulescu, O., Sturm, T., Weber, A.: Symbolic versus nu merical computation and visualization of parameter regions for multistationarity of biological networks. In: Computer Algebra in Scientific Computing (CASC ’17), LNCS 10490, pp. 93–108. Springer (2017),
https://doi.org/10.1007/978-3-319-66320-38
[24] England, M., Florescu, D.: Comparing machine learning models to choose the variable ordering for cylindrical algebraic decomposition. To appear in Proc. CICM ’19 (Springer LNCS) (2019). Preprint: https://arxiv.org/abs/1904.11061
[25] England,M.,Wilson,D.,Bradford,R.,Davenport,J.: UsingtheRegularChainsLibrarytobuildcylindrical algebraicdecompositionsbyprojectingandlifting.In: MathematicalSoftware–ICMS’14.LNCS8592,pp. 458–465.Springer(2014),http://dx.doi.org/10.1007/978-3-662-44199-269
[26] Huang,Z.,England,M.,Davenport,J.,Paulson,L.: Usingmachinelearningtodecidewhentoprecondition cylindricalalgebraicdecomposition withGroebner bases.In: Proc.SYNASC’16. pp.45–52.IEEE (2016), https://doi.org/10.1109/SYNASC.2016.020
[27] Huang, Z., England, M., Wilson, D., Bridge, J., Davenport, J., Paulson, L.: Using machine learning to improvecylindricalalgebraicdecomposition.MathematicsinComputerScience,Volumetobeassigned,28 pages(2019),https://doi.org/10.1007/s11786-019-00394-8
[28] Huang,Z., England,M., Wilson,D.,Davenport,J., Paulson,L.,Bridge, J.: Applyingmachinelearning to theproblem ofchoosing a heuristicto selectthevariable orderingfor cylindricalalgebraic decomposition. In: IntelligentComputerMathematics,LNAI 8543,pp.92–107.SpringerInternational(2014),
[29] Iwane,H.,Yanami,H.,Anai,H.,Yokoyama,K.: Aneffectiveimplementationof asymbolic-numericcylin drical algebraic decomposition for quantifier elimination. In: Proc. SNC ’09, pp. 55–64. SNC ’09 (2009), https://doi.org/10.1145/1577190.1577203
[30] Jovanovic, D.,deMoura,L.: Solvingnon-lineararithmetic.In: Gramlich, B.,Miller, D.,Sattler,U. (eds.) AutomatedReasoning−Proc.IJCAR’12, LNCS7364,pp.339–354.Springer(2012),
https://doi.org/10.1007/978-3-642-31365-327
[31] Kobayashi,M.,Iwane,H.,Matsuzaki,T.,Anai,H.: Efficientsubformulaordersforrealquantifierelimination ofnon-prenexformulas.In: Proc.MACIS’15,LNCS9582, pp.236–251. SpringerInternationalPublishing (2016),https://doi.org/10.1007/978-3-319-32859-121
[32] K¨uhlwein, D., Blanchette, J., Kaliszyk, C., Urban, J.: MaSh: Machine learning for sledgehammer. In: InteractiveTheoremProving,LNCS7998,pp.35–50.SpringerBerlinHeidelberg(2013),
https://doi.org/10.1007/978-3-642-39634-26
[33] Kuipers,J., Ueda,T., andVermaseren,J.A.M.: Codeoptimizationin FORM.ComputerPhysicsCommu nications,189,1–19(2015),https://doi.org/10.1016/j.cpc.2014.08.008
[34] Liang, J., Hari Govind, V., Poupart, P., Czarnecki, K., Ganesh, V.: An empirical study of branching heuristicsthroughthelensof globallearning rate.In: Proc.SAT ’17,LNCS10491,pp.119–135. Springer (2017),https://doi.org/10.1007/978-3-319-66263-38
[35] McCallum, S.: An improved projection operation for cylindrical algebraic decomposition. In: [12], pp. 242–268.(1998),https://doi.org/10.1007/978-3-7091-9459-112
[36] Markowski, C.A. and Markowski, E.P.: Conditions for theeffectiveness of a preliminary test of variance. TheAmericanStatistician,44:4,322–326 (1990)
[37] McCallum, S., Parusi´niski, A., Paunescu, L.: Validity proof of Lazard’s method for CAD construction. JournalofSymbolicComputation 92,52–69(2019),https://doi.org/10.1016/j.jsc.2017.12.002
[38] Mulligan,C.,Bradford,R.,Davenport,J.,England, M.,Tonks,Z.: Non-linearrealarithmeticbenchmarks derived from automated reasoning in economics. In: Proc. SC2 ’18, pp. 48–60. CEUR-WS 2189 (2018), http://ceur-ws.org/Vol-2189/
[39] Mulligan,C.,Davenport,J., England,M.: TheoryGuru: A Mathematicapackagetoapplyquantifier elim inationtechnologytoeconomics.In: MathematicalSoftware– Proc.ICMS’18.LNCS10931,pp.369–378. Springer(2018),https://doi.org/10.1007/978-3-319-96418-844
[40] Pedregosa,F.,Varoquaux,G.,Gramfort,A.,Michel, V.,Thirion,B.,Grisel,O.,Blondel,M.,Prettenhofer, P.,Weiss,R.,Dubourg,V.,Vanderplas,J.,Passos,A.,Cournapeau,D.,Brucher,M.,Perrot,M.,Duchesnay, E.: Scikit-learn: MachinelearninginPython.JournalofMachineLearningResearch12,2825–2830(2011), http://www.jmlr.org/papers/v12/pedregosa11a.html
[41] Strzebo´nski, A.: Cylindricalalgebraic decomposition using validated numerics.Journal of Symbolic Com putation41(9),1021–1038(2006),https://doi.org/10.1016/j.jsc.2006.06.004
[42] Sturm,T.: Newdomainsforappliedquantifierelimination.In: ComputerAlgebrainScientificComputing, LNCS4194,pp.295–301. Springer(2006),https://doi.org/10.1007/11870814 25
[43] Urban, J.: MaLARea: A metasystem for automated reasoningin large theories. In: Proc. ESARLT ’07, CEUR-WS257, p.14.CEUR-WS(2007),http://ceur-ws.org/Vol-257/
[44] Wilson, D., Bradford,R., Davenport, J., England, M.: Cylindrical algebraic sub-decompositions. Mathe maticsin ComputerScience 8,263–288 (2014),http://dx.doi.org/10.1007/s11786-014-0191-z
[45] Wilson, D.,Davenport,J.,England, M.,Bradford,R.: A“pianomovers” problemreformulated.In: Proc. SYNASC’13,pp.53–60.IEEE(2013),http://dx.doi.org/10.1109/SYNASC.2013.14
[46] Xu,L.,Hutter,F.,Hoos,H.,Leyton-Brown,K.: SATzilla: Portfolio-basedalgorithm selectionforSAT.J. ArtificialIntelligenceResearch 32,565–606(2008),https://doi.org/10.1613/jair.2490
![Table 1: Features used by ML in [28] to choose the ordering of 3 variables for CAD. # Description In Framework 1 2 3 4 5 6 7 8 9 10 11 Number of polynomials](https://thumb-us.123doks.com/thumbv2/123dok_us/10896289.2978679/5.892.163.761.123.382/table-features-ordering-variables-description-framework-number-polynomials.webp)