International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 9, Issue 10, October 2019)
64
Real Time Sentiment Classification of Tweets using Linear
(LDA) & Nonlinear (Cart and KNN) Algorithms
Kshama Singh
1, Sitaram Patel
2, Dr. Rachana Dubey
31M.Tech Scholar, 2Assistant Professor, 3Head Of Department, Department of Computer Science & Engineering, LNCTE, Bhopal, India
Abstract – In the past few years, there has been a large growth within the use of microblogging platforms like Twitter. Spurred by that growth, corporations and media organizations are more and more seeking ways in which to mine Twitter for information regarding what individuals suppose and feel regarding their merchandise and services. So it is very important to create a method which classifies the web data. Sentiment analysis is a method to classify the web data such as product reviews, views in to various polarities such a positive, negative or neutral. In this paper we can build a classifiers based on linear and non linear techniques. We can use linear algorithm as LDA (Linear Discriminant Analysis) and nonlinear KNN (K Nearest Neighbour) and CART (Classification and Regression Tree) algorithm for classifying the tweets text into various polarity and based on thier classify performance we can pick the best algorithm for real time sentiment classification.
Keywords—Sentiment analysis, text mining, opinion mining, R, LDA, KNN, CART, Decision tree, classification.
I. INTRODUCTION
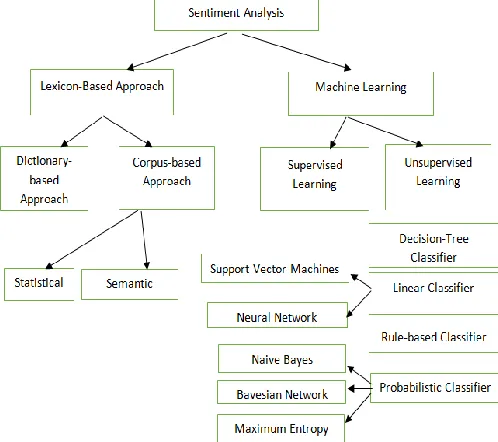
Sentiment Classification techniques are roughly divided into Lexicon primarily based approach, Machine Learning approach and hybrid approach. The Machine Learning Approach (ML) applies the renowned metric capacity unit algorithms and it uses linguistic options. The Lexicon-based Approach depends on a sentiment lexicon. Lexicon could be a assortment of illustrious and precompiled sentiment terms. It’s once more divided into dictionary-based approach and corpus primarily dictionary-based approach that use linguistics or applied math strategies to seek out sentiment polarity of the text.
[image:1.612.326.575.234.455.2]Figure 1. Machine Learning Approaches
II. MACHINE LEARNING APPROACH
In Machine learning we can create a model and these models can classify the reviews based on there learning techniques. In these we can train the model onto two ways
1. Unsupervised learning:
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 9, Issue 10, October 2019)
65
2. Supervised learning:In these we can select the labels and there is a supervisor who guides the model and selection in label though which they can get the desired output. In these we can divide the process into two phases:
1. Training Set 2. Test Set.
A various number of machine learning techniques are developed to classify the tweets into categories. The Machine learning techniques like Naive Bayes (NB), most entropy (ME), and support vector machines (SVM) have achieved nice success in sentiment analysis.
In these a machine learning first pre-process the dataset based on the algorithm which is using in supervised learning and after that we can trained the model by giving training dataset and the model is start learning and after the learning of the model is completed we can test the model performance on test dataset and then we can compute the various performance measures like accuracy, f1 score.
R
R could be a standard artificial language that is usually embraced by data researchers. In any case, traditional R should be dead during a solitary machine atmosphere. because the volume of accessible data income to quickly develop from an assortment of sources, versatile and execution investigation arrangements have was a basic device to upgrade business gain and financial gain. Existing data examination things, for instance, R, square measure compelled by the span of the elemental memory and cannot scale in various applications. data illustration is popping into an undeniably imperative a part of fact-finding within the time of big data . The steps needed for analyzing knowledge are:
the requirement for Meeting speed
Understanding the assorted varieties of knowledge Addressing the info quality
show the right perceivable results
The R atmosphere provides monumental inherent functions within the package “base”, most of that square measure usually needed for elementary knowledge analysis (e.g., linear modeling, graph plotting, basic statistics). However, the important great thing about R is its nearly skillfulness and infinite expandability. roughly a pair of,500 packages are developed for R by the active R community. [2]These bundles serve to enlarge R's regular talents in data examination and regularly consider enhancements in several scientific fields, and to boot systems utilised as a neighborhood of terribly specific data investigations.
III. LITERATURE REVIEW
According to (Rachana Bandana et al., 2018) [1], Applying sentiment analysis on Twitter is that the forthcoming trend with researchers recognizing the scientific trials and its potential applications. The challenges distinctive to the present downside space square measure mostly attributed to the dominantly informal tone of the small blogging. Pak and Paroubek [5] explanation the employment microblogging and additional significantly Twitter as a corpus for sentiment analysis. They cited:
Microblogging platforms are employed by different folks to precise their opinion concerning different topics, therefore it's a valuable supply of people’s opinions.
Twitter contains a colossal variety of text posts and it grows daily. The collected corpus is randomly giant.
Twitter’s audience varies from regular users to celebrities, company representatives, politicians, and even country presidents. Therefore, it's doable to gather text posts of users from totally different social and interests teams. Twitter’s audience is described by users from several countries.
According to (Paramita Ray et al., 2017) [2], Opinions square measure basic to each single human activity since they're key influencers of our practices. At no matter purpose we've got to decide on a alternative, we want to understand others' thoughts. In reality, organizations and associations faithfully ought to discover users’ standard sentiments concerning their things and services. shoppers use differing kinds of on-line platforms for social engagement together with web-based social networking sites; for instance, Facebook and Twitter. Through these webbased social networks, client engagement happens increasingly. this sort of association offers a motivating open door for advertising information. people of each position, sexual orientation, race and sophistication utilize the net to share encounters and impressions concerning just about each feature of their lives. aside from composing messages, blogging or feat remarks on company sites, an excellent several people utilize informal organization destinations to log opinions, express emotion and uncover insights concerning their everyday lives. people compose correspondence on nearly something, together with films, brands, or social exercises. These logs flow into throughout on-line teams and square measure virtual gatherings wherever shoppers illuminate and impact others.
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 9, Issue 10, October 2019)
66
In summary, we have a tendency to reviewed various papers that highlighted the positive impact of lexical options. every system used their own methodology to represent these lexical options within the feature vector. we have a tendency to noted that the majority papers combined these lexical options into one score that was additional as a price within the feature vector. There wasn’t enough work that explored the concept of changing this lexical analysis into various options that captures the freelance nature of lexical options and let the classification algorithmic program deduce the link between these options victimization the coaching knowledge. we have a tendency to explored this promising space of lexical options in depth through this analysis. Also, in contrast to analysis done earlier, this work uses a really conservative approach in adding options to the system.IV. PROBLEM DEFINITION
The existence and therefore the constructive stability of the trade and business depend on establishing a competitive dominance through effective and aggressive selling ways. With the prolific quantity of data that's unceasingly being created offered through the electronic media, the online users are unable to require advantage of those resources because of the shortage of acceptable tools to utilize. And many increases within the variety of internet sites puts forward a difficult task to arrange the contents of the websites to cater to the wants of the users.
V. PROPOSED WORK
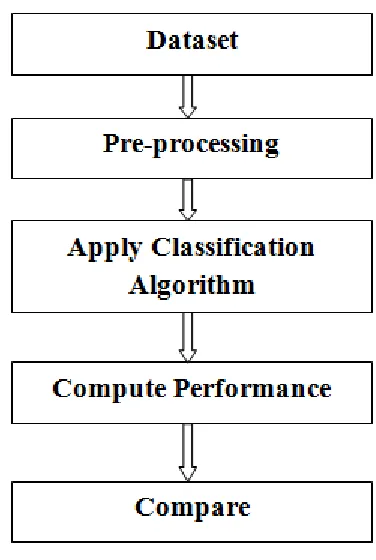
[image:3.612.348.536.133.413.2]In this paper we presents a linear algorithm (LDA) and nonlinear algorithm such as KNN and CART for classify the tweets text into positive and negative category. For which we can build the machine learning classifier model based on these algorithm and the proposed flow diagram are shown below.
Figure 2. Proposed Flow Diagram
Analysis steps are:
Step-1. We can collect the collection of tweets along with its polarity values.
Step-2. Once the data is loaded we cannot apply machine learning algorithm to the data because the raw data need to processed before apply the algorithm. In these pre-processing steps we performance various text mining functions to clean and transform the text.
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 9, Issue 10, October 2019)
67
Step-4. When the models is trained on training data we can test the performance of the model on testing datasets and compute the accuracy of the model.Step-5. On the basis of performance measure of these model we can pick the best algorithm for real time classification of the tweets.
VI. EXPERIMENTAL &RESULT ANALYSIS
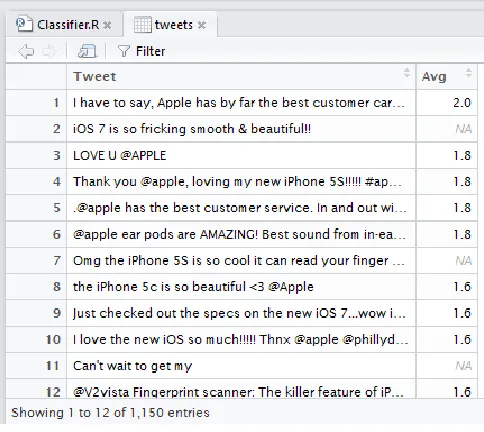
[image:4.612.49.291.324.540.2]The experimental result analysis are perform on windows machine on which the r-base are installed and rstudio which is an IDE of R are also installed. Once the experimental setup is ready we can load the tweets dataset into the R which consist of two attribute one is stored a tweet text and another one is stored a polarity of that tweets which is shown in figure 3.
Figure 3. Load the data
In figure 3 the dataset description is present which indicates their are collection of 1181 tweets along with its polarity. On the data has been loaded we can apply various text mining functions to the dataset for cleaning and transforming the data. For cleaning we can remove the numbers, punctuations and extra special characters from the text and for transforming the data we convert the text into lower case and perform stemming operation on it. All the text mining functions are shown in figure 4 which shows the text of tweets before and after pre-processing.
Figure 4. Pre-processing the data
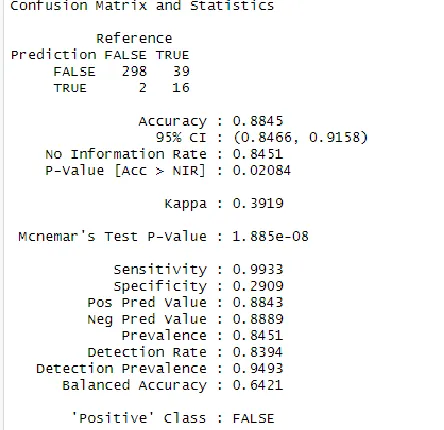
Once the pre-processing of the data is finished we splits the dataset into trainsparse (training data) and testsparse (testing data) and gives the trainsparse data to the machine learning algorithm for training and building a model. . When the models is trained on training data we can test the performance of the model on testing datasets and compute the accuracy of the model. Figure 5 shows the training of these models and then we test these models on testing datasets and measure the performance, figure 6 shows performance measure of LDA algorithm, Figure 7 shows performance of CART algorithm and Figure 8 shows performance measure of KNN algorithm.
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 9, Issue 10, October 2019)
[image:5.612.325.547.174.389.2]68
Figure 6. Performance measure of LDA AlgorithmFigure 7. Performance measure of CART Algorithm
[image:5.612.326.541.428.678.2]International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 9, Issue 10, October 2019)
69
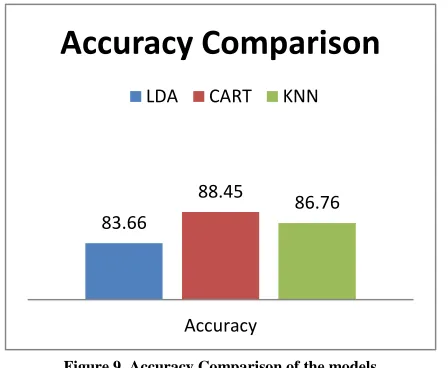
On the basis of performance measure of these model we can pick the best algorithm for real time classification of the tweets. Figure 9 shows the accuracy of the models.83.66
88.45 86.76
Accuracy
Accuracy Comparison
[image:6.612.331.565.160.334.2]LDA CART KNN
Figure 9. Accuracy Comparison of the models
On the basis of comparison of the performance of these models we can say that CART(Decision tree) algorithm performance better than the other algorithms so we pick the decision tree algorithm for real time classification.
For real time classification of tweets we create an twitter application from which we gets the consumers and access token keys for authentication . After getting these keys we can call the ROauth function for authentication and collect the tweets on the basis of keyword and stored the collection of tweets into some variable. the data we collect from the twitter is in the unstructured form and before classification its need to be pre-processed for which we can apply various text mining functions for transforming and cleaning the raw tweets and the classify the tweets by decision tree
algorithms into various polarity which is shown in figure 10.
.
Figure 10. Classification by Polarity
VII. CONCLUSION
Text mining algorithms will give us useful and structured data which can reduces time and cost. Hidden information in social network sites, bioinformatics and internet security etc. are identified using text mining is a major challenge in these fields. The advancement of web technologies has lead to a tremendous interest in the classification of text documents containing links or other information. In this paper we use linear algorithm as LDA (Linear Discriminant Analysis) and nonlinear KNN (K Nearest Neighbour) and CART (Classification and Regression Tree) algorithm for classifying the tweets text into various polarity and based on their classify performance we can pick the best algorithm for real time sentiment classification. In this the decision tree algorithm perform better as compared to other so we can pick the decision tree algorithm for real time classification.
REFERENCES
[1] Rachana Bandana, “Sentiment Analysis of Movie Reviews Using Heterogeneous Features “in IEEE 2018.
[2] Paramita Ray and Amlan Chakrabarti, "Twitter Sentiment Analysis for Product Review Using Lexicon Method" in 2017 International Conference on Data Management, Analytics and Innovation (ICDMAI) Zeal Education Society, Pune, India, Feb 24-26, 2017.
[3] Rasika Wagh, Payal Punde, "Survey on Sentiment Analysis using Twitter Dataset" in Proceedings of the 2nd International conference on Electronics, Communication and Aerospace Technology (ICECA 2018), IEEE.
[image:6.612.58.282.178.362.2]International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 9, Issue 10, October 2019)
70
[5] Hailin Jin and Jianchao Yang, Quanzeng You and Jiebo Luo, “Robust Image Sentiment Analysis Using Progressively Trained and Domain Transferred Deep Networks”, Association for the Advancement of Artificial Intelligence (2015).
[6] Apoorv Agarwal, Boyi Xie, Ilia Vovsha, Owen Rambow and Rebecca Passonneau, “Sentiment Analysis of Twitter Data”, NextGen Invent (NGI) Corporation (2012).
[7] Efthymios Kouloumpis, TheresaWilson and Johanna Moore, “Twitter Sentiment Analysis: The Good the Bad and the OMG!” Proceedings of the Fifth International AAAI Conference on Weblogs and Social Media(2011).
[8] James Spencer and Gulden Uchyigit, “Sentimentor: Sentiment Analysis of Twitter Data”, School of Computing, Engineering and Mathematics, University of Brighton (2014).
[9] Aarati Patil and Srinivasa Narasimha Kini, “Location Based Sentiment Analysis of Products or Events over Social Media”, International Journal on Recent and Innovation Trends in Computing and Communication ISSN: 2321-8169, Volume: 4 Issue:7,50 -55. [10] Vasavi Gajarla and Aditi Gupta, “Emotion Detection and Sentiment
Analysis of Images”, Georgia Institute of Technology (2015). [11] Kausikaa.N and V.Uma, “Sentiment Analysis of English and Tamil