International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 5, Issue 4, April 2015)
355
Comparative Study of some Audio Watermarking Techniques
based on DCT, SVD, LWT and EMD Principals
Hemantkumar Kulkarni
1, Chitra Gaikwad
21
Dept. of CSE, Govt. College of Engineering, Aurangabad, (MS), India.
2Dept. of IT, Govt. College of Engineering, Aurangabad, (MS), India.
Abstract— With this paper we study the comparative analysis of some current robust audio watermarking techniques. In this paper audio watermarking techniques based on discrete cosine transform (DCT), lifted wavelet transform (LWT), singular value decomposition (SVD) and empirical mode decomposition (EMD) are studied. Algorithms are compared with the properties signal to noise ratio (SNR), data payload, bit error rate (BER) and normalized cross correlation (NC) for different signal processing attacks like cropping, re-sampling, compression etc. The comparative study states that algorithm based on EMD technique perform better than other two algorithms.
Keywords— DCT, DWT, EMD, FWHT, LPT, LWT, SVD.
I. INTRODUCTION
With the advancements in internet, digital multimedia their users are tremendously increased due to availability of these facilities on gazettes like mobiles tabs etc. Also digital media can be easily copied and transferred from one place to other. It tends to piracy of intellectual property and affects revenue generation of its owner. Another important reason of piracy is the advancement in the compression techniques and different file formats, which causes the media to be saved in less than 10% space of its original size. Watermarking deals an important role in the copyright protection of such intellectual properties [1]. Digital watermarking is the process of embedding watermark into the host data, which can be retrieved later to prove the ownership [1].
This paper deals with some latest audio watermarking techniques. Generally, an effective audio watermarking technique should satisfy following requirements: Imperceptibility, Robustness, Security, and Data Payload [1][2]. Imperceptibility is the measure of audio quality of watermarked signal. It can be evaluated using objective and subjective measures. According to IFPI (International
Federation of the Phonographic Industry)
recommendations, a watermarked audio signal should maintain more than 20 dB SNR. Robustness is ability to successfully extract watermark from watermarked audio signal.
The measure of robustness is BER (Bit Error Rate). Security of watermarked audio signal should be such that it should not leave any clues or indications that the audio signal is watermarked. Security of watermarked signal should be depends on the secrecy of secret keys, and not on the secrecy of watermark embedding algorithms [1]. Data payload is the amount of data that can be embedded within host signal of unit time [1][2]. The trade-off between these requirements is that the increase in data rate results in quality degradation of the watermarked signal and decreased robustness against signal processing attacks [3].
Audio Watermarking technique involves the embedding of secret information (watermark) into a host audio signal. In order to understand the issue of protecting, monitoring & tracking the digital contents, broad understanding of the existing methods is very essential. Several watermarking schemes have been implemented for the protection of intellectual property rights of the digital audio. As Human Auditory System (HAS) is more complex, audio watermarking is more challenging than image & video watermarking. An audio signal requires less number of samples to represent the signal therefore the amount of information that can be embedded in audio signal is very less. Large numbers of algorithms were developed for secure and robust watermarking. The range starts from simple Least Significant Bit (LSB) algorithm to complex Spread Spectrum algorithms [1][4].
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 5, Issue 4, April 2015)
356
Time domain signals are simply the plot of amplitude of the signal with reference to its time. Analysis of time domain signal cannot give the information about the frequencies contained in the signal. In the frequency domain transformation the details of frequency components present in the signal can be analyzed but it does not provide the information of time at which particular frequency present. Wavelet domain transform removes the drawback of both time domain and frequency domain and provides time-frequency representation of the signal.
Generally, watermarking techniques based on transform domain are more popular than those based on time domain since they provide higher audio quality and much more robustness. The most popular and common transform domain techniques are fast Fourier transform (FFT) [8], discrete cosine transform (DCT)[5][9], discrete wavelet transform (DWT) [3], singular value decomposition (SVD) [3][5][6][9] and support vector regression [11]. Meanwhile, the hybrid transforms are very popular, too. The typical hybrid transforms are DWT-SVD [3], DCT-SVD [5][9], LWT-SVD [6][10] etc. These algorithms use other techniques to improve overall performance and security. Some algorithms use chaotic encryption like tent map [5], Bernoulli map [6] for the security of watermark image. In [5] entropy of signal segment is used to improve robustness against various attacks. During watermark extraction process, synchronization of watermark data with extraction algorithm is major issue, because proper synchronization watermark cannot be detected, although it is present in the signal. Some algorithms [3][7][8] use synchronization techniques during watermark embedding, to overcome such problems.
In this paper we compare three broadly used audio watermarking techniques: 1) DCT-SVD-LPT based
watermarking [4], 2) LWT-FWHT-SVD based
watermarking [5] and EMD based watermarking [6]. Section II describes embedding algorithms of these schemes. In Section III we compare these algorithms and make compressive performance analysis. Section IV is concluding session in which present result of comparative analysis.
II. AUDIO WATERMARKING TECHNIQUES
A. DCT- SVD-LPT based watermarking [5]
[image:2.612.364.519.143.387.2]The discrete cosine transform is the spectral transformation, which has the properties of Discrete Fourier Transformation. DCT uses only cosine functions of various wave numbers as basis functions and operates on real valued signals and spectral coefficients.
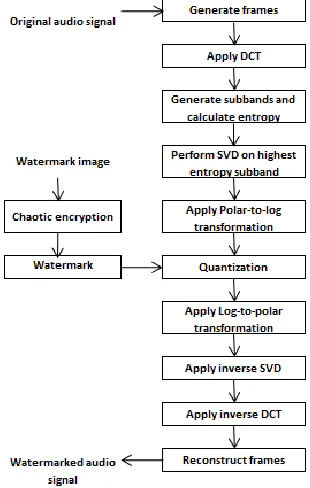
FIGURE 1: DCT-SVD-LPT based watermarking
The block diagram of DCT-SVD-LPT based watermarking scheme is shown in Figure 1. In this scheme, to enhance the confidentiality of watermark image, the watermark is encrypted using tent map. In the embedding process the original audio signal is first segmented into non overlapping frames and then each frame is transformed into DCT domain to calculate the DCT coefficients. The DCT coefficients of each frame are divided into m number of sub bands B= {B1, B2, B3,...,Bm} with r numbers of coefficients
in each sub band Bj, where j indicates the sub band number. The entropy of each sub band Bj of each frame Fi is calculated. The sub band which contains the highest entropy value of each frame is selected and DCT coefficients of Bj(highest) of each frame Fi are rearranged into an N×N square matrix Ri. SVD is performed to decompose each matrix Ri into three matrices: Ui, Si, and
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 5, Issue 4, April 2015)
357 B. LWT-FWHT-SVD based watermarking [6]
Conventional wavelet transform provides good results for its multi resolution characteristics and perfect reconstruction. However, it is mainly calculated by convolution operation, resulting in high computation. Also it requires large storage to store generated floating numbers [7].
The lifting scheme of wavelet transform which was introduced by Wim Sweldens is a second generation wavelet transform. The discrete wavelet transform applies several filters separately to the same signal. In the lifting scheme the signal is divided like a zipper and then a series of convolution-accumulate operations are applied [14].
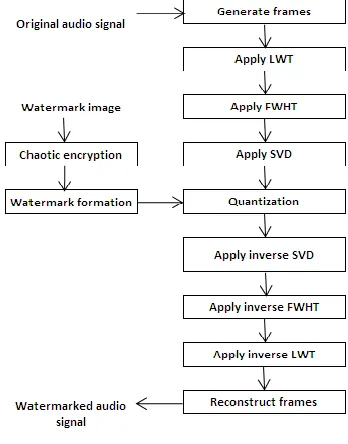
Figure 2 shows block diagram of LWT-FWHT-SVD based watermarking scheme. In this scheme Pranab Kumar Dhar and Tetsuya Shimamura introduced an LWT-based audio watermarking using fast Walsh Hadamard transform (FWHT) and singular value decomposition (SVD)[6]. It uses Bernoulli map, containing the chaotic characteristic to enhance the confidentiality of the watermark image. The data payload of the proposed scheme is 172.39 bps which is relatively higher than that of the state-of-the-art methods. It achieves a good trade-off among payload imperceptibility, and robustness. First the original audio signalis segmented into non-overlapping frames F= {F1, F2, F3,...,FPxP} and
then a two-level LWT is performed on each frame Fi. This operation produces three sets of coefficients D1, D2, and A2,
where Di and Ai represent the detailed and approximate coefficients, respectively. FWHT is applied to the approximate coefficients A2of each frame Fi to obtain the
[image:3.612.352.526.142.364.2]FWHT coefficients. The coefficients are reshaped into square matrix Ri, and SVD is applied to decompose each matrixinto three matrices: Ui, Si, and Vi.
FIGURE 2: LWT-FWHT-SVD based watermarking
Highest singular value Si(1,1) of each frame Fi is then multiplied by a scaling factor β and rounded it to the nearest integer. Then watermark bits are embedded into it. An optimal value of β should be chosen for trade-off between imperceptibility and robustness. Modified SVD is calculated by dividing it by scaling factor β. Then inverse SVD and inverse LWT operations are performed to obtain watermarked audio frame. Finally all frames are concatenated to form watermarked audio signal.
C. EMD based watermarking [7]
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 5, Issue 4, April 2015)
358
In this method the signal is decomposed into the time domain functions of length equal to the original signal. These functions are known as intrinsic mode functions (IMF). In this paper Kais Khaldi presents a new adaptive watermarking scheme based on Empirical Mode Decomposition. In this scheme watermark is embedded in very low frequency to achieve good performance against various attacks. Also watermark is associated with synchronization codes to make it robust against de-synchronization attacks like shifting and cropping. Data bits of the synchronized watermark are embedded in the extrema of the last IMF of the audio signal based on QIM [13]. The proposed scheme has higher payload and better performance against MP3 compression. Due to synchronization code, the proposed scheme achieves very low false positive and false negative error probability rates.
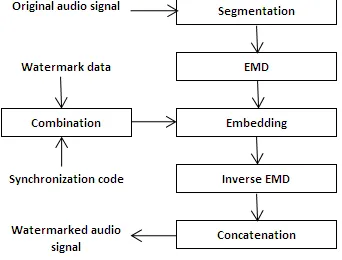
Figure 3 shows EMD Based watermarking. In this scheme first binary sequence is formed by prefixing and suffixing synchronization code to the watermark. Original audio signal is split into frames. Each frame is decomposed using EMD into number of Intrinsic Mode Functions (IMFs). Then the binary sequence (Watermark) is embedded into extrema of last IMF by Quantization Index Modulation (QIM).
FIGURE 3: EMD Based watermarking
Finally the modified frame is reconstructed by applying inverse EMD and all frames are concatenated to form the watermarked audio signal.
III. COMPARATIVE ANALYSIS
To compare the performance of all the three algorithms following attacks are applied on the watermarked signals.
Noise addition: Additive white Gaussian noise (AWGN) is added to the watermarked audio signal.
Cropping: 1000 samples are removed from the beginning of the watermarked signal and then these samples are replaced by the watermarked samples attacked with AWGN.
Re-sampling: The watermarked signal originally sampled at 44.1 kHz is re-sampled at 22.050 kHz and then restored by sampling again at 44.1 kHz.
Re-quantization: The 16 bit watermarked audio signal is quantized down to 8 bits/sample and again re-quantized back to 16 bits/sample.
MP3 Compression: MPEG-1 layer 3 compression with 128 kbps is applied to the watermarked audio signal.
Performance of these algorithms is compared with parameters data payload, signal to noise ratio SNR normalized cross-correlation NC and bit error rate BER. Table I shows SNR and data payload of these schemes whereas Table II shows the detailed comparison of normalized cross-correlation and bit error rate between all three algorithms [5][6] and [7] for different audio processing attacks.
TABLEI
COMPARISON OF SNR AND DATA PAYLOAD BETWEEN DCT-SVD-LPT,
LWT-FWHT-SVD AND EMDALGORITHMS
Algorithm SNR (dB) Data Payload
(bps)
DCT-SVD-LPT [5] 48.33 172.39
LWT-FWHT-SVD [6] 33.83 172.39
EMD [7] 25.42 46.9-50.3
With the comparison between three audio watermarking schemes, it is observed that EMD based scheme has better normalised cross-correlation (NC) and bit error rate (BER). Thus it is more robust than other two schemes against common signal processing attacks.
According to International Federation of the Photographic Industry (IFPI) recommendations, a watermark audio signal should maintain more than 20 dB SNR. Although all schemes have good SNR, DCT-SVD-LPT scheme performs best.
To improve security of watermark image most of the schemes uses chaotic encryption to encrypt original watermark image.
[image:4.612.85.256.431.561.2]International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 5, Issue 4, April 2015)
359
EMD based watermarking overcomes the drawback of fixed basis functions in wavelet domain. A major advantage of EMD relies on no a priori choice of filters or basis functions.
In DCT-SVD-LPT scheme, during embedding process original largest singular values need to be saved and used as secret key during the extraction process. It degrades the blindness of the algorithm and will become the cause of de-synchronization on attacks like cropping.
TABLEII
COMPARISON OF NC AND BER BETWEEN DCT-SVD-LPT,LWT-FWHT-SVD AND EMD ALGORITHMS FOR DIFFERENT ATTACKS
Audio
Signal Attack type
DCT-SVD-LPT [5] LWT-FWHT-SVD [6] EMD [7]
NC BER NC BER NC BER
Pop
No attack 1 0 1 0 1 0
Noise addition 1 0 0.9943 0.6836 1 0
Cropping 1 0 0.9984 0.1953 1 0
Re-sampling 1 0 0.991 1.0742 0.9783 3
Re-quantization 1 0 1 0 1 0
MP3 compression 0.982 2.1484 0.9737 3.125 0.9996 0
Jazz
No attack 1 0 - - 1 0
Noise addition 0.9984 0.1953 - - 1 0
Cropping 0.9984 0.1953 - - 1 0
Re-sampling 1 0 - - 0.9983 2
Re-quantization 1 0 - - 1 0
MP3 compression 0.9766 2.832 - - 1 0
Classical
No attack 1 0 1 0 1 0
Noise addition 0.9959 0.4883 0.9951 0.5859 1 0
Cropping 0.9984 0.1953 0.9992 0.0977 1 0
Re-sampling 1 0.4883 0.9902 1.1719 0.9986 2
Re-quantization 1 0 1 0 1 0
MP3 compression 0.9746 3.0273 0.9666 4.0039 1 0
Folk
No attack 1 0 1 0 - -
Noise addition 1 0 0.9951 0.5859 - -
Cropping 0.9984 0.1953 0.9976 0.293 - -
Re-sampling 1 0 0.9894 1.2695 - -
Re-quantization 1 0 1 0 - -
MP3 compression 0.9772 2.7344 0.9721 3.3203 - -
Average 0.9958 0.5208 0.9923 0.9114 0.9986 0.3888
Data payload of an algorithm depends on i) size of each frame and ii) whether every frame is used to embed data bits. Lesser the frame size payload capacity is higher, but it degrades quality of the signal. As watermark data is very low compared to host signal, payload can be compensated to improve perceptual quality of the watermarked signal and robustness.
IV. CONCLUSION
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459,ISO 9001:2008 Certified Journal, Volume 5, Issue 4, April 2015)
360
Data payload capacity can be increased by decreasing of frames, but it degrades perceptual quality and robustness. Hybrid watermarking techniques in which more than one basic watermarking technique are used, improves perceptual quality and robustness, and complexity also.
REFERENCES
[1] S. Katzenbeisser, F.A.P. Petitcolas, Information Hiding Techniques for Steganography and Digital Watermarking, Artech House, Boston, 2000.
[2] I. J. Cox and M. L. Miller, ―The First 50 Years of Electronic Watermarking,‖ J. Appl. Signal Processing, vol. 56, no. 2, pp. 225-230, 2002.
[3] V. K. Bhat, I. Sengupta, and A. Das, ―An Adaptive Audio Watermarking Based on the Singular Value Decomposition in the Wavelet Domain,‖ Digital Signal Processing, vol. 20, no. 6, pp. 1547-1558, 2010
[4] D. Kiroveski and S. Malvar, ―Robust Spread Spectrum Audio Watermarking,‖ IEEE International Conference on Acoustics, Speech, and Signal Processing (ICASSP’01), pp. 1345-1348, 2001. [5] Pranab Kumar Dhar and Tetsuya Shimamura , ―Entropy-Based
Audio Watermarking Using Singular Value Decomposition and Log-Polar Transformation‖, 56th International Midwest Symposium on Circuits and Systems (MWSCAS), IEEE 2013
[6] Pranab Kumar Dhar and Tetsuya Shimamura , ―A Blind LWT-Based Audio Watermarking Using Fast Walsh Hadamard Transform and Singular Value Decomposition‖, International Symposium on Circuits and Systems, IEEE 2014
[7] K. Khaldi and A. O. Boudraa, ―Audio Watermarking Via EMD,‖ IEEE Trans. Audio, Speech and Language Processing, vol. 21, no. 3, pp. 675- 680, 2013.
[8] D. Megias, J. Serra-Ruiz, and M. Fallahpour, ―Efficient self-synchronised blind audio watermarking system based on time domain and FFT amplitude modification,‖ Signal Process., vol. 90, pp. 3078–3092, 2010.
[9] B. Y. Lei, I. Y. Soon, and Z. Li, ―Blind and robust audio watermarking scheme based on SVD-DCT,‖ Signal Process., vol. 91, pp. 1973–1984, 2011.
[10] B. Y. Lei, I. Y. Soon, F. Zhou, Z. Li, and H. Lei, ―A robust audio watermarking scheme based on lifting wavelet transform and singular value decomposition,‖ Signal Process., vol. 92, pp. 1985– 2001, 2012.
[11] X. Wang, W. Qi, and P. Niu, ―A new adaptive digital audio watermarking based on support vector regression,‖ IEEE Trans. Audio, Speech, Lang. Process., vol. 15, no. 8, pp. 2270–2277, Nov. 2007.
[12] Xiangui Kang, Rui Yang, and Jiwu Huang, Senior ―Geometric Invariant Audio Watermarking Based on an LCM Feature‖, IEEE Transaction on Multimedia, Vol. 13, No. 2 April 2011.