International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 2, Issue 1, January 2012)71
Clustering of Web Users using ART1 NN based Clustering
Approach with a Complete Preprocessing Methodology
1
Ramya C,
2Dr. Shreedhara K S
1Lecturer, Dept. of Studies in CSE, University B.D.T College of Engineering, Davangere
VTU, Karnataka, INDIA
2
Professor,Dept. of Studies in CSE,University B.D.T College of Engineering, Davangere VTU, Karnataka, INDIA
1[email protected] 2[email protected]
Abstract—In this paper, a complete preprocessing methodology for discovering patterns in web usage mining process to improve the quality of data by reducing the quantity of data has been proposed. A dynamic ART1 neural network clustering algorithm to group users according to their Web access patterns with its neat architecture is also proposed. Several experiments are conducted and the results show the proposed methodology reduces the size of Web log files down to 73-82% of the initial size and the proposed ART1 algorithm is dynamic and learns relatively stable quality clusters. We compare the quality of clustering of our ART1 based clustering technique with that of traditional K-Means and SOM clustering algorithms. The results show the average inter-cluster distance of ART1 is high compared to K-Means and SOM when there are fewer clusters. As the number of clusters increases, average inter-cluster distance of ART1 is low compared to K-Means and SOM which indicates the high quality of clusters formed by our approach.
Keywords- Adaptive Resonance Theory (ART), ART1 neural network, Clustering, Preprocessing, Web usage mining
I. INTRODUCTION
World Wide Web is a huge ocean of web pages and links. Users’ accesses are recorded in web logs. The web log files are growing at a faster rate and the size is becoming huge because of the tremendous usage of web. Today’s real world databases are likely to be influenced by noisy, incomplete and inconsistent data due to their typically huge size data and their origin from multiple, heterogeneous sources. The attributes that we can look for in quality data includes accuracy, completeness, consistency, timeliness, believability, interpretability and accessibility. Rushing to analyze usage data without a proper preprocessing method will lead to poor results or even to failure. Hence, there is a need to preprocess data to make it have these attributes and to make it easier to mine for knowledge. This paper gives a complete preprocessing methodology having merging, data cleaning, user/session identification and data formatting and summarization activities to improve the quality of data by reducing the quantity of data.
We also present an ART1 based clustering algorithm to group users according to their Web access patterns. In our ART1 based clustering approach, each cluster of users is represented by a prototype vector that is a generalized representation of URLs frequently accessed by all the members of that cluster. One can control the degree of similarity between the members of each cluster by changing the value of the vigilance parameter. In our work, we analyze the clusters formed by using the ART1 technique by varying the vigilance parameter ρ between the values 0.3 and 0.5. We also compare the performance of ART1 clustering technique with that of K-Means and SOM clustering algorithm in terms of average inter-cluster and average intra-cluster distances.
The results show that the proposed methodology reduces the size of Web access log files down to 73-82% of the initial size and offers richer logs that are structured for further stages of Web Usage Mining (WUM). Experimental results are provided to show that ART1 NN based clustering approach performs better in terms of intra-cluster and inter-cluster distances compared to K-Means and SOM clustering algorithms. The time complexity of all the three algorithms is compared. ART1 takes less time compared to K-Means and SOM, proving ART1 is efficient than SOM and K-Means.
II. RELATEDWORK
We present in this section the main related works in this domain. In the recent years, there has been much research
on Web usage mining
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 2, Issue 1, January 2012)72
In another work [15], the authors compared time-based and referrer-based heuristics for visit reconstruction. In [16], Marquardt et al. addressed the application of WUM in the e-learning area with a focus on the preprocessing phase.
Clustering users based on their Web access patterns is an active area of research in Web usage mining. R. Cooley et al. [17] proposed a taxonomy of Web Mining and present various research issues, techniques and future directions in this field. Phoha et al. use competitive neural networks and data mining techniques to develop schemes for fast allocation of Web pages [18]. M. N. Garofalakis et al. [19] review popular data mining techniques and algorithms for discovering Web, hypertext, and hyperlink structure. Y. Fu et al. [20] present a generalization based clustering approach, which combines attribute oriented induction, and BIRCH [21] to generate hierarchical clustering of Web users based on their access patterns. I. Cadez et al. [22] use first-order Markov models to cluster users according to the order in which they request Web pages. The Expectation Maximization algorithm is then used to learn the mixture of first-order Markov models that represent each cluster. G. Paliouras et al. [23] analyze the performance of three clustering algorithms (1) Autoclass, (2) Self Organizing Maps and (3) Cluster Mining for constructing community models for the users of large Websites. Xie and Phoha [24] apply the concept of mass distribution in Dempster-Shafer’s theory and propose a belief function similarity measure.
III. PRE-PROCESSING METHODOLOGY
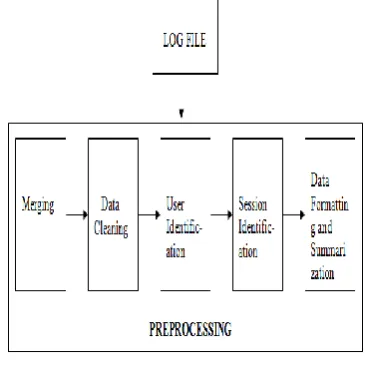
The main objectives of preprocessing are to reduce the quantity of data being analyzed while, at the same time, to enhance its quality. Preprocessing comprises of the following steps – Merging of Log files from Different Web Servers, Data cleaning, Identification of Users, Sessions, and Visits, Data formatting and Summarization as shown in Fig. 1.
A. Merging
At the beginning of the data preprocessing, the requests from all log files, put together into a joint log file with the Web server name to distinguish between requests made to different Web servers and taking into account the synchronization of Web server clocks, including time zone differences.
B. Data Cleaning
The second step of data preprocessing consists of removing useless requests from the log files. Since all the log entries are not valid, we need to eliminate the irrelevant entries. Usually, this process removes requests concerning non-analyzed resources such as images, multimedia files, and page style files.
C. User Identification
In most cases, the log file provides only the computer address (name or IP) and the user agent (for the ECLF log files). For Web sites requiring user registration, the log file also contains the user login (as the third record in a log entry) that can be used for the user identification.
D. Session Identification
A user session is a directed list of page accesses performed by an individual user during a visit in a Web site. A user may have a single (or multiple) session(s) during a period of time. The session identification problem is formulated as ―Given the Web log file, capture the Web users’ navigation trends, typically expressed in the form of Web users’ sessions‖.
E. Data Formatting & Summarization
[image:2.595.338.521.405.588.2]This is the last step of data preprocessing. Here, the structured file containing sessions and visits are transformed to a relational database model.
Figure 1. Stages of Pre-processing
IV. CLUSTERINGMETHODOLOGY
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 2, Issue 1, January 2012)73
A. The Clustering Model [image:3.595.58.270.288.403.2]The proposed clustering model involves two stages – Feature Extraction stage and the Clustering Stage. First, the features from the preprocessed log data are extracted and a binary pattern vector P is generated. Then, ART1 NN clustering algorithm for creating the clusters in the form of prototype vectors is used. The feature extractor forms an input binary pattern vector P that is derived from the base vector D. The procedure is given in Fig. 2. It generates the pattern vector which is the input vector for ART1 NN based clustering algorithm.
Figure 2. Procedure for generating Pattern Vector
[image:3.595.49.281.443.630.2]B. ART1 Neural Network Clustering
Figure 3. Architecture of ART1 NN based Clustering
The Architecture of the ART1 NN based clustering technique for clustering hosts/Web users is as shown in Fig. 3. Each input vector activates a winner node in the layer F2 that has highest value among the product of input vector and the bottom-up weight vector. The F2 layer then reads out the top-down expectation of the winning node to F1, where the expectation is normalized over the input pattern vector and compared with the vigilance parameter ρ.
If the winner and input vector match within the tolerance allowed by the ρ, the ART1 algorithm sets the control gain G2 to 0 and updates the top-down weights corresponding to the winner. If a mismatch occurs, the gain controls G1 & G2 are set to 1 to disable the current node and process the input on another uncommitted node. Once the network is stabilized, the top-down weights corresponding to each node in F2 layer represent the prototype vector for that node. Summary of the steps involved in ART1 clustering algorithm is shown in Table I.
V. EXPERIMENTAL RESULTS
We have conducted several experiments on log files collected from NASA Web site during July 1995. Through these experiments, we show that our preprocessing methodology reduces significantly the size of the initial log files by eliminating unnecessary requests and increases their quality through better structuring. It is observed from the Table 2 that, the size of the log file is reduced to 73-82% of the initial size. Fig. 4 shows the file containing only interesting patterns after preprocessing the web access log files.
The results show that the proposed ART1 algorithm learns relatively stable quality clusters compared to K-Means and SOM clustering algorithms. Here, the quality measures considered are functions of average Inter-Cluster and the Intra-Cluster distances. Experimental simulations are performed using MATLab
[image:3.595.320.540.505.744.2]
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 2, Issue 1, January 2012) [image:4.595.50.283.162.258.2]74
TABLE II. RESULTS AFTER PREPROCESSING
Fig. 5 shows the variations in the average inter-cluster distances for the three ART1, K-Means and SOM
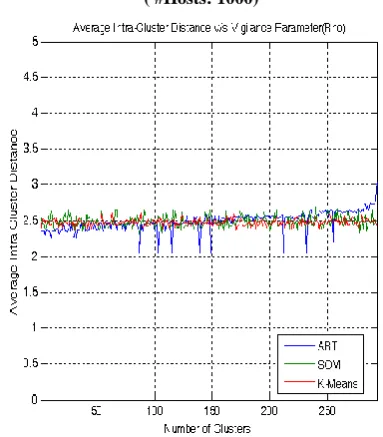
[image:4.595.51.548.350.717.2]algorithms. It is observed that, average inter-cluster distance of ART1 is high compared to K-Means and SOM when there are fewer clusters, and as the number of clusters increases, average inter-cluster distance of ART1 is low compared to K-Means and SOM. Variations in the average intra-cluster distances of the three algorithms for varying number of clusters are shown in the Fig. 6. Average intra-cluster distance of ART1 is low compared to K-Means and SOM when there are fewer clusters, and as number of clusters increases, average intra-cluster distance of ART1 is high compared to K-Means and SOM. It is clear from the observation that, the ART1- clustering results are promising compared to K-Means and SOM algorithms.
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 2, Issue 1, January 2012)75
To evaluate the quality of clustering results, internal quality measure such as Cluster Compactness (Cmp) is used. Cluster Compactness is used to evaluate the intra-cluster homogeneity of the intra-clustering result and is defined as:
C i
i X v
c v C Cmp
1 ( ) ) (
1 (1)
Where C is the number of clusters generated on the data set X, v(ci) is the deviation of the cluster ci, and v(X)
is the deviation of the data set X given by:
) , ( 1 ) (
1 2
x x d N X v
N
i i
(2)
Where d(xi, xj) is the Euclidean distance, is a measure
between two vectors xi and xj, N is the number of
members in X, and
x
is the mean of X. The smaller the Cmp value, the higher the average compactness in the output clusters. It is observed from the Fig. 7 that Cmp value of ART1 clustering algorithm is small showing higher average compactness compared to SOM and K-Means algorithms. Also, Cmp value of ART1 varies steadily with the increase in number of clusters, whereas the Cmp value of SOM and K-Means algorithms are quite constant irrespective of the number of clusters.The Overall cluster quality (Ocq) is used to evaluate both intra-cluster homogeneity and inter-cluster separation of the results of clustering algorithms. Ocq is defined as:
Sep Cmp
Ocq(
)
(1
) (3)Where [0, 1] is the weight that balances the measures Cmp and Sep. Avalue of 0.5 is often used to give equal weights to the two measures for overcoming the deficiency of each measure and assess the overall performance of a clustering system. Therefore, the lower the Ocq value, the better the quality of resulting clusters. It is observed from Fig. 8 that, the Ocq value of our ART1 clustering algorithm is lower compared to SOM and K-Means indicating the clusters formed by our ART1 NN are with better quality.
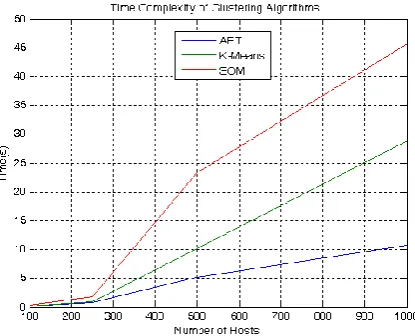
For the efficiency analysis, the time complexity of all the three algorithms are compared with the same number of hosts to be clustered (input) and with same number of clusters (k value in case of SOM and K-Means, value in case of ART1). For a value of 0.5, the response time is measured for the three algorithms on different number of hosts (100,250,500, and 1000).
It is observed from the Fig. 9 that, for large data set, ART1 takes less time compared to K-Means and SOM, proving ART1 is efficient than SOM and K-Means. The time complexity of ART1 is almost linear log time O (n*log2n), where as the time complexity of K-Means is
quad log time O (n*k*log2n) and SOM is polynomial log
[image:5.595.324.522.249.458.2]time O (n*k*log2n) with varying number of iterations.
Figure 5. Variations in Average Inter-Cluster Distances ( #Hosts: 1000)
[image:5.595.330.522.481.700.2]International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 2, Issue 1, January 2012) [image:6.595.65.265.143.304.2] [image:6.595.64.266.341.514.2]76
Figure. 7 Variations in Cluster Compactness( #Hosts: 1000)Figure. 8 Variations in Overall Cluster Quality( #Hosts:
1000)
Figure 9. Time Complexity of Clustering Algorithms
VI. CONCLUSIONS
In this paper, we have presented an effective methodology for preprocessing required for WUM process. The experimental results illustrate the importance of the data preprocessing step and the effectiveness of our methodology. Next, we presented our approach to group hosts (each host represents an organizationally related group of users) according to their Web request patterns. We use the ART1 clustering algorithm to cluster these communities of users. We compared the performance of the ART1 clustering with K-Means and SOM clustering algorithm and show that the ART1 clustering performs better than the K-Means and SOM clustering algorithms. The time complexity of all the three algorithms are compared ART1 takes less time compared to K-Means and SOM, proving ART1 is efficient than SOM and K-Means.
VII. FUTURE ENHANCEMENT
It should be noted at this point that the WUM is an interesting potential field for research and accordingly the list of open issues is quite long. The problem of knowledge extraction from WWW is even more challenging because the data stored in the Web is very dynamic in nature, and constantly changing due to continuous update of the existing data or Web pages and addition of new information every moment. Whether the log data comes from client, Web server or the content server, effective WUM will continue to grow as an important tool for analyzing, optimizing and personalizing the Web sites. There are a number of unsolved technical problems and open issues at the stage of data collection & preprocessing. New techniques and possibly new models for acquiring data are needed. One serious issue concerning data collection is the protection of the user’s privacy. A Poll by KDnuggets (15/3/2000 – 30/3/2000) revealed that, about 70% of the users consider Web mining as a compromise of their privacy. Thus it is imperative that new Web usage mining tools are transparent to the user by providing access to the data collected and clarifying the use of these data as well as the potential benefits for the user.
References
[1] Configuration files of W3C httpd,
http://www.w3.org/Daemon/User/Config/ (1995). [2] W3C Extended Log File Format,
http://www.w3.org/TR/WD-logfile.html (1996). [3] J. Srivastava, R. Cooley, M. Deshpande, P.-N. Tan,
[image:6.595.65.273.577.745.2]International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 2, Issue 1, January 2012)77
[4] R. Kosala, H. Blockeel, Web mining research: a survey, SIGKDD: SIGKDD explorations: newsletter of the special interest group (SIG) on knowledge discovery & data mining, ACM 2 (1), 2000, 1–15. [5] R. Kohavi, R. Parekh, Ten supplementary analyses to
improve e-commerce web sites, in: Proceedings of the Fifth WEBKDD workshop, 2003.
[6] B. Mobasher R. Cooley, and J. Srivastava, Creating Adaptive Web Sites through usage based clustering of URLs, in IEEE knowledge & Data Engg work shop (KDEX’99), 1999.
[7] Bettina Berendt, Web usage mining, site semantics, and the support of navigation, in Proceedings of the Workshop ―WEBKDD’2000 - Web Mining for E-Commerce - Challenges and Opportunities‖, 6th ACM SIGKDD In Conf. on Knowledge Discovery and Data Mining, 2000, Boston, MA.
[8] B. Berendt and M. Spiliopoulou. Analysis of Navigation Behaviour in Web Sites Integrating Multiple Information Systems. VLDB, 9(1), 2000, 56-75.
[9] A. Joshi and R. Krishnapuram. On Mining Web Access Logs. In ACM SIGMOD Workshop on Research Issues in Data Mining and Knowledge Discovery, pages 2000, 63- 69.
[10] C. Shahabi and F. B. Kashani. A Framework for Efficient and Anonymous Web Usage Mining Based on Client-Side Tracking. In WEBKDD 2001 - Mining Web Log Data Across All Customers Touch Points, Third International Workshop, San Francisco, CA, USA, August 26, 2001, Revised Papers, volume 2356 of LNCS, Springer, 2002, 113-144.
[11] Y. Fu, K. Sandhu, and M. Shih. A Generalization-Based Approach to Clustering ofWeb Usage Sessions. In Proceedings of the 1999 KDD Workshop on Web Mining, San Diego, vol. 1836 of LNAI,. Springer, 2000, 21-38.
[12] M. S. Chen, J. S. Park, and P. S. Yu. Efficient Data Mining for Path Traversal Patterns. Knowledge and Data Engineering, 10(2), 1998, 209-221.
[13] B. Mobasher, H. Dai, T. Luo, and M. Nakagawa. Discovery and Evaluation of Aggregate Usage Profiles for Web Personalization. Data Mining and Knowledge Discovery, 6(1), 2002, 61-82.
[14] M. El-Sayed, C. Ruiz, and E. A. Rundensteiner. FS-Miner: Efficient and Incremental Mining of Frequent Sequence Patterns in Web Logs. In Proceedings of the 6th Annual ACM International Workshop on Web Information and Data Management , 2004, 128-135. [15] B. Berendt, B. Mobasher, M. Nakagawa, and M.
Spiliopoulou. The Impactof Site Structure and User Environment on Session reconstruction in Web Usage Analysis. In Proceedings of the Forth WebKDD 2002 Workshop, at the ACM-SIGKDD Conference on Knowledge Discovery in Databases, Canada, 2002.
[16] C. Marquardt, K. Becker, and D. Ruiz. A Pre- Processing Tool for Web Usage Mining in the
Distance Education Domain. In Proceedings of the International Database Engineering and Applications Symposium (IDEAS'04), 2004, 78-87.
[17] Cooley R., Mobasher B., and Srivatsava J., ―Web Mining: Information and Pattern Discovery on the World Wide Web.‖ ICTAI’97, 1997.
[18] Phoha V. V., Iyengar S.S., and Kannan R., ―Faster Web Page Allocation with Neural Networks,‖ IEEE Internet Computing, Vol. 6, No.6, pp. 18-26, December 2002.
[19] Garofalakis M. N., Rastogi R., Sheshadri S., and Shim K., ―Data mining and the Web: past, present and future.‖ In Proceedings of the second international workshop on Web information and data management, ACM, 1999.
[20] Fu Y., Sandhu K., and Shih M., ―Clustering of Web Users Based on Access Patterns.‖ International Workshop on Web Usage Analysis and User Profiling (WEBKDD’99), San Diego, CA, 1999.
[21] Zhang T., Ramakrishnan R., and Livny M., ―Birch: An Efficient Data Clustering Method for Very Large Databases.‖ In Proceedings of the ACM SIGMOD Conference on Management of Data, pages 103-114, Montreal, Canada, June 1996.
[22] Cadez I., Heckerman D., Meek C., Smyth P., and Whire S., ―Visualization of Navigation Patterns on a Website Using Model Based Clustering.‖ Technical Report MSR-TR-00-18, Microsoft Research, March 2002.
[23] Paliouras G., Papatheodorou C., Karkaletsis V., and Spyropoulos C.D., ―Clustering the Users of Large Web Sites into Communities.‖ In Proceedings of the International Conference on Machine Learning (ICML), pages 719-726, Stanford, California, 2000. [24] Xie Y., and Phoha V. V., ―Web User Clustering