Relevance Feedback For Information Retrival
Based on User Query Using SIFT Algorithm
Anjana Tamrakar1, Prof Dr Abha Choubey2, Prof. Dr Siddhartha Choubey3
1
Shri Shankaracharya group of Institution Dept. of Computer Technology Bhilai, Chhattisgarh, India 2
Shri Shankaracharya Group of Institution Dept. of Computer Technology Bhilai, Chhattisgarh, India 3
Shri Shankaracharya Group of Institution Dept. of Computer Technology Bhilai, Chhattisgarh, India
Abstract: In old days, people have turned out to be conscious about the outcomes of documenting and discovering information. With the arrival of computers, it became possible to store tremendous measure of information; and finding the valuable information from images collections which is turning into a need. Out of this need in the 1950s, the field of Information Retrieval (IR) was conceived. The field of information retrieval has developed extensively finished the most recent forty years. A few IR systems are utilized on a regular by a wide assortment of users. Information retrieval turns into an imperative research region in the field of software engineering. Information retrieval (IR) is generally concerned about the looking and recovering of relevant similar image information from database. In this paper, we propose a novel mechanism in combination of SIFT and Relevance Feedback algorithm for looking of similar image. The user queries based of image and system produces output of similar images with relevance feedback mechanism for development of retrieval.
Keywords: Information retrieval, quantum mechanics, relevance feedback, quantum detection.
I. INTRODUCTION
Current information retrieval system enables user to retrieve tremendous measure of electronically stored information objects. Information retrieval is worried about recovering and indexing documents including information which is relevant to a user's information require. Users can express their required information utilizing different courses, a standout amongst the most widely recognized means is queries written in natural languages. Notwithstanding, a query can be extremely trying for the reason that the richness of natural language. Usually, a query is unstructured and in addition ambiguous hence, a query may express two or more than two variety of information needs and furthermore retrieval of one information might be communicated by at least two distinct queries.
The user accessed the information by the information retrieval system, the information is as a rule as unstructured or as semi-organized. Anyway a database system will be utilized to answer
“Mexico City has the worst air pollution in the world. Pertinent documents would contain the specific steps Mexican authorities have taken to combat this deplorable situation”
irrelevant documents previously utilizing them for reducing the query [1]. The method by which an information retrieval system utilizes the information of relevance feedback given by the user is the primary focus of this surveys some of the strategy utilized for Information retrieval. The fundamental focus of this paper is the methodology by which an information retrieval system utilizes the relevant information which is given by the user. This paper covers different features of Relevance Feedback: the portrayals utilized as a part of RF, how these illustration prompt settle on a decision how to change a query and in addition the part of interface in RF. It may be possible for an information retrieval system for small collections of documents to get to each report thus and choosing whether or not it is probably going to be so relevant to a user's query [2][3]. This become impractical for larger collections, particularly in intelligent systems. Hence, it is extremely important to make the record collection into an effortlessly make accessible the portrayal; documents that are well on the way to be relevant that report one can focused, here is the case, those documents that are having at least one word that come into view in the user's query [4]. This total change from a text document to a portrayal of a text is called indexing the documents [5]. Here are different kinds of indexing methods regardless of this the majority depends on choosing great report descriptors, there are numerous sorts of descriptors, for example, keywords, or terms, to speak to the important information from the content of documents. For IR a 'good' descriptor is a term that used to clarify the information substance of the record and it additionally one that can separate the report from alternate documents in the collection of documents. Again a 'good' descriptor has a specific discriminatory as power. The power of a term, for example, a 'good' in discriminating documents can be utilized to separate between the relevant and non-relevant documents. Once the text document has been tokenized it is exceptionally important to settle on choice which terms ought to be utilized to represent the documents. Thusly, we have to settle on decision which descriptors are so valuable for the joint part of representing the document’s content and the discriminating of the archive from alternate documents in the collection. The high frequency terms getting ones out of a high extent of the documents in the collection that will tend not to be exceptionally successful either in discriminating between documents or in representing documents.
II. LITERATURESURVEY
Massimo Melucci [6], proposes a class of RF algorithms propelled by quantum identification to re-weight the question terms and to re-rank the archive recovered by an IR framework. These algorithms venture the question vector on a subspace spread over by the eigenvector which boosts the separation between the dissemination of quantum likelihood of relevance and the dispersion of quantum likelihood of non-relevance. The tests demonstrated that the RF algorithms motivated by quantum recognition can outperform the cutting edge algorithms.
Kevyn Collins-Thompson et. al. [7] demonstrates how perusing level can give an important new relevance motion for both general and customized Web seek. We portray models and algorithms to address the three key issues in enhancing relevance for look utilizing perusing trouble: assessing client capability, evaluating result trouble, and re-positioning in view of the contrast amongst client and result perusing level profiles. We assess our strategies on an extensive volume of Web question movement and give a largescale log examination that features the significance of discovering comes about at a proper perusing level for the client. Donna Harman et. al. [8] concentrated on tests, utilizing the Crartfield 1400 accumulation demonstrated the significance of question development notwithstanding inquiry reweighing, and demonstrated that including as few as 20 very much chose terms could bring about performance upgrades of more than 100%. Also it was demonstrated that performing different emphases of feedback is very successful.
Ingo Frommholz et. al. [9] proposes an approach enlivened by quantum mechanics to speak to inquiries and their reformulations as thickness administrators. Distinctively built densities can conceivably be connected for various kinds of question reformulation. To do as such, we propose and talk about markers that can indicate us to the kind of question reformulation we are managing.
Yujiao Zhang, [10] proposed system in which Image corners are removed by Harris-Laplace corner locator and the notable locale is gotten by the thickness proportion in each appropriated territory of image corners. At that point, shading and shape in the striking region are combined for the underlying recovery. At long last, relevance feedback in view of S V order is brought into CBI. The reproduction comes about demonstrate that the technique proposed in this paper performs well in assessment records of normal precisions.
III. METHODOLOGY
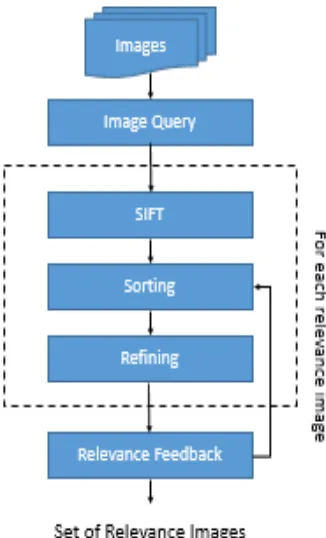
Fig. 1. Propsoed System Architecture
A. Images
Diverse images are taken for building datasets. The image dataset contains images of extremely well known monuments likes Taj Mahal, Qutub Minar, Red Fort and so forth and many more.
B. Image Query
Image Query is the pursuit query which the user performs. The user basically upload the image and demand for looking of comparable images.
C. SIFT Algorithm
SIFT is Scale Invariant Feature Transform, for detecting salient feature of any picture in the search space. It smartly recognizes the highlights of each picture and in view of that different similar images are recovered.
Different key purposes of SIFT algorithm is:
1) Can able to recognize salient features.
2) Points are recognized of the images.
3) It insightfully decides the relationship between purposes of the images.
D. Sorting
The Sorting is performed to mastermind the images in a specific rank. The most comparative images is ranked 1 and so on.
E. Refining
After Sorting, the refining of images are done to check whether images need further refinement or not. The refinement are done based on feedback to the user.
F. Relevance Feedback
The Relevance feedback module, just request that client check the relevant images form the given arrangement of images. Based on that SIFT algorithm calls again and refined its outcomes.
IV. RESULT
Fig. 2. Shows the suer query image
[image:4.612.183.423.320.423.2]After query, the SIFT algorithm creates some output and request that user give some feedback. The fig. 3. Demonstrates the feedback of user.
Fig. 3. Shows the feedback of the user to SIFT Algorithm for Refinement
Fig. 4. Shows the refined search results with RF Algorithm
The fig. 4. Demonstrates the refined image search results. The proposed algorithm viably retrive relevant images from the database.
V. CONCLUSION
[image:4.612.183.427.451.612.2]REFERENCES
[1] C. J. Van Rijsbergen, The Geometry of Information Retrieval. Cambridge, U.K.: Cambridge Univ. Press, 2004.
[2] X. Wang, H. Fang, and C. Zhai, “A study of methods for negative relevance feedback,” in Proc. 31st Annu. Int. ACM SIGIR Conf. Res. Develop. Inf. Retrieval, 2008, pp. 219–226.
[3] R. W. White and R. A. Roth, Exploratory Search: Beyond the QueryResponse Paradigm. San Rafael, CA, USA: Morgan & Claypool,2009.
[4] S. Wong and V. Raghavan, “Vector space model of information retrieval: A reevaluation,” in Proc. 7th Annu. Int. ACM SIGIR Conf. Res. Develop. Inf. Retrieval, 1984, pp. 167–185.
[5] Yuanhua Lv, ChengXiang Zhai, “Adaptive Relevance Feedback in Information Retrieval”, ACM November 2–6, 2009.M. Young, The Technical Writer’s Handbook. Mill Valley, CA: University Science, 1989.
[6] M. Melucci, "Relevance Feedback Algorithms Inspired By Quantum Detection," in IEEE Transactions on Knowledge and Data Engineering, vol. 28, no. 4, pp. 1022-1034, April 1 2016.
[7] Kevyn Collins-Thompson, Sebastian de la chica and David Sontag,” Personalizing Web Search Results by Reading Level”, 2011 ACM. [8] Donna Harman, “Relevance Feedback Revisited”, 2010 ACM.
[9] Ingo Frommholz, Benjamin Piwowarski , Mounia Lalmas and Keith van Rijsbergen. “Processing Queries in Session in a Quantum-inspired IR Framework”, 2011 ACM.