59
Volume-4, Issue-4, August-2014,
ISSN No.: 2250-0758
International Journal of Engineering and Management Research
Available at:
www.ijemr.net
Page Number: 59-65
Privacy Preservation of Sensitive Data used in Datamining Task
M.A Satyanarayana1, V. Uma Rani 2
1Student in M. Tech, Computer Science, School of Information Technology JNTU Hyderabad, Andhra Pradesh, INDIA 2Asst. Professor, Computer Science Department, School of Information Technology JNTU Hyderabad, Andhra Pradesh, INDIA
ABSTRACT
In this paper we address the issue of privacy preservation of sensitive data used in data mining. Specifically, we consider a scenario in which party owning confidential database wish to run a data mining algorithm on their database, without revealing any unnecessary information. Our work is motivated by the need to both protect privileged information and enable its use for research or other purposes. The above problem is a specific example of secure party computation and as such, can be solved using known generic protocols. However, data mining algorithms are typically complex and, furthermore, the input usually consists of massive data sets. The generic protocols in such a case are of no practical use and therefore more efficient protocols are required. When data are to be shared between parties, some sensitive data which should be closed to the other parties since now days data sharing between two organizations is common in many application areas like marketing or business planning. Patients privacy protection is necessary and the medical data security also required .One more thing is medical records are also more sensitive, it requires to take privacy protection more seriously . As per requirement by the Health Insurance Portability and Accountability Act (HIPAA), it is necessary to protect patients privacy and the medical data security must be ensured. First we have to apply generalization on modified or randomized data, Before this we randomize the original data. This method is called privacy preserving using Hybrid approach. This technique can reconstruct original data, makes usability of data since provides data with no information loss .This technique also protects private data with better accuracy. Mainly Hill-cipher technique was applied to numerical attribute data. With this, we can maintain privacy and also partial recovery of numerical attribute is possible.
Keywords— Data Mining, Hill-cipher, k-anonymity,
Privacy preserving, quasi-identifier, Sensitive Data.
I.
INTRODUCTION
Use of data mining is increasing , personal data in large volumes are regularly updated and processed. This data contain travelling information, job
details, family data, voter list etc ,since privacy is must be considered whenever one person requires to use of data that involve individual privacy data. That data is very much important to any commercial organizations and governments both to do decision making processes and to provide public use, such as medical security, genetic research, literacy improvement, etc. on the other hand. Ultimate goal is data must be used in view of public only, because this is mainly concerned with private firms, medical institutions, banks, and commercial organizations these give data to who wants to use the data like research scholars, statistical institutions. Publication of privacy preserving data now become one of the most important research topics and in recent years publication of personal data become a serious concern due to Internet . But data owners mostly worrying about their privacy because it has public data regarding individuals has been published by private firms and commercial organizations, like medical institutions. Due to this, new threats to the individual privacy are also increasing. So, new direction of data mining research has been developed, known as privacy preserving data mining (PPDM). It is not only doing private information protection but also from large collection of data, these algorithms gives relevant knowledge extraction.
60
II.
PRESENT
SCENARIO
To preserve the sensitive data different approaches already exists ,since it is known from privacy preserving data mining [2, 3, 6] basics. The literature review main aim is not only to establish most good methods for sensitive or private data preservation but also to know existing techniques depth, then from large database it is possible to preserve sensitive data and knowledge. The existing privacy preserving techniques identification is ultimate goal of this objective.
2.1.1 Blocking based method
In this a true value or a question mark is used to replace some data items certain attributes[2]. The sensitive association rules support and confidence degrees are reduced in this method. Data confidentiality is not violated because sensitive rule the confidence and/or the support lie below the middle in these two ranges of values, because a minimum confidence interval and a minimum support interval replaces minimum confidence and minimum support respectively.
One transaction item increase is possible when D_CONF1 algorithm circulates one time, that’s why algorithm selection must be done so that it cannot be effected by the original data-base. In privacy preserving process there are more association rules and much data. To not effect the database accuracy it is better not to use D_CONF1 algorithm repeatedly, then only some association rules generation is not possible and data quantity increase also. D_SUPP and D_CONF2 are has same front parts . We can get from D_SUPP algorithm and D_CONF2 algorithm, sacrifice item from whole generated item-set and sacrifice item in back-end item set respectively. D_CONF1 algorithm is used wherever deletion or modification of some important items not possible. Algorithm selection is based on D_SUPP and D_CONF2 algorithms sup-port ,selected sacrifice item importance and the quantity and efficiency values if selecting sacrifice item influence for the original data-base o in back-end is smaller, Because it is better to select D_CONF2 algorithm, whenever selecting sacrifice item effect for the original database ,in front-end is smallest. So we choose sacrifice item and the sensitive transaction more efficient, before this we could analyze the sensitive association rule set to be hidden and original database transaction set and find their relation. original database effect will be smaller and modified data will be fewer.
Finally the sanitized dataset which contains unknown values is released to public[4] .This method is easy to implement but gives information loss.
2.1.2 Condensation approach
Different records statistical information , certain level is maintained for each group. Before this we condense the data into known sized different groups. To maintain statistical information regarding the correlations and mean among the various dimensions, this statistical information is enough. It is impossible to differentiate among records from one another ,within a group. The privacy preserving
indistinguishability level means each group has a certain minimum size n. We can get more the privacy amount, whenever the indistinguishability level is more. The condensation of a larger number of records into a single statistical group entity, information amount loss is more. Condensed unit means each group of records. Put D a condensed group has the records {Y1 . . .Yn}. Also consider that each record Yi has the c dimensions which are denoted by (y1i. . . yci). Each group of records S has following data:
– We store the corresponding sum values of each attribute l. Its value is ∑i=1
n
xi l
. Corresponding first order sums by FRl(D). First order sums vector is denoted by FR(D).
– We keep corresponding attribute values the product sum, for each attributes pair i and l. It is equal to ∑t=1n xt i xtl.
Corresponding second order sums is Rcil(D). Then second order sums vector is Rc(D).
– Total number of records n in that group we have to keep, is noted by n(D).
Observations are:
1 The attribute l mean value in group D is given by FRl(D)/n(D).
2 In group D the covariance between attributes i and l is Rcil(D)/n(D) − FRi(D) · Fsl(D)/n(D)
2
. Group construction method will be decided based on the data records available in an incremental fashion or records an entire database is available .
Charu C. Aggarwal and Philip [7, 8] introduced Condensation approach. It gives information loss.
2.1.3 Cryptographic technique
To solve nature problems the privacy preserving data mining algorithms are developed. No party is like to open its own output to anyone, but two or more parties require to conduct a computation based on their private inputs. Without effecting the inputs privacy computation is required to be carried out. It is known as Secure Multiparty Computation (SMC) problem. Each participant has one input in a distributed network, Since computing a probabilistic function on any input is problem with SMC, computation must be correct , inputs could be independent, and after computation participant’s input and output only revealed to a participant.
Four secure multiparty computation algorithms are described in paper [1] these can support privacy preserving data mining. In this The set intersection secure size, the scalar product , the secure set union,the secure sum. Transformation framework was given in paper [9] with this transformation to secure multiparty computations from normal computations possible. Data clustering, data generalization ,data characterization ,association rule mining, data summarization and data classification, these data mining applications are described.
61
individual records[12]. Also, this method is not suitable whenever more than a few parties are involved.
2.1.4 Method of k- anonymity
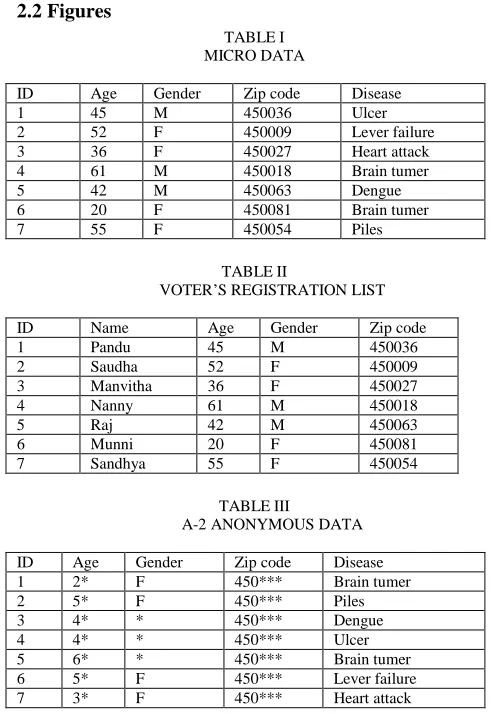
Open risks must be within allowable boundaries and data utilization is also maximum, these points must be considered whenever data is to be given for research. To limit open risk, in an anonymzed table each record must be different within the dataset ,with at least k-1 other records, with respect to a set of quasi-identifier attributes [11],it is k-anonymity privacy requirement, Sweeney introduced .For this, he used both suppression for data anonymization and generalization. Hiding of identity information from a communication or records called anonymization [5][13]. Micro data is available in Table I. Table II indicates registration data of voter’s. 2-anonymous generalization for Table I is in Table III. Nanny may be the person in the last three tuples of Table-3 even with the voter registration list, or to say that nanny real disease was known only with 33% probability. k-anonymity does not give enough security for attribute open, due to its limitations [14,16] . In paper [15] with external tables containing the individuals identities linking attack is performed and public attributes are taken all or some. This method has disadvantage of background attack and homogeneity.
2.2 Figures
TABLEI MICRO DATA
ID Age Gender Zip code Disease
1 45 M 450036 Ulcer
2 52 F 450009 Lever failure 3 36 F 450027 Heart attack 4 61 M 450018 Brain tumer
5 42 M 450063 Dengue
6 20 F 450081 Brain tumer
7 55 F 450054 Piles
TABLEII
VOTER’S REGISTRATION LIST ID Name Age Gender Zip code
1 Pandu 45 M 450036
2 Saudha 52 F 450009
3 Manvitha 36 F 450027
4 Nanny 61 M 450018
5 Raj 42 M 450063
6 Munni 20 F 450081
7 Sandhya 55 F 450054
TABLEIII
A-2 ANONYMOUS DATA
ID Age Gender Zip code Disease 1 2* F 450*** Brain tumer
2 5* F 450*** Piles
3 4* * 450*** Dengue
4 4* * 450*** Ulcer
5 6* * 450*** Brain tumer 6 5* F 450*** Lever failure 7 3* F 450*** Heart attack
III. EXISTING DIFFICULTY
Attribute transitional probability matrix is used to dataset U, then create the private dataset C, as we know it is for data privacy preserving, first, since B1,B2…..Bn are n
attributes for dataset U. Now on private dataset U k-anonymity method is applied. We found that it is not possible to get the U records by generalization and data randomization from C.
IV.
ADOPTED SOLUTION
Proposed algorithm has following advantages: 1) Reconstruction of data is possible.
2) It secures private data without information loss.
4.1 Algorithm
I. Inputs: Permutation Matrix Q and Original training dataset U.
II. Output: Derived table ,Conversed training dataset C. III. Procedure:1. From table U, pick one attribute. 2. Create permutation matrix Q with size v*v randomly. 3. To the column of U (U1,U2… Uv) ,randomly allot to
each Q (Q1, Q2… Qv) .
4.According to Q location highest value, U element to be rearranged. Take next highest location, if already used Q location, select left hand side value if two or more locations has same Q value.
5. U matrix to be recombined. 6. In table to be re-substituted.
7.Depending upon taken attribute apply K-anonymity on table.
8.Suppose numeric has lowest and highest value, generalization to be applied.
9. Stop.
In this from table U we have to take quasi identifier or attribute. Then it creates permutation matrix Q. Based on Q location highest value U elements are reorganized. Take next highest location, if already used Q location, select left hand side value if two or more locations has same Q value. In table U reenter all values. If numeric has lowest and highest value ,generalization to be applied.
4.2 An example
Table IV indicates medical data. Adopted solution application was explained in this example. Problem is sensitive attribute and zip code ,berth, gender, are quasi identifiers. To not release individuals identities in the medical data, names are not indicated. We are taken U1=
Berth year, U2= Gender, and U3= Zip Code from table IV.
62
TABLEV MEDICAL DATA
Sr.No. Berth Gender Zip code Problem 1 1971 M 7020181 Malaria 2 1976 F 7020008 Typhoid 3 1973 M 7020060 Lung cancer 4 1980 F 7020190 Brain death 5 1979 F 7020160 Sinus 6 1972 M 7020019 Polio 7 1977 F 7020063 Numonia 8 1975 F 7020019 Stomach pain 9 1974 M 7020060 Lung cancer
2 7 9 1 3 4 5 6 8 5 3 1 7 6 9 8 2 4 8 4 3 9 2 7 6 1 5 7 6 8 5 9 2 3 4 1 Q1 = 3 8 7 2 4 5 9 1 6
4 5 3 8 7 1 2 9 6 7 2 4 6 5 8 1 3 9 4 9 6 2 8 1 3 7 5 9 1 7 8 2 4 5 3 6
4 9 1 3 8 2 6 7 5 7 5 3 8 9 1 4 2 6 1 3 2 6 7 9 5 4 8 5 1 6 3 2 4 7 9 8 Q2 = 4 8 9 7 5 6 1 3 2
2 3 5 8 9 4 6 1 7 8 5 7 9 1 3 2 4 6 6 8 4 2 7 5 3 1 9 3 1 2 4 8 6 9 5 7
3 4 8 2 1 7 5 6 9 7 9 1 3 8 4 5 6 2 2 6 3 5 7 9 8 4 1 1 7 9 8 6 5 2 3 4 Q3 = 6 2 7 1 5 8 4 9 3
9 1 2 4 3 6 8 7 5 5 3 8 2 9 7 1 6 4 2 8 9 1 6 4 3 5 7 8 5 4 2 1 3 9 7 6
Randomly match like Q3 to U1, Q1 to U2 and Q2 to
U3. As per algorithm rules we select Q value in each line
i.e., choose Q location highest value , next highest location value is chosen if Q location is used already. Select the left hand side value to determine attributes values,if same two or more locations there. Each line largest value, in Q3
positions are 9, 2, 6,3, 8,1, 5,4 and 7 Then from U1 select
the 9th (1974), the 2nd (1976), the 6th(1972), the 3rd (1973) the 8th (1975), the 1st(1971), the 5th (1979), the 4th(1980) and the 7th(1977) to get C1.
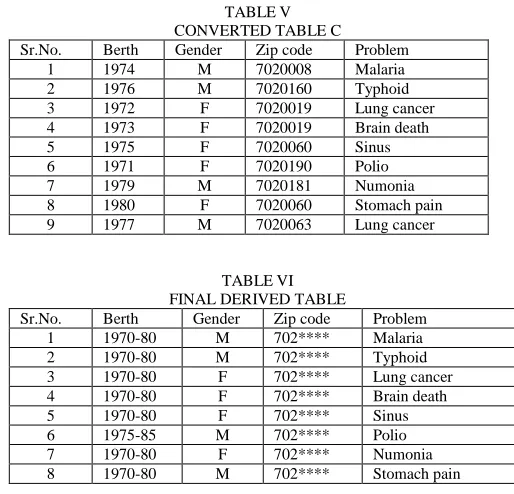
TABLEV CONVERTED TABLE C
Sr.No. Berth Gender Zip code Problem 1 1974 M 7020008 Malaria 2 1976 M 7020160 Typhoid 3 1972 F 7020019 Lung cancer 4 1973 F 7020019 Brain death 5 1975 F 7020060 Sinus 6 1971 F 7020190 Polio 7 1979 M 7020181 Numonia 8 1980 F 7020060 Stomach pain 9 1977 M 7020063 Lung cancer
TABLEVI FINAL DERIVED TABLE
Sr.No. Berth Gender Zip code Problem 1 1970-80 M 702**** Malaria 2 1970-80 M 702**** Typhoid 3 1970-80 F 702**** Lung cancer 4 1970-80 F 702**** Brain death 5 1970-80 F 702**** Sinus 6 1975-85 M 702**** Polio 7 1970-80 F 702**** Numonia 8 1970-80 M 702**** Stomach pain
We can get like this C2 and C3. We get converted
table C, after grouping these three matrices. After doing randomization method on medical data, we get Table V. Table VI indicates final derived table. By taking lowest and highest value numeric values are generalized.
In order from 1...m sensitive Attribute values are arranged. Suppression is indicated by ”*”. It is one way of generalization. 702**** indicates zip code range from 7020001 to 7029999.Duplicate values are removed.
4.3 Hill-cipher
Matrix manipulations is the heart of Hill-cipher. The athematician Lester Hill ,It is developed in 1929 and is a multi-letter cipher. In encryption, m cipher multi-letters are substituted in place of m successive plaintext letters. A numerical value was given for each character ,as:
a=0, b=1, ….. ….. z=25.
Plaintext place was replaced by cipher text letters ,then m linear equations will come. For m(block length)=3, the system can be described as follows:
B1=(P1 K11+P2 K21+P3 K31)MOD 26---(2.1)
B2=( P1 K12+P2 K22+P3 K32)MOD 26---(2.2)
B3=( P1 K13+P2 K23+P3 K33)MOD 26---(2.3)
It is represented with column vectors and matrices: B=PK B and P are column vectors of length 3, indicates the plaintext and the cipher text respectively . K is a (m*m)3*3 matrix, and is the encryption key. Mod 26 operations are must be performed. Matrix K inverse was needed for Decryption . Matrix K inverse ,K-1 is given as.
K K-1= I ---(2.4) , where I is the Identity matrix.
63
the plain text K-1 is multiplied to the cipher text. We can write as:
For encryption: B=Ek(P)= PK For decryption: P=Dk(B) = BK-1 = PKK-1=P
4.3 .1 Modular Arithmetic: A brief Analysis
Self repetitive matrix generation is valid for matrix of positive integers that are the residues of modulo arithmetic on a prime number. Addition, subtraction, Unary operation, Multiplication and division are the arithmetic operations presented here. The Modulo operator have the following properties:
1. a=b mod p if n| (a-b) 2. (a mod p)=(b mod p)=>a=b mod p 3. a=b mod p=>b=a mod p 4. a=b mod p and b=a mod p=>a=c mod p The modulo arithmetic have the following properties: Let z= [0,1,…..,p-1], the set residues modulo p. If modular arithmetic is performed within the set zn, the following equations present the arithmetic identities:
1. Addition: (a+b) mod p=[(a mod p)+(b mod p)]mod p 2. Subtraction: (a-b) mod p=[(a mod p)-(b mod p)]mod p 3. Multiplication: (a*b) mod p=[(a mod p)*(b mod p)]mod p 4. Negation: -a mod p=p-(a mod p) 5. Division: (a/b) mod P=c when a=(c*b) mod p 6. Multiplicative inverse: (a-1)=c if there exists (c*z) mod p=1 Below Table VII shows the properties of modulo arithmetic:
TABLEVII
MODULO ARITHMETIC PROPERTIES Sl. No. Property Expression
1 Commutative Law ( w + x ) mod p=( x + w ) mod p, (w*x) mod p= (x*w) mod p
2 Associative Law [( w + x )+y] mod p=[w+ (x + y)] mod p 3 Distributive Law [w*(x + y)] mod p=[w*x +w*y] mod p,
[w*(x * y)] mod p=[{w*x mod p}*{(w*y) mod p}] mod p 4 Identities (0+a) mod p=a mod p
and(1*a) mod p= a mod p 5 Inverse For each X belongs to zp , there exists y
such that (x + y) mod p =0 then y= -x. For each X belongs to zp, there exists y
such that (x*y) mod p=1
For any alphabetic attribute using Hill-cipher we are maintaining privacy and recovered original data also.
4.4 An example
After applying Algorithm for alphabetic attributes we have to apply Hill-cipher as it is. For alphabetic attributes divide numeric attribute into block of m letters. Each letter has two digits. Taking as an example m=2,then
K = 2 5 and P = 1970
9 4 = (19,70) =(19,18) (MOD 26)
Encryption: B=PK
= (19,18) *
= (19*2+18*9, 19*5+18*4) = (200,167)
= (18,11) (MOD 26)
Similarly for other numeric attribute values, of which length is even number to be calculated. For numeric attribute values,of which length is odd number to be calculated in the same way after adding leading digit as zero ,so that again length is even number.
V. DATA RECOVERY
Decryption: P = BK-1 = PKK-1
As we know that ,if K =
Then K-1 = (det(K)) -1 *
accordingly det(K) = K11 *K22 - K12* K21
= 2 *4- 5* 9
= -37
= 15 (MOD 26) (det(K)) -1 = 7 (MOD 26)
Now K-1 = 7 * =
= (MOD 26)
P = (18,11) *
= (18*2+11*15, 18*17+11*14) = (201,460)
= (19,18) (MOD 26)
Similarly for other numeric attribute values,this process to be done. For alphabetic attributes we have to apply Hill-cipher as it is.Then ,we get as converted table C as in Table VIII.
2 5
9 4
K11K12
K21K22
4 -5
- 9
2
28 -35
- 63
14
2 17
15
14
2 17
15
14
K22 -K12
64
TABLEVII CONVERTED TABLE C
Sr.No. Berth Gender Zip code Problem 1 1974 M 7020008 Malaria 2 1976 M 7020160 Typhoid 3 1972 F 7020019 Lung cancer 4 1973 F 7020019 Brain death 5 1975 F 7020060 Sinus 6 1971 F 7020190 Polio 7 1979 M 7020181 Numonia 8 1980 F 7020060 Stomach pain 9 1977 M 7020063 Lung cancer
Now ,we have to apply inverse algorithm on each sensitive attribute, so that we can get original data.By taking same permutation matrix Q, Randomly match like Q3 to U1, Q1 to U2 and Q2 to U3. As per algorithm rules we
select Q value in each line i.e., choose Q location highest value , next highest location value is chosen if Q location is used already. Select the left hand side value to determine attributes values, if same two or more locations there. Each line largest value, in Q3 positions are 9, 2, 6,3, 8,1, 5,4 and
7 .Then from Table VIII ,in U1 (= Berth year) select the1st
(1974), the 2nd (1976), the3rd (1972), the 4th (1973) the 5th (1975), the 6th (1971), the 7th (1979), the 8th (1980) and the 9th (1977) insert into 9th ,2nd ,6th ,3rd ,8th ,1st ,5th ,4th and 7th we get C1.
We can get like this C2 and C3. We get original
data as in Table IX, after grouping these three matrices.
TABLEIX ORIGINAL MEDICAL DATA Sr.No. Berth Gender Zip code Problem
1 1971 M 7020181 Malaria 2 1976 F 7020008 Typhoid 3 1973 M 7020060 Lung cancer 4 1980 F 7020190 Brain death 5 1979 F 7020160 Sinus 6 1972 M 7020019 Polio 7 1977 F 7020063 Numonia 8 1975 F 7020019 Stomach pain 9 1974 M 7020060 Lung cancer
V.
CONCLUSION
There are more privacy preserving techniques available, each one has atleast one disadvantage. In Privacy preserving field so much research is going on. Blocking method has disadvantage of loss of information. Anonymity procedure has drawback of background attack and homogeneity but it has data usability and privacy protection. Cryptography technique has shortcoming of more computational overhead and data usability but has privacy protection. Random perturbation also not has data usability. Condensation and randomized response also has information loss but preserve privacy. Hybrid approach includes K-anonymity and randomization technique. As we know K-anonymity method is suffering from background attack and homogeneity. Attacker unable to know data pattern with Randomization technique. So we
combined K-anonymity with randomization in the adopted solution. Data usability possible because it does not has information loss, so data reconstruction is possible and with better accuracy it protects private data. For attacker also it is difficult to identify homogeneity and background attack.
From above analysis using Hill-cipher technique it is known that, we can maintain privacy and also partial recovery of numerical attribute is possible, since I was taken data as (19,70) but I was got (19,18) only. To get original data of 70,how much to be added like 1*26,2*26 or 3*26 i.e, 26,52 or 78 to 18 confusion arises. To get exact numerical attribute value must be composed from numbers 01 to 26.Research to be done such that original data must be recoverable, if numerical attribute value not composed from numbers 01 to 26.This technique can be used wherever privacy maintenance is required. If we apply this technique, on data on which already Algorithm was applied, then we get more privacy.
REFERENCES
[1] Chris Clifton, Murat Kantarcioglou, Xiadong Lin, and Michael Y. Zhu, Tools for privacy preserving distributed data mining, SIGKDD Explorations 4 (2002), no. 2.. [2] Anita A. Parmar, Udai Pratap Rao, “Blocking Based approach for Classification Rule Hiding to Preserve the Privacy in Database”, International Symposium on Computer Science and Society (ISCCS) , pp.323-326, 2011.
[3] Jian Wang, Yongcheng Lou, Yen Zhao, Jiajin Le, “A Survey on Privacy Preserving Data Mining”, International Workshop on Database Technology and Applications, pp.111-114, 2009.
[4] Jinfei Liu, Jun Luo, and Joshua Zhexue Huang, “Rating: Privacy Preservation for Multiple Attributes with Different Sensitivity Requirements”, International conference on Data Mining Workshops, pp.666-670, 2011. [5] B.C.M. Fung, K. Wang, and P.S. Yu, “Anonymizing Classification Data for Privacy Preservation”, IEEE Trans. Knowledge and Data Eng., vol. 19, no. 5, pp. 711-725, May 2007.
[6] Agrawal, R. and Srikant, R, “Privacy-Preserving Data Mining”, Proceeding of Special Interest Group on Management of Data , pp. 439-450, 2000.
[7] Haisheng Li , “Study of Privacy Preserving Data Mining”, Third International Symposium on Intelligent Information Technology and Security Informatics, pp.700-703, 2010.
[8] Charu C. Aggarwal , Philip S. Yu, “A condensation approach to privacy preserving data mining”, International Conference on Extending Database Technology (EDBT), pp. 183–199, 2004.
65
Computer Sciences, Purdue University, West Lafayette, IN 47906, 2001.
[10] Vassilios S. Verykios, Elisa Bertino, “State-of-the-art in Privacy Preserving Data Mining”, Proceeding of Special Interest Group on Management of Data (SIGMOD) Record, Vol. 33, No. 1,pp.50-57, 2004.
[11] L. Sweeney, “K-anonymity: A Model for Protecting Privacy”, International Journal on Uncertainty, Fuzziness and Knowledge based Systems, pp. 557-570, 2002. [12] Y. Lindell , B.Pinkas, “Privacy preserving data mining”, Journal of Cryptology, 5(3), 2000.
[13] S.Vijayarani, A.Tamilarasi, M.Sampoorna, “Analysis of Privacy Preserving K Anonymity Methods and Techniques”, Proceedings of the International Conference on communication and Computational Intelligence, pp.540-545, December 2010.
[14] Yan Zhu, Lin Peng, “Study on K-anonymity Models of Sharing Medical Information”, International Conference on Service Systems and Service Management, pp.1-8, 2007.
[15] E. Poovammal , M. Ponnavaikko , “Task Independent Privacy Preserving Data Mining on Medical Dataset”, International Conference on Advances in Computing, Control and Telecommunication Technologies ,pp.815-818, 2009.
[16] Weijia Yang,“Knowledge Reserving in Privacy Preserving Data Mining”, Second international Symposium on Intelligent Information Technology Application, pp.855-859, 2008