Contextual Structure Analysis of the big data for Data Mining
G Manoj KumarM.Tech in Software Engineering Aurora‟s Technological & Research Institute,
parvathapur, uppal, Hyderabad-500039 Email id:[email protected]
G.Vara Lakshmi Assoc Proff in Computer Science Aurora‟s Technological & Research Institute,
parvathapur, uppal, Hyderabad-500039 Email id:[email protected]
161
ISSN: 2278 – 7798 All Rights Reserved © 2015 IJSETR
Abstract: We reside in a period of big data that has integrated a huge prospective, enhanced information complexity and also concerns like uncertainty and information overload as well as irrelevancy. Additionally business intelligence as well as analytics are significant in handling with the magnitude as well as affect of data derived issues and remedies in the modern society and industry. Experts, computer professionals, economists, mathematicians, political experts, sociologists, and various scholars are clamoring for use of the significant volumes of data if you wish to extract relevant data and information. Extremely large data sets are provided by resulting in organizations, people, also their alliance and relationships in the digital ecosystems as well as physical areas. Numerous groups dispute about the possible advantages, limitations, also risks of obtaining and evaluating huge quantities of data like financial information, genetic sequences, social media connections, medical documents, phone, e-mail logs, executive records, also remaining digital traces provided by people as well as organizations. Using the advancement of internet connection and alliance, data is having fun a central as well as vital role. Plenty of data extensive applications take place in recent times like the Google+, Twitter, and LinkedIn also Facebook and so on. Those data intensive derived programs generate as well as process significant data normally retained in the cloud.
While currently the phrase big data simply includes about data quantities, Wu et al. (2013) have revealed HACE proposition that outlined the key attributes of the big data. In this context we manage with a reputable capability to comprehend not only the data frameworks, that is in the instance of HACE (and the simplicity for a provided processing strategy), but also the data as well as business value that is taken out from big data. Index Terms—Big Data, data mining, heterogeneity, autonomous sources, complex and evolving associations
I. Introduction
In the former Oracle white report on Information Management Reference Architecture we characterized how “information” was at the center of all effective, lucrative and trustworthy business in the globe - something that‟s as true present as it was then. Advice is the center of each organization also though Information Management (IM) techniques are too frequently regarded as a obstacle to progress in the business instead of an enabler of it. At ideal IM is an obscure hero.
What has evolved in the recent years is the growth of “Big Data”, the two as a means of handling the massive amounts of ambiguous and semi-structured information retained but not used in numerous organizations, plus the prospective to tap towards new resources of insight like social-media web pages to build a market edge.
It represents to justification that inside the business segment Big Data has been used more quickly in data derived sectors, like financial services as well as
telecoms. Such providers have practiced a more speedy development in data quantities rather than other market areas, besides tighter regulatory specifications and falling productivity.
Several providers may have actually observed Big Data features as indicates to „manage down‟ the price of large scale data procedures or shrink the prices of following with new regulatory specifications. This has altered as more forward-looking organizations have comprehended the value production prospective when blended with their wider Information Management structures for making decisions, and applications structure for performance. There is a holding need for providers to align analytical as well as execution abilities with „Big Data‟ to be able to completely gain from the further information that can be accumulated.
Accepted wisdom recommends that above 80% of latest IT budgets is utilized just maintaining the lights on instead of allowing business to introduce or differentiate by themselves in the market. Financial facts are contracting budgets even additional, making
162
ISSN: 2278 – 7798 All Rights Reserved © 2015 IJSETR
IT‟s capability to change this expenditures mix a much more complicated task. For companies seeking to add some component of Big Data to specific IT portfolio, they should do so such that complements existing possibilities and cannot incorporate to the cost concern in coming years. An executive strategy is obviously what is needed.
II. Background and Research Approach Demirkan as well as Delen (2013) have described some research guidelines such as involved with practical statistics for big data. This indicates utilizing open-source, free-of-charge data/text mining methods also connected business tools (e.g. R, RapidMiner, Weka, Gate, etc.). New techniques {need to|should incorporate solutions for relocating these resources to the cloud as well as produce effective and economical solutions for discovering information and patterns from quite large/big data sets {directed to|sent to maintain business intelligence as well as selection support systems services.
The concepts of security-as-a-service, analytics-as-a-security-as-a-service, and data/information-as-a-service are revealed in the framework of utilizing SOA. Anyhow the cloud systems are not totally appropriate service oriented consideration also further there is a controversy that cloud computing is a variety of SOAs, also grid computing.
The primary determination of following cloud computing for statistics used for large (big) data models could be considering cloud systems are obtainable outside the an online provider interaction protected with firewalls. Cloud formulated business statistics are also affordable, effortless set up as well as test. The outcomes are simple to be shared outside the companies. Greg Sheldon, CIO of Elite Brands stated “The biggest benefit, is to be able to access a large quantities of data from anyplace you have web access, particularly on an iPad. This is advantageous to our field sales team when data is required on the fly.” (Fields, 2013:2)
The primary research queries are associated but not restricted to the appropriate aspects:
1. In the perspective of big data as well as cloud computing how statistics (e.g. data mining), info as well as knowledge handling procedures and techniques will change
2. What need to be the strategies, techniques and procedures to enhance the advantages and reduce the big data challenges
3. The prospective to lessen the increasing amount of security breaches as well as cyber-security issues and enhance firm awareness, business agility as well as durability
4. The current guidelines like data security law, limitations and specifications how should develop. Furthermore, the ethics concerns will be perceived.
III. Efforts and Challenges of Big Data Mining and Discovery
Thinking About big data a assortment of elaborate and spacious data sets that are complicated to procedure and mine for activities and understanding using conventional database procedures tools or data handling and mining techniques a briefing of the active efforts and difficulties is offered in this paragraph. Although now the phrase big data literally issues about data quantities, Wu et al. (2013) have propose HACE theorem that explained the key attributes of the big data as (1) massive with heterogeneous and different data sources, (2) independent with dispensed and decentralized control, and (3) complicated and growing in data and insights interaction.
Usually, business cleverness programs are utilizing data statistics that are seated commonly in data mining and analytical methods and strategies. These techniques are normally based on the grow commercial software techniques of RDBMS, data warehousing, OLAP, and BPM. Because the late 1980s, assorted data mining algorithms have become developed primarily within the artificial cleverness, and database communities. In the IEEE 2006 International Conference on Data Mining, the 10 most effective data mining algorithms were determined based on expert nominations, citation matters, and a community survey (Chen et al, 2012). In placed order, these methods are as follows C4.5, k-means, SVM (support vector machine), Apriori, EM (anticipation maximization), PageRank, AdaBoost, kNN (k-nearest neighbors), Naive Bayes, and CART (Wu et al, 2007). These Types Of algorithms are for definition, clustering, simple regression, association rules, and network research. Many of these well recognized data mining algorithms have become carried out and deployed in profitable and open provider data mining techniques (Witten et al. 2011). Chen at al. (2012) has contrasted data base administration systems and statistics as well as ETL with utilizing MapReduce and Hadoop. Hadoop was
163
ISSN: 2278 – 7798 All Rights Reserved © 2015 IJSETR
initially a (distributed) file system strategy applying the MapReduce framework which is a software strategy launched by Google in 2004 to assistance distributed calculating on large/big data units. Newly, Hadoop has been created and utilized as a complicated ecosystem that contains a wider range of software techniques, such as HBase (a dispensed table store), Zookeeper (a dependable coordination service), and the Pig and Hive high-level different languages that put together down MapReduce elements (Rabkin and Katz, 2013). Subsequently in the modern conceptual techniques Hadoop is mainly considered an ecosystem or an structure or a framework and not simply the file system along with MapReduce elements.
The big data and cloud computing frameworks consist of the Google MapReduce, Hadoop Reduce, Twister, Hadoop++, Haloop, and Spark etc. that are used to procedure big data and run computational work. The cloud databases are utilized to store significant planned and semi-structured data created from another types of programs. The many significant cloud databases consist of the BigTable, Hbase, and HadoopDB. In purchase to implement an effective big data mining and research framework, the data warehouse handling is also significant. The most significant data warehouse operating products include the Pig, Hive etc. Strambei (2012) recommends a another conceptual explanation of the OLAP system considering the introduction of web services, cloud computing and big data. One of the about important effects could be widely open entree to web logical technologies. The associated strategy has assessed the OLAP Web Services viability in the framework of the cloud based architectures.
Generally there are also a few revealed practical purposes of big data mining in the cloud. Patel et al. (2012) have investigated a practical answer to big data question using the Hadoop data cluster, Hadoop Distributed File System along with Map Reduce framework, and a big data prototype program scenarios. The outcomes acquired from various tests indicate guaranteeing results to manage big data problem.
The outcomes for moving further than existing data mining and information discovery techniques (NESSI, 2012) are dissimilar as follows:
1. A solid technical foundation to be intelligent to select an adequate analytical technique and a software design solution.
2. New algorithms (and show the competence and scalability, etc.) and machine knowledge techniques.
3. The enthusiasm of using cloud architecture for big data results and how to achieve the best presentation of implementing data analytics using cloud platform (e.g. big data as a examine).
4. Commerce with data protection and isolation in the context of groping or predictive study of big data.
5. Software platforms and architectures beside adequate knowledge and growth skills to be able to realize them.
6. A genuine ability to understand not only the data structures (and the usability for a given processing method), but also the information and business value that is extracted from big data.
IV. Data Pooling HACE-CSA Approach Clients with a additional essential notion in the appreciate that can be taken from the further weakly entered data usually opt for a Data Pooling strategy. The more apparent example of clients following this „build it and they will come‟ means is from the Ability agencies, but business corporations have also implemented this strategy for particular use cases these as for pooling web logs.
In this strategy, the main task is to establish a Hadoop cluster and occupy it with the obtainable information as a pool which can be dropped into to find anything is needed. Frequently this data is merged with definitely entered data approaching from whatever of the Data Warehouse levels but most usually the Basis or Entree and Efficiency Layers.
In numerous cases, the information required to manage any specific business difficulties will currently be present inside the data pool. If not really, the data pool might be enhanced with this unique information which may appear from any source and might be retained in our cluster. The leftover tasks of evaluating the data, generating a design of some kind and then utilizing the knowledge to incoming channels as correct are very a lot the same as earlier, but there are many variations in consequent implementation steps.
We can choose our fundamental pool of information to be component of the Basis Layer of our Data Warehouse. Although it will be actually implemented on a various set of technologies, realistically it suits
164
ISSN: 2278 – 7798 All Rights Reserved © 2015 IJSETR
our strongly entered information with weakly entered data. The information is our immutable supply of truth in simply the same means. Our process then is to include any new information that has become used in the evaluation to this pool of information; sometimes to the relational preserve if firmly entered or the Hadoop store normally. Any following modification steps formerly encoded in Map-Reduce jobs might need to be enhanced and made appropriate for a manufacturing setting and then incorporated as function of the ETL feed of our Warehouse. This downstream information then realistically gets part of our Entree and Efficiency Layer as it signifies an explanation of data and is not actuality.
V. PERFORMANCE ANALYSIS
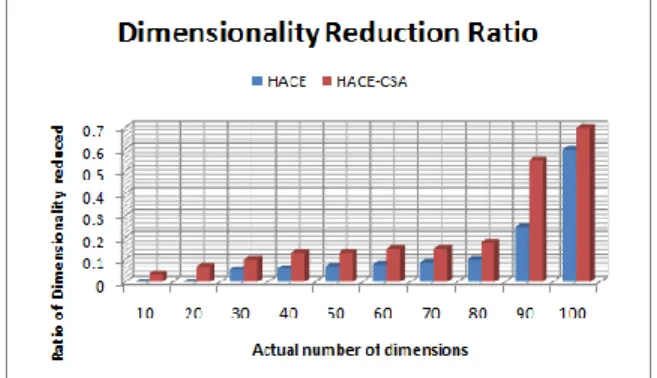
The experiments were done on HADOOP with clusters done. The given data search tasks are in the range of 100 to 1000 and task uniqueness is of 38% to 60%. The tasks given are on text data extraction for further mining and search routines build by MapReduce. The results explored are interesting and delivered the significance of HACE-CSA over HACE. The figure 1 concludes that the HACE is significant towards search and data extraction time, and by figure 2, it can be conclude that the HACE-CSA performed well towards dimensionality reduction.
Figure 1: A comparison chart that elevates the advantage HACE-CSA over HACE towards data search time
Figure 2: The ratio dimensions reduced by HACE and HACE-CSA
VI. Conclusion
The big data motion has stimulated the data mining, understanding discovery in information bases and connected software improvement areas, and it has launched complicated, fascinating questions for experts and practioners. As companies maintain to enhance the quantity and appreciates of accumulated data formalizing the procedure of big data evaluation and statistics becomes complicated. In this paper, we reveal some current techniques and have assessed the main search problems of big data mining, understanding, and designs breakthrough in a data concentrated cloud computing surroundings. This analysis will be developed offering theoretical and functional techniques that will be proven through the improvement of a situation study for the use of big data.
References
Chen, H., Chaing, R.H.L. and Storey, V.C. (2012) Business Intelligence and Analytics: From Big Data to Big Impact, MIS Quarterly, 36, 4, pp. 1165-1188 Chong, R.F. (2012) Changing the World: Big Data and the Cloud, The Atlantic. Available at: http://www.theatlantic.com/sponsored/ibm-cloud-rescue/archive/2012/09/changing-the- world-big-data-and-the-cloud/262065/ [Accessed by: 20 May, 2013]
Demirkan, H. and Delen, D. (2013) Leveraging the capabilities of service-oriented decision support systems: Putting analytics and big data in cloud, Decision Support Systems, 55, 1, pp. 412-421. European Commission (2010) The Future of Cloud Computing - Opportunities for European Cloud Beyond 2010, European Commission Public Report.
165
ISSN: 2278 – 7798 All Rights Reserved © 2015 IJSETR
Fields, E. (2013) Why Business Analytics in the Cloud?,Tableau Software White Paper. Grace, L. (2012) Basics about Cloud Computing, Software Engineering Institute, Carnegie Mellon University, USA at:
http://www.sei.cmu.edu/library/assets/whitepapers/Cl oudcomputingbasics.pdf
Mell, P. and Grance, T. (2009) The NIST definition of cloud computing v15. Version 15 available at
http://csrc.nist.gov/groups/SNS/cloud-computing/cloud-def-v15.doc
McKinsey Global Institute (2011) Big Data: The next frontier for innovation, competition and productivity. NESSI (2012) Big Data - A New World of Opportunities, White Paper.
Rabkin, A. and Katz, R.H. (2013) How Hadoop Clusters Break, IEEE Software, Feature: Big Data, pp. 88-94
Patel, A.B., Birla, M. and Nair, U. (2012) Addressing Big Data Problem Using Hadoop and Map Reduce, NIRMA University Conference on Engineering, NUiCONE, pp. 1-5. Rittinghouse, J.W. and Ransome, J.F. (2010) Cloud Computing Implementation, Management and Security, CRC Press Taylor and Francis.
Schouten, E., (2012) Big Data 'as a Service'. The
Atlantic. Available at:
http://www.theatlantic.com/sponsored/ibm-cloud-rescue/archive/2012/09/big-data-as-a-
service/262461/ [Accessed by: 20 May, 2013] Strambei, C. (2012) OLAP Services on Cloud Architecture, Journal of Software & Systems Development, IBIMA Publishing.
Witten, I.H., Frank, E. and Hall, M.A. (2011) Data Mining: Practical Machine Learning Tools and Techniques. 3rdedtion. Morgan Kaufamann series in data management systems.
Wu, X., Kumar, V., Quinlan, J. R., Ghosh, J., Yang, Q., Motoda, H.,McLachlan, G. J., Ng, A., Liu, B., Yu, P.S., Zhou, Z.-H., Steinbach, M., Hand, D. J., and Steinberg, D. (2007). Top 10 Algorithms in Data Mining, Knowledge and Information Systems, 14,1, pp. 1-37.
Wu, X. , Zhu, X., Wu, G., Ding, W. (2013) Data Mining with Big Data, Knowledge and Data Engineering, IEEE Transactions, in press
World Economic Forum (2012). Big Data, Big Impact: New Possibilities for International Development. World Economic Forum Report.