warwick.ac.uk/lib-publications
A Thesis Submitted for the Degree of PhD at the University of Warwick
Permanent WRAP URL:
http://wrap.warwick.ac.uk/94683
Copyright and reuse:
This thesis is made available online and is protected by original copyright.
Please scroll down to view the document itself.
Please refer to the repository record for this item for information to help you to cite it.
Our policy information is available from the repository home page.
Imitation Learning in Artificial Intelligence
by
Alexandros Gkiokas
Thesis
Submitted to the University of Warwick
for the degree of Computer Science.
Supervisor: Alexandra I. Cristea
Doctor of Philosophy
Department of Computer Science
Contents
Acknowledgments v
Declarations vi
Abstract vii
Abbreviations viii
List of Tables xi
List of Figures xii
Chapter 1 Introduction 1
1.1 Human Intelligence . . . 1
1.2 Imitation in Humans . . . 2
1.3 Imitation in Artificial Intelligence . . . 3
1.4 Cognitive Artificial Intelligence . . . 4
1.5 Icarus Engine . . . 5
1.6 Research Scope & Biological Plausibility . . . 6
1.7 Contributions . . . 8
1.8 Thesis Overview . . . 9
Chapter 2 Background and Literature Review 10 2.1 Alan Turing and the intelligent machines . . . 10
2.2 Imitation in Nature . . . 11
2.2.1 What is imitation? . . . 11
2.2.2 How does imitation work? . . . 12
2.3 Symbolic Artificial Intelligence . . . 13
2.3.1 Knowledge Representation . . . 14
2.4 Connectionistic Artificial Intelligence . . . 19
2.4.1 Artificial Neural Networks . . . 19
2.4.2 General Purpose Computing on Graphic Processing Units . . 24
2.4.3 Deep Learning . . . 24
2.4.4 Reinforcement Learning . . . 28
2.4.5 Deep Reinforcement Learning . . . 31
2.4.6 Connectionism Criticism and Limitations . . . 32
2.5 Cognitive or Synthetic Artificial Intelligence . . . 33
2.5.1 Bach and Synthetic Intelligence . . . 33
2.5.2 Haikonen and Cognitive Intelligence . . . 34
2.5.3 Five Cognitive Agent Criteria . . . 36
2.5.4 AI Architectures . . . 37
2.6 Programming by Example . . . 40
2.6.1 PBE: Theory and Models . . . 40
2.6.2 PBE: Application Domains and Criticism . . . 43
2.6.3 PBE: Differences from Imitation Learning . . . 44
2.7 Parsing and Understanding . . . 44
2.7.1 Semantics . . . 44
2.7.2 Distributional Semantics . . . 45
2.7.3 Relational Semantics . . . 46
2.7.4 Part of Speech Tagging . . . 48
2.7.5 Semantic and Syntactic Parsing . . . 48
2.7.6 Implementing Parsing and NLU . . . 50
2.7.7 Models and Algorithms in NLU . . . 52
2.7.8 NLU Performance and Issues . . . 53
2.8 Background Conclusion . . . 54
Chapter 3 Theory and Agent Design 56 3.1 MDP as a Template for Learning . . . 57
3.2 Paradigm Decomposition and Training . . . 58
3.3 Rewarding and Evaluation . . . 62
3.4 Episode Iteration and Inference . . . 63
3.5 Decision Making and Policy Approximation . . . 64
3.6 Statistical and Probabilistic Approximation . . . 67
3.7 Semantic and Heuristic Approximation . . . 68
3.8 Neural Approximation and Distributed Encoding . . . 70
3.10 Semantic Approximation and Sparse Encoding . . . 74
3.11 Conceptual Graph Output . . . 75
3.12 Metalearning and Knowledge Compression . . . 76
3.12.1 Metalearning on Learnt Knowledge . . . 76
3.12.2 Grouping by Similarity . . . 76
3.12.3 Generalising Cluster Graphs . . . 77
3.12.4 Optimisation by Belief Evaluation . . . 78
3.13 Conclusion . . . 78
3.13.1 Bandura and Imitation in Humans . . . 79
3.13.2 Haikonen and Cognitive AI . . . 79
3.13.3 Bach and Synthetic Intelligence . . . 80
3.13.4 Five Cognitive Agent Criteria . . . 81
3.13.5 Icarus and Cognitive AI . . . 81
3.13.6 Discussion on Icarus Implementation . . . 82
Chapter 4 Conceptual Graph Dataset 83 4.1 Datasets for NLU and NLP . . . 84
4.1.1 Creating a New Dataset . . . 85
4.1.2 Partitioning the Dataset . . . 86
4.1.3 Translating and Converting Datasets . . . 87
4.2 Conceptual Graph Complexity . . . 88
4.2.1 Graph Columns and Linearity . . . 89
4.2.2 Graph Branching and Grouping . . . 90
4.2.3 Graphs and Operators . . . 90
4.3 Dataset Conclusion . . . 91
Chapter 5 Experiments, Methodology and Results 92 5.1 Methodology and Experiment Design . . . 92
5.1.1 Randomised Block Design . . . 93
5.1.2 Experiment Logs . . . 93
5.1.3 Accuracy Measures . . . 95
5.2 Semantic-Heuristic Experiments . . . 97
5.2.1 Implementation . . . 97
5.2.2 Results and Discussion . . . 99
5.3 Probability-based Experiments . . . 101
5.3.1 Implementation . . . 101
5.3.2 Probability Space Analysis . . . 103
5.3.4 Discussion & Conclusion . . . 109
5.4 Shallow Neural Experiments . . . 110
5.4.1 Implementation . . . 110
5.4.2 Results . . . 114
5.5 Deep Learning Experiments . . . 118
5.5.1 Implementation . . . 118
5.5.2 Results . . . 122
5.6 Experiment Conclusions . . . 126
Chapter 6 Conclusions and Future Work 129 6.1 Conclusions . . . 129
6.2 Criticism and Limitations . . . 132
6.3 Future Work . . . 133
Appendix A Penn Treebank POS tags 135
Acknowledgments
I would like to express my sincere gratitude to my supervisor Alexandra Cristea,
without whom this thesis and research would never have taken place. My parents
George and Maria, for never giving up on me and always believing. My current
employer Stratos Arampatzis and Ortelio Ltd, as well as my previous employer
Matthew Sewell and Athium Ltd, for their support, funding and understanding.
Karen Stepanyan and Panagiotis Petridis for putting up with my questions, offering
their support and advice, and guiding me through this adventure. Finally, Mina
Makridi for putting up with me and for the past four years, and entertaining the
Declarations
This thesis is submitted to the University of Warwick in support of my application
for the degree of Doctor of Philosophy. All experimental data presented and
sim-ulations were carried out by the author, except in the following cases: Daedalus
experiments were done on-line after being approved by the BSREC with
refer-ence REGO-2015-1529. All experiments for Daedalus were carried out on the web
and they represent anonymous data. Chapter 3 contains theoretical formulations
[Gkiokas et al., 2014] carried out in cooperation with Matthew Thorpe from the
Mathematics Institute in Warwick. Parts of this thesis have been published by the
author, including submitted papers:
- Training a Cognitive Agent to Acquire and Represent Knowledge from RSS
feeds onto Conceptual Graphs [Gkiokas and Cristea, 2014a].
- Unsupervised neural controller for Reinforcement Learning action-selection:
Learning to represent knowledge [Gkiokas and Cristea, 2014b].
- Self-reinforced meta learning for belief generation [Gkiokas et al., 2014].
- Cognitive Agents and Machine Learning by Example: Representation with
Conceptual Graphs [Gkiokas and Cristea, 2016a].
- Deep Learning and Encoding in Natural Language Understanding: Sparse
and Dense Encoding Schemes for Neural-based Parsing [Gkiokas and Cristea,
Abstract
Acquiring new knowledge often requires an agent or a system to explore, search and
discover. Yet us humans build upon the knowledge of our forefathers, as did they,
using previous knowledge; there does exist a mechanism which allows transference
of knowledge without searching, exploration or discovery. That mechanism is known
as imitation and it exists everywhere in nature; in animals, insects, primates, and
humans. Enabling artificial, cognitive and software agents to learn by imitation
could potentially be crucial to the emergence of the field of autonomous systems,
robotics, cyber-physical and software agents. Imitation in AI implies that agents
can learn from their human users, other AI agents, through observation or using
physical interaction in robotics, and therefore learn a lot faster and easier.
Describing an imitation learning framework in AI which uses the Internet as
the source of knowledge requires a rather unconventional approach: the procedure
is a temporal-sequential process which uses reinforcement based on behaviouristic
Psychology, deep learning and a plethora of other Algorithms. Ergo an agent using a
hybrid simulating-emulating strategy is formulated, implemented and experimented
with. That agent learns from RSS feeds using examples provided by the user; it
adheres to previous research work and theoretical foundations and demonstrates
that not only is imitation learning in AI possible, but it compares and in some cases
Abbreviations
ADABOOST Adaptive Boosting
AGI Artificial General Intelligence
ANN Artificial Neural Networks
AI Artificial Intelligence
BFGS Broyden-Fletcher-Goldfarb-Shanno
BPROP Back Propagtion
CA Cognitive Agent
CE Cross Entropy
CG Conceptual Graph
CNN Convolutional Neural Networks
CRF Conditional Random Field
DARPA Defense Advanced Research Projects Agency
DNN Deep Neural Networks
FOL First Order Logic
FSM Finite State Machine
GOFAI Good Old Fashioned Artificial Intelligence
HOL Higher Order Logic
KR Knowledge Representation
LBFGS Limited storage Broyden-Fletcher-Goldfarb-Shanno
LMA Levenberg-Marquardt Algorithm
LSTM Long Short Term Memory
MBSGD Mini Batch Stochastic Gradient Descent
MDP Markov Decision Process
ML Machine Learning
MRL Meaning Representation Language
MSE Mean Squared Error
NLP Natural Language Processing
NLU Natural Language Understanding
PBD Programming by Demonstration
PBE Programming by Example
POS Part Of Speech
RBM Restricted Boltzmann Machine
ReLU Rectified Linear Unit
RNN Recurrent Neural Network
RPROP Resilient Propagation
SVM Support Vector Machine
List of Tables
2.1 State of the Art NLU Software Tools. . . 50
4.1 Common NLP Datasets . . . 84
5.1 Accuracy Metrics Equivalence. . . 97
List of Figures
2.1 Simple MRL structure. . . 15
2.2 MRL with Edges. . . 16
2.3 Annotated MRL with Edges and Meta-data. . . 16
2.4 Conceptual Graph example. . . 17
2.5 Conceptual Graph Directed Edges. . . 17
2.6 Example of a Neural Network. . . 20
2.7 Example of a deep fully connected neural network. . . 25
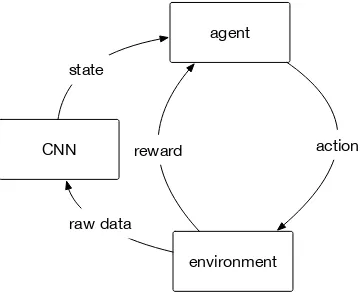
2.8 Reinforcement Learning Episode. . . 28
2.9 Reinforcement Learning Agent Interaction with Environment. . . 29
2.10 Rewarding the Terminal State . . . 29
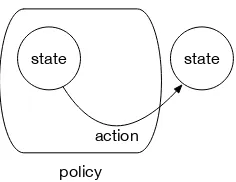
2.11 Example of a Policy. . . 30
2.12 Epicentre of Multiple Episodes. . . 30
2.13 Deep Reinforcement Learning Agent & Environment. . . 31
2.14 Knowledge sharing by agent and user . . . 42
2.15 WordNet Semantic Tree Graph. . . 47
3.1 Icarus Engine Blueprint. . . 56
3.2 Agent Observes Example . . . 59
3.3 Agent Recreates Example . . . 59
3.4 Agent Decomposes Example . . . 60
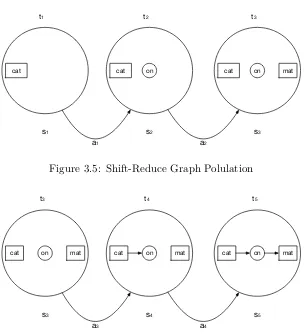
3.5 Shift-Reduce Graph Polulation . . . 61
3.6 Shift-Reduce Edge Creation . . . 61
3.7 Agent as a Decision Maker. . . 65
3.8 Decision Making Process. . . 66
3.9 Semantic Graph Union. . . 69
3.10 Deep Learning Cascade. . . 73
4.1 A CG example . . . 83
4.3 Clustering Coefficient: CG rhombus versus KR triplet . . . 89
5.1 Semantic-Heuristic Accuracy. . . 100
5.2 Probability Histograms. . . 104
5.3 Probability Value Map . . . 105
5.4 Probability Accuracy and Action Ratios. . . 107
5.5 Filtering withθ . . . 108
5.6 Cyclic Process: MDP to Statistics to ANN . . . 113
5.7 ANN Classifying and Mapping Search Space. . . 115
5.8 ANN Accuracy. . . 116
5.9 Sparse POS and Distributed Term Classifiers . . . 123
5.10 Sparse-Encoded POS and Term Edge Classifiers . . . 124
5.11 Sparse-Encoded Term Edge and Distributed-Encoded POS Classifier 125 5.12 Distributed Term Edges and Distributed POS Edges . . . 126
5.13 Complexity Mapping to Accuracy PCA . . . 127
B.1 Synthetic marijuana is made with shredded plant material coated with chemicals designed to mimic THC psychoactive compound found in marijuana. . . 138
B.2 Artificial magnetic bacteria turn food into natural drugs. . . 139
B.3 Ataluren Phase 3 trial results in nonsense mutation cystic fibrosis. . 140
B.4 UK drug company AstraZeneca rejects improved final £69 billion takeover offer from US firm Pfizer. . . 141
B.5 Lewy body dementia is most misdiagnosed dementia affecting 13 mil-lion Americans. . . 142
B.6 Action star has got himself tank and destroys piano and birthday cake with it. . . 143
B.7 Plan to offer better care and treatment for 500000 patients living with neurological conditions. . . 144
B.8 Each cell uses particular schemes of molecular interaction which psy-chologists call intercellular signaling pathways. . . 145
B.9 Branching with Column Graphs . . . 146
Chapter 1
Introduction
In the never-ending quest for Artificial Intelligence (AI), we take example from our-selves and our own intellect, since we are what we believe to be the most intelligent
species on the planet. Intelligence however, did not spontaneously come into
ex-istence, but was the result of a painstaking process of evolution [Bjorklund, 2006; Wynn, 1985; Sternberg, 1982]; even more interestingly, scientists argue that there
exist multiple intelligences and not just one [Gardner, 2011]. How those intelligences
arose is a topic biologists, geneticists and psychologists researching human intelli-gence have been working on for more than a century; yet their beliefs and theories
directly affect computer scientists working on AI. Our focus are machines: robots,
software and hardware, artificial artifacts, upon which humanity is trying to instill
intelligence and make them as smart as humans. Yet we cannot dismiss how
hu-man intelligence arose as outside the scope of AI, not only because it may be very
relevant to the actual processes we’re trying to recreate, in that there may be cru-cial information in the emerge of intelligence in Homininae, information that could
make Artificial General Intelligence (AGI) a reality (AGI as in, an irrefutably
in-telligent, sentient and self-aware technological singularity [Goertzel and Pennachin, 2007; Kurzweil, 2005]).
1.1
Human Intelligence
Nowadays we know that one of the pieces of the puzzle that aided the emergence of
intelligence isimitation[Dautenhahn and Nehaniv, 2002b]. Not only did imitation
aid human intelligence, but there is overwhelming evidence in nature which suggests that imitation is one of the core mechanisms behind intelligence in animals, insects
2002; Galef Jr, 1988]. It is human intelligence that interests us the most, and there
have been speculations that the ”great leap forward”, a period 200,000 years ago
when our intellect exploded and we started creating tools, is mostly attributed
to our ability to imitate [Ramachandran, 2000] in combination with our tendency
to congregate and socialise. Thus it appears that the two driving factors of the
leap forward were the development of communities and the ability to learn from
others. By doing so, theknowledge of previous generations was passed down to the
next generations, and thus individual knowledge, and by extension the collective knowledge began accumulating [Jones, 2009]. Through imitation, human societies
taught their offspring how to create tools, how to farm, and most importantly how
to survive. It thus becomes apparent that learning and imitation are closely knit
together [Heyes, 2002]; we can’t have imitation without the ability to learn, and,
vice-versa, being able to learn is of questionable use when there exists no mechanism
through which to acquire learning material.
1.2
Imitation in Humans
Imitation is a very broad term but appears to be a low-level to mid-level ability
of identifying examples, and learning from peers either via direct demonstration
or from observation [Dautenhahn and Nehaniv, 2002a]. Contemporary researchers
argue that imitation is a unitary competency, a behavioural process that could have evolved as a unit and can be inherited as well as shared across a species
[Myowa-Yamakoshi et al., 2004; Ferrari et al., 2006]. The implication of this argument is
that in AI an imitation process is something that can be learnt; an algorithm, a
heuristic or a cybernetic system.
Other researchers add that a neurological mechanism enables imitation in
humans [Iacoboni and Dapretto, 2006; Iacoboni, 2005; Gr`ezes et al., 2003; Decety
et al., 2002; Iacoboni et al., 1999] known as the ”mirror system”. Whilst the
neuron-based imitation in humans is not fully understood, such a hypothesis could imply
that an artificial neural-based imitation system could in theory be implemented.
However, it is not currently known if the mirror system enables higher cognitive
functions, or only sensor-motor functions [Bonini and Ferrari, 2011], although there
exists evidence to suggest that social and higher level functions are indeedpartially
attributed to the mirror-system.
There exist many types of imitation: high-level, physical, hierarchical,
struc-tured and more [Dautenhahn and Nehaniv, 2002a]. Imitation may be supervised
when observation is the only means of acquiring learning material.
1.3
Imitation in Artificial Intelligence
Artificial imitation research has mostly focused on Robotics, in order to achieve a
similar process to how infants learn movement and sensormotor abilities [Suleiman
et al., 2008; Nakaoka et al., 2007; Breazeal et al., 2005; Breazeal and Scassellati, 2002]. Artificial imitation in applications not related to robotics deals mostly with
programming by example (PBE) also known as programming by demonstration (PBD), the only imitation-related topic in non-robotic AI [Lieberman, 2001, 2000;
Halbert, 1984]. Research in PBE/PBD is more than 15 years old, and was mostly
concerned with programming and focused on user interfaces (UI). Regardless of the
advent and subsequent sunset of PBE, imitation as a learning mechanism for AI,
and more specifically for software agents, has been ignored and is to this very day
an esoteric and perplexing topic.
The transition from PBE to AI agents is not an easy one; whereas PBE was
concerned only with programming, AI agents are focusing on autonomy, learning,
self-organisation, knowledge representation, logic and reasoning. An imitating AI
agent is an even more peculiar entity: it does utilise the aforementioned topics, but
it revolves around the combination of learning via imitation.
The notion that imitation is not learning is often perplexing, the reason
being that learning is the main focal point of an agent without describinghow the
training material or samples have been acquired and used. Imitation thus focuses
on acquiring learning material, training samples, data or information which is of use to the agent, and serves the purpose of acquiring new behaviours, performing new
tasks or procedures [Dautenhahn and Nehaniv, 2002a]
Whilst learning and imitation are sometimes used interchangeably in AI and machine learning (ML), fundamentally they are different. The way in which the
model, agent or algorithm acquires information and translates it into knowledge, is
what differentiates learning from imitation [Dautenhahn and Nehaniv, 2002a]. A neural network being trained and evaluated by a user displays no form of
imitation; yet an autonomous, self-trained and self-evaluating agent requires that it
is able to identify paradigms from which it can extract samples, pre-process them,
and then use them appropriately so that learning may occur. Before acquiring
learning material an imitating agent must be able to extract or decode some kind of a paradigm which relates to what is being learnt. Post learning the agent should be
to other agents [Lawniczak and Di Stefano, 2010].
1.4
Cognitive Artificial Intelligence
Due to the cognitive nature of such agents this research further explores cognitive AI
and AI architectures. The termcognitive agent (CA) interchangeably used with the
term ”cognitive AI”, requires that the agent must meet certain criteria [Lawniczak and Di Stefano, 2010].
- perceive information in the environment provided by other agents
- reason about this information using existing knowledge
- judge the obtained information using existing knowledge
- respond to other agents
- learn and augment current knowledge if newly acquired information allows it.
The above basic criteria set the bar for a cognitive agent, but an imitating agent
has additional requirements, which are discussed in detail in Chapter 2.
This thesis sets the imitation requirements by taking into consideration the
cognitive nature of such systems; the core premise of the imitative ability being the acquisition of knowledge by the agent and by drawing parallelisms from the
observable, ostensible and discernible processes of the human cognitive system,
thereby recreating the outcome of that process. Whilst the goal is not to produce a biologically-plausible system, the agent is driven by biomimicry since it
demon-strates how AI might mimic human intelligence.
From the background research and work carried out in the last two decades, it can be asserted that imitation is not a unitary model, a finite-state machine
(FSM) or an algorithm, nor is it a theoretical abstract; it is in fact a group of
models, algorithms, a fusion or cascade of existing and new models into a software middle-ware, an agent. However imitation in AI and in robotics has not delivered its
promises; PBE has eclipsed as a field, and robotics to this very day still depend on
heuristic controllers. High level cognitive functions are usually programmed rather
than learnt and few state-of-the-art experimental research have so far focused on
learning by imitation. The main research question is therefore:
Due to recent developments in deep learning and cognitive AI and because of
the complexity of such agents, this thesis implements an agent using an AI existing
architecture: the Icarus cognitive model developed by Stanford University
[Lang-ley et al., 2003]. Icarus is a hybrid cognitive AI architecture, funded by Defence
Advanced Research Projects Agency (DARPA) Information Processing Techniques Office, United States Office of Naval Research, and the Unites States National
Sci-ence Foundation. It incorporates various models from across computer sciSci-ence, and
it mainly focuses onaction and perception over cognition.
Furthermore, Icarus separates categories from skills, uses a hierarchical
struc-ture for long-term memory [Langley et al., 2004] and usescorrespondence between
short-term and long-term memory [Langley et al., 2009]. Those four fundamental notions of Icarus are the basis upon which we draw comparison with the biological
counterpart and the human imitation mechanisms and implement the set of those
mechanisms in software. The advantages of implementing Icarus as a software cog-nitive agent are that it allows to examine the abilities, algorithms, processes and
qualities that anartificially imitating learning agentshould or mayposes, formulate
a theoretical model, examine the hypotheses via experimentation, and consolidate our conclusions through evaluation.
1.5
Icarus Engine
The Icarus implementation (called hereinafterIcarus engine) is greatly inspired by
PBE which has its roots in Henry Lieberman’s work [Lieberman, 2001]. However
in stark comparison to Lieberman’s PBE (described in Chapter 2.6), in this thesis Icarus is deployed as a stand-alone autonomous agent with the sole purpose of
acquiring knowledge from the Internet.
The reason for aiming at acquiring knowledge from the Internet is its ubiq-uitous nature. According to the United Nations Telecommunications development
Sector (ITU-D) around 40% of the global population has Internet access [Pe˜
na-L´opez et al., 2009], and most of those users generate content, information, news,
knowledge and data. Most of the human knowledge is being accumulated on the
Internet, either in open and public sites such asWikipedia or in specialist platforms,
suchQuora orStackExchange. Other knowledge engines (such asWolfram Alpha or
DBpedia) offer tailored meta-data, and last but not least, the blogs, new-sites, RSS
feeds and social networks all provide free information and knowledge. Hence, the
core research question is rephrased as:
Using the largest knowledge pool in the history of the human civilisation is
a promising source from which future AI agents can mature and reach higher-levels of intelligence. Thus the Icarus engine aims to acquire knowledge extracted from
widely and freely available information found on the Internet. The Icarus engine is
the first step towards an agent which learns by being taught”how to read and
under-stand” the Internet data thereby transforming information into knowledge. Albeit
the domain is natural language, it is not constrained by algorithms or models
tai-lored for natural language processing (NLP) and should be able to parse and acquire knowledge from other domains. Its main purpose is to project textual information
found on the Internet onto a knowledge representation (KR) structure. It does that
by satisfying all the cognitive agent (CA) criteria set by [Lawniczak and Di
Ste-fano, 2010], but it is not limited by finite-states or heuristics. Furthermore, the
way thememory is organised adheres to the Icarus specifications of a hierarchical
and structured knowledge index, with corresponding short and long term memory.
The Icarus engine is in a sense a parser, which instead of being programmed how
to parse, learns how to parse by example. By doing so, this thesis researches and
experiments into the specifics ofimitation learning and extracts conclusions about
the suitability of such agents and systems for cognitive AI functionality.
1.6
Research Scope & Biological Plausibility
Choosing to implement such a CA as a parsing agent is due to the fact that such
an ability is considered to be one of the high-level developmental steps in humans:
learning to read and understand information [Stuart and Coltheart, 1988]. The
approach taken is that of simulation: the process of mimicking the outwardly
ob-servable behaviour of children who learn how to read by being shown repeatedly
text inputs of various (usually increasing) sizes. This thesis focuses on the third and fourth state of reading development [Seymour, 1999] due to the fact that those
are the stages where decoding and hierarchical structuring develops. However, the
work reported in this thesis draws no parallelism to the human brain, nor does it
claim tosimulate the same processes. Yet the choices of machine learning (ML) are
all biologically-inspired, some based on behaviourist psychology, others use
artifi-cial neural networks, and only a handful are mathematical or heuristic components.
This approach is thus indirectly based on thehuman information processing models
[Berger et al., 2013], but does not implement them or as a whole; it only appears
to be functioning in a similar way, in order to achieve similar goals, however as a
The advantage of taking this approach outweighs the effort of designing and
implementing what can seem to be a complex agent: first and foremost the work is
focused on an artificial agent which does not rely on pre-programmed logic but on
learnt logic. This agent’s learning is not constrained by the logic embedded in the
program, but is adaptive and flexible. The implementation and experimentation of
the Icarus engine theory is based upon the following rationale: not programming
an agent, only teaching it. Whereas the actual implementation does indeed require
to be programmed, it is done via a neuro-dynamic agent [Bertsekas and Tsitsiklis,
1995] using abehaviouristapproach, similar to how humans learn from reinforcement
Thorndike [1901]; Galef Jr [1988].
The advantages ofimitation in AI are the same as the premise of imitation
in nature; allowing agents to acquire knowledge and information from their peers,
their social structure and our society, as well as surviving and evolving into capable
entities. The implied novelty of imitating agents (cognitive or not) is promising: AI software which can seamlessly and effortlessly acquire and manipulate knowledge
and information from humans directly or indirectly (through the internet), robots
which can learn how to reason and use logic by example and through observing human interactions, and much more. A comparison between traditional software
systems and imitating agents can thus provide the incentive to further explore imi-tation and support the usage of such agents in real-life applications. The advantages
of enabling autonomous agents and systems to acquire and evolve their knowledge
base only recently have been explored as corporations are gearing towards AI as-sistants, such as Microsoft’s Cortana, Apple’s Sirii, and Amazon’s Alexa. It is a
fact that such AI agents require imitation because it is the only known mechanism
through which passive observation and proactive teaching enables information and knowledge to be acquired and manipulated. Therefore less central but still
impor-tant research questions are:
- What are the differences between learning by imitation and programming by example [Lieberman, 2001]?
- What are the advantages of agents which learn by imitation? [Dautenhahn
and Nehaniv, 2002a]
- How do artificially imitating agents compare to traditional software systems?
Other questions related to the imitation learning literature [Dautenhahn and
Nehaniv, 2002a], such as ”what makes a good teacher?” are still inherently relevant,
in AI has numerous applications and can be applied in a variety of ways with the
potential to change high-level cognitive functions, such aslearning, reasoning, logic,
decision-making, etc. Although all those areas are relevant and applicable to the
work described hereinafter, it would be impossible to include them all, experiment
with a broad array of applications, or address all the entailing issues from each of
those fields. Therefore, our only scope islearning and not logic, reasoning or other
cognitive abilities. However, the Icarus engine sets a basis upon which logic and
reasoning can take place in addition to learning using our theoretical model and software engine.
1.7
Contributions
- The main and foremost contribution to the field of AI is the formulation and
combinationof a Markov decision process (MDP) in atemporal-spatial fashion
through which learning of symbolic KR structures (conceptual graphs) takes
place [Gkiokas and Cristea, 2014a].
- This novel approach enables reinforcement learning [Sutton and Barto, 1998]
to manipulate as an episodic process the creation and representation of a KR structure learnt by example.
- The importance of this contribution is explained in detail in Chapter 3 and
challenges the way in which symbolic and connectionistic AI deal with data
and knowledge, due to it demonstratinghow those two foundational approaches
in AI can be bridged.
- Furthermore, I address ”learning by imitation” at the highest possible level in
AI, that of symbolism, but learn it via reinforcement and deep learning.
- The imitation paradigm is given by a human user and is decomposed based
on observations, similar to visual decomposition in the brain [Biederman and Gerhardstein, 1993], and inspired by the decoding process of the 3rd and 4th
reading developmental stages in infants [Seymour, 1999].
Furthermore I created new algorithms and used them in experiments;
de-composition heuristics, relational and attribute semantics and statistical inference.
Those algorithms were implemented as parts of the Icarus CA, and used in order to examine both accuracy and suitability of such agents in AI [Gkiokas and Cristea,
2016a] and simulate the imitation process in humans, thereby formulating,
earlier. The cascade of various learning models used within the Icarus CA included
artificial neural networks (ANN) and restricted Boltzmann machines (RBM) in com-bination with the reinforcement learning algorithm, as an action-selection
mecha-nism for KR construction [Gkiokas and Cristea, 2014b], thus addressing
observa-tional qualities of the agent and off-policy exploration as well as inference. I also
employed sparse and dense encoding with deep learning in Icarus in order to examine
how it compares to more traditional shallow networks, drawing conclusions on the
advantages and the complexity involved when using sparse non-processed encoding, whilst formulating alternatives to dealing with unknown input [Gkiokas and Cristea,
2016b]. In addition to experimenting with natural language understanding (NLU)
in the Icarus CA, this work expanded into the field ofmeta-learning by formulating
a new model based upon the same principle of MDP knowledge graph construction.
We usedabstraction of existing KR graphs and theorised it is possible to compress
andgeneralise knowledge intobeliefs; autonomously generated meta-KR constructs which represent a group or cluster of highly related KR instances [Gkiokas et al.,
2014].
The contributions therefore are numerous and address imitation as a
mecha-nism in AI and cognitive agents, all the processes involved, such asdecomposition or
decoding of paradigms, the main learning mechanism and models used to bothlearn
and associate paradigms with understanding of the input (both semantically and
syntactically) as well as a variety of learning models, algorithms and sub-processes
required by the ad-hoc Icarus engine. I have expanded all research questions and mapped the characteristics and attributes that govern them and describe possible
solutions to previous questions raised in the imitation learning literature
[Dauten-hahn and Nehaniv, 2002a].
1.8
Thesis Overview
This thesis is organised in the following manner: in Chapter 2 is described what has
been researched in the past, all related fields, models and systems. The theoretical agent model is formulated and analysed in Chapter 3, and correlated to both the
biological mechanisms and the Icarus CA design. Following the theoretical
descrip-tion, the data-set created to evaluate the Icarus engine is presented and analysed in Chapter 4. Chapter 5 analyses experiments carried out using the Icarus engine,
describes in detail the components and algorithms, and reports on results and find-ings. The last Chapter 6 discuss in detail various findings, conclusions and future
Chapter 2
Background and Literature
Review
In this chapter the background literature is detailed and an analysis and presentation
on the work on which this thesis is based is examined. This aids in justifying the
arguably unconventional - but highly utilitarian - approach taken.
2.1
Alan Turing and the intelligent machines
One of the forefathers of Artificial Intelligence was Alan Turing, amongst others such as Allen Newell, J.C. Shaw, Herbert Simon, John McCarthy and Marvin Minsky.
Turing envisioned AI not just as an an intelligent machine, but as an artificial
child, a synthetic entity which has to go through a developmental process to achieve intelligence [Turing, 1950]. How Turing had imagined that specific progression and
development of AI is matter of speculation or scientific debate [Muggleton, 2014],
but we can deduce from his paper that he believed AI would have to follow a developmental phase similar to that of infants. And as aforementioned, two of the
most important developmental phases in infants revolve around imitation learning,
symbol decoding and hierarchical representation [Seymour, 1999].
The brief history of computer science showcases that modern AI has not
indulged Turing’s original thoughts and ideas. Two different schools of thought
have existed since the birth of AI:Symbolic AI, also know as good old fashioned AI
(GOFAI), andConnectionism orConnectionistic AI1. Whereas Symbolism takes a
modelling or aprogrammatic approach,Connectionism takes a pseudo-biological or
1Also known assub-symbolic AI, albeit that term may have been coined by the symbolic school
network-centric approach [Smolensky, 1987]. It is not clear if Turing had intended
to take any of the two approaches or combine them; in fact although it was in the that the first artificial neural networks were theorised, actual implementations
and models were published later, in the late 1950s, after his death. Therefore,
Turing’s approach was mostly theoretical and albeit based on biomimicry, it did
not explicitly specifyhow those intelligent machines would be created, since when
he wroteComputing Machinery and Intelligence [Turing, 1950], Connectionism was
still in its infancy.
Around the same time, the field ofCybernetics [Wiener, 1948] was described
as a interdisciplinary field for examining systems, their structures and organisation.
Whereas Norbert Wiener differentiated Cybernetics from AI, there was a clear ten-dency of describing AI systems and agents in a cybernetic fashion: as well defined
and modelled systems. The late 1940s and 1950s therefore saw the genesis of modern
AI, which was for the largest part based on symbolic approaches: models, theorems, well defined processes and programs.
2.2
Imitation in Nature
2.2.1 What is imitation?
The exact nature of imitation has been studied only in modern sciences; it wasn’t until the early 20th century that Edward Thorndike begun studying imitation in
animals [Galef Jr, 1988; Thorndike, 1901]. The study of imitation in humans was
be-lated; only after the modern field of Psychology started advancing (e.g., Jean Piaget and developmental theory, Raymond Cattell and crystallised intelligence, Burrhus
Skinner’s behaviourism and reinforcement, Erik Erikson and developmental psy-chology, and Albert Bandura and social cognitive theory) was imitation given some
attention. The field of developmental psychology and in specific the development
of children is what mostly interests us. As discussed in Chapter 1, Sections 1.1 and 1.2, one of the core mechanisms which enable human intelligence to develop and
progress into what Cattell refers to ascrystallised intelligence [Cattell, 1963], is the
ability to learn from others, our environment, our parents and peers.
That development enables us to acquire knowledge through subjective
ex-perience, what Haikonen refers to as qualia [Haikonen, 2009]. However, that
ex-perience is in effect a knowledge transference, either sensorimotor, or more general
and abstract. Verbalisation and learning by description plays a role (such as a
teacher explaining things), but even higher level learning (such as learning how to
phys-ical and non-physphys-ical: the hand learns how to draw and write, yet the brain is
conditioned into learning representations of letters, and then words. Psychologists suggest that imitative learning is a mechanism inherited and shared across humans
[Myowa-Yamakoshi et al., 2004; Ferrari et al., 2006] and one which is the product of
evolution; a hypothesis supported by the fact that not only humans are capable of imitation, but so are homininae, primates, animals and insects [Fritz and Kotrschal,
2002; Herman, 2002; Visalberghi and Fragaszy, 2002; Galef Jr, 1988], thus making
imitation a cognitive function shared across multiple species (but not necessarily of
the same competence level). Imitation therefore is the ability to acquire knowledge
from peers or others either via active demonstration, or passive observation.
2.2.2 How does imitation work?
Not taking into account the neurological and morphological properties of the brain,
and how those have evolved or how they enable imitation, Albert Bandura explicitly
states (direct quotation):
”Attentional processes regulate exploration and perception of modelled
activities; through retentional processes, transitory experiences are
con-verted into symbolic conceptions that serve as internal models for re-sponse production and standard for rere-sponse correction; production
pro-cesses govern the organisation of constituent sub-skills into new response
patterns; and motivational processes determine whether or not observa-tionally acquired competencies will be put to use.” [Bandura, 1986]
Analysing the above quote we can deduce a few key components and prop-erties of imitation and its overall structure:
- Perception produces a model (or a modelled activity)
- A process retains a symbolic conception (through experience)
- The internal models serve the purpose of providing responses (or correcting responses)
- Motivation determines if a competency (skill) will be re-used.
Thus, and similar to how Thorndike [Galef Jr, 1988] and others have demon-strated, imitation uses rewarding (either via motivation or reinforcement) in order
tolearn a competency. The subjective experience (qualia) must perceive a temporal
uses some form of symbolism or conceptualisation and serves the purpose of being
reused, either so that the agent can provide responses, or correct its responses. The key components are a model or structure which uses symbolism to represent an
action, a sequence or behaviour, an episode or sequence, the related reinforcement,
and the re-usability of the model.
The perceptive and cognitive abilities which relate to imitation have been
studied in human infants [Seymour, 1999] and involve a decomposition (or
decod-ing) of structures, objects or symbols and the internal hierarchical modelling (or
representation) of those within the short-term, and if rewarded or reinforced, into
the long-term memory. Visual understanding also uses decomposition [Biederman
and Gerhardstein, 1993], thus it appears that the process of breaking down stimuli or information into primitives or archetypes, prior to internally representing them
or modelling them, is a commonly occurring phenomenon.
2.3
Symbolic Artificial Intelligence
The symbolic school of thought has its roots in philosophical and centuries old beliefs
about what intelligence and cognition is, and many of those beliefs stem from Julien
Offray de La Mettrie and theL’homme machine (Man - Machine) [de La Mettrie,
1912]. The philosophical beliefs that followed suit of de La Mettrie’s medical
ex-periments, although revolutionary for his time2 set the path for future research and
development in Medicine, Psychology and eventually Artificial Intelligence. Those
beliefs described the human mind as a complicated machine, a notion which
sup-ports Artificial Intelligence; it did however indoctrinate later research in Psychology, Cognitive sciences and AI to the effect where mental and cognitive abilities were
be-lieved to be definable as a process or a model, such as in the case of Allen Newell and
theLogic Theorist [Newell and Simon, 1956] or theGeneral Problem Solver [Newell and Shaw, 1959].
This belief still echoes in modern AI: many designs for cognitive systems
take a purely programmatic approach, identical to a finite state machine (FSM)
[Gill et al., 1962; Minsky, 1967] and thereby limited by its very finite nature and
the logic enabling it. Admittedly, Symbolism and FSM are a necessity and part of
what is today the modern field of AI and Von Neumann computers operate on a
symbolic level. There are realistically many advantages to modern computing and
Symbolism which are not easily dismissed and a plethora of algorithms and models
2He was forced to quit his position with the French Guards, due to his materialistic and
with decades of research and a proven track record.
2.3.1 Knowledge Representation
One of the topics most important and relevant to imitation learning of Symbolic
AI is Knowledge Representation or KR [Sowa, 1999]. Representing knowledge is
a major field under AI, with close ties to Philosophy and Psychology. Whilst the philosophical aspects of KR are outside the scope of artificial imitation (e.g., ”what
is knowledge”) the psychological attributes aren’t; since the research in this thesis is
using the developmental cycle of human intelligence as a reference point, employing KR requires that this work is at least partially based on models which are perceived
to be plausible mental representation models.
It is not by chance that the issue of KR first arose during the development
of the General Problem Solver [Newell and Shaw, 1959], that was also the moment
when the symbolic school of AI underpinned the basis of KR. In the past three
decades, multiple KR models and schemes have been devised, ranging from the
family ofKL-ONE [Woods and Schmolze, 1992], to Sowa’sconceptual graphs (CG)
[Chein and Mugnier, 2008; Sowa, 1999, 1984], and to more modern schemes such
as the resource description framework or RDF [Klyne and Carroll, 2005] and the
web ontology language or OWL [Bechhofer, 2009]. Most KR schemes feature similar
designs: an ontology and the relations required to describe the hierarchy; it is intended to be used by computers (although it can be readable) and serves the
purpose of representation but may also enable reasoning [Sowa, 1999; Levesque
and Brachman, 1984]. KR can be used by first order logic or FOL [Fitting, 1990]
which operates on the actual KR structure, and may be combined with or represent
semantics [Fellbaum, 1998]. KR uses primitives (e.g., domain archetypes) which,
depending on the application domain, may change. Meta-representation (or meta-data) is also used in most modern KR schemes such as RDF and OWL, which are
appliedon top of or as extensions to the primitives.
The most important aspects or topics related to KR are:
- incompleteness orcompleteness (e.g., semantic, functional, refutation or syn-tacticcompleteness associated with statement in the structure) [Lipschutz and
Judith, 1916; Duffy, 1991]. Fuzzy logic is one of the sub-fields of AI which deals
with a certain degree with incompleteness [Nov´ak et al., 2012; Zadeh, 1996].
- definitions, universals, facts and defaults are general rules and patterns which
relate tospecificity and offer quantification and generality employed by logic
- non-monotonic reasoning or hypothetical reasoning, asserts new hypotheses
based on rules or facts [Dung, 1995].
- expressiveness or functional completeness relates to the ability of adequately
expressing all truth tables when using first order logic (FOL) [Fitting, 1990]
expressions such asAND, OR as well asNAND, NOR.
- reasoning in general terms relates to the ability of the agent or system to
be updated, develop new inferences, and operate within reasonable time con-straints.
From the above list it is possible to identify related material which overlaps
KR, logic, learning and imitation. Whereas KR serves the purpose ofrepresentation
anddescription, it is used by logic. For the intents and purposes of this thesis, I am mostly concerned with KR and how it is to be used and manipulated by imitating
agents, rather than the logic enabled or applicable, which albeit relevant is outside
the scope of the work described hereinafter. There is a clear connection between KR and logic, how KR enables or allows inference, hypotheses and propositions,
and more important how the agent may learn to form such hypotheses, assertions
and propositions. Yet my scope is focusing on creating KR and not logically
ma-nipulating it.
Another form of KR is the meaning representation (MR) or the most
com-monly used term meaning representation language (MRL). Those structures have
been widely used in parsing (see Section 2.7.5) and are mostly related to natural
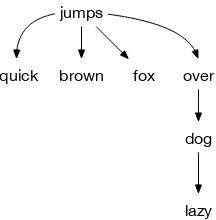
language processing (NLP). The phrase ”quick brown fox jumps over lazy dog” is
shown as a simple MRL in Figure 2.1, whereas the same phrase with directededges
is shown in Figure 2.2.
quick brown fox jumps
over
lazy dog
Figure 2.1: Simple MRL structure.
Whereas the first Figure 2.1 is overly simplistic, the addition of directed edges
quick brown fox jumps
over
[image:31.595.267.375.114.224.2]lazy dog
Figure 2.2: MRL with Edges.
In certain KR such as a Penn treebank tree[Marcus et al., 1993], direction is often implied originating from the root label/node of the tree graph. Such structures can
often become esoteric or obscure, since they may include syntactic attributes mixed
with words and labels, making them hard to understand. A modern MRL form of the same phrase which includes propositional and syntactic meta-data is shown in
Figure 2.3; in this example, the blue labels in capitals are syntactic attributes (part
of speech tags, see Section 2.7.4) with extra information including a rudimentary propositional logic (edge labels in pink).
JJ
quick
JJ
brown
NN
fox
NNS
jumps
IN
over
JJ
lazy
NN
dog
amod amod
nn prep
pobj
[image:31.595.253.388.423.571.2]amod
Figure 2.3: Annotated MRL with Edges and Meta-data.
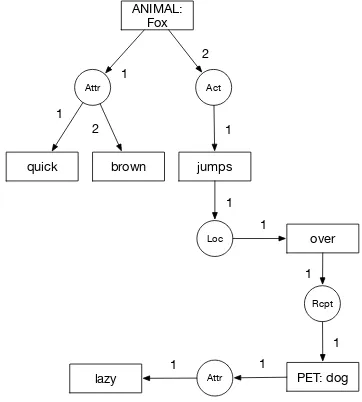
The equivalent of that same phrase as a conceptual graph (CG) is shown in Figure 2.4. In this instance and according to Sowa’s publications [Sowa, 1999,
1984], rectangles depict concepts and circles depict relations. Sowa’s CG contain
implied relations and not just relations extracted from the text such as relations
between concepts. That approach might be confusing; whereas theedges describe
and relations are of different types. The edge label (number) indicates the order
of the edges and some of the labels in the concepts are implied and not contained
within the phrase, such as the relationsattr (attribute),act (actions),loc (location)
andrcpt (recipient).
quick brown
ANIMAL: Fox
jumps
over
lazy PET: dog
Attr Act
1 2
1
Loc
2
Rcpt
Attr
1
1
1
1
1
1 1
Figure 2.4: Conceptual Graph example.
Furthermore, Sowa in his original publications providedcontradicting
exam-ples such as the one shown in Figure 2.5. Those examexam-ples are called adisplay form,
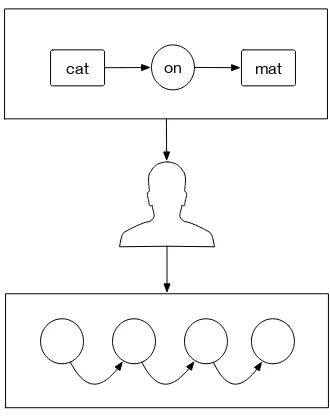
which is a visualised conceptual graph. Figure 2.5 demonstrates the phrase ”a cat
on a mat”; the relation on is contained within the phrase, and is used to link the
concepts.
[image:32.595.229.410.185.386.2]cat on mat
Figure 2.5: Conceptual Graph Directed Edges.
Part of the reason why Sowa treats CG (in their display form) in such a
way maypossibly be because he derives them from a logic form. The logic formula
of Figure 2.4 may be as shown in (2.1) when ignoring the attributes. The root is
the actionjump which in the Figure is shown as a concept and based on a Pierce
formula from which Sowa derived the CG in the display form.
[F ox]−>(J ump)−>[Dog]. (2.2)
Similarly, Sowa describes Figure 2.5 as having a linear form, as shown in
(2.3).
[Cat]−>(On)−>[M at]. (2.3)
Theconceptual graphs interchange format (CGIF), which was developed sim-ilar to the ISO Common Logic Project, would represent the linear form of (2.2) as
(J umps[F ox][Dog]) and the linear form of (2.3) as (On[Cat][M at]). Therefore, Sowa
did not attribute importance to either the order of appearance, nor to the
direc-tion of edges. He hypothesised that, albeit those forms may appear different, their
semantic foundations translate to the same predicate calculus. Later, researchers in CG have used a better defined approach [Obitko, 2007; Amati and Ounis, 2000],
in which the order of the graph is drawn from the first appearing node (concept
or entity), and the direction of the edges is important, as it demonstrates the logic continuation of the phrase being represented.
Furthermore, whereas Sowa used relations in an implicit manner (e.g.,
ex-tracting roles of concepts), there is no rule or limitation as to why relations (the
nodes within the graph) must beimplied entities; Sowa in his examples also used
relationsexplicitly obtained from the original phrase.
2.3.2 Criticism and Limitations of Symbolic Artificial Intelligence
When researching imitating agents, we expect a form of KR structure to be produced
which is identical orhighly similar to the one the teacher, paradigm or demonstrator
provided to the agent. That process, when described using symbolic AI, is a
well-defined model, an algorithm, a program or a heuristic process, as that is the nature of
Symbolism. Therefore, that process is in fact afinite state machineor a combination
of FSM, described by a program or agent operating on the information on a symbolic level. In the history of AI the two cornerstones supporting the suitability of symbolic
AI for our intents and purposes are theChurch-Turing thesis [Searle, 2001] and the
Myhill-Nerode theorem [Ignjatovi´c et al., 2010]. The Church-Turing thesis states that a function is computable by a human following an algorithm, if it is computable
by a Turing machine. Church-Turing thesis implies what can physically be computed
by a computer [Piccinini, 2011] or what could realistically be computed, however multiple researchers in the past have argued for or against it [Goldin and Wegner,
The Myhill-Nerode theorem offers insight into what can and cannot be done
when using FSM: it suggests that any language can be recognised by a model, by mapping strings in the language to unique accepting states, and strings not in the
language to unique non-accepting states. However, not all languages are regular,
that is they do not correspond to the language accepted by any FSM, and equiva-lently, there may be no regular expression to represent that language. Furthermore,
natural languages contain ambiguity and contradictions [Gorrell, 2006], which
cre-ate exceptions to rules and the logic enabled by the FSM. Finally, the FSM may
suffer from the halting problem [Stannett, 1990], and therefore the use of FSM,
al-beit advantageous, due to decades of research and the existence of multiple models,
theories and algorithms, does have the aforementioned drawbacks.
2.4
Connectionistic Artificial Intelligence
Connectionism takes a black-box approach and is based on Neuroscience and the
observation that our own intelligenceemerges from neural networks in the human
brain. Neuroscience and modern medical imaging have allowed us to observe and
analyse the neuronalnetwork mechanisms which enable cognitive functions and
in-telligent behaviour. It is from Neuroscience that artificial neural networks (ANN)
were inspired, and in 1943 McCulloch described the first artificial neuronal model
[McCulloch and Pitts, 1943]. In the 1949 Donald Hebb first describes Hebbian
net-works [Hebb, 1949], but it isn’t until 1958 that thePerceptron is published
[Rosen-blatt, 1958], the precursor of modern ANN. In 1969 Minsky criticises Connectionism
and neural networks [Minski and Papert, 1969] due to their computational limita-tions in training and deploying them, but most important due the fact that they
couldn’t learn to perform an exclusive (XOR) on the input. Those issues were
ad-dressed in the 1980ies and 1990ies with the advent of the personal computer, and
multi-layered networks in combination with back-propagation [Werbos, 1974]
show-cased that they could process complex input. At the same time GOFAI lost interest
from the research community, yet connectionism and the related ANN did not make any considerable breakthroughs until the late first decade of the third millennium
withdeep learning.
2.4.1 Artificial Neural Networks
An artificial neural network is a non-biologically plausible, yet bio-inspired network.
It works upon the premise of associative memory and learns to associate input
n1
n2
n3
n4
n5
n6
Input
hidden
output w1
w2
w3
w4
w5
w6
w7
w8
[image:35.595.249.393.115.248.2]w9
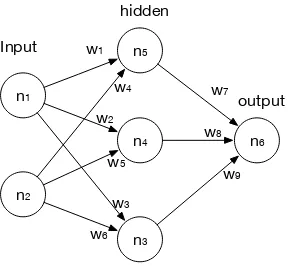
Figure 2.6: Example of a Neural Network.
[Picton, 1994; Hertz et al., 1991; Hopfield, 1988]. There are multiple types of neural
networks, but we’ll only examine and present the most typically used, the fully
connected feed-forward neural network, also known as the single-layer or multi-layer
perceptron. From the Figure 2.6 we observe what a neural network is: layers of
nodes (or neurons) which are connected by synapses, or weights. In that figure
above, there are three layers: the input layer with nodes n1 and n2, one hidden
layer with nodes n3, n4 and n5 and an output layer with a single node n6. The
premise upon which the feed-forward perceptron relies is forward propagation: an
input vector of two values is fed into the input nodes, and is the activated, using anactivation function, most often alogistic function, with the most popular shown
below.
f(x) = 1
1 +e−x. (2.4)
f(x) = e
x−e−x
ex+e−x. (2.5)
The above functions are the sigmoid shown in (2.4) and hyperbolic tangent
shown in (2.5); others less popular are the sigmoid bipolar in (2.6), the scaled
hy-perbolic tangent [LeCun et al., 2012] in (2.7), and thesoft-sign in (2.8).
f(x) = −1 + 2
1 +e−x. (2.6)
f(x) = 1.7159∗tanh(2
f(x) = x
1 +|x|. (2.8)
A characteristic of the logistic functions is that they produce a S shaped
output. Non-logistic functions such as theGaussian have been used but are not as
popular. Common criticism for such networks, is that logistic activation functions
cannot be used in deep networks; often there is no need for such networks, and
one hidden layer may suffice to learn the task at hand. However, logistic activation
functions often lead tosaturation[Heaton, 2015], an issue which has been addressed
by usinglinear activation functions.
The forward propagation in neural networks is a task of accumulating the
inputIj multiplied by the weightsWi for each node and activating it viaf(Ii). The
most commonly used approach is to do vector and matrix arithmetic: we obtain
previous layer node output denoted as Oj where subscript j is the previous layer.
For input layers, Oj is the input value Ij whereas for hidden layers we substitute
Oj with Ii, e.g., the output of the activation function f(x) from the previous layer
j. Multiplying each node output Oj ·W i with every corresponding weight Wi is
a vector-matrix product, we then sum each input vector for the nodes in layer i:
P
(Oj ·Wi), e.g. reducing each produced matrix into a row vector of values, each
row corresponding to node input Ii in layer i. Finally, each value in that vector
isactivated using one of the functions f(Ii) as shown earlier in (2.4,2.5,2.6 or 2.7).
The above step is repeated for all layers; that is in essenceforward propagation.
Training neural networks is considerably more complex; one of the early
critiques on neural networks was the computational requirements, and the biggest issue was that training was inefficient [Minski and Papert, 1969]. Nowadays, there
are many training algorithms, the most notable of which are theback propagation
(or BPROP); other methods also have been used, such as reinforcement learning,
theLevenberg-Marquardt [Mor´e, 1978], and the Broyden-Fletcher-Goldfarb-Shanno
algorithm [Shanno, 1985] abbreviated as (BFGS), amongst the most famous. The
most commonly used training approach for ANN and shallow networks throughout the last two decades, has been the BPROP as described by Seppo Linnainmaa
[Linnainmaa, 1970], and was later demonstrated by application [Werbos, 1982]. The
basic mechanism behind BPROP, is that the observable error at the output layer, is back-propagated to account for each weight adjustment, until the desirable, or
highly similar to the desirable output is produced by the network. We define the
error asE shown in (2.9), e.g., the squared difference for each output node, where
E= (yi−yˆi)2. (2.9) We then proceed to reversely iterate all the layers, first we calculate the
output delta error, shown in (2.10).
δi=−E·f0
X
(Oi)
. (2.10)
In (2.10) f0 is the prime or derivative of the activation function and Oi is
the node input. The sigmoid and tanh derivatives are shown in (2.11) and (2.12).
f0(x) =f(x)·(1−f(x)). (2.11)
f0(x) = 1−tanh2(x). (2.12)
For hidden layers we calculate the value of the derivative on the node input
f0(P
(Oj·Wji)), e.g., the vector-matrix multiplication. Then those values are
mul-tiplied by thenext weightsWik and the next layer’s delta error3 δk, which are called
node deltas, shown in (2.13).
δi =f0
X
(Oj·Wji)·
X
(Wik·δk)
. (2.13)
Finally, we calculate the weight gradient for layeritok, as shown in (2.14),
with each gradient multiplying the next layer’s node delta and the observed node
outputOi.
∂E
∂W ik =δk·Oi. (2.14)
That gradient is then used in the update of the weight values. There are
different ways of updating weights; in batch training, the gradients are summed
P ∂E
∂Wik
and then used to adjust the individual weights at the end of an epoch
(a training sample iteration), whereas in on-line training, the weights are updated
after propagating a single training sample. The update rule in BPROP for batch
training is shown in (2.15), the time-steptdefines the index in time, and hencet−1
is the previous update, thelearning rate α defines how large adjustments are made
and themomentum µaffects current adjustment using previous adjustments.
3
Please note we swapδkwithδi from formula (2.10). At every backwards iteration, we replace
δkin (2.13) with the next layerδi. Because this is a reverse iteration, we start at the output layer,
∆Wik(t)=α·
∂E ∂Wik
+µ∗ ∆Wik(t−1). (2.15)
Other training algorithms have been based on BPROP, most notablyresilient
back-propagation (RPROP) [Riedmiller and Braun, 1993], as well as many of its
derivatives. The RPROP uses incremental small weight adjustments, and is assumed
to be faster than BRPOP, as shown in (2.16).
∆Wik(t)=
−∆Wik(t), if∂W∂E
ik (t)
>0
+∆Wik(t), if∂W∂E
ik (t)
<0
0, otherwise
. (2.16)
The increments and decrements taking place are constant (or range bound)
and ∆Wik(t) increases or decreases by η, where 0 < η− < 1 < η+. Redmiller and
Braun published akernel of the algorithm, and reported significantly better results
than BPROP [Riedmiller and Braun, 1993], since then newer versions have been
published.
Neural networks have various ways of calculating theerror; the most notable
being themean square error (MSE): n1Pn
i=1(ˆyi−yi)2 fornsamples. Nowadays for
classification thecross entropy/log loss(CE) [Heaton, 2015, 104,120] is also used as
shown in (2.17) whereyi is the ideal node output and ˆyi is the actual node output4.
CE=−1
N
N
X
i=1
yilog(ˆyi) + (1−yi)log(1−yˆi)
. (2.17)
All the above networks are trained in a supervised manner where training
samples are obtained and associate input to specific output. Non-supervised learning before the advent of deep learning was a peculiar topic; the few models able to learn
unsupervised were theself-organising maps (SOM) [Kohonen, 1990], the
Hebbian-inspired gas networks [Fritzke et al., 1995] and the K-means family of clustering
kernels [MacQueen et al., 1967].
Evidently, the field of neural networks had its ups and downs; in its infancy it was heavily criticised, it appeared to not live up to the expectations of revolutionising
AI, and even after the 1980 developments they hadn’t been widely adopted.
4
2.4.2 General Purpose Computing on Graphic Processing Units
Part of the reason of the advent of deep learning has to do with advances and recent changes from the traditional ANN to deep networks and activation functions, but it
is also attributed to the new GPU hardware. Most of the graphics processing units
(GPUs) on modern computers have hundreds of simple cores and even
consumer-grade GPUs nowadays have thousands of cores. At the early third millennium
researchers started using GPUs for general purpose computing [Thompson et al.,
2002; Pharr and Fernando, 2005], coined general-purpose computing on graphics
processing units(GP2U), once it was realised that GPUs favoured parallel algorithms
[Nickolls et al., 2008; Che et al., 2008; Owens et al., 2007] such as the training
algorithms which are used for neural networks.
The nature of the matrix form operations on the input Ij and weights Wi,
the vector-matrix multiplications during forward propagation or the back propaga-tion such as (2.13, 2.14) as well as the training update rules such as (2.15, 2.16)
can execute a lot faster when using GP2U. Because GP2U kernels are able to run
asynchronous parallel operations on multiple training samples, weights and input vectors, a resurgence in the research of ANN took place before and during the rebirth
of the field, now calleddeep learning.
2.4.3 Deep Learning
The pragmatic approach of using GP2U from the research community enabled deep
learning to advance intorealistic applications dealing with computer vision, speech
recognition, pattern recognition, classification, prediction, regression, approximation
and auto-encoding.
Whereas the early ANN were mostly used fortoy problems and trained using
small data-sets, deep learning is able to crunch big data and has proven usable in
real-life sceanrios and most important on par with human performance [He et al.,
2015; Taigman et al., 2014] thus having a profound effect to the adaptation of deep
learning in multiple fields and domains. Perhaps the most important breakthrough
was recently in 2016 by Google [Silver et al., 2016] whenDeepMind beat the world
champion in the gameGo by 5 - 0, thereby proving that deep learning and
Connec-tionism are capable of super-human performance. Modern ANN (hereinafter deep
networks ordeep learning) differ from the traditional ANN in five distinct ways:
- Traditional ANN use logistic activation functions [Zadeh et al., 2010], e.g.,
sigmoid, tanh, arctan. Deep learning most often use linear functions such as
and Bengio, 2010].
- ANN normally use no hidden layers, or one to two hidden layers. In comparison
deep neural networks use multiple hidden layers, hence the termdeep. In some
cases it is possible to stack different types of networks (e.g., as in the case of
auto-encoders).
- Although not limited to deep networks,node dropout,L1 andL2regularisation
are new optimisation techniques which evolved as optimisation techniques for
deep learning [Dahl et al., 2013; Ngiam et al., 2011b,a; Bengio, 2009].
- Other types of deep networks such as convolutional neural networks (CNN)
are profoundly different from traditional ANN. They use max pooling and
convolution layers (often in alternating multi-layered fashion) and perform
classification at the final fully connected layer [Krizhevsky et al., 2012; Ciresan
et al., 2011].
- Development of deep learning saw the use of soft-max as the output layer
activation, instead of using traditional logistic functions. Whilst soft-max is
applicable in shallow networks, its use in deep learning proved very successful [Glorot and Bengio, 2010].
The Figure 2.7 below showcases the difference between traditional and deep networks. More often than not deep networks are harder to train [Glorot and
Ben-gio, 2010], they have more hyper-parameters which do not always warrant better
accuracy or performance, such as in the case of increasing hidden layers and amount of nodes and quite often require more training iterations or epochs.
n1
n2
n3
n4
n5
Input hidden output
n6
n7
n8
n9
n10
n11
n12
n13
n14
hidden hidden hidden
n15
n16
Figure 2.7: Example of a deep fully connected neural network.
Other types of networks used for deep learning are thedeep Boltzmann