Big Data Challenges in Simulation-based
Science
Manish Parashar*
Rutgers Discovery Informatics Institute (RDI
2)
Department of Computer Science
*Hoang Bui, Tong Jin, Qian Sun, Fan Zhang, ADIOS Team, and
other ex-students and collaborators….
Outline
•
Data Grand Challenges
–
Data challenges of simulation-based science
•
Rethinking the simulations -> insights pipeline
•
The DataSpaces Project
RDI
2Astronomy: LSST Physics: LHC
Oceanography: OOI
Sociology: The Web
Biology: Sequencing
Economics: POS terminals
Neuroscience: EEG, fMRI
Data-driven Discovery in Science
Nearly every field of discovery is transitioning from “data
poor” to “data rich”
Scientific Discovery through Simulations
•
Scientific simulations running on high-end computing systems generate
huge amounts of data!
– If a single core produces 2MB/minute on average, one of these machines could
generate simulation data between ~170TB per hour -> ~700PB per day ->
~1.4EB per year
•
Successful scientific discovery depends on a comprehensive understanding
of this enormous simulation data
How we enable the computation scientists to
e
ffi
ciently manage and explore extreme scale data:
Scientific Discovery through Simulations
•
Complex, heterogeneous
components
•
Large data volumes and data rates
•
Data re-distribution (MxNxP), data
transformations
•
Dynamic data exchange patterns
•
Strict performance/overhead
constraints
•
Complex work
fl
ows integrating
coupled models, data management/
processing, analytics
•
Tight / loose coupling, data
driven, ensembles
•
Advanced numerical methods (E.g.,
Adaptive Mesh Re
fi
nement)
•
Integrated (online) analytics,
uncertainty quanti
fi
cation, …
Traditional
Simulation -> Insight
Pipelines Break Down
•
Traditional
simulation ->
insight
pipeline
– Run large-scale simulation
workflows on large supercomputers – Dump data to parallel disk systems
– Export data to archives
– Move data to users’ sites – usually
selected subsets
– Perform data manipulations and
analysis on mid-size clusters – Collect experimental /
observational data – Move to analysis sites
– Perform comparison of
experimental/observational to validate simulation data
Figure. Traditional data analysis pipeline
Analysis/Visualization Cluster Simulation Machines Storage Servers
…
Simulatio n Raw DataChallenges Faced by Traditional HPC Data Pipelines
•
Data analysis challenge
• Can current data mining, manipulation
and visualization algorithms still work effectively on extreme scale machine?
The
costs of data movement
are increasing and dominating!
Figure. Traditional data analysis pipeline•
I/O and storage challenge
• Increasing performance gap: disks are outpaced
by computing speed
•
Data movement challenge
• Lots of data movement between simulation and analysis machines, between
coupled multi-physics simulation components -> longer latencies
• Improving data locality is critical: do work where the data resides!
•
Energy challenge
• Future extreme systems are designed to have low-power chips – however,
•
The energy cost of moving data is a
significant concern
From K. Yelick, “Software and Algorithms for Exascale: Ten Ways to Waste an Exascale Computer”
The Cost of Data Movement
Energy _ move _ data= bitrate * length
2
cross_section_area_of_wire
performance
gap
•
Moving data between node
memory and persistent
storage is slow!
Rethinking the Data Management Pipeline – Hybrid Staging +
In-Situ & In-Transit Execution
Issues/Challenges
•
Programming abstractions/systems
•
Mapping and scheduling
•
Control and data flow
•
Autonomic runtime
•
Link with the external workflow
Systems
Design space of possible workflow architectures
• Loca%on of the compute resources
– Same cores as the simulaHon (in situ)
– Some (dedicated) cores on the same nodes
– Some dedicated nodes on the same machine
– Dedicated nodes on an external resource
• Data access, placement, and persistence
– Direct access to simulaHon data structures
– Shared memory access via hand-‐off / copy
– Shared memory access via non-‐volaHle near
node storage (NVRAM)
– Data transfer to dedicated nodes or external
resources
• Synchroniza%on and scheduling
– Execute synchronously with simulaHon
every nth simulaHon Hme step
– Execute asynchronously
Processing data on remote nodes
Using distinct cores on same node Sharing cores with the simulation
DRA M DRA M DR A M Simulation Node DR A M Staging Node Network Communication Analysis Tasks Simulation Visualization DRAM NVRAM SSD Hard Disk CPUs DRAM NVRAM SSD Hard Disk CPUs Network Node 1 Node 2 Node N ... Staging option 1 Staging option 2 Staging option 3
DataSpaces: A Scalable Shared Space Abstraction for Hybrid
Data Staging [JCC12]
App1 put()/pub()
Shared Space Model
Simula�on get()/sub() put() App3 get() App2 get() m d d d d d: Data object m: Meta-data object m m m d l
Shared-space programming
abstraction over hybrid staging
l
Simple API for coordination,
interaction and messaging
l
Provides a global-view
programming abstraction
l
Distributed, associative,
in-deep-memory object store
l
Online data indexing, flexible
querying
l
Exposed as a persistent service
l
Autonomic cross-layer runtime
management
l
High-throughput/low-latency
asynchronous data transport
010 20 30 40 50 60 70 80 90 100 110 120 512/32 1024/64 2048/1284096/2568192/51216K/1K 32K/2K 64K/4K 2GB 4GB 8GB 16GB 32GB 64GB 128GB 256GB Throughput(GB/s)
Aggregate data redistribution throughput
D ata Sp ac es s ca la b ility o n O R N L T ita n
DataSpaces Abstraction: Indexing + DHT
[HPDC10]
• Dynamically constructed structured
overlay using hybrid staging cores
• Index constructed online using SFC
mappings and applications attributes
• E.g., application domain, data,
field values of interest, etc.
• DHT used to maintain meta-data
information
• E.g., geometric descriptors for
the shared data, FastBit indices, etc.
• Data objects load-balanced
Multphysics Code Coupling at Extreme Scales [CCGrid10]
PGAS Extensions for Code Coupling [CCPE13]
DataSpaces: Enabling Coupled Scientific
Workflows at Extreme Scales
Data-centric Mappings for In-Situ Workflows [IPDPS12]
Simulation
in-situ analytics
DART
...
Data Pool of computation bucket in the staging area
Simulation in-situ analytics DART Simulation in-situ analytics DART Simulation in-situ analytics DART DataSpaces "data-read y" event "buck et-read y" even t Assig ned ta sk & data d escri ptors DART in-transit analytics DART in-transit analytics DART in-transit analytics DART in-transit analytics
compute nodes running simulation and in-situ analytics
Data Interaction and coordnation
Resoure scheduler
Dynamic Code Deployment In-Staging [IPDPS11]
kernel_min { for i = 1, n for j = 1, m for k = 1, p if (min > A(i, j, k)) min = A(i, j, k) } data_kernels.c 0x69 0x20 0x61 0x6d 0x20 0x63 0x6f 0x6f 0x6c 0x0 data_kernels.o Applications.o Applications executable apr un apr un Compute nodes Link gcc -c Staging nodes rexec() return() for i = 0, ni-1 do for j = 0, nj-1 do for k = 0, nk-1 do val = input:get_val(i,j,k) if min > val then min = val end end end data_kernels.lua
Runtime execution system (Rexec)
Integrating In-situ and In-transit Analytics [SC’12]
•
S3D: First-principles direct
numerical simulation
•
Simulation resolves features on
the order of 10 simulation time
steps
•
Currently on the order of every
400
thtime step can be written
to disk
•
Temporal fidelity is
compromised when analysis is
done as a post-process
Recent data sets generated by S3D, developed at the CombusHon Research Facility, Sandia NaHonal Laboratories
Integrating In-situ and In-transit Analytics – Design
23Topology
StaHsHcs
Identify features of
interest
Volume Rendering
*J. C. Bennett et al., “Combining In-Situ and In-Transit Processing to Enable Extreme-Scale Scientific Analysis”,
SC’12, Salt Lake City, Utah, November, 2012.
In-situ/In-transit Data Analytics
•
Online data analytics for large-scale simulation workflows
–
Combine both in-situ and in-transit placement to r
educe impact onsimulation, reduce network data movement, reduce total execution time
–
Adaptive runtime management:
Optimize the performance ofsimulation-analysis workflow through adaptive data and analysis placement, data-centric task mapping
primary resources shared data structures secondary resources Simulation In-situ processing In-transit Task Executors asynchr onous in-s itu to in-trans it data tr ansfers Workflow Manager data ready
Pull task & data descriptors
Figure. Overview of the in-situ/in-transit
Simulation case study with S3D: Timing
results for 4896 cores and analysis every
simulation time step
16.85& 2.72& 0.73& 1.7& 1.69& 2.06& 119.81& 5.07&
0& 2& 4& 6& 8& 10& 12& 14& 16&
simula3on& hybrid&topology& hybrid&visualiza3on& in@situ&visualiza3on& hybrid&sta3s3cs& in@situ&sta3s3cs& seconds&
Simulation case study with S3D: Timing
results for 4896 cores and analysis every
simulation time step
16.85& 2.72& 0.73& 1.7& 1.69& 2.06& 119.81& 5.07&
0& 2& 4& 6& 8& 10& 12& 14& 16&
simula3on& hybrid&topology& hybrid&visualiza3on& in@situ&visualiza3on& hybrid&sta3s3cs& in@situ&sta3s3cs& seconds&
S3D&
in@situ&
data&movement&
in@transit&&
10.0% 10.1% 4.3%
.04%
Simulation case study with S3D: Timing
results for 4896 cores and analysis every 10
th
simulation time step
168.5& 119.81&
0& 20& 40& 60& 80& 100& 120& 140& 160&
simula1on& hybrid&topology& hybrid&visualiza1on& in>situ&visualiza1on& hybrid&sta1s1cs& in>situ&sta1s1cs& seconds&
S3D&
in>situ&
data&movement&
in>transit&&
1.0% 1.0% .43%
.004%
Simulation case study with S3D: Timing
results for 4896 cores and analysis every 100
th
simulation time step
1685% 0% 200% 400% 600% 800% 1000% 1200% 1400% 1600% simula/on% hybrid%topology% hybrid%visualiza/on% in<situ%visualiza/on% hybrid%sta/s/cs% in<situ%sta/s/cs% seconds%
S3D%
in<situ%
data%movement%
in<transit%%
.1% .1% .04%
.004% .16%
In-Situ Feature Extraction and Tracking using
Decentralized Online Clustering (DISC’12)
DOC workers executed in-‐situ on simula%on machines
SimulaHon Compute Nodes
One compute node
Processor core runs simulaHon Processor core runs DOC worker
Benefits of runtime feature extraction and tracking
(1) Scientists can follow the events of interest (or data of interest) (2) Scientists can do real-time monitoring of the running simulations
Pixplot
8 cores
Pixmon
1 core
(login node)
ParaView Server
4 cores
In-situ viz. and
monitoring with
staging (SC’12)
Pixie3D
1024 cores
DataSpaces
record.bp
record.bp
record.bp
pixie3d.bp
pixie3d.bp
pixie3d.bp
Scalable Online Data Indexing and Querying
(BDAC’14, CCPE’15)
•
Enable query-driven data analytics to extract insights from the
large volume of scientific simulation data
N 3 Index-‐1 Index-‐4 Index-‐3 Index-‐2 Query1 Query2 Query3 Query4 Coord-‐based Coord-‐based Value-‐based Value-‐based Hilbert SFC Z -‐ o r d e r SFC Bitmap Index Tree Index N 1 N 2 N 4 Hash: H2 Hash: H4 Hash: H3 Hash: H1
Figure. Conceptual view of the
programmable online indexing & querying using multiple index
Figure. Value-based online index and query framework using FastBit
Fig. Conceptual framework for realizing multi-tiered staging for coupled data-intensive simulation workflows.
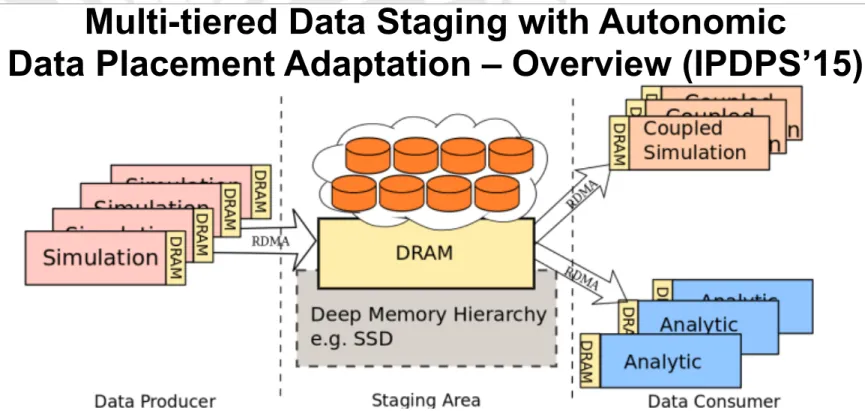
Multi-tiered Data Staging with Autonomic
Data Placement Adaptation – Overview (IPDPS’15)
•
A multi-tiered data staging approach that uses both DRAM and
SSD to support data-intensive simulation workflows with large
data coupling requirements.
•
Efficient application-aware data placement mechanism that
get()/sub() put()/pub() ADIOS/ Dataspaces ADIOS/ Dataspaces App App TCP/IP RDMA, Gridftp Control Node Data Tx/ Rx Node Dataspaces WA
Wide-area Staging (Demo at SC’14)
•
Wide-area shared staging abstraction achieved by
interconnecting multiple staging instances
– Leverages SDN for provisioning; Workflow/Grid technologies
•
Data placement optimized based on demand, availability,
Combus%on: S3D uses chemical model to simulate combusHon process in order to understand the igniHon characterisHc of bio-‐fuels for automoHve usage.
PublicaHon: SC 2012.
Fusion: EPSi simulaHon workflow provides insight into edge plasma physics in magneHc fusion devices by simulaHng movement of millions parHcles.
PublicaHon: CCGrid 2010, Cluster 2014
Subsurface modeling: IPARS uses mulH-‐physics, mulH-‐model formulaHons and coupled mulH-‐block grids to support oil reservoir simulaHon of realisHc, high-‐ resoluHon reservoir studies with a million or more grids.
PublicaHon: CCGrid 2011
Computa%onal mechanics: FEM coupled with AMR is oben used to solve heat transfer or fluid dynamic problems. AMR only performs refinements on
important region of the mesh. (work in progress)
Material Science: QMCPack uHlizes quantum Monte Carlo (QMC) studies in heterogeneous catalysis of transiHon metal nanoparHcles, phase transiHons, properHes of materials under pressure, and strongly correlated materials. (work in progress)
Material Science: SNS workflow enables integraHon of data, analysis, and modeling tools for materials science experiments to accelerate scienHfic