A Novel Approach for Choosing Summary Statistics in Approximate Bayesian Computation
92
0
0
Full text
(2)
(3)
(4)
(5)
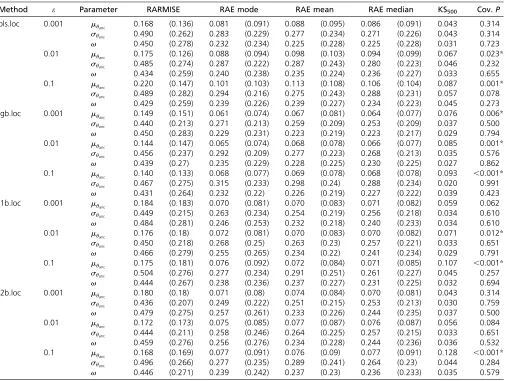
Figure

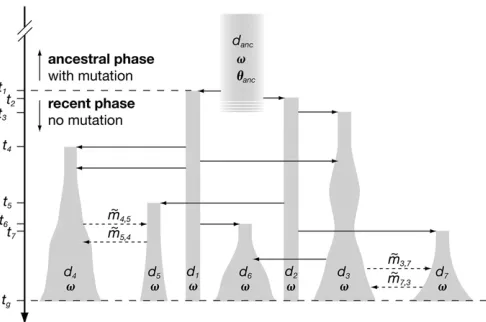
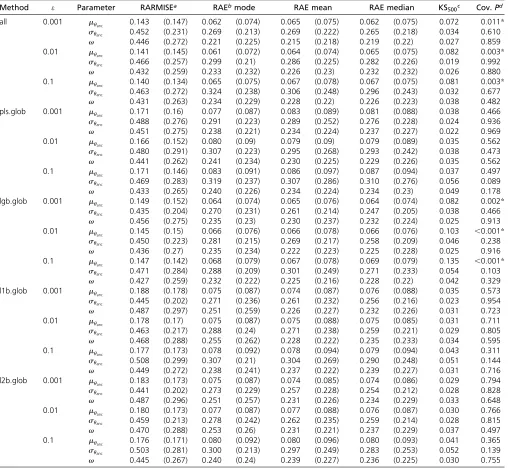
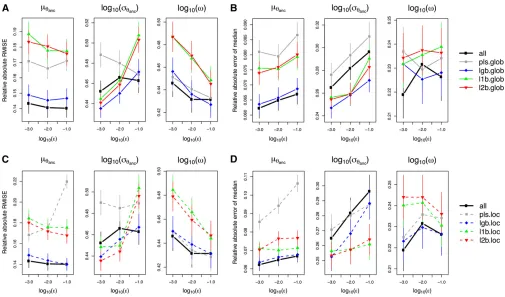
+7
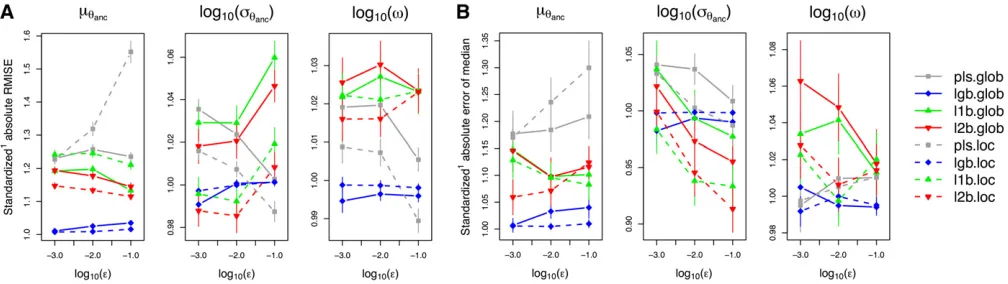

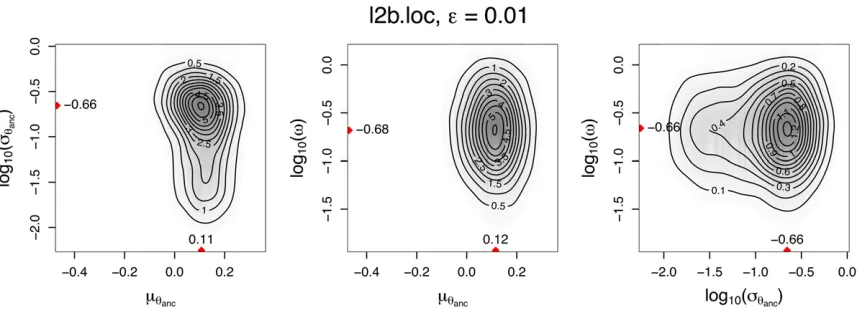
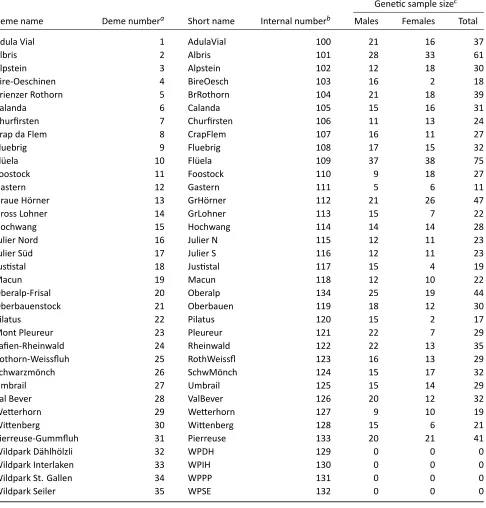
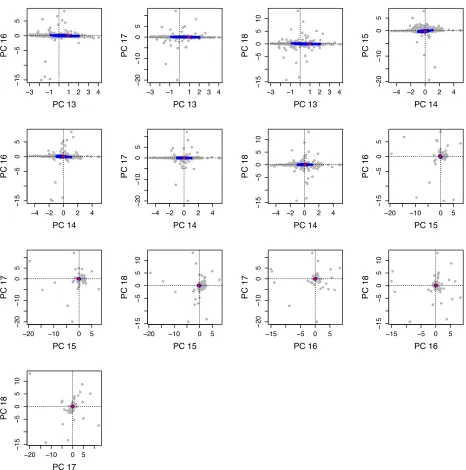
Related documents
We propose that hetZ regulates heterocyst differentiation by promoting the expression of hetC and of other genes required for heterocyst development and that regulation of
To incorporate both the leptokurtic feature and \volatility smile", this paper proposes, for the purpose of studying option pricing, a jump di®usion model, in which the price of
Reconstruction of metabolic pathways for pantothenate, biotin and thiamine was therefore performed by manual curation of whole genome sequences and revealed that one or more genes
An examination of government bonds in the light of revolutionary as well as events related to the Russo-Japanese War aims to add to the picture: an almost equal price reaction to
The MC-UPQC operation is the combina- tion of two series voltage converter and one shunt volt- age converter which are connected back-to-back with a common DC-link capacitor, by
As the school teacher with limited knowledge of the scientific or mechanical world, Mr Watts is an authority on Dickens ( MP 24), and it is his quiet voice and his narration of
New choices for the taxonomy Individuals Nursing Service Providers Other Service Providers Registered Nurse Lactation Consultant Non-RN 174N0000X.. Gutowski, BA,
GSEA: Gene set enrichment analysis; IFN: Interferon; LPS: Lipopolysaccharide; LV GLS: Left ventricular global longitudinal strain; SCM: Septic cardiomyopathy; TLR: Toll-like
