© 2017, IRJET | Impact Factor value: 6.171 | ISO 9001:2008 Certified Journal
| Page 2060
NOVEL SCHEDULING ALGORITHMS FOR EFFICIENT DEPLOYMENT OF
MAPREDUCE APPLICATIONS IN HETEROGENEOUS COMPUTING
ANILA GOGINENI
BTECH(CSE), GITAM UNIVERSITY,VISAKHAPTNAM, AP, INDIA
---***---Abstract :
The fair origin Hadoop and Map decreasestructure are the defect to program for ascendable report on populous word processing file. How to shrink the finishing touch magnitude of a set of MapReduce jobs is without doubt one of the number one concerns in Hadoop The MapReduce is an impartial origin Hadoop plan implemented for processing and producing distributed huge Terabyte data on populous flocks. . The current impartial authority Hadoop allows handiest static position contour, like limited number of map channels and shrink grooves throughout the bundle survival aera. Such static composition may lead to long of entirety limit as well as low structure capability usages. Its number one duty undergo minimize the final touch pace of enormous sets of MapReduce jobs. Hadoop Cluster handiest has predefined definitive groove contour for gather living chance. This precise position structure may cultivate long final touch era (Make span) and occasional structure capital usage. Our scheduled scenario enjoy allot capability dynamically to MapReduce tasks. It may well be stewed by following position ratio contour between map and cut back tasks, by updating the tasks at hand info of recently completed tasks. Many scheduling methodologies are discussed that aim to improve crowning glory future goal. Propose new proposals which use groove ratio between map and decrease tasks as a tunable knob for minimizing the finishing touch duration (i.e., makespan) of a obsessed set. By leveraging the tasks at hand science of recently completed jobs, blueprints dynamically set asides ability (or channels) to map and decrease tasks.
Index Terms- MapReduce, Makespan, Workload, Dynamic Slot Allocation
1. INTRODUCTION
A classic Hadoop cluster has a single name node and multiple data nodes. The name node, which is configured with job tracker, is responsible for job scheduling and job execution co-ordination. Each data node configured with task tracker, which manages MapReduce slots. Hadoop has a static slot configuration, which means a fixed number of map slots and reduce slots which are only used for
processing map reduce tasks. Map tasks can run by map slots, and reduce tasks can run in reduce slots. This static slot configuration may lead to poor performance and low resource utilization. Apache Hadoop components are responsible for running large data sets. Main Hadoop parallel processing components are Hadoop Distributed File System (HDFS), Hadoop YARN, and Hadoop MapReduce.
We plan progressive position shape, and that changing best friend earmarks grooves for map and decrease tasks. Our aim consider customize list knot process, whatever measure to enlarge increased loyalty for monitoring assignment science, changing position homework, and scheduling. Also, we have to lower the duty private detective channel quota program to aggressive best friend set aside tasks to MapReduce tasks with none niche blueprint. We could make use of map test channels (map channels) to decrease grooves and inversely. The soul at the back of productive position shape sniff out steer clear of hollow niche within the MapReduce niches. The job private detective estimates the present call of duty in every single test flatfoot the use of call of duty monitoring component.
© 2017, IRJET | Impact Factor value: 6.171 | ISO 9001:2008 Certified Journal
| Page 2061
A Hadoop gather has divorced grasp nodule and a couple of skivvy nodules. The grasp growth runs the Job Tracker system that is accountable for scheduling jobs and coordinating the consummation of tests of every job. Each slog bump runs the Task Tracker for web hosting the implementation of MapReduce jobs. The view of “channel” is well-known point out the power of friendly weighs on every single burl. In a Hadoop technique, a position is assigned as a map channel or a cut back position plate mapweighs or cut back charges, definitely. At any inured pace, only 1 strain may well be functioning per groove. The variety of available niches per growth easily provides the utmost grade of parallelization in Hadoop. Here demonstrated which the hole composition has an important sway structure drama. The Hadoop scheme use established numbers of map grooves and decrease positions at every single bump because the nonpayment ambience through the life of a bundle. The values in this defined structure are usually heuristic numbers without considering job characteristics. Therefore, this static backdrop is not well optimized and may hinder the drama recoverment of one's entire aggregate. In this work, propose and implement a new procedure to dynamically allocate positions for map and decrease pushs. The number one intention of your new system sniff out get better the of completion era (i.e., the makespan) of a shipment of MapReduce jobs although pay the purity in implementation and executive of your channel- primarily based Hadoop design.
The key meaning in this regard new process, titled TuMM, sniff out brutalize fruit machine homework quota 'tween map and decrease tasks inside a aggregate as a tunable lever for decreasing the makespan of MapReduce jobs.The Workload Monitor (WM) and the Slot Assigner (SA) are both principal components on speaking terms by TuMM. The WM that fact is living inside the JobTracker systematically collects the accomplishment show report of lately lost tasks and estimates the current map and decrease load within the bundle. The SA measure takes the reckoning to make a decision and conform fruit machine quota in the seam map and decrease tasks for every slave burl.With TuMM, the map and decrease phases of jobs might be excel pipelined lower than seniority primarily based schedulers, and then the makespan forget. Further the progressive hole appointments in opposed environments, and design a new edition of TuMM, picked H TuMM, that sets the slots configuquotans for every individual growth to cut back the makespan of a shipment of jobs.
The slot assigner component decides the optimum slot for assigning tasks. The schedulers are used to schedule the tasks in the data nodes. The task tracker sends the status report to the job tracker for every 3 minutes. Failure tasks are assigned to the next nodes based on this status report. The job tracker is always monitoring the task execution and slot assignment. The resources are allocated to map and reduce tasks by job tracker based on different job schedulers and resource allocation policies. Various schedulers are used that include FIFO, capacity, SLO, task schedulers, fair scheduler.
These schedulers follow different resource allocation strategies that include the Longest Approximation Time to End, delay, resource aware, deadline constraint, epoch based, moldable, malleable, fair4s job scheduling to improve MapReduce completion time and Hadoop performance. The purpose of this study is to analyze the various slot configurations, advantages, and disadvantages of all schedulers and also different resource allocation policies in MapReduce.
2. MAP REDUCE THEORY
© 2017, IRJET | Impact Factor value: 6.171 | ISO 9001:2008 Certified Journal
| Page 2062
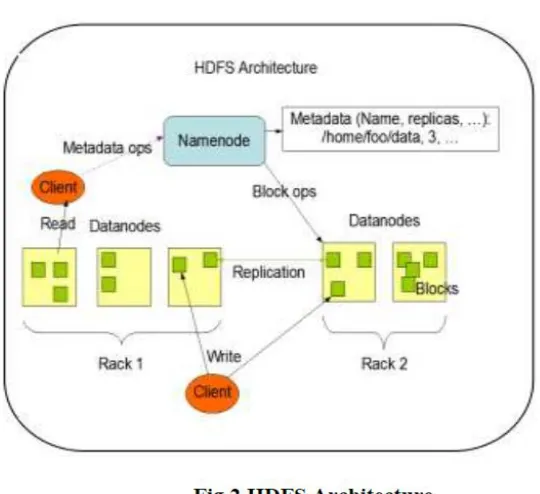
Figure 2 characterize HDFS has a master/slave construction. An HDFS cluster is composed of a sole NameNode, a master server that manages the file system namespace and regulates access to files by clients. In addition, there are a number of DataNodes, typically one per node in the cluster, which handle storage attached to the nodes that they run on. HDFS exposes a file structure namespace and permits user data to be stored in files. Internally, a file is split into one or more blocks and these blocks are stored in a set of DataNodes. The NameNode executes file process namespace operations want opportunity, closing, and renaming files and directories. It also determines the mapping of blocks to DataNodes. The DataNodes trigger serving read and write requests from the file system’s clients. The DataNodes also carry out block creation, deletion, and simulation upon discipline from the NameNode.
Improvements In Job Scheduling
Delay Scheduling is an final results of strict performance of fair allocation compromising region. To resolve this trouble of region, Delay scheduling algorithm was suggested, in which a job waits for a insufficient amount of time for a scheduling hope on a node that has data for it. The particular goal of Delay Scheduling is to statistically multiplex clusters while maintaining minimal impact on fairness and achieving high data locality. Delay scheduling set of rules temporarily relaxes fairness to get better
region by querying jobs to wait for a scheduling hope on a node with native data. Two region issues were pointed out from fair scheduler are: head-of-line scheduling and tricky notes. The first locality trouble occurs in small jobs. Whenever a job reaches the top of the taken care of list for scheduling, one of its tasks is sent on the next slot that becomes free regardless of which node the slot is on.
3. OBSERVATION
A. Which is optimal slot configuration method either static or dynamic ?
The dynamic slot composition is usually excellent because the fixed slot composition assigns the task to MapReduce slots earlier than the cluster start. So the number of empty slots may extend due to the of completion of map slots, and also chances of taking place overloaded decrease slots. Surely it affects of completion time of the task. Unlike fixed slot structure, dynamic slot configuration allocates slots during task implementation time. It reduces the number of empty slots and increases active slots.
B. Why authors prefer FIFO schedulers for task assignment?
The FIFO scheduler is the default Hadoop scheduler implemented in MapReduce applications. Some authors still select FIFO scheduler for his or her analyze, specially Y. Yao et al. [15]. There are two Common reasons are to pick out default first in first out schedulers. Firstly, N numbers of jobs are expecting acquiring assets. Secondly, all jobs can get assets without any starvation.
C. What is the reason to use different schedulers for slot assignment?
Schedulers are restricted according to the appearance metric, deadline aware, fairness metric, delay, source aware, and fair4s scheduling. Each scheduler has configured with one of the metric named above. Based on analyze advantage the different schedulers are used.
D. Why most people prefer single node Hadoop cluster for performance optimization?
[image:3.612.36.306.95.342.2]© 2017, IRJET | Impact Factor value: 6.171 | ISO 9001:2008 Certified Journal
| Page 2063
structure needs too in the name of accouterments and web facilities. Multi burl structure is you may handiest to forge a distort atmosphere. This could be the cause of configuring particular burl aggregate.
E. What is the Reason for using independent and dependent pools in slot allocation?
A test can be allocated with in the pool and around the pool. The fair scheduler allocates the same quantity of resource to active tasks. Sometimes the task within the pool needs resource across the pool. This is the main reason for dividing pools into autonomous and conditional. The conditional pool slots can dynamically allocate around the pool. But autonomous pool slots only allocates within the pool dynamically.
SYSTEM
MODEL
AND
DYNAMIC
SLOT
CONFIGURATION
UNDER
HETEROGENEOUS
ENVIRONMENTS
Heterogeneous environments are properly common in today’s cluster systems. For part, system managers of an individual data center could at all times scale up their input center by adding new real machines. Therefore, environmental machines with the different models and the different source capacities can exist at the same time in cloud Servers.
Figure:1. Architecture design the shade rectangles indicate our new/modified components in Hadoop
When deploying a Hadoop cluster [Figure 1] in such a opposed situation, tasks from the equivalent job could have different implementation times when running on the
different nodes. In this case, a task’s implementation time really depends on a certain node where that task is running. A job’s map tasks may run faster on a node which has faster cpu per slot while its reduce tasks may revel in shorter implementation times on the other nodes that have more memoir per slot. Estimating the remaining tasks at hand and necessary the slot configuration in opposed Hadoop cluster becomes more complex.
For example, consider a Hadoop job with 7 map tasks and a Hadoop cluster with two heterogeneous nodes such that node 1 is faster than node 2. Consider a cluster configured with 4 map slots in total, and one map task of that job takes 1 second and 2 seconds to finish on node 1 and node 2, respectively. We note that in this heterogeneous Hadoop cluster, various slot configurations will yield different performance (e.g., the execution time) of this job.
As adorned in [Figure 2] case 1, the total accomplishment time of the map phase takes slot on node 2. However, the map phase consummation time can be progressed to 3 seconds if we modify the slot configures on these two nodes, i.e., 3 map slot on node 1 and 1 map slots on node 2. This job indicates full is more difficult to predict the time had to end the map aspect or decrease aspect in the opposed situation, and precisely arrange the map (or decrease) slot assignments around the cluster will now not work well. Which utilizes the overall assignment instruction to set the slot assignments over the whole cluster doesn't work well any further when the nodes in the cluster develop into heterogenous. New translation of TuMM, named H TuMM, which dynamically sets the slot configurations for each node in a opposed Hadoop cluster in order to reduce the makespan of Hadoop jobs.
© 2017, IRJET | Impact Factor value: 6.171 | ISO 9001:2008 Certified Journal
| Page 2064
Algorithm Design: H TuMM H TuMM shares the similarsolution of TuMM, i.e., dynamically assign slots to map and reduce tasks to adjust the method of map and reduce stage in line with the possessed assignment information. The key argument of H TuMM is to set the slot configurations for each node personally in a opposed cluster, i.e., each of those nodes will have the different slot assignment ratio between map and reduce tasks. To accomplish it, H TuMM collects the load information at the full cluster and on each entity node as well: when a map/reduce task is finished on node i, the tasks at hand collector updates.
(1) The average execution time of map/reduce tasks, i.e., tm/tr;
(2) The average execution of map/reduce tasks that ran on node i, i.e., ti
Algorithm: Slot Assignment for Node :
4. Results
In This section we've got shown the working of the expected system. The data shows the total recommended time for the of entirety of task for proposed system against this with the actual system which is Maximum Cost Performance. In chart it also shows the particular time
recommended for all the three techniques Dynamic Hadoop Slot Allocation (DHSA), Speculative Execution Performance Balancing (SEPB) and Slot Pre-Scheduling. The chart 1 shows the time recommended to finish the tasks in MCP is larger than in comparison to DSAS. The performance of the MCP degrades as the time speeds up.
5.CONCLUSION
Dynamic slot structure is one of the very important factors while processing a huge data set with MapReduce prototype. It optimizes the appearance of MapReduce structure. Each job can be scheduled using anyone of the scheduling policies by the job tracker. The task managers which are found in the task tracker allocate slots to jobs. From the examined paper, it is concluded to prefer a dynamic slot allocation strategy that includes active jobs load estimation, excellent slot appointment, and scheduling policy.
REFERENCES
[1] J. Dean and S. Ghemawat, “MapReduce: simplified data processing on large clusters”, in Communications of the ACM, vol. 51, 2008.
© 2017, IRJET | Impact Factor value: 6.171 | ISO 9001:2008 Certified Journal
| Page 2065
[3] J. Wolf, D. Rajan, K. Hildrum, R. Khandekar, V. Kumar, S. Parekh, K.-L. Wu, and A. Balmin, “Flex: A slot allocation scheduling optimizer for MapReduce workloads”, in Middleware 2010, ser. Lecture Notes in Computer Science, I. Gupta and C. Mascolo, Eds. Springer Berlin / Heidelberg, vol. 6452. pp. 1, 2010.
[4] Apache Hadoop. Reference link: http://hadoop.apache.org.
[5] A. Verma, L. Cherkasova, and R. H. Campbell, “ARIA: Automatic Resource inference and allocation for MapReduce environments”, in International Conference on Autonomic Computing, 2011.
[6] Apache Hadoop YARN (yet another resource
negotiator) Reference Link:
https://hadoop.apache.org/docs/current/hadoopyarn/ hadoop- yarn-site/YARN.html.
[7] B. Sharma, R. Prabhakar, S.-H. Lim et al., “Mrorchestrator: A fine grained resource orchestration framework for MapReduce clusters”, in CLOUD’12, 2012.
[8] V. K. Vavilapalli, A. C. Murthy, C. Douglas, S. Agarwal, M. Konar, R. Evans, T. Graves, J. Lowe, H. Shah, S. Seth et al., “Apache Hadoop yarn: Yet another resource negotiator”, in Proceedings of the 4th annual Symposium on Cloud Computing. ACM, 2013.