International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 1, Issue 1, November 2011)42
Applying Feedback Mechanism for Content Based Image
Retrieval Using Data Mining Technique
Vaishali Khandave
1, Nitin Mishra
21M.Tech Scholar, Nri Institute of Information Science and Technology, Bhopal 2Assistant Professor (I.T), Nri Institute of Information Science and Technology, Bhopal
1[email protected] 2[email protected]
Abstract— A project that riggingand tests a simple color histogram based search and recover algorithm for images. The study finds the technique to be helpful as shown by analysis using the Rank Power measurement. The testing also highlights the weaknesses and strengths of the model, ultimate that the technique would have to be improved and customized in order for practical use. The aim of this paper to develop such a color histogram based categorization approach, which is well-organized, fast and enough strong. In the interest of this I used some characteristics of color histograms, and classified the images using these characteristics. The benefit of this approach is the relationship of histogram characteristics is much faster and well-organized than of other commonly used methods. Database search engines are generally used in a one-shot fashion in which a user provides query information to the system and, in return, the system provides a number of database instances to the user. A significance opinion system allows the user to indicate to the system which of these instances are attractive, or significant, and which are not. Based on this feedback, the system modifies its retrieval method in an attempt to return a more desirable instance set to the user.
Key words — Content-based image retrieval, significance feedback, K-Means, query expansion, direction-finding prototype mining.
I.INTRODUCTION
Content-based image liberate, a technique which uses visual filling to search images from huge level image databases according to users' benefit, has been an lively and fast advancing investigate area since the 1990s.
e.g. [11]
all through the past decade, important progress has been made in both pretend research and system advance. However, there hang regarding many difficult research problems that continue to attract researchers from several authority. [image:1.612.334.536.478.542.2]Before introducing the original theory of content-based recovery, we will take a short look at its development. Early work on image retrieval can be traced back to the late 1970s. In 1979, a discussion on Database Techniques for detailed Applications was held in Florence. Since then, the application possible of image database management techniques has disturbed the notice of researchers. Early techniques were not generally based on design characteristics but on the textual appendix of images. In other words, images were first interpret with text and then search using a text-based come near from usual database management systems. All-inclusive surveys of early text-based image retrieval methods can be found in. Text-based image retrieval uses traditional database techniques to manage images. All the way through text descriptions, images can be planned by significant
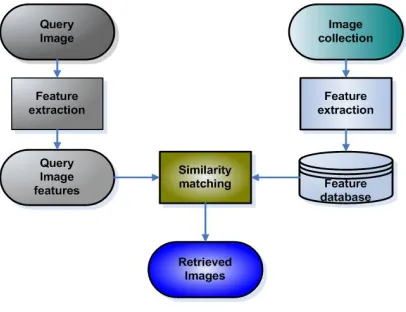
Figure 1.1 local histogram based system
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 1, Issue 1, November 2011)42
[image:2.612.329.532.157.313.2]Content-based image retrieval uses the illustration contents of an image such as color, shape, surface, and spatial arrangement to represent and index the image. In typical local histogram based system (Figure 1-1), the visual contents of the images in the database are remove and describe by multi-dimensional characteristic vectors
e.g. [5]
. The attribute vectors of the images in the database form a characteristic database. To retrieve images, users provide the retrieval system with example images or sketch figures. The system then changes these examples into its internal representation of characteristic vectors. The related ity distance between the characteristic vectors of the query example or drawing and those of the images in the database are then calculated and taking back is performed with the aid of an indexing visual information, are on the increase worldwide. The goal of this project is to travel around important enabling techniques for an image retrieval system to lay a solid method. The indexing method provides a well-organized way to search for the image database. Recent retrieval systems have incorporated users' relevance feedback to modify the taking back process in order to generate perceptually and semantically more important retrieval results. In this chapter, we introduce these essential techniques for content-based image retrieval. image (in the form of a histogram or probability distribution depicting the intensities of pixels in an image) is the most widely used characteristic for content-based image retrieval (CBIR),e.g. [12]
while texture and shape characteristics are also used, albeit to a smaller degree. The three types of image characteristics are utilized in different CBIR applications ranging from scene/object and fingerprint categorization and matching to face and pattern identification. More frequentlythan not, a single characteristic is not enough to seperate among a homogeneous group of images. In such cases, either pairs of these characteristics or all of them are used for the purpose of indexing and retrieval.The advance in multimedia content have fashioned an massive number of digital imagery files in a mixture of application domains. All this imagery in sequence is useful only when one can access it well-organizedly.Fig. 1.2. Content Based Image System
Thus, the demands for an intellectual CBIR system, capable of effective considerate and exact retrieval of foundation for future multimedia search engines. We will focus on developing an automatic image marginal note factor, a relevance feedback-based image retrieval factor, or a semantic-correlation-based image retrieval factor
Overview of the Image Search Method
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 1, Issue 1, November 2011)43
words. This variant will be referred to as several assignments (MA) in the experiments. Weighting frequency vectors, Representation of the image. Distance: A distance transform, also known as distance map or distance field, is a derived representation of a digital image. The choice of the term depends on the point of view on the object in question: whether the primary image is transformed into another representation, or it is simply capable with an additional map or field.
Well-Organized Search: The distance calculation is optimizedwith an inverted file system exploiting the sparsely of the visual word vectors. Such an inverted file can be used for Any Murkowski norm when the vectors are of unit norm. For huge expressions sizes, the strategies projected in and greatly reduce the cost of passing on the descriptors to visual words.
Rank Aggregation: The idea is to use several visual vocabularies, i.e., to merge the results of several image search systems where each one uses different expressions each expression is learned on a different subset of the descriptors.
II.PROJECT WORK
Relevance feedback in principle, refers to a set of approaches learning from an range of users’ browsing behaviors on image retrieval Some earlier studies for RF make use of existing machine learning techniques to achieve semantic image retrieval, including Statistics, EM, KNN, etc. While these forerunners were devoted to methodting the special semantic characteristics for image retrieval, e.g., Photo book BIC, Visual SEEK, there still have not been ideal descriptions for semantic characteristics. This is because of the diversity of visual characteristics, which widely exists in real applications of image retrieval. Therefore, active query modification, based on the analysis of usage logs, attracts researchers’ attention in this area of RF.
A. Query Reweighting
Some previous work keeps an eye on investigating what visual characteristics are important for those images (positive examples) picked up by the users at each feedback (also called iteration in this paper).
e.g.[1]
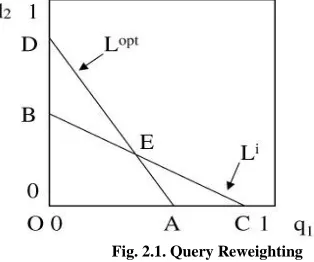
The notion behind QR is that, if the ith characteristic fi exists in positive examples frequently, the system assigns the higher degree to fi. QRlike approaches were first projected by Rui et al, which convert image characteristic vectors to weighted-term vectors in early version of Multimedia Analysis and Retrieval System (MARS). Furthermore, Rui et al. provided a new method for query reweighting to deal with document retrieval. The projected method uses genetic algorithms to reweight a user's query vector, based on the user's relevance feedback, to improve the [image:3.612.327.484.374.505.2]performance of document retrieval systems. Chromosome is found, the projected method decodes the chromosome into the user's query vector for dealing with document retrieval. The projected query reweighting method can find the best weights of query terms in the user's query vector, based on the user's relevance feedback. It can increase the precision rate and the recall rate of the document retrieval system for dealing with document retrieval.
Fig. 2.1. Query Reweighting
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 1, Issue 1, November 2011)44
B. Online Image Search
As we can recall from previous explanations, the aim of the search strategy is to attack the weakness of the traditional approaches, including redundant browsing and exploration convergence. Indeed, these unsolved problems result in large limitation in RF. Perhaps, the aged hybrid systems fusing the results generated by several query modification systems can look for the better results than individual systems. However, the expensive calculation cost makes it impractical in real applications. Instead, we attempt to approximate the optimal result, namely NPRFSearch.
e.g[10]
, to resolve such problems by using the generated navigation patterns. For the problem of exploration convergence, our projected approach extends the search range from a query point to a number of significant navigation paths. As a result, each iterative search can escape from the local optimal space and further move toward the global optimal space for the user’s interest. For the problem of redundant browsing, the discovered navigation patterns are adopted as the shortest paths to derive the superior results in a shorter feedback process. Additionally, the expensive navigation cost is saved further, especially for the massive image data. In general, the NPRFSearch algorithm can be recognized as a very important part of our projected iterative result to RF, which merges QEX, QP, and QR strategiesAlgorithm NPRFSearch:
As already described above, with the help of navigation patterns NPRFSearch gets to reach high precision of image retrival in shorter query.
NPRFSearch algoritm is triggered by receiving 1) Set of positive examples G, Set of negative examples N which are determined from user feedback. 2) Set of Navigation Patterns TR = {tr1, tr2..trh} where trh referes to query seed rth and several patterns {C11,C32,C42,} and accuracy threashhold thrd. The iterative procedure can be shown accordingly
1. Genearate a new query point by averaging the visual-features of positive examples. 2. Find the matching navigation patterns by
calculating nearest query seeds (root). 3. Calculate the nearest leaf node from the
matching navigation patterns tree.
4. Find the top s relevant visual query points from the set of the nearest leaf node nodes.
5. Finally the top k images are returned to the user.
From the aspect of NPRFSearch, step1 can be regarded as QPM and steps 2-5 can be regarded as QEX. For QR the feature weights are iteratively updated based on positive examples at each feedback.As a whole,the proposed NPRF search takes advantage of QPM, QEX, QR and navigation patterns to make RF more efficiently and effectively.Without navigation patterns,NPRF search can not reach high quality of RF. From the viewpoint of applicability, the goal of our approach is to satisfy each query efficiently instead of providing personalized functions for each user.So irrelevant queries from a user will not be a problem.
The well-known space-vector method projected.
where Qi is the vector of the ith query, Rj is the vector of the jth significant image, IRj is the vector of the jth unrelated image, nr is the cardinality of significant images, and nir is the cardinality of unrelated images. One of the QPM approaches is the modified version of. MARS performs weighted euclidean distance to calculate the related ity between the query and the targets. Another well-known study is MindReader, which took advantage of a generalized euclidean distance to look for the targets in well ellipsoids. However, different visual contents shared by different kinds of images spoil the retrieval quality very much. Also, it is very difficult to derive an adaptive and ideal measuring function. A specific measuring function indeed cannot cover all target groups with different visual contents. Moreover, the modified query point of each feedback most likely moves toward the local optimal centroid. Thus, global optimal results are not easily touched in QPMlike work.
C. Query Expansion
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 1, Issue 1, November 2011)45
[image:5.612.81.290.246.373.2]broad characteristic space. As a result, different results for the same concept are difficult to attain. For this reason, the modified version of MARS groups the related significant points into several clusters, and selects good representative points from these clusters to construct the multipoint query. Wu et al. projected FALCON, which is designed to handle disjunctive queries within random metric spaces.
Fig.2.2Query Exapansion
Qcluster, developed by Kim and Chung plans to handle the disjunctive queries by employing adaptive categorization and cluster merging methods. As experimented in earlier studies, the effectiveness of QEX is better than those of QPM and QR. However, there are still some problems unanswered for QEX. For MARS, unsuitable search states cannot deal with complex queries. For FALCON, the significant query points are too many to be well-organized. Adjusting the disjunctive queries causes the expensive search cost and the results cannot escape from the restricted range (clusters) that the users are able to specify. On the whole, QEX brings out higher calculation cost and more feedbacks in RF.
D. Hybrid RF
In addition to past studies previously explained, another type of RF approach emphasizes the integration of different search strategies However, this kind of method is instinctive, and very little hybridized work focuses on the accumulated information (long-term usage log) coming from different users. Moreover, the greater effectiveness of the multisystem requires a higher calculation cost, due to several processings. One of the hybrid RF strategies is IRRL. IRRL, projected by Yin et al. addresses the important experimental question of how to precisely
capture the user’s interest at each feedback. In IRRL, exploiting knowledge from the long-term experience of users can facilitate the selection of several RF techniques to get the best results. The derived problems from IRRL are: the selection of optimal RF technique cannot avoid the overhead of long iterations of feedback. Also, the visual diversity existing in the global characteristic space cannot be resolved with an optimal RF technique alone.
III EXPERIMENTAL RESULTS
A.K-Means Clustering
In statistics and data mining, k-means clustering is a method of cluster analysis which aims to partition n observations into k clusters in which each observation belongs to the cluster with the nearest mean. This results into a partitioning of the data space into Verona cells. The problem is calculationally difficult (NP-hard), however there are well-organized heuristic algorithms that are commonly employed that converge fast to a local optimum. These are usually related to the expectation-maximization algorithm for mixtures
Fig. 3.1 K-Means Cluster
[image:5.612.333.533.438.603.2]International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 1, Issue 1, November 2011)46
X1,…, XN are data points or vectors or observations
Each observation will be assigned to one and only one cluster
C(i) denotes cluster number for the ith observation Disrelated ity measure: Euclidean distance metric K-means minimizes within-cluster point scatter:
where
o m
Mk is the mean vector of the kth cluster
o N
Nk is the number of observations in kth cluster
Commonly used primaryization methods are Forgy and Random Partition. The Forgy method randomly chooses k observations from the data set and uses these as the primary means. The Random Partition method first randomly assigns a cluster to each observation and then proceeds to the Update step, thus computing the primary means to be the centroid of the cluster's randomly assigned points. The Forgy method tends to spread the primary means out, while Random Partition places all of them close to the center of the data set. According to Hamerly et al the Random Partition method is generally preferable.k-means clustering result for the Iris flower data set and actual species visualized using ELKI
e.g. [8]
. Cluster means are marked using larger, semi-transparent symbols. B.HistogramA histogram is a graphical data analysis technique for summarizing the distributional information of a variable. The response variable is divided into equal sized intervals (or bins). The number of occurrences of the response variable is calculated for each bin. The histogram consists of: Vertical axis = frequencies or relative frequencies; Horizontal axis = response variable (i.e., the mid-point of each interval).
There are 4 types of histograms:
1.histogram (absolute counts);
2.relative histogram (converts counts to proportions);
3.cumulative histogram;
4.cumulative relative histogram.
The histogram and the frequency plot have the same information except the histogram has bars at the frequency values, whereas the frequency plot has lines connecting the frequency values.
Syntax 1: HISTOGRAM
<y> <SUBSET/EXCEPT/FORqualification> RELATIVE HISTOGRAM <y> <SUBSET/EXCEPT/FOR qualification> CUMULATIVE HISTOGRAM <y> <SUBSET/EXCEPT/FOR qualification> CUMULATIVE RELATIVE HISTOGRAM <y> <SUBSET/EXCEPT/FOR qualification> where <y> is the variable of raw data values which will appear on the horizontal axis; and where the <SUBSET/EXCEPT/FOR qualification is optional.This syntax is used whenyou have raw data only.
Examples: Histogram Temp Relative Histogram Temp
Cumulative Histogram Temp Cumulative Relative Histogram Temp Histogram Counts State Relative Histogram Counts State Cumulative Histogram Counts State Cumulative Relative Histogram Counts
Fig. 3.2 Histogram Calculation
Kk Ci k k i k K
k Ci kC j k j
i
x
N
x
m
x
C
W
1 ()
2
1 () ()
2
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 1, Issue 1, November 2011)47
Color Spaces:
Digital representation of color images is realized by storage of color intensity values of each pixels. These intensity values usually are explained by three dimensional vectors, whose factors largely depend on the applied color space. The detailed description of color spaces can be found.
RGB Color Space:
RGB space is a widely used color space for image display. It is collected of three color factors red, green and blue. Since color cameras, scanners and displays are most frequently provided with direct RGB signal input and output, this color space is the basic one, which is, if necessary, transformed into other color spaces. In order to eliminate the influence of explanation amount, color can be plotted on a two-dimensional diagram such as: r + g + b = 1. Tristimulus values are thus definied by:
where R, G and B the red, green and blue coordinates of one pixel in RGB space, and r, g and b the coorinates of the same pixel in rgb space, respectively. The transformation from RGB space to rgb space a very simple color normalization method, whose advantage is the quick calculation. We should use much more difficult normalization method as well, which remains in the RGB space, i.e. color cluster rotation.
IV. CONCLUSION
To deal with the long iteration problem of CBIR with RF, we have presented a new approach named NPRF by integrating the navigation pattern mining and a navigation- pattern-based search approach named NPSearch. In summary, the main characteristic of NPRF is to well-organizedly optimize the retrieval quality of interactive CBIR. On one hand, the navigation patterns derived from the users’ longterm browsing behaviors are used as a good support for minimizing the number of user feedbacks.On the other hand, the projected algorithm NPRF Search performs the navigation- pattern-based search to match the user’s intention by merging three query modification strategies. As a result, traditional problems such as visual diversity and exploration convergence are
solved. For navigation-pattern-based search, the hierarchical BFS-based KNN
e.g. [9]
is employed to narrow the gap between visual characteristics and human concepts effectively. In addition, the involved methods for special data partition and pattern trimming also speed up the image exploration. The experimental results reveal that the projected approach NPRF is very effective in terms of precision and coverage. Within a very short term of relevance feedback, the navigation patterns can assist the users in attaining the global optimal results. Moreover, the new search algorithm NPRFSearch can bring out more exact results than other well-known approaches. In the future, there are some outstanding issues to investigate. First, in view of very large data sets, we will scale our projected method by utilizing parallel and distributed computing techniques. Second, we will incorporate user’s profile into NPRF to further increase the retrieval quality. Third, we will apply the NPRF approach to more kinds of applications on multimedia retrieval or multimedia proposal.References
[1] M.D. Flickner, H. Sawhney, W. Niblack, J. Ashley, Q. Huang, B. Dom, M. Gorkani, J. Hafner, D. Lee, D. Steele, and P. Yanker, “Query by Image and Video Content: The QBI System,” Calculater, vol. 28, no. 9, pp. 23-32, Sept. 1995. [2] R. Fagin, “Combining Fuzzy Information from Several Systems,” Proc. Symp. Principles of Database Systems (PODS), pp. 216-226, June 1996.
[3] R. Fagin, “Fuzzy Queries in Multimedia Database Systems,” Proc. Symp. Principles of Database Systems (PODS), pp. 1-10, June 1998.
[4] J. French and X-Y. Jin, “An Experimental Investigation of the Scalability of a Several Viewpoint CBIR System,” Proc. Int’l Conf. Image and Video Retrieval (CIVR), pp. 252-260, July 2004.
[5] D. Harman, “Relevance Feedback Revisited,” Proc. 15th Ann. Int’l ACM SIGIR Conf. Research and Development in Information Retrieval, pp. 1-10, 1992.
[6] Y. Ishikawa, R. Subramanya, and C. Faloutsos, “MindReader: Querying Databases through Several Examples,” Proc. 24th
Int’l Conf. Very Large Data Bases (VLDB), pp. 218-227, 1998.
[7] X. Jin and J.C. French, “Improving Image Retrieval Effectiveness via Several Queries,” Multimedia Tools and Applications, vol. 26, pp. 221-245, June 2005.
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, Volume 1, Issue 1, November 2011)48
[10] J. Liu, Z. Li, M. Li, H. Lu, and S. Ma, “Human Behaviour Consistent Relevance Feedback Model for Image Retrieval,” Proc. 15th Int’l Conf. Multimedia, pp. 269-272, Sept. 2007.
[11] A. Pentalnd, R.W. Picard, and S. Sclaroff, “Photobook: Content- Based Manipulation of Image Databases,” Int’l J. Calculater Vision (IJCV), vol. 18, no. 3, pp. 233-254, June 1996.