Using Gaze Information
A Thesis Submitted to The University
of Kent
For The Degree of Doctor of Philosophy
In Electronic Engineering
Asad Ali
March 2015
Abstract
This thesis is concerned with liveness detection for biometric systems and in particular for face recognition systems. Biometric systems are well studied and have the potential to provide satisfactory solutions for a variety of applications. However, presentation attacks (spoofing), where an attempt is made at subvert-ing them system by maksubvert-ing a deliberate presentation at the sensor is a serious challenge to their use in unattended applications. Liveness detection techniques can help with protecting biometric systems from attacks made through the pre-sentation of artefacts and recordings at the sensor. In this work novel techniques for liveness detection are presented using gaze information.
The notion of natural gaze stability is introduced and used to develop a number of novel features that rely on directing the gaze of the user and establishing its behaviour. These features are then used to develop systems for detecting spoofing attempts. The attack scenarios considered in this work include the use of hand held photos and photo masks as well as video reply to subvert the system. The proposed features and systems based on them were evaluated extensively using data captured from genuine and fake attempts.
The results of the evaluations indicate that gaze-based features can be used to discriminate between genuine and imposter. Combining features through feature selection and score fusion substantially improved the performance of the proposed features.
I would like to thank my supervisors Dr. Farzin Deravi and Dr. Sanaul Hoque for their guidance and support. I thank them especially for giving me the freedom to explore new research ideas. My conversations with them have been a source of great encouragement, inspiration and learning. Their words of wisdom and advice for my work has always been invaluable and has been instrumental to finishing my PhD. I would also like to thank the school of Engineering and Digital Arts and the University of Kent for providing me the financial support.
I would also like to thank Mr. Harvey Twyman and Mr. Clive Birch of the technical team at the School of Engineering and Digital Arts for their timely help whenever.
Special thanks go to Mr. Richard Douglas and Helen Winder, who patiently made every effort to support me in every way they could. Without their encour-aging words and support, finishing the PhD would not have been possible.
Finally, I would like to thank my family in Pakistan and in the UK. I would not have finished this PhD without the support, love and encouragement from my elder brother. Their wisdom and insight has been a great source of strength.
Contents
Abstract i Acknowledgements ii List of Figures vi 1 Introduction 1 1.1 Biometric systems. . . 2 1.2 Motivation . . . 51.3 Aims and Objectives . . . 8
1.4 Scope of the Project . . . 8
1.5 Structure of the Thesis . . . 9
2 Literature Review 11 2.1 Introduction . . . 11
2.2 Literature . . . 12
2.2.1 Eyeblink Based Liveness detection. . . 12
2.2.2 Face Liveness Detection using Frequency and Texture Anal-ysis . . . 21
2.2.3 Challenge Response Mechanisms. . . 28
2.2.4 3D face . . . 32
2.2.5 Face Liveness Assessment Using Motion Analysis . . . 33
2.2.6 Miscellaneous Technologies . . . 37 3 Experimental Framework 41 3.1 Introduction . . . 41 3.2 Proposed System . . . 42 3.3 Attack Scenarios . . . 43 3.4 Implementation . . . 46 3.4.1 Hardware Setup . . . 46
3.4.2 Challenge Design and Response Acquisition . . . 46
3.5 Data Collection . . . 48 3.5.1 Initial Database . . . 49 3.5.2 Extended Database . . . 50 3.5.3 Implementation Details . . . 52 3.5.4 Subjects . . . 55 3.5.5 Data Storage . . . 56 3.6 Performance Analysis . . . 57 3.7 Conclusion . . . 58 4 Gaze Colocation 59 4.1 Introduction . . . 59
4.2 Gaze Colocation Motivation . . . 60
4.3 Gaze Colocation Features . . . 61
4.4 Experimental Evaluation . . . 65
4.4.1 Preliminary Experimental Results . . . 65
4.4.1.1 Single Eye Feature . . . 65
4.4.1.2 Feature Fusion . . . 66
4.4.1.3 Score Fusion . . . 68
4.5 Extended Experimental Results . . . 73
4.6 Conclusion . . . 79
5 Gaze Collinearity 80 5.1 Introduction . . . 80
5.2 Gaze Collinearity Motivation. . . 81
5.3 Gaze Collinearity Features . . . 82
5.4 Experimental Results . . . 88
5.4.1 Preliminary Experimental Results . . . 88
5.4.2 Directional Sensitivity in Gaze Collinearity . . . 91
5.4.3 Extended Experimental Results . . . 95
5.5 Fusion both Collinearity and Colocation . . . 98
5.6 Conclusion . . . 105
6 Gaze Homography-based Feature 107 6.1 Introduction . . . 107
6.2 Homography and its Estimation . . . 108
6.3 Feature based on Gaze Homography. . . 111
6.4 Proposed Systems . . . 113 6.4.1 System 1. . . 114 6.4.2 System 2. . . 115 6.5 Experiment . . . 116 6.5.1 Preliminary Experiments . . . 116 6.5.2 Extended Experiments . . . 118
6.6 Fusion of Colocation, Collinearity and Homography . . . 122
6.7 Conclusion . . . 132
Contents v
7 Conclusions and Future Work 134
7.1 Introduction . . . 134
7.2 Summary and Conclusion . . . 134
7.3 Main Contributions . . . 137
7.4 Recommendations for Future Work . . . 137
List of Publications 139
Bibliography 140
1.1 Possible points where biometrics system can be attacked. (The focus of the thesis is shown by the red arrow - presentation attacks) 4
1.2 System structure flow diagram . . . 7
2.1 Graphic structure of CRF-based blinking model. C and NC are for closed state and non-closed state respectively [1] . . . 14
2.2 Illustration of the blinking activity sequence. The value of the closeness for each frame is below the corresponding frame. The bigger the value, higher the degree of closeness [2] . . . 15
2.3 Examples of scene region of interest and fiducial points extraction. Yellow dashed line rectangles are face regions and red solid line rectangles are scene regions of interest. Fiducial points are labeled by colorful squares [3]. . . 16
2.4 Illustration of liveness detection system using a combination of eyeblinks and scene context [3]. . . 17
2.5 (a) Keep photo still. (b) Move vertically, horizontally, backward and forward. (c) Rotate in depth. (d) Rotate in plane. (e) Bend inward and outward [3] . . . 18
2.6 The first row is four scene reference images. The second row is live faces in video [3] . . . 18
2.7 Example of binarized eye regions of (a) fake face and (b) live face [4] . . . 19
2.8 Algorithm flowchart . . . 21
2.9 Eye opening estimation [5] . . . 21
2.10 Frequency-based feature extraction (a) original facial image (b) Log-scale magnitude of the Fourier-transformed image (power spec-trum) (c) 1-D frequency feature vector extracted from the normal-ized power spectrum [6] . . . 22
2.11 Feature vector extraction process based on LBP (a) original facial image (b) LBP-coded image (c) histogram of the LBP-coded image [7] . . . 23
2.12 Block diagram of the used fusion strategy [8] . . . 25
2.13 Difference between live face and fake face in frequency domain [9] 26
2.14 The framework of the proposed approach for liveness detection by Wu [10] . . . 28
List of Figures vii
2.15 Random challenge directions [11] . . . 29
2.16 Dimension reduction of the extracted velocities in the mouth re-gion [12] . . . 30
2.17 Head motion actions examples [13] . . . 32
2.18 Proposed anti spoofing system [14] . . . 33
2.19 The Genuine and Fake attempt example [15] . . . 34
2.20 Optical flow fields generated by four basic types of relative motions (a) Translation (b) Rotation (c) Moving forward or backward (d) Swing [16] . . . 36
2.21 Examples of the optical flow fields with (a) Group 1 (b) Group 2 (c)Group 3 [16] . . . 37
2.22 Stages of SuperRes algorithm . . . 38
2.23 Examples of genuine and video replay with and without flashlight. (a) Genuine user without flashlight (b) Genuine user under flash-light (c) Video replay without flashflash-light (d) Video replay under flashlight [17] . . . 40
3.1 Proposed system block diagram . . . 43
3.2 Example of Genuine attempt. . . 44
3.3 Example of Photo Spoof attempt . . . 44
3.4 Example of Photo Mask Spoof attempt . . . 45
3.5 Example of Video replay Spoof attempt. . . 45
3.6 Data Acquisition Setup . . . 47
3.7 Challenge Locations . . . 47
3.8 Pupillary distance ruler for measuring subjects PD . . . 51
3.9 Landmarks extracted (best fit) using STASM . . . 54
3.10 Landmarks extracted (poor fit)using STASM . . . 55
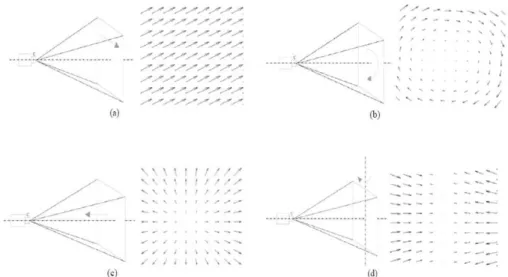
4.1 Pupil coordinates deviations from mean during genuine attempt for a location of the stimulus. . . 61
4.2 Pupil coordinates deviations from mean during spoof attempt for a location of the stimulus. . . 62
4.3 Observed (•) and expected (?) landmark positions . . . 63
4.4 Scheme, where feature extracted from single-eye . . . 66
4.5 Performance with single eye feature using the entire feature vector for photo attack . . . 67
4.6 Feature fusion using left and right eye. . . 67
4.7 Feature fusion performance from both eyes for photo attack . . . 68
4.8 Score fusion scheme . . . 68
4.9 Score fusion performance of both eyes for photo attack . . . 69
4.10 Variation in accuracy with feature dimension for feature and score fusion . . . 70
4.11 Feature performance with single-eye feature . . . 71
4.12 Feature fusion performance. . . 72
4.13 Score fusion performance . . . 73
4.14 ROC curve of the colocation feature using entire feature set for
photo attack. . . 74
4.15 ROC curve of the colocation feature using entire feature set for mask attack . . . 75
4.16 ROC curve of the colocation feature using entire feature set for video replay attack . . . 76
4.17 Variation in accuracy with feature dimension . . . 77
4.18 Variation in accuracy with FPR . . . 77
4.19 ROC curve of the colocation feature using optimum feature set . . 78
5.1 Vertical and Horizontal Collinear set of points . . . 82
5.2 Observed locations (•) and expected locus of the landmark posi-tions (–) . . . 84
5.3 Observed locations (•) and expected locus of the landmark posi-tions (–) . . . 86
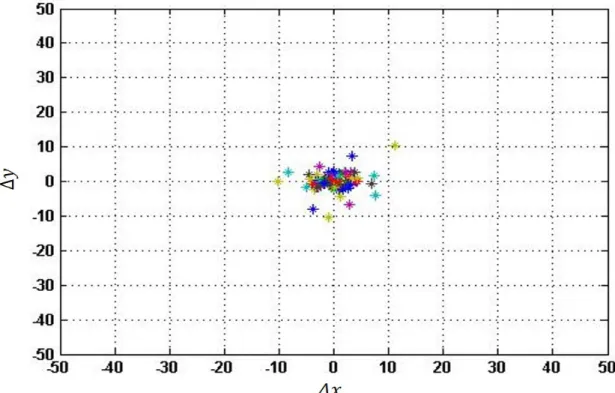
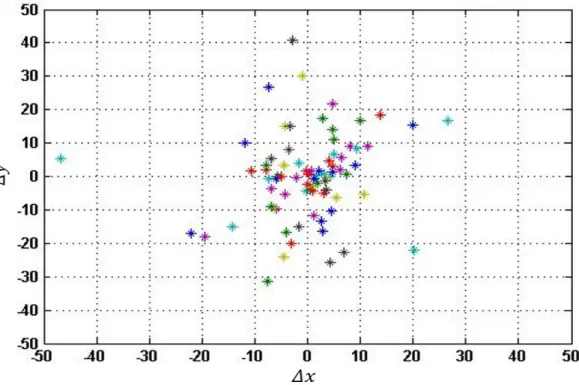
5.4 Feature distribution with outlier inclusion . . . 89
5.5 Feature distribution without outliers . . . 90
5.6 Score fusion using x coordinates of the left and right eye . . . 92
5.7 Score fusion using y coordinates of the left and right eye . . . 93
5.8 Score fusion using x and y coordinates of the left and right eye . . 93
5.9 ROC curves showing the performances of the three proposed schemes 94 5.10 Variation in accuracy with FPR for Collinearity Feature . . . 97
5.11 ROC curve of the proposed system using optimum feature set schemes . . . 98
5.12 Collinearity and colocation fusion . . . 99
5.13 ROC curve using entire feature vector. . . 100
5.14 Variation in accuracy with feature dimension . . . 101
5.15 ROC curve of the proposed system using optimum feature set . . 102
5.16 Score fusion performance using optimum feature sets . . . 103
5.17 Genuine vs fake (photo, mask, video) performance using optimum feature sets . . . 104
6.1 Score fusion using feature extracted from left and right eye . . . . 114
6.2 System 1, where set of H matrixes are calculated. . . 115
6.3 System 2 . . . 115
6.4 ROC curves of System 1 using normalised pupil centre and corre-sponding screen coordinates for calculating H . . . 117
6.5 ROC curves of System 2 using normalised pupil centre and corre-sponding screen coordinates for calculating H . . . 118
6.6 ROC curves of System 1 using pupil centre and corresponding screen coordinates for calculating H . . . 119
6.7 Variation in accuracy with homography feature dimension . . . . 120
6.8 ROC curve for phot, mask video using optimum feature vector . . 121
6.9 Proposed scheme combining collinearity, colocation and homogra-phy using score fusion . . . 123
List of Figures ix
6.10 ROC curve for photo using proposed fusion scheme . . . 124
6.11 ROC curve for mask using proposed fusion scheme. . . 125
6.12 Variation in accuracy with feature dimension . . . 126
6.13 ROC curve of the proposed system using optimum feature set schemes . . . 127
6.14 Collinearity, colocation and homography feature . . . 129
6.15 f:Variation in accuracy with gaze feature dimension for collinearity, colocation and homography . . . 130
6.16 Collinearity, colocation and homography feature using an opti-mum feature sets . . . 131
6.17 ROC curve for impostor detection using fusion . . . 132
Introduction
This thesis is concerned with liveness detection for biometric systems. Biomet-ric systems have the potential to provide security for a variety of applications. Biometric systems are vulnerable to certain attacks. Security countermeasure is, therefore, required to be incorporated to protect a biometric system from attacks. Examples of security measures include liveness detection which can detect fake biometric samples. Liveness detection is a challenging area and requires an in-depth understanding of the subtle differences between genuine and fake attempts, and the exploitation of that information to prevent such impostor attacks1. This thesis suggests a challenge/response gaze-based novel features scheme which can overcome sophisticated impostor attacks in face recognition systems. Unlike ex-isting work described in the literature, this study does not focus on a particular type of attack but aims to deal with a collection of attack modes (photo, photo mask and video).
In this thesis terms such as impostor attack, presentation attack, fake attempt, spoofing attack are used interchangeably. In the context of liveness detection
1Any person who, intentionally or otherwise poses as an authorised user is named an im-postor [18]
Chapter 1. Introduction 2
these terms are used when artifacts are presented to the biometric system at sensor level to subvert its normal operation.
In the rest of this chapter the motivation for this research is further expanded upon. Section 1.1 will present a brief introduction to biometrics systems along with potential vulnerability related to biometric systems. Section1.2will present the motivation of this research along with system block diagram. Aims and objectives are listed in Section 1.3. A scope for the work will be explored in Section1.4. Finally Section 1.5 will present the structure of the thesis.
1.1
Biometric systems
Security systems which require high accuracy are becoming more important than ever in our technologically dependent world. In the modern interconnected so-ciety we live in, to be able to reliably recognise a person at the remote end of a computer network is becoming critical. Many questions can be raised, for exam-ple,“Is she/he really who she/he claims to be?” or “Is this person at the other end of the network authorized to use this facility?”, and so on.
The search for techniques that can improve the performance of an automatic person recognition system is very important [19]. Traditionally a person is auto-matically recognised based on “what s/he remembers”, for example, passwords, PIN, etc. Similarly such recognition can also be based on tokens possessed by someone such as ID cards and keys, etc. All these methods have been used to control access to premises or systems, etc. [20]. However, if the ID card is stolen or a password is known to an unauthorised user, security can be breached, espe-cially if the system is unattended. Recognition based on what a person is or does can address the problems related to these traditional methods [21]. Technologies
for person recognition based on their physiological or behavioural characteristics is known as biometrics [22].
The biometrics-based systems can have their functioning based on various parts of the human body or human behaviour. For example, voice [23–27]; signature [28–31]; gaze [32–36]; gait [37–40] etc. are usually classified as behavioural bio-metrics and iris [41–45]; hand geometry [46–50]; fingerprint [51–55]; face [56–61]; etc. are examples of physiological biometric, all of which are used in the real world for security.
However all modalities typically aim to fulfil the following criteria [22]:
• Universality: It is present in every person.
• Uniqueness: Two persons should be sufficiently different in terms of the characteristic.
• Permanence: It must not change with time.
• Measurability: It has to be possible to measure it.
Biometrics-based methods have several advantages over the traditional security methods, such as PIN codes, passwords, keys, cards, IDs, tokens, etc. For exam-ple, the old classical security methods require the user to remember PIN codes or long passwords that could easily be forgotten, or to carry cumbersome bunches of keys, tokens or cards that can be easily lost or stolen [62–65]. Biometrics, however, guarantees that the user who accesses certain facilities cannot deny us-ing it (non-repudiation) [24] and does not require the possession of any physical tokens, nor rely on uncertainty of the human memory. Biometric information has been widely used with a satisfactory performance in criminal investigation, access control, etc. [66].
Chapter 1. Introduction 4
Despite these advantages, biometric systems do have some disadvantages, and can be vulnerable to external attacks which can compromise security [65]. Ratha et al. [67] highlighted several possible attack points to biometric recognition systems as depicted in Figure1.1. These can be grouped into two main categories: direct attacks also called presentation attacks, where the impostor attacks the biometric system at the sensor by presenting synthetic biometric samples, e.g. gummy fingers [68]. Matsumoto et al. [68] showed how easily gummy fingers can be made with a common material like gelatine which can be used to spoof various fingerprint devices with optical or capacitive sensors. Ruiz-Albacete at el. [69] reported the vulnerabilities of iris-based recognition systems. They printed high quality photo of the iris to present to the iris recognition system.
Figure 1.1 Possible points where biometrics system can be attacked. (The focus of the thesis is shown by the red arrow
-presentation attacks)
The remaining points of attack shown in Figure1.1 can be considered indirect attacks. This study only deals with presentation attacks. This is a type of attack where the the impostor does not need any prior knowledge about the underlying working principles of the system.
1.2
Motivation
Humans most commonly use facial appearance to recognise a person, therefore, it is the natural choice as a modality in biometric technology [70, 71]. As the face is normally visible, it is easy to capture the facial image of a person with or without the cooperation of the individual [72]. A considerable amount of work has been reported in the literature on this modality [56–59]. Among all the biometric systems, face recognition is especially convenient in areas where immediate, correct recognition of individuals at unattended access control points, such as entrances to buildings, or security at border crossings, security in the street, and where being able to uniquely recognize individual humans without user cooperation is a vital aspect of achieving effective security.
Many companies have already implemented face recognition systems. These may be accurate and fast, but they can also be susceptible to various threats such as presentation attacks. Most facial recognition systems process facial im-ages for identification without checking whether the sample is captured from the authorised user or from a photo or video of the authorised user. Therefore, an impostor can use a high quality image or a video of authorised users in order to gain unauthorized access to premises, systems or data. A reliable facial recog-nition system should, therefore, prevent impostors from gaining unauthorized access to unattended places or data. Hence the suggestion that existing facial recognition systems require an effective liveness detection function in order to avert impostor attacks [73, 74].
The algorithms proposed in this study are based on the assumption that the spatial and temporal coordination of the movements of eye, head and hand in-volved in the task of following a visual stimulus are significantly different when a genuine attempt is made compared with certain types of spoof attempts. The
Chapter 1. Introduction 6
task requires head/eye fixations on a simple shape that appears on a screen in front of the user, and in the case of a photo spoofing attack, visually guided hand movements are also required to orientate the photographic artifact to point in the correct direction towards the challenge item on the screen.
It is likely that the head pose and direction of gaze will be different when photo spoofing is attempted as coordination may be maintained by delaying the hand movements until the eye is available for guiding the movement [75]. The introduction of hand movements is also likely to change the relationship between head and eye movements, as the coordination of the eye and head in gaze changes is usually a consequence of synergistic linkage rather than an obligatory one [75–
77]. Therefore, it is assumed that accurately directing the photograph to a particular orientation indicated by the visual stimulus on the screen is likely to be less repeatable than merely looking at the stimulus. Hence, the variance in measured gaze parameters is used to distinguish genuine from fake attempts as described in the rest of the research. So the features which will be investigated in this research will be based on the gaze of the human. By gaze we mean head/eye movements.
Many algorithms have been proposed in the literature [78–80] to address the difficult problem of face liveness detection. A variety of techniques have been proposed for liveness detection including detecting eye blinks, sensing response to stimuli, and detection of facial gestures. Various approaches and constraints are used to enhance the reliability of these systems. However, finding good novel features which can detect all types of attack scenarios is a challenging task.
The general architecture of the face liveness detection system that will be fol-lowed in this thesis is shown in Figure 1.2. Novel features from facial landmarks will be extracted from the images which are then analysed to determine whether the captured images are acquired from a genuine source or not.
Figure 1.2 System structure flow diagram
Most smart phones have built-in cameras and have the option to use face recog-nition for logging into the phone [81] instead of using a password. The proposed liveness detection system can be added to such devices to enhance the security of the existing face recognition system.
People normally use a password to log into a PC, laptop or note book. This can be replaced by face recognition together with a liveness detection mechanism to avoid entering a user name and password each time a system is used. In fact this can be used to lock the system automatically as well if the authorised user is not sitting in front of the PC. This will not only make it easier for the user, but it will also enhance the system security as one can steal a client’s password.
There is another, perhaps more important aspect to the face liveness detection method that can be implemented e.g. when the user is making an online trans-action or withdrawing money from an ATM machine. The proposed system can be embedded to the existing process of the online payment procedure, where the system will ensure that the live face of the authorised user is available at the time of completing the transaction to avoid unauthorised payment transaction and unauthorised withdrawal using a card cloned from the card belonging to the authorised user.
There are many potential applications of the proposed system and here we have highlighted only a few important ones which demonstrate the potential impact
Chapter 1. Introduction 8
of the proposed approach.
Note that the proposed liveness detection approach may be combined with other biometric modalities too - notably iris recognition.
1.3
Aims and Objectives
The general aim of this research is to develop robust and efficient liveness detec-tion algorithms to enhance the trust in and the security of biometric recognidetec-tion systems. This work will explore the effectiveness of such systems to counteract impostor attacks for a number of attack scenario schemes. The specific ob-jectives of the research are to review the state of the art of biometric liveness detection methods and to propose a liveness detection framework that can deal with a multitude of presentation attack types. This study will also aim to collect the appropriate biometric databases and propose an evaluation framework to facilitate investigative analysis of presentation attacks. The research objectives include the exploration of gaze-based features to achieve liveness detection. This work will also explore the use of fusion techniques to improve the efficiency of the scheme and to optimise the proposed algorithms and carry out comparative analysis.
1.4
Scope of the Project
The list of the work which will be carried in this study is summarized below an explains the areas which will be covered in this research. The areas which will not be covered in this research are also listed. This study will only explore facial liveness detection methods. The research will deal with three types of
presentation attacks, e.g photo, mask and video replay. In this study 2-D photo mask attack detection will be explored. This work will not explore 3-D mask attack detection. One would need several photos of the target and a 3-D printer to produce the 3-D mask which may not be available promptly. The research will investigate features based on gaze stability. Though liveness detection techniques are normally used in conjunction with biometric person recognition systems, this research does not address novel techniques for biometric recognition in general and face recognition systems in particular. However, the interaction between biometric systems and the liveness detection function is of relevance to the work presented here.
1.5
Structure of the Thesis
The organization of the thesis is given below.
In Chapter 2, the background of various key concepts for understanding the related previous work on face liveness detection is presented. A detailed com-parative study is presented that focusses on various liveness detection methods that have been proposed in recent years. The related previous work is grouped into two main categories. This is further divided into several groups based on the type of feature used for liveness detection.
Chapter 3 provides the detail of the database that was collected for training and testing purposes. It also provides further details on the evaluation strategy used for this work as well as the hardware and software used to conduct the experiments.
Chapter 4 introduces the gaze colocation feature. The use of ROC curves to analyze and assess the performance is proposed and demonstrated.
Chapter 1. Introduction 10
Another novel feature, the gaze collinearity, is presented in Chapter 5 and is aimed at improving the performance of the proposed face liveness detection sys-tem. This chapter also explores combining collinearity and colocation to produce more effective measures for liveness detection.
Chapter 6 presents another novel gazed-based homography feature, to further enhance the accuracy of the proposed face liveness detection system. This chapter also explores combining collinearity, colocation and homography to produce more effective measures for liveness detection.
Conclusions, a summary of the contributions of this work and suggestions for future work are provided in Chapter 7.
The goal of this thesis has been to perform an extensive experimental study of various novel features, classification and combination rules applied to the problem of face liveness detection for biometric systems.
Literature Review
2.1
Introduction
The biometric technology involving face recognition has developed rapidly in re-cent years as it is user friendly and convenient, and is used for many security purposes, but is vulnerable to abuse, such as spoofing photographic or video substitution and many others as discussed in Chapter 1. However, by adding liveness detection the effectiveness of security systems can be substantially im-proved. The differences between a photograph or video of an individual and the real person can be used to establish liveness.
Various approaches have been presented in the literature to establish liveness for detecting presentation attacks. Liveness detection approaches can be grouped into two broad categories: active and passive. Active approaches require user engagement to enable the facial recognition system to establish the liveness of the source through the sample captured at the sensor. Passive approaches do not require user co-operation or even user awareness but exploit involuntary physical movements, such as spontaneous eye blinks, and 3D properties of the image.
Chapter 2. Literature Review 12
Challenge response is a type of intrusive approach, the user is asked to perform specific activities to ascertain the liveness. Uttering digits, changing head pose are the examples of the challenge response. Passive anti-spoofing techniques are usually based on the detection of signs of life, e.g. eye blink, facial expression, etc. Here the face liveness detection methods are grouped based on the feature and the methods that were used to estimate the liveness.
2.2
Literature
Several approaches which are implemented to solve the the problem of face live-ness detection for the face recognition system. In this section, these approaches are grouped and explored based on the nature of the feature. Following methods are proposed in literature for liveness detection.
2.2.1
Eyeblink Based Liveness detection
Blinking is a natural biological function of the closing and opening of the eyelid. The blink helps spread fluid from the tear ducts across the eye and removes irri-tants from the surface of the cornea and conjunctiva [82]. Blinking can vary with fatigue, emotional stress, amount of sleep, eye injury, medication, and disease [83]. It has been reported [84, 85] that the blink rate of a human is between 15 to 30 times per minute. The average blink lasts for about 250 milliseconds [86].
Blinking has been used as a means of human interaction with computer [87,89]. Various researchers have used blink detection for face liveness detection.
One method to detect blinks, is to classify each image in the video sequence independently as one state (closed eye or opened eye), for example, using the
Viola-Jones cascaded Adaboost approach to detect the face and eye [90]. Ad-aBoost is a learning algorithm that selects a small set of weak classifiers from the large number of potential features. This method assumes that all of the im-ages in the temporal sequence are independent. In real, the neighbouring imim-ages during blinking are dependent, since the blink is a procedure of eye going from open to closed, and back to open. The temporal information, which may be very helpful for recognition, is ignored in this method. Lin Sun et al. [1] presented an eye blink detection approach for detecting face liveness using Conditional Ran-dom Fields (CRFs). Using Hidden Markov Model (HMM) [91] which can not accommodate long-range dependencies on the observation, they used conditional random fields(CRFs) which are probabilistic models for segmenting and labeling sequence data and mainly used in natural language processing for its ability to accommodate long-range dependencies on the observed sequence [92–94]. Lin Sun et al. employed a linear chain of CRFs in their method [1].
Lin Sun et al. [1] demonstrated that the blinking consisted of two continuous sub-actions, from open to closed and from closed to open. These (open to closed and from closed to open) activities could be sampled into an image sequence with eye in various states. The state of the eye in images are classified as open, half open and closed. Each state of the blink should not be considered independently for blinking recognition. They stressed the need to model blinking on the con-textual dependencies in an eye blinking sequence. At particular points of time, it is hard to predict blinking activity using the previous state and the current observation.
Lin Sun et al. [1] used symbols C for closed state and N C for non-closed (including open and half-open), to label eye states. The graphical structure of their CRF-based blinking model is shown in Figure2.1.
Chapter 2. Literature Review 14
Figure 2.1 Graphic structure of CRF-based blinking model. C and NC are for closed state and non-closed state respectively [1]
They collected video database from genuine users using a webcam. There were 20 participants and 4 video clips were recorded of each creating 80 video clips of about 5 seconds length. The number of blinking varies from 1 to 6 times in each video. They also collected impostor database which contain 180 impostor video capture using photo. The authors reported 98.3% imposter detection rate.
Pan et al. in [2] further enhanced the Lin Sun et al. work [1]. The main eye states modeled are opening and closing. In addition, there is an ambiguous state when blinking from open state to closed or from closed state to open. In this method they extract the temporal information from the process of the eye blink, namely the consecutive stages of open, half closed and closed, followed by half open and fully open all of which are sequential eye blink movements and constitute a complete eye blink pattern which was used to determine liveness.
In this work the authors defined a three-state set for eyes,α : open,γ : closed, β: ambiguous and a typical blink activity was described as a state change pattern
Figure 2.2 Illustration of the blinking activity sequence. The value of the closeness for each frame is below the corresponding frame. The bigger the value, higher the degree of closeness [2]
of α→β →γ →β→α. They used the same database which is discussed in [2] for evaluating the performance of their method. They compared three methods, cascaded Adaboost, HMM and and their method against photo spoofing using the photo-imposter video database.
Pan et al. [3] further explored the method to enhance their face liveness de-tection system discussed [1] and [2]. In this work they fused eyeblink and scene context. The authors assumed that the face recognition system camera is fixed while the system is operating. The first frame was captured from the scene with-out a person in front of the camera. This frame was designated as the reference scene; an impostor video would be of a different scene.
They extracted reference points or activity in the captured frame and named them clues. Clues extracted from the face region were named inside clue, example of a face clue is eye blinks. Similarly clues extracted from the background of the captured image near a face were named outside clues (scene context clue). These
Chapter 2. Literature Review 16
Figure 2.3 Examples of scene region of interest and fiducial points extraction. Yellow dashed line rectangles are face re-gions and red solid line rectangles are scene rere-gions of interest.
Fiducial points are labeled by colorful squares [3]
can be any item located in the background which can be captured and extracted for recognition.
They extract scene context clues from the right and the left parts of the detected face region as shown in Figure 2.3. The eye blink may stop the photographs and 3D models spoofing, while the scene context is used for anti-spoofing by video replay. They combined these clues of eyeblinks and scene context to improve the performance of the liveness detection system. The proposed fusion system is shown in Figure 2.4.
For training and testing purposes, they collected their own data. The database consist of 100 video clips from 20 volunteers. A high-quality photo was taken from each volunteer. The five categories of photo attacks below were simulated.
Figure 2.4 Illustration of liveness detection system using a com-bination of eyeblinks and scene context [3]
• Move the photo vertically, horizontally, back and front.
• Rotate the photo in depth along the vertical axis.
• Rotate the photo in plane.
• Bend the photo inward and outward along the central line.
For each attack, one video clip is captured with a length of about 10 to 15 seconds. Some samples are shown in Figure 2.5.
The live face video database contains 196 clips for 14 individuals. There were 2 indoor and 5 outdoor scenes. Each scene has a scene reference image. Each individual appears before the camera twice and stays there about 5 seconds for liveness verification. Examples of the data are shown in Figure2.6.
Jee et al. [4] introduced a memory efficient method for face liveness detection for embedded face recognition system. The method is based on the analysis of
Chapter 2. Literature Review 18
Figure 2.5 (a) Keep photo still. (b) Move vertically, horizon-tally, backward and forward. (c) Rotate in depth. (d) Rotate
in plane. (e) Bend inward and outward [3]
Figure 2.6 The first row is four scene reference images. The second row is live faces in video [3]
the eye movement. They used Viloa-Jones [90] methods to detected the eye in the facial images.
They normalized the input face images as they can vary in size and orientation. After normalizing the face region, the eye regions were extracted. Then the eye regions were binarized in order to achieve the pixel value of 0 and 1 by using a threshold. The threshold is adaptively obtained from the mean pixel value of each eye region. Figure2.7 shows the eye regions of genuine and fake face which change very little in case of fake attempt, and a much larger variation in shape in case of the genuine attempt because of the blink or the movement of the pupil.
Figure 2.7 Example of binarized eye regions of (a) fake face and (b) live face [4]
The authors used the hamming distance method to calculate the liveness de-tection score for the eye region. They extracted 10 liveness scores of both the left and right eyes and added them, and used the average of the scores. If the average liveness score was bigger than the set threshold, the input image is classified as a genuine face.
Chapter 2. Literature Review 20
Wang et al. [5] presented a liveness detection method in which the physiolog-ical motion was detected by estimating the eye blink and using an eye contour extraction algorithm. They used an active shape model [95] with a random forest classifier trained to recognize the local appearance around each landmark. They showed that if any motion in the face region is detected the sample is considered to be captured from an imposter.
The proposed method is composed of two parts; the attempt passed through both parts of the approach for the liveness check. The first part detects the physiological motion in three modules for eye detection, eye contour extraction, and eye blinking detection. The second part extracts the motion cues and seeks to hold the head still. If any motion in the face region was detected, the attempt was classified as fake. The flow chart of the system is shown in Figure 2.8
The eye blink estimation detects the eye blinks in the face sequences. The authors related the blinking to the degree of the eye opening estimated from the distancesd1 and d2 in Figure2.9. whered1is the distance between the upper and
lower eyelids of the left eye and d2 is the distance between the upper and lower
eyelids of the right eye. Where as de is the distance between the center of the
left and right eyes. The eye opening is then calculated as in Equation 2.1
D= min(d1, d2) de
(2.1)
When the opening degree is deduced from larger to small, an eye blink is de-tected.
Figure 2.8 Algorithm flowchart
Figure 2.9 Eye opening estimation [5]
2.2.2
Face Liveness Detection using Frequency and
Tex-ture Analysis
Kim et al. [6] proposed a face liveness detection method for distinguishing 2-D paper masks from the genuine faces. They used a multi-classifier method
Chapter 2. Literature Review 22
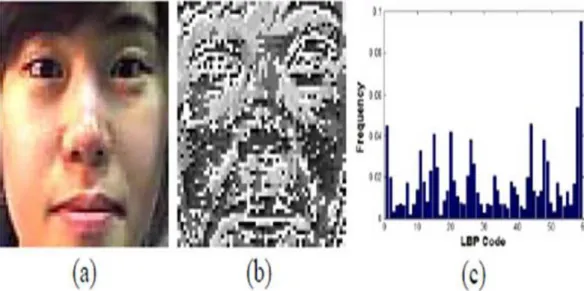
for detecting fake attempts by combining frequency information from the power spectrum and texture information using Local Binary Pattern (LBP) features.
3-D shapes lead to the difference in the low frequency regions which is closely related to the illuminance component induced by the overall shape of a face. The detail between the live attempts and the mask attempts trigger the disparity in the high frequency information [96] [9]. The images taken from the 2-D objects have less texture richness compared to the images taken from the 3-D objects. The texture information obtained using Local Binary Pattern (LBP) features.
Figure 2.10 Frequency-based feature extraction (a) original fa-cial image (b) Log-scale magnitude of the Fourier-transformed image (power spectrum) (c) 1-D frequency feature vector
ex-tracted from the normalized power spectrum [6]
Frequency information from the facial images were extracted and were trans-formed to the frequency domain using the 2-D discrete Fourier transform. The face image is shown in Figure2.10(a), Figure2.10(b) shows the Fourier-transformed image and Figure 2.10(c) shows the resulting frequency feature. Local Binary Patterns (LBP) [7] is one of the most popular methods to describe the texture information of the images. The authors used LBP to analyze the texture charac-teristics of the image taken from genuine and fake attempt. Figure 2.11 explain
the process of acquiring the LBP feature vector from a given facial image. Fig-ure2.11(a) is the original facial image while Figure2.11(b) shows the LBP-coded image of Figure 2.11(a). Figure 2.11(c) shown histogram of the LPB-coded im-age, which will be exploited as the feature vector for the classification.
Figure 2.11 Feature vector extraction process based on LBP (a) original facial image (b) LBP-coded image (c) histogram of the
LBP-coded image [7]
They extracted frequency-based feature, texture-based feature and implemented own their own and fused them together. They used Support Vector Machine (SVM) classifiers using the two types of feature vectors extracted. The decision values of these two SVM classifiers were then used as 2-D feature vectors for the subsequent fusion.
Komulainen et al. [97] explored the use of dynamic texture information for spoofing detection. They argued that masks and 3D head models are rigid, whereas genuine faces are non-rigid with contractions of facial muscles resulting in temporal deformation of facial features, such as moving eyelids, lips, etc. The structure and dynamics of the micro-textures that characterise real faces were used in their proposed approach to spoof detection. They used spatiotemporal (dynamic texture) extensions of the local binary pattern in this approach.
Chapter 2. Literature Review 24
The authors considered local binary patterns from three orthogonal planes (LBP-TOP) which have been shown to be very effective in describing the hor-izontal and vertical motion patterns in addition to appearance. The original LBP operator was defined to only deal with the spatial information. It has been extended to a spatiotemporal representation for dynamic texture analysis (DT). This has resulted in the so called Volume Local Binary Pattern operator (VLBP) [98]. The idea behind VLBP consists of looking at dynamic texture as a set of volumes in the (X,Y,T) space where X and Y denote the spatial coordinates and T denotes the frame index (time). The neighbourhood of each pixel is thus defined in a three dimensional space. Then, similarly to basic LBP in spatial do-main, volume textons can be defined and extracted into Face Spoofing Detection Using Dynamic Texture 149 histograms. Therefore, VLBP combines motion and appearance into a dynamic texture description.
They carried out experiments on the CASIA Face Anti-Spoofing Database [99] and Print-Attack Database [100]. The CASIA data set contains 50 real clients and the corresponding fake faces are captured with high quality from the original ones. Three imaging qualities, low, normal and high were then extracted. They used SVM classifier for training and testing the method.
Komulainen et al. [8] explored fusion of motion and texture based countermea-sures under several types of face attacks. They explored the fusion potential of different visual cues and show that the performance of the individual methods can be vastly improved by performing fusion at score level.
Figure2.12 is the diagram of the authors’ proposed fusion strategy. The video sequences were divided into overlapping windows of frames. Each observation generate scores from motion and micro-texture are combined to achieve a single score using score based fusion using linear logistic regression (LLR). They carried out experiments on the Replay Attack database [101]. The database was divided
Figure 2.12 Block diagram of the used fusion strategy [8]
into three sets for training, development and testing to evaluate the method. Jiangwei Li et al. [9] explored a technique based on the analysis of 2-D Fourier spectra of the face image. They proposed that the size of a photograph is smaller than the real image and the photograph is flat, it therefore has fewer high fre-quency components than real face images. They further explored that if a photo is held before a camera and is in motion, since the expressions and poses of the face contained in the photo are invariant, the standard deviation of frequency components in the sequence must be very small. This can only be valid for low resolution photographs but it is possible print bigger and high resolution pho-tographs in which the high frequency components will be closer to those of a real image.
The most common presentation attack are printed photo, video replay on lcd screen. The media of these sources are 2-D planar structure, whereas genuine face is 3-D structures. The intensity contrast of a genuine facial image is more obvious than that of a fake image and such differences lead to greatly different reflectivity of light, which is shown in the frequency distribution of an image. Figure2.13, shows the comparison of the Fourier spectra of a genuine face image
Chapter 2. Literature Review 26
to that of a fake face image. (a) genuine face image; (b) A fake face image; (c) 2D Fourier spectra of (a); (d) 2D Fourier spectra of (b).
Figure 2.13 Difference between live face and fake face in fre-quency domain [9]
Bharadwaj et al. [102] explored the utility of Local Binary Patterns (LBP) based features along with motion magnification. The authors explored two types of feature extraction algorithms. They presented a configuration of LBP that provided better performance compared to other computationally expensive tex-ture based approaches. Motion featex-ture estimation is also explored.
The authors localized required motion and then magnified it under the Taylor expansion assumption. The approach enhances facial movements including subtle motion such as blinking, saccadic and conjugate eye motion that may otherwise only be visible on close inspection of the video.
Motion magnified video of a subject can be classified for spoofing detection using either texture or motion based features. As mentioned, texture features are widely explored in spoofing detection literature as compared to motion based
features. They proposed the texture and motion based features for spoofing detection.
Bharadwaj et al. [102] exploited various texture based spoofing detection ap-proaches [101, 103–107] to explored the utility of LBP based features along with motion magnification for liveness detection system. To encode texture informa-tion at multiple scales, they proposed to use feature concatenainforma-tion of the three LBP configurations.
Wu et al. [10] suggest a liveness detection scheme, combining Fourier statistics and local binary patterns. Both techniques, Fourier spectra and local binary patterns, have been investigated on their own and the authors fuse them together in order to improve the liveness detection performance. Figure 2.14 shows the their proposed system where the score from features of local binary patterns and Fourier spectra are combined using support vector machine.
They carried out experiments on the NUAA [96] database which consists of genuine and photo of impostor. Their method classified genuine and fake with 100% and 92.33% respectively.
Das et al. [108] proposed method based frequency analysis and texture anal-ysis by using frequency descriptor and Local Binary Pattern respectively. They exploited frequency and texture based analysis to differentiate between images captured from genuine and fake attempts. Images captured from fake attempts have low frequency regions and less texture richness. However, genuine sam-ples have high frequency information and high texture richness. They also used NUAA database for training and testing purposes.
Chapter 2. Literature Review 28
Figure 2.14 The framework of the proposed approach for live-ness detection by Wu [10]
2.2.3
Challenge Response Mechanisms
Systems based on the challenge-response approach belong to the active category, where the user is asked to perform specific activities to ascertain liveness such as uttering digits or changing his or her head pose. For instance Frischholz et al. [11] investigated a challenge-response approach to enhance the security of the face recognition system. They developed a head pose estimation technique using a single camera. The users were required to look in certain directions, which were chosen by the system randomly. The system estimated the head pose and
compared the real time movement (response) to the instructions asked by the system (challenge) to verify the user authenticity. After responding to several of these challenges, the user is asked to look straight into the camera and the final image is captured for face recognition.
Figure 2.15 Random challenge directions [11]
Kollreider et al. [12] explored the liveness detection approach where users are required to interact with the face liveness detection system. This interaction oc-curred through the utterance of a specific digit sequence, either known previously by the person or prompted randomly. The authors favored the latter scheme, since a sound utterance can be recorded easily. They explored the changes in facial expressions during the utterances.
In this technique they located the mouth regions and process every frame and extract OFL in real time. They have used the XM2VTS database for evaluation. Volunteers’ videos were recorded pronouncing digits (from 0 to 9). The aim was to recognize the digits of the volunteer through lip-motion only. For a digit, they have used 100 short videos. For training, there were a total of 60 videos and
Chapter 2. Literature Review 30
for testing, a total of 40 videos. For each of the digit videos, feature vectors are extracted from mouth regions and given to SVM classifier for purpose of classification. Out of 100 individuals, recognition rate is 0.73 (73%).
Figure 2.16 Dimension reduction of the extracted velocities in the mouth region [12]
Eveno et al. [109] proposed a liveness detection method by measuring the correlation between the movement of the lips and the speech produced. Linear predictive coding (LPC) was used to parameterize the speech signal. The LPC filters parameters are extracted at the video frame rate of 25fps. The video parameters are derived from the outer contour of the lips. The algorithm requires the manual selection of a single point above the mouth in the first frame and then the remaining segmentation is automatically achieved by fitting a deformable template. Five audio parameters and three video parameters are associated with each video frame. Canonical correlation analysis is the statistical method used to measure the relationship between two sets of the multi dimensional data. This method was used to find the linear combination of the audio and video variable
correlation. They also considered another method called Coinertia Analysis, a statistic tool used to solve problems in ecology.
Bredin et al. [110] explored the synchronisation between the motion of the lips and the sound of the speech of the talking face. Talking faces contain more information which is available for verification, and not only contain the voice signal and video signal but the most important dynamic detail which is the correlation of the movement of the lips and the sound produced by the speech. They cross fused the audio and video signals to estimate the correlation between them.
Kant et al. [111] proposed a technique in which the user was asked to perform some activities to check liveness of the attempt. They were asked to act like chew-ing, smile or forehead movement. The camera captured sequences of images at certain frame rate while the users were responding to the request. They extracted the feature from the facial using correlation coefficient and image extension fea-ture. Using some discriminant analysis method, images are discriminated and skin elasticity is calculated. The output is compared with the stored database to discriminant between fake and genuine attempts.
Saad [13] explored challenge response mechanism to avert spoofing attempt. They located face in the captured images and calculated the center of the face in the images as a reference point to track it once the challenge begins. The users were asked randomly to look toward right, left, up and down features were then estimated. Figure2.17 shows the head movement in all four direction. The collected data of 21 users providing both still and interactive attempts. The videos were replayed using phone and tablet for spoofing attempts.
Singh et al. [112] suggested a liveness detection method where random challenge was generated to the user. The user’s response was observed. The users were
Chapter 2. Literature Review 32
Figure 2.17 Head motion actions examples [13]
ask to open and close the mouth or eyes.
2.2.4
3D face
Some authors use methods based on the 3D structure of the face for face live-ness detection. Andrea Lagorio et al. [14] proposed a novel liveness detection method, shown in Figure2.18, based on the 3D structure of the face. The method computed the 3D features of the captured facial image data to detect whether a human face has been presented to the acquisition camera. They collected a 3D fa-cial database using a stereo camera system (VERTRA3D CRT) for performance evaluation.
Wang et al. [15] explored novel liveness detection approach to counter spoofing attacks by recovering sparse 3D facial structure using a single camera. They detected facial landmarks and selected key frames from a face video or several
Figure 2.18 Proposed anti spoofing system [14]
images which are captured from several viewpoints. The sparse 3D facial struc-ture is recovered from the selected key frames and from the selected key frames, the sparse 3D facial structures are recovered. The SVM classifier was used to test the efficiency of the proposed method in classifying genuine and fake attempts. For experiments, the authors had collected three databases using different qual-ity cameras to inspect the anti-spoofing performance across different devices. The proposed approach achieves 100% for both classification results and face liveness detection accuracy. Genuine and Fake attempt examples are shown in Figure2.19.
2.2.5
Face Liveness Assessment Using Motion Analysis
Kollreider et al. [113] combine face parts (nose, ears) detection and optical flow estimation to determine a liveness score. They assumed that a 3D face produces a 2D motion which is higher at central face parts (e.g. nose) compared to the outer face regions (e.g. ears). The parts nearest to the camera move differently to parts
Chapter 2. Literature Review 34
Figure 2.19 The Genuine and Fake attempt example [15]
which are further away in a live face. On the other hand, a translated photograph generates constant motion at various face regions. For the face part detection they employ a model-based Gabor decomposition and SVM. They locate the position of the face parts and compare their speed relative to each other. They also compare the direction of the motion of the same face part. This enables them to distinguish a live face from a photograph.
Continuing the work Kollreider et al. [114] exploited lightweight optical flow for face motion estimation using structure tensor and input frames. The authors presented a technique for computing and implementing the optical flow of lines (OFL). Here they again used the model-based local Gabor decomposition which are linear filters for edge detection and SVM.
The authors introduced two approaches for the face parts detection. First one was based on optical flow pattern matching and model-based Gabor feature clas-sification. The second one extracted Gabor features in a non-uniform retinotopic grid and classifies them with trained SVM experts. The database which was
used contained 100 videos of Head Rotation Shot-subset (DVD002 media) of the XM2VTS database. Data was downsized to 300x240 pixels. Videos were cut (3 to 5 frames) and were used for live and non-live sequences. Each user’s last frame was taken and was translated horizontally and vertically to get two non-live sequences per person.
Therefore, 200 live and 200 non live sequences were examined. Most of the live sequences achieved a score of 0.75 out of 1, whereas the non-live pictures achieved a score less than 0.5. It was also noticed that glasses and moustaches lowered the score, as they were close to the camera. The authors mentioned that the system will be error free if sequences containing only horizontal movements are used. By considering a liveness score greater than 0.5 as alive, the proposed system separates 400 test sequences with error rate of 0.75%.
Bao et al. [16] presented a method based on optical flow field. The difference of the optical flow filed generated through the movement of the two dimensional plane and three dimensional object was exploited for face liveness detection. The relative motion between the two dimensional plane and camera are four types named translation, rotation, moving forward or backward and swing. All other movements are combinations of these four basic types. The authors described four types of motion that can generate different optical flow field as shown in Figure2.20. Any planar object’s optical flow field can be represented as a linear combination of these four basic types with regularity.
During the investigation the authors found that translation, rotation and mov-ing generated almost similar optical flow fields for both two and three dimen-sional objects whilst swing generated optical flow field that have much difference between two and three dimensional object. Their approach was based on the idea that the optical flow field for 2D objects can be represented as a projection transformation. The optical flow allowed them to deduce the reference field,thus
Chapter 2. Literature Review 36
Figure 2.20 Optical flow fields generated by four basic types of relative motions (a) Translation (b) Rotation (c) Moving
for-ward or backfor-ward (d) Swing [16]
allowed them to determine whether the test region is planar or not. For that, the difference among optical flow fields was calculated. To decide whether a face is a real face or not, this difference was noted as a threshold. The authors carried out experiments on three types of data. The first set contained 100 printed facial photo that were translated and rotated in front of the camera randomly. The second set of data contains 100 facial photos which were folded and curled before the photos were presented to the camera. The third set of data consisted of faces of real people doing random gestures like swinging, shaking, etc. Ten people participated the experiment in turn, with a total of 10 turns.
Tronci et al. [115] explored the information extracted from motion and clues from still images and video. They captured spatial information of the still images using different visual features as color. Video-based analysis was performed as a combination of information of motion such as blink, mouth movement and facial expression change among others.
Pinto et al. [116] proposed technique for video spoofing attempts. They ex-plored that the addition of noise pattern in the sample is inevitable in acquisition
Figure 2.21 Examples of the optical flow fields with (a) Group 1 (b) Group 2 (c)Group 3 [16]
process. Fixed pattern noise and noise resulting from the sensor due non-uniform light-sensitive can be present in photo [117]. Noise pattern has been widely ex-plored in digital document forensics [117,118]. The exploited the noise signatures generated by the recaptured video to distinguish between genuine and fake. They used Fourier spectrum and then compute the video visual rhythms [119].
2.2.6
Miscellaneous Technologies
Chetty et al. [120] explored fusion of super resolved texture (SRT) features and 3D shape features with acoustic features for liveness checks. The proposed SRT features allowed information related to non-rigid variations on speaking faces, such as expression lines, gestures, and wrinkles, enhancing the performance of the system against impostor and spoof attacks. They transform each image into a new parametric vector space characterised by edge image and create a database of the source edges. The low resolution data of the target edge is replaced with
Chapter 2. Literature Review 38
high resolution from the database. The super resolution (their proposed method) is divided into two stages absorption and synthesis. In the absorption phase, the source and target image frames are transformed and added to the edge database while in the synthesis phase the single target image frame is reconstructed at a higher resolution.
Figure 2.22 Stages of SuperRes algorithm
Synthesis: In this stage they key generation and hierarchical decomposition. Key generation is to construct keys of for each edge. These keys were then entered into the database and searched. Then, a hierarchical decomposition model was used for mapping edges to keys with the start by creating a single key for an entire edge, then recursively splitting the edge into two segments. Figure2.22 illustrate this scheme.
Bai et al. [121] explored a physics-based method, the key idea of their approach is that when an image is displayed on paper or screen and captured the image again, the recapture image is an image of the medium (paper or screen) only.
However, because the medium has a target image, the new image appears to be the target image itself.
Chetty et al. [122] present the multi-level liveness verification (MLLV) frame-work for realizing the face-voice authentication system to avert audio and video replay attacks. The MLLV framework is based on feature extraction and mul-tilevel fusion. The fusion approaches are bimodal feature fusion, cross model fusion and 3D multimodal fusion. The bimodal fusion level the system detects the still photo and pre-recorded audio but can be cheated with video replay. At the level of cross-modal fusion the system averts video replay attacks but it can be cheated with 3D synthetic talking head. The 3D multimodal fusion performs liveness check based on modelling the speaker in 3D space with the 3D shape and texture features.
Chan et al. [17] presented a method where the images of the user with and without flashlight and estimate the brightness of the face region and background and compared with each other. They believed that the genuine and fake should have different brightness difference. Figure2.23example of genuine and impostor video replay attack with and without flashlight. They collected data from 21 subjects.
Peng et al. [123] proposed a method based on high frequency descriptor. In-stead of simply calculating the high frequency descriptor and comparing it with the set threshold, they calculated a high frequency descriptor for two images. One image was taken as normal and the other one taken with additional illumination provided by flashlight.
Kim [124] suggested a method for liveness detection using variable focusing. They captured two images sequentially taken at different focus. They discovered that in real faces, focused regions are clear and other regions are blurred due
Chapter 2. Literature Review 40
Figure 2.23 Examples of genuine and video replay with and without flashlight. (a) Genuine user without flashlight (b) Gen-uine user under flashlight (c) Video replay without flashlight (d)
Video replay under flashlight [17]
to depth information. They also found that this did not happened in images taken from a printed photo. The extracted information based on the variation of the sum modified Laplacian [125] that represents the degrees of focusing. This information was used to discriminate between the genuine and impostor attack.
Yang [126] revised the method suggested in [124]. In this method the author proposed by investigating the focus distance between the face and background. The suggested that the focus distance should be same for photo and video and should very for genuine attempt. Kim et al. [127] further enhanced the method using the defocusing techniques this time. They argued that real face is 3D and the ear region may or may not be clear while there was little difference in clarity in case of photo using focus. This was used to classify genuine and fake face.
Experimental Framework
3.1
Introduction
This chapter provides details of the experimental framework developed for the evaluation of the proposed approach. It presents the proposed implementation and the hardware set up used for the experiments. It also covers the definitions of different types of attack scenarios and the performance measures used to assess detection rates. The challenge design which is used for collecting the data is also explained in this chapter. The database that is developed for the purpose of evaluation of facial liveness detection methods is also described in this chapter. Facial liveness detection is a relatively new area of research, nevertheless, there are already some databases available for evaluation of liveness detection systems. However, due to the specific nature of the proposed challenge-response approach for liveness detection, none of the existing public databases are appropriate and a new database has been collected to evaluate the proposed system.
To enable the proposed system to evaluate the liveness, the user is required to interact with the system in a specific way, hence the visual stimulus providing the
Chapter 3. Experimental Framework 42
challenge to the user is designed in a particular order to extract the required gaze-based novel features. The database included genuine and fake attempts (photo attacks, photo mask attacks and video replay attacks) collected from male and female volunteers.
The remainder of the chapter is organised as follows: Section3.2 introduces the proposed system. The attack scenarios are presented in Section 3.3. Section 3.4
provides details of the system implementation and test setup. It covers system hardware, challenge design and landmark extraction. Section3.5provides details of the data collection covering hardware and software parameters, the number of volunteers, ethics approval and data storage. Finally, Section 3.6 presents the objective evaluation methods and metrics used in this study and Section3.7
presents a brief conclusion of the chapter.
3.2
Proposed System
To explore the approach based on gaze stability introduced in the introductory chapters a system is proposed based on a challenge-response mechanism as out-lined in Figure 3.1. The challenge is presented to the user as a visual stimulus appearing on a display screen. The client is asked to follow the shape that ap-pears on the screen with their gaze through natural head/eye movements and the camera (sensor) captures the facial images at varying positions of the stimulus on the screen.
A control mechanism is used to ensure the placement of the display target shape and the image acquisition are synchronized. The system extracts facial landmarks (centre of eyes/corner of eyes) in the captured frames and computes various features from these landmarks, which are then used to classify the presentation
Figure 3.1 Proposed system block diagram
attempt as either genuine (i.e. coming from a live sample) or fake (i.e. coming from an impostor using a photo/mask or video attack instrument).
3.3
Attack Scenarios
Various types of attack scenarios were investigated in this study. The scenarios considered here include that of an impostor attempting authentication by holding a photograph, a simple photo mask or by replaying a recorded video of a genuine client in front of the camera of the face recognition system.
The photo presentation attack scenario uses a high quality colour photo of a genuine user held in front of the camera, whilst the attacker attempts to follow the stimulus by orienting the photograph to “face” the position of the challenge shape on the screen. In the case of photo mask presentation attacks, a high quality colour photo of a genuine user with holes made in the pupil of the eyes was held by the user in front of the eyes as a mask, and used to follow the stimulus. In the case of the video replay attack the videos of the genuine users were recorded while the users were following the challenge in a genuine attempt. These videos were then replayed later for different challenges to attempt to spoof the proposed system.
Chapter 3. Experimental Framework 44
Figure 3.2 Example of Genuine attempt
Figure 3.4 Example of Photo Mask Spoof attempt
Chapter 3. Experimental Framework 46
Figure3.3 shows an impostor (attempting a photo presentation attack) during the data collection process. Figure 3.4 shows an impostor (attempting a photo mask presentation attack) holding a photo mask to follow the challenge while in Figure3.5 a recorded video is replayed to attack the system. Figure 3.2 shows a genuine user tracking the challenge to establish liveness.
3.4
Implementation
The following section describes the implementation of the proposed system. It explains the details of the hardware setup, challenge design and landmark ex-traction.
3.4.1
Hardware Setup
The hardware setup consists of a webcam, a PC and a display monitor of the PC. The challenge was displayed on the LCD screen for the user to follow the challenge to establish liveness. The webcam captures an image at each location of the challenge and stores these on the PC. Figure3.6 is the sketch of the setup for the proposed system.
3.4.2
![Figure 2.1 Graphic structure of CRF-based blinking model. C and NC are for closed state and non-closed state respectively [1]](https://thumb-us.123doks.com/thumbv2/123dok_us/1108207.2647454/24.893.203.753.149.420/figure-graphic-structure-based-blinking-closed-closed-respectively.webp)
![Figure 2.4 Illustration of liveness detection system using a com- com-bination of eyeblinks and scene context [3]](https://thumb-us.123doks.com/thumbv2/123dok_us/1108207.2647454/27.893.191.766.140.470/figure-illustration-liveness-detection-using-bination-eyeblinks-context.webp)
![Figure 2.6 The first row is four scene reference images. The second row is live faces in video [3]](https://thumb-us.123doks.com/thumbv2/123dok_us/1108207.2647454/28.893.182.771.608.976/figure-scene-reference-images-second-live-faces-video.webp)
![Figure 2.13 Difference between live face and fake face in fre- fre-quency domain [9]](https://thumb-us.123doks.com/thumbv2/123dok_us/1108207.2647454/36.893.206.745.198.595/figure-difference-live-face-fake-face-quency-domain.webp)
![Figure 2.14 The framework of the proposed approach for live- live-ness detection by Wu [10]](https://thumb-us.123doks.com/thumbv2/123dok_us/1108207.2647454/38.893.235.730.133.708/figure-framework-proposed-approach-live-live-ness-detection.webp)