Contents lists available a
Asian Journal of Computer Science and Information Technology
Journal homepage
USING ARABIC POETRY SYSTEM FOR STEGANOGRAPHY
Esam Ali Khan
Umm Al-Qura University
ARTICLE INFO ABSTRACT
Corresponding Author: Esam Ali Khan
Umm Al-Qura University [email protected]
DOI
Arabic text Steganography has gained increased attention in recent years, utilizing characteristics of Arabic language in hiding information. Arabic poetry system has an embedded binary representation that can be used for hiding secret data. In this work, we propose a steganography technique to utilize this binary redundancy available in the Arabic poetry system for steganography. The capacity of the proposed technique has been improved by inserting diacritics or kashida in some cases. Experimental results proved that the capacity of the proposed technique exceeds most of the previous techniques.
Keywords: Arabic steganography, Arabic poetry system.
©2014, AJCSIT, All Right Reserved
1. INTRODUCTION
Steganography is the art and science of hiding information by embedding messages within others. The hidden message is called "secret message" and the message to be used for hiding the secret message is called "cover message" or "cover media". The resulting message is called "stego message", which consists of the two messages, the secret message and the cover message [1] [2]. The goal of steganography is to use any redundancy in the cover message to hide the secret message in such a way that keeps the secret message undetectable without destroying the cover media integrity [3].
To measure the effectiveness and usefulness of a steganography technique, three metrics are usually used. These are capacity, security, and robustness. Capacity is defined as the amount of data bits that can be hidden in the cover media. Security refers to the difficulty for a third party to detect that a hidden message exists in the stego message. Robustness is the resistance of the steganography technique against modifying or destroying the secret message [3].
Basically, any digital file format can be used as a cover media. However, image, audio, video, and text files are more common in today's steganography [2] [3]. In image, audio, and video steganography, hiding information is done using the available noise in the cover media. In text steganography, in contrast, the redundancy to hide secret information has different forms, such as changing the formatting of a text, changing some words, and using random character sequences [4]. In recent years, attention has been paid to using characteristics of Arabic language for hiding information. In this work, we utilize a redundancy embedded in the Arabic poetry system for hiding binary data.
The paper is organized as follows. Section 2 reviews previous work done in text steganography using Arabic language. In Section 3, Arabic poetry system is described, showing how the binary redundancy is embedded within Arabic poems. The proposed technique is discussed in Section 4 and its capacity is compared to other techniques in Section 5. Finally, the paper is concluded in Section 6.
2. RELATED WORK
A number of methods for text steganography were proposed in literature. Some of these methods were used for Arabic text steganography. Some others were not, but they can be used. These methods can be classified into the following categories:
1) Shifting letters or dots of letters:
In [5], pointed letters are used to hide secret bits. If the secret bit to be hidden is zero, the pointed letter remains unchanged. If otherwise it is one, the point of the letter is shifted upwards.
Multipoint letters are used in [6] to hide secret data. Each letter can hide two bits of secret information. Table 1 below shows the different possible cases of using this method.
Table 1. Using multiple letters for hiding secret bits [6]
Secret bits Shifting points Distance between points
00 No shift Normal
01 No shift Points are separated
10 Shifted up Normal
56
2) Using the Arabic Extension (Kashida or Tatweel) Character:
In [1], kashida is added to those letters that can hold it to hide secret bits. One kashida is used to hide 0 and two consecutive kashidas are used to hide 1. For optimization, all possible forms of Arabic letters – which are less than 64 – are encoded using 6 bits, instead of the 16-bit Unicode. In addition, to increase security of the method, a "finishing character" is used to show that hiding the secret object is done and all coming kashidas are redundant.
An algorithm called MSCUKAT (Maximizing Steganography Capacity Using 'Kashida' in Arabic Text) has been developed in [7] and [8]. This algorithm searches in the cover object to find a letter where kashida can be inserted. If the secret bit is 1, then a kashida is added. Otherwise, it is not.
Kashida is used with pointed and pointed letters in [9] to hide secret bits. If the secret bit is 0, a kashida is added to an un-pointed letter. Otherwise, it is added to a un-pointed letter. Of course, only letters that can hold kashida are used here.
To increase the security of using kashida for steganography, the number of possible kashidas per word is calculated in [10] and then only some of the possible positions are used to hide secret bits. An improved version of this method was represented in [11], where a secret key is used to define the positions that will bear secret bits in each word of the cover text. Some redundant kashidas are then inserted in that word to increase the security.
A kashida variation algorithm (KVA) has been proposed in [12] to increase the robustness. A cover text is segmented into blocks, and then hiding bits in each block is based randomly on one of four scenarios:
a. Adding kashida after pointed letters to encode one, otherwise, pass zero. b. Adding kashida after non-pointed letters to encode one, otherwise, pass zero. c. Adding kashida after letters to encode one, otherwise, pass zero.
d. Adding kashida after letters to encode zero, otherwise, pass one.
3) Diacritics-based methods:
Three methods of using diacritics for steganography have been proposed in [13]. The basic method starts with all possible diacritics present in the cover text. Then, if the secret bit to be hidden is 1, the corresponding diacritic is left present, and it is removed if the secret bit is 0. The second method proposed in [13] is called the switch technique, where a diacritic is only shown whenever there is a switch from 0 to 1 or from 1 to 0. The third technique uses a parity bit for every letter in the cover text, where 0 is assigned to letters whose positions are even and 1 to those whose positions are odd. Then, if the secret bit is equal to the corresponding parity bit, the diacritic is removed. Otherwise, it is shown.
In [14],it has been found that fatha is used almost as frequently as the other seven diacritics used in Arabic language. Therefore, the authors proposed to use fatha to hide 1 and the other diacritics to hide 0.
An improvement to the work presented in [14] has been proposed in [15]. Two algorithms have been proposed based on the number of diacritics needed to hide secret bits. The first algorithm uses fixed-size blocks of secret bits in the cover text. The second algorithm maps all consecutive bits with value 1 and all consecutive bits with value 0 into the length of their corresponding run.
Multiple diacritics have been used for steganography in [16], where multiple instances of a diacritic is used to hide secret bits. This technique has two approaches: text approach and image approach. In textual approach, arbitrary number of repeated but invisible diacritics is used to hide secret bits, given that the Arabic font selected allows for this feature. In the image approach, the level of darkness of a diacritic determines the number of hidden bits. Also here, the Arabic font should be selected to allow for this feature.
4) Unicode-based:
Some Arabic and Persian letters have similar shapes that can be used alternatively. In [17], this fact has been used with the two letters "ﻱ" and "ﻙ" . To hide 0, the Persian letters "ﻯ" and "ـﻛ" are used. The Arabic letters"ﻱ" and "ﻙ" are used to hide 1. In [18], a feature of Unicode standard has been used to hide bits. This feature is special for Arabic and Persian languages, where each letter can be represented in two ways; either by its isolated form or by the connected form which is determined by the location of the letter in the word. For hiding 0, the isolated form is used, while the connected form is used for hiding 1. When mixing the two methods, the text viewer may not be able to determine the correct form of the isolated letters. The ZWJ character, which is a hidden character, is used to help the text viewer in putting the letter in its correct form.
Zero-space characters have been used in [19] to hide secret bits. These characters are ZWJ and ZWNJ. ZWJ forces two letters to be connected, and ZWNJ prevents two letters from being connected. To hide secret bits, each letter is checked. If it is connected to the next letter, ZWJ is inserted to hide 1 and nothing is inserted in the case of hiding 0. On the other hand, if the letter is not connected to the next letter, ZWNJ is inserted to hide 1 and nothing is inserted in the case of hiding 0.
A special character used in Arabic language is La character "ﻻ", which is composed of two letters: Lam "ﻝ" and Alif "ﺍ". The usual way of writing La character is in the form "ﻻ". However, it could also be written like this "ﺎـﻟ". In [20] and [21], these two forms of writing the La character have been used to hide secret bits. The normal form "ﻻ" is used to hide 1 and the other form "ﺎـﻟ" is used to hide 0. The difference between the technique used in [20] and that used in [21] is in the way the form "ﺎـﻟ" is written. In [20], a kashida is inserted between the Lam and the Alif, while the Unicode of the required shape is used in [21].
Each Arabic letter has 5 codes in Unicode standard. One code is used as a representative code, which shows the letter in isolated form regardless of its position in the word. The other 4 codes show the letter in its position in the word, which are isolation (i.e. not connected to any other letter), beginning, middle, and end of a word. This feature has been used in [22] to hide secret bits. If the secret bit is 0, the representative code is used. The codes of the position are used to hide bit 1.
5) Sharp-edges:
Table 2. Number of sharp edges in Arabic letters as used in [23]
Number of sharp edges Arabic letters
1 ﻡ ﻩ ﻕ ﻑ ﺓ ﻭ
2 ﺽ ﺹ ﻥ ﻅ ﻁ ﻝ ﻱ ﺯ ﺭ ﺯ ﺩ ﺙ ﺕ ﺏ ﺍ
3 ﺥ ﺝ ﺡ ء ﻉ ﻍ
4 ﺵ ﺱ
5 ﻙ
The algorithm uses two keys. The first key determines whether dotted or un-dotted letters will be used to hide secret bits. If the sum of digits of the key is even, then dotted letters are used; and un-dotted letters are used otherwise. The second key is used to determine the positions of the secret bits in the letters of the cover text. This is done using a reference table, where each edge of a letter is given a 5-digit code that represents the bits that can be hidden in the edges of that letter.
In [24], the feature of connecting most of the Arabic letters has been utilized to hide secret bits. The authors have used kashida to hide one bit. If more bits are to be hidden, they have used the zero-width character, which is a hidden character.
3. ARABIC POETRY SYSTEM
One of the important and old Arabic traditions is poetry, which was an oral tradition of saying rhymed poems. Al-Khaliil Ibn Ahmed was the first author who characterized traditional Arabic poems into the Arabic poetry system, known as E`lm Al-a`arudh [25].
A poem (or Qasida) is the building body in Arabic poetry system. Any poem can be classified into one of 16 meters, each of which is called (Bahr) in Arabic. A meter consists of similar lines. Each line is called a verse (or Bait) and is divided into two half-lines, each of which is called hemistich (or Shatr). The building blocks of a meter are called feet (or tafa 'il), each of which is composed of some units, called peg (or watid) and cord (or sabab) [26].
The basis for building pegs and cords is the fact that each letter in Arabic is either silent or movement. A silent letter is the one marked with the silence diacritic, which is called sukun, while a movement letter is that marked with one of the other three diacritics, fatha, damma, or kasra. In order to differentiate between a silent letter and a movement letter, Al-Khaliil Ibn Ahmed used the binary system to symbolize these letters. A silent letter can be indicated with a "0" and a movement letter can be indicated by a "1". Using this notation, there are four types of pegs and cords, as shown in Table 3.
Table 3. Types of pegs and cords
Unit name Description Binary representation (right to left)
Light cord A movement letter followed by a silent letter 0 1
Heavy cord Two consecutive movement letters 1 1
Collected peg A silent letter after two consecutive movement letters 0 1 1
Separated peg A silent letter between two movement letters 1 0 1
Using these types of pegs and cords, there are 10 feet (or tafa 'il), and each poetry meter is composed of some of these feet [26]. Table 4 shows these ten feet with their binary representation [27].
Table 4. The ten feet used in Arabic poetry meters
Foot Binary representation (right to left)
ﻦﻟﻮﻌﻓ 01 011
ﻦﻠﻋﺎﻓ 011 01
ﻦﻠﻌﻔﺘﺴﻣ 011 01 01
ﻦﺘﻠﻋﺎﻔﻣ 01 11 011
ﻦﻠﻴﻋﺎﻔﻣ 01 01 011
ﻦﻠﻋﺎﻔﺘﻣ 011 01 11
ﻦﺗﻼﻋﺎﻓ 01 011 01
ﻦﻟ ﻊﻔﺘﺴﻣ 01 101 01
ﻦﺗ ﻻ ﻉﺎﻓ 01 01 101
ﺕﻻﻮﻌﻔﻣ 101 01 01
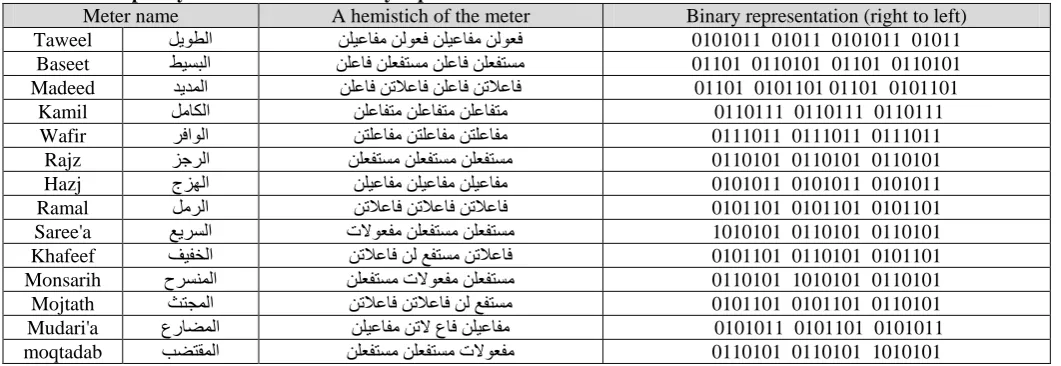
Table 5 shows one hemistich (or Shatr) of each of the sixteen poetry meters, with the corresponding binary representation. Table 5. Arabic poetry meters and their binary representation
Meter name A hemistich of the meter Binary representation (right to left)
Taweel ﻞﻳﻮﻄﻟﺍ ﻦﻠﻴﻋﺎﻔﻣ ﻦﻟﻮﻌﻓ ﻦﻠﻴﻋﺎﻔﻣ ﻦﻟﻮﻌﻓ 0101011 01011 0101011 01011
Baseet ﻂﻴﺴﺒﻟﺍ ﻦﻠﻋﺎﻓ ﻦﻠﻌﻔﺘﺴﻣ ﻦﻠﻋﺎﻓ ﻦﻠﻌﻔﺘﺴﻣ 01101 0110101 01101 0110101
Madeed ﺪﻳﺪﻤﻟﺍ ﻦﻠﻋﺎﻓ ﻦﺗﻼﻋﺎﻓ ﻦﻠﻋﺎﻓ ﻦﺗﻼﻋﺎﻓ 01101 0101101 01101 0101101
Kamil ﻞﻣﺎﻜﻟﺍ ﻦﻠﻋﺎﻔﺘﻣ ﻦﻠﻋﺎﻔﺘﻣ ﻦﻠﻋﺎﻔﺘﻣ 0110111 0110111 0110111
Wafir ﺮﻓﺍﻮﻟﺍ ﻦﺘﻠﻋﺎﻔﻣ ﻦﺘﻠﻋﺎﻔﻣ ﻦﺘﻠﻋﺎﻔﻣ 0111011 0111011 0111011
Rajz ﺰﺟﺮﻟﺍ ﻦﻠﻌﻔﺘﺴﻣ ﻦﻠﻌﻔﺘﺴﻣ ﻦﻠﻌﻔﺘﺴﻣ 0110101 0110101 0110101
Hazj ﺝﺰﻬﻟﺍ ﻦﻠﻴﻋﺎﻔﻣ ﻦﻠﻴﻋﺎﻔﻣ ﻦﻠﻴﻋﺎﻔﻣ 0101011 0101011 0101011
Ramal ﻞﻣﺮﻟﺍ ﻦﺗﻼﻋﺎﻓ ﻦﺗﻼﻋﺎﻓ ﻦﺗﻼﻋﺎﻓ 0101101 0101101 0101101
Saree'a ﻊﻳﺮﺴﻟﺍ ﺕﻻﻮﻌﻔﻣ ﻦﻠﻌﻔﺘﺴﻣ ﻦﻠﻌﻔﺘﺴﻣ 1010101 0110101 0110101
Khafeef ﻒﻴﻔﺨﻟﺍ ﻦﺗﻼﻋﺎﻓ ﻦﻟ ﻊﻔﺘﺴﻣ ﻦﺗﻼﻋﺎﻓ 0101101 0110101 0101101
Monsarih ﺡﺮﺴﻨﻤﻟﺍ ﻦﻠﻌﻔﺘﺴﻣ ﺕﻻﻮﻌﻔﻣ ﻦﻠﻌﻔﺘﺴﻣ 0110101 1010101 0110101
Mojtath ﺚﺘﺠﻤﻟﺍ ﻦﺗﻼﻋﺎﻓ ﻦﺗﻼﻋﺎﻓ ﻦﻟ ﻊﻔﺘﺴﻣ 0101101 0101101 0110101
Mudari'a ﻉﺭﺎﻀﻤﻟﺍ ﻦﻠﻴﻋﺎﻔﻣ ﻦﺗﻻ ﻉﺎﻓ ﻦﻠﻴﻋﺎﻔﻣ 0101011 0101101 0101011
58
Mutaqarib ﺏﺭﺎﻘﺘﻤﻟﺍ ﻦﻟﻮﻌﻓ ﻦﻟﻮﻌﻓ ﻦﻟﻮﻌﻓ ﻦﻟﻮﻌﻓ 01011 01011 01011 01011
Mutadarak ﻙﺭﺍﺪﺘﻤﻟﺍ ﻦﻠﻋﺎﻓ ﻦﻠﻋﺎﻓ ﻦﻠﻋﺎﻓ ﻦﻠﻋﺎﻓ 01101 01101 01101 01101
It should be noted that there are some rules applied to pegs and cords that may change the feet shown in Table 4, and in turn change the representation of the meters. Some of these rules are used more frequently than others. Details of these rules and their effect on each meter can be found in [25] and [27].
An example of a verse and how it is represented in Arabic poetry system is shown in Table 6. In this example we can notice the following:
1)The matching between a verse and its corresponding meter is based on the pronounced (or spoken) letters, not the written ones. In instance, the "tanween" in the word " ٌﻦﻁﻭ", which is considered as a diacritic in the written word, is converted as the letter "noon".
2)In order to find the proper feet of a verse, the words may be cut and split between different feet.
3)Any vowel (or Madd), which may be the letter (Alif "ﺍ", Waw "ﻭ", or Yaa "ﻱ"), is considered as a silent letter. 4)The feet ""ﻦﻟﻮﻌﻓ" and "ﻦﻠﻴﻋﺎﻔﻣ" has been changed into "ﻝﻮﻌﻓ" and "ﻦﻠﻋﺎﻔﻣ" based on the rules mentioned above.
Table 6. An example of a verse of an Arabic poem and how it is classified into poetry meters
The verse ﺎﻛﻟﺎﻣ َﺭﻫﺩﻟﺍ ﻪﻟ ﻱﺭﻳﻏ ﻯﺭﺃ ّﻻﺃﻭ ُﻪَﻌﻳﺑﺃ ﻻﺃ ﺕﻳﻟﺁ ٌﻥﻁﻭ ﻲﻟﻭ
How it is pronounced ﺎﻜﻟﺎﻣﺭ ﻩﺩﺪﻬﻟ ﻱﺮﻴﻏ ﻯﺭﺃ ﻼﻟﺃﻭ ﻮﻬﻌﻴﺑﺃ ﻼﻟﺃ ﺕ ﻲﻟﺍء ﻦﻨﻁ ﻭ ﻲﻟﻭ
The corresponding feet ﻦﻠﻋﺎﻔﻣ ﻦﻟﻮﻌﻓ ﻦﻠﻴﻋﺎﻔﻣ ﻦﻟﻮﻌﻓ ﻦﻠﻋﺎﻔﻣ ﻦﻟﻮﻌﻓ ﻦﻠﻴﻋﺎﻔﻣ ﻝﻮﻌﻓ
Binary representation 011011 01011 0101011 01011 011011 01011 0101011 1011
Its classification Al-Taweel meter
4. PROPOSED TECHNIQUE
In this paper, we propose to use the Arabic poetry system in order to hide secret bits. Since there is a binary representation embedded in each Arabic poem, this can be used as the basis for hiding secret bits. The idea here is to presuppose that the embedded binary bit in a poem position contains a secret bit. The actual secret bit either is the same as that binary position or its reverse. In order to distinguish between these two cases, we will use some of the techniques reviewed in Section 2. We will add redundant techniques only when the secret bit is the opposite of the binary bit of the corresponding letter in the cover poem. This is summarized in Table 7.
Table 7. Indicating the case of the secret bits using the proposed technique
Cover text binary representation Secret bit Redundant techniques
0 0 Hide
0 1 Show
1 0 Show
1 1 Hide
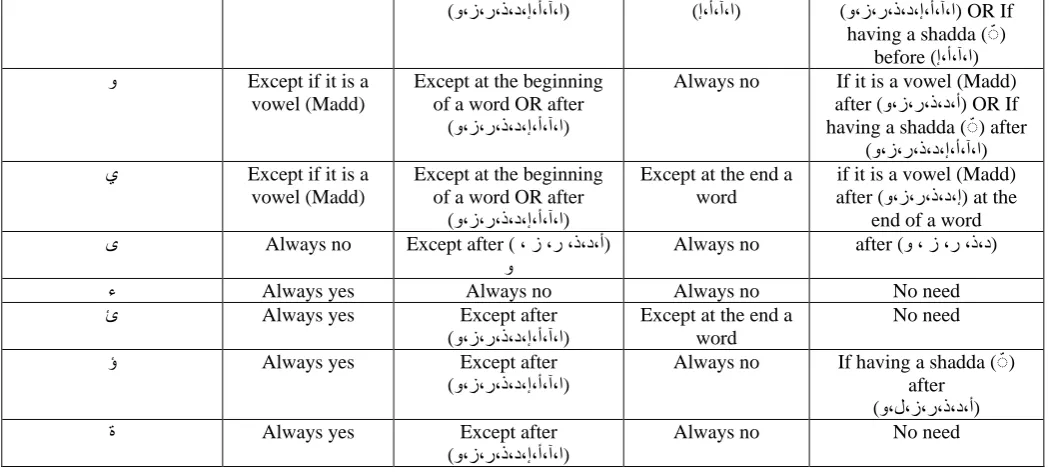
Since any letter in Arabic words must have a diacritic, whether shown or hidden, we decided to use diacritics as the basic redundant technique. However, there are some cases where a diacritic may not be shown in the written text. For example, the letters (Alif "ﺍ", Waw "ﻭ", and Yaa "ﻱ") when used as vowel (or Madd) are considered silent, but the Sukun ( ْ◌) is not usually shown in the written text. Furthermore, using the Arabic poetry system, there are some cases where a written letter is actually composed of two letters. For instance, a letter with Shadda ( ّ◌) is composed of two identical letters, the first is silent (with sukun " ْ◌") and the second is with one of the three diacritics (fatha " َ◌", damma " ُ◌" or kasra " ِ◌"); but only one letter is written. Showing diacritics in such cases will decrease the security of the proposed steganography technique.
In order to increase the capacity of the proposed technique while increasing the security as well, we need to use another redundant technique in the cases where diacritics cannot be shown. We decided to use the kashida technique in such cases. We have two choices, kashida-before and kashida-after. We use kashida-before whenever possible, and use kashida-after otherwise. If
neither one can be used, then we skip that position.Table 8 summarizes the possibility of using the above mentioned redundant
techniques with all Arabic letters in all cases.
Table 8. Possibility of using redundant techniques for all Arabic letters
Arabic letter Diacritic Kashida-before Kashida-after skip
ﺁ ،ﺍ Always no Except at the beginning
of a word OR after (ﻭ،ﻝ،ﺯ،ﺭ،ﺫ،ﺩ)
Always no At the beginning of a
word OR after (ﻭ،ﻝ،ﺯ،ﺭ،ﺫ،ﺩ)
ﺃ Always yes Except at the beginning
of a word OR after (ﻭ،ﻝ،ﺯ،ﺭ،ﺫ،ﺩ)
Always no If having a shadda ( ّ◌)
after (ﻭ،ﻝ،ﺯ،ﺭ،ﺫ،ﺩ)
ﺇ Always yes Except at the beginning
of a word OR after (ﻭ،ﻝ،ﺯ،ﺭ،ﺫ،ﺩ)
Always no No need
،ﺱ،ﺥ،ﺡ،ﺝ،ﺙ،ﺕ،ﺏ ،ﻍ،ﻉ،ﻅ،ﻁ،ﺽ،ﺹ،ﺵ
ﻩ،ﻥ،ﻡ،ﻙ،ﻕ،ﻑ
Always yes Except at the beginning
of a word OR after (ﻭ،ﺯ،ﺭ،ﺫ،ﺩ،ﺇ،ﺃ،ﺁ،ﺍ)
Except at the end of a word
If having a shadda ( ّ◌) at the end of a word after
(ﻭ،ﺯ،ﺭ،ﺫ،ﺩ،ﺇ،ﺃ،ﺁ،ﺍ)
ﺯ،ﺭ،ﺫ،ﺩ Always yes Except at the beginning
of a word OR after (ﻭ، ﺯ،ﺭ،ﺫ،ﺩ،ﺇ،ﺃ،ﺁ،ﺍ)
Always no If having a shadda ( ّ◌)
after (ﻭ،ﺯ،ﺭ،ﺫ،ﺩ،ﺇ،ﺃ،ﺁ،ﺍ)
ﻝ Always yes Except at the beginning
of a word OR after
Except at the end a word OR before
(ﻭ،ﺯ،ﺭ،ﺫ،ﺩ،ﺇ،ﺃ،ﺁ،ﺍ) (ﺇ،ﺃ،ﺁ،ﺍ) (ﻭ،ﺯ،ﺭ،ﺫ،ﺩ،ﺇ،ﺃ،ﺁ،ﺍ) OR If having a shadda ( ّ◌)
before (ﺇ،ﺃ،ﺁ،ﺍ)
ﻭ Except if it is a
vowel (Madd)
Except at the beginning of a word OR after
(ﻭ،ﺯ،ﺭ،ﺫ،ﺩ،ﺇ،ﺃ،ﺁ،ﺍ)
Always no If it is a vowel (Madd)
after (ﻭ،ﺯ،ﺭ،ﺫ،ﺩ،ﺃ) OR If having a shadda ( ّ◌) after
( ﻭ،ﺯ،ﺭ،ﺫ،ﺩ،ﺇ،ﺃ،ﺁ،ﺍ)
ﻱ Except if it is a
vowel (Madd)
Except at the beginning of a word OR after
(ﻭ،ﺯ،ﺭ،ﺫ،ﺩ،ﺇ،ﺃ،ﺁ،ﺍ)
Except at the end a word
if it is a vowel (Madd) after (ﻭ،ﺯ،ﺭ،ﺫ،ﺩ،ﺇ) at the
end of a word
ﻯ Always no Except after ( ، ﺯ ،ﺭ ،ﺫ،ﺩ،ﺃ)
ﻭ Always no after (ﻭ ، ﺯ ،ﺭ ،ﺫ،ﺩ)
ء Always yes Always no Always no No need
ﺉ Always yes Except after
(ﻭ،ﺯ،ﺭ،ﺫ،ﺩ،ﺇ،ﺃ،ﺁ،ﺍ)
Except at the end a word
No need
ﺅ Always yes Except after
(ﻭ،ﺯ،ﺭ،ﺫ،ﺩ،ﺇ،ﺃ،ﺁ،ﺍ) Always no If having a shadda (after ّ◌)
(ﻭ،ﻝ،ﺯ،ﺭ،ﺫ،ﺩ،ﺃ)
ﺓ Always yes Except after
(ﻭ،ﺯ،ﺭ،ﺫ،ﺩ،ﺇ،ﺃ،ﺁ،ﺍ) Always no No need
5. EXPERIMENTAL RESULTS AND COMPARISON
We used the proposed technique explained in the previous section to hide secret bits in selected Arabic poems. We selected three very famous Arabic poems written in the era before Islam, which are among ten poems called "the ten hanged poems". The selected three poems have different poetry meters. For each poem, we hid five sets of secret bits as shown in Table 9.
Table 9. The sets of secret bits used in the experiments Set
number
Description
1 From an actual file
2 All 1's
3 All 0's
4 Toggling between 1 and 0 starting by 0
5 Toggling between 1 and 0 starting by 1
In literature, different approaches have been used to calculate the capacity of a certain steganographic technique and to compare its quality with other approaches.
One approach defines the capacity as the percentage of the stego-text that hide secret data [13]. This can be represented in percentage or in bits/KB. For example, a capacity of 5% means that every 100 bits of the stego-text are carrying 5 bits of hidden information; and a capacity of 300 bits/KB means that every kilobyte of stego-data is carrying 300 bits of hidden data.
Another approach is to calculate the total capacity that can be achieved using a certain cover text. Then, the quality of a certain steganographic technique is calculated as the percentage of the capacity usage [1].
A third approach counts the number of usable characters capable of hiding secret bits. It uses p for the ratio of characters capable of baring a secret bit of a given level, and q for the ratio of characters capable of baring the opposite level [9] [10] [16].
Another approach measures capacity in two ways:
1. The amount of embedded bits in a predefined cover message (secret bits/cover byte) or the amount of cover message needed for a given secret message (cover bytes/secret bit).
2. The size of the combined message needed for a hidden message, either compared to the hidden message (combined bytes/secret bit), or recorded as a percent increase to the size of the cover message (bytes/byte). [15].
In this paper, we will use the first approach to compute the capacity of our proposed technique and will compare it to other techniques that used the same method. It should be noted that we assume that each letter, diacritic, or kashida will be represented in Windows-1256 encoding which takes one byte for each character, as used in [13] and [14]. The capacity of our proposed technique is shown in Table 10.
Table 10. The capacity of the proposed technique using different poems and secret bits
Poem # Set # Capacity
In percentage In bit/KB
1 1 7.89 646.19
1 2 8.92 731.04
1 3 7.22 591.13
1 4 7.97 652.67
1 5 8.25 676.22
2 1 7.69 630.21
2 2 8.52 697.80
2 3 7.08 580.23
60
2 5 7.74 634.44
3 1 8.13 665.96
3 2 9.20 754.00
3 3 7.34 601.41
3 4 8.23 674.55
3 5 8.10 663.63
Average 8.00 655.48
The cumulative average capacity of our proposed technique is 8.00 % or 655.48 bit/KB, which is higher than all previous techniques as shown in Table 11.
Table 11. The capacity of previous techniques
Technique Capacity
Kashida with pointed letters [9] 1.22 %
Diacritic based [14] 3.27 %
Diacritic based (basic) [13] 6.44 %
Diacritic based (parity) [13] 6.33 %
Diacritic based (switch) [13] 6.45 %
Kashida watermarking method (complete) [10] 2.8 %
Kashida watermarking method (without preparation phase) [10] 3.3 %
Dotted letters [5] (from [18] and [21]) 112.8 bit/KB
Unicode [18] [19] 407.2 bit/KB
Similar letters [17] 33.25 bit/KB
'La' word [20] [21] 1.171 bit/KB
Multipoint letters [6] 91.2 bit/KB
Pseudo characters (even method) [19] [23] 750 bit/KB
Pseudo characters (odd method) [19] [23] 550 bit/KB
Unicode [22] 102.38 bit/KB
The capacity of the even method reported in [19] and [23] is higher than the capacity of our method. However, this reported capacity considered only the number of sharp edges which can hide secret bits; and not included the redundant bits used to represent these secret bits, where every two bits are represented using five bits. This means that the reported capacity equals 2.5 times the actual capacity.
6. CONCLUSION
In this paper, a text steganography technique is proposed utilizing binary redundancy embedded in Arabic poetry system. In order to increase the capacity of the proposed technique, diacritics and kashida techniques have been used in some cases. The experimental results showed that the capacity of this proposed technique outperforms most of the previous techniques. The proposed technique can be further improved to have more security and robustness by compromising the capacity.
REFERENCES
[1] A. A. Gutub, W. Al-Alwani, and A. Bin Mahfoodh, "Improved Method of Arabic Text Steganography Using the Extension
‘Kashida’ Character," Bahria University Journal of Information & Communication Technology, Vol. 3, Issue 1, December 2010, pp. 68-72.
[2] S. Bhattacharyya, I. Banerjee, and G. Sanyal, "A Survey of Steganography and Steganalysis Technique in Image, Text, Audio and Video as Cover Carrier," Journal of Global Research in Computer Science, Volume 2, No. 4, April 2011, pp. 1-16. [3] A. A. Gutub and M. M. Fattani, "A Novel Arabic Text Steganography Method Using Letter Points and Extensions," WASET
International Journal on Computer, Information and Systems Science and Engineering, Vol. 1, No. 3, 2007, pp. 379-482.
[4] K. Bennett, "Linguistic Steganography: Survey, Analysis, And Robustness Concerns For Hiding Information in Text,"
Technical Report 2004-13, Center for Education and Research in Information Assurance and Security, Purdue University, West Lafayette, IN 47907-2086, 2004.
[5] H. Shirali-Shahreza and M. Shirali-Shahreza, "A New Approach to Persian/Arabic Text Steganography," Proceedings of the
5th IEEE/ACIS International Conference on Computer and Information Science (ICIS2006), Honolulu,10–12 July 2006, pp.
310–315.
[6] A. Odeh, A. Alzubi, Q. B. Hani, and K. Elleithy, "Steganography by Multipoint Arabic Letters," Proceedings of the 2012
IEEE Long Island Systems, Applications and Technology Conference (LISAT), 2012, pp. 1-7.
[7] A. Al-Nazer, and A. Gutub, "Exploit Kashida Adding to Arabic E-Text for High Capacity Steganography," International Workshop on Frontiers of Information Assurance & Security (FIAS 2009), Gold Coast, Queensland, Australia, 19–21 October 2009, pp. 447-451.
[8] A. Gutub and A. Al-Nazer, "High Capacity Steganography Tool for Arabic Text Using 'Kashida'," The ISC Int'l Journal of Information Security (ISeCure), Vol. 2, No. 2, July 2010, pp. 109-120.
[9] A. Gutub, L. Ghouti, A. Amin, T. Alkharobi, and M. K. Ibrahim, "Utilizing Extension Character 'Kashida' with Pointed Letters for Arabic Text Digital Watermarking," Proceedings of the International Conference on Security and Cryptography
(SECRYPT'07), Barcelona, Spain, 2007, pp. 329-332.
[10]A. A. Gutub, F. Al-Haidari, K. M. Al-Kahsah, and J. Hamodi, "E-Text Watermarking: Utilizing 'Kashida' Extensions in
Arabic Language Electronic Writing," Journal of Emerging Technologies in Web Intelligence (JETWI), Vol. 2, No. 1,
[11]F. Al-Haidari, A. Gutub, K. Al-Kahsah, and J. Hamodi, "Improving Security and Capacity for Arabic Text Steganography
Using 'Kashida' Extensions," The 7th ACS/IEEE International Conference on Computer Systems and Applications
(AICCSA-2009), Rabat, Morocco, 10-13 May 2009, pp. 396-399.
[12] A. Odeh, K. Elleithy, and M. Faezipour, "Steganography in Arabic Text Using Kashida Variation Algorithm (KVA),"
Proceedings of the 2013 IEEE Long Island Systems, Applications and Technology Conference (LISAT), May 2013, pp. 1 – 6,
DOI: 10.1109/LISAT.2013.6578239.
[13]M. L. Bensaad and M. B. Yagoubi, "Boosting the Capacity of Diacritics-Based Methods for Information Hiding in Arabic Text," Arabian Journal for Science and Engineering, February 2013, pp. 2035-2041, DOI: 10.1007/s13369-013-0576-3. [14]M. A. Aabed, S. M. Awaideh, A. M. Elshafei and A. A. Gutub, "Arabic Diacritics Based Steganography," Proceedings of the
2007 IEEE International Conference on Signal Processing and Communications (ICSPC 2007), Dubai, United Arab
Emirates, November 2007, pp. 756-759.
[15]A. Gutub, L. Ghouti, Y. Elarian, S. Awaideh, and A. Alvi, "Utilizing Diacritic Marks for Arabic Text Steganography," Kuwait Journal of Science & Engineering (KJSE), Vol. 37, No. 1, June 2010, pp. 89-109.
[16]A. A. Gutub, Y. S. Elarian, S. M. Awaideh, and A. K. Alvi, "Arabic Text Steganography Using Multiple Diacritics,"
Proceedings of the 5th IEEE International Workshop on Signal Processing and its Applications (WoSPA 2008), Sharjah,
UAE, 2008.
[17]H. Shirali-Shahreza and M. Shirali-Shahreza, "Arabic/Persian Text Steganography Utilizing Similar Letters with Different Codes," Arab. J. Sci. Eng., Vol. 35, No. 1B, 2010, pp. 213–222.
[18]M. Shirali-Shahreza, and S. Shirali-Shahreza, "High Capacity Persian/Arabic Text Steganography," J. Appl. Sci., Vol. 8, No. 22, 2008, pp. 4173–4179
[19]M. Shirali-Shahreza, and M. H.Shirali-Shahreza, "Steganography in Persian and Arabic Unicode Texts Using Pseudo-Space
and Pseudo Connection Characters," Journal of Theoretical & Applied Information Technology, Vol. 4, Issue 8, August 2008, pp. 682 – 687.
[20]M. Shirali-Shahreza, "A New Persian/Arabic Text Steganography Using 'La' Word," Proceedings of the International Joint
Conference on Computer, Information, and Systems Sciences, and Engineering (CISSE'07), Bridgeport, CT, USA, 2007,
Springer Verlag, pp. 339-342.
[21]M. Shirali-Shahreza, and M. H. Shirali-Shahreza, "An Improved Version of Persian/Arabic Text Steganography Using 'La'
Word," Proceedings of IEEE 2008 6th National Conference on Telecommunication Technologies and IEEE 2008 2nd
Malaysia Conference on Photonics, Putrajaya, Malaysia, 26-27 August 2008, pp. 372 - 376.
[22]M. Shirali-Shahreza and S. Shirali-Shahreza, "Persian/Arabic Unicode Text Steganography," Proceedings of the Fourth International Conference on Information Assurance and Security, 2008, pp. 62 – 66.
[23]N. A. Roslan, R. Mahmod, and N. Udzir, "Sharp-Edges Method in Arabic Text Steganography," Journal of Theoretical and
Applied Information Technology, Vol. 33, No. 1, November 2011, pp. 32 – 41.
[24]A. Odeh and K. Elleithy, "Steganography in Arabic Text Using Zero Width and Kashida Letters," International Journal of Computer Science & Infromation Technology (IJCSIT), Vol. 4, No. 3, June 2012, pp. 1-11.
[25]J. M. Maling, "The Theory of Classical Arabic Metrics," Massachusets Institue of Technology, PhD Dissertatin, Jan. 1973. [26]H. Scott, "Pegs, Cords, and Ghuls: Meter of Classical Arabic Poetry," Swarthmore College, Dept. of Linguistics, Thesis (B.
A.), 2010.
[27]M. Mustafa, "ﺔﻴﻓﺎﻘﻟﺍﻭ ﺽﻭﺮﻌﻟﺍ :ﻞﻴﻠﺨﻟﺍ ﻲﻤﻠﻋ ﻰﻟﺇ ﻞﻴﺒﺳ ﻯﺪﻫﺃ", World of Books, Beirut, Lebanon, 1st edition, 1996.