2754
Multi-Class Support Vector Machine Based
Continuous Voiced Odia Numerals Recognition
Prithviraj Mohanty, Ajit Kumar Nayak
Abstract: With rapid advancement of automatic speech-recognition technologies, speech-based machine interaction has fascinated attention by many researchers to apply their approach from the research laboratory to real-life applications. A continuous voiced numerals recognition system is always useful for physically challenged persons (blind people) or elder people to have a telephonic conversion, setting the PIN number for their debit and credit cards and also devising the security code for some applications without physically touching the system. The work presented on this paper emphasize the recognition of continuous Odia numerals using multi-class Support Vector Machine (SVM).Three popular feature extraction techniques such as: PLP, LPC and MFCC are used to extract the feature parameters from voiced numerals and fed as the input to the recognition process. Different kernel mapping functions like: polynomial, sigmoid, Radial Basis Function (RBF) and wavelet are used in order to map the non-linear input feature space of framed signals to linear high dimensional feature space. So as to recognize the Odia numerals, multi-class SVM models are constructed using the techniques of One-Verses-All (OVA) and Half-Verses-Half (HVH). For the proposed system, diverse experimentations has been performed and results are analyzed over multi-class SVM models considering different feature parameter techniques with various kernel mapping functions. It has been observed that, OVA SVM model with MFCC for feature extraction and wavelet as kernel mapping function provides better accuracy as compared to other variations of the results attained.
Index Terms: SVM, PLP, LPC, MFCC, Sigmoid, RBF, Wavelet, OVA, HVH.
—————————— ——————————
1.
INTRODUCTION
UTOMATIC speech recognition (ASR) by machine is believed to be the most active and exciting field of research and being well-thought-out for more than 50 years. The main objective of an ASR system is to transcript input voiced utterances into its corresponding text. The ASR system can be exploited for certifying users via their voiced signals and executing the activity in the form of commands specified by the human [1]. ASR is also, treated as one of the active application of speech processing and usually used for human machine interaction. ASR applications are very much crucial in voice based activities, automatic debit and credit card activation, safety and investigation amenities. In the present day, in most of the smart phones, laptops and tablets, ASR based soft wares such as: OK Google, Apple Siri, and Microsoft Cortana are incorporated to make the life more simple and productive [2]. Automatic numeral recognition of spoken utterances has concerned a lot of authenticity because several numerical data such as account number, debit and credit card number, telephone number can be inputted to the machine conveniently using the voices of humans. Isolated word recognition and spoken digit recognition are mostly applicable for data entry automation, generation of PIN code applied in various services, automation in banking and security systems. Similarly, the application of continuous voice based numeral recognition is generally helpful for automatically dialing telephone numbers [3]. In the early research over the speech recognition systems, HMM model, a statistical method based classifiers have been employed to evaluate the acoustic probability. Using the maximum likelihood estimation (MLE) algorithm, parameters for HMM models are computed [4]. Since the parameters are evaluated using only the input class data and mainly depends upon the prior probability
distribution, so it exhibits poor performance in classification. Therefore, it requires a technique which may be used to classify in a better manner. During last few decades researchers were proposed some alternative approaches that have better performance compared to HMM. Most of the approaches based on Artificial Neural Networks [5] or the hybrid approach of HMM-ANN [6]. A new machine learning technique like SVM which has good generalization and convergence property, can be used as a better classifier. Generally SVM is a linear classifier but use of different kernel mapping functions permits SVM to function as a non-linear classifier which has high dimensional feature space [7]. A lot of enhancement has been already done in the field of ASR for all popular spoken language like English, French, Chinese, Japanese, and Mandarin etc. ASR systems are there and further evolving is going on continuously. Currently many research works are going on over Indian languages like Hindi, Bengali, Kannada, Telugu, Marathi, Punjabi, Gujarati etc. Indian language like Odia, is still less advanced due to absence of computational linguistic resources. ASR system for Odia language has been found inefficient even though it is spoken by approximate 33 million of people in India. Yet, a few research work has been found for Odia language. So the non-availability of advanced ASR software for Odia language and regional sensation makes curiosity for adding more research effort towards it. In this paper, we proposed a system for recognizing continuous voiced Odia numerals using support vector machines. The system implements by considering voiced mobile numbers spoken in Odia language. First the continuous voiced numerals are preprocessed and segmented into isolated numerals. Then different feature extractions methods are applied like: MFCC, LPC and PLP. These features are inputted to multi-class SVM for recognition of numerals. The input voiced numeral signal contains many different features which is non-linear in nature can’t be classified easily by SVM. So, various kernel mapping functions such as: polynomial, sigmoid, RBF and wavelet are used to map from non-linear input space to linear feature space [8]. The efficiency of the system is computed using the above mapping functions along with different multi-class SVM classifier. The next part of the paper is framed as follows. Section-2 describes the related work over word and digit A
———————————————— Prithviraj Mohanty ,
Department of CS&IT, ITER, S’O’A (Deemed to be) University, Bhubaneswar, India.E-mail: [email protected]
Dr. Ajit Kumar Nayak
2755
recognition for different languages. Section-3 outlines the proposed model along with fundamental of SVM classifier. The experimental result with comparison is presented in section-4. Finally section-5 accomplishes the paper and suggests the future directions.
2
RELATED
WORK
Continuous voiced numeral recognition is treated as a designing technique for a voiced dialer system. The system is usually significant for substantially defied (blind people) or aged people for having a telephonic exchange without physically dialing the numbers. This is also helpful for the illiterate people those who can speak the numerals but can’t recognize them accurately. A number of research work have been proposed to recognize numerals for different languages. The exploration work related to isolated word recognition and digit/numeral recognition for different spoken languages with different parametric representation of the speech along with various methods for classification are main focus for our discussion. Isolated word and digit recognition for various language with different techniques along with their performances has been presented in [9]. Odia word recognition system based on HMM model used for the visually diminished students in school and public education was proposed in [11]. S. Mohanty et.al developed a model where speech recognition and speaker verification has been achieved by HMM and SVM respectively [12]. Isolated voiced Odia digit recognition with implementation particulars using HTK tool is presented in [13]. Pandit et.al developed an ASR system which uses dynamic time warping method for recognizing Gujarati digits [14]. A survey which presents different methods and approach for spoken English digit recognition has been proposed in [15]. Ali et.al proposed a model for Urdu digit recognition using three classification models such as: SVM, Random Forest (RF) and Linear Discriminant Analysis (LDA).The experimental outcomes obtained by them suggests that SVM provides better performance related to other two classifiers [16].Biometric classification using some voiced keywords as the input for Brazilian Portuguese language has been proposed in [17].SVM with kernel mapping functions like RBF and linear functions are used in their experiment for speaker identification. Using MFCC as the parameter technique and SVM as classifier an independent Malayalam digit recognition has been proposed in [18].From the experimental results, it has been shown that the average recognition accuracy of the system is 97.6%. Hedge et.al developed an isolated word recognition model for Kannada language [19]. The system which was implemented using SVM as classifier combined with MFCC as feature extraction, noise reduction method and end point detection for voices produced good accuracy rate for input words. Isolated English digit recognition using ANN as classifier has been proposed in [20]. The model was evaluated by considering a set of 63 feature vectors for each input signal obtained from the combination of different feature extraction techniques. They tested the model over 280 samples and obtained an accuracy of 85%. In [35], data classification using some heuristic methods has been proposed. A novel method known as Diminishing Learning (DL) has been suggested in [8] which is used to reduce the number of support vector points without negotiating the classification accuracy. The system has been evaluated for digit recognition with PLP and MFCC as parameter extraction with different approach of SVM
classifications. A continuous speech recognition with SVM which takes decision at frame level and a token passing method which is considered for finding the sequence of recognized words, has been proposed in [21]. Mittal et.al proposed a multiclass SVM for recognition of spoken Hindi digits. They used MFCC, LPC and mix of both for feature extraction and different kernel mapping functions of SVM for classification. The system has been experimented with different approaches (one vs. all and ten one vs. all) for SVM classification with variation of frames for a signal. The performance comparison of various feature extraction technique along with other recognition technique has been reported in [22]. A new technique where wavelet analysis and SVM is utilized for speaker verification has been proposed by Returi et.al [23]. Filter banks present in wavelet has been used for extracting the features which consequently distinct the normal and abnormal input voices. Furthermore SVM approach was used to segregate the particular speaker signal from multiple dialogs. The results obtained was found to be 95% accuracy considering appropriate classification. Whispered recognition using SVM and HMM approach has been proposed in [24]. The experimental outcomes obtained by the authors suggest that, for speaker independent (SI) HMM provides better result while for speaker dependent (SD) SVM was found to be superior. A hybrid technique which uses both HMM and SVM can be considered to provide an average accuracy for SI and as well as SD environment.
3
PROPOSED
MULTI-CLASS
SVM
BASED
CONTINUOUS
VOICED
ODIA
NUMERALS
RECOGNITION
SYSTEM
3.1 Frame-work for MSVM-CVONR
The proposed model for continuous voiced Odia numerals recognition using multi-class SVM (MSVM-CVONR) is represented in Fig.1.Two phases: training phase and testing phase are considered for developing the proposed model. Training phase comprises pre-processing and end point detection, framing, windowing, feature extraction using PLP/LPC/MFCC technique and evolving multi class SVM. In this phase the recorded continuous utterances of numerals are first preprocessed (noise and silence removal) and divided into individual signals for numerals that is present in the utterance. Then the individual voices for the numerals are
2756
further divided in to sequence of frames which are being overlapped. The entire frames should be quantized by using a hamming or windowing function. Several acoustical coefficient parameters are obtained by considering individual frames. From many feature extraction methods, three popular feature extraction techniques: PLP, LPC and MFCC are considered for our proposed work [25]. Each numeral of continuous voiced Odia numerals has its special features in amplitude, energy, pitch and spectrum. Using signal processing technique, we can manipulate these feature parameters to ultimately, find out the required different voiced numerals. In the testing phase, first the untrained continuous voiced signals are pre-processed and end point detection was done in order to get the individual signal for isolated numerals present in the utterances. Then framing, windowing function is to be applied to the isolated numerals. In the next step, parameters are extracted from each framed signal and considered as the input to the multi-class SVM classifier to detect the particular numeral.
3.2 Preprocessing and End-point Detection
Generally in voiced signal low frequency formants have higher amplitude than high frequency formants. A pre-emphasis technique for high frequency is required in order to balance the amplitude for all formants. This can be achieved by cleaning the voiced signal with the 1st order finite impulse response (FIR) filter, who’s mapping method is defined in Z-domain as [26]: H (z) =1-0.95*Z-1 The end-point detection method can be utilized to find the starting and ending point of each spoken numerals present in the recorded continuous voiced numerals. It is applied to find the region where actual speech is present and also used to eliminate the silent and noise area of the inputted signal. Mostly two end point algorithms are used such as: short time energy which uses the energy level of the featured signal and zero crossing rate which usages the number of zero crossings for each signal frame [27].
3.3 Feature Extraction
The technique used for pull out the parameters from the input speech wave form at a reduced data rate for further processing and exploration is known as feature extraction. These features are very essential for speech recognition. This is generally named as the front end part of speech or voice processing [28]. It transforms the treated speech signal to a brief but logical illustration that is more discriminative and consistent than the genuine signal. In speech recognition the front end comprises the feature extraction process while the back end uses the pattern matching or speaker modelling technique. Therefore, acceptable recognition of speech is more dependent on the quality of the features already extracted. Currently for automatic speaker recognition (ASR) systems, the idea for parametric representation of wave forms should be more reliable and with slight alternation of the features the speech signal portions remains the same. Feature extraction technique involves with more than one dimensional feature parameters for each speech signal. An extensive range of choices are there for parametric representation of the wave form such as: MFCC, LPC, PLP, Linear Prediction Cepstral Coefficients (LPCC), Line Spectral Frequencies (LSF) and Discrete Wavelet Transform (DWT). In our proposed work, we consider the MFCC, LPC and PLP as the feature extraction technique.
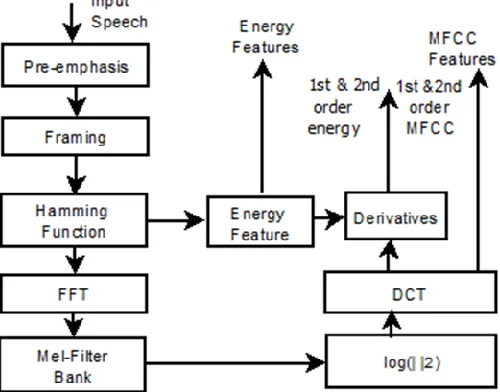
Mel-Frequency Cepstral Coefficient:The utmost leading and prominent method used for extraction of spectral features is Mel-Frequency Cepstral Coefficients (MFCC). It extracts parameters from the speech just like the way humans are listening the speech and at the same time it deemphasizes other vital data. A linear frequency < 1000Hz and logarithm spacing>1000Hz can be found in the Mel scale. A reference point can be set by considering a pitch of 1000Hz with audible threshold as 40dB. Using a filter bank signals can be disintegrated. Also, MFCC provides a discrete cosine transform (DCT) which is a real logarithm of short-term energy being reflected on the Mel frequency scale [4]. MFCC technique have been applied for a wide range of signal analysis task and considered to be performing well compared to other feature extraction methods. For each input frame of a signal, it evaluates the cepstral coefficient, delta cepstral energy and power spectrum deviation. For individualframe of a signal, MFCC computes first 12 coefficients along with a null coefficient, 13 delta coefficients ( obtained using 1st order derivative of initial 13 coefficients) and 13 acceleration coefficients (obtained using 2nd order derivative of initial 13
Fig. 2. Block diagram for MFCC feature extraction
coefficients) [10]. So, all together 39 features are extracted for each frame of the input speech wave form. Fig. 2 depicts the block diagram for MFCC feature extraction method. Linear Predictive Coefficient: LPC is one of the most powerful speech analysis techniques which replicates the human vocal tract and has gained popularity as a formant estimation technique. It computes the power spectrum of the signal and generally used for low bit rate order. The least square error method is used for generating the parameters. Using this technique, the speech sample is guessed as a linear grouping of its previous samples. LPC coefficient describes the formant that is frequencies where the resonant peaks present. Using this method, the position of the formants of a signal are computed considering the linear predictive coefficients over a framed window. From the resulting linear predicting filter, it also finds the peaks of the spectrum. With slight variation of LPC, other features that can be deduced such as: linear predication cepstral coefficients (LPCC), log area ratio (LAR), reflection coefficients (RC), line spectral frequencies (LSF) and Arcus Sine Coefficients (ARCSIN) [25]. Fig. 3 represents the block diagram for LPC feature extraction technique.
2757
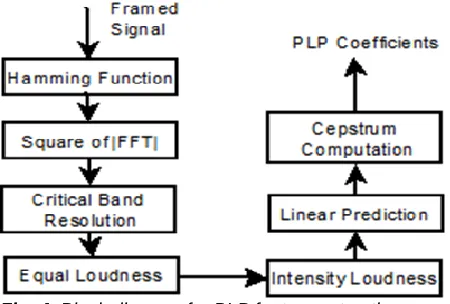
The PLP model was first developed by Hemansky. Using the concept of psychophysics of hearing, PLP method for human speech is considered. It also discards the unnecessary coefficients should be transferred to match with human auditory system. PLP approximate three main accepts such as: the critical band resolution, the equal loudness and the intensity loudness [25]. Fig.4 depicts the steps for PLP coefficient computation. For our experiment altogether 18 cepstral coefficients are extracted from each framed signal. 3.4 Multi-class SVM Classifier
Support vector machines are reasonably a new form of machine learning technique applied for classification,
Fig. 3. Block diagram for LPC feature extraction
Fig. 4. Block diagram for PLP feature extraction
regression, outlier detection and clustering. However, it is mostly used in classification problems. For 2-dimesinal feature space, it is to create decision boundary that can separate two class labels. But for m-dimensional feature space, SVM can create a hyperplane which is used to classify different class labels. In such type of scenario, SVM discovers the hyperplane which enhances the margin and simultaneously reduces the misclassification rate. The perfect approach to distinct 2 groups of data is, by considering a straight line having single dimension, uniform plane having 2 dimensions or an N-dimensional hyperplane. However, there are some circumstances where a nonlinear section can discrete the groups more competently. SVM knobs this by considering kernel functions intended to map the input space into another space where a hyperplane cannot be utilized for the separation. That means a non-linear function is trained by using a linear learning machine in a higher dimensional feature space, at the same time the capability of the system has been controlled by a factor which is free from the dimensionality of the input feature space. The above technique
is known as kernel trick. Fig.5 depicts the mapping of non-linear space to non-linear higher order feature space.
The basic equation of an SVM classifier can be represented as:
Where zin is the test input vector, wo is a vector which is normal to hyperplane and used to separate the classes in the feature space. The feature mapping function φ () which may be linear or non-linear used to produce the feature space. The parameter bi is the bias term. The decision plane or
Fig. 5. Non-linear to Linear mapping using kernel mapping of SVM
hyperplane is determined by minimizing the misclassification and maximizing the boundary between two classes. The size of the decision boundary is .
Let < xi, yi > for i=1, 2, 3...n denote the training data set where yi is the targeted output for the training data xi. So the basic equation of SVM can be modified by applying constraints which maximize the margin and minimizes the misclassification is expressed as:
Subject to yi ( (xi) + bi) ≥ 1 − , ≥ 0, for all i
Where P is the penalty parameter and is the slack variable. This parameter P is used to balance the complexity of the decision plane and the number of incorrectly classified testing point. Erroneous selection of the penalty parameter can create sever loss in the performance. Using cross validation and exponential growing sequence of P, the parameter values are computed. Using quadratic programming optimization, solution to the above equation can be represented as [29]:
Subject to 0 ≤ βi ≤ P, ∀i and
Where M is an nXn matrix. The (i, j) th element of M is given by:
A Langrage multiplier βi is used for individually training sample xi. Training samples whose βi values are non-zero are called support vector points. Now solving the above quadratic problem yields [30]:
2758
Where nsvp= number of support vector points and βsvp, ysvp and xsvp denote the parameters matching to each support vector point. Now, the SVM classifier for a test data can be expressed as:
Where Kl(xsv, ) = ) is a kernel function. It is observed from the above equation that, with increase in support vector points leads to increase in computational requirements and making the classifier slow for the nonlinear kernels. If we will reduce the support vector points, it also reduces the number of time kernel should be updated. Table- 1 represents some of the popular kernel functions used in SVM classifier. The kernel mapping function must satisfy the Karush-Kuhn-Tucker and Mercers condition [31] in order to interpret the input feature space. The solution for the objective function have the hyperplane that should lie in the mapped feature space.
For the multi-class classifier, the output is defined as Y ( ) = {1, 2,….m} where m is number of classes. Langrage multipliers ( ) and bias ( ) values are associated for each m class, where jε {1, 2 … nsvp}. The decision function can be represented as:
Where is evaluated for each class j ε {1, 2, ….. m} using Eq (7). Basically this is linking a hyperplane for individual class and assigning the test input to that class whose hyperplane is farthest away from it.
TABLE1
KERNEL MAPPING FUNCTIONS USED IN SVM
4
RESULT
ANALYSIS
AND
DISCUSSION
4.1 Data Set Preparation
For our proposed MSVM-CVONR system, the training corpus is being developed with 100 mobile numbers recorded by 20 different speakers (10 male and 10 female) whose age’s lies between 20 to 60 years. Speakers are chosen from different regions of Odisha. Each speaker is asked to speak 10 set of mobile numbers. So, a total of 10X20=200 sound files are recorded. Recording of the voiced mobile numbers are done using a room environment. Some of the utterances of the speaker are done using the audacity (a recording and editing software for speech) using a headset microphone with a
volume level as 1.0. Recordings of the mobile numbers in Odia language are prepared considering the sampling frequency of 16 KHz with 16 bits per sample. Also, some of the recordings are done using smart mobile phones using a sound recording application software. Each sound file containing the recordings of a single mobile number is preprocessed in order to remove the continuous silent period and noise. Also, the file is segmented into 10 portions, each portion is corresponding to an Odia numeral. For preprocessing and end point detection, each recorded sound file is passed with audacity software. As a total of 200X10=2000 isolated Odia numeral files are resulted with a labelling of each file corresponds to any individual numerals. For testing purpose, 5 speakers (3 male and 2 female) are considered. Each speaker has to record their utterances for 10 mobile numbers. Thus, a total of 5X10=50 wave files are created for testing. Preprocessing and segmentation is done using audacity software. After preprocessing and end point detection was done using audacity, each individual speech signals now segmented into a series of continuous frames of approximately 20 to 30ms. The method, framing is used to make the input signal to segmented quasi-stationary frames. Further, each individual frame may overlap to its previous frame. Also, framing is required in order to minimize the signal discontinuities at the start point and end point of each frame. Mostly, the Hamming window function is applied for windowing, since it produces the least amount of distortion. In the next step, the feature extraction techniques (PLP/LPC/MFCC) are applied for generating the equivalent parametric representation of the framed signal and considered as the input to the multiclass SVM for classification.
4.2 Odia Numerals Recognition
2759
Fig.6 Block diagram of Multi-class SVM classifier with SOFM array
Fig. 7. OVA learning mechanism used in SVM
classification. This technique transfers the feature vector sequence into trajectories in a square matrix of fixed dimension [33]. The feature map is trained using Kohonen’s self-organizing learning method. It has the useful property that, after training, similar input vectors whose Euclidian distance are close can be found as vertices in the feature map. The size of the SOFM may be 32X32, 24X24, 18X18 or any other combination. Using SOFM weights, transferred features for each numeral is obtained. SOFM matrix present in fig.6 contains some black dots and white dots which are denoted 1 and 0 respectively.
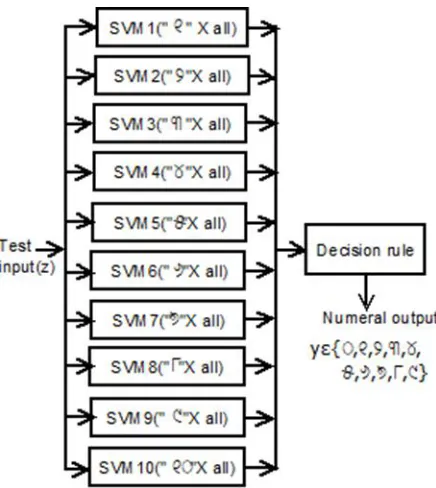
From the Eq.7, it can be concluded that computational complexity depends on the number of support vector points. Support vector points are obtained during the learning phase of SVM. The most popular technique used for multi-class SVM is One-Verses-All (OVA). This is being used for our proposed work for Odia numeral recognition. The OVA learning mechanism is depicted in fig.7. The whole data set is utilized for creating a decision boundary between classes and the support vector points obtained for each class. A multi-class parallel SVM classifier may be designed as shown in fig.8. In this approach, the decision boundary is always strict with respect to individual classes, hence each classifier may identify the input test data more precisely. As a result, overall recognition accuracy is improved. Table-2 represents the Odia numeral with equivalent words, words in Roman and English language, Odia symbol and International Phonetic Alphabet
(IPA).
TABLE2
ODIA NUMERALS WITH EQUIVALENT WORDS, WORDS IN ROMAN AND
2760 Fig. 8. Parallel SVM classifier using OVA
The confusion matrix for MSVM-CVON classifier using wavelet kernel (a=10) for MFCC feature inputs with SOFM size 24x24 with OVA for a Odia voiced mobile number is represented in Table-3 . This matrix represents the number of instances each numeral is correctly classified and also the number of times these are misclassified. Ten utterances for same mobile number is considered for recognition. From the table it has been seen that when the numeral is chhaa (Six) being considered for 10 times , it has been correctly classified to 8 times and misclassified for 2 times. Similar for other numerals like naa (Nine) the correct classification and misclassification are 7 and 3 respectively.
4.3 Performance Comparison of Odia numeral recognition using different Classifiers
In this section, the performance of MSVM-CVON for recognition of Odia numerals using two different classification scheme such as: One-Verses-All (OVA) and Half–Verses-Half (HVH) [34] are evaluated and results are compared. The architecture for OVA and HVH are represented in Fig.8 and Fig.9 respectively.
TABLE3
CONFUSION MATRIX FOR MSVM-CVON WITH CLASSIFICATION ORDER OF THE VOICED MOBILE NUMBER ―୮୨୪୯୫୬୭୧୨୦‖
Fig. 9. HVH SVM classifier architecture
2761
classifiers required for m number of numerical will be m-1 and maximum number of binary classifiers required to classify any test input is (m/2)-1. For our case, since the number of numerals is 10, hence total number of binary classes and maximum number of binary classes required to test an input will be 9 and 4 respectively. The implementation has been
done using Python. The recognition rate for two different classifiers: OVA and HVH with different SOFM size and different feature extraction technique along with various kernel mapping functions is represented in table-4 and table-5 respectively.
TABLE4
AVERAGE RECOGNITION RATE (%) OF PROPOSED MSVM-CVON CONSIDERING DIFFERENT SOFM SIZE WITH OVA CLASSIFIER
SOFM size
Kernel Polynomial Sigmoid RBF Wavelet
Feature Extraction Technique
ARR #SVP ARR #SVP ARR #SVP ARR #SVP
18x18 PLP LPC MFCC 85.25 89.5 90.25 870 876 908 83.75 88.75 89 743 745 880 85.5 89.5 91 840 810 814 87.5 90.5 92 840 770 785 24x24 PLP
LPC MFCC 86.25 91.5 92.25 890 880 920 87.75 93.75 94.5 710 675 840 86.5 91.5 96 820 760 780 90.5 95 96.5 800 720 750 32x32 PLP
LPC MFCC 86 90.5 92.25 880 786 926 87.75 92.7 92 770 725 863 86.5 90.75 96 821 788 805 90.5 92.7 93.5 810 712 770 TABLE5
AVERAGE RECOGNITION RATE (%) OF PROPOSED MSVM-CVON CONSIDERING DIFFERENT SOFM SIZE WITH HVH CLASSIFIER
SOFM size
Kernel Polynomial Sigmoid RBF Wavelet
Feature Extraction Technique
ARR #SVP ARR #SVP ARR #SVP ARR #SVP
18x18 PLP LPC MFCC 83.25 86.5 90.2 834 887 911 82.55 87.5 88.3 783 795 940 84.75 88.5 91.5 845 830 845 88.5 91.5 92 845 795 815 24x24 PLP
LPC MFCC 84.5 91.5 92.25 856 893 930 87.75 93.5 94.25 754 770 850 86.5 90.45 95.5 830 765 787 90 95.25 95.75 820 725 784 32x32 PLP
LPC MFCC 85 91.5 92.2 895 810 946 86.5 90.7 91.5 787 745 890 85.5 91.75 96.3 825 890 855 88.5 91.7 93 825 812 790
2762 Fig. 10. Comparison of ARR of OVA and HVH with various
kernel mapping functions (Considering SOFM size as24x24 with MFCC as feature extraction technique)
Fig. 11 Comparison of ARR of OVA and HVH with different feature extraction techniques (Considering SOFM size as24x24 with wavelet as kernel mapping function)
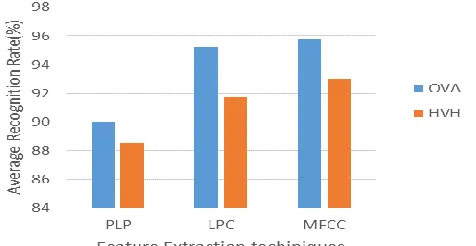
a) It may be perceived from table 4 and 5 that, OVA multi-class classifier has better average recognition rate compared to HVH classifier considering SOFM size of 24x24 with various kernel mapping functions.
b) Also it may be detected from the table 4 and 5 that, both the multi-class classifier performs well considering SOFM size of 24x24 with MFCC as feature extraction method and wavelet as kernel mapping function.
c) It may be noticed that MFCC feature extraction technique is better compared to other two feature extraction methods used. The number of SVPs is more in case of MFCC and varies a little compared with other methods. Also use of wavelet kernel mapping function for multi-class SVM classifier is observed to be better compared to other kernel mapping functions.
d) In fig. 10, it may be noticed that the average recognition rate of OVA and HVH matches for polynomial and sigmoid kernel mapping functions but OVA performs better for RBF and wavelet functions, fixing the SOFM size as 24x24 and MFCC as feature extraction technique.
e) Considering SOFM size as 24x24 and wavelet as kernel mapping function, it may noticed from fig. 11 that, OVA has better recognition rate with different feature extraction techniques.
f) Finally, the best recognition rate obtained by OVA and HVH (considering SOFM size of 24x24, wavelet as kernel mapping function and MFCC as feature extraction technique) is compared with our previous work of continuous Odia voiced
recognition using N-gram model [10] and depicted in fig. 12. It is observed that, OVA and HVH classifiers has better average recognition rate compared to our previous work which is implemented using Hidden Markov Model (HMM) with trigram language model approach.
Fig. 12. Comparison of ARR of OVA and HVH (Considering best values obtained for MSVM-CVONR with SOFM size as 24x24, wavelet kernel function and MFCC as feature extraction technique) with Continuous Voiced Odia Digit Recognition(CVODR –implemented using HMM with trigram approach)
4
CONCLUSION
Speech signals for Indian language always contains complex features and also sensitive for varying ascents, so more and more prominence must be needed in order to construct the desired ASR systems. In this work, we have demonstrated the usage of multi-class SVM classifier for recognition of continuous voiced Odia numerals. We have considered PLP, LPC and MFCC as the parameter extraction technique for the input voiced numerals with different kernel mapping functions for SVM classifier. Concurrently the experimentation has been carried out by considering different SOFM array sizes. The experimental results reveals that, OVA SVM classifier has better recognition rate as compared to HVH SVM classifier. Further, by analyzing the reported results, wavelet based kernel mapping multi-class OVA SVM classifier with SOFM
array size 24x24 has attained better accuracy in respect to various kernel mapping functions
inclusive off other SOFM array sizes. We except these outcomes will encourage for further exploration on Odia ASR. In future, the use of other parameter extraction methods along with SVM-HMM hybrid model, can be considered for Odia numeral recognition. Further experiment might be conducted considering different frame sizes for the inputted voiced signals. We suggest for more robust classifier which can aid for achieving better performance. In addition to the above, the work can be extended for using deep learning model, which may achieve higher performance on larger data set.
REFERENCES
[1] R. Rabiner and B. H. Juang, ―Fundamentals of Speech Recognition,‖
Prentice-Hall International, New Jersey, 1993
[2] G. Chen, C. Parada, and G. Heigold, ―Small-footprint Keyword
2763
[3] P. Mohanty and A. K. Nayak, "Design of an Odia Voice Dialer
System," 2019 5th National language (5th NLC-2019) IOSR at Ravenshaw University, Cuttack, Odisha, 04-06 February 2019.
[4] J.H. Martin and D.Jurafsky, ―Speech and language processing: An
Introduction to natural language processing, computational linguistics, and speech recognition,‖ Pearson / Prentice Hall Upper Saddle River, 2009.
[5] Y. Bengio ―Neural Network for Speech and Sequence Recognition‖, 1996, London: International Thomson Computer Press.
[6] E.Trentin, M. Gori ― A survey of hybrid ANN/HMM models for
Automatic Speech Recognition‖, Neurocomputing, 2001, 37(1-4), pp-91-126.
[7] A. Osowska and S. Osowski, ―Voice Command Recognition Using
Statistical Signal Processing and SVM,‖ in International Work-Conference on Artificial Neural Networks, Springer, 2019, pp.65-73
[8] J. Manikandan and B. Venkataramani, ― Study and Evaluation of a
Multi-class SVM classifier using diminishing learning rate,‖ Neurocomputing (Elsevier), 2010, Vol-73, pp. 1676–1685. [9] P. Prajapati and M. Patel, ―A Survey on Isolated Word and
Digit Recognition using Different Techniques,‖ International Journal of Computer Applications (IJCA), 2017, Vol-161, Issue-3 pp. 6–15.
[10]P. Mohanty and A. K Nayak ―N-Gram Language Model based Continuous Voiced Odia Digit Recognition‖, International Journal of Recent Technology and Engineering (IJRTE), 2019, Vol.8, Issue-2, pp-4565-4574. [11]S .Mohanty and B. K Swain, ―Markov Model Based Oriya
Isolated
Speech -An Emerging Solution for Visually Impaired Students in School and Public Examination,‖ International Journal of Computer & Communication Technology (IJCCT) 2010, Vol-2, Issue-2 pp. 1–5.
[12]S. Mohanty and B. K Swain, ―Speaker Identification using SVM during Oriya Speech Recognition,‖ International Journal Image, Graphics and Signal Processing, 2015, Vol-7, Issue-10 pp. 28–36.
[13]P. Mohanty and A. K. Nayak, ―Isolated Odia Digit Recognition Using HTK: An Implementation View,‖ 2nd International Conference on Data Science and Business Analytics (ICDSBA) . 2018, pp. 30–35.
[14]P. Purnima and B. Shardav, ―Automatic Speech Recognition of
Gujarati Digits Using Dynamic Time Warping,‖ International Journal of Engineering and Innovative Technology (IJEIT), 2014, Vol-3, pp. 69–73.
[15]V. Trivedi , ―A Survey On English Digit Speech Recognition
Using HMM,‖ International Journal of Science and Research (IJSR), 2013, Vol-2, Issue-3 pp. 247–253. [16]H. Ali, A. Jianwei and K. Iqbal ‖Automatic speech
recognition of Urdu digits with optimal classification approach‖, International Journal of Computer Applications, 2015, Vol-118, No-9, pp.1–5.
[17]F. G. Barbosa and W. L. S. Silva, ―Support vector machines, Mel
Frequency Cepstral Coefficients and the Discrete Cosine Transform applied on voice based biometric authentication,‖ SAI Intelligent Systems Conference (IntelliSys), London, 2015, pp. 1032–1039.
[18]C. Kurian, Firoz Shah. A and K. Balakrishnan, ―Isolated Malayalam digit recognition using Support Vector Machines,‖ International Conference on Communication, Control and Computing Technologies (ICCCCT), 2010, pp. 692–695.
[19]S. Hegde, K.K Achary and S. Shetty, ―Isolated Word Recognition for Kannada Language Using Support Vector Machine,‖ Communications in Computer and Information Science, 2012, Vol-292, pp. 262–269.
[20]B. P. Das and R. Parekh, ― Recognition of Isolated words using features based on LPC, MFCC, ZCR and STE with Neural Network Classifiers,‖ International Journal of Modern Engineering Research (IJMER), 2012, Vol-3, Issue-3, pp. 854–858.
[21]T. Mittal and R. K. Sharma, ―Multiclass SVM based Spoken Hindi numerals recognition,‖ The International Arab Journal of Information Technology, 2015, Vol-12, Issue-6A, pp. 666–671.
[22]D. Gupta, P. Bansal and K. Choudhary, ―The State of the Art of Feature Extraction Techniques in Speech Recognition,‖ Speech and Language Processing for Human- Machine Communications, 2018, Vol-664, pp. 195–207.
[23]K.D Returi, VM Mohan and Y. Radhika ―A Novel Approach for Speaker Recognition by Using Wavelet Analysis and Support Vector Machines‖, in Proceedings of the Second International Conference on Computer and Communication Technologies, Springer, New Delhi,2016, pp. 163-174.
[24]J. Galić, B. Popović and D.Š Pavlović, ―Whispered Speech Recognition using Hidden Markov Models and Support Vector Machines‖ Acta Politechnica Hungarica, 2018. Vol.-15 No-.5, pp-11-29.
[25]N. Dave, ―Feature extraction methods LPC, PLP and MFCC in speech recognition‖, 2013. International journal for advance research in engineering and technology, 1(6), pp.1-4.
[26]C. Bechetti, and L. Ricotti. "Speech recognition theory and C++ implementation." John WILEY&Sons, Ltd, 1999, pp: 125-137.
[27]D. B Hanchate, M. Nalawade, M. Pawar, V Pophale, P.K Maurya,‖ Vocal digit recognition using artificial neural network‖. 2nd International Conference on Computer Engineering and Technology 2010, Apr 16, Vol. 6, pp.88-91.
[28]C. Cornaz, U. Hunkeler, V. Velisavljevic, ―An Automatic Speaker
Recognition System.‖ Switzerland: Lausanne; 2003.
Retrieved from:
http://read.pudn.com/downloads60/sourcecode/multimedi a/audio/209082/asr_project.pdf
[29]Simon Haykin, ―Neural Networks, Second Edition‖, Prentice-hall of India, 2003
[30]Edwin K.P. Chong and S.H Zak, ‖An introduction to optimization‖,
John Wiley & Sons, 2013, Vol.76.
2764
[32]M.T. Hagan, H.B. Demuth and M. Beale, ―Neural network design‖, PWS Publishing Co. 1997.
[33]Z. Huang and A. Kuh, ―A combined self-organizing feature map and multilayer perception for isolated word recognition‖, IEEE Transaction on Signal processing, 1992, Vol.40 (11), pp-2651-2657.
[34]Hansheng Lei and Venu Gobindaraju, ―Half-against-half multi-class support vector machines, Springer Book Series, Lecture Notes in Computer Science, 2005, pp. 156-164.
[35]N. Panda and S.K Majhi, ―How Effective is Slap Swarm Algorithm in Data Classification‖, 1st