INCMARFI: MINING MAXIMAL
REGULAR FREQUENT ITEMSETS IN
INCREMENTAL DATABASES
G. VIJAY KUMAR
Computer Science and Engineering Department, Acharya Nagarjuna University, Guntur, Andhra Pradesh 522510, India
[email protected] http://<webaddress> V. VALLI KUMARI
Department of CS & SE, AU College of Engineering, Visakhapatnam, Andhra Pradesh 530003, India
[email protected] http://<webaddress> Abstract :
In incremental databases, new transactions will add continuously to the old transactions. Maximal frequent patterns are one of the condensed representations of frequent patterns. Recently, regular pattern mining along with frequent patterns playing an important role in data mining research. Several algorithms have been proposed so far to mine maximal frequent patterns on various domains. There is no suitable algorithm to mine maximal regular frequent (MRF) itemsets in incremental databases using transaction_ids. So, in this paper we are proposing a new algorithm called IncMaRFI to mine MRF itesmsets in incremental databases using common items from a set of transaction_id pairs. Our algorithm extracts all the latest MRF itemset(s) at a time with in a single scan. Our experiment results show the out performance of our algorithm.
Keywords: Frequent patterns; Regular patterns; Maximal patterns; Transaction_ids; Incremental databases. 1. Introduction
Incremental mining is one of the interesting areas in the real world applications. Since there is a rapid change in the field of information systems, transactional database are being updated continuously in several applications like stock market, web administration, super market, network monitoring etc. In order to get all maximal regular frequent itemsets, the algorithm has to be run whenever the database changes because some of the patterns which are not regular-frequent in old database may become regular-frequent in updated database. To discover maximal regular-frequent patterns from scratch every time is ineffective in data mining process. This leads to the study of incremental mining algorithm in finding maximal regular-frequent patterns. When ever new data added to the old database, the IncMaRFI algorithm minimizes the computational and I/O cost by discovering recent maximal regular-frequent itemsets using IncMaRFI header table.
The maximal regular-frequent patterns change whenever the database is updated. For decision making, users may be interested on obtaining the latest maximal regular-frequent patterns from the updated database. Therefore, it has been an important issue to find various efficient ways to find latest maximal regular-frequent patterns whenever the transactions are being updated to the database. Currently there are a few incremental mining algorithms that have been proposed to find regular-frequent patterns either in FP-tree based or in vertical format based. Tanbeer et al., [1] proposed IncRP-tree which is FP-tree based to find only regular patterns. Vijay kumar et al., [2] proposed IncVDRP algorithm based on vertical format which is more efficient than IncRP-tree to find regular patterns and later they extended to find regular-frequent patterns [3] in incremental databases. So far there is no suitable algorithm that finds maximal regular-frequent patterns in incremental transactional databases. Instead of using Apriori based, FP-tree based or vertical format based, we are using common itemsets from transaction pairs [4]. So in this paper we are introducing a new algorithm called IncMaRFI that obtains recent maximal regular-frequent patterns in incremental databases using transaction-ids.
2. Related Work
Apriori was the first algorithm to find frequent itemsets introduced by Agrawal et al., [5] [6] satisfies the minimum support threshold to generate strong association rules from the obtained frequent patterns. It is a level wise approach to generate frequent patterns. The major drawback of Apriori algorithm is it requires k number of database scans to generate k-itemset which is expensive. Later Han et al., [7] in 2000 introduced a highly compact tree structure called FP-tree and FP-growth algorithm to mine frequent patterns in support descending order with only two database scans which is more efficient than apriori like algorithms. Frequent pattern mining in incremental transactional databases have been studied widely over the last decade in data mining research and is based on support threshold. In 2008 the concept of regular pattern mining was introduced which is some what related to periodic patterns [8] [9] but they differ with the type of data considered, time-series data or sequence data. Recently, Tanbeer et al., [10] introduced the problem of mining regular patterns in transactional databases and then extended to incremental transactional databases [1] with a highly compact tree structure called IncRT-tree and a pattern growth approach based on the occurrence behaviour of a pattern. In the year 1998, Maximal Frequent Itemset (MFI) was first introduced. Bayardo et al., proposed MaxMiner Algorithm [11] which uses a breadth-first traversal of the search space, database scans will reduce by employing a look-ahead to prune the branches of the tree i.e., it involves in superset pruning. It also employs item re-ordering heuristic to increase the effectiveness of superset-freqency pruning. This algorithm uses the original horizontal database so it can perform the same number of passes over a database as Apriori does. DepthProject Algorithm [12] was introduced by Agrawal et al., uses depth first search of a lexicographic tree and also used counting method based on transaction projections along with its branches to find long itemsets. This projection is equivalent to the horizontal version of the tidsets at a given node in the search tree. It also uses the look-ahead pruning method with item reordering and returns a superset of the maximal frequent itemset and also require post-pruning to eliminate non-maximal patterns.
Mafia [13] is introduced by Burdick et al., which uses three pruning strategies to remove non-maximal sets to obtain maximal frequent patterns. The first pruning is look-ahead pruning strategy which is used like in MaxMiner. Second is to check if a new set is subsumed by an existing maximal set and the last technique checks if t(X) t(Y). This algorithm uses vertical bit-vector data format, compression and projection of bitmaps to improve the performance. Mafia mines a superset of MFI and requires a post-pruning step to eliminate non-maximal patterns just like in DepthProject algorithm. Another algorithm called GenMax [14] [15] was introduced by Gouda and Zaki which is used backtracking search for enumerating all maximal patterns. This algorithm uses number of optimizations to quickly prune away a large portion of the subset search space. In GenMax the data representation is vertical format representation and also uses a progressive focussing technique to remove non-maximal patterns and uses diffset propogation to perform fast frequency counting. Schmidt and Kramer [16] prosed an incremental mining algorithm to find maximal frequent patterns online where instances observed only once with a tree structure called Augmented itemset tree (AIST).
Table 1. Transactional Database
Tid Transaction 1 a, d, e, c
2 d, e, f, a, c 3 a, e, c 4 d, e, c 5 e, c, a, f
6 b, f
7 d, c, e, b 8 b, c, d, e 9 a, d, c, b 3. Problem Definition
Here, we describe the concepts of maximalregular frequent pattern mining and define the basic definitions of the problem to obtain the recent maximal regularfrequent patterns in incremental transaction databases.
Let I = {i1, i2, . . . , in} be a set of items. A set X = {ij, . . . , ik} I, where j≤k and j, k [1, n] is called a
pattern or an itemest. A transaction t = (tid, Y) is a couple where tid is a transaction-id and Y is a pattern. Let size (t) be the size of t, i.e., the number of items in Y. A transaction database DB over I is a set of transactions T
= {t1, . . . ,tm}, m = | DB | is the size of DB, i.e., the total number of transactions in DB. If XY, which means
that t contains X or X occurs in t and denoted as tjX, j[1, m]. Therefore, TX = {tjX, . . . ,tkX}, j≤k and j, k[1, m]
is the set of all transactions where pattern X occurs in DB. 3.1. Definition 1 (Frequent Pattern X)
The total number of transactions in a DB that contains pattern X is called the support of X i.e., Sup(X). Hence
Sup(X) = | TX |, where | TX | is the size of TX. The pattern X is said to be frequent if its support is greater than or equal to user given minimum support threshold i.e., Sup(X) ≥minsup().
3.2. Definition 2 (Regular of Frequent Pattern X)
Let tjX and tXj+1, j[1, (m - 1)] be two successive transactions where frequent pattern X appears. The variation
between these two successive transactions can be defined as a period of X, say pX (i.e., pX = tXj+1 – tXj, j[1, (m -
1)]). For ease, to calculate the period of a pattern, we consider the first transaction in the DB as null i.e., tf = 0
and the last transaction is the mth transaction i.e., tl = tm. Let for a TX, PX be the set of all periods of X i.e., PX =
{p1X, . . . , prX}, where r is the total number of periods in PX. Then the regularity of a frequent pattern X can be
denoted as Reg(X) = max{p1X, . . . ,prX}. A frequent pattern X is said to be regular frequent if its regularity is less
than or equal to user given maximum regularity threshold i.e., .
3.3. Definition 3 (Regularity of a Frequent Pattern X in Incremental Databases)
Let db+ denotes the set of newly added transactions to the database DB. The updated database is denoted as
UDB (DBdbi+), i be the number of newly added transactions to the DB. Whenever the database is updated
with i transactions the first transaction-id i.e., null transaction tf = 0 will be replace to tf = tf + i (tf = 0 + i) at the
front end of the transactional database and tl = tl + i at the rare end of DB. For example, in db+ (Table 3) two
transactions 10 and 11 are added to DB. So i value is 2, the null transaction for the updated UDB is tf = 2 and the
last transaction is tl= 11. After replacing the values of first transaction (tf) and last transaction(tl) the process
continues to find support and PX for every TX to obtain latest regular frequent patterns from the UDB. 3.4. Definition 4 (Maximal Regular- frequent pattern(s) in incremental databases)
An itemset X is a maximal regular-frequent itemset if it is regular-frequent and should not be a subset to any other regular-frequent itemset in the same database.
4. Mining Maximal Regular Frequent Patterns
In this section we are going to describe the mining process of maximal regular-frequent patterns in incremental transactional databases using transaction_ids requires only one database scan. Finding maximal regular frequent patterns at once reduces lot of space and time. Let us consider Table 1 is our example database taken from [3]. In the process we first formulates all the possible combinations of transaction pairs to extract the common items from the pair of transaction_ids i.e., {(1, 2), (1, 3), . . . ,(1, n), (2, 3), (2, 4), . . . , (2, n), (3, 4), . . , (n - 2, n), (n - 1, n)}. If there are n number of transactions in a given database, the number of possible combinations would be
common itemset and their lengths. Let us consider the user given support threshold is 2 and user given regularity threshold is 3.
Table 2. IncMaRFI Table – Common itemsets with lengths from transaction pairs
Transaction Pairs
Common Itemset
Itemset Length
Transaction Pairs
Common Itemset
Itemset Length
1, 2 a, c, d, e 4 3, 7 c, e 2
1, 3 a, c, e 3 3, 8 c, e 2
1, 4 c, d, e 3 3, 9 a, c 2
1, 5 a, c, e 3 4, 5 c, e 2
1, 6 nil 0 4, 6 nil 0
1, 7 c, d, e 3 4, 7 c, d, e 3
1, 8 c, d, e 3 4, 8 c, d, e 3
1, 9 a, c, d 3 4, 9 c, d 2
2, 3 a, c, e 3 5, 6 f 1
2, 4 c, d, e 3 5, 7 c, e 2
2, 5 a, c, e, f 4 5, 8 c, e 2
2, 6 f 1 5, 9 a, c 2
2, 7 c, d, e 3 6, 7 b 1
2, 8 c, d, e 3 6, 8 b 1
2, 9 a, c, d 3 6, 9 b 1
3, 4 e, c 2 7, 8 b, c, d, e 4
3, 5 a, c, e 3 7, 9 b, c, d 3
3, 6 nil 0 8, 9 b, c, d 3
We first consider the first largest itemset from the pairs of transactions. If there are any other itemsets with the same largest value, we compare the chosen itemset with the other itemset(s) of same length. If we find any other itemset which is exactly equal, our algorithm calculates support and regularity. From the example database, the first largest common itemset from Table 2 is (a, c, d, e) which is frequent but not regular. The second largest common itemset is (a, c, e, f) which is also frequent and not regular. The third and final largest common itemset is (b, c, d, e), is also frequent and not regular.
From Table 2 all length-4 itemsets were calculated and none of them are regular-frequent. So now we consider length-3 itemsets to check any of these itemsets will become maximal regular-frequent itemset or not. Itemset (a, c, e) appears in four transaction pairs (1, 3), (1, 5), (2, 3) and (3, 5). After eliminating the duplication the itemset (a, c, e) appears in four transactions (1, 2, 3, 5) in Table 1. Since it founds in four transactions, its
Table 3. Incremental Database db+
Tid Transaction 10 a, d, c, b
11 d, e, f, c, b
Table 4. Updated Database UDB (DB db+)
Tid Transaction
1 a, d, e, c
2 d, e, f, a, c
3 a, e, c
4 d, e, c
5 e, c, a, f
6 b, f
7 d, c, e, b
8 b, c, d, e
9 a, d, c, b
10 a, d, c, b
Table 5. IncMaRFI Table – Common itemsets with lengths from transaction pairs
Transaction Pairs
Common Itemset
Itemset Length
Transaction Pairs
Common Itemset
Itemset Length
3, 4 c, e 2 5, 9 a, c 2
3, 5 a, c, e 3 5, 10 a, c 2
3, 6 nil 0 5, 11 c, e 2
3, 7 c, e 2 6, 7 b 1
3, 8 c, e 2 6, 8 b 1
3, 9 a, c 2 6, 9 b 1
3, 10 a, c 2 6, 10 b 1
3, 11 c, e 2 6, 11 b, f 2
4, 5 c, e 2 7, 8 b, c, d, e 4
4, 6 nil 0 7, 9 b, c, d 3
4, 7 c, d, e 3 7, 10 b, c, d 3
4, 8 c, d, e 3 7, 11 b, c, d, e 4
4, 9 c, d 2 8, 9 b, c, d 3
4, 10 c, d 2 8, 10 b, c, d 3
4, 11 c, d, e 3 8, 11 b, c, d, e 4
5, 6 F 1 9, 10 a, b, c, d 4
5, 7 c, e 2 9, 11 b, c, d 3
5, 8 c, e 2 10, 11 b, c, d 3
support is 4 and the user given support threshold is 2, so it is a frequent itemset. Now we check whether this frequent itemset is regular or not by calculating its regularity and compare with the user given regularity threshold. To find out the regularity of this itemset, as in definition 2 in section 3 let the first transaction be a null itemset i.e., tf = 0 and the last transaction is tl = 9. As this itemset appears in (1, 2, 3, 5) transactions, periods
are calculated by subtracting two successive transaction_ids i.e., (1 - tf )1, (2 – 1)1, (3 – 2)1, (5 – 3)2, (tl – 5)4.
So the regularity is the maximum of (1, 1, 1, 2, 4) i.e., 4 but the user given regularity threshold is 3, so it is not a regular itemset. The next itemset is (c, d, e) appears in eight transaction pairs (1, 4), (1, 7), (1, 8), (2, 4), (2, 7), (2, 8), (4, 7) and (4, 8). After eliminating duplication, it appears in five transactions (1, 2, 4, 7, 8). According to our definitions its support is 5 and regularity is 3 satisfies the user given support and regularity thresholds. Therefore itemset (c, d, e) is regular frequent which is the maximum size of our running example. There are another two length-3 itemsets (a, c, d) and (b, c, d) in Table 2, but these itemsets doesn’t satisfy the regularity threshold. So the maximum regular frequent itemset is (c, d, e). The subsets of (c, d, e) are also regular frequent because our algorithm satisfy the down-ward closure property.
Whenever the database is updated our IncMaRFI-algorithm updates the value of i i.e., number of transactions added to the old transactions and changes the first transaction_id and the last transaction_id. Let Table 3 is the increment database (db+) to the transactional database DB containing two transactions 10 and 11. From these added transactions some of the itemsets may turn into regular frequent itemsets which are infrequent and irregular in the previous mining process. By changing the values of first transaction and last transaction we can obtain latest regular frequent patterns from the incremental transactional databases. Our IncMaRFI-header table maintains all of the initial transaction-ids and last transaction-ids whenever the database is updated. The mining process repeats the procedure recursively whenever the database is incremented to obtain recent maximal regular frequent patterns. Therefore the decision makers can make changes according to the obtained recent maximal patterns in finding good results.
5. Experiment Results
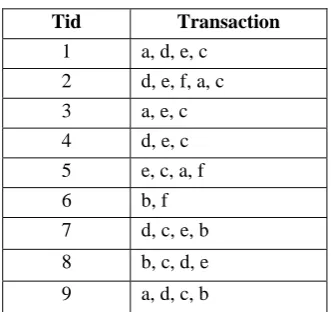
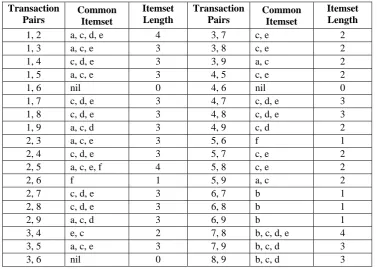
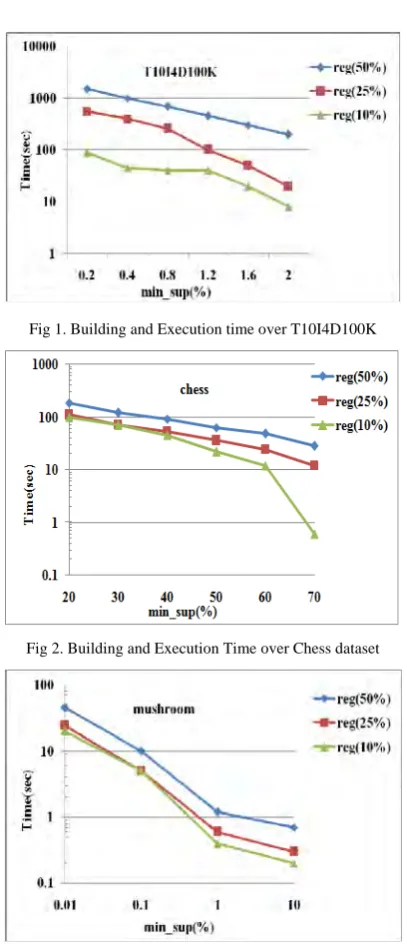
In this section we are going to show our experimental results over various datasets T1014D100K, chess and mushroom which are commonly used in frequent pattern mining experiments and other interesting measures. These datasets are developed at IBM Almaden Quest research group and obtained from http://cvs.buu.ac.th/mining/Datasets/synthesis_data/ and UCI Machine Learning Repository (University of California-Irvine, CA). All experiments are done in NetBeans 7.3 on windows XP contains 2.66 GHz with 2 GB of main memory.
Fig 1. Building and Execution time over T10I4D100K
Fig 2. Building and Execution Time over Chess dataset
Fig 3. Building and Execution time over Mushroom dataset
and Chess data set contains 28056 transactions, 34 items and 7 is the maximum length as well as average length. As the average length decreases, the building transaction pairs and retrieving common itemsets from transaction pairs from the dataset also decreases. Figure 2 shows the building and execution time over different min_sup and max-reg values. Mushroom dataset contains 8124 transactions, 120 items and 23 as the average length. Figure 3 shows the building and execution time over different min_sup and max-reg values on mushroom dataset.
References
[1] S. K. Tanbeer et al., Mining Regular Patterns in Incremental Transactional Databases. 12th International Asia-Pacific web conference,
(2010) IEEE, DOI 10.1109/APWeb.2010.68, pp. 375-377.
[2] G. Vijay Kumar et al., A Vertical Format to Mine Regular Patterns using Vertical Format in Incremental Transactional Databases. Journal of Computing, Vol 3, issue 11, pp. 91 – 94, 2011.
[3] G. Vijay Kumar et al., Incremental Mining for Regular Frequent Patterns in Vertical Format. International Journal of Engineering and Technology. Vol 5, No 2, pp. 1506 – 1511, 2013.
[4] G. Vijay Kumar et al., MaRFI: Maximal Regular Frequent Itemset Mining using a pair of Transaction-ids. International Journal of Computer Science and Engineering Technology, Vol 4, No 7, pp. 1057 – 1064, 2013.
[5] R. Agrawal, T. Imielinski, A. Swamy. Mining association rules between sets of items in large databases. In ACM SIGMOD Int. Conference on Management of Data, pp. 207 – 216 (1993).
[6] R. Agrawal, R. Srikanth. Fast algorithms for mining association rules. In Proceedings (1994) International conference on very large databases. (VLDB’94). pp. 487-499.
[8] M. G. Elfeky, W. G. Aref, A. K. Elmagarmid. Periodicity Detection in Time Series Databases. IEEE Transactions on Knowledge and Data Engineering 17(7), pp. 875-887 (2005).
[9] S. K. Tanbeer et al. Discovering Periodic-Frequent Patterns in Transactional Databases. Springer PAKDD, pp. 242-253 (2009). [10] S. K. Tanbeer et al., Mining Regular Patterns in Transactional Databases, IEICE, Trans. On information and systems, E91-D, 11, pp.
2568 – 2577, 2008.
[11] Bayardo, R.J., Efficiently mining long patterns from databases, In proceeding of the ACM SIGMOD international conference on management of data, pp. 85-93, 1998
[12] Agarwal, R. C., Aggarwal, C. C., & Prasad, V. V. V. “ Depth first generation of long patterns,” In Proceedings of the 6th ACM SIGKDD international conference on knowledge discovery and data mining , 2000,pp. 108–118
[13] Burdick, D., Calimlim, M., & Gehrke, J, “Mafia: A maximal frequent itemset algorithm for transactional databases” In Proceedings of 17th international conference on data engineering ,2001,pp. 443–452
[14] Gouda, K., & Zaki, M. J, “Efficiently mining maximal frequent itemsets”, In Proceedings of 1st IEEE international conference on data mining, 2001, pp. 163–170
[15] Gouda, K., & Zaki, M. J, “GenMax: An Efficient Algorithm for Mining Maximal Frequent Itemsets”, Data Mining and Knowledge Discovery, Springer Science, 11, pp. 1-20, 2005.
[16] J Schmidt and S Kramer, The Augmented Itemset Tree: A Data Structure for Online Maximal Frequent Pattern Mining. In: T. Elomaa, J. Hollmen, and H. Mannila (Eds.) DS 2011. LNCS, vol 6926, pp 277-291, Springer, Heidelberg 2011.
[17] Sunil Joshi, Dr. R. C. Jain: “A Dynamic Approach for Frequent Pattern Mining Using Transposition of Database” IEEE International Conference on Communication software and Networks (ICCSN 2010) 2010.