Volume 3, Special Issue 1, ICSTSD 2016
Analysis & Optimization of Association Rule Mining
with Multiple Constraints
Sonali P. Mahindre
Department of Computer Science & Engineering PRMIT&R,
Badnera. (MS)India
Dr.Gajendra R.Bamnote
2Department of Computer Science & Engineering PRMIT&R,
Badnera. (MS)India [email protected]
Abstract— Association rule mining is a data mining process that discovers associations among items in a transactional database. Some association rules consider only items enumerated in transactions. Such rules are called as positive association rules. Negative association rules also consider the exact items, but in addition consider negated items.(Negative association rules are applied in market-basket analysis to identify products that contrast with each other or products that complement each other. Association rules mining (ARM) is an important task in the field of data mining, mining frequent item sets is a key step of many algorithms for ARM. In a very large dataset, rules generated may be too much, but some of them are useless to the users, to improve the effectiveness and efficiency of mining tasks, because of constraint-based mining users are able to concentrate on mining their interested association rules instead of the complete set of association rules.
Keywords—mining; positive association rules; negative association rules; ARM; dataset.
I. INTRODUCTION
The mining association rule is a data mining task that aims to discover relationships among items in a transactional database[1]. Mining association rules is a crucial task. Past dealings information will be analyzed to get client buying behaviors such the standard of business call will be improved. The association rules describe the associations between things within the massive information of client transactions. The powerful administration of business is altogether subject to the kind of its choice making. It is along these lines vital to break down past exchange information to find client buying practices and developed the nature of business choice. It deals with the market basket analysis to find frequent patterns and generate association rules of the form A⇒B, which can be used to predict that “If a customer buys item set A, he/she will most likely buy item set B as well”, where A and B are frequent item sets in a transaction database and A ∩ B=∅. The rule of the form A⇒B is considered a strong rule if its support (s) and confidence (c) prove minimum support (mins) and minimum confidence (minc) thresholds; these are called positive association rules (PARs)[3]. So this algorithm produces some redundant rule along with the interesting rule. This drawback can be overcome with the help of min-max algorithm. Since most of the data mining approaches uses the greedy algorithm instead of min-max algorithm. Min-max
algorithm is somewhat best as compare to the greedy algorithm because it performs a global search and copes better with the attribute interaction. In min-max algorithm population evolution is simulated. Min-max algorithm is a biological technique which uses chromosome as an element on which solutions (individuals) are manipulated. Generally association rule focuses on finding positive relationship between the data set. Negative association rule is also important in analysis of intelligent data.
II. LITRATURE REVIEW
In this section discuss some related work to negative and positive association rule mining.
Reference [1] In this paper authors have proposed Mining Optimized Association Rules Algorithm (MOAR) which maintains two populations: the internal population, and a Pareto−store. This algorithm incorporates partial ordering in the search mechanism for rules. The algorithm iteratively evaluates a solution by first decoding the bit string into a rule which is compared to the data in the database. For all records that cover a given consequent the values are compared against the consequent to calculate the supports of the antecedent and the consequent. After the dataset scan, the measures of strength used as the objectives are calculated for each rule[16]. This algorithm adopts the Pareto dominance approach pro-posed in for maintaining multiple stable niches. This ensures that the individuals in the Pareto store are uniformly distributed near the Pareto−optimal front. To determine the dominance of an individual all individuals in the internal population and the Pareto store are evaluated.
Volume 3, Special Issue 1, ICSTSD 2016 The negative association rule mining can be useful to a
domain that has too many types of factors. Negative association rules can help users quickly decide to which ones are important instead of checking too many rules. Algorithms for discovering negative association rules are not widely discussed. The discovery procedure of these algorithms can be decomposed into three stages: (1) find a set of positive rules; (2) generate negative rules depended on existing positive rules and domain knowledge; (3) prune the redundant rules[5].
The work presented by [2] explained a new algorithm called U2P-Miner for mining frequent U2 patterns from univariate uncertain data, where each and every attribute in a transaction is associated with a quantitative interval and a probability density function. This algorithm is implemented in two phases. First, they construct a U2P-tree that compresses the information in the target database. Then author use the U2P-tree to discover frequent U2 patterns. Potential frequent U2 patterns are derived by joining base intervals and verified by traversing the U2P-tree. They also develop two techniques to speed up the mining task. Since the proposed method is based on a tree-traversing strategy, it is both efficient and scalable.
As the research in data mining goes further Li Guang-yuan, et.al claimed an algorithm for mining association rules with multiple constraints,[3] the proposed algorithm simultaneously copes with two different kinds of constraints, it consists of three phases, first, the frequent 1 –item set are generated, second, use the properties of the given constraints to prune search space or save constraint checking in the conditional databases. Third, for each item set possible to satisfy the constraint, they generate its conditional database and perform the three phases in the conditional database recursively. Experimental results shows that the this method outperform the revised FP-growth algorithm. The problem of discovering all frequent item sets that satisfy constraints is a difficult.
The aim of this study is to create a new model for mining interesting negative and positive association rules out of a transactional data set. The presented model is integration within two algorithms, the Positive Negative Association Rule (PNAR) algorithm and the Interesting Multiple Level Minimum Support (IMLMS) algorithm, to present a new approach (PNAR IMLMS) for mining all negative and positive association rules from the interesting frequent and infrequent item sets mined by the IMLMS model. The practical results show that the PNARIMLMS model provides significantly better results than the previous model. One demerit of this algorithm is negative rule extract from uninteresting pattern sets which is useless [4].
So the future research in related described the method is joined with the concept of hierarchical concept, data of the generalization sets processing, and also uses SOFM neural network generalization into the database after the transaction, by way of introducing an internal threshold so there is no need to set the minimum support threshold, to generate the local frequent item sets as global candidates item sets to generate global frequent item sets, So enhancing the efficiency of multi-level association rules and accuracy. And after
simulation the case shows that the method can not only efficient mining single-layer and cross-layer association rules, but also the association rules is new ,easy to understand and meaningful [5].
Gavin Shaw, Yue Xu, Shlomo Geva had explained two approaches which measure multi-level association rules to help evaluate their interestingness. These measures of differentiability and peculiarity can be used to help identify those rules from multi-level datasets that are potentially useful. Association rule mining is one technique that is widely used when querying databases, specially those that are transactional, in order to gain useful associations or correlations between sets of items. Much work has been done focusing on efficiency, effectiveness, flexibility and redundancy. There has also been a focus on the quality of rules from single level datasets with various interestingness measures proposed.
III. PROBLEM STATEMENT
The Knowledge Discovery in Databases (KDD) field is interested with the development Of methods and techniques for making sense of data. Association rule mining identifies collections of data attributes that are statistically related in the underlying data. An association rule is an expression of the form X=>Y where X and Y are disjoint sets of items. In a dataset D, consisting of data instances where each instance is a set of items, the rule X=>Y has support sup, equal to the percentage of the instances of D that have both X and Y.
The association rule mining suffered following problem.
1. Scanning and pruning problem of dataset
2. Generation of negative and positive rules.
3. Superiority measure problem.
4. Number of passes over the database.
5. Sampling problem of data set
Volume 3, Special Issue 1, ICSTSD 2016
IV. PROPOSED WORK
a) OVERVIEW : Validation of association rule mining is very important and critical phase of rule generation. The dependence of rule generation has two factors one is minimum support value and other is minimum confidence value. The process of validation satisfy the given condition and used for the process of rule generation[27]. The generated rules come along with some negative rule and some positive rule in form of rule set. Now the process of strong rule generation used various constraints function such as monotonic and non-monotonic function for range validation of association rule mining. Some authors also used some multi-level approach for generation of association rule mining. Some also used some optimization technique for strong rule generation. In this dissertation proposed a sine cosine multiple constraints based association rule mining. The sine and cosine function work in maximum and minimum range of value for the processing of given data. In the continuity of chapter discuss association rule mining, Apriori algorithm, sine and cosine function and proposed algorithm and proposed model.
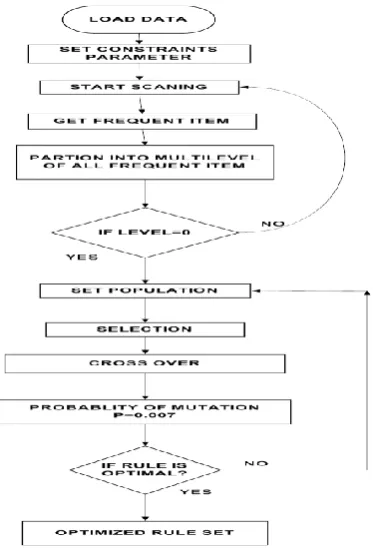
b) PROPOSED METHODOLOGY: In this section discuss proposed algorithm for optimization of association rule mining, the proposed algorithm solves the problem of negative rule generation and also optimized the process of rule generation. Negative association rule mining is a great challenge for large dataset[17]. In the generation of valid rules or method generate a series of negative rules, which generate rules which affect a performance of association rule mining. In the process of rule generation, many multiple objective association rule mining algorithms are proposed but all these are not solved. In this Paper we proposed MLMS-GA of association rule mining with min-max algorithm. In this algorithm we used MLMS for multi-level minimum support for constraints validation. The frequent data logically assigned 1 and infrequent data logically assigned 0 for MLMS process. The divided process reduces the uninteresting or unnecessary item in given database. The proposed algorithm MLMS-GA is a combination of MLMS and min-max algorithm along this used level weight for the separation of frequent and infrequent item. The weight value act as Support length key is a vector value given by the transaction data set. The support value passes as a vector for finding a near level between MLMS candidates key. After finding a MLMS candidate key the closest or nearest level divide into two levels, one level take a higher odder value and another level obtain infrequent minimum support value for rule generation process[33]. The process of selection of level also reduces the passes of data set. After finding a selected level of lower and higher of a given support value, compare the value of level weight vector. Here level length vector work as a fitness function for selection process of min-max algorithm [34]. Here we present steps for process of algorithm step by step and finally draw a flow chart of complete process.
Steps of algorithm (MLMS-GA)
1. Scanning of database used flowing steps
Some standard notation of pseudo code of algorithm such as D dataset, K level MLMS, Ls generation candidate
K = MLMS dataset (D)
n = Number of multiple level block For i = 1 to n loop
Scan_k (Ki ∈k) Li = gen__itemsets (ki)
For (i = 2; Lj i≠ φ, j = 1,2....,n; i++) Ci G = ∪j = 1,2,...nLij
End; For i = 1 to n scan_kmap (ki∈K)
For all items C ∈CG generate block (C, ki) End;
LG = {c ∈CG|}
2. Generate multiple support vector value for selection process for all transaction LG do
generate count table TC L1 =(frequent 1-itemsets); C2 =L1 ∞ L1;
L2 ={cEC2 | sup(c)≥MinSupNum}; For(k=3;Lk-1 ≠Ø ;k++)do begin For (j=k;j≤m;j++)do
Generate CIVijk-1; Ck=candidate_gen(Lk-1)
Lk ={cECk| sup(c)≥MinSupNum};\ End
3. Set of rule is generated Return L = Ư Lk;
Candidate_gen(frequent itemset Lk-1) a. for all(K-1)-itemsetlE Lk-1 do b. for all ijE Lk-1 do
c. //S is the result of the formula(2)
If for every r(1≤r≤k) such that S[r]≥k-1 then L1 = (frequent 1-itemsets);
C2 =L1 ∞ L1;
L2 = {cEC2 | sup(c)≥MinSupNum}; For (k=3;Lk-1 ≠Ø ;k++)do begin For (j=k;j≤m;j++)do
Generate CIVijk-1; Ck=candidate_gen(Lk-1) 4. Check MLMS value of table
5If rule is not MLMS go to selection process 6. Else optimized rule is generated.
7. Exit
a.) Data Encoding
The process of data in min-max algorithm needs some data encoding technique for representation of data. In this technique used binary encoding technique.
b.) Fitness function
The population selection of Min-max Algorithm is a design of Fitness Function:
Ai = {frequent item support}
Volume 3, Special Issue 1, ICSTSD 2016 The selection strategy based on the basis of individual fitness
and concentration pi is the probablity of selection of individual whose value is greater than one and m(s) is a those value whose fitness is less than one but near to the value of 1.The Min-max operators determine the search capability and convergence of the algorithm. Min-max operators hold the selection crossover and mutation on the population and generate the new population. In this algorithm it restore each chromosome in the population to the corresponding rule, and then calculate selection probability pi for each rule based on above formula[18]. In which single point are used. It divide multiple level domain of each attribute into a group and identify the cut point of each continuous attributes into one group .And the crossover done between the corresponding groups of two individuals by a certain rate. Any bit in the chromosomes is modified by a certain rate, that is, changing “0” to ”1” & ”1” to ”0”. Now we explain complete process of algorithm shows block diagram of proposed algorithm using min-max algorithm.
Fig 1: shows that proposed block model of algorithm.
V. RESULTANALYSIS
Fig 5.1: Shows that the comparative result for different methods and shows that our proposed method generated the no. of rule are less than other
methods.
Figure 5.2: Shows that the comparative result for different methods and shows that our proposed method generated the no. of rule are less than other
methods.
Figure 5.3: Shows that the comparative result for different methods and shows that our proposed method generated the no. of rule are less than other
Volume 3, Special Issue 1, ICSTSD 2016 References
[1].Xiaobing Liu , Kun Zhai, Witold Pedrycz “An improved association rules mining method” Expert Systems with Applications 2012, Pp 1362–1374.
[2]. Ying-Ho Liu “Mining frequent patterns from univariate uncertain data” Data & Knowledge Engineering, 2012. Pp 47-68.
[3].Li Guang-yuan, Cao Dan yang, Guo Jian-wei “Association Rules Mining with Multiple Constraints” Elsevier ltd. 2011, Pp 1678-1683.
[4].Idheb Mohamad Ali O. Swesi, Azuraliza Abu Bakar, Anis Suhailis Abdul Kadir “Mining Positive and Negative Association Rules from Interesting Frequent and Infrequent Item sets” IEEE 9th International Conference on Fuzzy Systems and Knowledge Discovery, 2012. Pp 650-655.
[5].Huang QingLan, Duan LongZhen “Multi-level association rule mining based on clustering partition” IEEE Third International Conference on Intelligent System Design and Engineering Applications, 2013. Pp 982-986.
[6].Vidhu Singhal, Gopal Pandey “A Web Based Recommendation Using Association Rule and Clustering” International Journal of Computer & Communication Engineering Research, 2013. Pp 1-5.
[7].Gavin Shaw, Yue Xu, Shlomo Geva “Interestingness Measures for Multi-Level Association Rules’ Proceedings of the 14th Australasian Document Computing Symposium, 2009. Pp 2-9. [8].Noha Negm , Passent Elkafrawy , Mohamed Amin, Abdel Badeeh
M. Salem “Investigate the Performance of Document Clustering Approach Based on Association Rules Mining” International Journal of Advanced Computer Science and Applications, vol-4, 2013. Pp 142-151.
[9].Huang QingLan, Duan LongZhen “Multi-level association rule mining based on clustering partition” Third International Conference on Intelligent System Design and Engineering Applications, IEEE 2013. Pp 982-985.
[10].Aritra Roy, Rajdeep Chatterjee “Introducing New Hybrid Rough Fuzzy Association Rule Mining Algorithm” Proc. of Int. Conf. on Recent Trends in Information, Telecommunication and Computing, ITC, 2014. Pp 167-175.
[11].Deepak A. Vidhate, Dr. Parag Kulkarni “improvement in association rule mining by multilevel relationship algorithm” International Journal of Research in Advent Technology, Vol-2, 2014. Pp 366-373.
[12].Yin-Fu Huang, San-Des Lin “Applying Multidimensional Association Rule Mining to Feedback-based Recommendation Systems” International Conference on Advances in Social Networks Analysis and Mining, 2011. Pp 412-417.
[13].XING Xue, CHEN Yao. WANG Yan-en “Study on Mining Theories of Association Rules and Its Application” IEEE, 2010. Pp 2-10.
[14].Yingqin Gu, Hongyan Liu, Jun He, Bo Hu and Xiaoyong Du “A Multi-relational Classification Algorithm based on Association Rules” IEEE, 2009. Pp 235-242.
[15].W. Li, J. Han, and J. Pei “CMAR: Accurate and efficient Classification Based on Multiple Class-Association Rules” Proceedings of the ICDM, IEEE Computer Society, San Jose California, 2001, Pp 369-376.
[16].X. Yin, and J. Han “CPAR: Classification based on Predictive Association Rules” Proceedings of the SDM, SIAM, Francisco California, 2003.
[17].Zhen Peng, Lifeng and Wu Xiaoju Wang “Research on Multi-Relational Classification Approaches” IEEE, 2009. Pp 3-9. [18]. He J, Liu HY, Du XY. “Mining of multi-relational association
rules” Journal of Software, 2007, Pp 2752-2765.
[19].Baralis, E., Cerquitelli, T, & Chiusano, S. “IMine: Index support for item set mining” IEEE Transactions on Knowledge and Data Engineering, 2009, Pp 493–506.
[20].Chen, L., & Wang, C. L. “Continuous sub-graph pattern search over certain and uncertain graph streams” IEEE Transactions on Knowledge and Data Engineering, 2010, Pp 1093–1109. [21].Chen, S. M., & Bai, S. M. “Using data mining techniques to
automatically construct concept maps for adaptive learning systems” Expert Systems with Applications, 2010, Pp 4496– 4503.
[22].Chu, C. J., Tseng, V. S., & Liang, T.” Efficient mining of temporal emerging itemsets from data streams” Expert Systems with Applications, 2009 Pp 885–893.
[23].Ding, J. F., & Yau, S. S. T. “TCOM, an innovative data structure for mining association rules among infrequent items” Computers and Mathematics with Applications, 2009, Pp 290–301.
[24].Du, Y. J., & Li, H. M. “Strategy for mining association rules for web pages based on formal concept analysis” Applied Soft Computing, 2010 Pp 772–783.
[25].Eichhorn, A., Girimonte, D., Klose, A., & Kruse, R. “Soft computing for automated surface quality analysis of exterior car body panels” Applied Soft Computing, 2005 Pp 301–313. [26].Gharib, T. F., Nassar, H., Taha, M., & Abraham, A. “An efficient
algorithm for incremental mining of temporal association rules” Data and Knowledge Engineering, 2005, Pp 800–815.
[27].Kuo, R. J., Chao, C. M., & Chiu, Y. T. “Application of particle swarm optimization to association rule mining” Applied Soft Computing, 2011 Pp 326–336.
[28].Lee, A. J. T., Wang, C. S., Weng, W. Y., Chen, Y. A., & Wu, H. W. “An efficient algorithm for mining closed inter-transaction item sets” Data and Knowledge Engineering, 2008, Pp 68–91. [29].C.K. Leung, D.A. Brajczuk “Efficient algorithms for mining
constrained frequent patterns from uncertain data” Proc. ACM SIGKDD Workshop on Knowledge Discovery from Uncertain Data, 2009, Pp 9–18.
[30].C.K. Leung, D.A. Brajczuk “Mining uncertain data for constrained frequent sets” Proc. International Database Engineering & Applications Symposium, 2009, Pp 109–120. [31].C.C. Aggarwal, Y. Li, J. Wang, J. Wang “Frequent pattern mining
with uncertain data” Proc. ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, 2009, Pp 29–37.
[32].S. Zhang, Q. Chen, Q. Yang “Editorial: acquiring knowledge from inconsistent data sources through weighting” Data & Knowledge Engineering, 2010. Pp 779–799.
[33].L.A. Abd-Elmegid, M.E. El-Sharkawi, L.M. El-Fangary, Y.K. Helmy “Vertical mining of frequent patterns from uncertain data” Computer and Information Science, 2010. Pp 171–179.