A Methodology for the Usage of Side Data in
Content Mining
Prof.Vishal Vitthal Bandgar Asst. Professor SVERI’s college of Engineering
(Polytechnic) Pandharpur, Solapur
Prof. Priyanka S. Muttur Asst. Professor Shri. Siddheshwar.Womens
.Polytechnic, Solapur
Prof.Amol Ulhas Kuntham Asst.Professor
V.V.P.Polytechnic, Solapur.
Prof.G.A.Fattepurkar Asst.Professor V.V.P.Polytechnic,
Solapur.
Abstract- Compelling In different text mining applications, side-information is accessible close-by the text records. Such side-information may be of distinctive sorts, case in point, report provenance information, the relationship in the record, client access conduct from web logs, or other non-textual properties which are embedded into the text document. Such qualities may contain a monster measure of information for clustering purposes. On the other hand, the relative targets of this side-information may be hard to gage, particularly precisely when a portion of the information is uproarious. In such cases, it can be dangerous to unite side-information into the mining logic, in light of the way that it can either redesign the method for the representation for the mining process, or can add unsettling influence to the system. Subsequently, we oblige a principled strategy to perform the mining system, to build the slant from utilizing this side information. In this paper, we mastermind a processing which joins secured disseminating with probabilistic models so as to make a persuading social occasion method. We then show to broaden the methodology to the approach issue. We show test happens on different true blue information sets to design the focal purposes of utilizing such a method.
Keywords - Clustering, Data mining, Text mining,
1. INTRODUCTION
THE issue of text clustering emerges in the context of numerous application spaces, for example, the web, social networks, and other digital accumulations. The quickly expanding measures of text information in the context of these expansive online accumulations have prompted an enthusiasm toward making adaptable and compelling mining algorithms. A gigantic measure of work has been done in late years on the issue of clustering in text accumulations [5], [11], [27], [30], [37] in the database and information recovery groups. On the other hand, this work is principally intended for the issue of immaculate text clustering, without different sorts of traits. In numerous application areas, a huge measure of side- information is additionally related alongside the reports. This is on account of text reports regularly happen in the con- text of a mixed bag of uses in which there may be a lot of different sorts of database traits or meta information which may be helpful to the clustering procedure.
A few cases of such side-information are as per the following:
In an application in which we track client access conduct of web records, the client access conduct may
be caught as web logs. For each one archive, the meta-information may relate to the searching conduct of the diverse clients. Such logs can be utilized to improve the nature of the min- ing process in a manner which is more serious to the client, furthermore application-touchy. This is on account of the logs can regularly get unpretentious connections in con- tent, which can't be grabbed by the crude text alone.
Many text records contain joins among them, which can likewise be dealt with as traits. Such connections contain a great deal of helpful information for mining pur- postures. As in the past case, such qualities might regularly give experiences about the connections among reports in a manner which may not be effortlessly accessible from crude substance.
diverse groups with side properties. These aides in abstracting out the clamor in the participation conduct of distinctive traits. The apportioning methodology is particularly intended to be extremely productive for vast information sets. This can be essential in situations in which the information sets are extensive. We will introduce exploratory results on various genuine information sets, and outline the adequacy and proficiency of the methodology. While our essential objective in this paper is to study the clustering issue, we note that such an approach can likewise be reached out on a fundamental level to other information mining issues in which helper information is accessible with text. Such situations are extremely regular in a wide mixture of information areas. Thusly, we will likewise propose a strategy in this paper to develop the methodology to the issue classification. We will demonstrate that the augmentation of the methodology to the arrangement issue gives predominant results as a result of the joining of side information. Our objective is to demonstrate that the points of interest of utilizing side-information augment past an immaculate clustering assignment, and can give preferences to a more extensive mixed bag of issue situations.
This paper is sorted out as takes after. The rest of this segment will exhibit the related deal with the subject. In the following area, we will formalize the issue of text clustering with side information. We will likewise introduce a calculation for the clustering methodology. We will demonstrate to expand these strategies to the characterization issue in Area 3. In Area 4, we will display the trial results. Segment 5 contains the conclusions and outline.
2. LITERATURE REVIEW
The issue of text-clustering has been contemplated broadly by the database group [18], [25], [34]. The significant center of this work has been on versatile clustering of multi- dimensional information of distinctive sorts [18], [19], [25], [34]. A general overview of clustering algorithms may be found in [21]. The issue of clustering has likewise been studied broadly in the context of text-information. An overview of text clustering strategies may be found in [3]. A standout amongst the most well known systems for text-clustering is the dissipate assemble procedure [11], which utilizes a blend of agglomerative and partitioned clustering. Other related techniques for text-clustering which utilize comparable systems are talked about as a part of [27], [29]. Co-clustering techniques for text information are proposed in [12], [13]. A Desire Expansion (EM) technique for text clustering has been proposed in [22]..
Matrix factorization strategies for text clustering are ace postured in [32]. This system chooses words from the docu- ment focused around their significance to the clustering process, and uses an iterative EM technique with a specific end goal to refine the clusteres. A nearly related territory is that of point modeling, occasion track- ing, and text-order [6], [9], [15], [16]. In this context, a technique for subject driven clustering for text information has been proposed in [35]. Systems for text clustering in the con- text of
catchphrase extraction are examined in [17]. A number of commonsense apparatuses for text clustering may be found in [23]. A relative investigation of distinctive clustering routines may be found in [30].
The issue of text clustering has additionally been contemplated in context of adaptability in [5], [20], [37]. Be that as it may, these systems are intended for the instance of immaculate text information, and don't work for cases in which the text-information is consolidated with different manifestations of information. Some restricted work has been carried out on clustering text in the context of system based linkage information [1], [2], [8], [10], [24], [31], [33], [36], however this work is not pertinent to the instance of general side- information characteristics. In this paper, we will give a first approach to utilizing different sorts of properties as a part of conjunction with text clustering. We will demonstrate the preferences of utilizing such a methodology over immaculate text-based clustering. Such a methodology is particularly valuable, when the assistant information is exceptionally useful, and gives powerful direction in making more lucid groups. We will likewise amplify the technique to the issue of text characterization, which has been mulled over broadly in the writing. Definite reviews on text order may be found in [4], [28].
3. PROBLEM ANALYSIS
In this segment, we will examine a methodology for clustering text information with side information. We accept that we have a corpus S of text reports. The aggregate number of records is N, and they are signified by T1 ... TN . It is accepted that the situated of unique words in the whole corpus S is indicated by W. Connected with each one archive Ti, we have a set of side properties Xi. Each one set of side traits Xi has d dimensions, which are meant by (xi1 ... xid). We allude to such qualities as helper properties. For simplicity in documentation and investigation, we accept that each one side-property xid is parallel, however both numerical and absolute properties can easily be changed over to this arrangement in a genuinely clear manner. This is on the grounds that the diverse estimations of the straight out credit can be thought to be independent paired traits, though numerical information can be discredited to double values with the utilization of property reaches. A few illustrations of such side-characteristics are as per the following:
In a web log investigation application, we accept that xir relates to the 0-1 variable, which shows whether the ith archive has been gotten to by the rth client. This information can be utilized as a part of request to group the pages in a site in a more informative path than a methods which is built simply in light of the substance of the reports. As in the past case, the quantity of pages in a site may be vast, however the quantity of reports got to by a specific client may be moderately little.
clustering methodology. Since hyperlink diagrams are vast and meager, it takes after that the quantity of such assistant variables are high, however just a little part of them tackle the estimation of 1.
In a record application with related GPS or provenance information, the conceivable properties may be drawn on countless. Such characteristics will commonly fulfill the sparsity property.
As noted in the cases above, such assistant properties are very scanty in a lot of people genuine applications. This can be a test from a productivity point of view, unless the sparsity is painstakingly considered amid the clustering methodology. Accordingly, our methods will be intended to record for such sparsity. Notwithstanding, it is conceivable to effectively plan our methodology for non-meager qualities, by treating the characteristic values in a more symmetric manner.
4. METHODOLOGY
We note that our system is not confined to parallel assistant qualities, yet can likewise be connected to characteristics of different sorts. At the point when the helper traits are of different sorts (quantitative or clear cut), they can be changed over to parallel characteristics with the utilization of a basic transformation process. Case in point, numerical information can be discretized into double qualities. Indeed for this situation, the inferred twofold traits are truly inadequate particularly when the numerical reaches are discretized into countless. On account of downright information, we can characterize a parallel trait for every conceivable unmitigated quality. By and large, the num- ber of such values may be expansive. Accordingly, we will plan our procedures under the implied presumption that such characteristics are truly inadequate. The definition for the issue of clustering with side information is as per the following:
Text Clustering with Side Information: Given a corpus S of reports meant by T1 ... TN, and a set of assistant vari- ables Xi connected with report Ti, focus a clustering of the archives into k groups which are meant by C1 ... Ck, in view of both the text content and the assistant variables. We will utilize the helper information as a part of request to expert vide extra experiences, which can enhance the nature of clustering. By and large, such assistant information may be boisterous, and might not have valuable information for the clus- tering procedure. Along these lines, we will plan our methodology with a specific end goal to amplify the reasonability between the text substance and the side-information, when this is identified. In cases, in which the text substance and side-information don't demonstrate lucid conduct for the clustering process, the impacts of those allotments of the side-information are minimized.
4.1 THE COATES ALGORITHM
In this segment, we will portray our calculation for text clus- tering with side-information. We allude to this calculation as COATES all through the paper, which relates to the way that it is a Content and Auxiliary trait based Text clustering calculation. We expect that a data to the algo- rithm is the quantity of groups k. As on account of all
text-clustering algorithms, it is accepted that stop-words have been evacuated, and stemming has been performed with a specific end goal to enhance the unfair force of the traits. The calculation obliges two stages:
INITIALIZATION: We utilize a lightweight introduction stage as a part of which a standard text clustering methodology is utilized without any side-information. For this pur- posture, we utilize the calculation portrayed as a part of [27]. The reason that this calculation is utilized, in light of the fact that it is a straightforward calculation which can rapidly and productively give a sensible beginning stage. The cen- troids and the parceling made by the groups structured in the first stage give a starting beginning stage to the second stage. We note that the first stage is focused around text just, and does not utilize the assistant information.
clusteres, we expect that every helper cycle has an earlier probability of task of archives to groups (focused around the execution of the calculation in this way), and a back capacity of task of records to groups with the utilization of assistant variables in that emphasis. We mean the former likelihood that the archive Ti has a place with the cluster Cj by P(ti∈ Cj). Once the unadulterated text clustering stage has been executed, the from the earlier group participation probabilities, capacities of the helper characteristics are produced with the utilization of the last substance based cycle from this stage. The apriori estimation of P(ti ∈ Cj) is just the portion of documents which have been appointed to the group Cj. So as to figure the back probabilities P(ti ∈ Cj|xi) of membership of a record toward the end of the assistant cycle, we utilize the helper traits Xi which are connected with Ti. Subsequently, we might want to register the restrictive likelihood P(ti ∈ Cj|xi). We will make the close estimation of considering just those assistant properties (for a particular report), which tackle the estimation of 1. Since we are focusing on scanty double information, the estimation of 1 for an property is a substantially more enlightening occasion than the default estimation of 0. Consequently, it suffices to condition just looking into the issue of characteristic qualities tackling the estimation of 1. For exam- ple, let us consider an application in which the assistant information compares to clients which are scanning spe- cific website pages. In such a case, the clustering conduct is impacted significantly all the more altogether by the situation when a client does scan a specific page, as opposed to one in which the client does not skim a specific page, in light of the fact that most pages will commonly not be skimmed by a specific client. This is for the most part the case crosswise over numerous inadequate information areas, for example, credits relating to connections, discretized numeric information, or clear cut information which is all the time of high cardinality, (for example, postal divisions).
Besides, so as to guarantee the strength of the methodology, we have to take out the uproarious qualities. This is particularly paramount, when the quantity of helper characteristics is extensive. Subsequently, toward the starting of every helper cycle, we register the gini-record of each one property focused around the clusteres made by the keep going substance based emphasis. This gini-record gives an evaluation of the oppressive force of each one credit concerning the clustering procedure. The gini-list is processed as follows. Let frj be the part of the records in the cluster is signified by Gr, and is characterized as takes after:
The estimations of Prj are characterized, so they aggregate to 1 over a specific property r and diverse groups j. We note that when all estimations of Prj tackle a comparative estimation of 1/k, then the trait qualities are equitably dispersed over the dif- ferent bunches. Such a quality is not exceptionally discriminative concerning the clustering procedure, and it ought not be utilized for clustering. While
the assistant traits may have an alternate clustering conduct than the textual qualities, it is likewise expected that useful helper characteristics are in any event to a degree identified with the clustering conduct of the textual properties. This is by and large valid for some applica- tions, for example, those in which assistant characteristics are characterized either by linkage-based examples or by client conduct. Then again, totally boisterous ascribes are unrealistic to have any relationship to the text content, and won't be exceptionally powerful for mining purposes. In this way, we would like the estimations of Prj to fluctuate over the distinctive groups. We allude to this variety as skew. The level of skew can be measured with the utilization of the gini-record. The gini-list of characteristic r is signified by Gr, and is characterized as takes after:
The estimation of Gr lies between 1/k and 1. The more discriminative the property, the higher the estimation of Gr. In every emphasis, we utilize just the assistant qualities for which the gini-file is over a specific edge γ . The estimation of γ is picked to be 1.5 standard deviations beneath the mean estimation of the gini-record in that specific emphasis. We note that since the groups may transform from one emphasis to the next, and the gini-list is characterized as for the dog rent groups, the estimations of the gini-record will likewise change over the diverse emphases. Consequently, distinctive assistant traits may be utilized over diverse cycles as a part of the clus- tering methodology, as the nature of the groups get to be more refined, and the relating discriminative power of helper qualities can likewise be registered all the more effectively. Let Ri be a set containing the lists of the characteristics in Xi which are viewed as discriminative for the cluster ing methodology, and for which the estimation of the relating quality is 1. For instance, let us consider an application in which we have 1000 diverse assistant properties. In the event that the measurement files of the properties in the vector Xi which tackle the estimation of 1 are 7, 120, 311, and 902 separately, at that point we have Ri = {7, 120, 311, 902}. Subsequently, as opposed to figuring P(ti ∈ Cj|xi), we will figure the restrictive likelihood of participation focused around a specific estimation of the set Ri. We characterize this amount as the trait subset based contingent likelihood of group enrollment.
Definition 1. The quality subset based contingent likelihood of cluster participation of the report Ti to the group Cj is characterized as the restrictive likelihood of enrollment of document Ti to cluster Cj built just in light of the set of characteristics Ri from Xi which tackle the estimation of 1. Cj (made in the last substance based cycle), for which the quality r takes on the esteem of 1. At that point, we compute the relative vicinity Prj of the quality r in group j as takes after:frj. The quality subset based contingent likelihood of document Ti to cluster Cj is meant by Ps(ti ∈ Cj|ri).
comparative estimation of 1/k, then the trait qualities are equally circulated over the different groups. Such a property is not exceptionally discriminative concerning the clustering procedure, and it ought not be utilized for clustering. While the helper characteristics may have an alternate clustering conduct than the textual properties, it is likewise expected that instructive assistant traits are at any rate to some degree identified with the clustering conduct of the textual qualities. This is for the most part valid for some applications, for example, those in which helper traits are characterized either by linkage-based examples or by client conduct. Then again, totally boisterous credits are unrealistic to have any relationship to the text content, and won't be exceptionally successful for mining purposes. In this manner, we would like the estimations of Prj to change over the diverse groups. We allude to this variety as skew. The level of skew can be measured with the utilization of the gini-list. The gini-record of characteristic r way. We note that these are the back probabilities of group participation after the assistant quality based itera- tion, given that specific sets of helper characteristic qualities are exhibited in the distinctive records. We will utilize these pos- terior probabilities to re-alter the cluster centroids amid the helper trait based emphases. The from the earlier probabilities of participation are appointed focused around the current substance based emphasis of the clustering, and are signified by Pa(ti ∈ Cj). The from the earlier and a-posteriori probabilities are connected as takes after: Ps(ti ∈ Cj|ri) = Pa(ri|ti ∈ Cj) • Pa(ti ∈ Cj)/Pa(ri). (3) The above equation takes after from the basic development of the representation for the contingent probabilities. We will likewise see that every declaration on the right-hand side can be assessed in an information driven way with the utilization of the restrictive assessments from the last emphasis. Particularly, the estimation of Pa(ti ∈ Cj) is just the part of the reports alloted to the cluster Cj in the last substance based (minor) emphasis.In request to assess back probabilities from Equation3, we likewise need to gauge Pa(ri) and Pa(ri|ti ∈Cj). Since Ri may contain numerous traits, this is essentially a joint likelihood, which is difficult to gauge precisely with a restricted measure of information. Hence, we make an innocent Bayes estimate so as to gauge the estimations of Pa(ri) and Pa(ri|ti ∈ Cj). This rough guess has been demonstrated to attain amazing results in a wide mixture of reasonable situations [14]. To make this rough guess, we accept that the distinctive properties of Ri are free of each other. At that point, we can estimated P(ri) as takes after:
Pa(Ri) = Pa╥ (xir = 1). (4) r∈ri
This estimation of Pa(xir = 1) is just the portion of the documents in which the estimation of the quality xir is one. This can be effortlessly evaluated from the fundamental report col- lection. Additionally, we utilize the autonomy presumption as a part of request to gauge the estimation of Pa(ri|ti ∈ Cj).
Pa(ri|ti ∈ Cj) = Pa╥(xir = 1|ti ∈ Cj). (5) r∈ri
The estimation of Pa(xir = 1|ti ∈ Cj) is the part of the doc- uments in cluster Cj in which the estimation of quality xir is one. This worth can be accessed from the last set of clusteres acquired from the substance based clustering stage. For each one cluster Cj, we focus the division of records for which the estimation of rth helper characteristic is 1. We note that the main distinction between the second definition and the first is the way that in the second case, we are registering the part of the reports in the cluster j for which the rth trait is 1. At that point, we can substitute the consequences of Equations 4 and 5 in Equation 3 with a specific end goal to acquire the accompanying:
We note that the estimations of Ps(ti ∈ Cj|ri) ought to entirety to 1 over the distinctive estimations of (cluster list) j . Nonetheless, this may not be the situation in practice, in light of the utilization of the inde- pendence rough guess while registering the probabilities for the diverse properties. Along these lines, we standardize the posteri- ori probabilities to Pn(ti ∈ Cj|ri), with the goal that they signify 1, as takes after: Keeping in mind the end goal to streamline the declaration further so as to make it more instinctive, we process the investment proportion I(r, j) as the declaration. This is the investment degree for the rth assistant ascribe in connection to the jth bunch Cj. We formally characterize the investment degree as takes after: Definition 2. The investment degree I(r, j) characterizes the significance of ascribe r regarding the jth group Cj This is characterized as the proportion of the likelihood of an archive fitting in with clus- ter Cj, when the rth assistant characteristic of the report is situated to 1, to the degree of the same likelihood unequivocally. Naturally, the degree shows the relative increment in like- lihood of a report having a place with a specific group (from the current set of groups) due to a specific helper characteristic worth. At the end of the day, we have:
I(r, j) = Pa(xir = 1|Ti ∈ Cj)
Pa(xir = 1) (7) An estimation of I(r, j), which is altogether more prominent than 1 indicates that the assistant property r is very identified with the current group Cj. The equal the initial investment estimation of I(r, j) is one, and it demonstrates that the assistant characteristic r is not exceptionally identified with the group Cj. We can further disentangle the interpretation for the restrictive likelihood in Mathematical statement 6 as takes after:
P (Ti ∈ Cj|ri) = P (Ti ∈ Cj) •╥ I(r, j). (8) r∈ri
We note that the estimations of Ps(ti ∈ Cj|ri) ought to aggregate to 1 over the diverse estimations of (group file) j . Then again, this may not be the situation in practice, in view of the utilization of the inde- pendence rough guess while figuring the probabilities for the distinctive traits. Thusly, we standardize the posteri- ori probabilities to Pn(ti∈Cj|ri), so they indicate 1, as takes after:
P (Ti ∈Cj|Ri) = Ps(Ti ∈Cj|Ri)
These standardized back probabilities are then utilized as a part of request to re-modify the centroids L1 ... Lk. Particularly, each one report Ti is relegated to the comparing centroid Lj with a prob- capacity relative to Pn(ti ∈ Cj|ri), and the text substance of the record Ti is added to the group centroid Lj of Cj with a scaling variable relative to Pn(ti ∈cj|ri). We note that such an emphasis regulates the text substance of the centroids on the premise of the helper information, which thusly influences the task of reports to centroids in the following substance based emphasis. Hence, this methodology iteratively tries to assemble an agreement between the text substance based and assistant characteristic based assignments of archives to bunches.
In the following substance based emphasis, we allocate the docu- ments to the changed group centroids focused around the cosine similitude of the archives to the bunch centroids [26]. Each one record is doled out to its closest bunch centroid focused around the cosine comparability. The allocated archives are then totaled keeping in mind the end goal to make another centroid meta- report which totals the recurrence of the words in the reports for that group. The minimum successive words in this bunch are then pruned away, in order to utilize a vector of just the most regular words in the group centroid with their relating frequencies. This new task of reports to bunches is again utilized for characterizing the from the earlier equations. A key issue for the calculation is the joining of probabilities for the assistant qualities in the following itera tion. A key issue for the calculation is the merging ofthe calculation towards an uniform arrangement. So as to com- pute joining, we expect that we have an identifier connected with each one bunch in the information. This identifier does not transform starting with one emphasis then onto the next for a specific centroid. Inside the tth real emphasis, we process the fol- lowing amounts for each one report for the two distinctive minor emphases:
First we process the group identifier to which the doc- ument Ti was alloted in the substance based venture of the tth real cycle. This is meant by qc(i, t).
we figure the bunch identifier to which the document Ti had the most noteworthy likelihood of task in the assistant quality set of the tth significant cycle. This is meant by qa(i, t). With a specific end goal to focus when the iterative procedure ought to ter- minate, we would like the reports to have assignments to comparable bunches in the (t − 1)th and tth steps toward the end of both the assistant trait and substance based steps. As such, we would like qc(i, t − 1), qa(i, t − 1) qc(i, t) furthermore qa(i, t) to be as comparative as could reasonably be expected. Consequently, we com- pute the quantity of reports for which every one of the four of these amounts are the same. As the calculation advances, the quantity of such records will at first expand quickly, and after that gradually level off. The calculation is expected to have ended, when the number of such records does not increment by more than 1% starting with one emphasis then onto the next. Right now, the calculation is accepted to have arrived at a certain level of security as far as its task conduct, and it can hence be ended. An essential point to be recollected is that the yield to the
calculation are both the vectors qc(•, t) and qa(•, t). While the clustering procedure is inalienably intended to merge to groups which utilize both substance and helper information, a percentage of the docu- ments can't be made to concur in the clustering conduct with the utilization of distinctive criteria. The normal assignments in qc(•, t) and qa(•, t) relate to the cases in which the substance based and helper assignments can be made to concur with a decently planned clustering methodology, and the distinctions in the two vectors relate to those doc- uments which demonstrate distinctive clustering conduct for the assistant and substance based information. Such reports are fascinating, in light of the fact that they give intensional comprehend ing of how some of the substance based information may be unique in relation to the helper information in the bunch ing procedure. The general clustering calculation is outlined in Fig. 1.
4.2 SMOOTHING ISSUES
An imperative smoothing issue emerges in methodology of evalu- ating the right hand side of Equation 6. Particularly, the
╥Pa (xir =1|ti ∈cj )
r∈ri Pa (xir =1) articulation indicated by may contain zero values for Pa(xir = 1|ti ∈ Cj). Indeed a solitary such zero worth could set the entire representation to zero. This will come about in an ineffectual clustering procedure. Keeping in mind the end goal to maintain a strategic distance from this issue, we utilize a smoothing parameter
ǫr for the rth aux- iliary property. Particularly, the articulation in Equation6. In this way, the comparing articulation is assessed by
╥ Pa (xir =1|ti ∈cj )+ǫr
r∈ri Pa (xir =1)+ǫr. The estimation of ǫr is altered to inside a little portion of Pa(xir = 1).
Algorithm COATES (NumClusters: k, Corpus: T1……..Tn,Auxilary Attributes: X1…..Xn);
Begin
Use Content‐based algorithm in [27] to cerate Initial set of k clusters C1……Ck;
Let centroids of C1…...Ck be Denoted by L1……Lk;
T=1;
While not (termination_criterion) do Begin
{First minor iteration}
Use Cosine‐similarity of each document Ti to Centroids cluster to Ti and update the
Cluster assignments C1……Ck; Denote assigned cluster index for
Document Ti by qc(I,t);
Update cluster centroids L1…..Lk to the Centroids of the updated clusters C1….Ck;
{Second minor Iteration}
Compute gini –index of Gr fgor each auxiliary Attribute r with respect to current
Clusters C1….Ck;
Mean as the non‐discriminatory; {for document Ti let Ri be the set of attributes
Which take on value of 1, and for Which gini –index is discriminatory;} For each document Ti use the is method discussed
In the section 2 to determine the posterior Probability P^n(Tiє Cj|Ri);
Denote qa(I,t) as the cluster‐index with the highest posterior probability of assignment for document Ti
Update the cluster‐centroids L1…..Lk with Use of posterior probabilities discussed in
Section2 t=t+1;
End End
Fig. 1. COATES algorithm
4.3 TIME COMPLEXITY
The time Complexity of the methodology is ruled when needed for the substance based and assistant minor cycles. We will focus this running time regarding the quantity of clusteres k, the quantity of words in the text dictionary dt, the quantity of helper traits d, and the complete number of reports N. In every emphasis of the methodology, O(k) cosine separation processings are every framed. For N archives, we oblige O(n • k) cosine reckonings. Since every cosine reckoning may oblige O(dt) time, this running time is given by O(n•k•dt). In addi- tion, every emphasis obliges us to figure the closeness with the assistant qualities. The significant contrast from the substance based reckoning is that this obliges O(d) time. Hence, the aggregate running time needed for every emphasis is O(n • k • (d + dt)). Along these lines, the general running time may be acquired by increasing this quality with the aggregate num- ber of emphases. In practice, a little number of emphases (between 3 to 8) are sufficient to achieve merging in many situations. Thusly, in practice, the aggregate running time is given by O(N • k • (d + dt)).
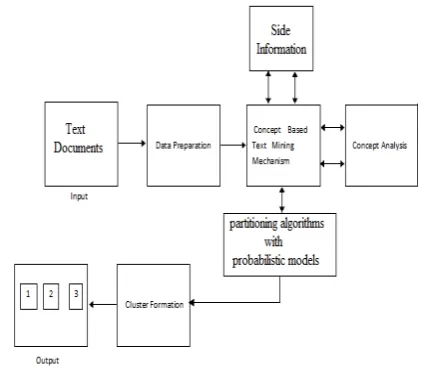
5. PROPOSED METHODOLOGY
The proposed methodology can be depicted in the accompanying steps:
1. First we consider that include is the quantity of text archive without any side-information.
2. In the first stage we utilize light weight instatement as a part of which standard text clustering methodology for this reason we utilize the calculation of projection for productive report clustering.
3. After this steps apportioning made by clustering calculation. This stage begins off with these beginning gatherings, and iteratively reproduces these bunches with the utilization of both text substance and assistant information.
4. In next the stage clustering calculation signifies the bunch record with most astounding back likelihood for enhancing nature of clustering.
5. Finally we performed mining process., to amplify the points of interest of utilizing this side information.
Fig2 .Proposed System Architecture 5.1 METHODS OF DATA COLLECTION Three real data sets are used in order to test proposed approach. The data sets used are as follows:
Cora Data Set: In this set mining of text data related to Information Retrieval, Databases, Artificial Intelligence, Encryption and Compression, Operating Systems, Networking, Hardware and Architecture, Data Structures Algorithms and Theory, Programming and Human Computer Interaction and for mining they have to use efficiency,no.of cluster and their data size. DBLP-Four-Area Data Set: We are also used this data set for mining co-authorship as another type of side information.They also uses different attributes for comparison like efficiency,no.of cluster, data size. IMDB Data Set: The Internet Movie Database (IMDB) is an online collection of movie information. We used the plots of each movie as text to perform pure text c clustering. The variety of each movie is regarded as its class label. We extracted movies from the top four variety in IMDB which were labeled by Short, Drama, Comedy, and Documentary so we removed the movies which contain more than two above genres.
5.2 PROBABLE METHODS OF DATA ANALYSIS The analysis is done with the parameters for a comparison between our text mining model and the existing methodology.
We compare the performance of the models like the probabilistic model, and the other model in terms of the various parameters like their efficiency, no. of clusters and their data size.
The graphical representation of the comparison of the probabilistic and other models on precision, along with the increasing number of visited documents,Analysis is done on the basis of some data evolution technique i.e. precision and recall with existing system.
6. CONCLUSION
procedure. To outline the clustering technique, we consolidated an iterative apportioning system with a likelihood estimation process which figures the criticalness of various types of side-information. This gen- eral methodology is utilized as a part of request to plan both clustering and characterization algorithms. We present results on genuine information sets representing the adequacy of our methodology. The results demonstrate that the utilization of side-information can incredibly improve the nature of text clustering and order, while keeping up an abnormal state of effectiveness.
REFERENCES
[1] C. C. Aggarwal and H. Wang, Managing and Mining Graph Data.New York, NY, USA: Springer, 2010.
[2] C. C. Aggarwal, Social Network Data Analytics. New York, NY, USA: Springer, 2011.
[3] C. C. Aggarwal and C.-X. Zhai, Mining Text Data. New York, NY, USA: Springer, 2012.
[4] C. C. Aggarwal and C.-X. Zhai, “A survey of text classification algorithms,” in Mining Text Data. New York, NY, USA: Springer, 2012.
[5] C. C. Aggarwal and P. S. Yu, “A framework for clustering mas- sive text and categorical data streams,” in Proc. SIAM Conf. Data Mining, 2006, pp. 477–481.
[6] C. C. Aggarwal, S. C. Gates, and P. S. Yu, “On using partial supervision for text categorization,” IEEE Trans. Knowl. Data Eng., vol. 16, no. 2, pp. 245–255, Feb. 2004.
[7] C. C. Aggarwal and P. S. Yu, “On text clustering with side information,” in Proc. IEEE ICDE Conf., Washington, DC, USA, 2012.
[8] R. Angelova and S. Siersdorfer, “A neighborhood-based approach for clustering of linked document collections,” in Proc. CIKM Conf., New York, NY, USA, 2006, pp. 778–779.
[9] A. Banerjee and S. Basu, “Topic models over text streams: A study of batch and online unsupervised learning,” in Proc. SDM Conf., 2007, pp. 437–442.
[10] J. Chang and D. Blei, “Relational topic models for document net- works,” in Proc. AISTASIS, Clearwater, FL, USA, 2009, pp. 81–88. [11] D. Cutting, D. Karger, J. Pedersen, and J. Tukey, “Scatter/Gather:
A cluster-based approach to browsing large document collec- tions,” in Proc. ACM SIGIR Conf., New York, NY, USA, 1992, pp. 318–329.
[12] I. Dhillon, “Co-clustering documents and words using bipartite spectral graph partitioning,” in Proc. ACM KDD Conf., New York, NY, USA, 2001, pp. 269–274.
[13] I. Dhillon, S. Mallela, and D. Modha, “Information-theoretic co- clustering,” in Proc. ACM KDD Conf., New York, NY, USA, 2003, pp. 89–98.
[14] P. Domingos and M. J. Pazzani, “On the optimality of the sim- ple Bayesian classifier under zero-one loss,” Mach. Learn., vol. 29, no. 2–3, pp. 103–130, 1997.
[15] M. Franz, T. Ward, J. S. McCarley, and W. J. Zhu, “Unsupervised and supervised clustering for topic tracking,” in Proc. ACM SIGIR Conf., New York, NY, USA, 2001, pp. 310–317.
[16] G. P. C. Fung, J. X. Yu, and H. Lu, “Classifying text streams in the presence of concept drifts,” in Proc. PAKDD Conf., Sydney, NSW, Australia, 2004, pp. 373–383.
[17] H. Frigui and O. Nasraoui, “Simultaneous clustering and dynamic keyword weighting for text documents,” in Survey of Text Mining, M. Berry, Ed. New York, NY, USA: Springer, 2004, pp. 45–70.
[18] S. Guha, R. Rastogi, and K. Shim, “CURE: An efficient clustering algorithm for large databases,” in Proc. ACM SIGMOD Conf., New York, NY, USA, 1998, pp. 73–84.
[19] S. Guha, R. Rastogi, and K. Shim, “ROCK: A robust cluster- ing algorithm for categorical attributes,” Inf. Syst., vol. 25, no. 5, pp. 345–366, 2000.
[20] Q. He, K. Chang, E.-P. Lim, and J. Zhang, “Bursty feature repre- sentation for clustering text streams,” in Proc. SDM Conf., 2007, pp. 491–496.
[21] A. Jain and R. Dubes, Algorithms for Clustering Data. Englewood Cliffs, NJ, USA: Prentice-Hall, Inc., 1988.
[22] T. Liu, S. Liu, Z. Chen, and W.-Y. Ma, “An evaluation of feature selection for text clustering,” in Proc. ICML Conf., Washington, DC, USA, 2003, pp. 488–495.
[23] A. McCallum. (1996). Bow: A Toolkit for Statistical Language Modeling, Text Retrieval, Classification and Clustering [Online].Available: http://www.cs.cmu.edu/ mccallum/bow
[24] Q. Mei, D. Cai, D. Zhang, and C.-X. Zhai, “Topic modeling with network regularization,” in Proc. WWW Conf., New York, NY, USA, 2008, pp. 101–110.
[25] R. Ng and J. Han, “Efficient and effective clustering methods for spatial data mining,” in Proc. VLDB Conf., San Francisco, CA, USA, 1994, pp. 144–155.
[26] G. Salton, An Introduction to Modern Information Retrieval. London, U.K.: McGraw Hill, 1983.
[27] H. Schutze and C. Silverstein, “Projections for efficient document clustering,” in Proc. ACM SIGIR Conf., New York, NY, USA, 1997, pp. 74–81.
[28] F. Sebastiani, “Machine learning for automated text categoriza- tion,” ACM CSUR, vol. 34, no. 1, pp. 1–47, 2002.
[29] C. Silverstein and J. Pedersen, “Almost-constant time clustering of arbitrary corpus sets,” in Proc. ACM SIGIR Conf., New York, NY, USA, 1997, pp. 60–66.
[30] M. Steinbach, G. Karypis, and V. Kumar, “A comparison of docu- ment clustering techniques,” in Proc. Text Mining Workshop KDD, 2000, pp. 109–110.
[31] Y. Sun, J. Han, J. Gao, and Y. Yu, “iTopicModel: Information net- work integrated topic modeling,” in Proc. ICDM Conf., Miami, FL, USA, 2009, pp. 493–502.
[32] W. Xu, X. Liu, and Y. Gong, “Document clustering based on non- negative matrix factorization,” in Proc. ACM SIGIR Conf., New York, NY, USA, 2003, pp. 267–273.
[33] G Fattepurkar, V Bandgar “Fast Compressive Tracking of Robust Object with Kalman Filter” International Journal of Engineering Research & Technology (IJERT)
[34] B Vishal V “A Review on: Automatic Movie Character Annotation by Robust Face-name Graph Matching” International Journal of Computer Applications 104 (october 2014)..
[35]B V. V ”An Approach for development of Multitenant application as SaaS cloud” International Journal of Computer Applications 106 (November 2014)
[36] Y. Zhou, H. Cheng, and J. X. Yu, “Graph clustering based on struc- tural/attribute similarities,” PVLDB, vol. 2, no. 1, pp. 718–729, 2009.