International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 5, Issue 2, February 2015)
216
Sentiment Based Text to Speech Synthesis using Forward
Parsing with Prosody Feature for Tamil
B. Sudhakar
1, R. Bensraj
21,2
Assistant Professor, Electrical Engineering Dpt, Annamalai University, India
Abstract - Several prototypes and fully operational systems have been built based on different synthesis techniques. This paper describes the Text to Speech Synthesizer with prosody feature for generating natural human conversation. It also deals with forward parsing technique for sentiment analysis of the TTS system in an efficient way. The prosody features plays an important roll to generate the TTS out put just like human voice. To produce the out put of TTS in the same form as if it is actually spoken the prosody feature allows the synthesizer to vary the pitch of voice. The forward parsing is utilized to compute the sentiment in the text and the sentiment based out put will be generated.
Keywords -Text to speech synthesizer (TTS), Forward parsing, prosody feature
I. INTRODUCTION
Over the past years there has been a great development in speech technology .Among the applications of speech technology, the automatic speech production, which is referred to as text-to-speech (TTS) system is the most natural sounding technology. Text-to-speech synthesis is the process of converting ordinary orthographic text into acoustic signal which is indistinguishable from human speech[1]. Speech synthesis is the artificial production of human speech. A computer system used for this purpose is called a speech synthesizer, and can be implemented in software or hardware products.
A (TTS) system converts normal language text into
speech, other systems render symbolic linguistic
representations like phonetic transcriptions into speech[2]. To implement complex waves of physical, phonetic effects that is being applied to express speculation, attitude and attention as a parallel channel in our daily speech communication is carried out by prosody feature. From listener aspect prosody contains systematic perception and recovery of speaker intention based on relative volume, rate of vocal fold cycle as function of time (pitch), phoneme duration and time.
Synthesized speech can be created by concatenating pieces of recorded speech that are stored in a database. Systems differ in the size of the stored speech units; a system thatstores phones or di-phones provides the largest output range, but may lack clarity.
For specific usage domains, the storage of entire words or sentences allows for high-quality output. Alternatively, a synthesizer can incorporate a model of the vocal tract and other human voice characteristics to create a completely "synthetic" voice output
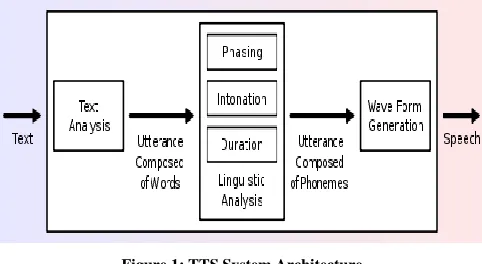
II. GENEREL ARCHITECTURE OF TTSSYSTEM
A text-to-speech system (or "engine") is composed of two parts: a front-end and aback-end. The front-end has two major tasks. First, it converts raw text containing symbols like numbers and abbreviations into the equivalent of written-out words. This process is often called text normalization, pre-processing, or tokenization[3].
The front-end then assigns phonetic transcriptions to each word, and divides and marks the text into prosodic units, like phrases, clauses, and sentences. The process of assigning phonetic transcriptions to words is called text-to-phoneme or grapheme-to-text-to-phoneme conversion. Phonetic transcriptions and prosody information together make up the symbolic linguistic representation that is output by the front-end. The back-end often referred to as the
synthesizer—then converts the symbolic linguistic
[image:1.612.323.564.509.641.2]representation intosound. In certain systems, this part includes the computation of the target prosody
Figure 1: TTS System Architecture
(pitch contour, phoneme durations), which is then imposed on the output speech.
a) Pre-processing
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 5, Issue 2, February 2015)
217
b) Sentence splitting
Segmentation of the document into a list of sentences.
c) Tokenisation
Segmentation of each sentence into a number of tokens, possible processing of XML.
III. OVER VIEW OF SYNTHESIS
III.a. Formant Synthesis
Formant synthesis, also known as rule-based synthesis, creates the acoustic speech data entirely through rules on the acoustic correlates of the various speech sounds. No human speech recordings are involved at run time. The resulting speech sounds relatively unnatural and ―robot-like‖ compared to state-of-the-art concatenative systems, but a large number of parameters related to both voice source and vocal tract can be varied quite freely. This, of course, is interesting for modeling emotionalexpressivity in speech. Several larger undertakings [4][5][6] have used Formant synthesizers because of the high degree of control that they provide.
III.b. Di-phone Concatenation
In concatenative synthesis, recordings of a human speaker are concatenated in order to generate the synthetic speech. The use of di-phones, i.e. stretches of the speech signal from the middle of one speech sound (―phone‖) to the middle of the next, is common. di-phone recordings are usually carried out with a monotonous pitch. At synthesis time, the required F0 contour is generated through signal processing techniques which introduce a certain amount of distortion, but with a resulting speech quality usually considered more natural than formant synthesis[7].
III.c. Unit Selection
The synthesis technique often perceived as being most natural is unit selection, or large database synthesis, or speech resequencing synthesis. Instead of a minimum speech data inventory as in diphone synthesis, a large inventory (e.g., one hour of speech) is used. Out of this large database, units of variable size are selected which best approximate a desired target utterance defined by a number of parameters. These parameters can be the same as used in diphone synthesis, i.e. phoneme string, duration and F0, or they could be different. The weights assigned to the selection parameters influence which units are selected. If well-matching units are found in the database, no signal processing is necessary. While this synthesis method often gives very natural results, the results can be very bad when no appropriate units are found.
The feature of unit selection synthesis to preserve the features of the recorded speech very well has been exploited by [9] for the synthesis of emotional speech. For each of three emotions (anger, joy, and sadness), an entire unit selection database was recorded by the same speaker. In order to synthesis a given emotion, only units from the corresponding database are selected. The emotions in the resulting synthesized speech are well recognized (50-80%).
IV. PROSODY FEATURE
a) Pause. Pause as hesitation is a non-fluency feature. However, intentional pauses are used to demarcate units of grammatical construction, such as sentences or clauses. These can be indicated in writing by full stops, colons, semi-colons and commas.
b) Pitch. Different pitch levels, or intonation, can affect meaning. The most obvious example is the way in which speakers raise the pitch at the end of a question, and this is indicated by a question mark in writing. However, patterns of rise and fall can indicate such feelings as astonishment, boredom or puzzlement, and these can be shown in writing only in a special transcription.
c) Stress. Stress, or emphasis, is easy to use and recognize in spoken language, but harder to describe. A stressed word or syllable is usually preceded by a very slight pause, and is spoken at slightly increased volume.
d) Volume. Apart from the slight increase in loudness to indicate stress, volume is generally used to show emotions such as fear or anger. In writing, it can be shown by the use of an exclamation mark, or typographically with capitals or italics (or both).
V. PROSODY GENERTION
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 5, Issue 2, February 2015)
218
Figure2: Architecture of Prosody GeneratorThe various phases of Prosody Generator::
Speaking Style:
Prosody depends not only on the linguistic content of a sentence. Different people generate different prosody for the same sentence. Even the same person generates a different prosody depending on his or her mood. The speaking style of the voice in Figure 1, can impart an overall tone to a communication. Examples of such global settings include a low register, voice quality (falsetto, creaky, breathy, etc), narrowed pitch range indicating boredom, depression, or controlled anger, as well as more local effects, such as notable excursion of pitch, higher or lower than surrounding syllables, for a syllable in a word chosen for special emphasis. The various parameter which influence the speaking Style are presented in[11,12].
a. Character:
It is an importent determining element in prosody, refers primarily to long-term, stable, extra-linguistic properties of a speaker, such as membership in a group and individual personality.. In determines the features such as gender, age, speech defects, etc. affect speech, and physical status may also be a background determiner of prosodic character. Finally, character may sometimes include temporary conditions such as fatigue, inebriation, talking with mouth full, etc. Since many of these elements have implications for both the prosodic and voice quality of include temporary conditions such speech output, they can be very challenging to model jointly in a TTS system.[5,7]
b. Emotion:
The prosody should consider the temporary emotional conditions such as amusement, anger, contempt, sympathy, suspicion, etc are suggested in[11][12]. A large number of high-level factors go into determining emotional effects in speech. Among these are point of view (can the listener interpret what the speaker is really spontaneous vs. symbolic (e.g., acted emotion vs. real feeling); culture-specific vs. universal; basic emotions and compositional emotions that combine basic feelings and effects; and strength or intensity of emotion.
1. Anger,though well studied in the literature, may be too broad a category for coherent analysis. One could imagine a threatening kind of anger with a tightly controlled F0, low in the range and near monotone; while a more overtly expressive type of tantrum could be correlated with a wide, raised pitch range.
2. Joyis generally related with increase in pitch and pitch range, with increase in speech rate. Untrained listener can easy to identify smiling because it raises F0 and formant frequencies.
3. Sadnessgenerally has normal or lower than normal pitch realized in a narrow range, with a slow rate and tempo. It may also be characterized by slurred pronunciation and irregular rhythm.
4. Fearis characterized by high pitch in a wide range, variable rate, precise pronunciation, and irregular voicing.
VI. DURATION ASSIGNMENT
The phoneme durations are characterized by various factors. The general factors are
a. Semantic and Pragmatic Conditions
b. Speech rate corresponding to speaker intent, mood and emotion
c. The use of duration or rhythm to possibly signal document structure above the level of phrase or sentence [13]
d. The lack of a consistent and coherent practical definition of the phone such that boundaries can be clearly located for measurement Rule based method is one of the most commonly used methods for Duration Assignment. For every phone type this method uses table lookup for minimum and inherent duration. The duration is rate dependent, so all phones can be globally scaled in their minimum duration for faster or slower rates.
Speech Style
Input Text
Enhanced Prosodic Representation
Pause insertion and Prosodic phrasingInternational Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 5, Issue 2, February 2015)
219
The inherent duration is raw material and using the specified rules, it may be stretched or contracted by pre-specified percentage attached to each rule type as pre-specified and then it is finally added back to the minimum duration to yield a millisecond time for a given phone. The duration of phone is expressed asWhere dmin is the minimum duration of the phoneme, d is average duration of the phoneme and correction ―r‖ is given by:
For the case of N rules applied, where each rule has correction ri. At the very end, a rule may apply that lengthens vowels when they are preceded by voiceless plosives. The list of rules used for calculating duration as follows:
[1]. Lengthening of final vowel and following
consonant in pre - pausal syllables
[2]. Shortening of all syllabic segments in nonpre-pausal positions
[3]. Shortening of syllabic segments if not in a word final syllable
[4]. Consonant in non word initial positions are shortened
[5]. Un-stressed and secondary stressed phones are shortened
[6]. Emphasized vowels are lengthened
[7]. Vowels may be shortened or lengthened according
to phonetic features of their context [8]. Consonants may be shortened in cluster
VII. PITCH GENERATION
Since generating pitch contours is an incredibly tedious problem, pitch generation is often divided into two levels, with the first level computing the so-called symbolic prosody and the second level generating pitch contours from this symbolic prosody. This division is somewhat arbitrary since, as we shall see below, a number of important prosodic phenomena do not fall cleanly on one side or the other but seem to involve aspects of both. Often it is useful to add several other attributes of the pitch contour prior to its generation, which is discussed in coming section
VII.a. Pitch Range:
Pitch range refers to the high and low limits within which all the accent and boundary tones must be realized: a floor and ceiling, so to speak, which are typically specified in Hz. This may be considered in terms of stable, speaker-specific limits as well as in terms of an utterance or passage.
VIII. FORWARD PARSING METHOD
Parsing is an important method for scanning the text. Through parsing we can determine various points such as content of text, context of text, frequency of particular word in the text etc. It is necessary to determine context of text to find out the emotions present in it. The context of the text is not only used to determines the current emotions present in the text and also used to determine the variation in the emotion. Most of the commercial available TTS are based on regular parsing in which the emotion present in the text is generated at the same time when the text is converted and represented in the voice form to the user. This approach followed in current text to speech synthesizers,. [14]
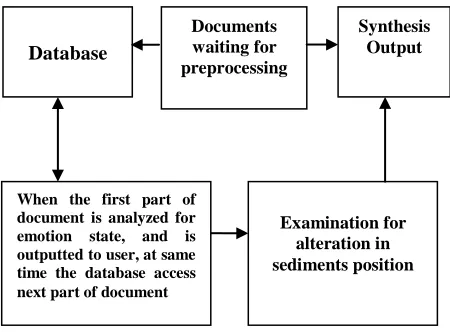
Forward Parsing Implementing
[image:4.612.321.546.443.609.2]The block diagram for implementing forward parsing is as shown in the figure.
Figure 3:Architecture for Forward Parsing
As shown in the figure 3, a Database is maintained, which contains the keywords and category of emotion to which it belongs. Following types of emotions are handled using the architecture.
Anger, Joy, Surprise, Disgust, Contempt, Pride, Depression, Funny, Sorry, Boredom, Suffering, Shame
Documents waiting for preprocessing
Synthesis Output
Examination for alteration in sediments position
When the first part of document is analyzed for emotion state, and is outputted to user, at same time the database access next part of document
International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 5, Issue 2, February 2015)
220
The text is scanned and keywords present in the text are compared with the contents of database. The comparison will determine the value of emotion. Once the type of emotion is fixed the information is supplied to the composer, which then composes the wave file based on value of emotion[16]. The value of emotion is changed based on intensity of emotion in the text. For example if thetext isMagizchiaga Irukiren: Then the intensity of
[image:5.612.331.555.144.409.2]emotion is normal and will be represented by <+>.
Figure 4:Magizchiaga Irukiren
Figure 5: Migavum Magizchiaga Irukiren
Migavum Magizchiaga Irukiren:Then the intensity is increase and will be represented by <++>
This approach will help in varying the pitch of the
keyword “Magizchiaga”.
IX. RESULTS AND DISCUSSION
TABLE 1
PERFORMANCE MEASURE
GTTS STTS Emotions
Compara tive Output
Set 1 (5 Members)
Set 1 (5
Members) Angry
GTTS > STTS
Set 2 (5 Members)
Set 2 (5
Members) Sadness
GTTS > STTS
Set 3 (5 Members)
Set 3 (5
Members) Joy
GTTS > STTS
Set 4 (5 Members)
Set 4 (5
Members) Fear
GTTS > STTS
Set 5 (5 Members)
Set 5 (5
Members) Disgust
GTTS > STTS
GTTS :Generated Text to Speech STTS:Standard Text to Speech
(Commercially available)
From this proposed work the performance are inferred that the speech of five speakers with respect to the quality of the synthesized speech and variations in natural speech related to prosody has been enhanced. For developing an emotion based TTS output using prosody features we have taken different sets of samples with diversified emotions. For performance measure we have taken 5 sets of GTTS and STTS with different emotions. From the performance measure we inferred that GTTS has produced a high-quality Tamil text-to-speech system. Based on part-of-speech analysis, prosodic modeling and non-uniform units Tamil text into natural speech has been produced[15][16]. These technologies efficiently enhance thenaturalness and the precious quality of the TTS system.
[image:5.612.72.264.246.541.2]International Journal of Emerging Technology and Advanced Engineering
Website: www.ijetae.com (ISSN 2250-2459, ISO 9001:2008 Certified Journal, Volume 5, Issue 2, February 2015)
221
REFERENCES
[1] Cahn, J. E., Generating Expression in SynthesizedSpeech, Master’s Thesis, MIT, 1989.http://www.media.mit.edu/~cahn/masters-thesis.html
[2] Cahn, J. E., The Generation of Affect in Synthesized Speech, Journal of the American Voice I/O Society, 8, July 1990, pp. 1-19. [3] Murray, I. R., Simulating emotion in synthetic speech, PhD Thesis,
University of Dundee, UK, 1989.
[4] Murray, I. R., & Arnott, J. L., Implementation and testing of a system for producing emotion-by-rule in synthetic speech, Speech Communication, 16,pp. 369-390.
[5] Burkhardt, F., Simulation emotionaler Sprechweise mit [Simulation of emotionalmanner of speech using speech synthesis techniques],PhD Thesis, TU Berlin, 2000. http://www.kgw.tuberlin.de/~felixbur/publications/diss.ps.gz [6] Burkhardt, F., & Sendlmeier, W. F., Verification of Acoustical
Correlates of Emotional Speech usingFormant-Synthesis, ISCA Workshop on Speech &Emotion, Northern Ireland 2000,pp. 151-156.
[7] Vroomen, J., Collier, R., & Mozziconacci, S. J. L.,Duration and Intonation in Emotional Speech,Eurospeech 93, Vol. 1, pp. 577-580. [8] Edgington, M., Investigating the Limitations ofConcatenative
Synthesis, Eurospeech 97.
[9] Campbell, N., Iga, S., Higuchi, F., & Yasumura, M., A Speech Synthesis System for Assisting Communication, ISCA Workshop on Speech & Emotion,Northern Ireland 2000, pp. 167-172
[10] Marumoto, T., & Campbell, N., Control of speaking types for emotion in a speech re-sequencing system [inJapanese], Proc. of the Acoustic Society of Japan, Spring meeting 2000, pp. 213-214. [11] D. Jurafsky and J. H. Martin. Speech and Language Processing: An
Introduction to Natural Language Processing, Computational Linguistics, and Speech Recognition. Prentice Hall PTR, Upper Saddle River, NJ, USA, 2000
[12] Fangzhong Su and Katja Markert. 2008. From word to sense: a case study of subjectivity recognition. In Proceedings of the 22nd International Conference on Computational Linguistics, Manchester [13] Allen, J., M.S. Hunnicutt, and D.H. Klatt, From Text to Speech: the
MITalk System, 2007, Cambridge, UK, University Press
[14] B. Pang and L. Lee. 2004. A sentimental education: Sentiment analysis using subjectivity summarization based on minimum cuts. In (ACL-04), pages 271–278, Barcelona, ES. Association for Computational Linguistics
[15] Hong Yu and Vasileios Hatzivassiloglou. 2003. Towards answering opinion questions: Separating facts from opinions and identifying the polarity of opinion sentences. In Conference on Empirical Methods in Natural Language Processing , pages 129–136, Sapporo,Japan. [16]B. Pang and L. Lee. 2004. A sentimental education: Sentiment analysis using subjectivity summarization based on minimum cuts. In (ACL-04), pages 271–278, Barcelona, ES. Association for Computational Linguistics