International Journal of Video& Image Processing and Netwo rk Security IJVIPNS-IJENS Vol:10 No:02 7
100902-3737 IJVIPNS-IJENS © April 2010 IJENS
A Hybrid Method for Extracting Key Terms of Text
Documents
Ahmad Ali Al-Zubi
Computer Science Department / King Saud University
Saudi Arabia
Email: [email protected], [email protected]
Abstract-- key terms are important terms in the document, which can give high-level description of contents for the reader. Extracting key terms is a basic step for many problems in natural language processing, such as document classification, clustering documents, text summarization and output the general subject of the document. This article proposed a new method for extracting key terms from text documents. As an important feature of this method, we note the fact that the result of its work is a group of key terms, with terms from each group are semantically related by one of the main subjects of the document. Our proposed method is based on a combination of the following two techniques: a measure of semantic proximity of terms, calculated based on the knowledge base of Wikipedia and an algorithm for detecting communities in networks. One of the advantages of our proposed method is no need for preliminary learning, because the method works with the knowledge base of Wikipedia. Experimental evaluation of the method showed that it extracts key terms with high accuracy and completeness.
Index Term-- Extraction Method, Key Term, S emantic Graph, Text Document
I. INT RODUCT ION
Key terms (keywords or key phrases) are important terms in the document, which can give high-level description of contents for the reader. Extracting key terms is a basic step for many problems in natural language processing, such as document classification, clustering documents, text summarization and output the general subject of the document (Manning and Schtze, 1999). In this article we propose a method for extracting document key terms, using Wikipedia as a rich information resource about the semantic proximity of terms.
Wikipedia www.wikipedia.org is a free available encyclopaedia, which is now the largest encyclopaedia in the world. It contains millions of articles and redirect pages of synonyms of the main title of the article available in several languages. With a vast network of links between articles, a large number of categories, redirect pages and disambiguation pages, Wikipedia is an extremely powerful resource for our work and for many other applications of natural language processing and information retrieval.
Our method is based on the following two techniqu es: A measure of semantic proximity, calculated based on Wikipedia and an algorithm for networks analysis, namely, Girvan-
Newman algorithm for communities detection in networks. A brief description of these techniques is given below.
Establishing the semantic proximity of concepts in the Wikipedia is a natural step towards a tool, useful for the problems of natural language processing and information retrieval. Over the recent years a number of articles were published on semantic proximity computatio n between concepts using different approaches [7, 8, 3, 12]. [7] Gives a detailed overview of many existing methods of semantic proximity calculation of concepts using Wikipedia. Although the method described in our article does not impose any requirements to the method of semantic proximity determination, the efficiency of this method depends on the quality of the chosen method for semantic proximity calculation. For the experiments described in this article, we used the method for semantic proximity calculation.
Knowing the semantic proximity of terms, we can construct a semantic graph for all terms of processed document. The semantic graph is a weighted graph in which nodes are the document terms, the existence of edges between a pair of terms means that these two terms are semantically similar, the weight of the edges is the numerical value of the semantic proximity of these two terms. We noticed that, thus constructed graph, possesses an important property : Semantically similar terms “stumble” into dense subgraphs in so-called community, the most massive and highly connected subgraphs tend to correlate with the main subject of the document and the terms included in such subgraphs, are considered as the key terms of this document. The novelty of our approach is to apply the algorithm for detecting such communities in networks, which allows us to identify thematic groups of terms and then choose the densest among them. Those densest groups of terms are the result of the method -thematically grouped key terms .
International Journal of Video& Image Processing and Netwo rk Security IJVIPNS-IJENS Vol:10 No:02 8
100902-3737 IJVIPNS-IJENS © February 2010 IJENS II. PREVIOUS SIMILAR WORKS
In the field of statistical processing of natural language there are classical approaches for key terms extraction: tf.idf and collocation analysis [5]. tf.idf (term frequency-inverse document frequency) is a popular metric for solving problems of information retrieval and text analysis [10]. tf.idf is a statistical measure of how important the term is in the document, which is a part of a collection of documents. By using tf.idf the importance of the term is proportional to the number of occurrences of the term in the document and inversely proportional to the number of occurrences of the term in the entire collection of documents. While tf.idf is used to extract the key terms of one-word, Collocation Analysis (CA) is used to detect phrases.
Approach tf.idf, supplemented by the CA, is used to extract key phrases. Both approaches require a certain collection of documents for statistics gathering, such collection is known as Training Set (TS). Quality of approaches depends on the quality of TS.
The advantages of these approaches are the simplicity of implementation and satisfactory quality of work when the TS is well chosen. Due to these advantages, these approaches are widespread in practice. We would like to note an interesting fact: in these researches [7, 2, 6] where Wikipedia was used as a TS, they showed that Wikipedia is a good TS for many practical applications.
An alternative class of approaches for natural language processing problems (keywords extraction is one of such problems) and this article belongs to this class of approaches. Approaches of this class based on the use of knowledge about the semantic proximity of terms. The semantic proximity of terms can be obtained with the help of a dictionary or thesaurus, but we are interested in the articles that use the semantic proximity of terms, obtained from Wikipedia.
Calculation of semantic proximity of terms using Wikipedia can be performed with one of the following two ways:
Using hypertext links between the articles of Wikipedia, which correspond to the terms [8, 10, 5].
Measuring cosine of the angle between the vectors constructed by the texts of relevant articles of the Wikipedia [3].
There are many articles where the semantic proximity of terms is derived from Wikipedia, are used to solve the following problems of natural language processing and information retrieval: resolution of lexical polysemy of terms [6, 11] derivation of document overall theme [13], categorization [4] co-reference resolution [12].
The authors of this article are not aware of articles, where the semantic proximity of terms would be used to extract document key terms; however, article [4] is the closest to mine. In [4] problem of text categorization is being solved, with the text terms a semantic graph is being constructed, similar to what I propose in this article. The idea of using algorithms for graphs analysis in this article appears in a
simple form according to which: the most central terms in the graph are chosen by the Betweenness Centrality Algorithm (BCA), then these terms are used to categorize the document.
We distinguish the following advantages of our method:
Our method does not require training, in contrast to traditional approaches described above. Due to the fact that Wikipedia is large and continually updated encyclopaedia by millions of people, it remains relevant and covers a lot of s pecific areas of knowledge. Thus, practically any document, that has most of the terms described in Wikipedia, can be processed by our method Key terms are grouped by subject and the method extracts
many different thematic groups of terms, as many as different topics covered in the document. Thematically grouped key terms can significantly improve the general subject determination of the document (using, for example, the spreading activation method on categories graph of Wikipedia, as described in [13]) and document categorization [4].
Our method is highly effective regarding the quality of extracted key terms. Experimental evaluation of the method, discussed later in this article showed that the method extracts key terms with high accuracy and completeness from any document
III. MAT ERIALS AND MET HODS
III.1. Key Terms Extracting Method.
Our proposed method for key terms extraction consists of the following five steps :
Extraction of candidate terms
Resolution of lexical polysemy of terms Building a semantic graph
Detection of communities in the semantic graph Selection of suitable communities
III.2. Extraction of Candidate Terms.
The purpose of this step is to extract all the terms of the document and prepare for each term a set of Wikipedia articles, which could potentially describe its meaning.
We break the source document into tokens, allocating all possible N-grams. For each N-gram, we construct its morphological variations. Then for each variation a search will be performed on all articles titles on Wikipedia. Thus, for each N-gram, we obtain a set of Wikipedia articles, which can describe its meaning.
Construction of various morphological forms of words allows us to expand the search by articles titles of Wikipedia and thus, finding relevant articles for a larger portion of terms. For example, the words of reads, reading and read may be linked to two articles on Wikipedia: Read and reading.
III.3. Resolution of Lexical Polysemy of Terms.
International Journal of Video& Image Processing and Network Security IJVIPNS-IJENS Vol:10 No:02 9
100902-3737 IJVIPNS-IJENS © February 2010 IJENS The polysemy of words -is a widespread phenomenon of
natural language. For example, the word “platform” can mean a railway platform, or software platform, as well as a platform, as a part of the shoe.
The correct meaning of an ambiguous word may be determined by the context in which this word is mentioned. The task of lexical polysemy resolution is an automatic selection of the most appropriate meaning of the word (in our case-the most appropriate article on Wikipedia) when mentioning it in some context.
There are several articles on resolving lexical polysemy of terms using Wikipedia [6, 7, 11]. For the experiments discussed in this study a method was implemented, where we use the pages for ambiguous terms and Wikipedia redirect pages. With the use of these wiki pages a set of possible meanings of the term is constructed. Then the most appropriate meaning is selected using the knowledge of the semantic proximity of terms : the degree of semantic proximity to the context is calculated for every possible meaning of the term. As a result, the meaning with the largest degree of semantic proximity to the context will be chosen as the meaning of the term.
One common problem of traditional methods for extracting key terms is the existence of absurd sentences in the result, such as, for example, “using”, “electric cars are”. Using Wikipedia as a controlling thesaurus allows us to avoid this problem: All key terms extracted using our method are meaningful phrases.
The result of this step is a list of terms in which each term is correlated with a corresponding article on Wikipedia, which describes its meaning.
III.4. Building the Semantic Graph.
In this step, we construct a semantic graph using the list of terms obtained in the previous step. The semantic graph is a weighted graph whose nodes are the terms of the document, the existence of edges between two nodes means that the terms are semantically related to each other, the weight of the edges is numerical value of the semantic proximity of the two connected terms.
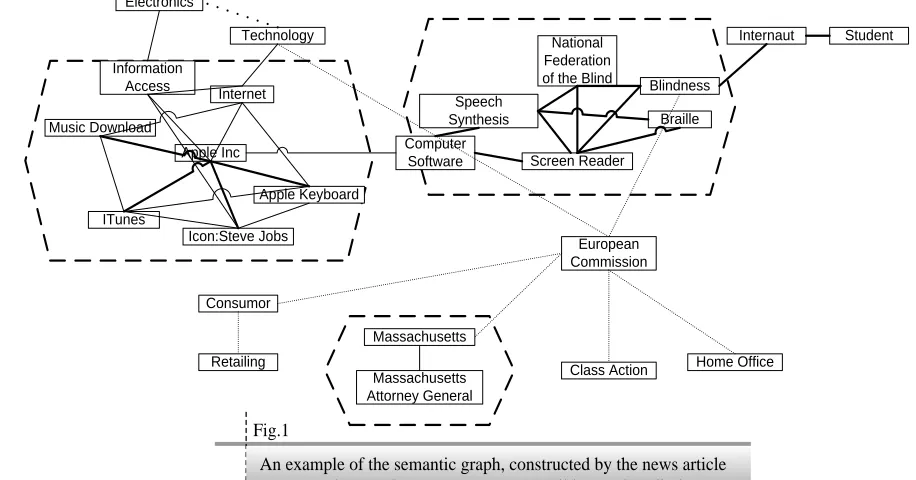
Fig. 1 shows an example of the semantic graph, constructed from a news article «Apple to Make ITunes More Accessible for the Blind». The article says that the chief prosecutor in Massachusetts and the National Federation of the Blind have reached an agreement with the corporation of Apple Inc., Following which Apple will make available its online music service ITunes for blind users through screen-reading technology. On Fig. 1 we can see that the relevant terms Apple Inc. and Blindness, form the two dominant communities and the terms student, retailing and year were on the periphery and poorly connected with the rest of the graph.
It is important to note that the terms -errors, that have occurred in the resolution of lexical polysemy of terms, performed on the second step, are peripheral or even isolated nodes of the graph and do not adjoin to the dominant communities.
ITunes Electronics
Information Access
Technology
Internet
Apple Inc Music Download
Apple Keyboard
Icon:Steve Jobs
National Federation of the Blind Speech
Synthesis
Screen Reader
Braille Blindness
European Commission
Massachusetts
Massachusetts Attorney General Consumor
Retailing Home Office
Class Action
Internaut Student
Computer Software
Fig.1
An example of the semantic graph, constructed by the news article «Apple to Make ITunes More Accessible For the Blind»
International Journal of Video& Image Processing and Netwo rk Security IJVIPNS-IJENS Vol:10 No:02 10
100902-3737 IJVIPNS-IJENS © February 2010 IJENS The purpose of this step is automatic detection of
communities in the built semantic graph. To solve this problem we apply Girvan-Newman algorithm. As a result of the algorithm the original graph is divided into subgraphs, which represent a thematic community terms.
To evaluate the quality of the partition of some graph on the community authors [9] suggested using a measure of modularity of the graph. Modular graphs are a p roperty of a graph and some of its partitioning into subgraphs. It is a measure of how this partitioning qualitative in the sense that there is a lot of edges lying within communities and few edges lying outside the communities (connecting communities with each other). In practice, the value of modularity in the range of 0.3-0.7 means that the network has quite discernible structure with the communities and the application of algorithm for detecting communities makes sense.
We noted that the semantic graphs, built from text documents (such as, for example, a news article or scientific article), have modularity value from 0.3-0.5.
III.6. Choosing the Right Community.
In this step, from all communities should be chosen those that contain key terms. We rank all communities so that communities with high ranks to hold important terms (key terms) and communities with low ranks to hold unimportant terms, as well as errors of resolution of lexical polysemy of terms that may occur on the second step of our method.
The ranking is based on the use of density and informational content of the community. Community density is the sum of the weights of edges connecting the nodes of this community.
Experimenting traditional approaches, we found that the use of tf.idf measures of terms helps to improve the ranking of communities. tf.idf gives high coefficients to terms corresponding to named entities (e.g., Apple Inc., Steve jobs, Braille) and lower coefficients to terms corresponding the general concepts (such as, for example, Consumer, Year, Student). We believe that tf.idf for terms when using Wikipedia as described in [6]. Under informational content of the community we understand the amount tf.idf-terms included in this community, divided by the number of terms in this community.
As a result, we consider the rank of a community, as a community density multiplied by its information content and communities sorted in descending order regarding their ranks.
Any application that uses our method for extracting keywords can use any number of communities with the highest ranks, but in practice it makes sense to use 1-3 communities with the highest ranks.
IV. RESULT S
IV.1. Experimental Evaluation.
In the results, we discuss the experimental evaluation of the proposed method. Since there is no standard benchmark for measuring the quality of key terms extracted from the
texts, we have conducted experiments involving manual efforts, that is, the completeness and accuracy of the extracted keywords were evaluated by people-participants in the experiment.
We collected 30 blog posts. The experiment included five people. Each participant had to read each blog post and select from 5-10 key terms for this blog post. Every key term must be in blog post and a relevant article in Wikipedia must be found for it. Participants also were instructed to choose the key terms so that they cover all main topics of the blog -post. As a result, for each blog post, we chose some key terms that have been allocated, at least by two participants in the experiment. Titles of redirect articles of Wikipedia and the titles of articles, to which redirection is made, in fact, represent synonyms and in our experiment and we considered them as one term.
The method presented in this article was executed based on the following architectural principles :
To achieve the best performance we have not calculated the semantic proximity of all pairs of Wikipedia terms in advance.
The data needed to calculate the semantic proximity of terms on the fly, i.e., titles of Wikipedia articles, information about links between articles, statistical information about the terms are loaded into memory. The client applications work with the knowledge base
through remote procedure calls
IV.2. Completeness Evaluation of Selected Key Terms. By completeness we mean the proportion of keywords assigned manually, which also were identified automatically by our method:
{ME} {AE}
Completeness
{ME}
(1)
Where:
ME = Manually Extracted AE = Automatically Extracted
For 30 blog posts we have 190 key terms, selected by participants of the experiment, 303-assigned automatically, the 133 hand-selected key terms were also identified automatically. Thus, the completeness is 68%.
IV.3. Accuracy Evaluati on of Selected Key Terms.
We evaluate the accuracy using the same methodology used for completeness evaluation. By accuracy we mean the proportion of those key terms that automatically identified by our method and were also detected by participants in the experiment:
{ME} {AE}
Accuracy
{ME}
International Journal of Video& Image Processing and Network Security IJVIPNS-IJENS Vol:10 No:02 11
100902-3737 IJVIPNS-IJENS © February 2010 IJENS Following the indicators of our test collection, accuracy =
41%.
IV.4. Revision of Completeness and Accuracy Evaluation. In order to better evaluate the method performance, we also reviewed the completeness and accuracy evaluation. An important feature of our method is that it allocates usually more key terms than people and retrieves more key terms that are relevant to one topic. For example, let us have a look at Fig. 1. For the topic related to Apple Inc. Our method has retrieved the following terms : Internet, Information access, Music download, Apple Inc., ITunes, Apple Keyboard and Steve Jobs, while a man usually retrieved less key terms and inclined to retrieve such as terms and names : Music download, Apple Inc., ITunes and Steve Jobs. This means that sometimes our method extracts key terms that cover the subject of the article better than people do. This fact made us to re-evaluate the completeness and accuracy of our method.
Each participant was instructed to review the experiment key terms, which he identified as follows. For each blog post he was to examine key terms selected automatically and, if possible, expand his own key terms list with the terms, that he thinks are related to the main subject of the document, but were not included on the first stage.
After such review, we have 213 key terms, selected by participants instead of 190, thus participants in the experiment added 23 new key terms, which means that our assumption is meaningful and this revision is important for a full evaluation of the method. As a result, Completeness = 77% and Accuracy = 61%.
V. CONCLUSION
We have proposed a new method for extracting key terms from text documents. One of the advantages of our method that is no need for preliminary training, because the method is working on a knowledge base built on Wikipedia. Another important feature of our method is the form in which it gives the result: the key terms derived from the document, grouped by subjects of this document. Grouped key terms (by subject) can greatly facilitate the further categorization of this document and determination of its general subject.
Experiments conducted manually, have shown that our method can extract key terms with high accuracy and completeness.
We noted that our method can be successfully used for purification of complex composite documents from unimportant information and determine its general subject. This means that it would be very useful to apply this method for key terms extraction from Web-pages, which are usually loaded with secondary information, such as menu, navigation elements, ads.
VI. REFERENCES
[1] Clauset, A., M.E.J. Newman and C. Moore, 2004. Finding community structure in very large networks. Phys. Rev. E., 70: 066111.
[2] Dakka, W. and P.G. Ipeirotis, 2008. Automatic extraction of useful facet hierarchies from text databases. Proceedings of the ICDE, IEEE, pp: 466-475. In ICDE, 466–475. IEEE. [3] Gabrilovich, E. and S. Markovitch, 2007. Computing semantic
relatedness using Wikipedia-based explicit semantic analysis. Proceedings of the 20th International Joint Conference for Artificial Intelligence, pp: 1606-1611. Morgan Kaufmann Publishers Inc. San Francisco, CA, USA,
[4] Janik, M. and K.J. Kochut, 2008. Wikipedia in action: Ontological knowledge in text categorization. Proceedings of the International Conference on Semantic Computing, pp: 268-275. August 04- 07.ISBN: 978-0-7695-3279-0
[5] Manning, C.D. and H. Schtze, 1999. Foundations of Statistical Natural Language Processing. T he MIT Press.
[6] Medelyan, O., I.H. Witten and D. Milne, 2008. T opic indexing with Wikipedia. Proceedings of the Wikipedia and AI Workshop at the AAAI-08 Conference, (WikiAI’08). Chicago, I.L. [7] Mihalcea, R. and A. Csomai, 2007. Wikify!: Linking documents to
encyclopaedic knowledge. Proceedings of the 16th ACM Conference on Information and Knowledge Management , ACM Press, New York, USA., pp: 233-242.
ISBN:978-1-59593-803-9
[8] Milne, D. and I. Witten, 2008. An effective, low-cost measure of semantic relatedness obtained from Wikipedia links. Proceedings of the Wikipedia and AI Workshop at the AAAI-08 Conference, (WikiAI’08).
[9] Milne, D., 2007. Computing semantic relatedness using Wikipedia link structure. Proceedings of the New Zealand Computer Science Research Student Conference, (NZCSRSC).
[10] Newman, M.E.J. and M. Girvan, 2004. Finding and evaluating community structure in networks. Phys. Rev. E., 69: 026113. [11] Salton, G. and C. Buckley, 1988. T erm-weighting approaches in automatic text retrieval. Inform. Process. Manage., 24: 513-523. [12] Sinha, R. and R. Mihalcea, 2007. Unsupervised graph-based word
sense disambiguation using measures of word semantic similarity. Proceedings of the International Conference on Semantic Computing, IEEE Computer Society, Washington DC., USA., pp: 363-369.
DOI: 10.1109/ICSC.2007.107