Similarity based Word Sense Disambiguation
Full text
Figure


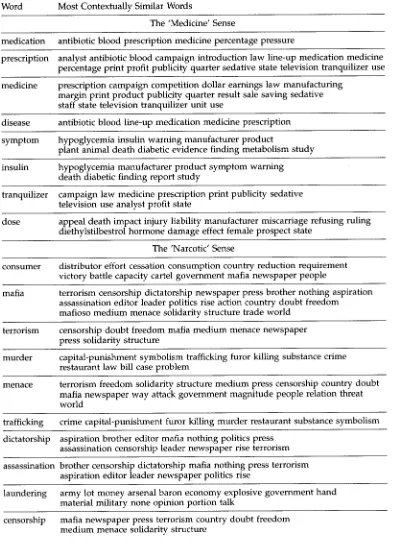


Related documents
In this paper we in- vestigate a label propagation based semi- supervised learning algorithm for WSD, which combines labeled and unlabeled data in learning process to fully realize
By manually examining a subset of about 1,000 examples, we estimate that the sense-tag error rate of training examples (tagged with lumped senses) obtained by our parallel
Corpora contain examples of words that enable the development of statistical models of word senses and their contexts (Ide and Veronis, 1998; Leacock and Chodorow,
In order to show that our approach allows for capturing large amounts of data, we created a corpus using the dis- ambiguation pages of the whole German Wikipedia.. For
We analyze the obtained data and perform a correlation analysis between several relevant variables, including word frequency, number of senses, sense distribution skewness,
empirically demonstrate that a) Basic Level Con- cepts group senses into an adequate level of ab- straction in order to perform supervised class– based WSD, b) that these
We propose an automatic method to estimate the number of senses (or sense number, model or- der) of a target word in mixed data (tagged cor- pus+untagged corpus) by maximizing
In order to show that our approach allows for capturing large amounts of data, we created a corpus using the dis- ambiguation pages of the whole German Wikipedia.. For
