2831
Posterior-regularized REINFORCE for Instance Selection in Distant
Supervision
Qi Zhang1, Siliang Tang1∗, Xiang Ren3,Fei Wu1, Shiliang Pu2 & Yueting Zhuang1 1Zhejiang University,2Hikvision,3University of Southern California,
{zhangqihit,siliang,wufei,yzhuang}@zju.edu.cn, [email protected],
Abstract
This paper provides a new way to improve the efficiency of the REINFORCE training pro-cess. We apply it to the task of instance selec-tion in distant supervision. Modeling the in-stance selection in one bag as a sequential de-cision process, a reinforcement learning agent is trained to determine whether an instance is valuable or not and construct a new bag with less noisy instances. However unbiased methods, such as REINFORCE, could usually take much time to train. This paper adopts posterior regularization (PR) to integrate some domain-specific rules in instance selection us-ing REINFORCE. As the experiment results show, this method remarkably improves the performance of the relation classifier trained on cleaned distant supervision dataset as well as the efficiency of the REINFORCE training.
1 Introduction
Relation extraction is a fundamental work in natu-ral language processing. Detecting and classifying the relation between entity pairs from the unstruc-tured document, it can support many other tasks such as question answering.
While relation extraction requires lots of la-beled data and make methods labor intensive, (Mintz et al., 2009) proposes distant supervision (DS), a widely used automatic annotating way. In distant supervision, knowledge base (KB) , such as Freebase, is aligned with nature documents. In this way, the sentences which contain an en-tity pair in KB all express the exact relation that the entity pair has in KB. We usually call the set of instances that contain the same entity pair a bag. In this way, the training instances can be di-vided into N bags B = {B1, B2, ..., BN}. Each bagBkare corresponding to an unique entity pair
∗
Corresponding author
Ek = (ek1, ek2) and contains a sequence of in-stances{xk1, xk2, ..., xk|Bk|} . However, distant su-pervision may suffer a wrong label problem. In other words, the instances in one bag may not ac-tually have the relation.
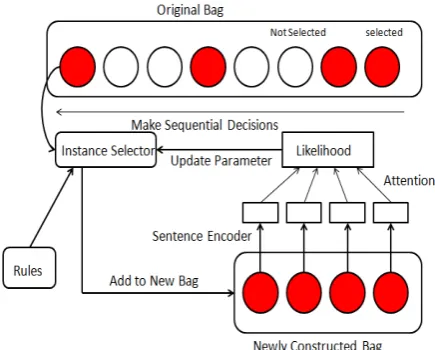
To resolve the wrong label problem, just like Fig.2 shows, (Feng et al.,2018) model the instance selection task in one bagBkas a sequential deci-sion process and train an agentπ(a|s, θπ)denoting
the probabilityPπ(At =a,|St=s, θt=θπ)that
actionais taken at timetgiven that the agent is in stateswith parameter vectorθπ by REINFORCE
algorithm (Sutton and Barto,1998). The actiona can only be 0 or 1 indicating whether an instance xk
i is truly expressing the relation and whether it
should be selected and added to the new bagBk.
The states is determined by the entity pair cor-responding to the bag, the candidate instance to be selected and the instances that have already been selected. Accomplishing this task, the agent gets a new bag Bk at the terminal of the
trajec-tory with less wrong labeled instances. With the newly constructed datasetB ={B1, B2, ..., BN}
with less wrong labeling instances, we can train bag level relation predicting models with better performance. Meanwhile, the relation predicting model gives reward to the instance selection agent. Therefore, the agent and the relation classifier can be trained jointly.
However, REINFORCE is a Monte Carlo algo-rithm and need stochastic gradient method to op-timize. It is unbiased and has good convergence properties but also may be of high variance and slow to train (Sutton and Barto,1998).
the pattern and label in any one of the rules) are denoted as xM I and we adopt posterior
regular-ization method (Ganchev,2010) to regularize the posterior distribution ofπ(a|s, θπ)onxM I. In this
way, we can construct a rule-based agent πr. πr
tends to regard the instances inxM I valuable and
select them without wasting time in trial-and-error exploring. The number of such rules is 134 alto-gether and can match nearly four percents of in-stances in the training data.
Our contributions include:
• We propose PR REINFORCE by integrating domain-specific rules to improve the perfor-mance of the original REINFORCE.
• We apply the PR REINFORCE to the in-stance selection task for DS dataset to alle-viate the wrong label problem in DS.
2 Related Work
Among the previous studies in relation extrac-tion, most of them are supervised methods that need a large amount of annotated data (Bach and Badaskar,2007). Distant supervision is proposed to alleviate this problem by aligning plain text with Freebase. However, distant supervision inevitably suffers from the wrong label problem.
Some previous research has been done in han-dling noisy data in distant supervision. An expressed-at-least-once assumption is employed in (Mintz et al., 2009): if two entities partici-pated in a relation, at least one instance in the bag might express that relation. Many follow-up stud-ies adopt this assumption and choose a most credi-ble instance to represent the bag. (Lin et al.,2016; Ji et al., 2017) employs the attention mechanism to put different attention weight on each sentence in one bag and assume each sentence is related to the relation but have a different correlation.
Another key issue for relation extraction is how to model the instance and extract features, (Zeng et al.,2014,2015;Zhou et al.,2016) adopts deep
[image:2.595.307.525.64.239.2]Figure 1: Rule Pattern Examples
Figure 2: Overall Framework
neural network including CNN and RNN, these methods perform better than conventional feature-based methods.
Reinforcement learning has been widely used in data selection and natural language process-ing. (Feng et al., 2018) adopts REINFORCE in instance selection for distant supervision which is the basis of our work.
Posterior regularization (Ganchev, 2010) is a framework to handle the problem that a variety of tasks and domains require the creation of large problem-specific annotated data. This framework incorporates external problem-specific informa-tion and put a constraint on the posterior of the model. In this paper, we propose a rule-based RE-INFORCE based on this framework.
3 Methodology
In this section, we focus on the model details. Be-sides the interacting process of the relation clas-sifier and the instance selector, we will introduce how to model the state, action, reward of the agent and how we add rules for the agent in training pro-cess.
3.1 Basic Relation Classifier
We need a pretrained basic relation classifier to de-fine the reward and state. In this paper, we adopt the BGRU with attention bag level relation clas-sifierfb (Zhou et al.,2016). Withodenoting the
output offbcorresponding to the scores associated
Pfb(r|B
k, θ b) =
exp(or) Pnr
k=1exp(ok)
(1)
whereris relation type,nris the number of
re-lation types,θbis the parameter vector of the basic
relation classifierfb andBkdenotes the input bag
of the classifier.
In the basic classifier, the sentence rep-resentation is calculated by the sentence encoder network BGRU, the BGRU takes the instance xki as input and output the sen-tence representation BGRU(xki). And then the sentence level(ATT) attention will take
{BGRU(xk1), BGRU(xk2), ..., BGRU(xk|Bk|)} as input and outputowhich is the final output of fb corresponding to the scores associated to each
relation.
3.2 Original REINFORCE
Original REINFORCE agent training process is quite similar to (Feng et al.,2018). The instance selection process for one bag is completed in one trajectory. Agent π(a|s, θπ) is trained as an
in-stance selector.
The key of the model is how to represent the state in every step and the reward at the terminal of the trajectory. We use the pretrainedfbto address
this key problem. The reward defined by the basic relation classifier is as follows:
R= logPfb(r
k|Bk, θ
b) (2)
In whichrk denotes the corresponding relation ofBk.
The state s mainly contained three parts: the representation of the candidate instance, the rep-resentation of the relation and the reprep-resentation of the instances that have been selected.
The representation of the candidate instance are also defined by the basic relation classifierfb. At
time step t, we use BGRU(xkt) to represent the can-didate instancexktand the same for the selected in-stances. As for the embedding of relation, we use the entity embedding method introduced in TransE model (Bordes et al.,2013) which is trained on the Freebase triples that have been mentioned in the training and testing dataset, and the relation em-beddingrekwill be computed by the difference of
the entity embedding element-wise.
The policy π with parameter θπ = {W, b} is
defined as follows:
Pπ(At|St, θπ) =sof tmax(W St+b) (3)
With the model above, the parameter vector can be updated according to REINFORCE algorithm (Sutton and Barto,1998).
3.3 Posterior Regularized REINFORCE
REINFORCE uses the complete return, which in-cludes all future rewards up until the end of the trajectory. In this sense, all updates are made af-ter the trajectory is completed (Sutton and Barto, 1998). These stochastic properties could make the training slow. Fortunately, we have some domain-specific rules that could help to train the agent and adopt posterior regularization framework to inte-grate these rules. The goal of this framework is to restrict the posterior of π. It can guide the agent towards desired behavior instead of wasting too much time in meaninglessly exploring.
Since we assume that the domain-specific rules have high credibility, we designed a rule-based policy agent πr to emphasize their influences on
π. The posterior constrains forπ is that the pol-icy posterior for xM I is expected to be 1 which
indicates that agent should select the xM I. This
expectation can be written as follows:
EPπ[l(At= 1)] = 1 (4)
wherelhere is the indicator function. In order to transfer the rules into a new policyπr, the KL
di-vergence between the posterior ofπandπrshould
be minimized, this can be formally defined as
minKL(Pπ(At|St, θπ)||Pπr(At|St, θπ)) (5)
Optimizing the constrained convex problem de-fined by Eq.(4) and Eq.(5), we get a new policy πr:
Pπr(At|St, θπ) =
Pπ(At|St, θπ)exp(l(At= 1)−1)
Z
(6) where Z is a normalization term.
Z = 1
X
At=0
Pπr(At|X, θπ)exp(l(At= 1)−1)
Algorithm 1 formally define the overall frame-work of the rule-based data selection process.
4 Experiment
Data: Original DS Dataset:
B={B1, B2, ..., BN}, Max Episode:M, Basic Relation Classifier:fb, Step Size:α Result:An Instance Selector initialization policy weightθπ0 =θπ;
initialization classifier weightθ0b=θb; forepisode m=1 to Mdo
forBkinBdo
Bk={xk1, xk2, ..., xk|Bk|}, Bk={};
forstep i in|Bk|do
constructsibyBk, xki, rek; ifxki ∈xM I then
constructπr;
sample actionAifollow
πr(a|si, θ0π); else
sample actionAifollow
π(a|si, θπ0); end
ifAi=1then
Addxki inBk; end
end
Get terminal reward: R= logPfb(r
k|Bk, θ0 b);
Get step delayed reward:Ri=R;
Update agent: θπ ←θπ+αP
|Bk|
i=1 Ri∇θπlogπ
end
θπ0 =τ θπ+ (1−τ)θπ0;
Update the classifierfb; end
Algorithm 1:PR REINFORCE
We tuned our model using three-fold cross val-idation on the training set. For the parameters of the instance selector, we set the dimension of en-tity embedding as 50, the learning rate as 0.01. The delay coefficientτ is 0.005. For the parame-ters of the relation classifier, we follow the settings that are described in (Zhou et al.,2016).
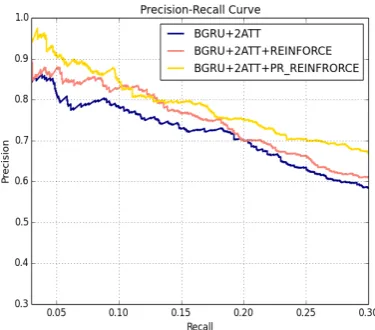
[image:4.595.319.507.72.237.2]The comparison is done in rule-based rein-forcement learning method, original ment learning and method with no reinforce-ment learning which is the basic relation classifier trained on original DS dataset. We use the last as the baseline.
Figure 3: Precision/Recall Curves
4.1 Dataset
A widely used DS dataset, which is developed by (Riedel et al.,2010), is used as the original dataset to be selected. The dataset is generated by aligning Freebase with New York Times corpus.
4.2 Metric and Performance Comparison
We compare the data selection model performance by the final performance of the basic model trained on newly constructed dataset selected by different models. We use the precision/recall curves as the main metric. Fig.3 presents this comparison. PR REINFORCE constructs cleaned DS dataset with less noisy data compared with the original RE-INFORCE so that the BGRU+2ATT classifier can reach better performance.
5 Conclusions
In this paper, we develop a posterior regular-ized REINFORCE methodology to alleviate the wrong label problem in distant supervision. Our model makes full use of the hand-crafted domain-specific rules in the trial and error search dur-ing the traindur-ing process of REINFORCE method for DS dataset selection. The experiment re-sults show that PR REINFORCE outperforms the original REINFORCE. Moreover, PR REIN-FORCE greatly improves the efficiency of the RE-INFORCE training.
Acknowledgments
Joint Research Center, Chinese Knowledge Cen-ter of Engineering Science and Technology (CK-CEST), Engineering Research Center of Digital Library, Ministry of Education. Xiang Ren’s re-search has been supported in part by National Sci-ence Foundation SMA 18-29268.
References
Nguyen Bach and Sameer Badaskar. 2007. A review of relation extraction. Literature review for Language and Statistics II, 2.
Antoine Bordes, Nicolas Usunier, Alberto Garcia-Duran, Jason Weston, and Oksana Yakhnenko. 2013. Translating embeddings for modeling multi-relational data. In Advances in neural information processing systems, pages 2787–2795.
Jun Feng, Minlie Huang, Li Zhao, Yang Yang, and Xi-aoyan Zhu. 2018. Reinforcement learning for rela-tion classificarela-tion from noisy data.
Kuzman Ganchev. 2010. Posterior regularization for learning with side information and weak supervi-sion. Ph.D. thesis, University of Pennsylvania.
Guoliang Ji, Kang Liu, Shizhu He, Jun Zhao, et al. 2017. Distant supervision for relation extraction with sentence-level attention and entity descriptions. InAAAI, pages 3060–3066.
Yankai Lin, Shiqi Shen, Zhiyuan Liu, Huanbo Luan, and Maosong Sun. 2016. Neural relation extraction with selective attention over instances. In Proceed-ings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Pa-pers), volume 1, pages 2124–2133.
Mike Mintz, Steven Bills, Rion Snow, and Dan Juraf-sky. 2009. Distant supervision for relation extrac-tion without labeled data. In Proceedings of the Joint Conference of the 47th Annual Meeting of the ACL and the 4th International Joint Conference on Natural Language Processing of the AFNLP: Vol-ume 2-VolVol-ume 2, pages 1003–1011. Association for Computational Linguistics.
Sebastian Riedel, Limin Yao, and Andrew McCallum. 2010. Modeling relations and their mentions with-out labeled text. In Joint European Conference on Machine Learning and Knowledge Discovery in Databases, pages 148–163. Springer.
Richard S Sutton and Andrew G Barto. 1998. Re-inforcement learning: An introduction, volume 1. MIT press Cambridge.
Daojian Zeng, Kang Liu, Yubo Chen, and Jun Zhao. 2015. Distant supervision for relation extraction via piecewise convolutional neural networks. In Pro-ceedings of the 2015 Conference on Empirical Meth-ods in Natural Language Processing, pages 1753– 1762.
Daojian Zeng, Kang Liu, Siwei Lai, Guangyou Zhou, and Jun Zhao. 2014. Relation classification via con-volutional deep neural network. In Proceedings of COLING 2014, the 25th International Conference on Computational Linguistics: Technical Papers, pages 2335–2344.