ContentslistsavailableatScienceDirect
Neurocomputing
journalhomepage:www.elsevier.com/locate/neucom
Deep-FS:
A
feature
selection
algorithm
for
Deep
Boltzmann
Machines
Aboozar
Taherkhani
a,∗,
Georgina
Cosma
a,
T.
M
McGinnity
a,b aSchoolofScienceandTechnology,NottinghamTrentUniversity,Nottingham,UKbIntelligentSystemsResearchCentre,UlsterUniversity,NorthernIreland,Derry,UK
a
r
t
i
c
l
e
i
n
f
o
Articlehistory:
Received5March2018 Revised12August2018 Accepted17September2018 Availableonline22September2018 CommunicatedbyJiayuZhou
Keywords:
DeepBoltzmannMachine Deeplearning
DeepNeuralNetworks Featureselection
RestrictedBoltzmannMachine Generativemodels
Missingfeatures
a
b
s
t
r
a
c
t
ADeepBoltzmannMachineisamodelofaDeep NeuralNetworkformedfrommultiplelayersof neu-ronswithnonlinearactivationfunctions.ThestructureofaDeepBoltzmannMachineenablesittolearn verycomplexrelationshipsbetweenfeaturesandfacilitatesadvancedperformanceinlearningof high-levelrepresentationoffeatures,comparedtoconventionalArtificialNeuralNetworks.Featureselection attheinputlevelofDeepNeuralNetworkshasnotbeenwellstudied,despiteitsimportancein reduc-ingtheinputfeaturesprocessedbythedeeplearningmodel,whichfacilitatesunderstandingofthedata. Thispaperproposesanovelalgorithm, Deep FeatureSelection (Deep-FS), whichiscapableof remov-ingirrelevantfeaturesfromlargedatasetsinordertoreducethenumberofinputswhicharemodelled duringthelearningprocess.Theproposed Deep-FSalgorithmutilizesaDeep BoltzmannMachine,and usesknowledgewhichisacquiredduringtrainingtoremovefeaturesatthebeginningofthelearning process.Reducinginputsisimportantbecauseitpreventsthenetworkfromlearningtheassociations be-tweentheirrelevantfeatureswhichnegativelyimpactontheacquiredknowledgeofthenetworkabout theoveralldistributionofthedata.TheDeep-FSmethodembedsfeatureselectioninaRestricted Boltz-mannMachinewhichisused fortrainingaDeep BoltzmannMachine.The generativepropertyofthe RestrictedBoltzmannMachineisusedtoreconstructeliminatedfeaturesandcalculatereconstructed er-rors,inordertoevaluatetheimpactofeliminatingfeatures.Theperformanceoftheproposedapproach wasevaluated withexperimentsconductedusingthe MNIST,MIR-Flickr, GISETTE,MADELONand PAN-CANdatasets.TheresultsrevealedthattheproposedDeep-FSmethodenablesimprovedfeatureselection withoutlossofaccuracyontheMIR-Flickrdataset,whereDeep-FSreducedthenumberofinputfeatures byremoving775featureswithoutreductioninperformance.WithregardstotheMNISTdataset,Deep-FS reducedthe numberofinput featuresbymorethan45%;itreduced thenetworkerrorfrom0.97%to 0.90%,andalsoreducedprocessingand classificationtimebymorethan5.5%.Additionally,when com-paredtoclassicalfeatureselectionmethods,Deep-FSreturnedhigheraccuracy.Theexperimentalresults onGISETTE,MADELONandPANCANshowedthatDeep-FSreduced81%,57%and77%ofthenumberof in-putfeatures,respectively.Moreover,theproposedfeatureselectionmethodreducedtheclassifiertraining timeby82%,70%and85%onGISETTE,MADELONandPANCANdatasets,respectively.Experimentswith variousdatasets,comprisingalargenumberoffeaturesandsamples,revealedthattheproposed Deep-FSalgorithmovercomesthemainlimitationsofclassicalfeatureselectionalgorithms.Morespecifically, mostclassicalmethodsrequire,asaprerequisite,apre-specifiednumberoffeaturestoretain,howeverin Deep-FSthisnumberisidentifiedautomatically.Deep-FSperformsthefeatureselectiontaskfasterthan classicalfeatureselectionalgorithmswhichmakesitsuitablefordeeplearningtasks.Inaddition, Deep-FSissuitableforfindingfeaturesinlargeandbigdatasetswhicharenormallystoredindatabatchesfor fasterandmoreefficientprocessing.
© 2018TheAuthors.PublishedbyElsevierB.V. ThisisanopenaccessarticleundertheCCBYlicense.(http://creativecommons.org/licenses/by/4.0/)
∗ Correspondingauthor.
E-mail addresses: [email protected] (A. Taherkhani), [email protected] (G. Cosma), [email protected] (T.M. McGin-nity).
1. Introduction
Thesuccessfulperformanceofdeeplearninginvarious applica-tions such as image recognition [1,2], speechrecognition [3] and bioinformatics [4], has captured considerable attention in recent literature. Deep learning(DL) methods provide promising results on problems for which conventional machine learning methods https://doi.org/10.1016/j.neucom.2018.09.040
have not made major progress, despite many attempts [1]. Con-ventional machine learning methods havelimited ability to pro-cessrawdata,andforthisreasonconsiderableeffortis tradition-allyplacedonfeatureengineering. Featureengineeringrepresents datainamannersuchthatmachinelearningalgorithmscan iden-tifypatterns andclassifythe data.An importantadvantageof DL methods over conventional approaches(e.g.Artificial Neural Net-work, Support Vector Machine, NaïveBayes), isthat DLmethods integrate thefeatureextractionandlearningprocessintoa single model,andthusfeatureengineeringisdealtwithasan integrated ratherthanaseparatetask.
Feature selection, aims to eliminate redundant and irrelevant features via different criteria. The most commonly used criteria measure therelevance ofeach featureto thedesiredoutput, and use this information to select the most important features [5,6]. Highly dependent features can be considered as redundant fea-turesandsome ofthesecanbeeliminatedduringafeature selec-tionprocess.Eliminatingirrelevantandredundantfeatures,results in a permanent reduction inthe dimensionality ofthe data, and thiscanincreasetheprocessingspeedandaccuracyoftheutilized machinelearningmethods.
Deep Neural Networks (DNNs), such as those proposed in [1,7,8] use feature extraction rather than feature selection meth-ods forextractingunderlying featuresfrombigdata.Forexample Hintonetal.[1] proposed aDNNmethodwhich reducesdata di-mensionality through a non-linear combination of all input fea-tures in a number of layers of the neural network, andthis ap-proach inspired the development ofnew algorithms in the deep learningfield [9,10,11].DNNscanlearnverycomplexrelationships between variables throughtheir highnumbers ofnon-linear ele-ments.However,ifthereexistahighnumberofirrelevantfeatures intheinputfeaturespace,thentherelationshipbetweenthese ir-relevant features may alsobe modelled.Modelling the irrelevant features acts as noise, and learning the associations between ir-relevantfeaturesnegativelyimpactsontheacquiredknowledgeof the networkabouttheoverall distributionof thedata,aswell as thecomputationaltime.Modellingtheirrelevantfeaturescanalso lead tooverfittinga model[10],becausethemethodlearns irrel-evant details from thetrainingdata andit becomesmore biased topreviously seendata[12].AtechniquecalledDropout[10] was proposed toincreasethe generalisationabilityofneural networks whichhaveahighnumberofneurons.However,amajorlimitation oftheDropoutmethodisthatitcouldretainalltheinputfeatures andneuronsthatincluderedundantandirrelevantfeatures.
The Deep Belief Networks (DBNs) proposed by Hinton and Salakhutdinov[1],andtheDeepBoltzmannMachines(DBMs) pro-posed by Srivastava and Salakhutdinov et al. [7] are two types of DNNswhich usedensely connected RestrictedBoltzmann Ma-chines (RBMs).The highnumberofprocessingelementsand con-nections, whicharise becauseofthefullconnections betweenthe visible and hidden units, increase the RBM’s computational cost andtrainingtime.Inaddition,trainingseveralindependentRBMs increases the training time [13–15]. When the scale of the net-workisincreased,therequiredtrainingtimeisalsoincreased non-linearly. Reducing the numberof input features can significantly reducethesizeoftheconstructedweightmatrix,andconsequently it can reduce the computational cost of running deep learning methods,especiallywhenalargenetworksizeisrequiredfor prac-ticalapplications[16].
Thispaperproposesa novelalgorithm,Deep-Feature Selection (Deep-FS),forembeddingfeatureselectioncapabilitiesintoDBMs, such that irrelevant features are removed from raw data to dis-coverthe underlyingfeaturerepresentationsthat arerequired for featureclassification.DBMsprimarilyuseanunsupervisedlearning method to initialize thelearning parameters ofa DNN. Then the initializedDNNisfine-tunedbyabackpropagationmethod.
Deep-FS combines the feature extraction property of DBM witha fea-tureselection methodwhich isbased onthe generative property of RBMs. RBMs are generative models and they can reconstruct missinginputfeatures.TheproposedDeep-FSusesanRBMthatis trainedduringthelearningprocedureofDBMtoimprovethe effi-ciencyofthemethodindealingwithhighvolumesofdata. Deep-FS returns a reduced subset of features and improves the deep learningmethod’scomputationalefficiencybyreducingthesizeof the constructed network. DBMs are known to have good perfor-manceforfeatureextraction,andaddingafeatureselectionability to DBMs can lead to a new generation of deep learning models which havean improved abilityto deal withhighly dimensional data.
The remainder of the paper is structured as follows: Section 2 discusses the background to the work; Section 3 pro-vides details of the proposed method; Section 4 describes the experimental results; and Section 5 provides a conclusion and futurework.
2. Background
This section provides a background on Deep Boltzmann Ma-chinesandfeatureselectionmethods.
2.1. DeepBoltzmannMachine
Deep Neural Networks (DNNs) are mainly based on stochas-ticgradientdescentandbackpropagationtrainingalgorithms.Two main techniques are used fortraining DNNs. The first technique is based on a filtering strategy and the second one is based on unsupervisedpre-training. The first filteringtechniqueis usedby ConvolutionalNeuralNetworks(CNNs)to locallyfilterinputs. Fil-tering is performedby convolving the input by weight matrices. In the second technique, information processing starts by using an unsupervised learning method. In this stage, unlabelled data canbeused.Then,theDNNisfine-tunedbyasupervisedmethod using labelled data. Deep Belief Networks (DBN) [1] and DBMs [7,17] areexampleswhichusethissemi-supervisedtechnique. Pre-trainingusing an unsupervised method improves the generalisa-tionofthetrainednetworkespeciallywhenthedatasetcontainsa smallamountoflabelleddata.ThispaperisfocusedonDBMsthat include unsupervised learningduring their first stage of training procedure.
DBMshavebeenused indifferentapplicationssuchas image-text recognition [7], facial expression recognition [18],3D model recognition [19], and audio-visual person identification [20] and belongtoagroupofDNNsthatusesapre-trainingprocedure.After thepre-trainingprocedure,DBMisfine-tuned usinglabelleddata [11,20].ADBMiscomposedofasetofvisibleunitscorresponding to input data.Additionally, thereare a network of symmetrically coupledstochasticbinaryunitscalledhiddenunits.Thebinary hid-denunitsarearranged indifferentlayers andtherearetop-down andbottomup couplings betweentwo adjacentlayers. Thereare nodirectconnectionsbetweenunitsinthesamelayer.ADBM rep-resentstheinput datainseverallayers withincreasingly complex representations.In DBMa learningprocedure isexecuted to pre-trainanumberoflayersinconjunctionwitheachother.DBMcan potentially be used to capturea complexinternal representation ofinputdata.Theinteractionofdifferenthiddenlayersduringthe initiallearninggeneratesadeepnetworkwithahighabilityto re-constructambiguousinputsthroughtop-downfeedbackusing dif-ferentinteractinglayers.Duringthepre-trainingstageofaDBM,a learningproceduresimilartoRBMsisused.TheRBMisdiscussed inSection3.
Recently, a multimodal data processing methodwas designed basedon DBMs [20].In the multimodaldata processingmethod,
initiallytwonetworksofDBMsaretrainedseparatelyonvisualand auditorydata.Thenthe outputofthetwoDBMsare combinedin ajoint layer. The representationextractedfrom thejoint layer is consideredasinputtoaRestrictedBoltzmannMachine(RBM).The RBMistrained onthe jointlayer representation.Then the entire networkisfine-tunedbylabelleddata.
The fullyinterconnectednetwork betweenthevisibleand hid-denunitsincrease the computational cost ofa DBM,andfinding amethod toreduce the numberofinput feature throughfeature selectionmethodcanreducethecomputationalcostofaDBM. 2.2.Featureselection
The amount of data available to machine learning models is increasing exponentially. The number of features in datasets is alsoincreasing,andmanyofthe featuresareirrelevant or redun-dant,andthus not neededtoimprove theperformance of a ma-chine learning model [12]. Feature Selection (FS) can accelerate thelearningprocessofa machinelearningmethodbecauseit al-lowsthe algorithm to learn using a smaller numberof features. Additionally,itcanimprovetheclassificationperformanceby pre-ventingoverfitting[12,21].Afeatureselectionmethodreducesthe numberofinputfeatures withoutsignificant decreasein the per-formanceofamachinelearningmethod[6,12,22].
Featureselectionmethodsforclassificationcanbe dividedinto three main categories: filter, wrapper and embedded methods. These approaches are used to combine feature selection with a classification model. In filter methods, feature selection is per-formedasaprepossessingstagewhichisindependentofthe clas-sificationmodel.Eachfiltermethodranksthefeatures basedona criteria, andthe highest ranked features are selected [6]. In fea-tureranking methods,therelevance ofeachfeature toaclass la-belis evaluated individually,and a weight is calculated foreach feature.Then, featuresareranked basedontheirweights andthe topfeatures withthehighest weights are selected[12,21]. Maxi-mumRelevance(MR)featureselectionisatypeoffeatureranking algorithm, where Mutual information and kernel-based indepen-dencemeasures are usually employed to calculate the relevance score[23].Featurerankingmethodsaresimpleandhavelow com-putationalcost.KiraandRendell’s“Relief” algorithm[24],andthe feature selection method proposed by Hall [25] are examples of featureselection methodsthat workbased onthedependency of featurestotheclasslabels.Althoughtheselectedtopfeatureshave thehighestrelevancetotheclasslabels,theymightbecorrelated witheach other andhaveredundantinformation,anddo not in-cludealltheusefulinformationintheoriginalfeaturesets.
The featureselectionmethodproposed byFleuret[26] consid-ersthedependencybetweeninputfeaturesusingconditional Mu-tualInformation.Themethodconsidersthe dependencyofanew feature to the already selected features and eliminatesthat fea-turesthat aresimilar tothe previously selectedfeatures, because themain idea isthat ifa feature is dependenton previously se-lectedfeaturesthenitdoesnotcontainnewinformationaboutthe class,anditcanbeeliminated.
Peng et al. [27] proposed a feature selection method called MinimumRedundancy MaximumRelevance (mRMR)to solvethe problemof feature redundancy. A subset of features which have highrelevance to class labels and which are non-redundant are selected.The mRMRmethodhasbetter performancecomparedto themethodthatonlyworksbasedontherelevantfeatures.Inthe mRMRfilteringfeatureselectionmethod,thedimensionofthe se-lectedfeaturespaceisnotsetatthestartofprocedure.
In wrapper methods, the performance of a classifier is used toevaluate a subset offeatures. Different subsets offeatures are searchedusingdifferent searchingalgorithms to findthe optimal featuresubsetthatgivesthehighestclassificationperformance[6].
ForaninitialfeaturespacedimensionalityofN,atotalof2N
sub-setscanbe evaluated,andthat becomesan NP-hardproblem. Se-quential search, and evolutionaryalgorithms such asthe Genetic Algorithm orParticle Swarm Optimization can be used to design a computationally feasible method for wrapper feature selection methods [6].Wrappershave highercomputationalcost compared tofilterfeatureselectionmethods.
With Embedded feature selection methods, the feature selec-tion procedure is integrated into the training procedure of the classifier. It reduces the computational cost compared to wrap-permethodswhereahighnumberofsubsetsshouldberetrained by the classifiers[6]. Guyonet al.[28] used Support Vector Ma-chine(SVM)asaclassifiertodesignanEmbeddedfeatureselection method. Features are evaluated duringiterations of learningand thefeatures that decreasethe separationmargin betweenclasses areremoved.
Feature selection algorithms coupled with feature extraction methods,canimprovetheperformanceofmachinelearning meth-ods[12,21].Feature selectionalgorithms canreduce theinputsto aclassifierwhichinturnreducescomputationalcostandincreases accuracy. However, classical feature selection algorithms are usu-ally designed for small datasets and thus there is an emerging need to implement feature selection algorithms which can opti-mallysearchthroughlargedatasetswiththousandsofsamplesand a highnumberoffeatures. Thispaperfocusesontakingthe idea of feature selection coupled with the feature extraction capabil-ityofdeeplearningtoimprovetheperformance ofdeeplearning models.
2.3. Deeplearningandfeatureselection
This section discusses a number offeature selection methods thatare usedwithDeepLearningmethods.Ruangkanokmas etal. [29] have used a classical filter-based feature selection approach for sentiment classification. A filter-based feature selection tech-nique,calledthechi-squaredmethod,wasproposedtoselect fea-turesand, thereaftertheselectedfeatureswere utilisedtotrain a DBN. Feature selection and training the DBN were performed in twoseparatestages.CombiningfeatureselectionandDBNtraining, hasthepotentialtoimprovetheefficiencyofaclassifier.
Ibrahim et al. [30] have also used DBN, classical feature se-lectionmethods,andtheunsupervisedActiveLearningmethodto processgeneexpressiondata.DBNwasusedtomodelhigh dimen-sionalinputdataandto extracthigherlevelrepresentationofthe inputdata.Thenstatisticalclassicalfeatureselectionmethods,such asthet-testmethod,wereusedtoselectfeaturesfromthehigher levelextractedfeatures.Ibrahimetal’s[30] methodhasusedthree cascadedindependentmoduluswithseparatecomputationalcosts. Computationalcostscansignificantlyincreasewhenthenumberof trainingdataishigh. DBNisdesignedto workwitha high num-beroftrainingdatasamplesanditrequiresfeatureselection func-tionality which is suitable fortraining large datasets, inorder to preventunnecessarycomputationalcost.
Nezhad et al. [31,32] proposed a feature selection method whichisbasedonafive-layerstackedAuto-Encoderdeepnetwork. Higher-levelrepresentative features were extractedfromthe hid-denlayerplacedinthemiddleoftheAuto-Encoder.Then,a classi-calfeatureselectionmethodbasedonthefeaturerankingmethod andrandomforestwasusedtoselectfeatures.Afterthat,a super-vised learning method was trained on the selected features and evaluated using the Mean Squared Error (MSE). The number of hiddenneuronsinthe Auto-Encoderhiddenlayers, isadjusted to optimizethe structure ofthe network basedon the obtained re-sults.Thisprocessiscontinueduntilreachinganacceptableresult. Thismethodhasuseddifferentmodulesthatincreasethe compu-tationalcostofthemethod.
Lietal.[33] proposedadeepfeatureselection(DFS)model us-ingadeepstructureofnonlinearneurons.Theyhaveuseda multi-layerperception(MLP)neuralnetworktolearnthenonlinearityof input data.Additionally,they useasparseone-to-onelinearlayer beforethe MLPtoselectinputfeatures. Theweightmatrixofthe first linear layeris a sparse matrix andthe input features corre-spondingto nonzeroweights areselected.Theirproposed feature selection methodis flexible such thatthe one-to-onelinearlayer correspondingtothefeatureselectioncanbeaddedtootherdeep learningarchitectures.Despitetheflexibilityofthemethod,its ac-curacyisnotperfectandexperimentalresultshaveshownthatthe methoddidnotoutperformtherandomforestmethod.
ZhangandWang[34] proposed afeatureselection methodfor deep learning to classify scenes. Theyconverted a feature selec-tion methodtoafeature reconstructionproblem. Inascene clas-sification task they have selected the features that are more re-constructivethandiscriminative.However,removingdiscriminative features mightreduce theclassificationaccuracyinatypical clas-sificationtask.
Deeplearningmethods,suchasDBM,areusuallycomposedof ahighnumberofnonlinearprocessingelementsthat needahigh numberoftrainingsamples.Ontheotherhand,thenumberof re-quired observations(training samples)should grow exponentially withthe number ofinput features [23,35] to traina DL method. Through featureselection, thenumberofinput features and con-sequentlythe requirednumber oftrainingsamples fortraininga DBM can be reduced. Therefore, feature selection is strongly re-quiredtohelpdeeplearningmethodstobetrainedwithless train-ingdata.Inthispaper,afeatureselection methodisproposed for DBM to improve its processing ability and reduce the computa-tionalcostoffeatureselectionforDBM.
3. Principlesoftheproposeddeepfeatureselectionmethod
In this section, the mathematical properties of RBM are first described. Then, the RBM is used to design the proposed Deep-FSfeatureselectionmethod.Theprincipleoftheproposedfeature selection methodwhichworksbasedon RBMispresentedinthe secondpartofthissection.Twoversionsoftheproposeddeep fea-tureselection algorithm are presented.In thefirst version ofthe proposed featureselectionalgorithm,the RBMisnot trained dur-ing featureselection. However, inthesecond version, theRBMis trainedduringthefeatureselectionprocedure.
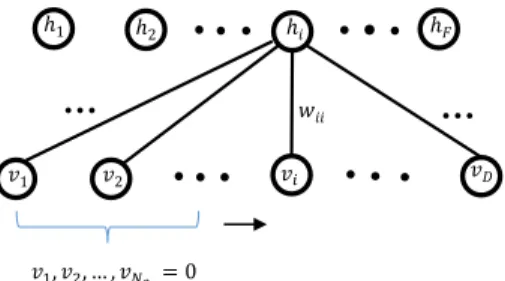
3.1. MathematicalpropertiesofRestrictedBoltzmannMachines A Boltzmann Machine (BM) is a parameterised probabilistic model.TheparametersofaBMaretrainedtoapproximatelymodel theimportantaspects ofan unknowntarget distributionbyusing availablesamplesdrawnfromthetargetdistribution.Theavailable samples that are used to train the parameters of the model are calledtrainingsamples[36].TherearetwotypesofunitsinaBM, theseare thevisibleandhiddenunits(orneurons). Thetwo sets ofunitsarearrangedintwolayers.Thefirstlayerisconstructedof visibleunits,andthehiddenunits(orneurons)are inthesecond layer.Eachneuronorunitinthefirstlayercorrespondstoaninput feature.Forinstance,iftheinputisanimagetheneachvisibleunit correspondstoapixel.Ingeneral,thevisibleunitscanaccept dif-ferenttypesofinputfeatures.Thehiddenunitsareusedtomodel complexdependenciesbetweenvisibleunits.
RestrictedBoltzmannMachines(RBMs)areaspecialcaseofthe generalBMwheretherearenointer-connectionsbetweenunitsin asinglelayer,i.e.eachunitisfullyconnectedtoallunitsinanother layerbutdoesnothaveanyconnectionswithanyunitsinitsown layer(Fig.1).RBMshaveacloseconnectionwithstatisticalphysics [37],andrepresentatypeofenergy-basedmodel.Duringtraining,
Fig.1. StructureofaRestrictedBoltzmannMachine.Itiscomposedoftwolayers ofneurons,namelythevisibleandhiddenneurons.ThereareDvisibleneuronsand FhiddenneuronsinthisRBM.
theparametersofanRBMareadjustedtogenerateamodel repre-sentingaprobabilitydistributionthatisclosetotheactual proba-bilitydistributionfromwhichthedataaredrawn.RBMshavebeen successfullyusedforprocessingbinaryandreal-value data[1,38– 40].
ConsideranRBMwithDbinaryvisibleunits.Let V beavector thatcontainsthestatesoftheDbinaryvisibleunits,i.e. V ∈{0,1}D,
and let h be a vector containing the states of the hidden units. Assume thereare Fhidden unitsin the RBM.The F dimensional hiddenvariablescanbedenotedby h ∈{0,1}F.Thejoint
configu-rationof V and h definetheenergyfunction(1).
E
(
V,h)
=− D i=1 F j=1 Wi jv
ihj− D i=1 biv
i− F j=1 ajhj (1)where Wij is a weight that connects the ith visibleunit, vi, and
thejthhiddenunit, hj.biandajarebiasesthatarerelatedtothe
ithvisibleandthejthhiddenunits.Theenergyfunctionisusedto assignajointdistributionoverthevisibleandhiddenvariablesas shownin(2).
P
(
V,h)
=1Zexp
(
−E(
V,h)
)
(2)whereZisanormalizingtermanditiscalledthepartition func-tion.Ziscalculatedby(3). Z= V h exp
(
−E(
V,h)
)
(3)Thesumiscalculatedoverall possiblepairsof(V ,h ). Let V be aDdimensionalvectorandlet h beanFdimensionalbinary vec-tor.There are2D+F differentpairs of(V ,h ) when thevisibleunits
arebinary. Theconditional probabilities P(h |V ) andP(V |h ) can be calculatedby(4) and(5). P
(
h|
V)
= F j=1 phj|
V (4) P(
V|
h)
= D i=1 p(
v
i|
h)
(5)ConditionalProbabilities(4) and(5) can bewrittenasfollows:
p
hj=1|
V =g D i=1 Wi jv
i+aj (6) p(
v
i=1|
h)
=g F j=1 Wi jhj+bi (7)whereg(x) isthe logistic function, 1/
(
1+exp(
−x)
)
. The network canbe trainedto increase itsassignedprobability to an inputby reducingtheenergyrelatedtotheinput.Thenetworkparameters areupdatedby usingthegradient-basedmethodtoreachthe ob-jective.Eq.(8) showsthederivativeofthelogprobabilityofvisibleinputsonasetofobservations,
{
V n}
Nn=1,withrespecttoaweight, Wij. 1 N N n=1∂
log(
P(
Vn)
)
∂
Wi j = Edatav
ihj −Emodelv
ihj (8)Thefirstterm,Edata[vihj],istheexpectationofvihjwithrespect
todatadistribution.Edata[vihj],showsthefrequencyinwhichboth
visibleunit,vi,andhiddenunit, hi,havethebinaryvaluesofone.
Emodel[vihj]isthesameexpectationwithrespecttothedistribution
definedbythe model.Theone-step contrastivediversion approx-imationisusedtoapproximateEmodel[vihj] [11,39].It iscalculated
byrunning one iteration ofthe Gibbssampler to reconstructthe visibleunitusing(6) and(7) toobtain(9).
1 N N n=1
∂
log(
P(
Vn)
)
∂
Wi j ≈ Edatav
ihj −Emodel ˜v
ihj (9)where
v
˜i is the reconstructed ith visible unit obtained throughGibbs sampling. Using the Gibbs sampler to approximate Emodel[vihj] is called the contrastive approximation method. A
similarprocedurecanbeusedtoextract(10) and(11) forupdating biases. 1 N N n=1
∂
log(
P(
Vn)
)
∂
aj ≈ Edata hj −Emodel ˜ hj (10) 1 N N n=1∂
log(
P(
Vn)
)
∂
bi ≈ Edata[v
i]−Emodel[v
˜i] (11)Gaussian-Bernoulli RBMs [1,7] are used for modelling real-valuedvectors. In thiscase, the visiblevector is V ∈RD, and the
hiddenunits are binary, h ∈{0, 1}F. The RBM assigns the
condi-tionaldistributionshownin(12) and(13).
p
hj=1|
V =g D i=1 Wi jσ
v
i i+ aj (12) p(
v
i|
h)
=N bi+σ
i F j=1 Wi jhj,σ
i2 (13)A Gaussian distribution with mean
μ
=bi+σ
iFj=1Wi j andvariance
σ
2i isusedformodellingavisibleunit,i.e.N
(
μ
,σ
i2)
.Thederivativeofthelogprobability ona setofobservations,
{
V n}
Nn=1,isgivenby(14),whichissimilarto(8).
1 N N n=1
∂
log(
P(
Vn)
)
∂
Wi j = Edatav
iσ
i hj −Emodelv
iσ
i hj (14)Similar to the binaryvisible unit, the first expression on the rightsideof(14) canbecalculatedfromthetrainingdataandthe secondexpression can be approximatedthrough aGibbs sampler [7].Theresultisobtainedusing(15).
1 N N n=1
∂
log(
P(
Vn)
)
∂
Wi j ≈ Edatav
iσ
i hj −Emodelv
iσ
i hj (15)The input features, vi, are usually normalized to have zero
mean,
μ
=0,andavarianceofone,σ
i=1.Thissimplifies(15) andit becomessimilar to (9). The following sections refer to (9) for bothbinaryandrealvalueinputdata.
3.2.ProposedRBM-baseddeepfeatureselectionalgorithm
An RBM is a generative probabilistic model and can generate the probability of the value of a visible unit given the states of hidden units. This property can be used to reconstruct missing
visible units.The generative property of RBMs hasbeen adopted to draw samples from the learned distribution to extract tex-turesfromimages[41].The generativepropertyofRBMshasalso beenused to samplethe missingparts ofan input image in im-agedenoisingtasks [42].The proposed Deep-FSalgorithmadopts the generative property of RBM to define a method for feature selection.
Deep-FSaims tofindasetoffeatureswithusefulinformation. Therefore,features that donot holdusefulinformationaboutthe input data are removedby the generative property of the RBM. The final selected features have a lower number of features and they reduce the complexity of the network. Feature selection is performedvia three steps 1) Initial training: of RBMon training datawithall thefeatures;2)Featureelimination:Removingextra featuresbytheinitiallytrainedRBM;and3)MainTraining: Train-ing the DBM withthe initially trainedRBM on the trainingdata whichconsistsoftheselectedfeatures. Eachofthesesteps is de-scribedintheremainderofthissection.
Step 1 - Initial training: The first step is performed via the
learningmethoddescribedinSection3.1 byusing(9).Duringthe trainingprocedure,trainingdata isinput intothe RBM.Then the outputsofhiddenneuronsarecalculatedforalltrainingdata,and thefirst expressionin(9) is calculated,i.e.Edata[vihj].Inthe next steptheinputsare reconstructedby Gibbssamplingandthe sec-ond expression in (9), Emodel[
v
˜ihj], is calculated accordingly.Fi-nally, theRBMweights are adjusted by calculatingthe difference Edata[
v
ihj]−Emodel[v
˜ihj]asshownin(9).Step2-Featureelimination:Inthesecond step,features are
eliminated through a proposed featureselection algorithm which isdescribinginthisstep.Theproposedalgorithmcanbetunedto eliminateasinglefeatureoragroupoffeaturesineachevaluation. Theproposedalgorithmstartswiththesetofallinputfeaturesand evaluatestheeffectofeachgroupoffeaturesbyusingthetrained RBM.ThelearningaiminRBMistominimizethenetworkerroror maximizethelog-likelihoodasshownin(9).Thederivativeofloss or error function of RBM can be obtained by multiplying (9) by thevalue ofminus one [11].Duringthelearningprocess, the ab-solutevalue oftheerrorisreduced.Consequently,theweight ad-justmentsare stabilized.The learningprocedureisstopped when theerrorreacheszeroorapredefinednumberoflearningepochs isreached.Theweight adjustmentcan becomezerowhenthe er-rorreacheszero.Inparticular,considertheerrorrelatedtooneof theinputfeatures.Theerrorrelatedtotheithvisibleunit isgiven
in(16) byusing(9). −N1Nn =1
∂
log(
P(
Vn)
)
∂
Wi j ≈ Emodel ˜v
ihj −Edatav
ihj (16)Thereconstructionerrorisdefinedusing(17):
ei∝
˜v
ihj −v
ihj 2 =(
v
˜i−v
i)
hj 2 ei=Emodel(
v
˜i−v
i)
2 (17)where ei is the reconstruction error relatedto input feature i. A
lowereicancausealowerabsoluteweightadjustment.
The RBM learningrule is based on feature extraction and di-mensionreduction. In RBM’sfeature extraction method,different visible inputs are combined and hidden features are extracted. Duringthislearningprocedure,thevalue ofweightadjustmentis stabilized andconsequently theabsolutevalue of errorshownin (16) isreduced.eidescribedin(17) isused todefine an
elimina-tioncriterionfortheproposedfeatureselectionmethod.
The input features are investigated to find whethera feature vi can be reconstructedby using other input features,i.e. tofind
whethertheother features contain enoughinformation to recon-struct the vi. The ith visible unit, vi, is eliminated and it is
tozero.Therefore,thevisibleunitviwiththeinitialvalueofzero
does not contribute to the output of the hidden variables (see (6) and(12)).Thehiddenfeaturesaregeneratedonlybytheother visibleinputs.Thentheithvisibleunitisreconstructedbythe hid-denunitsusing(7) forbinaryor(13) forcontinuousorrealvalue data.Theithreconstructedfeatureiscalled
v
¯i.Then(17) isusedtocalculatethe reconstruction error,e¯i=Emodel[
(
v
¯i−v
i)
2].Note that¯
v
iandv
˜ibotharereconstructedvisibleunits.However,v
¯iisgener-atedwhentheinitialvalueofviissettozero,and˜
v
iisgeneratedwhenviissettoitsoriginalvalue.
Ifthe reconstruction erroraftereliminationofithvisibleunit, ¯
ei,isequalorlessthantheoriginalreconstructionerrorofthe
vis-ible unit,ei,itbecomesevident thatthevisibleunit doesnot add
anyknowledgetothenetworkoritreducesthegeneralknowledge ofthenetwork. Therefore,removingtheithinputfeaturereduces the complexityof thenetwork andmay alsoreduce the errorof thenetwork.Additionally,reducingtheerrorcanleadtothe reduc-tionoftheabsolutevalueofthelearningerrorshownin(16). Con-sequently,the absolutevalue ofthe weight adjustmentshownin (9) isreducedandtheweightsbecomestabilized.Thus,thefeature selectionmethodcancooperativelyworkwiththeRBMweight ad-justmentmethodtoreducethefinalerror.
The proposed feature selection has been designed based on training aim of RBM. Suppose that a RBM is trained on all the input features.Theweights areupdated basedon(9).Theweight adjustmentis dependenton Edata[
v
ihj]−Emodel[v
˜ihj],a highvaluefor the expression leads to high weight adjustment and a low value leads to low weight adjustment. If the weights are ad-justedinsuch waythat theRBMcanregeneratethetraineddata, i.e.
v
i=v
˜i, then [v
ihj]=[v
˜ihj] leads to Edata[v
ihj]=Emodel[v
˜ihj].The equality leads to zero adjustment for the weights, i.e. Edata[
v
ihj]−Emodel[v
˜ihj]=0 which implies that the network hastrained perfectly. So an absolute value close to zero is desirable forthe expression Edata[
v
ihj]−Emodel[v
˜ihj], the zerovalue fortheexpression means that the network is trainedsuccessfully andit doesnotneedmoreweightadjustments.
Based on the abovementioned desired aim for training an RBM, reducing the weight adjustments by making Edata[
v
ihj]−Emodel[
v
˜ihj] close the zero, the proposed feature selection isde-signed.Thefeaturesarechecked(individuallyoringroups)to de-termine whetherremoving the features makes the RBMclose to the training aim.If the reconstructed visible unit isclose to the initialvalueofthevisibleuniti.e.
v
i=v
˜i,thelearninghasbecomeclosetoitstrainingaimanditdoesnotneedahighweight adjust-ment (because Edata[
v
ihj]−Emodel[v
˜ihj] hasa value closetozero).Therefore,ifbyremoving avisibleunit asimilar situationoccurs, i.e. the error of the reconstructed visible unit is reduced, which impliesthat the removedfeature not only doesnot add new in-formation to the network (to reconstructthe visibleunit) but it also reducesthe overall knowledge by increasing the reconstruc-tion error. Therefore,it is better to remove the visibleunit from theselectedfeaturesettomakeRBMbecomeclosetoitstraining aim. The proposed method, similar to the optimal brainsurgeon approach [43],works based on the comparison oftwo errors.In the optimalbrainsurgeonapproachthe difference inthetwo er-rorsiscreatedbypruningoflearningparameters, howeverinthe proposedmethodthedifferenceinerrorsisgeneratedby eliminat-ing the features. Then based on the derived reconstruction error thefeaturesare selected.Additionally,theproposedfeature selec-tionisdesignedtoworkwithDBM.
Theprocedureoftheproposedfeatureselectionissummarized inthepseudocodedescribedinTable1.After trainingtheRBM,it is used to calculate the reconstruction error ei for ith input
fea-turesbyusing(17) foralli.Inthewhileloop inTable1,the pro-posedmethod investigatesa group ofNe visiblefeatures.In each
iterationa groupofNe features areeliminatedby settingthe
cor-Fig.2. Ineachiteration,anumberofinputfeatures,Ne,areinvestigated,asagroup offeatureswhichcanpotentiallybeeliminated.Theinvestigatedgroupoffeatures aretemporaryremovedbysettingtheirvaluestozero,andthentheyare recon-structedbythetrainedRBM.SettingNetoahighvaluereducesthenumberof RBMreconstructioniterationsrequiredtoinvestigatetheentireinputfeatures.Ne issetatthestartoflearningandafixedNeisusedinthealliterations.
respondingvisibleunitsto zero.Investigation ofa groupofinput features whenNe>1(see Fig.2), reducesthe numberofrequired
iterationsandconsequentlyitreducestheprocessingtime.The re-constructionerrore¯kiscalculatedfortheNeeliminatedfeatures.e¯k
isthereconstruction errorofkthvisibleunit intheNeeliminated
featuresinthewhileloopinTable1.Forthektheliminatedfeature ife¯k<ek, whereek isthereconstruction errorofsame input
fea-turebeforeeliminating thefeatures, then thekth eliminated fea-tureis removedfrominput features permanently. Otherwise, the ktheliminatedfeatureisconsideredasselectedfeatures.Thewhile loopinTable1 iscontinueduntilall theinputfeaturesare inves-tigated.
InFig.2 theinvestigatedgroupoffeatures areselectedby ad-jacency.Reconstructionerrore¯iisutilizedtoevaluatetheeffectof
removing groupsoffeatures which havenot beenselected based onadjacency;andgroupsoffeatureswhich containadjacent fea-tures.e¯iis thereconstruction erroroftheithinputfeature when
Neinputfeaturesareeliminatedbysettingthemtozero.Asshown
inTable1, thee¯k<ek conditionis usedto decidewhetherto
re-movethekthfeature,i.e.avisibleunitwithalowerreconstruction errorisremovedpermanently.Therefore,visibleunitswithlower
¯
ei in the current iteration are more likely to be removed in the
next feature selection iteration. Consequently, e¯i can be used to
findthe next Ne features that should be tested forremoval. The
Ne visibleunitsthathavetheloweste¯iincurrentiterationof
fea-tureselectionareselectedforeliminationtestinthenextiteration. Inthiscase,theNe selectedvisibleunitsusually arenot adjacent
units.
AnalternativeversionofthealgorithmispresentedinTable2, wherethe RBM istrained beforefeature selection on the all the input features (similar to the first version presented in Table 1). Additionally, it is trained during the feature selection procedure usingthe reducednumber offeatures. In the alternativeversion, theRBMisfirsttrained,then,eiiscalculatedusing(17) forall
vis-iblefeatures (see Table2). After that,a setofNe features are
se-lected ascandidate features and they are temporarily eliminated fromtheinputfeature setbysettingtheir valuestozero.Then it is decided if the kth eliminated feature should be removed per-manentlybyusinge¯k.TheeliminationofNe featuresarerepeated
to investigateall the input features. After removing of every Nth featuretheRBMistrainedwiththereducednumberofinput fea-tures.Then thenewtrained RBMisused tocontinuethe feature selectionprocedure(seeTable2).
Step3 – Main training: After eliminating redundantfeatures
byusingoneofthetwoalgorithmsprovidedinTables1 and2,the trainingoftheRBMcontinuesusingtheselectedfeatures,i.e.RBM withtheremainingvisibleunitsisinitialized bytheprevious cor-responding weights andthe learning is continued.The RBM and theselectedfeaturesareusedfortrainingtheDBMsimilar tothe
Table1
PseudocodeoftheproposedfeatureselectionmethodwhentheinitiallytrainedRBMisnottrainedduringfeatureselection. TrainRBMonthetrainingdata.
CalculatetheinitialreconstructionerroreibythetrainedRBMusing(17)foralli. Nv=numbero fvisiblef eatures
i=1 Whilei<Nv:
SelectNefeaturesforevaluation. Ns= Ne
Setvk =0f ork∈{Neselected features}(eliminationoftheNe features). Calculatethereconstructionerrore¯kforeacheliminatedfeatureusing(17). fork ∈{Neeliminatedfeatures}:
ife¯k<ekthen:
Removethekthvisibleunit. Nv=Nv– 1
Ns=Ns– 1 else:
Resetvkfrom0toitsoriginalvalue,andaddittoselectedfeatures. i=i+ Ns
Table2
PseudocodeofthealternativeversionoftheproposedfeatureselectionmethodwhentheRBMistrainedduringthefeature selectionprocedure.
TrainRBMonthetrainingdata.
CalculatetheinitialreconstructionerroreibythetrainedRBMusing(17)foralli. Nv=numbero fvisiblef eatures
i=1
Nr=0;#numberofremovedfeatures Whilei<Nv:
SelectNefeaturesforevaluation. Ns= Ne
Setvk =0f ork∈{Neselected features}(eliminationoftheNefeatures). Calculatethereconstructionerrore¯kforeacheliminatedfeatureusing(17). fork ∈{Neeliminatedfeatures}:
ife¯k<ekthen:
Removethekthvisibleunit. Nv=Nv– 1
Ns= Ns−1 Nr= Nr+1 else:
Resetvkfrom0toitsoriginalvalue,andaddittoselectedfeatures. i=i+ Ns
IfNr>Nth:
TrainRBMwithcurrentreducednumberoffeatures.
CalculatetheinitialreconstructionerroreibythetrainedRBMusing(17). Nr=0
methodusedin[17].Thelearningmethodproposedin[17] hasan unsupervisedlearningprocedurewhereaDBMisinitiallytrained. Thenthelearningparameters ofthetrainedDBMareusedto ini-tializeacorresponding multilayerneural network. Finally,a stan-dardbackpropagationmethodisusedtotrainthemultilayer neu-ralnetwork.
In the proposed methods,the knowledge acquired duringthe trainingprocessoftheDBM(i.e.trainingoftheRBMasabuilding blockoftheDBM)isusedtoperformthefeatureselection,i.e.the resultofpre-trainingofDBMis usedforfeatureselection. There-fore,thecomputationcostofthefeatureselectiontaskisreduced, becausefeatureselection isperformedduringthe DBM’slearning process.
Theproposedfeatureselectionmethodusesthegenerative abil-ityof RBMtoreconstructeliminated features andthencalculates reconstruction errors to determine whether to retain or remove features.Other deeplearningalgorithms thathave thegenerative propertycanalso beused by theproposed method.Forinstance, the Deep Belief Network (DBN) is a deep learning method that uses RBM during its training procedure; therefore, the proposed
featureselectionmethodcanbeusedwithDBN.TheAuto-Encoder methodisalsoadeeplearningmethodthat reconstructsits input atthenetworkoutput.Therefore,theproposedmethodcanbe ex-tendedtoanAuto-Encoder.Theproposedfeatureselectionmethod hastheabilitytoworkwithdatathataresuitablefordeeplearning methods.
3.3. Normalizederror
Thenormalizederrorshownin(18) isusedtoevaluatethe per-formanceoftheproposedmethod.
E=
D i=1e¯i
D (18)
whereD isthe numberofvisual input features, ande¯iis the
re-constructionerrorrelatedtotheithvisibleunitcalculatedby(17).
4. Experimentalresults
Thissectionfirst presentstheexperimentalresultsofapplying theproposedDeep-FSmethodonfivebenchmarkdatasets,namely
Fig.3. Deep-FSremovesthoseperipheralpixelsthatareshownbydarkdotsonthe rightcolumn.Theremovedpixelsdonothaveusefulinformationaboutadigit.
MNIST[44],MIR-Flickr[7],GISETTE[45],MADELON[45],and PAN-CAN [46]. Datasets with a high number of features and train-ing samples were selected in orderto evaluate the accuracy and speed ofthe proposed feature selection method on high dimen-sionaldatasets.Thereafter,Deep-FSiscomparedwithotherfeature selectionmethodsusingtheMNISTdataset.Finally,Deep-FS’stime complexityisanalysedusingMNISTandrandomlygenerateddata. 4.1. ExperimentalresultsonMNIST
This section provides a brief description of the MNIST im-age dataset,and provides an explanation and illustrationof how features are selected and removed using the proposed Deep-FS method.Next,theeffectoftraininganRBMduringthefeature se-lection procedure is discussed via an empirical comparison with thetwoproposedmethodsdescribedinTables1 and2.Afterthat theeffectoftheapplicationofthetwoselectionmethodsfor eval-uating thefeatures,i.e.selectingthe N e adjacentfeatures (Fig.1), and selectingthe N efeatures that have the lowest reconstruction error, e ¯i, are investigated. Finally, the proposed feature selection method,Deep-FS,iscomparedwiththeoriginalDBM[17]. 4.1.1. MNISTimagedataset
In the first setof the experiments,Deep-FS isapplied on the MNISTimagedataset[44].MNISTcontains60,000trainingsamples and10,000testimagesamplesofhandwrittendigits.IntheMNIST dataset,eachimageiscentredina28×28pixelbox.Eachimagein theMNISTdatasetisobtainedfroman originalimagewhichisin a20×20pixelboxthroughatransformation.Thetransformationis fullyperformedinsuchawaythatthecentreofmassofthepixels ispreservedinthetwoimages.Thispre-processingisdescribedby LeCunetal.[44].Thehandwrittendigits havedifferentthickness, angularalignment,heightandrelativepositionintheimageframe. 4.1.2. IllustrationoftheselectedandremovedfeaturesontheMNIST dataset
Fig.3 illustratessomesamplesofreconstructedimagesafter ap-plyingDeep-FSdescribedinTable2 ontheMNISTdataset.Theleft column of Fig. 3 shows samples of the original images and the right-hand columnshows the reconstructed images with the re-moved pixels filledby blackpixels.Fig.3 showsthat themethod has in practice removed pixels surrounding the digits. The pe-ripheral pixels do not contain any useful information about the
Fig.4. (a)Histogramofremovedpixels.(b)Orderofindexingthepixels.The his-togramshowsthatahighnumberofpixelswhicharelocatedintheupperand lowersections(correspondingtothefirstandthelastcolumnsinthehistograms) areremoved.Theremovedpixelsdonotcontainusefulinformationaboutthedigit.
digit,andthereforewere removed.Some other pixelsinthe mid-dleareaoftheimageshavebeenremoved.Theremovedpixelscan bereconstructedbytheinformationfromneighbouringpixels,and removingthesepixelsdoesnotdestroythegeneralappearanceof thedigits.
InFig.4(a),ahistogramillustratingtheremovedpixelsfordigit 7 is shown. The pixels are indexed from 1 to 784 as shown in Fig.4(b). Thepixel located atthe top rightcorner hasthe index of1,the pixelnext toit onits rightside hasthe indexof2and so forth. The first and last columns in the histogram, shown in Fig. 4(b), have higher values than others and correspond to the pixels that are at the top and bottom of the figure, respectively. AsshowninFig.3,thereisnotmuchinformationinthosepixels, andthereforethesewereremovedappropriately by theproposed featureselectionalgorithm.Lesspixelsareremovedfromthearea inthemiddlepartofeachimageofthedigits,asshownbyshorter columnsinthemiddlepartofFig.4(b).
Inthis paperthe learningmethod proposed by Salakhutdinov andHinton[17] isusedasthebaselinelearningmethodfor com-parisonpurposes.In thisbaselinelearningmethod,a DBMis ini-tially trained, and thereafter the trained DBM is used to initial-izeamultilayerneuralnetwork.Then,astandardbackpropagation methodisusedtotrainthemultilayerneuralnetwork.
Theinputvectorhas28×28=784units.TheDBMhastwo hid-denlayers.Thefirst hiddenlayerhas500hiddenunitsandthere are 1000 hidden neurons in the second hidden layer. A similar structureisusedisused intheproposedmethodto comparethe results.The difference between the Deep-FS andDBM [23] is in thefirstlayer. Deep-FSselectsa setofinput pixels toreduce the numberofinputunits.Themaximum numberoflearningepochs arethesameforallthemethods.Forexample,theDNNsare fine-tunedfor100learningepochsusingbackpropagationmethods. 4.1.3. TheeffectoftrainingtheRBMduringfeatureselection
Table3 showstheexperimental resultswhenNe adjacent
fea-turesare usedduringthe featureselection sstage. Inthis exper-iment,theresultsoftrainingthefirstRBMduringthefeature se-lectionstage(using the algorithm described in Table 1) are com-paredwiththoseresultswhentheRBMisnottrainedduring fea-ture selection (i.e. using the algorithm of Table 2). In the first column, Deep-FS1, Deep-FS5, and Deep-FS10 are proposed
meth-Table3
ExperimentalresultsontheMNISTdatawhenadjacentfeaturesareused.
Method Nea #Inputfeatures Classificationerrorduring testingoutof10,000b
Processingtimein seconds(s)
RBMisnottrainedduringfeatureselection(SeeTable1)
Deep-FS1 1 413 101 55,872s
Deep-FS5 5 482 100 53,925s
Deep-FS10 10 488 97 53,425s
RBMistrainedduringfeatureselection(SeeTable2)
Deep-FS1 1 406 106 56,087s
Deep-FS5 5 483 95 53,989s
Deep-FS10 10 488 96 53,287s
aNumberofeliminatedfeaturesbeforeareconstruction.
bClassification–errorduringTrainingOutof60,000iszeroforallthemethods. Table4
ExperimentalresultsontheMNISTdatasetwhenthefeatureswiththelowestreconstructionerror,e¯i,areused. Method Nea #Inputfeatures Classificationerrorduring
testingoutof10,000b
Processingtimein seconds(s) RBMisnottrainedduringfeatureselection(AlgorithmshowninTable1)
Deep-FS1 1 415 103 55,134s
Deep-FS5 5 430 94 52,805s
Deep-FS10 10 430 90 52,442s
RBMistrainedduringfeatureselection(AlgorithmshowninTable2)
Deep-FS1 1 409 101 55,571s
Deep-FS5 5 416 100 53,106s
Deep-FS10 10 428 94 52,716s
aNumberofeliminatedfeaturesbeforeareconstruction.
bClassification–errorduringTrainingOutof60,000iszeroforallthemethods.
ods when Ne is set 1, 5, and 10, respectively. Ne is the number
ofpixelsthatareeliminatedbeforefeaturereconstruction.Ineach iterationofthefeatureselectionphase,Ne featuresareeliminated
and thereafter reconstructed together by RBM as explained in Section3.2 andTable1.Deep-FScanevaluatefeatures(pixels)one by one (Ne=1) or it can evaluate a group offeatures (pixels) as
describedin Section3.2 (Ne>1).Inthe later situation,insteadof
searchingbyasinglefeature,Ne=1,thesearchprocesssearchesby
agroupoffeatures ingroupsof5and10,i.e.Ne=5andNe=10,
respectively.The thirdcolumn, #InputFeatures, isthe numberof inputpixels(features)whichareselectedduringfeatureselection.
The fourth column, Classification Error During Testing, shows theclassification erroronthe testingdata(i.e.test images). Each test image is input into the network then the output of the ten neurons,each of which is corresponding to a class, on the out-put layer are investigated. The test input is assigned to a class that corresponds to the output neuron that has the maximum output value. The number of incorrect assignments are collected over 10,000 testing images and the results are reported in col-umnClassificationError during Testing. The processingtime col-umn,isthetotalrequiredtimeforthemethodstoperformtraining on60,000trainingimagesandalsototestthetrainednetworkon the10,000testingimages.Experimentswereperformedonan In-telE5-2640v42.40GHzprocessorwith64GBRAM.Table3 shows trainingRBM duringfeature selection slightly reducesthe errors whenNe>1adjacentfeaturesareused.
4.1.4. Theeffectofevaluatingthefeatureswiththeloweste¯i
Table 4 shows the results when the Ne features that have
the lowest reconstruction error, e¯i, are used during the
fea-ture selection process. The Ne features with the lowest
recon-struction errors in the current iteration of feature selection are evaluated in the next iteration of the feature selection proce-dure, and these features are usually not adjacent. Comparing Tables3 and4 revealsthat usingthe featuresthat havethe low-estreconstruction error,e¯i,duringthefeatureselectionprocedure
(Table 4)improvesthe accuracyoftheproposedfeature selection method,compared to when adjacent features are used (Table 3). Forinstance,comparingTables3 and4,theclassificationerrorfor Deep-FS10is reducedfrom97(Table3 whenRBMisnot trained)
to 90 (Table 4 when RBM is not trained). The results show that theapproachwhicheliminatesNe featureswiththelowest
recon-structionerrorhashigheraccuracycompared tothemethod that eliminatesNe featureswhichareadjacent.
Additionally,theresultsinTable4 showthatusingthefeature selection method, whichdoes not train the RBMduring the fea-tureselection procedure (see Table1), has higher accuracy com-pared to when RBM is trained during feature selection in addi-tion tothe initial trainingofRBM(see Table 2) whenNe>1. For
instance,Table 4 showsthat Deep-FS10misclassified fewerimage
samples when RBMwas not trainedduring the feature selection procedure, and the number of misclassified images wasreduced from94to90.
Inconclusion, highestclassificationaccuracyis achievedwhen a RBMis nottrained duringthefeature selection procedure,and hencewhen Deep-FS10 uses theinitially trained RBMbefore
fea-tureselection andthen performs the feature selection procedure bytheinitiallytrainedRBM.
4.1.5. ComparingDeep-FSwiththebaselineDBM
TheproposedDeep-FSmethodwascomparedagainsttheDBM [17] methodusingtheMNISTdataset.Thecomparisonconsidered theeffectofeachapproachonreducing thenumberofinput fea-tures and misclassified cases, and reduction in processing time. The baseline DBMis theone which wasoriginally introduced by Salakhutdinov and Hinton [17]. In this comparison, Deep-FS10 is
usedbecausethe experimentsinSections4.1.3 and4.1.4 revealed that removing features in groupsof 10 is a better feature elimi-nationstrategy which provides higher classification accuracy. For Deep-FS10,RBMisnot trainedduringthe featureselection
proce-dure.Additionally,features are evaluatedbased onthelowest re-constructionerror,e¯i,asitsresultsarereportedinTable4.
Table5
ExperimentalresultsontheMNISTdatasetwhenthefeatureswiththelowestreconstructionerror, ¯
ei,areusedandtheRBMistrainedduringfeatureselection.
Method #Inputfeatures Classificationerrorduring testingoutof10,000b
Processingtime inseconds(s)
BaselineDBM[17] 784 97 55,505s
Deep-FS10a 430 90 52,442s
a RBMisnottrainedduringfeatureselection,andfeatureswiththelowestreconstructionerror, ei,areused(seeTable4).
bClassification–errorduringTrainingOutof60,000iszeroforallthemethods.
The baseline DBM is trained on all 748 input pixels (see first row of Table 5). Table 5 shows that the proposed Deep-FS10 methodhasreducedthe numberofinput features. The
pro-posed method selected 430 features out of 784 total input fea-tures(see second rowofTable 5).Theresultsshow that the pro-posedmethod removesmorethan45% ofthe inputfeatures. The proposed methodreducedthenumberofmisclassifiedcasesfrom 97to 90forthebaseline DBMandthe proposed method respec-tively (seeTable5). Theresultsshow thatthe proposedmethod’s capability infinding redundantfeatures that donot add new in-formationto thenetworkandremoving theseredundantfeatures without reducingthe classificationaccuracyandit ismuchfaster than the baseline DBM. Selecting appropriate features based on the lowest error difference helps the algorithm find appropriate features, andincreasesaccuracy. Theclassification errorofallthe methodsonthe60,000trainingsamplesarezero.
Theprocessingtimeoftheexperimentfortheproposedmethod is reduced by about 5% when Ne is increased from 1 to 10
fea-tures. The processingtime isreduced from55,134 s for Ne=1to
52,442s forNe=10(see Table4 when RBMisnot trainedduring
feature selection). Eliminating a number of input features, Ne>1,
in eachinvestigation reducesthe requirednumber of reconstruc-tionprocedures whichconsequently reducesprocessingtime. The numberofselected features isincreasedby about4% when Ne is
increasedfrom1to10(seeTable4 whenRBMisnottrained dur-ingfeatureselection).Areconstructionerrorrelatedtoeach elimi-natedfeatureisincreasedwhenthenumberofeliminatedfeatures, Ne,before the reconstruction is high. Eliminating a highnumber
ofinputfeaturesduringfeatureselectionincreasesthe reconstruc-tionerrors,e¯k.Consequently,ahighnumberoffeaturesiskeptin theselectedfeaturesetwhene¯k<ekisusedforremovingthe
fea-tures(Table1).Moreover, Table5 showsthat theprocessingtime ofDeep-FS10islower thanthe baselineDBM [17].The processing
time of theproposed Deep-FS10 is52,442 swhile the processing
time ofthe baseline DBM [17] is55,505 s, i.e.it has about5.5% lower processingtime.The low numberofselectedfeatures, 430, forDeep-FS10comparedtothe initial784featuresthat shouldbe
processedbythebaselineDBMreducestheprocessingtimeofthe proposedDeep-FS10.
4.2. ExperimentalresultsontheMIR-Flickrdataset
Inthe secondset ofexperiments,the performanceofthe pro-posedDeep-FS1 method,that wasusedforMNISTdatainSection
4.1, is tested using the MIR-Flickr dataset obtained from the Flickr.com social photography site [7,47]. The MIR-Flickr dataset containsonemillionsamples.Eachinputsampleconsistsofan im-agewhichmayhaveuser-definedimagetags.Additionally,someof the input samples,image andusertext tags, are labelled. Outof the one million input samples,only25,000imageswith user as-signed tagsare annotatedwithlabelsandthe remaining975,000 samples are unlabelled.Labelling large datais a very demanding task. The images and their corresponding user assignedtags are annotatedby38labelsincludingobjectandscenecategoriessuch
Fig.5. SamplesfromtheMIR-Flickrdataset.Thetopwordsaretheannotationsand thewordsbehindeachimagearetagswrittenbyusers.Thefirstimagehasnotags. Mostoftheimagesbelongtovariousclasseswithdifferentannotationsasshown inthetoprow.
astree,bird,people,clouds,indoor,sky,andsunset.Eachsample canbelongtoanumberofclasses.
TheunsupervisedlearningabilityofRBMs,whicharethe build-ing blocks of a DBM, enables DBMs to be trained using a huge number of unlabelled data, and RBMs and DBMs are known for their suitability in training unlabelled data. After initial training, a limited number of labelled data can be used for fine-tuning the model.Out of the 25,000 labelled samples in the MIR-Flickr dataset,10,000samplesareusedfortrainingandanother5000 la-belledsamplesare usedasavalidationset.Theremaining10,000 samplesareusedduringthetestingstage [7].Eachsampleinthe MIR-Flickrdatasethastwosetsoffeatures,i.e.textandimage fea-tures.First,thetextfeaturesaredescribedthentheimagefeatures areintroduced.
Manywordswhichappearintheuserdefinedtags arenot in-formativeandsomeofthemarefiltered.Toorganizethetextinput, a dictionaryis generated.The dictionary containsthe 2000most frequenttags,whichwereextractedfromasetofusertagsfound inonemillion samples.Then each textinput isrefined, andeach text input containsonlythe text inthedictionary. Therefore, the textdataofeach sampleisrepresentedbythevocabulariesofits usertags thatare inthe dictionary(i.e. thetags are restrictedto theones inthe dictionary). Additionally, differentfeature extrac-tionmethodsareusedtoextractrealvaluefeaturesforeachimage. InthepreviousexperimentontheMNISTdataset,(seeSection4.1) theinputshadbinaryvalues,however,herethereareanumberof realvaluefeaturesforeachimage.Intotal,3857featureswere ex-tractedforeach image [7].The followingfeatures were extracted foreach image[7]:1.ConcatenatingPyramidHistogramofWords (PHOW) (2000 features), 2. Gist (960 features),3. Colour Layout Descriptor(192 features),4.Colour StructureDescriptor (256 fea-tures), 5. Scalable Colour Descriptor (256 features), 6. Edge His-togramDescriptor (150 dimensions), and7. HomogenousTexture Descriptor (150 features). The different features extract different aspects of an image. Three samples from MIR-Flickr dataset are shownin Fig.5. The top rowof Fig.5 showsthe annotations or labelsandthebottomrowshowstheusertags.
Table6
Classificationresultsusingfeaturesextractedfromthefirsthiddenlayerof imagepathway.
Layer MAP Prec@50 Imagefeatures
BaselineDBM[7] 0.476± 0.003 0.756 ±0.005 3857 ProposedDeep-FS 0.478±0.003 0.756 ±0.008 3082
Table7
Classificationresultsusingfeaturesextractedfromjointhiddenlayer.
Layer MAP Prec@50 Imagefeatures
BasedDBM[7] 0.622 ± 0.003 0.880 ±0.005 3857 ProposedDeep-FS 0.622 ± 0.003 0.879± 0.005 3082
The DBM used in [7] is employed as the baseline learning methodforcomparison,fortheMIR-Flickrimage-textdatainthis setofexperiments.Thereare3857Gaussianvisibleunitswithreal numberoutputvaluesforimage input,andthere aretwo hidden layersforimage pathwayeach ofthemcomposed of1024binary units. A Replicated Softmax model [7] with 2000 input units is usedfortextinputs.Thetextpathwayiscompletedbytwohidden layerseachofwhichhas1024binaryunits.Ajointlayerwith2048 binaryhiddenunitsisplacedaftertheimageandtextpathways.
Each sample, image withcorresponding user text tags, found in the MIR-Flickr dataset can belong to a number of classes. MeanAveragePrecision(MAP)andprecisionattop-50predictions (Prec@50)aretwostandardmethodscommonlyadoptedto evalu-atemulti-label classificationtasks [7]. MAPandPrec@50are also usedinthisresearch toevaluatetheclassificationperformance of the proposed Deep-FS and the baseline DBM on the MIR-Flickr data.
Deep-FSusesthefirst5000batchesofdatawithwholefeatures totrain theRBM.There are128 samplesineach batch. Then the proposedfeatureselectionmethodusesthetrainedRBMtoselect features. The learningprocess is continuedwith the reminder of thetrainingdatabyusingtheselectedfeatures.Extractedfeatures fromthefirsthiddenlayeroftheimagepathwayareclassifiedby thelogisticregressionmethodtoshowtheeffectofthefeature se-lectionmethodontheclassificationresults.Theresultsareshown inTable6.Deep-FSreturnedahigherMAPthanthebaselineDBM method,achievingvaluesof0.478and0.476respectively.There is [email protected] image features. The proposed feature selection method removes 775features to reduce the number ofinput features. The classi-ficationresultsonthehiddenfeaturesextractedfromjointhidden layerareshowninTable7.Deep-FSremovesfeatureswithout af-fectingtheclassificationperformanceofthetestingdata.
InFig.6 theerrorsoftheDeep-FSmethodonthetrainingand evaluation sets are compared to those of the baseline method, DBM [7], across various learning steps. In each learning step a newbatchof dataistrained.Eq.(17) is usedto calculatethe er-rors.Until step5000thetwo methodsusetheall thefeatures so theyreachthesameerrorlevelsof0.4228 and0.2658ontraining andevaluationsets respectively.In thenext steps ofthelearning process,theerrorsofboth methodsarereduced,however,the er-ror drops faster andreaches a final lower value when using the proposedmethod.Forinstance,theproposed methodreachesthe level of 0.2590 on the training set which is lower than that of the base method, i.e.0.3075 (Fig. 6(a)) at the end of the learn-ingsteps.Similarly,theproposedmethodreachestheerrorlevelof 0.1745comparedto0.2278 forthebaseline methodonevaluation set(Fig.6(b)).TheerrorsfortheproposedDeep-FSmethodandthe baselineDBMare34%and14%lower thantheerroratstep5000, i.e.0.2658,respectively.Thefeatureselectionmethodremovesthe redundantandirrelevantfeaturesandconsequentlyprevents
over-Fig.6. ComparisonoftheerrorofDeep-FSagainsttheerrorofthebaselineDBM [7]on(a)trainingand(b)validationsetsatdifferentlearningstepsusingthe MIR-Flickrdataset.Ineachlearningstepabatchoftrainingdataistrained.Theerrors arereportedafterevery5000steps.Theproposedmethodsignificantlyreducesthe errors.
fittingthetrainingdata.Theproposedmethodfinds775irrelevant andredundantfeatures.Theremovedfeaturesconstructabout20% oftheinitial3857features.
4.3. ExperimentalresultsontheGISETTEdataset
TheGISETTEdataset[45] isabenchmarkdatasetgeneratedfor binaryclassificationtasks.GISETTEisahandwrittendigit recogni-tion dataset,which waspart ofthe Advancesin Neural Informa-tion Processing Systems (NIPS 2003) feature selection challenge. The GISETTE training data contains6000 samples and5000 fea-tures. TheGISETTE learning taskis abinary classification taskto discriminatebetweentwo confusablehandwrittendigits of4and 9.In GISETTE, each digit has a dimension of28×28. The pixels
Table8
PerformancecomparisonontheGISETTEdataset.
Method #Features 10-foldclassification accuracy(%) Classifiertraining timeinseconds(s) Nofeature selection 5,000 92.9 262s ProposedDeep-FS 951 93.5 47s Table9
PerformancecomparisonontheMADELONdataset.
Method #Features 10-foldclassification accuracy(%) Classifiertraining timeinseconds(s) Nofeature selection 500 79.4 6.34s ProposedDeep-FS 214 80.3 1.90s
are normalised onthe datasettoput their valuesinthe [0,1] in-terval. Thefeaturesetcontainsthenormalizedvaluesofpixelsin addition to other features whichhave usefulinformationfor dis-criminatingbetweendigits4and9.IntheexperimentonGISETTE, 6000samplesareusedtotrainandtesttheproposedmethod.The Decision Tree classifier was adopted and k-fold cross validation with k=10 wasapplied to evaluate the performance of the pro-posed feature selection method. The Decision Tree classifier was selected experimentally as it hadachieved the highest classifica-tionaccuracycomparedtoalternativeconventionalmachine learn-ing methods. Additionally,experiments showedthat the Decision Tree classifier was trained in shorter time compared to mostof theothermethods.Thenumberofsplits intheDecisionTreewas experimentallyselectedandsetto30.Table8 showsthatthe pro-posedDeep-FSreducesthenumberofinputfeaturesfrom5000to 951,i.e.reductionof81%ofinputfeatures.Theaccuracyofthe De-cisionTreeclassifierontheselectedfeaturesis93.5%.Itsaccuracy whenusingthe entireset offeatures decreasedto 92.9%.Usinga smallersubsetcomprisingtheselectedfeaturesreducedthe train-ingtimeoftheclassifier(seeTable8).Theclassifierneededabout 262 s to train using all 5000 features, however,when the train-ing wasperformed usingthe selectedfeatures (i.e. 951) features, itonlyneeded47stotrain.Theproposedmethodreduced82%of theclassifier’strainingtime(seeTable8).
4.4. ExperimentalresultsontheMADELONdataset
The MADELON dataset [45] is an artificialdataset, which was part of the Advances in Neural Information Processing Systems (NIPS 2003) feature selection challenge. This is a two-class clas-sification problemwithcontinuous inputvariables. The challenge is that the problemis multivariate and highlynon-linear. In this experiment,2000trainingsamplesfromtheMADELONdatasetare used, andeach samplehas500 features. The performance ofthe proposed Deep-FS method on the MADELON dataset is reported inTable 9.Deep-FSreducesmorethan 57%ofinput features and achieves a higher classification accuracy, i.e. 80.3%. Additionally, it reduced the computationtime of trainingthe classifier, as re-portedinTable9.Itreduced70%oftheclassifiertrainingtime.In summary,higherorvery closeaccuracyisachievedusingamuch smaller set offeatures, but inlesstime (i.e.4.44 fewer seconds) whenDeep-FSisused.
4.5. ExperimentalresultsonthePANCANdataset
PANCAN[46] wasobtainedfromTCGAPan-CancerClinicalData Resource (TCGA-CDR) [48]. The data contains 801 data samples frompatientswith5typesoftumours:COAD, LUAD,PRAD, BRCA andKIRC.Eachpatientsamplecontains20,531features.Atotalof
264featureshadthesamevalueforallsamplesinthedatasetand thesewereremoved,resultinginatotalnumberof20,264features. Table10 shows thatDeep-FShas reducedthe number offeatures from20,264 to 4765, i.e.76.49% reduction in the number of in-putfeatures,andincreasedthe accuracyfrom97.1%to98.5%. 10-foldcrossvalidationwasappliedtoachievetheresultsforeachof thetwosituationsreportedinTable10.Importantly,theresults re-vealedsignificantreductioninthetimeneededbytheclassifierto trainusingtheselectedfeatures.Training ontheselectedfeatures needed 59.19 s compared to 400.39 s when all the features are used.Hence,trainingonthe selectedfeatures was341.20s faster (i.e.itreduced85%oftheclassifier’strainingtime).
4.6.ComparisonofDeep-FSwithotherfeatureselectionapproaches In the following experiments the proposed Deep-FS is com-paredwithotherfeature selectionapproaches.The comparisonis performedinthefollowingtwosteps.Step1:Selectfeaturesusing theproposed andother existingfeature selectionalgorithms;and Step2:TrainDBMusingtheselectedsubsetoffeatures.
Step1:Initially,theproposedDeep-FSmethodandthreeother feature selection methods were separately applied to the MNIST dataset.Eachfeatureselection methodreturneda selectedsubset of features, and then the selected features were used to train a DBM(resultsare presentedinTable11).Please note thatmostof theconventionalexisting featureselection algorithmsare compu-tationally veryexpensiveandnot suitable forlargedata.The Ge-neticAlgorithm(GA)forfeatureselectiondescribedin[49],the In-finite Feature Selection (InfFS) [50], and the Laplacian Score(LS) forfeatureselection[51] methodswerecomparedtoDeep-FS.The GA-based mRMR freature selection algorithm [49] calculates the joint mutual information matrix between pairs of features and thismakesthealgorithmimpracticalforhighdimensionaldatasets. InfFS[50] isafilterfeatureselectionmethodthatselectsthemost importantfeaturesbasedontheirranks.Allotherfeaturesare con-sideredtoevaluate thescoreof afeature.InfFS mapsthe feature selectiontasktoagraphandthefeatureselectionisconsideredas asubsetoffeaturesthatmakeapathinthegraph.Acostmatrixis constructedtogivepairwiseassociationsbetweenthefeatures us-ingvarianceandcorrelation ofthefeatures.Thematrixisusedto evaluaterelevanceandredundancyofafeaturewithrespecttoall theotherfeatures.LaplacianScore(LS)forfeatureselection[51] is anotherwell-knownmethodwiththeabilityoffindingfeaturesin unlabelleddata [52,53].The LSmethod usesa nearest neighbour graph to evaluate local geometric structures and selects features basedontheconstructedgraph.
Step2:The selected features identified by each feature selec-tionmethodareusedtotrainDBMs.TheweightsofeachDBMare initializedrandomly,thentheDBMistrainedontheselected


![Fig. 6. Comparison of the error of Deep-FS against the error of the baseline DBM [7] on (a) training and (b) validation sets at different learning steps using the MIR- Flickr dataset](https://thumb-us.123doks.com/thumbv2/123dok_us/9772683.2469012/11.892.59.413.232.285/comparison-baseline-training-validation-different-learning-flickr-dataset.webp)