717 | P a g e
A Confidentiality protect and copy determent content
based Image renewal design in cloud computing
1
Kakaraparthi.Vasantha Kumari
,
2Dr .Indraneel Sreeram
1Pursuing M.Tech (SE),
2Professor, Dept. of Computer Science and Engineering,
St.Ann's college of Engineering and Technology, Chirala.
ABSTRACT
The local touchy visual applications have profited from the upheaval of web pictures, all things considered the
estimated and inadequate labels erratically gave by clients, in light of the fact that the thistle of the rose, may
hamper the execution of recovery or compartmentalization frameworks anticipating such information. Amid this
paper, we tend to propose a remarkable neighborhood touchy low-rank model for picture label fulfillment
,which approximates the overall nonlinear model with an arrangement of local straight models. To adequately
imbue the idea of neighborhood affectability, a direct and viable pre-handling module is intended to discover
suitable delineation for learning parcel and a world accord regularize is acquainted with moderate the peril of
over fitting. In the mean time, low-rank lattice determination is used as local models, wherever the local
unadulterated arithmetic structures square measure protected for the low-dimensional representation of every
tag and tests. Inside and out experimental assessments directed on 3 datasets show the viability and strength of
the anticipated method, wherever our procedure beats past ones by an outsized source
I. INTRODUCTION
The approach of the extensive data period has seen relate dangerous development of the visual data that has
produced a few .Visual applications to get ready, break down, and recover these photos. Be that as it may, client
marked visual data, comparative theme genuine that square measure transferred and partook in Flicker, square
measure in some cases identified with general and inadequate labels. This may make dangers the recovery or
compartmentalization of those photos, dispensing them extreme to be gotten to by clients. Tragically, missing
mark is unavoidable inside the manual naming area, since it's unworkable for clients to name each associated
word and maintain a strategic distance from every feasible disarray, due to the presence of equivalent words and
client inclination. Accordingly, picture label culmination or refinement has developed as a stock inside the
mixed media framework group.
In the situation of picture label fruition, every one of the photos are thought to be somewhat labeled, suppose
picture whose genuine marks are could exclusively be labeled as, whilec1 and c3 are missing. The objective of
picture label finishing is to precisely recuperate the missing marks for every one of the photos. An exorbitance
of calculations are created to deal with this issue, among that few analysts investigate the knowledge that
associated labels female horse normally synchronal with each other, and picture wear raying comparative
718 | P a g e
bolstered on direct suspicions; along these lines the acquired models are limited due to their inadequacy to catchmuddled relationship designs.
To alter nonlinearity and keep the machine intensity at indistinguishable time, we tend to turn to a territory
touchy approach, with the conviction that though nonlinear universally, the model might be straight locally, that
allows the apparatus of direct models once tests zone unit confined to singular areas of the data house.
Following this thought, the entire data house is part into various areas, inside everything about an area straight
model is learnt, bringing about a model meant as neighborhood Sensitive Low rank Reconstruction (LSLR). The
primary issue including in such a zone delicate structure is the best approach to direct reason full data parcel that
is nontrivial inside the label fruition circumstance, since the space between tests, that is critical to most segment
ways, is phenomenally inconsistent once estimated by low-level choices and fragmented client gave labels. To
deal with such issues, a clear and powerful pre-handling module is planned, by taking out the angle effect of
every high-recurrence and uncommon labels, and learning for each example the low-dimensional representation
proper for parcel.
To our data, we tend to square quantify the essential to imbue the prospect of locale affectability into the
circumstance of picture label finish, and our principle commitments square measure condensed as takes after.
We propose a zone delicate low-rank model for picture label culmination ,that approximates the overall
nonlinear model with a gathering of local straight models, by that confounded relationship structures will be
caught. A few expansions square measure acquainted with change the combination of neighborhood
affectability and low-rank factorization, together with a clear and powerful pre-handling module and a world
accord regularize to alleviate the risk of over fitting.
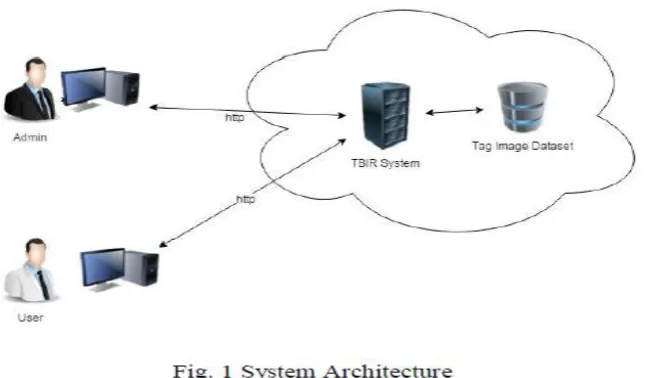
II. LOCALITY SENSITIVE FRAMEWORK
Assume we tend to are given n part tagged pictures, whose visual feature matrix and initial tag matrix is denoted
as X , severally, wherever d is that the dimension of visual feature, and m is that the size of our vocabulary. Our
goal for tag completion is to recover the entire tag matrix Y. The projected technique achieves this via many
modules, as well as pre-processing, information partition, and therefore the learning of native models. As
sketched in Fig. 1(a), the low-dimensional illustration is learnt for every sample within the part of
pre-processing. Based on this novel illustration, all the photographs within the dataset are divided into multiple
teams, so samples among similar cluster are semantically connected. As illustrated in Fig. 1(b), a neighbor hood
model is then established by factorizing the entire matrix Yi into a basis matrix WI and a thin constant matrix
719 | P a g e
Fig. Framework of the proposed LSLR. (a) Shows our pre-processing module, which learns a low-dimensionalimage level representation (W0)suitable for partition. (b) Illustrates the locality sensitive framework, where the
initial tag matrix D is partitioned into c clusters, then a local linear model is learnt for each cluster, through
matrix factorization. The final completed matrix is obtained by integrating the resulted Yi s.
III. PRE-PROCESSING AND DATA PARTITION:
This area presents firmly associated modules: preprocessing and data parcel. As specified in Section the
objective of data parcel is to isolate the entire example house into a gathering of local neighborhoods or groups,
such examples at interim disjoin bunch region unit semantically associated. Be that as it may, as we have a
tendency to found in our analyses, coordinate segments once in a while neglect to think of significance groups,
regardless of abuse visual choices or deficient starting labels. The basis behind is straight forward to get a
handle on. Incidentally, picture don raying people could likewise be isolated into the groups in regards to
shoreline or building per their experiences, especially once people is absent. On the contrary hand,
notwithstanding genuinely portraying entirely unexpected substance appreciate bear, fox or mountain, tests as
initio marked as snow could likewise be arranged into consistent group with respect to snow, since remove is
twisted once their frontal area labels zone unit truant. Amid this paper, a bunch is named as a chaotic group if its
photos don't appear to be genuinely semantically associated and a minimized bunch generally.
To lighten the peril of creating messy groups, a couples dance pre-handling module is utilized to be told the
low-dimensional representation that is less correlative, as appeared in Fig. 1(a).Our initiation is to dispense with
the viewpoint consequence of each the high-recurrence and uncommon labels by evacuating their relating
segments inside the underlying label framework, since they scarcely appear in light of the fact that the
fundamental substance of the photos. Incidentally, sky at times identifies with foundation rather than closer
view, however the training al technique may consider it Associate in nursing inborn example as a result of its
high-recurrence, accordingly saving its information inside the low-dimensional outline. To spot labels that
require to be expelled, a few edges region unit physically set bolstered the checks of the underlying tags.1The
720 | P a g e
is comprehended as column shrewd low-dimensional delineation for each example, so it is uniquely designed tosuit our request. In particular, we have a tendency to tackle (3) for the total dataset, and use the preface
framework W0 on the grounds that the novel delineation and sustain it into the information segment module,
with the subscript"0" signifying the whole dataset. Its esteem taking note of that here we tend toilkemis
treatment W0 over average mark change ways respect group.
IV. IMPLEMENTATION ANALYSIS:
In this section, several main parameters are analyzed, including η, γ, λ and the basis number k. We empirically
set an identical value of k for Corel5K and IAPR TC12, and only test its influences on Corel5K and
Flickr30Concepts. As shown in Fig. 2(a), the proposed method performs better as η gradually increases, then its
performance begins to decline when increasingly larger values are used. The curve in Fig. 2(b) corresponding to
γ exhibits a similar tendency. Next, to examine the influence of λ, which controls the strength of our global
consistency regularization, different values are tested on two clusters one is a cluttered cluster, and the other one
is a compact cluster containing initial tags including bridge, arch, reflection and water.
when λ = 0, the local model for the cluttered cluster is over fitted, leading to poor results. However, its
performance gradually improves with λ growing larger, while the performance for the other cluster remains
unchanged. This indicates that the model for the cluttered cluster is refined by global information, which
justifies the necessity of introducing global consistency regularization. However, if λ becomes too large, the
performance would degrade as well due to the loss of flexibility. Meanwhile, since our method employs a matrix
factorization scheme, it is necessary to specify an appropriate value for k, which is the number of columns in the
basis matrix. As illustrated in Fig. 4, the proposed method can achieve fairly good performance
With k = 20 for Corel5K (with 260 tags) and k = 50 for Flickr30Concepts (with 2513 tags). The impressive
reduction of dimensions benefits from our locality sensitive strategy, which implicitly partitions tags into groups
when performing clustering among samples.
V. CLUSTER ANALYSIS
In this section, many main parameters are analyzed, as well as η, γ, λ and therefore the basis range k. we tend to
by trial and error set a standardized worth of k for Corel5K and IAPR TC12, and solely take a look at its
influences on Corel5K and Flickr30Concepts. As shown in Fig. 2(a), the projected technique performs higher as
η bit by bit will increase, then its performance begins to say no once more and larger values are used. The curve
in Fig. 2(b) comparable to γ exhibits an identical tendency. Next, to look at the influence of λ, that controls the
strength of our world consistency regularization, totally different values are tested on 2 clusters, one may be al it
red cluster, and therefore the alternative one may be a compact cluster containing initial tags as well as bridge,
arch, reflection and water. As shown in Fig. 3(a), when λ = 0, the native model for the littered cluster is over
fitted, resulting in poor results. However, its performance bit by bit improves with λ growing larger, whereas the
performance for the opposite cluster in Fig. 3(b) remains unchanged. This means that the model for the littered
cluster is refined by world info that justifies the requirement of introducing world consistency regularization.
721 | P a g e
Meanwhile, since our technique employs a matrix factorization theme, it's necessary to specify Associate innursing acceptable worth fork, that is that the range of columns within the basis matrix. As illustrated in Fig. 4,
the projected technique are able to do fairly smart performance with k = twenty for Corel5K (with 260 tags) and
k = fifty for Flickr30Concepts (with 2513 tags). The spectacular reduction of dimensions edges from our
neighborhood sensitive strategy, that implicitly partitions tags into teams once activity agglomeration among
sample Cluster Analysis: In this section, we tend to analyze the influences of some parameters in agglomeration,
as well as the quantity of clusters c and therefore the rate, denoted by ρ. Here the Corel5K dataset and
Flickr30Concepts dataset are evaluated, since they're naturally organized by multiple linguistics topics. In
keeping with Fig. 5, the simplest cluster range are c = twenty for Corel5K and c = twenty five for
Flickr30Concepts, severally. With smaller c, the benefits of neighborhood sensitivity are weakened.
However, as c becomes larger, the possibility of encountering littered clusters would greatly increase, resulting
in vital performance deterioration. In observe, c may be calculable from previous information. Take
Flickr30Concepts as Associate in Nursing example; providing its pictures are organized by thirty keywords and
a few pictures are related to multiple ideas, Associate in whole number between twenty and thirty are going to
bean affordable estimate of c. Another necessary issue is that the rate, that has been fastened to ρ = zero.4
antecedently. During this section, totally different values of ρ are examined for agglomeration (D used for (3)
remains unchanged). the results obtained while not pre-processing are shown in solid lines, and results obtained
while not the primary step of pre-processing are shown in colored dash lines.
Additionally, our results obtained with ρ = zero.4 are shown in black dash lines. In keeping with , with the
assistance of preprocessing, the typical exactness achieved by our technique is appreciate the case of ρ = zero.32
for Corel5K and ρ = zero.3 for Flickr30Concepts, that directly verifies the effectiveness of our pre-processing
module. Meanwhile, while not the removal of high-frequency and rare tags, the low-dimensional illustration
learnt in pre-processing ends up in terribly restricted improvement, that coincides with our analysis in Section
III-B that these tags could hamper the training of the new illustration. Finally, to grant Associate in nursing
intuitive impression on however may the projected approach approximate the nonlinear reconstruction structure
during a neighborhood sensitive manner, many sample clusters are shown and wherever samples related to
water (one of the foremost frequent tags in Corel5K) are partitioned off into totally different subsets. Note that
the linguistics ambiguity caused by this high-frequency tag is remarkably eased, which might positively enhance
the aptitude of our technique, since ill beach inside the primary cluster.
722 | P a g e
VII. CONCLUSION
In this paper we have a tendency to propose a part sensitive low-rank model for image tag completion. The
planned technique will capture complicated correlations by approximating a nonlinear model with a set of native
linear models. To effectively integrate neighborhood sensitivity and low-rank factorization, many variations
area unit introduced, as well as the planning of a pre-processing module and a world agreement regularized. Our
technique achieves superior results on 3 datasets and outperforms permeable ways by an oversized margin.
VIII. FUTURE SCOPE
As future work we plan to explicitly address orthogonal issues in our design, such as key sharing, user access
control, and reliability issues. We also plan to investigate the applicability of our methodology – i.e. the
separation of information contexts when processing data (color and texture in this paper) – in other domains
beyond image data.
REFERENCES
[1] D. M. Blei and M. I. Jordan, “Modeling annotated data,” in Proc. Int.ACM SIGIR Conf. Res. Develop.
Inform. Retrieval, 2003, pp. 127–134.
[2] D. Putthividhy, H. T. Attias, and S. S. Nagarajan, “Topic regression multimodal latent dirichlet
allocation for image annotation,” in Proc. IEEEConf. Comput. Vis. Pattern Recog., Jun. 2010, pp. 3408–
3415.
[3] C. Yang, M. Dong, and J. Hua, “Region-based image annotation usesasymmetrical support vector
machine-based multiple-instance learning,” in Proc. IEEE Conf. Compute. Vis. Pattern Recog., Jun.
2006, vol. 2, pp. 2057–2063.
[4] A. Makadia, V. Pavlovic, and S. Kumar,“A new baseline for image annotation,” in Proc. Eur. Conf.
Comput. Vis., 2008, vol. 5304, pp. 316–329.
[5] M. Guillemin, T. Mensink, J. Verbeek, and C. Schemed, “TagProp: Discriminative metric learning in
nearest neighbor models for image autoannotation,” in Proc. IEEE Int. Conf. Compute. Vis., Sep.–Oct.
2009, pp. 309–316.
[6] Y. Verma and C. Jawahar, “Image annotation using metric learning in semantic neighborhoods,” in
Proc. Eur. Conf. Comput. Vis., 2012, pp. 836–849.
[7] K. Q. Weinberger and L. K. Saul, “Distance metric learning for large margin nearest neighbor
classification,” J. Mach. Learn. Res., vol. 10, pp. 207–244, 2009.
[8] S. S. Bucak, R. Jin, and A. K. Jain, “Multi-label learning with incomplete class assignments,” in Proc.
IEEE Conf. Comput. Vis. Pattern Recog., Jun. 2011, pp. 2801–2808.
[9] Y. Verma and C. Jawahar, “Exploring SVM for image annotation in presence of confusing labels,” in
Proc. Brit. Mach. Vis. Conf., 2013.
[10] H.-F. Yu, P. Jain, P. Kar, and I. S. Dhillon, “Large-scale multilabel learning with missing labels,” CoRR,
723 | P a g e
[11] M. Chen, A. Zheng, and K. Weinberger, “Fast image tagging,” in Proc. Conf. Mach. Learn., 2013, pp.
1274–1282.
AUTHOR DETAILS
Kakaraparthi.Vasantha Kumari,
pursuing 2nd M.Tech(SE), Computer Science and Engineering department in St.Ann's
college of Engineering and Technology, Chirala. She completed her B.Tech in Computer
Science and Engineering department in 2015 in St Ann's Engineering College.
Dr. Indraneel Sreeram
presently working as Professor in Computer Science and Engineering department in
St.Ann's college of Engineering and Technology, Chirala. He Completed his Ph.D. in
Computer Science & Engineering from Acharya Nagarjuna University, Guntur. He is
having 15 years of teaching experience. He guided 15 UG projects and 2 PG projects. He
published 8 international journal papers and presented in 2 National Conferences. His
research interests are in wireless sensor networks, Network Security, Data analytics,
Internet of Things.