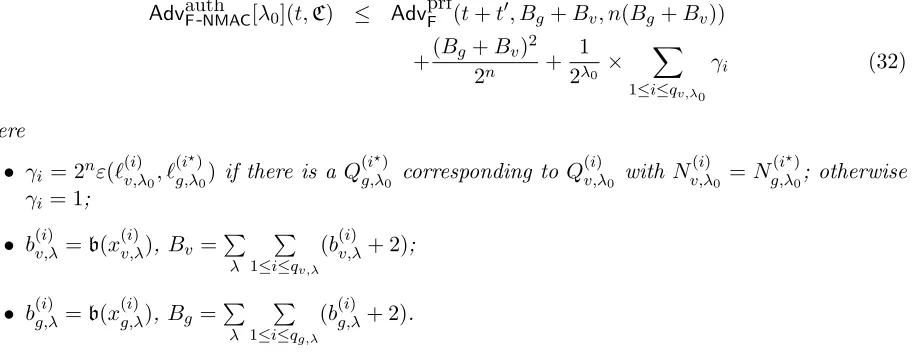Variants of Wegman-Carter Message Authentication Code
Supporting Variable Tag Lengths
Sebati Ghosh and Palash Sarkar Indian Statistical Institute
203, B.T.Road, Kolkata, India - 700108. {sebati r, palash}@isical.ac.in
May 15, 2020
Abstract
In this work, we study message authentication code (MAC) schemes supporting variable tag lengths. We provide a formalisation of such a scheme. Several variants of the classical Wegman-Carter MAC scheme are considered. Most of these are shown to be insecure by pointing out detailed attacks. One of these schemes is highlighted and proved to be secure. We further build on this scheme to obtain single-key variable tag length MAC schemes utilising either a stream cipher or a short-output pseudo-random function. These schemes can be efficiently instantiated using practical well known primitives.
Keywords: MAC, variable tag length, Wegman-Carter, security bound.
1
Introduction
Message authentication code (MAC) is the cryptographic mechanism to ensure the authenticity of messages transmitted across a public channel. A MAC scheme typically appends a short length tag to the message which is then transmitted. At the receiving end, a verification algorithm is run on the message-tag pair to confirm the authenticity. In such a set-up, the sender and the receiver share a previously agreed upon secret key.
from the interesting discussion on variable tag lengths for the UMAC scheme, we know of no other place where the issue of variable tag length MAC schemes has been considered.
The question of variable tag length received some attention in the past few years in the context of authenticated encryption (AE) schemes and the CAESAR [9] competition. Manger [17] pointed out that for the AE scheme OCB, 64-bit, 96-bit and 128-bit tags are defined where the “64-bit and 96-bit tags are simply truncated 128-bit tags”. This leads to simple truncation attacks on the scheme. An earlier paper by Rogaway and Wagner [22] had also discussed the problem of variable tag lengths in the context of the AE scheme CCM. A formal treatment of variable tag length AE schemes has been given by Reyhanitabar, Vaudenay and Viz´ar [21].
Two concrete motivations are provided in [21] as to why a variable tag length AE scheme may indeed be desirable in practice. The first mentions that variable tag lengths may be used with the same key due to “misuse and poorly engineered security systems”. The second reason is that for resource constrained devices, variable tag lengths may be desirable though changing the key for every tag length may be infeasible due to limited bandwidth and low power.
While the above two reasons have been put forward in the context of AE schemes, they are equally valid for MAC schemes. More generally, the issue of “mis-implementation” (also called “footguns”) [20] of cryptographic primitives has been extensively discussed as part of the discussion forum on post-quantum cryptography.
More concretely, Auth256 [7] is a Wegman-Carter type construction targeted at the 256-bit security level. Similarly, a 256-bit secure universal hash function has been proposed in [10], which can be mated to a 256-bit secure PRF using the Wegman-Carter template to obtain a 256-bit secure MAC. Such MAC schemes would be appropriate for high-security applications, or, for a post-quantum world. On the other hand, bandwidth limited applications would require shorter tags. Also, the possibility of mis-implementation using tag truncation remains. So, the question of designing a MAC scheme which can support various tag lengths up to 256 bits is of practical interest.
To summarise, the problem of variable tag length MAC schemes has been briefly mentioned about 15 years ago. Since then, there has neither been any formal treatment of the topic and nor has there been any variable tag length MAC scheme which is accompanied by a proof of security. The problem of constructing such MAC schemes, though, is of contemporary and future practical interest.
Our Contributions
We provide a formalisation of the notion of security for a variable tag length MAC scheme. For the same key, the desired tag length is to be provided as part of the input to the tag generation algorithm. Consequently, in the security model, we allow the adversary to control the tag length as well as the message. This is an extension of the usual security model for MAC schemes.
component of the Wegman-Carter scheme.
From a practical point of view, it is desirable to have a scheme which uses a single key. The key for the hash function is then derived from the key of the scheme and the tag length. The manner in which such derivation is made depends upon the primitive used to derive the hash key. We show two methods of deriving the hash key. The first method uses a stream cipher while the second method uses a short output length pseudo-random function (PRF). So, in effect, we obtain two constructions of single key variable tag length MAC scheme.
All the schemes that we describe can be instantiated by readily available concrete cryptographic primitives. For example, either of the 256-bit secure universal hash functions in [7, 10] can be combined with Salsa20 [3] to obtain nonce-based MAC schemes supporting variable tag lengths up to 256 bits. So, our work provides templates for designing efficient and practical MAC schemes which support variable tag lengths.
AE with variable tag length versus MAC with variable tag length: An AE scheme
supporting variable tag length has been proposed in [21]. Given a message M, suppose that the ciphertext is (C,tag). One may wonder whether we can construct a MAC scheme by throwing away
C and keeping tag. A MAC scheme obtained from the AE scheme in [21] in this manner is not secure. A simple reshuffling of the message blocks will give rise to the same tag. This, of course, has no implication to the security of the construction in [21] as an AE scheme. More generally, the above kind of simple strategy will fail to produce a secure MAC scheme from a secure AE scheme.
Previous and Related Works
The notion of MAC is several decades old. So, there is an extensive literature on this topic. Here we mention the papers which are directly related to our work.
The Wegman-Carter [28] scheme is four decades old. Several important and practical MAC schemes, such as UMAC [8] and Poly1305 [4] are based on the Wegman-Carter scheme. From a theoretical point of view, the security of the Wegman-Carter scheme was later analysed by Shoup [24] and Bernstein [5]. Recently, the optimality of Bernstein’s bound was established in [16, 19].
The point that tag lengths can vary depending on the application has been noted in [23] where the problem of determining an economically optimal tag length has been considered from a game theoretic point of view. This is completely different from the work reported in the present paper.
2
Definitions
Let x be a binary string: len(x) denotes the length of x; for a non-negative integer λ, msbλ(x) denotes the λ most significant bits of x. Given an integer i in the range 0 ≤ i < 2k−1, bink(i) denotes thek-bit binary representation ofi.
Throughout this paper,n is a fixed positive integer.
2.1 Hash Function
For distinct x, x0 ∈ M and anyn-bit string y, the differential probability ofHτ for the triplet (x, x0, y) is defined to be Prτ[Hτ(x)⊕Hτ(x0) =y], where the probability is taken over the uniform random choice of τ from Θ. The differential probability may depend on the lengths of x and x0. Suppose Lis the maximum of the lengths of the binary strings in M. Letε:{0, . . . , L}2 →[0,1] be a function such that the differential probability for any (x, x0, y) is at most ε(len(x),len(x0)). Then the family {Hτ}τ∈Θ is said to be ε-AXU.
2.2 Pseudo-Random Function
Let D and R be finite non-empty sets of binary strings and K be a finite non-empty set. Let
{FK}K∈K be a keyed family of functions with FK : D → R. Informally speaking, the function family {FK}K∈K is considered to be pseudo-random if a resource limited adversary is unable to distinguish it from a uniform random function from D to R. This is formalised in the following manner.
We consider an adversary A which has access to an oracle O, which is written as AO. A
adaptively sends queries to O and receives appropriate responses. At the end of the interaction,
A outputs a bit. The adversary is allowed to perform computations and also has access to private random bits.
Let (K ← K$ : AFK(·) ⇒ 1) denote the event that K is chosen uniformly at random from K
and the adversary produces 1 after interacting with the oracleFK(·). Let $(·) be a function chosen uniformly at random from the set of all functions from D toR. Let (A$(·) ⇒ 1) denote the event that the adversary produces 1 after interacting with the oracle $(·).
The advantage ofA in breaking the pseudo-randomness of{FK}K∈K is defined as follows.
AdvprfF (A) = PrhK ← K$ :AFK(·)⇒1 i
−PrhA$(·)⇒1i. (1)
The probabilities are over the randomness of A, the choice of K and the randomness of $(·). Suppose that A makes a total of q queries sending a total of σ bits in all the queries. By
AdvprfF (t, q, σ) we will denote the maximum advantage of any adversary taking time at most t, making at most q queries and sending at mostσ bits in all its queries.
2.3 Variable Tag Length Nonce-Based Message Authentication Code
A MAC scheme has two algorithms, namely, the tag generation algorithm and the verification algorithm. Typically, in a MAC scheme, tags are binary strings of some fixed length. The definition of MAC schemes, however, does not require tags to have the same length. So, it is possible to consider variable length tags within the ambit of the currently used definition of MAC schemes.
Our goal, on the other hand, is different. We would like the tag length to be provided as part of the input to the tag generation and verification algorithms. So, for the same message, by providing different values of the tag length, it is possible to generate tags of different lengths. This feature is not covered by the presently used definition of MAC schemes. We extend the syntax of MAC schemes and the definition of security to incorporate this feature.
A nonce-based MAC scheme is given by the message spaceM, the nonce spaceN, the key space
K, the allowed set L of tag lengths, the tag space T; and two algorithms NMAC.Gen(K, N, x, λ) and NMAC.Verify(K, N, x,tag, λ), where K ∈ K, N ∈ N, x ∈ M, λ ∈ L and tag ∈ T. We consider M,N, K and L to be finite non-empty sets and T to be equal to ∪i∈L{0,1}i. We write
denote NMAC.Verify(K, N, x,tag, λ).
The inputs and outputs ofNMAC.GenK(N, x, λ) andNMAC.VerifyK(N, x,tag, λ) are as follows.
• NMAC.GenK(N, x, λ):
input: K ∈ K;N ∈ N;x∈ M; and λ∈ L.
output: tag∈ T is a binary string of lengthλ.
• NMAC.VerifyK(N, x,tag, λ):
input: K ∈ K;N ∈ N;x∈ M;tag∈ T; and λ∈ Lsuch that tagis of lengthλ.
output: an element from the set {true,false}. The value true indicates that the input is accepted while the valuefalse indicates that the input is rejected.
The following correctness condition must hold.
NMAC.VerifyK(N, x,NMAC.GenK(N, x, λ), λ) = true.
Security: The security for a (nonce-based) MAC scheme against an adversaryA is modelled as follows. SupposeK is chosen uniformly at random fromK and the tag generation and verification algorithms are instantiated withK. Ais given oracle access to the tag generation and the verifica-tion algorithms. Amakes a total of qg queries to the tag generation oracle and a total ofqv queries to the verification oracle. The queries are made adaptively and queries to the tag generation oracle can be interleaved with those to the verification oracle.
Let the queries to the tag generation oracle be
Ng(1), x(1)g , λg(1), . . . ,N(qg)
g , x(gqg), λ(gqg)
and the corresponding responses be tag(1)g , . . . ,tag(gqg) respectively. Similarly, let the queries to the verification oracle be
Nv(1), x(1)v ,tag(1)v , λ(1)v , . . . ,N(qv)
v , x(vqv),tagv(qv), λ(vqv)
and the corresponding responses be xxx(1)v , . . . ,xxx(vqv) respectively, where for 1≤j ≤ qv, xxx(vj) is either trueorfalse. The query profile ofA is the list
C = (qg, qv,(ng(1),m(1)g , λ(1)g ), . . . ,(n (qg)
g ,m(gqg), λ(gqg)),(n(1)v ,m(1)v , λ(1)v ),
. . . ,(n(qv)
v ,m(vqv), λ(vqv))) (2) where for 1≤s≤qg,n
(s)
g =len(Ng(s)),m(gs) =len(x(gs)) and for 1≤s≤qv, n (s)
v =len(Nv(s)),m(vs)=
len(x(vs)).
There are two restrictions on the adversary. The first is a weaker form of nonce-respecting behaviour, namely,
Ng(i), λ(gi)
6
=
Ng(j), λ(gj)
restriction on the adversary is that it should not make any useless query. A query is useless if its response can be computed by the adversary. This means that the adversary should not repeat a query to the tag generation oracle or the verification oracle; and it should not query the verification oracle with
Ng(i), x(gi),tag(gi), λ(gi)
for any iin{1, . . . , qg}.
Forλ∈ L, let succA(λ) be the event that there is some j ∈ {1, . . . , qv} such that λ(vj) =λ and
NMAC.VerifyKNv(j), xv(j),tag(vj), λ(vj)
returns true. For each λ∈ L, the adversary’s advantage in breaking the authenticity ofNMACis defined to be Pr[succA(λ)]. This is written as follows.
AdvauthNMAC[λ](A) = Pr [succA(λ)]. (3)
The above probability is taken over the uniform random choice of K from K and over the possible internal randomness of the adversary A.
Note that there is no restriction on the adversary A to choose the target tag length before making the queries to its oracles. In particular, the notationsuccA(λ) specifies the success of Afor a tag length λ; it does not require Ato fix λbefore making its oracle queries.
Given a query profile C, AdvauthNMAC[λ](t,C) is the maximum of AdvauthNMAC[λ](A) taken over all adversaries running in timet and having query profileC.
Security in terms of query complexity: The query complexity is the total number of bits
sent by the adversary in all its queries. For tag generation queries, this consists of the number of bits sent as part of the nonces, the messages and the λg’s; for verification queries, this consists of the number of bits sent as part of the nonces, the messages, the tags and the λv’s. Let the
qg tag generation queries require a total of σg bits and the qv verification queries require a total of σv bits. So, σg = P1≤i≤qg(len(N
(i)
g ) +len(x(gi)) +len(λ(gi))) = P1≤i≤qg(n
(i)
g +m(gi) +len(λ(gi))) and σv = P1≤i≤qv(len(N
(i)
v ) +len(x(vi)) +len(tagv(i)) +len(λv(i))) = P1≤i≤qv(n
(i)
v +m(vi) +λ(vi)+
len(λ(vi))), aslen(tagv(i)) =λv(i). If the elements ofLare expressed as t-bit binary strings, thenσg=
P
1≤i≤qg(n
(i)
g +m(gi))+qgtandσv =P1≤i≤qv(n
(i)
v +m(vi)+λv(i))+qvt. Given query complexity (σg, σv),
AdvauthNMAC[λ](t, σg, σv) is the maximum of AdvauthNMAC[λ](A) taken over all adversaries A running in timet and having query complexity (σg, σv).
Given a query profile C of any adversary A the corresponding query complexity (σg, σv) can be readily derived in the above manner. On the other hand, it is to be noted that, various query profiles can have the same query complexity. Hence, in the security definition above in terms of query complexity, when one maximises over query complexity, the value obtained is the maximum over all possible query profiles which have that same query complexity. This gives us the following proposition.
Proposition 1. Let us fix a query complexity(σg, σv)and let C¸(σg,σv)be the set of all query profiles
having query complexity (σg, σv), i.e.,
C¸(σg,σv):={C:the query complexity of C is(σg, σv)}.
Then,
AdvauthNMAC[λ](t, σg, σv) =maxC∈C¸(σg ,σv)Adv
auth
NMAC[λ](t,C). (4)
Information theoretic security: This consists of analysing the security of a MAC scheme against a computationally unbounded adversary. In other words, the probability in (3) is considered for an adversary A without any reference to the run time of A. For such a computationally unbounded adversary A, without loss of generality, we may assumeA to be deterministic. In the context of information theoretic security, given a query profile C,AdvauthNMAC[λ](C) is the maximum of AdvauthNMAC[λ](A) taken over all adversariesA having query profileC.
3
Towards Building a Variable Tag Length MAC
It may appear that a variable tag length nonce-based MAC scheme can be obtained simply by truncating the output of the Wegman-Carter MAC algorithm. This, however, does not work as we show in this section. We further consider several “natural” extensions of the Wegman-Carter MAC algorithm and show that most of them are insecure. Only two of these extensions are secure: one of them is a generic construction, while we prove the security of the other in the next section. Overall, the discussion in the present section may be considered as showing the subtlety involved in constructing a variable tag length nonce-based MAC scheme.
Let N be the nonce space and M be the message space. Let {FK}K∈K be a PRF such that
FK : N → {0,1}n; let {Hashτ}τ∈Θ be an AXU hash function such that Hashτ : M → {0,1}n. Given{FK}K∈K and{Hashτ}τ∈Θ, the Wegman-Carter MAC [28] is the following. A nonce-message pair (N, x) is mapped under a key (K, τ) to FK(N)⊕Hashτ(x), i.e.,
WC-NMAC: (N, x)(−→K,τ)FK(N)⊕Hashτ(x). (5)
Below we argue that several natural extensions of WC-NMACare not secure. The attacks are shown for the following specific choice of the hash function. Under a fixed representation of the elements of the finite field F2n, we identify the elements of F2n with the set {0,1}n. The specific
hash function that we consider is Hashτ(x) = τ x, i.e., the output of Hashτ(x) is the n-bit string representing the product of τ and x considered as elements of F2n. This hash function is known
to be AXU. Attacks on schemes built using this specific hash function is sufficient to show that the schemes described below are not secure for an arbitrary AXU hash function. The choice of the hash function fixes the key space of the hash function to be Θ =F2n and the message space Mto
be either F2n orF2n−8, depending on the scheme.
We will use the following simple fact about the specific hash function that we consider.
Proposition 2. Consider the AXU hash function{Hashτ}τ∈F2n where Hashτ(x) =τ x. Letx1 and
x2 be distinct elements ofF2n andcbe such that Hashτ(x1)⊕Hashτ(x2) =c, thenτ =c(x1⊕x2)−1.
The most obvious approach to obtain a variable tag length scheme from (5) is to truncate the output, i.e.,
trunc: (N, x, λ)(−→K,τ)msbλ(WC-NMACK,τ(N, x)) =msbλ(FK(N)⊕Hashτ(x)).
The scheme trunc is not secure as can be seen from the following attacks. Note that in this case the message space isF2n.
Attack 2 on trunc: Another attack which repeats nonces in tag generation queries and reveals more information is the following. Letx1, x2 and x3 be distinct messages and N be a nonce. The adversary makes two tag generation queries (N, x1, n) and (N, x2, n−1) and gets in response t1 and t2 respectively. So, we have the following relations: FK(N)⊕Hashτ(x1) =
t1 and msbn−1(FK(N)⊕Hashτ(x2)) = t2. From the second relation, it follows that either
FK(N)⊕Hashτ(x2) =t2||0 orFK(N)⊕Hashτ(x2) =t2||1. Using Proposition 2, the adversary solves the equations Hashτ(x1)⊕Hashτ(x2) = t1 ⊕(t2||0) and Hashτ(x1)⊕Hashτ(x2) =
t1⊕(t2||1) forτ to obtain the solutions τ0 andτ1 respectively. As FK(N)⊕Hashτ(x2) takes exactly one of the two valuest2||0 ort2||1,τ takes exactly one of the two valuesτ0 orτ1. Let
y0 =t1⊕Hashτ0(x1). The adversary makes a verification query (N, x3, y0⊕Hashτ0(x3), n). If the verification query is successful then τ0 is the correct value ofτ. If the verification query fails, thenτ1 is the correct value ofτ. Thus the adversary recovers the hash key with two tag generation and one verification queries.
The first attack shows that a simple truncation of the Wegman-Carter MAC scheme does not work while the second attack shows that by repeating nonces in tag generation queries the hash key can be obtained. One possibility of modifying truncis to apply FK a second time before applying truncation, i.e., the tag is obtained asmsbλ(FK(FK(N)⊕Hashτ(x))).The resulting scheme is also not secure. The first simple attack on truncalso works for this modified scheme.
In the schemetrunc, the output of neitherF norHash depends on λ. To rectify this situation, one may introduce λas part of the input of one or both of F and Hash. Another possibility is to have one or both of the keys K and τ to depend on λ. Key dependencies are achieved by using a family of independent keys {Kλ}λ∈L and/or a family of independent keys {τλ}λ∈L. The various schemes that arise from such considerations are as follows.
NMAC-t1K,τ : (N, x, λ) (K,τ)
−→ msbλ(FK(bin8(λ)||N)⊕Hashτ(x)). (6)
NMAC-t2K,τ : (N, x, λ) (K,τ)
−→ msbλ(FK(N)⊕Hashτ(bin8(λ)||x)). (7)
NMAC-t3K,τ : (N, x, λ) (K,τ)
−→ msbλ(FK(bin8(λ)||N)⊕Hashτ(bin8(λ)||x)). (8)
NMAC-Generic(Kλ,τλ)λ∈L : (N, x, λ)(K−→λ,τλ)msbλ(FKλ(N)⊕Hashτλ(x)). (9)
NMAC-t4(Kλ,τ)λ∈L : (N, x, λ)
(Kλ,τ)
−→ msbλ(FKλ(N)⊕Hashτ(x)). (10)
NMAC-t5(Kλ,τ)λ∈L : (N, x, λ)
(Kλ,τ)
−→ msbλ(FKλ(N)⊕Hashτ(bin8(λ)||x)). (11)
NMAC-t6(K,τλ)λ∈L : (N, x, λ)(K,τ−→λ)msbλ(FK(N)⊕Hashτλ(x)). (12)
NMAC(K,τλ)λ∈L : (N, x, λ)(K,τ−→λ)msbλ(FK(bin8(λ)||N)⊕Hashτλ(x)). (13)
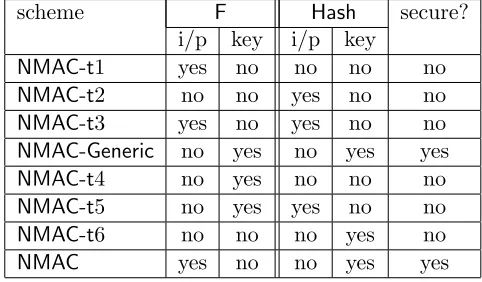
Dependencies of input and/or key onλfor the above schemes are summarised in Table 1.
Nonce stealing: Finney [12] had suggested that the nonce may be reduced by a few bits and
a binary encoding of the tag length be inserted. In the present context, this refers to letting the input of F depend on the tag length. From Table 1, we see that the schemes NMAC-t1, NMAC-t3 and NMAC use nonce stealing. While NMAC is secure (as proved later), schemes NMAC-t1 and
NMAC-t3 are insecure. So, nonce stealing by itself does not guarantee security.
For the ensuing discussion, we will consider the message space for the schemesNMAC-t1,NMAC
-Generic, NMAC-t4 and NMAC-t6 to be F2n, and that for the schemes NMAC-t2, NMAC-t3 and
Table 1: For the schemes in (6) to (13), a summary of whether the input and/or the key ofFand/or
Hash depend on the tag length λ.
scheme F Hash secure? i/p key i/p key
NMAC-t1 yes no no no no
NMAC-t2 no no yes no no
NMAC-t3 yes no yes no no
NMAC-Generic no yes no yes yes
NMAC-t4 no yes no no no
NMAC-t5 no yes yes no no
NMAC-t6 no no no yes no
NMAC yes no no yes yes
Algorithm 1 describes an attack onNMAC-t1 which usesfindTagas a subroutine. In the attack, the tag generation and verification oracles are denoted by Og and Ov respectively. On being supplied with input (N, x, λ), the functionfindTag(N, x, λ) finds tagsuch that (N, x,tag, λ) passes the test by the verification oracle. To do this, findTag repeatedly queries the verification oracle, until a suitable tag is obtained. The expected number of queries made by findTag(N, x, λ) is 2λ. Algorithm 1 invokesfindTag with values of the tag length which are less than the target tag length. The intuition behind the attack in Algorithm 1 is the following. The key (K, τ) of the scheme does not depend on λ. In particular, as the hash key τ does not depend on λ, the attack retrieves
τ using a smaller value ofλand uses it for the forgery with the targetλsuccessfully. Retrievingτ
using a smaller value ofλrequires significantly lesser number of oracle queries than that required for an attack by exhaustive search for the targetλ. The analysis of the attack is given in Proposition 3. This divide-and-conquer attack strategy of using shorter tag length to learn information, with low cost, which is useful for longer tag lengths has previously been used in the context of AE [11, 21].
Proposition 3. The attack given in Algorithm 1 on the scheme NMAC-t1 given in (6) produces a forgery for tag length λ which is correct with probability 1. It requires one tag generation query and at most 2λ1+ 2n−λ1 verification queries on tag lengthλ
1 and one tag generation query and one verification query on tag length λ.
Proof. That the attack mentioned in Algorithm 1 forges with probability 1 is proved if it can be shown that the forgery returned by the attack in Step 17 is accepted, i.e. the corresponding response from Ov istrue.
From Step 4 we get,
msbλ1(FK(bin8(λ1)||N1)⊕Hashτ(x1)) =tag
(1). (14)
The tag(2) returned by Step 5 satisfies
msbλ1(FK(bin8(λ1)||N1)⊕Hashτ(x2)) =tag
(2). (15)
So, from (14) and (15) we get,
msbλ1(Hashτ(x1)⊕Hashτ(x2)) =tag
(1)⊕tag(2). (16)
Here tag(1)⊕tag(2) is a λ
Algorithm 1 Attack onNMAC-t1 for λ=n. 1: setλ←n;
2: choose λ1 ∈ L, such thatλ1< λ;
3: choose distinctN1, N2∈ N and distinctx1, x2, x3, x4∈ M; 4: tag(1) ← Og(N1, x1, λ1);
5: tag(2) ←findTag(N1, x2, λ1); 6: setC ← {};
7: do
8: choose c← {0,1}n−λ1 \ C; 9: set C ← C ∪ {c};
10: using Proposition 2 solve Hashτ(x1)⊕Hashτ(x2) = (tag(1)⊕tag(2))||c 11: forτ and let the solution be τc;
12: set xc←tag(1)⊕msbλ1(Hashτc(x1));
13: R(3)v ← Ov(N1, x3, xc⊕msbλ1(Hashτc(x3)), λ1);
14: whileR(3)v =false; 15: tag(4) ← Og(N2, x4, λ); 16: choose any x∈ M \ {x4};
17: return (N2, x,Hashτc(x)⊕Hashτc(x4)⊕tag
(4), λ).
findTag(N, x, λ)
1: setD ← {}; 2: do
3: choose tag← {0,1}λ\ D; 4: set D ← D ∪tag;
5: Rv ← Ov(N, x,tag, λ); 6: whileRv =false
The fact that Hashτ(x1)⊕Hashτ(x2)∈ {0,1}nand (16) suggest that there is a correct c, such that the equation in Step 10 holds and we consider that iteration of the do-while loop which deals with this particular c. Theτc obtained in this iteration is the actual hash key used in the scheme. So,
NMAC-t1(N1, x3, λ1)
= msbλ1(FK(bin8(λ1)||N1)⊕Hashτc(x3))
= tag(1)⊕msbλ1(Hashτc(x1))⊕msbλ1(Hashτc(x3)) (17)
= xc⊕msbλ1(Hashτc(x3)). (18)
The expression in (17) comes from (14) and that in (18) comes from Step 12 in Algorithm 1. Hence, in this particular iteration of the do-while loop, R(3)v =trueand the loop terminates.
Sinceλ=n, from Step 15 we obtainFK(bin8(λ)||N2) =Hashτc(x4)⊕tag(4).For the choice of x
in Step 16, i.e., x∈ M \ {x4}we have
NMAC-t1(N2, x, λ) = FK(bin8(λ)||N2)⊕Hashτc(x)
= Hashτc(x4)⊕tag
(4)⊕Hash
τc(x), (19)
which is returned as the tag for (N2, x, λ) in the forgery and hence, the corresponding response from Ov istrue with probability 1, which proves the first part of the result.
In the attack, there are 2 tag generation queries in Steps 4 and 15. The subroutine findTag
makes a maximum of 2λ1 verification queries on tags of lengths λ1. The do-while loop in Steps 7 to 14 iterates at most 2n−λ1 times for different values ofcmaking a maximum of 2n−λ1 verification queries on tags of lengths λ1. The forgery returned in Step 17 is a verification query on a tag of lengthλ. Hence, the attack requires 2 tag generation queries and at most 2λ1+2n−λ1+1 verification queries including the forgery.
Remarks:
1. One may note that this work considers variable length tags. So, the adversary can make verification queries for a particular tag length and provide a forgery for another tag length. The attack given in Algorithm 1 on the scheme NMAC-t1, forges the scheme with an n-bit tag, i.e. the attack is for tag lengthn; whereas, as shown in Proposition 3, the attack requires 2 tag generation queries and 2λ1 + 2n−λ1+ 1 verification queries including the forgery, where
λ1 < λ. Among these queries, 1 tag generation query and 2λ1 + 2n−λ1 verification queries are with tag length λ1. For example, suppose n= 128, and let λ1 = 64. So, the attack uses 265+ 1<2128 verification queries and produces a forgery for tag length 128. This constitutes a valid attack for tag length 128.
2. The security model for variable length tag NMAC allows nonces in tag generation queries to be repeated as long as the tag lengths are distinct. The attack in Algorithm 1 does not repeat nonces in tag generation queries. So, the scheme NMAC-t1 is insecure even under the restriction that nonces in tag generation queries are distinct.
Insecurities of the schemes NMAC-t1 toNMAC-t5 follow from applications of Algorithm 1.
Attack on NMAC-t3: Algorithm 1 works with the only modification that the forgery is changed to (N2, x,Hashτc(bin8(λ)||x)⊕Hashτc(bin8(λ)||x4)⊕tag
(4), λ).
Attack on NMAC-t4: Algorithm 1 works with the only modification that the forgery is changed to (N2, x,Hashτc(x)⊕Hashτc(x4)⊕tag
(4), λ).
Attack on NMAC-t5: Algorithm 1 works with the only modification that the forgery is changed to (N2, x,Hashτc(bin8(λ)||x)⊕Hashτc(bin8(λ)||x4)⊕tag
(4), λ).
The insecurity ofNMAC-t6 is discussed in Appendix A.
The schemeNMAC-Genericcan be considered to be a collection of #L independentWC-NMAC
schemes, one for each value of λ. Each of the individual schemes for fixed values of λare already known to be secure. Since the keys of the various schemes are independent, it can be argued that the collection is also secure. The problem, however, is that size of the key increases by a factor of #L. So,NMAC-Genericcannot be considered to be a practical solution to the problem of obtaining a variable tag length MAC scheme.
The first step towards reducing key size is taken in the schemeNMACwhich uses a single keyK
forFand independent keys τλ. In the next section, we proveNMACto be secure and also consider further variants with smaller keys.
Remark: Suppose NMAC-t1 is modified to obtain a scheme NMAC-t10 in the following manner. The tag is obtained as msbλ(FK(FK(bin8(λ)||N)⊕Hashτ(x))), i.e., a second application of FK is made before truncating. It is not difficult to show that the scheme mapping (N, x, λ), under the key (K, τ), to the quantity FK(FK(bin8(λ)||N)⊕Hashτ(x)) is a PRF. It can be argued that NMAC-t10 is a secure variable tag length MAC scheme. However, the security bound for NMAC-t10 will be in the order ofq2ε, where the total number of queries isqand the hash function isε-AXU. This bound is higher than the bounds obtained for the schemes that we consider. Hence, we do not consider
NMAC-t10. In the above discussion, we have considered modification of NMAC-t1 to NMAC-t10. The same comments apply to similar modifications of the other insecure schemes, namelyNMAC-t2 toNMAC-t6.
4
Secure and Efficient MAC Schemes with Variable Length Tag
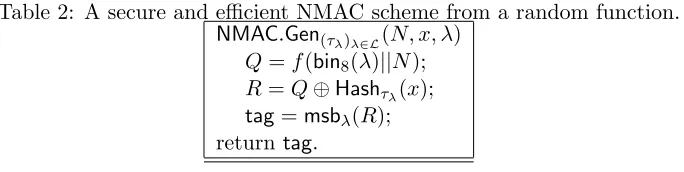
We start with the scheme NMAC given in (13). We carry out an information theoretic analysis of this scheme. To this end, we consider the scheme obtained by replacingFK with a random function
f :{0,1}n→ {0,1}n. The tag generation algorithm for this scheme is shown in Table 2. We require a hash family {Hashτ}τ∈Θ, where for each τ ∈Θ,Hashτ :M → {0,1}n, with M=∪Li=0{0,1}i for some sufficiently large positive integer L.
The nonce space for the scheme NMAC is N = {0,1}n−8 and the message space is M. Let
L ⊆ {1, . . . ,min(255, n)} be the allowed set of tag lengths. So, tag lengths can be represented by bytes. The key space forNMACis Θ#L, i.e., a particular key is a tuple (τ
λ)λ∈L. The key generation algorithm consists of choosingτλ independently and uniformly at random from Θ for eachλ. The verification algorithm is as follows. Given (N, x,tag, λ), computetag0 =NMAC.Gen(τλ)λ∈L(N, x, λ);
iftag=tag0 then returntrue, else returnfalse.
Here f is a random function but, not necessarily a uniform random function. Given q pairs (a1, b1), . . . ,(aq, bq), theq-interpolation probability [5] offis defined to be Pr[f(a1) =b1, . . . , f(aq) =
the interpolation probability off. Known bounds on the interpolation probability of uniform ran-dom function and uniform ranran-dom permutation provide the corresponding bounds on the security of the resulting NMAC schemes.
Table 2: A secure and efficient NMAC scheme from a random function.
NMAC.Gen(τλ)λ∈L(N, x, λ)
Q=f(bin8(λ)||N);
R=Q⊕Hashτλ(x);
tag=msbλ(R); returntag.
Theorem 1. In the schemeNMAC defined in Table 2, suppose that the hash function {Hashτ}τ∈Θ is ε-AXU, where ε(`, `0)≥1/2n for all`, `0 ≤L.
Fix a query profile C. For λ ∈ L, let qg,λ (resp. qv,λ) be the number of tag generation (resp. verification) queries for λ which are in C. Let λ be such that qv,λ ≥ 1 and for 1 ≤ i ≤ qv,λ, let
Qv,λ(i) = (Nv,λ(i), x(v,λi),tagv,λ(i), λ) be the i-th verification query with tag length λ. Let `v,λ(i) = len(x(v,λi)).
Corresponding to Q(v,λi), there is at most one tag generation query Q(g,λi?)= (Ng,λ(i?), x(g,λi?), λ) such that
Nv,λ(i) =Ng,λ(i?). Let `(g,λi?)=len(x(g,λi?)) if there is such aQg,λ(i?), otherwise`(g,λi?) is undefined.
Fix λ0 ∈ L. LetSλ0 be the set of all queries made by the adversary other than the verification queries for tag length λ0. Suppose that the queries in Sλ0 give rise to at most q distinct (nonce, tag-length) values. Further, suppose δi be such that the i-interpolation probability of f is at most
δi/(2n)i. Then
AdvauthNMAC[λ0](t,C) ≤ 1 2λ0 ×
X
1≤i≤qv,λ0
γi (20)
where γi= 2nδqε
`(v,λi)
0, ` (i?) g,λ0
if there is a Q(g,λi?)
0 corresponding to Q (i)
v,λ0 with N (i) v,λ0 =N
(i?)
g,λ0; other-wise γi=δq+1.
Remark: It has been proved in [5], that for 1≤j≤2n, if f is a uniform random function, then
δj = 1, and if f is a uniform random permutation, thenδj ≤(1−(j−1)/2n)−j/2.
Proof. The proof builds upon and generalises ideas used in the security proof of the Wegman-Carter nonce-based MAC scheme given in [5].
Let A be an adversary attacking the authenticity of NMAC. The result concerns information theoretic security and so we consider the adversary to be deterministic. A makes a number of queries to its oracles and receives the appropriate responses. The interaction of A with its two oracles is given by a transcript T which is a list of the queries made by A and the responses it received in return. The adversary’s view of the oracles is completely determined by the transcript
makes a verification query for tag lengthλ0 which returns true. So, if the transcriptT corresponds to the query profile C, thenAdvauthNMAC[λ0](t,C) = Pr[succ(A(T), λ0)].
The first reductionis to assume thatqv,λ0 = 1. Ifqv,λ0 = 0, i.e.,Adoes not make any verification query, then clearly,A has advantage 0 so that the theorem is trivially proved. So, suppose thatA
with transcript T makes qv,λ0 >1 verification queries for tag-length λ0. Let E be the event that the first verification query for the tag length λ0 is successful and S be the event that one of the later verification queries for the tag lengthλ0 is successful. So,
AdvauthNMAC[λ0](A) = Pr[succ(A(T), λ0)] = Pr[E ∨ S] = Pr[E ∨(E ∧ S)] = Pr[E] + Pr[E ∧ S].
LetA0 be an adversary with a transcriptT0which is obtained fromT by discarding all queries after the first verification query for tag lengthλ0. Let A00be an adversary with a transcriptT00obtained from T in the following manner: the first verification query for tag length λ0 is dropped fromT; insteadA00 takes the answerfalseas the response to this query. (Note that since we are disallowing useless queries, there could not have been a previous tag generation query for tag length λ0 with the same nonce and message as that of the first verification query for tag length λ0.) We have Pr[succ(A0(T0), λ0)] = Pr[E] and Pr[succ(A00(T00), λ0)] = Pr[E ∧ S]. Note that A00 makesqv,λ0 −1 verification queries for tag length λ0. So, the problem of proving the result for qv,λ0 verification queries has been reduced to the problem of proving the result for qv,λ0 −1 verification queries. Proceeding by induction, to prove the bound given in (20), it is sufficient to consider an adversary which makes exactly one verification query for tag lengthλ0. Let the single verification query for tag lengthλ0 be (N, x,tag, λ0).
The second reductionis to ignore all queries in T after the verification query for tag lengthλ0. Such queries have no effect on the success probability of the verification query for tag length λ0.
The third reductionis the following. If the queries inSλ0 give rise to less thanq distinct (nonce, length) values, then insert additional tag generation queries to the transcript with (nonce, tag-length) values not equal to (N, λ0) such that the queries in the augmentedSλ0 give rise to exactly
q distinct (nonce, tag-length) values. Such augmentation of the transcript does not decrease the adversary’s advantage.
In view of the above reductions, it is sufficient to consider an adversary A with a transcript
T where the last query is the verification query (N, x,tag, λ0) for tag length λ0 and the queries inSλ0 give rise to exactly q distinct (nonce, tag-length) values. The transcript T can contain any number of tag generation queries for the tag length λ0. However, by the restriction that among the tag generation queries, the (nonce, tag-length) pair cannot repeat,T can contain at most one tag generation query of the form (N, x0, λ0). For λ 6= λ0, the transcript T can contain multiple verification queries with the same value for the (nonce,λ) pair. So, the total number of queries in
Sλ0 can be greater thanq.
Let N = bin8(λ0)||N, Q = f(N) and τ0 = τλ0. Let the q distinct values of (nonce, tag-length) pairs arising from the queries in Sλ0 be (N(1), λ(1)), . . . ,(N(q), λ(q)). For i = 1, . . . , q, let
N(i) =bin
8(λ(i))||N(i) and Q(i) = f(N(i)). Define Q = (Q(1), . . . , Q(q)). Let q0 be the number of distinct tag-length values arising from the queries inSλ0 and letλ
(1), . . . , λ(q0)be these tag lengths.
For i = 1, . . . , q0, define τi = τλ(i) and τ = (τ1, . . . , τq0). The entire randomness in the transcript
arises from Qand τ.
Consider the final verification query (N, x,tag, λ0) and let ` = len(x). Let `(?) = len(x(?)) if there is a prior tag generation query (N(?), x(?), λ(?)) (with responsetag(?)) such thatN(?)=N and
To prove the theorem, it is sufficient to show
Pr[succ(A(T), λ0)] ≤ γ/2λ0. (21)
The verification query is successful if tag=msbλ0(Q⊕Hashτ0(x)). So,
Pr[succ(A(T), λ0)] = Pr[msbλ0(Q⊕Hashτ0(x)) =tag]. (22)
We consider the probability on the right hand side of (22) under two cases.
The first case is when there is no tag generation query having (nonce, tag-length) pair to be equal to (N, λ0) in T. In this case, N(1), . . . ,N(q),N are distinct values to which f is applied. Since the adversary is adaptive, the x and tag in the final verification query are functions of the earlier responses it received and in turn are functions of Q and τ. We write x ≡ x(Q,τ) and
tag≡tag(Q,τ) to emphasise this functional dependence. Letaandabe arbitrary values ofτ0 and
τ. Letb1, . . . , bq be arbitraryn-bit strings and letb= (b(1), . . . , b(q)). So,
Pr[msbλ0(Q⊕Hashτ0(x(Q,τ))) =tag(Q,τ)]
= Pr[msbλ0(Q) =tag(Q,τ)⊕msbλ0(Hashτ0(x(Q,τ)))]
= X a,a
Pr[msbλ0(Q) =tag(Q,τ)⊕msbλ0(Hashτ0(x(Q,τ)))∧(τ =a)∧(τ0 =a)]
= X a,a
Pr[msbλ0(Q) =tag(Q,a)⊕msbλ0(Hasha(x(Q,a)))∧(τ =a)∧(τ0 =a)]
= X a,a
Pr[msbλ0(Q) =tag(Q,a)⊕msbλ0(Hasha(x(Q,a)))] Pr[(τ =a)∧(τ0 =a)].
(23)
Letc be an arbitrary (n−λ0)-bit binary string. We consider
Pr[msbλ0(Q) =tag(Q,a)⊕msbλ0(Hasha(x(Q,a)))]
= X
b
Pr[msbλ0(Q) =tag(Q,a)⊕msbλ0(Hasha(x(Q,a)))∧(Q=b)]
= X
b
Pr[msbλ0(Q) =tag(b,a)⊕msbλ0(Hasha(x(b,a)))∧(Q=b)]
= X
b
Pr[msbλ0(Q) =b∧(Q=b)]
(where b=tag(b,a)⊕msbλ0(Hasha(x(b,a))))
= X
b
Pr[msbλ0(f(N)) =b, f(N
(1)) =b(1), . . . , f(N(q)) =b(q)]
= X
b
X
c
Pr[f(N) =b||c, f(N(1)) =b(1), . . . , f(N(q)) =b(q)]
≤ X
b
2n−λ0δ
q+1/(2n)q+1
= 2n−λ0δ
Combining (23) and (24), we have
Pr[msbλ0(Q⊕Hashτ0(x(Q,τ))) =tag(Q,τ)]
= X
a,a
Pr[msbλ0(Q) =tag(Q,a)⊕msbλ0(Hasha(x(Q,a)))] Pr[(τ =a)∧(τ0=a)]
≤ γ/2λ0X a,a
Pr[(τ =a)∧(τ0 =a)] =γ/2λ0. (25)
This proves the first case.
In the second case, let the transcriptT be such that there is a tag generation query (N(?), x(?), λ(?)) (with response tag(?)) where N(?) =N and λ(?) =λ0. Note that by the query restriction on the adversary,x(?)6=x. LetN(?)=bin8(λ(?))||N(?),Q(?)=f(N(?)) andτ? =τλ(?). ThenQ(?) =Qand τ? =τ0. Let Qbe the vector consisting ofQ(1), . . . , Q(q) but, not containingQ(?) and let τ be the vector consisting ofτ1, . . . , τq0 but, not containingτ?. So,Qis a vector havingq−1 components and
τ is a vector havingq0−1 components. In this case,x≡x(Q,τ,tag(?)) andtag≡tag(Q,τ,tag(?)). Due to the adaptive nature of the adversary, x(?) is also a function of portions of Q and τ which corresponds to the queries earlier to (N(?), x(?), λ(?)). Hence, we writex(?)≡x(?)(Q,τ). Note that
τ0 is independent of τ.
Letaand t be arbitrary values forτ andtag(?) respectively. Then
Pr[msbλ0(Q⊕Hashτ0(x(Q,τ,tag
(?)))) =tag(Q,τ,tag(?))]
= X a,t
Pr[(msbλ0(Q⊕Hashτ0(x(Q,τ,tag
(?)))) =tag(Q,τ,tag(?)))∧(τ =a)
∧(tag(?)=t)]
= X a,t
Pr[(msbλ0(Q⊕Hashτ0(x(Q,a, t))) =tag(Q,a, t))
∧(msbλ0(Q⊕Hashτ0(x
(?)(Q,a))) =t)∧(τ =a)]
= X a
X
t
Pr[(msbλ0(Hashτ0(x(Q,a, t))⊕Hashτ0(x
(?)(Q,a))) =tag(Q,a, t)⊕t)
∧(msbλ0(Q) =tag(Q,a, t)⊕msbλ0(Hashτ0(x(Q,a, t))))]
×Pr[τ =a]. (26)
Letb andabe an arbitrary value ofQand τ0. Letc1 and c2 be arbitrary (n−λ0)-bit strings. We consider
Pr[(msbλ0(Hashτ0(x(Q,a, t))⊕Hashτ0(x
(?)(Q,a))) =tag(Q,a, t)⊕t)
∧(msbλ0(Q) =tag(Q,a, t)⊕msbλ0(Hashτ0(x(Q,a, t))))]
=X b
Pr[(msbλ0(Hashτ0(x(Q,a, t))⊕Hashτ0(x
(?)(Q,a))) =tag(Q,a, t)⊕t)
∧(msbλ0(Q) =tag(Q,a, t)⊕msbλ0(Hashτ0(x(Q,a, t))))∧(Q=b)]
=X b
Pr[(msbλ0(Hashτ0(x(b,a, t))⊕Hashτ0(x
(?)(b,a))) =tag(b,a, t)⊕t)
To simplify notation, we write x(b,a, t) as x,x?(b,a) as x? andtag(b,a, t) as tag. So, we have
X
b
Pr[(msbλ0(Hashτ0(x)⊕Hashτ0(x
(?))) =tag⊕t)
∧(msbλ0(Q) =tag⊕msbλ0(Hashτ0(x)))∧(Q=b)]
=X b,a
Pr[(msbλ0(Hasha(x)⊕Hasha(x
(?))) =tag⊕t)
∧(msbλ0(Q) =tag⊕msbλ0(Hasha(x)))∧(Q=b)∧(τ0=a)]
=X b,a
Pr[(msbλ0(Hasha(x)⊕Hasha(x
(?))) =tag⊕t)∧(τ 0 =a)]
×Pr[(msbλ0(Q) =tag⊕msbλ0(Hasha(x)))∧(Q=b)]
=X b,a
Pr[(msbλ0(Hasha(x)⊕Hasha(x
(?))) =tag⊕t)∧(τ 0 =a)]
× X
c1
Pr[(Q= (tag⊕msbλ0(Hasha(x)))||c1)∧(Q=b)]
!
Let b= (tag⊕msbλ0(Hasha(x)))||c1). Then Pr[(Q=b)∧(Q=b)] is bounded from above by the
q-interpolation probability off. So, we have
X
b,a
Pr[(msbλ0(Hasha(x)⊕Hasha(x
(?))) =tag⊕t)∧(τ 0 =a)]
× X
c1
Pr[(Q=b)∧(Q=b)]
!
≤X
b,a
Pr[(msbλ0(Hasha(x)⊕Hasha(x
(?))) =tag⊕t)∧(τ
0=a)]×2n−λ0
δq (2n)q
= 2n−λ0 δq (2n)q ×
X
b,a
Pr[(msbλ0(Hasha(x)⊕Hasha(x
(?))) =tag⊕t)∧(τ 0=a)]
= 2n−λ0δ
q/(2n)q×
X
b
Pr[msbλ0(Hashτ0(x)⊕Hashτ0(x
(?))) =tag⊕t]
= 2n−λ0δ
q/(2n)q×
X
b
X
c2
Pr[Hashτ0(x)⊕Hashτ0(x
(?)) = (tag⊕t)||c 2]
≤2n−λ0δ
q/(2n)q×
X
b
2n−λ0ε(`, `(?))
= 2n−λ0δ
q/(2n)q×(2n)q−1×2n−λ0ε(`, `(?)) = 2n−2λ0δ
Combining (26) and (27), we have,
Pr[msbλ0(Q⊕Hashτ0(x(Q,τ,tag
(?)))) =tag(Q,τ,tag(?))]
≤ X
a
X
t
2n−2λ0δ
qε(`, `(?))
×Pr[τ =a]
= X
t
2n−2λ0δ
qε(`, `(?))×
X
a
Pr[τ =a]
= 2λ02n−2λ0δ
qε(`, `(?)) = 2n−λ0ε(`, `(?))δ
q=γ/2λ0. (28)
This proves the second case.
Tightness of the security bound: The schemeNMACis obtained as a variant of the
Wegman-Carter scheme. The statement and proof of Theorem 1 follows the bound on the Wegman-Wegman-Carter scheme established by Bernstein [5]. As mentioned earlier, Bernstein’s bound has been proved to be tight [16, 19]. A natural question is to consider whether the bound of Theorem 1 is also tight. We have considered this question for NMAC. It does not seem possible to use the proof approach used in [16, 19] to show the tightness of the bound in Theorem 1. In fact, the approach does not also seem to work for the generic scheme NMAC-Generic.
The security bound of Theorem 1 in terms of query complexity: The statement of
Theorem 1 and the security bound provided in it are in terms of query profile. If it is to be translated to terms of query complexity, the following point is to be noted. The hash function
{Hashτ}τ∈Θ may be such that, the differential probability of the hash function may depend on the lengths of the particular queries. For example, if {Hashτ}τ∈Θ is a polynomial hash, the degree of the polynomial formed from the messages and hence the corresponding differential probability is a function of the lengths of the messages. The details of this variation in the query lengths are lost when we move from the notion of query profile to the notion of query complexity. As a result, the variability in the differential probability also cannot be captured when the security is considered in terms of query complexity. In this case, a uniformity is required in the probability and to attain that, the maximum of all the differential probabilities is considered. As a result, the security bound obtained in terms of query complexity is not precise and depending on the particular queries made by the adversary, it may be an over-estimation by a large margin. Hence, in the detailed security analysis we consider the notion of query profile and the security in terms of query complexity has been mentioned in respective corollaries.
The statement of Theorem 1 and the security bound provided in it look as follows in terms of query complexity.
Corollary 1. In the schemeNMACdefined in Table 2, suppose that the hash function {Hashτ}τ∈Θ be such that for any distinctx, x0∈ Mand anyy ∈ {0,1}n,Pr[Hash
τ(x)⊕Hashτ(x0) =y]is at most
(nonce, tag-length) values. Further, suppose δq be such that the q-interpolation probability of f is at mostδq/(2n)q and (q+ 1)-interpolation probability of f is at most (δqε)/(2n)q. Then
AdvauthNMAC[λ0](t, σg, σv)≤2n−λ0qv,λ0δqε. (29)
Essentially, in this case the bound is similar to the bound given in the security proof of the Wegman-Carter nonce-based MAC scheme given in [5]. If in some case the actual queries are such that the corresponding differential probabilities are much lesser than the maximum value, then this bound becomes much higher than the actual advantage of the adversary, i.e. the bound becomes more loose. Let us consider a numerical example to illustrate this scenario.
In this example, we will consider Horner’s rule based hash function and the underlying field to be F2n. The differential probability of the Horner’s rule based hash for two distinct messages of
length`and `0, where`≥`0, is given byε(`, `0) =`/2n. For ease of understanding, in this example let us considerδq = 1, which is true for a uniform random function. Letn= 128,λ0 = 96,qv,λ0 = 1. Let us consider an (rather artificial) upper limit of 220 n-bit blocks on the length of the message the adversary can query on. We consider some scenarios and the corresponding query profile based advantages.
• Scenario 1: For tag length λ0, let the adversary make 1 tag generation query and 1 verifi-cation query, each on a message containing 512 blocks. The differential probability reflected in the bound (20) is ε(512,512) = 29/2128 and the corresponding bound becomes 2−87.
• Scenario 2: For tag length λ0, let the adversary make 1023 tag generation queries and 1 verification query, each on a message containing 1 block. Let one of the tag generation queries have the same nonce as the verification query. Then, the differential probability reflected in the bound (20) is ε(1,1) = 1/2128 and the corresponding bound becomes 2−96.
• Scenario 3: For tag length λ0, let the adversary make one tag generation query and one verification query on messages having 220 blocks and the same nonce. Then, the differential probability reflected in the bound (20) isε(220,220) = 220/2128 and the corresponding bound becomes 2−76.
Let us now consider the query complexity based advantage for the above scenarios. Looking at the bound in (29), we have no clue about which value of the differential probability to be used here. The reason is, in this case, we only have the information regarding the total query complexity, but we do not know the length of each message. As a result, we are forced to use the maximum value of the differential probability which is obtained for 220-block messages resulting in the differential probability to be 220/2128. The corresponding bound given by (29) in all three scenarios becomes 2−76. So, we see that even though the query complexities in Scenarios 1 and 2 is 1024 blocks and the query complexity in Scenario 3 is 221blocks, the query complexity based advantage in all three cases are the same. This illustrates that compared to the query complexity based advantage, the query profile based advantage provides a more granular information about the advantage.
It is to be noted that, the bound given by Bernstein [5] in the security proof of the Wegman-Carter nonce-based MAC scheme is qv,λ0δqε. This bound also lacks the information of particular message lengths. Hence, the difficulty stated above in case of complexity based advantage is appli-cable for this bound as well.
4.1 Reducing Key Size
In a practical instantiation ofNMAC, the random functionfwill be instantiated by a keyed function
FK. The key for the entire scheme will consist of the key K along with the #L keys (τλ)λ∈L for the hash function Hash. Depending on the size of L, for certain applications, the size of the key may be too large. Our next constructions show how to obtain NMAC schemes with short keys.
The hash family{Hashτ}τ∈Θ, the nonce spaceN, the message space M, the set of allowed tag lengths Land the tag space remain the same as in the case of NMAC.
Our goal is to derive the key for the hash function by applying a PRF to the concatenation of the tag length and the nonce. Depending upon the actual choice of the hash function, the key could either be ann-bit string (or, a string of some fixed length which is at leastn), or, it could be a variable length string which depends upon the length of the message. Typical examples of hash function where the key is a fixed length string is the polynomial hash or the BRW hash [4, 18, 6] while typical examples of hash function where the key depends upon the length of the message is either the multi-linear hash [14], or the pseudo-dot product [29], or the UMAC [8] construction.
We consider the key of the hash function to be a sequence of n-bit blocks with the last block possibly being a partial block. Given the hash functionHash and a messagex, let b(x) denote the number of n-bit blocks of key material required by Hash to process the messagex. As mentioned above, depending upon the choice of Hash, b(x) could be independent of x (i.e., Hash uses fixed length keys), or, it could depend upon x (i.e., Hash uses a key which depends upon the length of
x).
We start by constructing a nonce-based MAC scheme from a stream cipher supporting an initialisation vector. The assumption on such a stream cipher is that it is a PRF [2]. Formally, we use the PRF{SCK}K∈K, whereSCK is a stream cipher which maps ann-bit string under the keyK to an output keystream. We will assume that the output keystream is of some fixed length which is sufficiently big for all practical applications. An appropriate length prefix of the output keystream is used in a particular context. We denote the NMAC scheme built from SC as SC-NMAC. The tag generation algorithm for theSC-NMACscheme is shown in Table 3. The verification algorithm
SC-NMAC.VerifyK(N, x,tag, λ) works as follows: compute tag0 =SC-NMAC.GenK(N, x, λ); return
true iftag=tag0, else returnfalse.
The key space forSC-NMAC is K. The key generation algorithm consists of sampling K uni-formly at random from K.
Table 3: A secure and efficient NMAC scheme using a stream cipher supporting an initialisation vector.
SC-NMAC.GenK(N, x, λ)
b=b(x);
(Q, τ) =msb(b+1)n(SCK(bin8(λ)||N));
R=Q⊕Hashτ(x);
tag=msbλ(R); return tag.
The security ofSC-NMACis given by the following result.
Fix a query profile C. For λ ∈ L, let qg,λ (resp. qv,λ) be the number of tag generation (resp. verification) queries for λ which are in C. Let qg =Pλ∈Lqg,λ and qv =Pλ∈Lqv,λ. Let σg (resp.
σv) be the total number of bits in all the tag generation (resp. verification) queries in C.
Let λ be such that qv,λ ≥ 1 and for 1 ≤ i ≤ qv,λ, let Q(v,λi) = (Nv,λ(i), x(v,λi),tag(v,λi), λ) be the i-th verification query with tag length λ. Let `(v,λi) =len(x(v,λi)). Corresponding to Q(v,λi), there is at most
one tag generation query Q(g,λi?) = (Ng,λ(i?), x(g,λi?), λ) such that Nv,λ(i) = Ng,λ(i?). Let `g,λ(i?) = len(x(g,λi?)) if
there is such a Q(g,λi?), otherwise `(g,λi?) is undefined.
Fix λ0 ∈ L. LetSλ0 be the set of all queries made by the adversary other than the verification queries for tag length λ0. Suppose that the queries in Sλ0 give rise to at most q distinct (nonce, tag-length) values. Then
AdvauthSC-NMAC[λ0](t,C) ≤ AdvprfSC(t+t0, qg+qv, n(qg+qv)) + 1 2λ0 ×
X
1≤i≤qv,λ0 γi
(30)
where γi= 2nε(`(v,λi)0, `(i
?)
g,λ0) if there is a Q (i?)
g,λ0 corresponding to Q (i)
v,λ0 with N (i) v,λ0 =N
(i?)
g,λ0; otherwise
γi = 1. Here t0 is the time required to hash qv+qg messages of total length at most σg+σv, plus some bookkeeping time.
Proof. The proof is similar to the proof of Theorem 1. We mention the differences.
The first reductionis to replace SCK by a uniform random function ρ from {0,1}n to{0,1}L. The advantage of the adversary in detecting this change is captured by the termAdvprfSC(t+t0, qg+
qv, n(qg+qv)) in (30). Let the scheme resulting from the replacement be denoted as ρ-NMAC. Since SCK has been taken care of, the ensuing analysis is information theoretic. Let A be a deterministic and computationally unbounded adversary attacking ρ-NMAC and having query profileC. It is required to upper bound Advauthρ-NMAC[λ0](A).
As in the proof of Theorem 1, the task reduces to analysing the probability of the event
succ(A(T), λ0) for a transcriptT whose query profile isC.
The second reductionis to assume thatqv,λ0 = 1;the third reductionis to assume that all queries after the single verification query for tag length λ0 are discarded. These reductions are also used in the proof of Theorem 1 and the justifications for these reductions in the present context are the same as those described in the proof of Theorem 1. As in Theorem 1, consider the set Sλ0 which consists of all queries made by A other than the verification queries for λ0. Further, similar to the proof of Theorem 1, insert queries to the transcript T, to ensure that the number of distinct (nonce, tag-length) pairs arising from the queries in Sλ0 isq.
In view of the above reductions, it is sufficient to consider an adversary A with a tran-script T where the last query is the verification query (N, x,tag, λ0) for tag length λ0. Also, let (N(1), λ(1)), . . . ,(N(q), λ(q)) be the distinct (nonce, tag-length) pairs arising from the queries in
Sλ0. For 1 ≤i ≤q, define N
(i) = bin
8(λ(i))||N(i), (Q(i), τi) = ρ(N(i)) (considering the full length output of ρ), Q = (Q(1), . . . , Q(q)) and τ = (τ1, . . . , τq). The entire randomness in the transcript arises from Qand τ.
At this point, we would like to mention a small difference with the proof of Theorem 1. In the scheme NMAC, the hash key depends upon the tag length, whereas inSC-NMAC, the hash key is determined by (nonce, tag-length) pair. As a consequence, the vector τ defined above has q
Modulo this small difference, the rest of the proof is the same as the proof of Theorem 1. In particular, the proof divides into two cases. The first case is where the adversary does not make any previous tag generation query with (nonce, tag-length) pair equal to (N, λ0) and the second case is where the adversary does make such a query. The probability calculations for these two cases are almost the same as those in the proof of Theorem 1. The only difference is that in the present case,ρ is uniform random function and soδj = 1. Using these values ofδj, the calculations done in the two cases of the proof of Theorem 1 show the bound stated in (30).
The following corollary provides the translation of Theorem 2 in terms of query complexity.
Corollary 2. InSC-NMACdefined in Table 3, suppose that the hash function{Hashτ}τ∈Θ be such that for any distinct x, x0 ∈ M and any y ∈ {0,1}n, Pr[Hash
τ(x)⊕Hashτ(x0) = y] is at most
ε≥1/2n, i.e. εis the maximum of the differential probabilities for all combination of messages. Forλ∈ L, let qg,λ (resp. qv,λ) be the number of tag generation (resp. verification) queries for
λ. Let qg =Pλ∈Lqg,λ and qv =Pλ∈Lqv,λ. Let σg (resp. σv) be the total number of bits in all the tag generation (resp. verification) queries.
Fix λ0 ∈ L. LetSλ0 be the set of all queries made by the adversary other than the verification queries for tag length λ0. Suppose that the queries in Sλ0 give rise to at most q distinct (nonce, tag-length) values. Then
AdvauthSC-NMAC[λ0](t, σg, σv) ≤ AdvprfSC(t+t0, qg+qv, n(qg+qv)) + 2n−λ0qv,λ0ε.
(31)
Here t0 is the time required to hash qv +qg messages of total length at most σg +σv, plus some bookkeeping time.
In the schemeSC-NMAC, the pair (Q, τ) is derived by applying the stream cipher tobin8(λ)||N. Since a stream cipher produces a long enough keystream, a single application of SCis sufficient to obtain the pair (Q, τ). Suppose that we wish to use a PRF F whose output is an n-bit string (or, a short fixed length string). Clearly, then a single invocation of F will not be sufficient to obtain the pair (Q, τ). The PRF F will have to be invoked repeatedly to obtain an output bit string of desired length from which the pair (Q, τ) can be obtained.
Formally, we use a PRF family{FK}K∈K, where for eachK ∈ K,FK :{0,1}n→ {0,1}n. Similar to the case of SC-NMAC, the hash family {Hashτ}τ∈Θ, the nonce spaceN, the message space M, the set of allowed tag lengths L and the tag space remain the same as in the case of NMAC. The key space for the scheme is K. The key generation algorithm consists of samplingK uniformly at random from K.
that τ is uniformly distributed. The differential probability determining the AXU property of the hash function is computed based on uniform randomτ. So, ifτ cannot be considered to be uniform random, the AXU property of the hash function cannot be invoked. As a result, the proof would not go through. On the other hand, up to the birthday bound, it is reasonable to assume that the encryption function of a secure block cipher behaves like a PRF.
Table 4: A secure and efficient NMAC scheme using a short output length PRF.
F-NMAC.GenK(N, x, λ)
b=b(x);
S=FK(bin8(λ)||N);
(Q, τ) =FK(S⊕binn(1))|| · · · ||FK(S⊕binn(b+ 1));
R=Q⊕Hashτ(x);
tag=msbλ(R); returntag.
The security ofF-NMACis given by the following result.
Theorem 3. InF-NMACdefined in Table 4, suppose that the hash function{Hashτ}τ∈Θisε-AXU, where ε(`, `0)≥1/2n for all `, `0 ≤L.
Fix a query profile C. For λ ∈ L, let qg,λ (resp. qv,λ) be the number of tag generation (resp. verification) queries for λ which are in C. Let qg =Pλ∈Lqg,λ and qv =Pλ∈Lqv,λ. Let σg (resp.
σv) be the total number of bits in all the tag generation (resp. verification) queries in C.
Let λ be such that qv,λ ≥ 1 and for 1 ≤ i ≤ qv,λ, let Q(v,λi) = (Nv,λ(i), x(v,λi),tag(v,λi), λ) be the i-th
verification query with tag length λ. Let `(v,λi) =len(x(v,λi)). Corresponding to Q(v,λi), there is at most
one tag generation query Q(g,λi?) = (Ng,λ(i?), x(g,λi?), λ) such that Nv,λ(i) = Ng,λ(i?). Let `g,λ(i?) = len(x(g,λi?)) if
there is such a Q(g,λi?), otherwise `(g,λi?) is undefined.
Fix λ0 ∈ L. LetSλ0 be the set of all queries made by the adversary other than the verification queries for tag length λ0. Suppose that the queries in Sλ0 give rise to at most q distinct (nonce, tag-length) values. Then
AdvauthF-NMAC[λ0](t,C) ≤ AdvprfF (t+t0, Bg+Bv, n(Bg+Bv)) +(Bg+Bv)
2
2n + 1 2λ0 ×
X
1≤i≤qv,λ0
γi (32)
where
• γi = 2nε(`(v,λi)0, `(i
?)
g,λ0) if there is a Q (i?)
g,λ0 corresponding to Q (i)
v,λ0 with N (i) v,λ0 =N
(i?)
g,λ0; otherwise
γi = 1;
• b(v,λi) =b(x(v,λi)), Bv =
P
λ
P
1≤i≤qv,λ
(b(v,λi) + 2);
• b(g,λi) =b(x(g,λi)), Bg =P λ
P
1≤i≤qg,λ
(b(g,λi) + 2).
Proof. The proof is very similar to the proofs of Theorems 1 and 2. We briefly discuss the differences. There are two differences in the bound.
The first difference is in the number of queries to the PRFF in the expression AdvprfF . In the present case, if a query requires b+ 1n-bit blocks to obtain the pair (Q, τ), the number of times F
is invoked isb+ 2. The rest of the analysis proceeds by replacingFwith a uniform random function
ρ from {0,1}n to{0,1}n.
The main argument requires that for distinct values of (N, λ), the random variables (Q, τ) are independent and uniformly distributed. The pair (Q, τ) is derived by successively applying ρ to
S⊕binn(1), . . . ,S⊕binn(b+ 1) whereSitself is obtained by applyingρtobin8(λ)||N. If for distinct values of (N, λ), the quantitiesS,S⊕binn(1), . . . ,S⊕binn(b+ 1) are distinct, then the independent and uniform random distribution of (Q, τ) is ensured.
Let theqdistinct values of (nonce, tag-length) pairs arising from the queries inSλ0 be (N(1), λ(1)), . . . ,(N(q), λ(q)). LetD(i) ={S(i),S(i)⊕bin
n(1), . . . ,S(i)⊕binn(b(i)+ 1)} be the set of random vari-ables in the input of ρ corresponding to (N(i), λ(i)). Let D=∪qi=1D(i) and so #D ≤B
g+Bv. Let
bad be the event that any two of the variables in D are equal. Using the fact that ρ is a uniform random function, it is standard to see that Pr[bad]≤(Bg+Bv)2/2n.
LetA be an adversary attacking the scheme whereF is replaced with ρ. We assume that A is deterministic and computationally unbounded. Let succ(A) be the event that an adversary A is successful. Then
Pr[succ(A)] ≤ Pr[bad] + Pr[succ(A)|bad]
≤ (Bg+Bv)
2
2n + Pr[succ(A)|bad].
Conditioned on the event bad, the pairs (Q(i), τ(i)) are independent and uniformly distributed. From this point onwards, the rest of the proof is exactly the same as the proof of Theorem 2 and provides the same bound. We skip these details.
The following corollary provides the translation of Theorem 3 in terms of query complexity.
Corollary 3. InF-NMAC defined in Table 4, suppose that the hash function {Hashτ}τ∈Θ be such that for any distinct x, x0 ∈ M and any y ∈ {0,1}n, Pr[Hash
τ(x)⊕Hashτ(x0) = y] is at most
ε≥1/2n, i.e. εis the maximum of the differential probabilities for all combination of messages. Forλ∈ L, let qg,λ (resp. qv,λ) be the number of tag generation (resp. verification) queries for
λ. Let qg =Pλ∈Lqg,λ and qv =Pλ∈Lqv,λ. Let σg (resp. σv) be the total number of bits in all the tag generation (resp. verification) queries.
Let λ be such that qg,λ, qv,λ ≥ 1 and for 1 ≤i ≤qg,λ, let Qg,λ(i) = (Ng,λ(i), xg,λ(i), λ) be the i-th tag
generation query with tag length λ; for 1 ≤ i ≤ qv,λ, let Q (i) v,λ = (N
(i) v,λ, x
(i) v,λ,tag
(i)
v,λ, λ) be the i-th verification query with tag length λ.
Fix λ0 ∈ L. LetSλ0 be the set of all queries made by the adversary other than the verification queries for tag length λ0. Suppose that the queries in Sλ0 give rise to at most q distinct (nonce, tag-length) values. Then
AdvauthF-NMAC[λ0](t, σg, σv) ≤ AdvprfF (t+t0, Bg+Bv, n(Bg+Bv)) +(Bg+Bv)
2
2n + 2
n−λ0 ×q
where b(v,λi) =b(x(v,λi)), bg,λ(i) =b(x(g,λi)),Bv =P λ
P
1≤i≤qv,λ
(b(v,λi) + 2)and Bg =P λ
P
1≤i≤qg,λ
(b(g,λi) + 2). Here
t0 is the time required to hashqv+qg messages of total length at mostσg+σv, plus some bookkeeping time.
5
Conclusion
In this paper, we have considered the problem of constructing variable tag length MAC schemes. Several variants obtained from the Wegman-Carter MAC scheme have been shown to be insecure. One of these variants is proved to be secure. This scheme is extended to obtain constructions of single-key nonce-based variable tag length MAC schemes using either a stream cipher or a short-output PRF.
References
[1] Jean-Philippe Aumasson and Daniel J. Bernstein. Siphash: A fast short-input PRF. In Steven D. Galbraith and Mridul Nandi, editors,Progress in Cryptology - INDOCRYPT 2012, 13th International Conference on Cryptology in India, Kolkata, India, December 9-12, 2012. Proceedings, volume 7668 of Lecture Notes in Computer Science, pages 489–508. Springer, 2012.
[2] Cˆome Berbain and Henri Gilbert. On the security of IV dependent stream ciphers. In Alex Biryukov, editor, FSE, volume 4593 of Lecture Notes in Computer Science, pages 254–273. Springer, 2007.
[3] Daniel J. Bernstein. The Salsa20 family of stream ciphers. http://cr.yp.to/papers.html# salsafamily. Document ID: 31364286077dcdff8e4509f9ff3139ad. Date: 2007.12.25.
[4] Daniel J. Bernstein. The poly1305-aes message-authentication code. In Henri Gilbert and Helena Handschuh, editors, Fast Software Encryption: 12th International Workshop, FSE 2005, Paris, France, February 21-23, 2005, Revised Selected Papers, volume 3557 of Lecture Notes in Computer Science, pages 32–49. Springer, 2005.
[5] Daniel J. Bernstein. Stronger security bounds for Wegman-Carter-Shoup authenticators. In Ronald Cramer, editor, EUROCRYPT, volume 3494 of Lecture Notes in Computer Science, pages 164–180. Springer, 2005.
[6] Daniel J. Bernstein. Polynomial evaluation and message authentication, 2007. http://cr. yp.to/papers.html#pema.
[7] Daniel J. Bernstein and Tung Chou. Faster binary-field multiplication and faster binary-field macs. In Antoine Joux and Amr M. Youssef, editors, Selected Areas in Cryptography - SAC 2014 - 21st International Conference, Montreal, QC, Canada, August 14-15, 2014, Revised Selected Papers, volume 8781 of Lecture Notes in Computer Science, pages 92–111. Springer, 2014.