Web Page Noise Removal Using Firefly
Optimization Algorithm
Dr.S.Vijayarani, E.Suganya, K.Geethanjali
Abstract : The World Wide Web has large amount of web pages which contains a large amount of information. The website users facing more difficulties to get their relevant content from the web pages, because the web pages also contains irrelevant/noisy information that mingled with the main content. Nowadays to remove the noise from the web page is a challenging task. It disturbs and irritates the user, if the user searches some information on the internet suddenly the advertisement will appear over the information, the navigational information are scrolled up, ic ons of the Facebook and Twitter are appear left side of the screen, if the user copy paste the reference from the copyrighted information the link will appear on the screen which are disturbing to the user. It makes the user to distract and divert their concentration to other websites or web pages. In this work we have proposed a new model for removing local noises from web pages. The proposed model contains Block Density Based Noise Extractor Algorithm , Document Object Model based page segmentation, Style Density tree, tag based filtering; regular expression, structural analysis and optimization algorithms such as ant colony optimization, particle swarm optimization and firefly.
KEYWORDS: BDBNE Algorithm, DOM based page segmentation, Tag based Filtering, Style Density tree, ACO, PSO, Firefly
————————————————————
1.
INTRODUCTION
Data mining is a significant process that is used to search and extract massive amount of data in order to discover useful data.It includes clustering, classifications, decision tree analysis, and association rules techniques. The most important data mining application is web mining. The World Wide Web has a popular place for scattering and accumulates the information. Extracting the useful information from web pages becomes an essential task. The web is a medium for accessing the information store in different sources. Extracting the information from various resources has many problems like finding the useful information, extracting the knowledge from large data set and learning about individual users. To resolve these problems various methods and techniques are developed [1]. As the amount of information obtained on the web is increasing radically, number of redundant of web content also grows at the same time. Therefore, updating incoming data and retrieving useful information without duplicate data from the web, the web mining research communities to concern an activity that there is quickly and efficiently information from the web. Web mining research is an emerging area from a lot of research communities, for instance Database, Information Retrieval, and Artificial Intelligence, machine learning, psychology, and statistics. Web mining can be categorized into three types; content mining, structure mining and usage mining. Web content mining is useful for user required content i.e. text, image, audio and video extraction from web documents/pages. Web structure mining is deals withthe hyperlinks and also finds the connection among the web pages [3]. It can be classified into two different categories; hyperlink analysis and document structure analysis. Hyperlink analysis helps in connecting web pages to different locations
either in the same web page or on a different web page. A hyperlink is divided into two categories, i.e. intra-document hyperlink and the inter-document hyperlink. Intra document hyperlink connects different part of the same page, whereas Inter document hyperlink connects two different web pages [16]. Web usage mining is also known as web log mining which is used to analyze the user behavior of website users. It discovers user navigation patterns on the web for system improvement, site modification, business intelligence, personalization and usage characterization.
Web page noise removal is an emerging problem of web content extraction. Noise on a web page is not part of the main content of a web page [18] [19]. For example, advertisement banners, graphics, web page links from external web sites, etc. Noise elimination involves detection of web data that needs to be eliminated because it either does not form part of the main web page content or is not useful to a given user [20]. Web page noises are categorized into two kinds: local noise and global noise [18] [23]. Local noise is also referred as intra page level noise which consider the noisy elements in the web page. The advertisements, icons of the social media sites, unnecessary images, and navigational bars are considered as local noises and large granular objects such as duplicated web pages, mirror sites and old versioned web pages are considered as global noises [22]. Manually eliminating noises from the web pages is a challenging and expensive task. In most of the web pages the main content is present in the middle block [5]. The location, occupied area of the web page etc. of the main content play an important role in distinguishing noise patterns from the main content of the web page.
1.1 Problem Specification:
The main objective of the problem is to remove the local noise from the web pages and extract the main content using several methods, techniques and optimization algorithms. The experiments show the best results and optimum solution. The proposed framework removed the local noise and extract the main content from the web pages.
1.2 Research Contribution:
This research work consists of two models. One is existing model, i.e. Block Density Based Noise Extractor and another one is proposed model contains several methods like DOM ————————————————
Author name is currently working as Assistant Professor, Department ofComputer Science, Bharathiar University, Coimbatore, and Tamilnadu, India.E-mail: [email protected]
Co-Author1 name is currently pursuing is currently pursuing Ph.D in Department of ComputerScience, Bharathiar University, Coimbatore, Tamilnadu, India.E-mail: [email protected]
tree, SD tree, tag based filtering as two techniques such as regular expression and structural analysis, optimization algorithms. In the first method, a web page can be segmented by treebased page segmentation method. In this method a web page can be segmented into blocks or regions. A web page is generally separated into five regions: top, down, left, right and center. From this removing the noisy information is possible. It is based on two tree models one is DOM tree and another one is SD tree. The Document Object Model is an object-based and it builds an XML and HTML document as a tree structure in memory. It represents a document as a tree. In order to analyze a web page, first check the syntax of HTML document because most HTML web pages are not well-formed and then it parses web pages through an HTML parser, which corrects the markup and creates a Document Object Model (DOM) tree. After creating the DOM tree, the system splits it into multiple sub-trees according to the threshold level.The SD-Tree (Style-Density Tree) is an HTML DOM tree with features concerning the style and the density of a node. Each node is described by a variety of features explained earlier: Parent node, Child nodes, Tag, Cardinality, Text, Distance from root (dfr), Distance from max density region (dfm), Class, Id, Style, Ancestor title and Ancestor title level. In this phase these two methods are analyzed. In the second phase, tag based filtering methods are analyzed. In the tag based filtering method, regular expression and structural analysis are performed. From this based on the performance measures regular expression gives a better result than structural analysis. The third phase is used for finding the noise in the web pages with the help of filtering. ACO algorithms are existing algorithms used for web page noise removal. This work has found the drawbacks of ACO and these are solved using the proposed PSO and Firefly optimization algorithms. From the experimental results, it is observed thatthe PSO optimization algorithm gives the better result than Firefly algorithm.
2.
RELATED WORKS
Hassan F. Eldirdiery et al.[13]discussed a method called BDBNE (Block Density Based Noise Extractor) that to detect and remove the noisy data from web document. They suggested this algorithm based on the text density approach. The implementation of this technique proved that the textual content of the web document could be used properly to clean the web page from noisy data. This method simply works only on a single web page. Hence it is positively affects the storage and speed factors of the running algorithms. The conducted experiments evaluated the effectiveness of the algorithm and the results showed a significant improvement in the process of detecting and removing noisy data out of web document. In future, this work will be expanded to improve and refine the algorithm by combining other rich data types, such as video, audio and graphics. Yogita K patel et al. [11] are exposed noise elimination method that uses a first outlier detection technique which removed the outlier content and second tag based filtering method implemented by the regular expression which removed the remaining tag from the web pages. The DOM tree is used for segmenting the web pages. The purpose of noise elimination is to improve web content mining. Accurate and effective method to find more relevant document from the web pages. The motivation is to explore new possibilities in improving this area and identifying new ways and methods. So this flow information implies patterns
[10]proposed a DOM Based Page Segmentation method. This method is proposed for noise reduction and extraction of web content from web Pages. The navigational bar, home page and short description noise is removed using DOM based page segmentation which convert the web pages into blocks and regions remove the noise and extract the information based on regions and blocks. Shine N. Das et al. [14]proposed a novel task for finding local noise in web pages. The proposed technique aims at helping document classification in web content mining based on a new tree structure, featured DOM tree, and MWO (Minimum Weight Overlapping) method for similarity verification. Instead of processing a set of web pages as such, this method proposed three stage algorithm which runs on a single web page and increases the mining result remarkably. The authors focuses an optimal feature subset selection method along with a similarity verification method for identifying noisy blocks of a page. The experiment could detect and remove local noises with an increased relevancy. The work evaluates the performance of the algorithm in terms of F score and accuracy of web page classification and it could achieve an improved result with a large margin than before cleaning.
3. METHODOLOGY
3.1 Existing Model
Block Density Based Noise Extractor (BDBNE) Algorithm
The algorithm which is used for extracting the noise known Block Density Based Noise Extractor (BDBNE) algorithm which processes the target web page file and segment the web pages into multiple blocks that has informative and non-informative contents. It analyzed the segmented blocks in order to discriminate the noisy blocks from main content blocks using threshold value. The algorithm works on the HTML file of the web page. It used the sequence of characters outside HTML tags to construct the blocks and ignores the sequence of characters inside HTML tags. The process of detecting noisy blocks based on the text density of the block [13]. The text density is the number of words within a particular 2-dimentional area. Few of the segmented blocks contain noninformative content such as symbols and blank characters. Hence the algorithm identifies these blocks as invalid blocks and excludes them before proceeding to the next step. The process of distinguishing the invalid blocks from valid blocks based on comparing the content of each block with a pattern of characters. The value of the threshold, which used to differentiate the noisy blocks from not noisy blocks, is computed automatically through the processes of the algorithm [13].
3.2 Proposed Model
The proposed model has three different phases. Tree based segmentation, tag based filtering and optimization algorithms. In the tree based page segmentation is done by DOM tree and SD tree. The both methods are working as a same way. But, the SD tree having more features from the DOM tree. But the result will varying from the both model. The second one is tag based filtering. The tag based filtering method uses two different techniques. They are regular expression and structural analysis. Here, both of the methods are used. The last phase is optimization algorithms. There are two optimization algorithms such as PSO and Firefly are implemented and analyzed.
3.2.1 DOM Tree
The Document Object Model (DOM) specification is an object-based interface developed by the World Wide Web Consortium (W3C) that builds an XML and HTML document as a tree structure in memory. An application accesses the XML data through the tree in memory, which is a replication of how the data is actually structured. The DOM also allows the user to dynamically traverse and update the XML document. It provides a model for the whole document, not just for a single HTML tag [6]. The Document Object Model denotes a web document as a tree. It is exceedingly adaptable and can be simply used to renovate a whole webpage. It is an explicit HTML document model. Some HTML tags do not include a closing bracket. For some of these tags, the closing bracket is inferred by the following tag, for example <LI> tag is closed by the following </LI> tag. In order to analyze a web page, first check the syntax of HTML document because most HTML Web pages are not well-formed [5]. After that, it passes web pages via HTML parser that improves the markup and generates a DOM tree. Then the system fragmented it into several sub-trees according to threshold value. Different Websites have different layout and presentation style, therefore the depth of the tree of the Web page is varied according to their presentation style. The system must know the maximum level of DOM tree to choose the good choice of
BDBNE Algorithm: Detect Noisy Blocks
Input: set of valid blocks Bi , i = 0, 1, 2, …, n
Input: threshold value t
Output: set of noisy blocks
Step 1: For each block in the set Bi
Step 2: if density(Bi) != density(Bi+1) then
Step 3: if (epsilon > = t ) Step 4: if (lines(Bi) < = lines(Bi+1)) Step 5: Add Bi to noisy blocks set Step 6: Add i to noisy indices set Step 7: Else
Step 8: Add Bi+1 to noisy blocks set Step 9: Add i+1 to noisy indices set Step 10: End if
Step 11: Else i++ Step 12:End if Step 13: Next for
threshold level. Therefore, the system traverses the whole DOM tree to get the maximum depth of DOM.
3.2.2 SD Tree
The SD Tree (Style-Density Tree) is also a DOM tree with structures regarding the style and the density of a node. Each node is described by a variety of features explained earlier: Parent node, Child nodes, Tag, Cardinality, Text, Distance from root (dfr), Distance from max density region (dfm), Class, Id, Style, Ancestor title and Ancestor title level [8]. For the construction of the SD-Tree, initially the creation of the DOM tree is performed and right after the additional features for each of the nodes is calculated[19].The SD Algorithm recognizes the type of pages (Article, Comments, Multiple areas) and extracts their constituent regions. The algorithm ignores the noisy areas (the side panels, footer, header etc.) and keeps only the regions that have meaningful content. Two thresholds are used, the maximum density region distance threshold T1 and the min region density threshold T2. The T1 threshold, defines the max allowed distance from max density region, so for each node the threshold is compared against the distance from max density region (dfm). The T2 threshold, defines the min allowed de006Esity for a node in order not to be treated as noise [19].The algorithm, using T1 and T2 proceeds as follows:
3.2.3 Tag Based Filtering
Regular Expression
A regular expression is a sequence of characters that formulates a search design for find and replace operation. Most of the patterns are created using regular expression to remove contents enclosed by negative tags. Depending on the content of HTML tags in a web page, the tags can be classified into two types: a) positive tag and b) negative tag [11]. Positive tag contains useful information in a web page. All the tags except positive tags are referred to as Negative tags. Negative tags usually contain information that are not useful and improves the performance of web content mining process [4]. In this work we have defined the following tags as negative tags to remove noisy information from a web page: Anchor tag (<a>), Style tag (<style>), Link tag (<link>), Script tag (<script>), Comment tag (<!-- … -->) and Noscript tag (<noscript>), Horizontal Ruler (<hr>) and Line Break (<br>)[11].
Structural Analysis
Structural analysis and regular expression based method for eliminating noise from the web pages. The two main steps in this method include tag based filtering based on regular expressions and structural analysis of web page. Based on the content of HTML tags, tags are classified into positive tags and negative tags [24]. Contents of positive tag form the useful part of web page while negative tags includes noninformative contents that is not useful. Negative tags include <a>, <style>, <link>, <script>, <hr>, <br> etc. The contents inside the negative tags are removed using patterns which are created using regular expressions [7]. In order to remove noises like navigation panel, menu bar etc. structural analysis of the web pages crawled from the website is carried out. Obviously the aforesaid noise is present in every page of a website and has same content and presentation style.
3.2.4 Optimization Algorithms
Optimization algorithm helps either minimizing or maximizing the value of an objective function which is used to find the best solution. It is divided into two distinct kinds: deterministic and stochastic. The deterministic algorithms are used specific rules are used for moving one solution to other. The stochastic algorithms are in nature with probabilistic transaction rules. There are wide ranges of application where optimization is needed for instance shortest path finding for graph, for example travelling salesman problem. In this research work three optimization algorithms are applied to find the noisy information from the web pages.
Ant Colony Optimization (ACO)
In this algorithm multiple web documents or web pages are taken as input. It reads the web pages one by one. After reading the web pages the HTML tags are checked and to create the DOM tree structure using an html parser. Initially demonstrates the two mechanisms that decide which area of the present web page contains noise or a combination [15]. Then, another method of matching to determine how to process the three classes (noise, data and mixture) in ant colony optimization. Lastly, it removes the several noisy tags in current web page and extract the main content. This algorithm access the multiple web pages, then read one by one web page. After that check the HTML tags for identifying the noisy information and the algorithm considers the web document with various tags. Finally, the algorithm constructs ant colony solution ants will move the node N to C with probability by using the formula:
_____ (1)
Here W is a web page, N is a noise of web page, C is a content of a web page, Tcis the total amount of content on the
web page. Nc is the total amount of noise on the web page, α
is the influence of noise on the web page, β is the influence of content in the web page.
____(2) ΔTncis the amount extracted relevant content. Finally the
noisy information is eliminated and relevant contents are extracted using ant colony optimization algorithm.
Particle Swarm Optimization (PSO)
It is a empirical global optimization process and inspired by swarm intelligence that is based on fish and bird herd progress behaiour. The birds are scattered or gathered for searching the food from one location to another location. The birds can smell its food very well and the bird is observable for having the best foos resource information. The birds will eventually flock to the place where food can be found. The working principle of this algorithm is a bird has a position and velocity while flying. The bird changes the position while searching the food by adjusting velocity based on its previous experience and also receiving feedbacks from his neighbor. Each solution is consider as a bird, known particle. The best particle is adjusting the velocity using fitness value which is deliberated using the objective function. This algorithm can be used to work out the complex optimist problems.
Position of the particles updated as follows:
( ) ____(4)
Where is particle position, is velocity, is best individual particle position, is best swarm position, c1, c2 are cognitive parameters and r1, r2 are random values between 0 and 1. In this research work, PSO algorithm taken multiple web documents or web pages as input. It reads the web pages one by one. After reading the web pages the HTML tags are checked and then create the DOM tree structure using an html parser. After that, train the dataset in database where all the information related to web pages is stored for efficient retrieval of pattern by using PSO technique. The database is created using artificial neural network for storing the related data of the web pages. Matching the constructed DOM tree with data base for eliminating the noisy information. Finally, it can extracts the content.
Firefly Algorithm for Web Page Noise Removal
This algorithm is nature inspired based on the flashing light of fireflies and it mimics how the fireflies are interact each other. There are about two thousand firefly species and most fireflies produce short and rhythmic flashes. The pattern of flashes is often unique for a particular species. In the firefly algorithm multiple web documents or web pages are taken as input. It reads the web pages one by one. After reading the web pages the HTML tags are checked is given in step 3 then consider the web document with various tags. In step 5, objective function is calculated and generate initial population of fireflies in step 6. Light intensity is formulated in step 7 and define absorption coefficient in step 8. In step 9 the maximum generation is evaluated based on the new solution the light intensity is updated. In step 18 and step 19, the noisy information is identified and eliminated. Finally the main content is extracted. All the information related to web pages is stored for efficient retrieval of pattern by using Firefly technique. The database is created using artificial neural network for storing the related data of the web pages. Matching the constructed DOM tree with data base for eliminating the noisy information. Finally, we can get the main content. Initialize objective function f(wi) is calculated using light intensity I(o) which varies according to the inverse square law. The formula is below:
_______(5)Where I(o) is the intensity at the source and r is the observer distance. The light intensity I varies with
the square of distance d. The absorption coefficient γ is calculated using the following formula:
______(6)
Attractiveness of the firefly is proportionally to the light intensity perceived by another fireflies. Brightness observed by adjacent firefly β calculated using the formula:
_____(7)
Next, initialize the firefly‘s population. Firefly i is attracted to the more attracted firefly j, the movement is evaluated using the following formula:
( ) ______(8)
The fitness function of web page noise removal is calculated using the following formula:
_____(9)
Where Ttotis represented as total number of tags in a web
page, Tneg is negative tags in a web page, F is denoted as F-
measure and β is attractiveness of fireflies.
4. RESULT AND DISCUSSION
4.1 Dataset Description
In order to perform the experiments, the real time dataset is collected from different web pages. These web pages contain meaningful content and also have the noises like advertisement banners, navigation bars, copyright links and icons of face book and twitter etc. Here this work considered only HTML format web pages. Table 4.1 shows the details about dataset.
Table 4.1 Dataset
4.2 Performance Measure
In this research work valid blocks, invalid blocks, execution time, precision, recall and F-Measure are considered as
Firefly Algorithm for Web Page Noise Removal
Input: Multiple web pages
Output: Extract relevant content from web pages
Step 1: Access multiple web page Step 2: Read one by one page Step 3: Check web HTML tag
Step 4: Consider the document with various tags Step 5: Objective function f(wi) w=(w1,w2,w3..) Step 6: Generate an preliminary population of fireflies Step 7: Formulate light intensity
Step 8: Define absorbtion coefficient γ Step 9: While (t<Max_ Generation) Step 10: For i=1:n
Step 11: for j=1:n (n fireflies) Step 12: If(Ij> Ii)
Step 13: Move firefly i to j
Step 14: Calculate new solutions and update light intensity
Step 15: End if Step 16: End for j Step 17: End for i
Step 18: Identify the noisy information Step 19: Eliminate the noises
performance factors which is evaluated by number of negative tags and total number of tags.Experiments were conducted to test and evaluate the proposed method effectiveness toward detecting andremoving noisy blocks out of a web page and producing a clear document. The validity and accuracy of the proposed algorithm were checked using the measures recall, precision and F-measure from the field of information retrieval. The dataset that used in the experiments composed of multiple pages from different websites.
_____(10)
_______(11)
_______(12)
Sample Web Pages
Table 4.2 Valid and Invalid Blocks - BDBNE Algorithm
Figure 4.1 Valid and Invalid Blocks - BDBNE Algorithm
Table 4.3 Performance Measures – BDBNE Algorithm
Figure 4.2 Performance Measures – BDBNE Algorithm
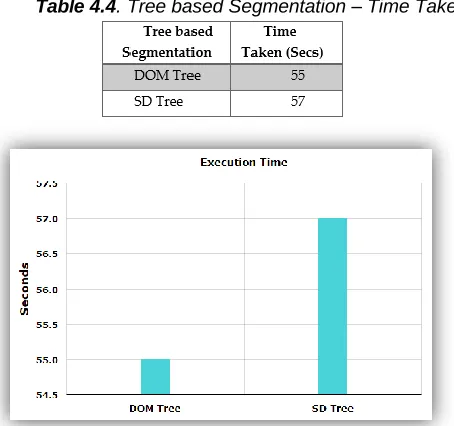
Table 4.4. Tree based Segmentation – Time Taken
Figure 4.3 Tree based Segmentation – Time Taken
Table 4.5 Tree based Segmentation – Precision
Figure 4.4 Tree based Segmentation - Precision
Table 4.6 Tree based Segmentation – Recall
Figure 4.5 Tree based Segmentation - Recall
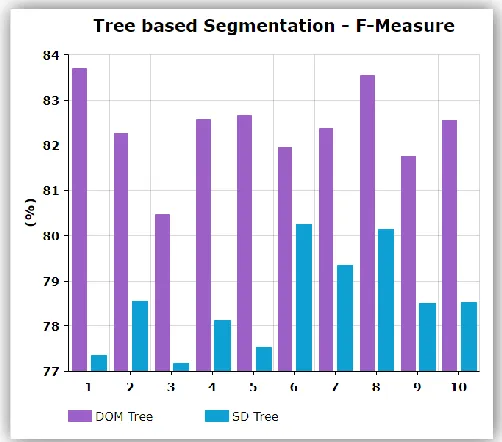
Figure 4.6 Tree based Segmentation - F-Measure
The above tables and charts are described the performance measures between DOM Tree and SD Tree. This comparison explains that the DOM Tree gives better performance than SD Tree. So, that the DOM Tree is the best technique for analyzing the html tags. There are three performance measures are performed such as precision, recall, F-Measure. Precision is the proportion of the removed noise. Recall is the ratio of the noises removed. F-Measure is combining precision and recall scores into a single measure of performance. Here, the negative tags are considered as noisy information.
Table 4.8 Performance Measure for Tag based Filtering
Figure 4.7 Performance Measure - Tag based Filtering
The optimization techniques Ant colony optimization, PSO and firefly are used in this experiment. The Ant colony optimization is an existing one and the PSO, firefly are proposed things. These optimization techniques are finding the easiest path to find the solution for the problem. The following table and charts shows the performance measure of optimization algorithms.
Table 4.9. Performance Measure -Optimization Algorithms
Figure 4.8 Performance Measure -Optimization Algorithms
Table 4.10 Comparison of Existing and Proposed Model
The above table 4.11 and figure shows the comparison of the existing and proposed model. The proposed model used to identify the noisy information the web pages after that remove those noises and extracts the meaningful information with high accuracy using of tree segmentation, tag based filtering and optimization algorithms. Here the existing model i.e. BDBNE algorithm identified only 28% of noises from the web pages but the proposed model identified 35% of noises and also the existing model removed only 21% of noises but the proposed model removed 34% of noises and extract the meaningful content.
5.
CONCLUSION
Web page noise removal is an emerging problem of web content extraction. Noise on a web page is not part of the main content of a web page. Here, we consider some of the techniques like DOM tree, SD Tree, outlier detection, duplicate detection, tag based filtering and optimization algorithms. The DOM tree and SD tree are the same techniques to solve the html web page. But there is some difference between them. Based on those differences, any one technique will be the best. For identifying the best technique, apply both techniques for the same web pages.This paper considering five different web pages and applied both techniques to the web pages. Finally, the DOM Tree gives the better result than the SD tree. So, the DOM tree is the best technique.Here, there are three optimization algorithms are compared for web page noise removal. They are Ant colony optimization, PSO and Firefly. In this three algorithms are applied for the same web pages. Here the ant colony optimization and particle swarm optimization algorithms are existing. Firefly optimization is the proposed algorithm. The existing model and proposed model are compared. The existing model i.e. BDBNE algorithm gives less accuracy when comparing the proposed model with high accuracy and extract the meaningful information from the web pages.
REFERENCES
[1] AnchalGarg, Bikrampal Kaur ―Web Page Performance Enhancement by Removing Noise‖, International Journal of Computer Applications (0975 – 8887) Volume 103 – No.6, October 2014
[2] S. S. Bhamare, Dr. B. V. Pawar ―Survey on Web Page Noise Cleaning for Web Mining‖ (IJCSIT) International Journal of Computer Science and Information Technologies, Vol. 4 (6) , 2013, 766-770
[3] Qinghai Bai ―Analysis of Particle Swarm Optimization Algorithm‖ Computer and Information Science, Vol. 3, No. 1, 2010.
[4] SurabhiLingwal ―Noise Reduction and Content Retrieval from Web Pages‖ International Journal of Computer Applications (0975 – 8887) Volume 73– No.4, July 2013. [5] Mrs.Madhushree B, Yogita K Patel ―A Review on Noise
Removal from Web pages for Web Content Mining ‖ International Institution for Technological Research and Development Volume 1, Issue 1, 2015
[6] SekharBabuBoddu ―Eliminate the Noisy Data From Web Pages Using Data Mining Techniques ‖ GESJ: Computer Science and Telecommunications 2013, No.2(38) ISSN:1512-1232
[7] Hassan F. Eldirdiery, A. H. Ahmed ―Detecting and Removing Noisy Data on Web Document using Text
Density Approach‖ International Journal of Computer Applications (0975 – 8887) Volume 112 – No. 5, February 2015.
[8] MrsMadhushree B, Yogita K Patel ―A Review on Noise Removal from Web pages for Web Content Mining‖ International Institution for Technological Research and Development Volume 1, Issue 1, 2015.
[9] Rajni Sharma, Max Bhatia,―Eliminating the Noise from Web Pages using Page Replacement Algorithm ‖ (IJCSIT) International Journal of Computer Science and Information Technologies, Vol. 5 (3), 2014, 3066-3068 [10] Sandeep Kaur, AbhishekTyagi, ―Noise Reduction and
Content Extraction from Web Pages Using DOM Based Page Segmentation‖ Int.J.Computer Technology & Applications,Vol 5 (6),2022-2027
[11] Yogita K patel ,Mr.NarendrasinhLimbad, ―Noise Removal from Web pages for Web Content Mining‖ IJARIIE-ISSN(O)-2395-4396 Vol-2 Issue-3 2016
[12] ThandaHtwe, Nan Saing Moon Kham ―Extracting Data Region in Web Page by Removing Noise using DOM and Neural Network‖ 2011 3rd International Conference on Information and Financial Engineering, vol.12 (2011) IACSIT Press, Singapore
[13] Hassan F. Eldirdiery,A. H. Ahmed ―Detecting and Removing Noisy Data on Web Document using Text Density Approach‖ International Journal of Computer Applications (0975 – 8887) Volume 112 – No. 5, February 2015
[14] Shine N. Das, Pramod K.Vijayaraghavan, Midhun Mathew, ―Eliminating Noisy Information in Web Pages using featured DOM tree‖ International Journal of Applied Information Systems (IJAIS) – ISSN: 2249-0868 Foundation of Computer Science FCS, New York, USA Volume 2– No.2, May 2012.
[15] Shaikh SakinaBanu, Hitesh Kumar Bhatia, ―Elimination of Noisy Information from Web Page using DOM and Ant Colony Optimization‖, International Journal of Engineering Research & Technology (IJERT) Vol. 3 Issue 2, February - 2014 IJERT ISSN: 2278-0181.
[16] HuiXiong, Member, IEEE, Gaurav Pandey, Michael Steinbach, Member, IEEE, and Vipin Kumar, Fellow, IEEE ―Enhancing Data Analysis with Noise Removal‖ IEEE Transactions on Knowledge and Data Engineering , VOL. X, NO. X, XXX 200X
[17] Nikolaos Pappas ―Extracting Informative Textual Parts from Web Pages Containing User-Generated Content‖ i-Know‘12,September05-07, 2012,Graz,Austria 2012, ACM978-1-4503-1242-4/12/09
[18] L. Yi, B. Liu, and X. Li, ‗Eliminating Noisy Information in Web Pages for Data Mining‘, in Proceedings of the Ninth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 2003, pp. 296–305.
[19] Dutta, S. Paria, T. Golui, and D. K. Kole, ‗Structural analysis andregular expressions based noise elimination from web pages for web content mining‘, in 2014 International Conference on Advances in Computing, Communications and Informatics (ICACCI), 2014, pp. 1445–1451.
[21] V. Chitraa and A. S. Thanamani, ‗Web Log Data Analysis by Enhanced Fuzzy C Means Clustering‘, Int. J. Comput. Sci. Appl., vol. 4, no. 2, pp. 81–95, Apr. 2014.
[22] P. Sivakumar and R. M. S. Parvathi, ―An efficient approach of noise removal from web page for effectual web content mining,‖ Eur. J. Sci. Res., vol. 50, no. 3, pp. 345–356, 2011.
[23] L. Yi et. al., ―Web page cleaning for Web mining through feature weighting,‖ In Proceedings of Eighteenth International Joint Conference on Artificial Intelligence, 2003.