A Persistent Functional Language for
Concurrent Transaction Processing
Lesley Wevers
Master’s Thesis
Department of Computer Science
University of Twente
Graduation Committee:
dr. Marieke Huisman
dr.ir. Ander de Keijzer
prof.dr. Jaco van de Pol
Abstract
In this thesis we investigate the construction of transaction processing systems using functional programming languages. The traditional method for the construction of a transaction processing system is to use a database management system (DBMS) to-gether with a general purpose programming language (GPPL). However working with a DBMS from a GPPL is difficult due to the impedance mismatch, and this model limits the potential concurrency of the system as a whole. We have developed a prototype per-sistent functional language for transaction processing that solves these problems.
In our language, states are a set of bindings from values to expressions. Transactions may evaluate expressions in the context of the current state, and they may update the bindings in the state. In our approach, a DBMS is implemented in our language using bulk data structures. A transaction processing application can be implemented within the same system, thus resolving the impedance mismatch. A domain specific interface for the transaction processing application can be created using stored transactions. Ad-ditionally, our systems allows ad-hoc querying and manipulation of the data through an interactive interpreter.
Our language model can be implemented efficiently through graph reduction. Concur-rency can be introduced through lazy reduction of states, which allows higher levels of concurrency than existing concurrency control methods. We have implemented a graph reducer based on template instantiation, which has been adapted to allow bindings to be created dynamically by resolving references to supercombinators statically such that unused bindings can be garbage collected automatically. We have implemented a transaction manager for our language model that allows the concurrent execution of transactions. Additionally, we introduce a novel approach to parallel graph reduction, where we distribute work among reduction threads by randomising the reduction order of strict function arguments, and by ensuring that reduction results are correctly shared between reduction threads.
Further, we investigate methods for storing states in persistent memory. One method is based on snapshotting the state of the system, allowing checkpointing of ongoing computations. Another method is based on log-structured storage, and allows storage of large states with low recovery times. We combine both of these approaches to allow checkpointing of ongoing computations, storing states larger than main-memory, and supporting low recovery times. In all of these approaches we use journaling as a method to ensure durability of transactions. For our prototype we have implemented journaling together with a simplified version of snapshotting that does not support checkpointing of ongoing computations.
Acknowledgements
First, I would like to thank my supervisors: Marieke Huisman, Ander de Keijzer and Jaco van de Pol. They have provided me the opportunity to define my own master’s project, as well as providing me vital feedback while writing this thesis. Marieke was my main advisor, with whom I had a SCRUM meeting almost every day. I would especially like to thank Ander for offering up his free time to help me with this thesis after he left the university.
I would also especially like to thank Stefan Blom who always took the time to discuss problems, and who provided many technical suggestions of which some led to the results in this thesis, most notably the combined approach to storing states in persistent mem-ory. Also, I would like to thank Elmer Lastdrager with whom I had a daily coffee break, and who provided me with many helpful suggestions.
From my group, I would like to thank Alfons Laarman and Tom van Dijk for taking the time and helping me with the system on which I have run the experiments, and providing insight into parallel algorithms. Also, I would like to thank Maarten de Mol for helping me on the topic of functional programming.
Also, I would like to thank my fellow final year students with some of whom I have shared the office: Freark van den Berg, Harold Bruintjes, Ronald Burgman, Gerjan Stokkink, Paul Stapersma and Vincent de Bruijn. They have provided me with a nice environment at the university, although sometimes a bit too ’gezellig’. I would also like to thank the rest of the FMT group for nice conversations during lunch as well as the occasional discussion.
Contents
1. Introduction 1
1.1. Traditional Transaction Processing Systems . . . 1
1.2. Problems in the Traditional Model . . . 2
1.3. Persistent Functional Languages . . . 4
1.4. Our Approach . . . 4
1.5. Early Work and Goals . . . 6
1.6. Contributions . . . 7
1.7. Thesis Outline . . . 7
I. Background 9 2. Functional Programming 11 2.1. The Lambda Calculus . . . 11
2.2. Functional Programming . . . 12
2.3. Lazy and Parallel Evaluation . . . 14
2.4. Graph Reduction . . . 15
2.5. Conclusions . . . 16
3. Functional Transaction Processing 17 3.1. Transaction Processing . . . 17
3.2. A Model for Functional Transaction Processing . . . 19
3.3. Executing Functional Transactions Efficiently . . . 21
3.4. Executing Functional Transactions Concurrently . . . 22
3.5. Transactional Functional Languages . . . 24
3.6. Conclusions . . . 27
II. Contributions 29 4. A Prototype Functional Transaction Processing Language 31 4.1. Expressions . . . 32
4.2. Transactions . . . 33
4.3. Stored Transactions . . . 35
4.4. Domain-Specific Interfaces . . . 36
5. Graph Reduction for Transaction Processing 39
5.1. Preliminaries . . . 39
5.2. Template Instantiation . . . 40
5.3. Adaptations for Dynamic Bindings . . . 41
5.4. Implementation Overview . . . 42
5.5. Resolving Free Variables . . . 44
5.6. Weak Head Normal Form Reduction . . . 47
5.7. Normal Form Reduction . . . 50
5.8. Conclusions . . . 51
6. Parallel Graph Reduction by Randomisation and Sharing Results 53 6.1. Preliminaries . . . 53
6.2. Parallelism in Functional Languages . . . 54
6.3. Randomisation and Result Sharing . . . 55
6.4. Randomisation and Result Sharing for Graph Reduction . . . 55
6.5. Result Sharing in Weak Head Normal Form Reduction . . . 56
6.6. Randomisation in Weak Head Normal Form Reduction . . . 59
6.7. Result Sharing and Randomisation in Normal Form Reduction . . . 62
6.8. Conclusions . . . 63
7. A Transaction Manager for Transactional Functional Languages 65 7.1. Overview . . . 65
7.2. Executing Transactions and Stored Transaction Calls . . . 68
7.3. Handling Concurrent Transactions . . . 70
7.4. Forcing Evaluation of Transactions . . . 72
7.5. Conclusions . . . 73
8. Maintaining Persistence 75 8.1. Characteristics of Persistent Storage . . . 75
8.2. Journaling . . . 76
8.3. Snapshotting . . . 76
8.4. Log-Structured Storage . . . 78
8.5. Mixed Approach . . . 81
8.6. Implementing Journaling and Snapshotting . . . 82
8.7. Conclusions . . . 90
III. Evaluation 91 9. Experiments 93 9.1. Experimental Setup . . . 93
9.2. Parallel Graph Reduction . . . 94
9.3. Transaction Processing - Concurrency . . . 97
Contents
9.5. Conclusions . . . 104
10.Related Work 105
10.1. Imperative Persistent Languages . . . 105 10.2. Functional Persistent Languages . . . 106 10.3. Parallel Graph Reduction . . . 107
11.Conclusions 109
1. Introduction
Where transaction processing systems could once only be found in the realm of large organisations, the decreasing cost of computing resources and the advent of the internet have made transaction processing systems an integral part of many small organisations and almost every website. Typical examples of transaction processing systems include banking systems, ticket reservation systems and inventory management systems. A transaction processing system often manages all the data of an organisation. Data that has to be available instantly, sometimes to many thousands of simultaneous users, while providing the illusion that each user has exclusive access to the data. It is also crucial that the data is kept safe from system failures, outside attackers, as well as programming mistakes. All of these requirements make the construction of a transaction processing system a challenging task.
In this thesis, we investigate the use of functional programming languages for the con-struction of transaction processing systems. It has already been known for some time that functional languages provide an interesting basis for the implementation, querying and manipulation of databases [26, 28, 38], which are an essential part of a transaction processing system. Interesting properties of functional programs are that they can be executed lazily and in parallel. When a program is executedlazily, only those parts of program are executed that are necessary to produce its result. This provides a basis for concurrent execution of transactions written in a functional programming language, as we only have to compute the modifications to those parts of the database that a trans-action requests, thereby enabling fast response times. Laziness also ensures that we only access the minimal part of the data that is necessary for the execution of a transaction, thereby minimising access to slow persistent storage media such as hard-disk drives. Another interesting property of functional programs, is that they are inherentlyparallel, allowing execution of transactions in parallel without explicitly introducing parallelism. Finally, functional programs are known to be relatively easy to reason about, providing a basis for verifying correctness of transaction processing systems.
1.1. Traditional Transaction Processing Systems
Before we describe our approach, we outline a common approach to the construction of transaction processing systems so that we can contrast this to our approach.
• Adata modelthat determines how databases are structured, and which also defines the basic operations that can be performed on databases. Examples of data models include the relational model [13] and the XML data model [17].
• Aprogramming interfacefor the interrogating and manipulation of databases. This is usually a high-level declarative language, allowing user to performad-hocqueries, leaving it up to the DBMS to determine how to execute queries efficiently. The programming interface is usually explicitly designed to work with the data model provided by the DBMS. For example, in relational databases a common program-ming interface is SQL, while for XML databases XQuery and XPath are commonly used.
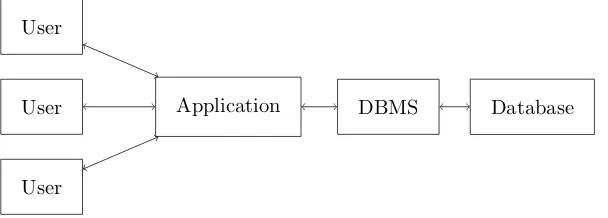
While a DBMS could in principle be used as a complete transaction processing system in itself, end users do not typically work directly on the DBMS for to two main reasons: the programming interface is not user friendly for the end users of the system, and it poses a security risk. To solve these problems, a transaction processing systems usually also consists of anapplication that provides an interface to the users of the system, such as a website or a physical device such as an ATM [23]. Figure 1.1 shows a an overview of such an architecture.
User
User
User
[image:12.612.174.478.336.445.2]Application DBMS Database
Figure 1.1.: Architecture of a simple transaction processing system.
The application translates transaction requests from the user into database programs that are sent to the DBMS, and translates responses from the DBMS into responses suit-able for end users. Additionally, the application can enforce additional domain specific security rules that can not be enforced by the DBMS itself.
1.2. Problems in the Traditional Model
1.2. Problems in the Traditional Model
provided by the DBMS. This divide between the DBMS and the application creates several problems, as described in the remainder of this section.
First, queries on the database are usually built dynamically from inside the GPPL by composing strings and values. This creates the possibility of command injection attacks [36], as well as making it difficult to validate the correctness of an application because regular type checking can not be applied.
Second, the mapping between the data model of the GPPL and the data model of the DBMS is often complex and unnatural, a problem known as the impedance mismatch
[17]. A programmer is required to explicitly map concepts from the DBMS to concepts in the programming language, and vice versa. Also, a database usually supports only a fixed set of data types, where an application may need additional data types. Creating a mapping between data types requires a lot of effort from the programmer, and is prone to error.
Third, because the system is distributed, the application programmer has to take care that DBMS failure is handled correctly. This complicates the implementation of the application as failure may occur at any point in the program where it communicates with the DBMS. Additionally, as the application and the database are different processes, they may evolve separately. Even if the correctness of the application has been verified, the schema of the database may change, which could lead to incorrect behaviour if the application is not updated.
Fourth, the communication between the application and the DBMS usually takes place over a network, which may incur a high overhead in the execution time of transactions. This is especially the case if the execution of a transaction requires a lot of interac-tion with the DBMS. Also, communicainterac-tion between an applicainterac-tion and a DBMS is often performed sequentially. This limits the potential to execute transactions in parallel. Ad-ditionally, as the DBMS does not know about the future actions of a user updating the database, the DBMS is unable to perform certain optimisations to the concurrent execu-tion of transacexecu-tions, limiting the performance of a DBMS while executing transacexecu-tions concurrently.
1.3. Persistent Functional Languages
An approach to solve many of the problems as described in the previous section is to integrate a GPPL with the features of a DBMS, as to close the divide between them. Such a system can either be seen as apersistent programming language [4], or a DBMS with an integrated programming language. For the purpose of this thesis we use the term persistent programming language, which can be seen as a programming language that transparently manages the storage of its state in persistent memory. Persistent programming languages solve many of the problems as discussed in the previous section: queries can be written in the same language as that is used for the construction of the application, the application and the DBMS are under the same type system, the system is not distributed, and there is no network communication overhead between the DBMS and the application.
Many attempts have already been made towards the development of persistent program-ming languages [1, 2, 4, 14, 25], but some of the problems as discussed in the previous section still remain. We observe that almost all of the existing systems are based on the use of imperative programming languages to define transactions. Using functional programming languages can solve some of the remaining problems.
One problem with the imperative programming model is that it is very different from the declarative model of many database query languages. In an imperative language, you not only have to tell the system what you want, but also how the system has to do it. This makes imperative languages difficult to use for querying and manipulating databases, and it is difficult to optimise transactions in an imperative language. In contrast, func-tional languages are quite close to the declarative model of database query languages. Research has been done that shows that list comprehensions in functional languages are relationally complete, and that functional transactions can be optimised similarly to optimising declarative database queries [38]. This makes functional languages well suited for querying databases.
Another problem when using imperative languages for defining transactions is that they are not well suited for concurrent execution [7]. One of the reasons for this is that imperative transactions must be executed sequentially. In contrast, there is flexibility in the execution order of a functional program, as any execution order produces the same result. This allows concurrency control through lazy evaluation of transactions, allowing higher levels of concurrency than possible using imperative languages. Furthermore, the flexibility in execution order also allows parallel execution of independent parts of a transaction.
1.4. Our Approach
1.4. Our Approach
an observable result. In order to provide persistence, we transparently store the states produced by transactions in persistent memory.
In our approach, the system itself does not provide a data model. Instead, a DBMS with a corresponding data model is implemented in our language. This makes our system very flexible, as any kind of data model can be implemented. A standard library of DBMS implementations can be provided with the language such that a user does not have to implement a DBMS itself. The systems ensures that concurrent operations on the database are executed correctly, and storage of states in persistent memory is handled automatically.
Transactions are written in the same language that is used to implement the DBMS, thus solving the impedance mismatch. Furthermore our language allows the definition of stored transactions to provide a method for the construction of the application part of a transaction processing systems. Figure 1.2 shows the architecture of a transaction processing system in our approach.
User
User
User
Application DBMS Persistent Language
[image:15.612.108.475.299.407.2]Persistent Store
Figure 1.2.: Architecture in our approach.
In contrast to the traditional approach, in our approach a transaction is sent in its entirety to the system, instead of using a sequential interface to issue individual queries. Because of this, all operations on the database are known when the transaction starts, allowing the execution of independent parts of the transaction in parallel. This also means that slow clients can not affect the performance of the system, as there is no interaction during the execution of a transaction. Further, transactions are guaranteed to commit, so there is no explicit management of transaction commits and aborts. A potential disadvantage of our approach is that the system does not support interactive transactions, however we have ideas to solve this issue, which is discussed briefly in the future work section.
1.5. Early Work and Goals
Before we discuss our contributions, we shortly review earlier work that has been done in the area of functional persistent languages.
In 1985, Nikhil proposed the use of functional languages for the implementation, query-ing and updatquery-ing of functional databases [28]. In particular, Nikhil proposed that a functional database can be viewed as an environment that maps identifiers to expres-sions. A transaction may evaluate an expression in the context of an environment to query the environment, and a transaction may update the database by replacing the environment with a new environment. Furthermore, Nikhil sketched an approach to implement what he calls a functional database programming language.
In 1989, Trinder [38] also explored the use of functional languages to construct func-tional databases. He defined a model where transactions are functions that take the current state of the database, and produce a new state of the database. A transaction manager takes a stream of such transactions, and executes them sequentially, producing a stream of results. As the state, Trinder uses bulk data structures such as binary trees to implement functional databases. Trinder showed that lazy evaluation of the states produced by transactions allows concurrent execution of transactions. Furthermore, he identified limitations to concurrency, as well as identifying approaches to overcome some of these limitations.
Existing implementation of persistent functional languages include STAPLE by Mc-Nally [26], and AGNA by Nikhil [29]. Both of these approaches are based on the model by Nikhil. However, a limitation of both approaches is that they do not support the concurrent execution of transactions. STAPLE supports persistence through the use of a generic persistent object system, while Agna supports persistence through paging but does not satisfy the durability requirements for transaction processing.
The main goal of this thesis is to develop a persistent functional language that supports concurrent transaction processing, and we want to investigate methods for persistence that are optimised for functional languages. As a starting point for our language we use the model as described by Nikhil and Trinder [38]. Concretely, our goals are to develop:
1. A functional language that can be used for transaction processing.
2. Methods for the concurrent execution of transactions.
3. Methods for the efficient storage of functional states in persistent memory.
1.6. Contributions
1.6. Contributions
Concretely, this thesis describes the following contributions:
• a language for the definition of transactions in a functional language, including stored transactions for the construction of applications;
• a prototype implementation of our language that supports concurrent execution of transactions and storing states in persistent memory;
• a graph reducer based on template instantiation that has been adapted for trans-action processing;
• a new method for load balancing in parallel graph reduction, based on sharing results between reduction threads, and randomising their reduction order;
• a discussion of different methods for storing functional states in persistent memory, allowing both the storage of suspended computations, as well as supporting states that are larger than main-memory;
• forcing the evaluation of transactions as a solution to space leaks that show up in the theoretical model due to lazy reduction of states; and
• an experimental evaluation of our prototype.
1.7. Thesis Outline
In the first part of the thesis, we present a study on the background of functional transaction processing. First, we review functional programming in Chapter 2. Then in Chapter 3, we provide an overview of functional transaction processing and we discuss a model for transactional functional languages.
In the second part of the thesis, we describe our contributions. We begin by describing our language for defining functional transactions in Chapter 4. Next, in Chapter 5 we describe a graph reducer that has been adapted to allow dynamic creation of bindings. In Chapter 6, we present our load balancing method for parallel graph reduction. In Chapter 7, we describe the implementation of a concurrent transaction manager for our language, and we forcing the evaluation of states. Finally, in Chapter 8 we describe methods for storing states in persistent memory.
Part I.
2. Functional Programming
In this chapter we review functional programming, which provides an alternative model of computation to the commonly used imperative programming model. Computation in the imperative model is performed as a side-effect of the sequential execution of in-structions. In contrast, functional programming models computation in terms of the evaluation of expressions. A functional program is essentially an expression that is re-duced until a non-reducible expression is obtained, which is the result of the program. Functional programming allows a form of reasoning that is similar to reasoning in math-ematics. Additionally, in contrast to the sequential nature of imperative programs, functional programs are naturally concurrent, and can be executed in parallel without affecting the result of a program.
In this chapter we first discuss the lambda-calculus, which provides the theoretical basis of functional programming. Next, we discuss how functional programming languages extend the lambda-calculus. After that we discuss the reduction order in the execution of functional programs. And finally, we discuss graph reduction as a method to implement lazy functional languages efficiently.
2.1. The Lambda Calculus
At the basis of functional programming is theλ-calculus [5], which is a model of compu-tation introduced in 1936 by Church [12]. Compucompu-tation in theλ-calculus is not based on the execution of instructions, but on the reduction of expressions in the λ-calculus. In this model, a computational problem can be encoded as aλ-calculus expression, which when fully reduced produces the result to the problem. In this section we provide a quick overview of the λ-calculus, and we define some of the terminology that we use in this thesis.
An expression in theλ-calculus consists of three basic syntactic elements:
• variables: x,y, z, . . . ;
• lambda abstractions of the form λx.E; and
• applications of the form (E1E2).
Where E, E1 and E2 are expressions in the λ-calculus. Additional parenthesis may
Some examples of expressions in theλ−calculusare: y
(λx.x) ((λx.x)y) (λx.(x x)λx.(x x))
Bound Variables and Free Variables
A lambda abstraction of the form λx.E is said to bind all occurrences of x in E. A variable x is bound if x is part of the body of a lambda-abstraction that binds x. A variablexisfree if it is not part of the body of a lambda-abstraction that binds x. For example, in the expressionλx.(x y), xis a bound variable, andy is a free variable. An expression is said to beclosed if it does not contain free variables.
Reduction
Reduction of a λ-calculus expression is performed by means of β-reduction, which is defines as a rewrite rule ((λx.E)s)→ E[x:=s], whereE[x:= s] is a capture-avoiding substitution that substitutes all free occurrences of x in E by s. For example, the expression ((λx.(x x))y) is reduced as follows:
((λx.(x x))y)→(x x)[x:=y]→(y y)
Underβ-reduction, a lambda-abstraction λx.E can intuitively be seen as a definition of an anonymous function of a single variablexwith abodyE. An application (E1E2) can
intuitively be seen as a call or invocation of a functionE1 with the parameterE2.
An expression of the form ((λx.E)s) is called areducible expression, orredex for short. If an expression does not contain any redexes, it is said to be innormal form. For example, (y y) is in normal form because it does not contain a redex, but (y((λx.(x x))y)) is not in normal form as is contains the redex ((λx.(x x))y).
An expression can be reduced to normal form by repeatedly rewriting it using β-reduction. However, not every expression has a normal form, for example (λx.(x x))(λx.(x x)) reduces to itself, so its reduction does not terminate. However, if there exists a termi-nating reduction sequence, then the normal form of an expression isunique.
2.2. Functional Programming
2.2. Functional Programming
Functions
Encoding a program into a single λ-calculus expression is quite cumbersome. In func-tional programming languages, this problem is solved by allowing the definition of func-tions, which are named expressions that may refer to one another by their name. Usually there is onemain function which, when reduced to normal form, produces the output of the program. During the execution of a functional program, references to functions are resolved by substituting them with their corresponding expression in the program. For example, consider the following program:
incr = λx.(x+ 1)
main = (incr 7)
The execution of this program consists of reducing the main expression (incr7). In order to do this, we first have to resolve the referenceincr, obtaining the redex ((λx.x+ 1) 7) which can then be reduced to 8.
Additionally, functional programming languages usually allow functions to be written in the more traditional formf(x1, . . . , xn) =E, which can be translated to an expression
f=λx1 . . . . λxn . E.
Data Constructor Functions
Functional programming languages also commonly provide methods to construct com-plex data types through data constructor functions. In contrast to regular functions, data constructor functions can not be reduced. For example, lists can be represented recursively using two data constructor functions, usually named Cons and Nil, where
Cons represents a list element followed by a list, andNil represents an empty list. To encode the list [1,2,3], we can write:
Cons 1 (Cons 2 (Cons 3Nil))
In order to work with constructor functions, functional programming languages usually provide case distinction expressions. Consider the following example:
length(x) = casexof
N il→0
Cons xxs →1 +length xs
Primitive Data Types
Encoding basic data types such as integers is not very practical in the λ-calculus, as well as being very inefficient in practice. For this reason most functional programming languages allow the use of primitive data types and primitive functions, such as number types and arithmetic functions. We have already seen the use of primitive data types in the examples above.
2.3. Lazy and Parallel Evaluation
At any time during the reduction of a functional expression, there may be multiple re-dexes that can be reduced. Typical programming languages evaluate the arguments of a procedure before invoking the procedure. Additionally, purely functional program-ming languages allow lazy evaluation of function arguments, delaying the evaluation of an argument until they are actually needed. For example, consider the following function:
f(x y) =if x >0then xelse y
If we reduce f(4 (3×3)) under eager evaluation we obtain the following reduction sequence:
f(4 (3×3))→f(4 9)→if 4>0then 4else 9→4 Under lazy evaluation we obtain the following reduction sequence instead:
f(4 (3×3))→if 4>0then 4else (3×3)→4
We see that under lazy evaluation, (3×3) is not evaluated, as it is not needed to produce the normal form of the expression. Lazy evaluation is very important for our functional transaction processing language, as it allows concurrency by reducing states lazily, as discussed in Chapter 3.
Additionally, lazy evaluation allows the definition of control flow structures such as if-expressions as functions as opposed to special language constructs as is common in eagerly evaluated languages. Additionally, lazy evaluation has the property that if there exists a reduction order that terminates, then lazy evaluation terminates. In practice this allows the use of recursively defined infinite data structures in a functional program, such as the Fibonacci sequence, while still guaranteeing that the program terminates.
In order for lazy evaluation to be correct, functions must be pure. A pure function is a function that is deterministic and is side-effect free. A function is deterministic if given the same input, it always produces the same output. A function is side-effect free
2.4. Graph Reduction
An important consequence of purity is that reduction of expressions that only contain pure functions results in a unique normal form. This means that during reduction any
reduction order may be chosen, and we are guaranteed to obtain the same result. Eager evaluation corresponds to reducing theinnermost redexes in an expression first, and lazy evaluation corresponds to reducing theoutermost redexes in an expression first.
To precisely define the reduction order chosen by lazy evaluation, we use the notion of weak head normal form [33]. We say that an expressionE is inweak head normal form if Eis a lambda-abstraction, a data constructor function, or a primitive data type. In lazy evaluation, we always reduce toward weak head normal form. In Chapter 5 we discuss how this is done in our prototype implementation.
Another implication of purity is that sub-expressions may be reduced in parallel, while the final result remains deterministic, which means that the functional programming model is naturally parallel. This is in contrast to the imperative programming model, where parallelism generally has to be introduced explicitly, and where it may lead to non-deterministic results. However, in order to take advantage of parallel reduction, a program has to make sure there are always multiple sub-expressions that can be reduced at any one time.
2.4. Graph Reduction
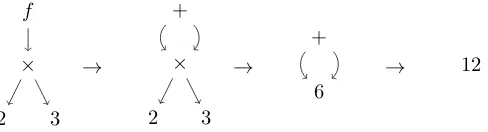
Graph reduction is a method for the efficient implementation of lazy functional program-ming languages. To illustrate why graph reduction is needed, consider that we have a function f(x) =x+x, and we want to know the normal form off(2×3). Under lazy evaluation we obtain the reduction:
f(2×2)→2×3 + 2×3→6 + 2×3→6 + 6→12
Note that the argument 2×3 is duplicated when instantiating the function body of f, requiring us to evaluate the argument twice. Under eager evaluation this does not happen, as shown in the reduction:
f(2×3)→f(6)→6 + 6→8
f
×
2 3
→
+
×
2 3
→
+
6
[image:26.612.201.445.97.163.2]→ 12
Figure 2.1.: Graph reduction off(2×3).
Figure 2.1 shows how reduction of f(2×3) is performed using graph reduction. On the left side we see f(2×3) in graphical form. When we reduce this graph, we see that the sub-graph for 2×3 is shared when the body of f is instantiated. Sharing of a computation result is performed by overwriting the root of a reducible expression. Similarly, graph reduction allows sharing of data in order to conserve memory, as can be seen in the example by sharing the intermediate result 6.
2.5. Conclusions
In this chapter we have provided a quick review of functional languages, and the prop-erties that are relevant for this thesis. In particular, we have seen:
• The lambda-calculus provides the basis of functional programming languages.
• Functional programming languages extend the lambda calculus with structured data, primitive data types and primitive functions, as well as allowing programs to be defined as multiple expressions that may refer to one another.
• Purity provides flexibility in the reduction order of functional programs, allowing lazy and parallel reduction.
• Graph reduction provides a method for the efficient implementation of lazy func-tional languages.
3. Functional Transaction Processing
In this chapter we discuss the theoretical background of using functional languages for transaction processing . First, we discuss transaction processing in general. Next, we review the work by Trinder [38] as a model for functional transaction processing. After that, we show that this model can be implemented efficiently using graph reduction. Next, we show that this model allows concurrent execution of transactions by lazy re-duction of states. Finally we discuss a model for transactional functional languages, based on the work by Nikhil [28].
3.1. Transaction Processing
In this section we first discuss the general concepts of transaction processing and trans-action processing systems.
Atransaction is a collection of operations on a state that provides guarantees about its execution as a whole [18]. Transactions are used in data management systems such as databases, file systems and version control systems, to ensure that operations on the data are executed correctly. Most such systems guarantee four correctness properties for the execution of transactions, known as theACID properties [19]:
Atomicity: Either all operations in a transaction are executed, or none at all.
Consistency: Consistency rules are not violated in the states between the execution of transactions.
Isolation: The result of transactions executing in parallel is the same as the result for some sequential executions of the transaction.
Durability: Once a transaction has been committed, its effects must persist even in the case of system failure.
A transaction can be terminated by either committing, making its effects persistent, or
We can now formalise the property of isolation in terms of serialisability and recover-ability:
Serialisability: A concurrent execution of a set of transactions producing some final state isserialisable if some sequential execution of the transactions produces that same final state.
Recoverability: Committed transactions may not have read data that is written by aborted transactions. This implies that, as long as a transaction thas not been committed, all transactions that have read changes by t can not commit until t commits, and if t chooses to abort, all transactions that have read changes by t must also abort.
A transaction processing system is a system that manages the concurrent execution of transactions by multiple users on a single state. A typical example of a transaction processing system is a banking system, where the state consists of bank accounts, and where transaction types include transferring funds between accounts, depositing funds, withdrawing funds, and adding interest.
In the literature, many examples of transaction processing systems can be found, ranging from simple single-computer systems, to very complex multi-server systems as can be found in large organisations [23]. This thesis only considers transaction processing in
shared memory systems, where all state resides on one machine. Transaction processing can also be done in distributed systems, but this is outside the scope of this thesis.
Ensuring that the ACID properties hold results in two main challenges for transaction processing system implementations:
• In order to minimise execution times of individual transactions, the system has to be able to execute transactions concurrently, i.e. it must allow the execution of transactions to overlap in time. In order to ensure that serialisability and re-coverability are not violated, a transaction processing system typically applies
concurrency control techniques.
• The system has to maintain the ACID properties even in the case of a system failure. Writes to persistent storage may only be partially complete at the time of failure, which may lead to inconsistent states or transactions not being exe-cuted atomically. A transaction processing system usually solves this byjournaling
transactions before executing them, and by executing arecovery procedure after a system crash that restores the state using information from the logs. This is discussed in more detail in Chapter 8
3.2. A Model for Functional Transaction Processing
3.2. A Model for Functional Transaction Processing
In this section we discuss how functional languages can be used for the construction of transaction processing systems, by reviewing the work of Trinder [38].
A transaction function is a function of type State → State × Result that takes a state and produces a new state together with anobservable result. Figure 3.1 shows a pictorial representation of a transaction function.
Transaction Function
s:State s�:State
[image:29.612.158.419.205.255.2]t:Result
Figure 3.1.: A transaction function.
As an example, consider that State = Integer × Integer and Result = String. We could define the following transaction functions in a functional language:
1 get_a (a, b) = ((a, b), show a)
2 get_b (a, b) = ((a, b), show b)
3 swap (a, b) = ((b, a), "")
Here we assume that theshow function converts its argument into a string. Theget a
and get b state transformers respectively produce as their observable result the first and second integer from the state, and return the state as it is. Theswap state trans-former swaps the two integers in the state, and returns an empty string as its observable result.
A functional transaction processing system can be constructed using atransaction man-ager function of type State×[Transaction] → [Result] that takes an initial state and a stream of transactions, and produces a stream of results. A simple implementation of a transaction manager function in a functional programming language is the follow-ing:
1 tm : State × [Transaction] → [Result]
2 tm state [tx:txs] = result:(tm new_state txs) where
3 (new_state, result) = tx(state)
That is, given a statestate, we take a transaction tx from the stream of transactions
t1 t2 . . . tn
s0 s1 s2 sn−1 sn
[image:30.612.162.487.94.149.2]r1 r2 rn
Figure 3.2.: Executing a stream of transactions.
Figure 3.2 shows how thetmfunction works for the execution of a stream of transaction functions t1, t2, . . . , tn on an initial state s0. We see that the output state of each
transaction ti is the input state of the next transaction ti+1. Additionally, we see that
the stream of transactions functions produces a stream of observable resultsr1,r2,. . .,
rn.
For example, using the transaction functionsget a, get band swap that we have just seen, we can execute the sequence of transactions[get a, get b, swap, get b, ...]
on the state initial state(1, 2) using thetm function as follows:
tm (1, 2) [get a, get b, swap, get b, . . . ]→["1", "2", "", "2", . . . ]
Assuming that we want multiple users to use the system, we can assume that each user produces a stream of transactions, and expects a stream of results. To obtain a single stream of transactions for thetmfunction, the streams from the users have to be merged into a single stream of transactions. Trinder merges the streams from multiple users non-deterministically. Additionally, we have to distinguish which result in the output stream belongs to which user. To do this, transactions in the merged stream can be tagged by the identifier of the user. The transaction manager can tag a result using the tag of the transaction it processed, such that we know to which user a result belongs. Because we implement our prototype in an imperative language, our approach differs from that of Trinder, so we will not cover this topic in further detail.
What is interesting about the functional transaction processing model is that it is rel-atively east to guarantee that the ACID properties hold. Serializability is trivially sat-isfied, as transactions are executed serially. Recoverability can be satisfied by requiring that all transactions are total functions. Atotal function is a function that always pro-duces a result. This also means that transactions have to handle any error that may occur, such as consistency errors. For example, a consistency property on a state can be guaranteed by wrapping a transaction functiontby a function of the form:
if g(t(s)) then t(s) else s
3.3. Executing Functional Transactions Efficiently
A limitation of this model in practice is that we have to assume that transactions can not abort due to run-time errors such as running out of memory. Another problem in practice is that transactions may be non-terminating, or take a very long time to terminate. However, these issues are out of the scope of this thesis.
3.3. Executing Functional Transactions Efficiently
Now that we have seen how the functional transaction processing model works, we will now discuss the efficient implementation of this model using graph reduction, as shown in the work of Trinder [38], Nikhil [28] and McNally [26].
Using graph reduction, we can represent a state as a graph that has a single root node. When a transaction is applied to a state graphs, a new state graphs� is constructed. The essential idea to maintain efficiency is that if sub-graphs of the states are used in the construction of s�, we share those sub-graphs between s and s� instead of copying
the whole graph. Intuitively we could say that in the construction of the new states�, we only encode hows� differs from s.
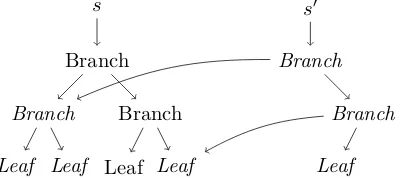
To make efficient use of sharing, it is neccesary that states have a tree structure, as this allows sharing of whole branches of the tree that are not modified. If instead the state has a sequential structure, such as a list, we are forced to copy most of the state if a single element is modified.
s Branch
Branch
Leaf Leaf
Branch
Leaf Leaf
s�
Branch
Branch
[image:31.612.191.391.416.505.2]Leaf
Figure 3.3.: Sharing common sub-graphs between states.
Figure 3.3 shows an example of sharing in action. We see two states, where s and s� are pointers to the root nodes of these states. The initial statescontains some abstract tree data structure. After a transaction updates a single tree element of the states, we obtain the states�. We see that only the path from the root of the tree to the updated element is stored in the new states�, and we refer to the old states for branches of the tree that have not been modified. Nodes reachable froms� are emphasised, showing that
the amount of memory required to store the states� does not increase compared to the
3.4. Executing Functional Transactions Concurrently
In the previous section we have seen that the functional transaction processing model can be implemented efficiently using graph reduction for transactions that are executed serially. However, for acceptable response times in a transaction processing application, we need to be able to execute transactions concurrently. In this section we show how functional transactions can be evaluated concurrently by reducing states lazily, as shown in the work of Trinder [38].
The essential idea for concurrency in functional transaction processing is that while a states is being constructed by a transactiont, another transactiont� can already start producing a new state s� based on the parts of s that have already been constructed. This idea essentially shows that concurrent evaluation of transactions is possible, as both transactions tandt� are evaluated at the same time.
Taking this idea further, we can first construct those parts of the statesthat are required for the construction of the new state s�. This idea can be implemented by constructing states lazily. That is, we only construct parts of the states if they are required for the construction of state s�. This means that states do not have to be reduced to normal form at all unless their normal form is required. In a transaction processing system, only the observable results of transactions need to be reduced. This means that parts of states only have to be reduced if they are required for the reduction of a transaction result.
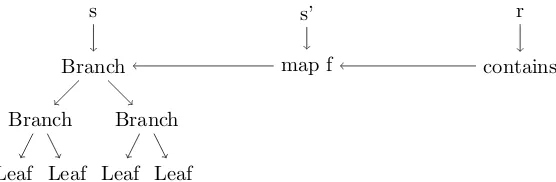
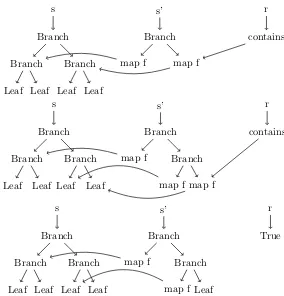
We now illustrate this concept through an example. Assume that we have some initial states, containing some abstract tree data structure. We have a transaction functiontu
that takes sand constructs a new state s� by applying a mapping functionmap to the tree in state s, mapping the function f. We also have a transaction tr applied to the
states� that reads the state by producing as observable resultr a boolean representing if some element is contained in the tree using a function contains. For simplicity, we omit the details of the function and data structure implementations.
s
Branch
Branch
Leaf Leaf
Branch
Leaf Leaf
s’
map f
r
[image:32.612.185.463.482.573.2]contains
Figure 3.4.: Example system before reduction.
Figure 3.4 shows a graphical representation of the example system before any reduction has taken place. We see that spoints to the root node of the initial state, s� points to
3.4. Executing Functional Transactions Concurrently
We see that common parts ofs ands� are shared, and we see that common parts of s�
[image:33.612.145.429.250.546.2]andrare shared.
Figure 3.5 shows intermediate steps in the reduction of the observable resultr. It can be seen that the parts of s� that are required for the reduction of r are reduced on demand through lazy evaluation. In the first and second reduction step, in order to evaluatecontains we first need the result ofmap f. In both cases we reducemap f to obtainBranch, which enables contains to be reduced by a single step, selecting one of the branches. In the last reduction step,map f evaluates toLeaf, allowing thecontains
function to reduce to its final result: True.
s Branch Branch Leaf Leaf Branch Leaf Leaf s’ Branch
map f map f
r contains s Branch Branch Leaf Leaf Branch Leaf Leaf s’ Branch
map f Branch
map f map f
r contains s Branch Branch Leaf Leaf Branch Leaf Leaf s’ Branch
map f Branch
map f Leaf
r
True
Figure 3.5.: Concurrent evaluation of functional transactions.
Limitations to Concurrency
The amount of concurrency that can be provided by this method is not unlimited. Trinder [38] was the first to investigate some of the limitations of this form of concurrency, and provided some approaches to overcome these limitations. In this section we will only discuss the limitations to concurrency, and refer the reader to the thesis of Trinder for additional details.
The evaluation of a transaction can be blocked by a redex that prevents access to a part of the state while it is being reduced. For example, if we have an expression E =if xthen aelse b, then either the valuea orbis only constructed when the value of x is known. So, all transactions that require access to the result ofE are prevented from making progress until the evaluation ofxhas been completed.
Using the concept of blocking, we can analyse how transactions might affect each other. A transaction that does not modify the state never hinders another transaction, as it does not insert redexes into the state. A transaction that modifies the state without reading from it is itself also never blocked, as the new state is reduced lazily. However, a transaction that modifies the state may hinder transaction that read the state, as the redexes that it inserts into the state may block access to part of the state that another transaction needs to access.
Blocking should present be no problem for redexes whose reduction takes just takes a constant number of steps. An example of such a redex is the application of map as in the example in the previous section. However, if the reduction of the redex requires a number of reduction steps dependent on one of its arguments, access to parts of the state could be prevented for a long time.
A concrete example of this problem that Trinder provides is maintaining balance in binary search trees when inserting elements. The problem here is that we only know if we need to re-balance at a certain node after the element has been inserted. This means that for the redex at the root of the tree, we only know what the result is once insertion is completely done, preventing concurrent access to the tree completely during the insertion of an element.
3.5. Transactional Functional Languages
3.5. Transactional Functional Languages
States
Astate in a transactional functional language is a set ofbindings from names to expres-sions, where expressions may refer to other expressions in the state by their name. A state is similar to a regular functional program, except that there is no main function. Transactions allow the state to be changed over time by replacing the state by a new state.
Expressions in the state can represent data as well as functions. A data expressions may include primitive data types such as integers and strings, as well as bulk data types such as lists, trees, relations and graphs. A function expression is aλ-abstraction, which may be used to operate on the data stored in the state. Consider the following example:
users → Cons ”Alice” (Cons ”Bob” (Cons ”Eve” Nil)) length → λlist . case list of
Nil→ 0
(Cons x xs)→ 1 + length xs
This example shows a state where the expressionusers models a list of user names, and the expressionlengthis a function that can be used to compute the length of a list.
Transactions
Atransaction in a transactional functional language consists of two parts, a result ex-pression and anupdate environment.
Aresult expression is an expression to be evaluated in the context of the current state, where the expression may refer to expressions in the state by their name, and which produces the observable result of the transaction. The result expression is in a way similar to the main expression of a functional program, with the main difference being that multiple result expressions may be evaluated over the same state by issuing multiple transactions. Consider the following example:
result = length users
In this example, the free variables length and users refer to expressions in the state. When evaluated in the example state as shown in the previous sub-section, this expres-sion reduces to the value 3.
Consider the following example:
length’ = length
users’ = Cons ”Dave” users
In this example, again the free variables length and users refer to expressions in the state. When evaluated in the state as in the previous sub-section, the lengthfunction is copied to the new state, and a new username “Dave” is prepended to the list in users.
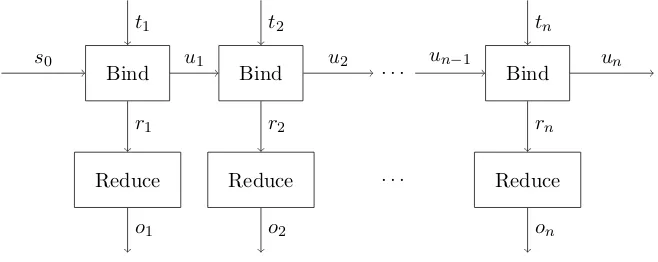
Execution of Transactions
Now that we have seen the structure of transactions and states, we can describe how transactions are executed in this model. Execution consists of two steps, binding the transaction to the state, and reducing the result expression. Binding a transaction to the state is performed by resolving names that refer to expression in the state. The bound environment is the state for the next transaction The bound result expression can be reduced to normal form to obtain the observable result of the transaction.
Bind Bind . . . Bind
Reduce Reduce . . . Reduce
s0 u1 u2 un−1 un
r1 r2 rn
t1 t2 tn
[image:36.612.159.488.317.448.2]o1 o2 on
Figure 3.6.: Executing transactions in a transactional functional language.
Figure 3.6 shows the flow of data for the execution of a sequence of transactionst1,. . .
, tn on an initial states0. Each transactiontiis bound to the state, producing a bound
update environment ui, which is the state for the next transaction, and producing a
3.6. Conclusions
3.6. Conclusions
In this chapter we have seen how functional languages can be applied to transaction processing. In particular, we have seen:
• The concept of transactions and transaction processing systems.
• A model for functional transaction processing systems.
• The efficient implementation of functional transaction processing by sharing com-mon parts between states.
• Using lazy reduction of states to allow concurrent execution of functional transac-tions, and the limitations of this approach.
• A model for transactional functional languages that allows bindings in the state to be created dynamically.
In Chapter 4 we describe our prototype language, which is based on the model for transactional functional languages that we have seen in this chapter. In Chapter 7 we discuss the implementation of a transaction manager that implements the execution of transactions in transactional functional languages. In Chapter 5 we discuss a procedure
resolvethat implements the binding operation to execute transactions, and a procedure
Part II.
4. A Prototype Functional Transaction
Processing Language
In the previous chapter we have discussed functional transaction processing, and we have seen a model for transactional functional languages. In this chapter we describe a pro-totype language for functional transaction processing that incorporates these ideas. Our language is similar to a regular functional programming language, but it has additional constructs for transaction processing.
<transaction> ::= (<definition>| <stored>)*
<stored> ::= ‘transaction’<variable>( ‘(’<variable>* ‘)’ )? ‘{’<definition>* ‘}’
<definition> ::= <variable>( ‘(’<variable>* ‘)’ )? ‘=’<expression> <expression> ::= LITERAL
| (<variable> |<constructor>) ( ‘(’<expression>* ‘)’ )?
| ‘match’ <expression>‘{’ (<pattern>‘->’<expression>)+ ‘}’
| ‘let’ ( <variable>‘=’<expression>)* ‘{’ <expression>‘}’ <pattern> ::= <constructor>( ‘(’ (<variable>|‘ ’ )* ‘)’ )?
[image:41.612.100.504.292.432.2]<variable> ::= ‘a’..‘z’ (‘a’..‘z’ |‘A’..’Z’)* ‘’’ ? <constructor> ::= ‘A’..‘Z’ (‘a’..‘z’ |‘A’..’Z’)*
Figure 4.1.: Grammar of prototype language.
4.1. Expressions
We start out by discussing the expressions language of our prototype language, which is similar to existing functional programming languages.
Expressions are defined recursively, and can be:
• Aliteral, such as an integer, a floating point number or a string.
• Afunction application of the form f(v1 . . . vn) that denotes the application of
the argumentsv1 . . . vn to f, wheref is either a variable or a data constructor
function. Iff has no arguments, the parenthesis may be omitted.
• A match expression of the form match E {P1 -> E1 . . . Pn -> En } that
de-notes a case distinction over the data constructor function obtained by reducing E, and reduces to Ei in Pi -> Ei if Pi matches the data constructor function.
A pattern has the form C(v1 . . . vn), and matches a data constructor function
of the form D(v1 . . . vm) if C = D, where m must be equal to n. A pattern
of the form C(v1 . . . vn) -> E binds the variables v1, . . . , vn in the expression
E. Additionally, each pattern C(v1 . . . vn) in a match expression must have a
distinct constructorC, which implies that the order of patterns does not affect the semantics of the program.
• Alet binding of the form let v1 = E1 . . . vn = En in E that denotes that the
variablesv1, . . . , vn with values E1, . . . , En are bound in E. A let expression
ex-plicitly introduces sharing of the expressionsE1, . . .,En inE.
Our language supports structured data throughdata constructor functions, as discussed in Section 2.2. A data constructor function is distinguishable from regular functions as data constructor functions start with an uppercase character, where regular function names start with a lowercase character.
Furthermore, our prototype implementation features some built-in functions that may be used in expressions. We have the arithmetic functions add, sub, mul and div to operate on primitive numerals. We have a function equals that checks for equality of two primitive literals a and b, returning True if a = b or False if a �= b. We have a function compare that compares two primitives a and b and returns LT if a < b, EQ if a = b or GT if a > b. Finally, we have a special function seq that evaluates its first argument to weak head normal form, and returns its second argument. The function
4.2. Transactions
4.2. Transactions
Our language differs from regular functional programming languages in that programs are transactions that are executed in the context of a state. In our language, a state consists of a set of bindings of names to closed expressions, as well as a set of stored transactions. A transaction may produce a value as its result by means of a result expression that is evaluated in the context of the state, and a transaction may modify the state by adding, removing or updating bindings and stored transactions.
The system accepts a sequence of transactions as input, where transactions may come from many different users using the system concurrently. Semantically, this sequence of transactions is executed sequentially, thereby ensuring atomicity and isolation. Our implementation of this language enables concurrent execution of transactions, as well as ensuring durability of the effects of executed transactions. The implementation of our language is discussed in the chapters following this chapter.
Atransactionconsists of a set of definitions and a set of stored transactions. Adefinition
can be of the form x = E where x is variable and E is an expression, or it can be of the formf(v1 . . . vn) = Eto define a function expressionf=λv1. . . . λvn. E. Stored
transactions are discussed in the next section.
In order to support transaction processing, we introduce two kinds of variables: current state variables and next state variables. To distinguish them syntactically, next state variables are primed. For example, we writex to refer toxin the current state, and we write x’ to refer tox in the next state. All expressions may refer to both the current state and the next state.
In contrast to the transactional functional language model, a transaction in our language only describes the updates to the state. In order to specify an update to the state, we assign an expression to a next state variable. For example by writingx’ = E, the value of xisE in the next transaction that is executed. We may also assign values to current state variables to define functions that do not go into the state, i.e. that are local to the transaction. E.g. we may write x = E, and use the variable xin the transaction. We also have a special local variableresult, which when assigned produces the observable result of the transaction.
Example: A Database of User Names
We now illustrate the use of our language for defining functional transactions by means of some examples. Let us assume that we want to create a database of user names where we want to be able to add user names, see a list of all user names in the database, test if a certain user name is in the database, and see how many user names are in the database.
list. To test if a certain user is in our database, we use a generic function to test if an element belongs to a list. To query how many users there are in our database, we use a generic function to compute the length of a list.
1 users’ = Nil
2 length’(list) = match list {
3 Nil -> 0
4 Cons(x xs) -> add(1 length’(xs))
5 }
Listing 4.1: Setting up the database.
Listing 4.1 shows a transaction that updates the state to include a variableusers, which is initialised to the empty list, and a functionlength that can be used to compute the length of a list. Note that in the definition of length’ we refer to length’ itself to create a recursive function. If we would refer to length instead, we would refer to the value of lengthin the current state.
1 users’ = Cons("bob" users)
2 result = length(users’)
Listing 4.2: Inserting a user name.
The transaction as shown in Listing 4.2 inserts a user into the database, and requests the size of the resulting database. Note that in the expressionusers’we refer tousers
in the current state; thus inserting a user into the existing database. The observable result of the transaction is the length of users’, which includes our newly inserted user “bob” as we refer tousersin the next state.
1 contains(value list) = match list {
2 Nil -> False
3 Cons(x xs) -> match equals(x value) {
4 True -> True
5 False -> contains(value xs)
6 }
7 }
8 result = contains("bob" users)
Listing 4.3: Querying the database.
4.3. Stored Transactions
4.3. Stored Transactions
A stored transaction is a predefined transaction that is stored in the state of the system, and is similar to a stored procedure in traditional database management systems. A stored transaction may be parameterised, and can be invoked multiple times. Stored transactions provide a basis for the construction of a domain specific interface to a functional transaction processing system, as discussed in the next section.
First, the main difference between a stored transaction and a function is that a function defines a transformation over an expression, while a stored procedure defines a transfor-mation over a state. This means that, given a state, a stored transaction can be executed on its own, while a function is part of an expression in a transaction.
The definition of stored transactions is part of a regular transaction, as it modifies the state of the system. A stored transaction consists of a name, a list of parameter names, and abody that is a transaction. The body of a stored transaction is a regular transaction, but this transaction is only executed when the stored transaction is called. When a stored transaction iscalled with a set of argument bindings, free variables in its body are bound to the current state and the arguments that have been provided.
Consider the following example:
1 transaction add_user(name) {
2 result = contains(users name)
3 users’ = match result {
4 True -> Cons(name users)
5 False -> users
6 }
7 }
This transaction defines a stored transaction calledadd userthat has a parametername. The body of the stored transaction contains a result expression that tests whethername
is already in the listusers, and inserts nameinusers if the name is not already in the list. This example shows that a stored transaction can enforce a consistency rule, as it enforces that no duplicates are inserted into a list.
A stored transaction can be invoked through an external interface, for example an HTTP interface could be used to invoke the stored transaction from the example as follows:
POST /add user?name=bob
The observable result of the stored transaction call can be returned in the body of the HTTP response.
Additionally, if our language would be extended to support typing, a stored transaction only has to be type checked and pre-compiled when it is inserted into the state. This allows a higher level of performance than using regular transactions, as less work has to be performed per transaction.
4.4. Domain-Specific Interfaces
Being able to invoke stored transactions using an external interface provides a basis for the implementation of a domain-specific interface to an application in our language. Figure 4.2 shows a possible architecture of a system based on this approach. The appli-cation consists of a set of stored transactions that implement a domain-specific interface. Additionally, this architecture extends the architecture that was shown in the introduc-tion with a presentaintroduc-tion layer. The presentaintroduc-tion layer is outside the persistent language, and can be a website, or a physical system such as an ATM.
User
User
User
Presentation Application DBMS Persistent Language
[image:46.612.164.484.284.408.2]Persistent Store
Figure 4.2.: Architecture in our approach.
4.5. Conclusions
4.5. Conclusions
In this chapter we have seen a language for the definition of transactions using functional languages. In particular, we have seen:
• The syntax of our language.
• Expressions, data constructor functions and built-in functions in our language.
• Current state variables and next state variables provide a basis for defining func-tional transactions that operate on a state consisting of a set of bindings.
• Stored transactions can be invoked externally, and provide a basis for security and performance optimisations.
• Stored transactions can provide a basis for the construction of transaction process-ing systems with a domain-specific interface.
5. Graph Reduction for Transaction
Processing
In this chapter we discuss the implementation of graph reduction for the implementation of functional programming languages. As a basis for our implementation we use template instantiation [32], which we have modified to allow bindings to be created dynamically. We use the graph reducer discussed in this chapter as the basis for a parallel graph reducer, which is discussed in Chapter 6.
In this chapter, we first discuss the notation that we use to describe our implementation. Next, we review template instantiation as a method for the implementation of graph reduction. We then discuss the modifications to template instantiation that are needed to create bindings dynamically. After that, we provide a global overview of our graph reduction implementation, followed by the details of our implementation: resolving free variables, weak head normal form reduction, and finally the reduction of graphs to normal form.
5.1. Preliminaries
Our implementation is written in Java, but for the purpose of conciseness we describe the implementation in a pseudo-language. We now briefly cover the notation that we use in this thesis.
We assume that memory is laid out according to a pointer structure model. A pointer structure consists of a fixed number of named fields that each have a corresponding value. Values can be either pointers to other nodes, primitive data values, or an array of values.
We writetype T = f1:T1 * . . . * fn:Tn to define the type of a nodeTthat has fields f1, . . ., fn of their respective typesT1, . . ., Tn. We writedata T = C1(f1:T1, . . .,
fn:Tn) | . . . | Cn(g1:U1, . . ., gn:Un)to define an enumeration data type Twith
pa-rameterised elements identified by a constructor C1, . . ., Cn. Given a pointer x : T
whereTis an enumeration data type, we can determine if xhas constructorCby writing
x is C.
In the definition of procedures, we assume that we can pattern match on the constructor of an enumeration data type. For example, if we define a procedure f(C(x) : T) {
f(new C(x)), then f(C(x) : T) is invoked. If we execute f(new D(x)), then f(x : T)is invoked.
We assume that parameters are passed by reference if an argument is a node or array, or passed by value if an argument is of a primitive data type. We writea ← bto assign
btoa.
We write n.f to access a field f of some node n. New nodes can be constructed by writingnew T(v1, . . ., vn), whereTis the type of the node, andv1, . . ., vn are values
that are assigned to the fields of the node being constructed, in the order of its type definition.
We can construct a new array of type T and lengthn by writing new T[n]. We write
a[i] to access the ith element of an array a, where the first index of the array is 0. Furthermore we assume that that we can request the length of an array a by writing
a.length.
Finally, for this implementation we are not concerned with memory management. We assume that an unlimited amount of memory is available. In our actual implementation in Java, the garbage collector reclaims memory that is no longer accessible to provide the illusion of having an unlimited amount of memory available.
5.2. Template Instantiation
We now discusstemplate instantiation [32] as a method for the implementation of graph reduction to implement lazy functional programming languages.
The basic idea of template instantiation is that for every function in a functional program we construct a template graph. All template graphs