The Effective Procession of Apriori Algorithm Prescribed
Data Mining on Medical Data
1
Potta Swathi,
2Bodapati Prajna
1,2Dept. of Computer Science and Systems Engineering, Andhra University, Visakhapatnam, AP, India
Abstract
Data Mining is a standout amongst the most inspiring zone of exploration that is turned out to be progressively prominent in health organization. Data Mining assumes an essential part to uncover new patterns in medicinal services organization which thus accommodating for all the gatherings connected with this
field. This study investigates the utility of different Data mining methods, for example, arrangement, bunching, affiliation, and
relapse in health space. In this paper, we show a brief presentation of
these systems and their focal points and detriments. This overview additionally highlights applications, difficulties and future issues
of Data Mining in medicinal services. Suggestion with respect to the reasonable decision of accessible Data Mining method is additionally talked about in this paper. Broad measures of data put away in restorative databases require the advancement of devoted instruments for getting to the data, data investigation, learning revelation, and successful utilization of sloretl data and data. Across the board utilization of restorative data frameworks and dangerous growth of medicinal databases require ordinary manual data examination to be combined with strategies for skilled PC helped investigation. In this paper, I utilize Data Mining strategies for the data examination, data getting to and learning disclosure strategy to demonstrate tentatively and for all intents and purposes that how steady, capable and quick are these procedures for the
study in the specific field? A strong numerical edge (0 to 1) is set to break down the data. The acquired result will be tried by applying
the way to deal with the databases, data stockrooms and any data stockpiling of various sizes with various passage values.
Keywords
Frequent Diseases; Data Mining; Medical Data; Association Rule; Apriori Algorithm
I. Introduction
Data mining is a method for mining the conceivably helpful data from the Data. Design acknowledgment is a kind of arrangement where an info example is grouped into one of the few classes in light
of its likeness to these predefined classes. The present development
of Data mining capacity and items is the aftereffect of years of impact from numerous orders including databases, data recovery, measurable calculation and machine learning, sight and sound and design this advancement is because of the backing of three advances that are adequately develop: gigantic data gathering, elite
figuring and data mining calculation. Continuous example mining
has applications running from interruption recognition and Market wicker bin investigation, to MasterCard extortion anticipation and medication disclosure. Learning Discovery in databases is the procedure of recognizing a substantial, possibly valuable and at
last justifiable structure in data. This procedure includes selecting
or examining data from a data distribution center, cleaning or pre-handling it, changing or lessening it, applying an data mining segment to create a structure and afterward assessing the inferred structure. Along these lines, the structure that are the result of the data mining process must meet certain conditions so that these
can be considered as learning. These conditions are legitimacy,
comprehend capacity, utility, curiosity and interestingness. Successive example are the arrangement of Items that happen as often as possible, near each other and are extricated from the value-based database. Incessant example mining is a standout amongst the most vital and all around inquired about strategies
of data mining. The Organization principle characterized as “the
assignment is to discover the relationship between the habitations
of different thing inside the dataset.” The Organization control exclusively reliant on the Discovery of Frequent example. The
nearness of one arrangement of things in an exchange suggests other arrangement of things.
II. Related Work
Brunie et al. [42] proposed engineering for mining geno-therapeutic data in heterogeneous and network based appropriated
bases. Mahmud Khan et al. [15] concentrated on choice tree
data digging calculation for restorative picture examination.
Particularly they contemplated on lung tumor finding through arrangement of x-beam pictures. Podgorelec et al. [21] introduced
an anomaly expectation technique for enhancing execution of grouping as a major aspect of therapeutic data mining. Wang
et al. [22] connected fluffy group investigation for therapeutic pictures. They utilized choice tree calculation to characterize
mammography into ordinary and anomalous cases. Cheng et al.
[17] connected grouping calculation to analyze cardio vascular
sicknesses. For characterization viability they concentrated on two element extraction strategies in particular programmed highlight choice and master judgment. Seng et al. [43] presented electronic data digging for the use of telemedicine.
Ghannad-Rezaie et al. [44] exhibited a way to deal with coordinate PSO guideline mining techniques and classifier on patient dataset. They utilized Particle Swarm Optimization system too. The outcomes uncovered that, their methodology is fit for performing surgery
hopeful determination handle adequately in epilepsy. Bethel et al.
[12] built up an affiliation principle learner which depends on the criteria gathered from past bosom disease patients. The principle learner is utilized as a part of an instrument by name “Clinical Trial Assignment Expert System”. Xue et al. [25] proposed and
connected Bayesian Network calculation for determination of an
infirmity known as Coronary Heart Disease (CHD). Abraham et
al. [26] proposed separation systems to enhance the precision of
grouping of medicinal data utilizing Naive Bayesian classifier calculation. Hassan and Verma [27] proposed a crossover
approach for grouping of restorative data which joins K-implies,
Self Organizing Map (SOM) and Naïve Bayes with NN based classifier. Tsumoto [45] concentrated on multi-stage restorative
conclusion utilizing specialists’ demonstrative guidelines and
analytic scientific classification. They concentrated on programmed
gathering of medicinal learning removed from clinical database.
Berlingerio et al. [28] considered Time Annotated Sequences (TAS) calculation for mining therapeutic data with transient measurements. The removed examples displayed the quality
connections in time space which helps in exact determination.
consolidated three forecast models, for example, SVM (Support Vector Machine), Artificial Neural Networks (ANN), and Decision trees utilizing C4.5 or ID3, CART and C5. Abe et al. [46] proposed
a coordinated timeseries data digging environment for mining enormous measure of therapeutic data for extricating more
significant standard sets. Jiquan et al. [47] proposed a structure
known as term-mapping to consolidate different medicinal data
hotspots for data mining. Barnathan et al. [30] introduced a structure
for bunching, arrangement and likeness inquiry of biomedical pictures or 2D and 3D in nature. Shusaku et al. [48] proposed
multi-scale coordinating and grouping strategy on medicinal data. Their outcomes uncovered that their system is fit for gathering hepatitis
data in light of worldly covariance of choline esterase, egg whites
and platelet. Hai Wang, and Shouhong Wang [49] contemplated
on the part of medicinal specialists in therapeutic data mining.
Therapeutic specialists can give master exhortation that can
be utilized as contribution as a part of medicinal data mining.
Abdullah et al. [1] connected apriori calculation for restorative data mining. They removed regular thing sets by dissecting relationship amongst medications and analysis. Saraee et al. [18] connected data
mining strategies to medicinal data relating to military as for death
rate in kids because of mishaps. They utilized CART calculation to create a choice tree. Balakrishnan and Narayanaswamy [31] exhibited highlight determination utilizing SVM for ordering
diabetes databases. Medications and health impacts are mined
by Froelich and Wakulicz-Deja [29] utilizing versatile FCM (Fuzzy Cognitive Maps). Their work has prompted enhanced choice backing and arranging in Healthcare space. Pradhan and Prabhakaran [50] proposed a methodology through affiliation
standard mining to mine high-dimensional, time arrangement
restorative data for finding high certainty designs. Karegowda and Jayaram [23] proposed a model to order diabetic database
utilizing two systems as a part of falling design for characterization
precision. The procedures are known as Correlation based Feature Selection (CFS) and Genetic Algorithm (GA). CHAO and WONG [19] proposed a choice tree learning system which could decipher
qualities in medicinal data arrangement for higher precision when
contrasted and Incremental Tree Induction (ITI) calculation. TANG and TSENG [24] considers three classifiers for therapeutic data mining. They are weighting fluffy k-NN, fluffy k-NN, and fresh k-NN to group diabetic and malignancy datasets. Tu et al. [20] proposed an astute restorative choice emotionally supportive
network which gives conclusion of heart ailments through choice
tree calculation C4.5 and packing calculation Naïve Bayes. Su et al. 2011 [14] investigated three strategies to be specific Back Propagation Network (BPN), C4.5 (choice tree calculation), and Bayasian Network (BN) for mining medicinal databases. Hogl [51] presented a dialect known as Knowledge Discover Question Language for get ready inquiries that are utilized to find learning from medicinal data. They investigated ways and means for astute
therapeutic data mining.
III. Data Mining in Health Care Sector
Healthcare sector is a massive area which deals with data about hospitals, patients, doctors,medical devices and equipment’s. The
management of large health care data poses a great challenge to
the researchers. The usage of data mining and machine learning techniques has revolutionized the healthcare organizations. The field of data mininghelps to discover hidden patterns by bringing
a set of machine learning tools and techniques. It is useful in evaluating the effectiveness of medical treatments. Data mining
techniques like classification, association, clustering are applied
to healthcare datasets to analyses data to improve health policy-making, early detection of disease outbreaks and preventing the occurrence of various diseases. Data mining provides healthcare authorities an additional source of knowledge for effective
decision-making. The information provided by data mining
methods can help healthcare insurers detect fraud and abuse and healthcare organizations can make better customer relationship management decisions. Further physicians can identify effective treatments with best practices and patients will receive better and more affordable healthcare services. Data Mining techniques are also used to analyze the various factors that are responsible for diseases for example type of food, different working environment, education level, living conditions, availability of pure water, health care services, cultural ,environmental and agricultural factors.
IV. Methodology
The conceptual model of virtuous data mining cycle presented in figure-1, presented by [15]. Every time data mining start with the problem identification followed by data preprocessing and finally implementation of data mining task. In the figure-1 showed the
basic steps involved in data mining complete process which can also consider a life cycle of data mining process may have several
iterations. According to four boxes in the figures representing the
four basic steps, may includes some other sub-tasks in each of the steps. For example, in the second step data transformation consider a comprehensive steps must include in the data mining cycle.
Fig. 1: Virtuous Cycle of Data Mining
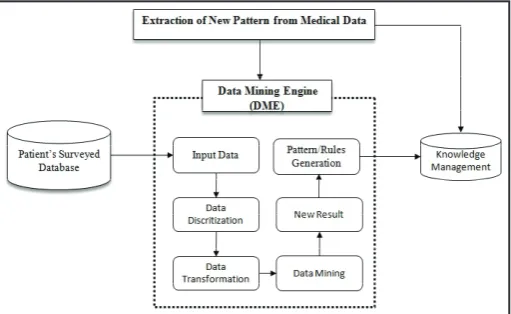
A. Data Mining Engine(DME)
The Data Mining Engine (DME) model presented in the fig. 2, is the core part of this paper. The DME model has been
tested also by using surveyed data of patient in the subsequent
sections. The complete process inside the model with six major steps will generate new patterns and rules from the data. The first step about input data can betaken from online direct survey or from any operational database. Hence, the basic idea here is to finding association between several attributes of patient data.
role for any model. Ultimately the result is based on input data we entered in the model at beginning. If the data has inconsistencies or some cleaning issues then result will not generate appropriately.
As stated by [22] that in every project, problem identification and data preprocessing consume 85% of the total project time.
Furthermore, after selection of data and data preprocessing the next phase is to select appropriate method for data mining task.
Depend on the data itself, problem definition and target value will
guide here in this phase that which technique will be more suitable
here. Therefore, model showed here its simplicity and common
approach can be adaptable by any type of data or organization.
The model is applicable for marketing strategies, sales forecast,
insurance companies, and medical data also. Finally the last two boxes are showing the generation of the result and extraction of new patterns and rules. Knowledge management database is always updating by new result or experience data. For any problem interface is connected with both directly; knowledge management and new process. First the cursor will search the queried answer in the knowledge management, where knowledge management always updating by new result and experience queried data.
Hence, searching in the knowledge management database will
consider rapid result and save of times for running out new process always. It shows also the importance of knowledge management database in this model. In the succeeding section a case study using empirical medical data by using the above mentioned model and followed by each step.
Fig. 2: Data Mining Engine(DME) for Medical Data
V. Concept of Apriori Algorithm
It is the fundamental and most important algorithm for mining
frequent itemsets. It was first given by AgrawalandSrikant in 1994 [7].It is a level wise algorithm which works in an iterative
fashion to discover all frequent itemsets in a database. It uses prior knowledge of frequent itemsets properties [8]. Frequent itemsets
are the sets of items that satisfy minimum support threshold.This
algorithm takes only categorical input and associates attributes
present in the dataset. There is a property associated with this algorithm called “Apriori Property” which states that any subset
of frequent itemsets is also a frequent itemset. For example, if {x,y,z} is a frequent set then the sets { {x},{y},{z} }, { { x,y },{
x,z },{ y,z }} must also be frequent.The execution of this algorithm is organized in two phases. In the first stage, the candidates are
generated and in the next phase frequent itemsets are generated
[9]. The generated large itemsets are used to produce association
rules from database.
The generated large itemsets are used to produce association rules
from database.
Notation:Lk, set of large k-itemset
1. L1 = { large 1-itemsets }
2. for(k=2; Lk− 1 6= ∅ ; k + +) do begin 3. Ck=apriori-gen(Lk− 1); // new candidates
4. forall records r ∈ D do begin
5. Cr = subset(Ck,r); // candidates contained in r
6. forall candidates c ∈ Cr do
7. c.count + +
8. end
9. Lk = {c ∈Ck|(c.count/size(D)) >minsup} 10. end
11. Answer = L =k Lk
VI. Proposed Work
Data mining tools are created for effective analysis of medical data for helping the clinician in enhancing the determination. In this investigation work, the master can assemble data from
Hospital Data System (HIS) which has the satisfactory unobtrusive
components of patient including his name, age, sickness, range, locale, and date from labs which keeps building up an apparently
unending measure of time. Having assembled the data from healing center office data structure, this investigation can find the much of the time happening maladies with the help of affiliation strategies. This examination work mines the data about the much of the time
happening diseases with the help of weka tool associated over
planning data set. In the therapeutic field, the healing center office
data structure is used to get different sorts of medical records of diseases and its patients who hail from various domains. It is a colossal assignment to recognize the consistent sicknesses and its reasons from the considerable data set. Patients from particular
zones approach various centers. They don’t meet in a same spot. Their records are kept up by the mending focuses where they get
treated. Gathering data about the habitually happening sicknesses
is not a basic assignment. The data amassing with respect to these sorts of diseases ought to be conceivable through the affiliation
rules. Bits of knowledge regarding the occasion of these diseases in a particular time period can in like manner be mined with the assistance of apriori algorithm.
Fig. 3: Proposed System
VII. Conclusion
In this paper we analysis various data mining techniques that have been employed for medical data mining. Data mining techniques have higher utility in medical data mining as there is voluminous data in this industry. Due to the rapid growth of medical data, it has become indispensable to use data mining techniques to help
The medical mining yields required business intelligence to support well informed diagnosis and decisions. This paper has provided
the summary of data mining techniques used for medical data
mining besides the diseases they classified. It also throws light
into the importance of locally frequent patterns and the mining
techniques used for the purpose.The association rules play a major role in many data mining applications, trying to find interesting
patterns in data bases. Apriori is the simplest algorithm which is used for mining of frequent patterns from the transaction database.
The main drawback of Apriori algorithm is that the candidate
set generation is costly, especially if a large number of patterns
and/or long patterns exist. Apriori algorithm uses large item set
property, easy to implement, but it repeatedly scan the database.
Apriori takes more time to scan the large Frequents patterns. The Memory based approach is used for efficient mining of frequent
patterns in large databases. Memory based approach we count the support of candidate set only in the transaction record whose length is greater than or equal to the length of candidate set and it
is more efficient than apriori algorithm and also takes lesser time
and gives better performance.
VIII. Results and Decisions
A. We Load EMR Dataset:
In the above screenshot patients EMR dataset is loaded. Here, we have to click on the button view EMR Graph and then on Find Disease in Each Month.
B. Generate Charts:
Here, in the above screenshot two bar charts are generated. One
chart is regarding number of diseases occurs in month-wise
and another chart is regarding number of patients affected from diseases in month-wise.
C. Diseases in Each Month
This is the list of diseases in in each month. From this screen
we have to generate frequent item set by clicking on the button Frequent Disease Mining using Apriori Algorithm.
D. Apriori Algorithm Output:
References
[1] ManasaSudhaAkula, PrajnaBodapati, Shashi Mogalla, CLUSTERING DOCUMENT TREES BASED ON SIMILARITY MEASURE [Online] Available: http://www. innovativejournal.in/index.php/ajcsit/article/view/291,
[2] M.K.V.Anvesh, Dr. B. Prajna, [Online] Available: http:// www.ijecs.in/index.php/archive/103-volume-4-issue-8-
august-2015/397-potential-based-similarity-metrics-for-implementing-hierarchical-clustering,
[3] Rahul Mishra, Abhachoubey,"Comparative Analysis of Apriori Algorithm and Frequent Pattern Algorithm for
Frequent Pattern Mining in Web Log Data", (IJCSIT) International Journal of Computer Science and Information Technologies, Vol. 3 (4) , 2012.
[4] Huipingpeng,“Discovery of Interesting Association Rules on Web Usage Mining”, International Conference, 2010. [5] Agrawal R, Srikant R.,“Fast Algorithms for Mining
Association Rules”, VLDB. Sep 12-15 1994, Chile, 487-99, pdf.
3 - Jun 2014,
[7] Agrawal, R., Imielinski, T., Swami, A. N.,"Mining association
rules between sets of items in large databases", In Proceedings
of the 1993 ACM SIGMOD International Conference on Management of Data, pp. 207-216, 1993.
[8] C.Borgelt,“Efficient Implementations of Apriori and Eclat”, In Proc. 1st IEEE ICDM Workshop on Frequent Item Set Mining Implementations, CEUR Workshop Proceedings 90, Aachen, Germany 2003.
[9] Krutika. K .Jain, Anjali. B. Raut,"Review paper on finding
Association rule using Apriori Algorithm in Data mining
for finding frequent pattern", International Journal of Engineering Research and General Science, Vol. 3, Issue 1, January-February, 2015.
[10] Himani Bathla, Ms. Kavita Kathuria,"Apriori Algorithm and filtered associator in association rule mining", International Journal of Computer Science and Mobile Computing; Vol. 4, Issue. 6, June 2015, pp. 299 – 306,
[11] Shelly Ahuja, Gurpreet Kaur,"Review of Association Rule Mining Using Apriori Algorithm", International Journal
of Advanced Research in Computer Science and Software
Engineering; Vol. 4, Issue 3, March 2014.
[12] R. Agrawal, S. Gollapudi, A. Kannan, K. Kenthapadi. Enriching textbooks with images", In CIKM, 2011.
Potta Swathi is Pursuing M.Tech (Computer Science and Software Engineering) in the Dept. of Computer Science and Systems Engineering, Andhra University, Visakhapatnam,
Andhra Pradesh, India.
Prof. Bodapati Prajna is working as a Professor in Dept. of Computer
Science and Systems Engineering, Andhra University, Visakhapatnam,
![figure-1, presented by [15]. Every time data mining start with the The conceptual model of virtuous data mining cycle presented in problem identification followed by data preprocessing and finally implementation of data mining task](https://thumb-us.123doks.com/thumbv2/123dok_us/1332141.1641567/2.595.303.467.370.620/presented-conceptual-virtuous-presented-identification-followed-preprocessing-implementation.webp)